Xception: Deep Learning with Depthwise Separable Convolutions
xception:深度学习,深度可分离卷积
Abstract
We present an interpretation of Inception modules in convolutional neural networks as being an intermediate step in-between regular convolution and the \textit{depthwise separable convolution} operation (a depthwise convolution followed by a pointwise convolution). In this light, a depthwise separable convolution can be understood as an Inception module with a maximally large number of towers. This observation leads us to propose a novel deep convolutional neural network architecture inspired by Inception, where Inception modules have been replaced with depthwise separable convolutions. We show that this architecture, dubbed Xception, slightly outperforms Inception V3 on the ImageNet dataset (which Inception V3 was designed for), and significantly outperforms Inception V3 on a larger image classification dataset comprising 350 million images and 17,000 classes. Since the Xception architecture has the same number of parameters as Inception V3, the performance gains are not due to increased capacity but rather to a more efficient use of model parameters.
摘要
我们将卷积神经网络中的Inception模块解释为是常规卷积和深度可分离卷积之间的中间步骤运算(先进行深度卷积,再进行点状卷积)。鉴于此,可以将深度方向上可分离的卷积理解为具有最大数量的塔的Inception模块。这一发现使我们提出了一种受Inception启发的新颖的深度卷积神经网络体系结构,其中Inception模块已被深度可分离卷积替代。我们显示,这种被称为Xception的体系结构在ImageNet数据集(Inception V3在此上面设计,这是个包含3.5亿张图像和17,000个类别的较大图像分类数据集)上明显优于Inception V3。它有着和Inception V3相同数量的参数,但是模型更有效果。
.
Introduction
Convolutional neural networks have emerged as the master algorithm in computer vision in recent years, and developing recipes for designing them has been a subject of considerable attention. The history of convolutional neural network design started with LeNet-style models , which were simple stacks of convolutions for feature extraction and max-pooling operations for spatial sub-sampling. In 2012, these ideas were refined into the AlexNet architecture , where convolution operations were being repeated multiple times in-between max-pooling operations, allowing the network to learn richer features at every spatial scale. What followed was a trend to make this style of network increasingly deeper, mostly driven by the yearly ILSVRC competition; first with Zeiler and Fergus in 2013 and then with the VGG architecture in 2014 . At this point a new style of network emerged, the Inception architecture, introduced by Szegedy et al. in 2014 as GoogLeNet (Inception V1), later refined as Inception V2 , Inception V3 , and most recently Inception-ResNet . Inception itself was inspired by the earlier Network-In-Network architecture . Since its first introduction, Inception has been one of the best performing family of models on the ImageNet dataset , as well as internal datasets in use at Google, in particular JFT . The fundamental building block of Inception-style models is the Inception module, of which several different versions exist. In figure inception_module we show the canonical form of an Inception module, as found in the Inception V3 architecture. An Inception model can be understood as a stack of such modules. This is a departure from earlier VGG-style networks which were stacks of simple convolution layers. While Inception modules are conceptually similar to convolutions (they are convolutional feature extractors), they empirically appear to be capable of learning richer representations with less parameters. How do they work, and how do they differ from regular convolutions? What design strategies come after Inception?
简介
近年来,卷积神经网络已成为计算机视觉中的主要算法,开发用于设计它们的配方已成为相当受关注的主题。卷积神经网络设计的历史始于LeNet样式的模型[ 10 ],该模型是用于特征提取的卷积的简单堆栈和用于空间子采样的最大池化操作。在2012年,这些想法被提炼为AlexNet架构[ 9 ],在最大池操作之间多次重复进行卷积操作,从而使网络可以在每个空间尺度上学习更丰富的功能。随后出现的趋势是使这种类型的网络越来越深,这主要是由年度ILSVRC竞争推动的。首先在2013年加入Zeiler和Fergus [ 25 ] ,然后在2014年加入VGG架构[ 18 ]。
此时,出现了一种新的网络样式,即由Szegedy等人介绍的Inception体系结构。在2014年[ 20 ]改名为GoogLeNet(Inception V1),后来又更名为Inception V2 [ 7 ],Inception V3 [ 21 ],以及最近的Inception-ResNet [ 19 ]。Inception本身的灵感来自早期的Network-In-Network体系结构[ 11 ]。自从首次推出以来,Inception一直是ImageNet数据集[ 14 ]以及Google使用的内部数据集,特别是JFT [[5 ]。
Inception样式模型的基本构建模块是Inception模块,其中存在几种不同的版本。在图1中,我们显示了Inception V3体系结构中的Inception模块的规范形式。初始模型可以理解为此类模块的堆栈。这与早期的VGG样式网络不同,后者是简单的卷积层的堆栈。
尽管Inception模块在概念上与卷积相似(它们是卷积特征提取器),但从经验上看,它们似乎能够以较少的参数学习更丰富的表示形式。它们是如何工作的,它们与常规卷积有何不同?Inception之后会有哪些设计策略?
The Inception hypothesis 初始假设
A convolution layer attempts to learn filters in a 3D space, with 2 spatial dimensions (width and height) and a channel dimension; thus a single convolution kernel is tasked with simultaneously mapping cross-channel correlations and spatial correlations. This idea behind the Inception module is to make this process easier and more efficient by explicitly factoring it into a series of operations that would independently look at cross-channel correlations and at spatial correlations. More precisely, the typical Inception module first looks at cross-channel correlations via a set of 1x1 convolutions, mapping the input data into 3 or 4 separate spaces that are smaller than the original input space, and then maps all correlations in these smaller 3D spaces, via regular 3x3 or 5x5 convolutions. This is illustrated in figure inception_module. In effect, the fundamental hypothesis behind Inception is that cross-channel correlations and spatial correlations are sufficiently decoupled that it is preferable not to map them jointly A variant of the process is to independently look at width-wise correlations and height-wise correlations. This is implemented by some of the modules found in Inception V3, which alternate 7x1 and 1x7 convolutions. The use of such spatially separable convolutions has a long history in image processing and has been used in some convolutional neural network implementations since at least 2012 (possibly earlier). . Consider a simplified version of an Inception module that only uses one size of convolution (e.g. 3x3) and does not include an average pooling tower (figure simplified_inception_module). This Inception module can be reformulated as a large 1x1 convolution followed by spatial convolutions that would operate on non-overlapping segments of the output channels (figure simplified_inception_reformulation). This observation naturally raises the question: what is the effect of the number of segments in the partition (and their size)? Would it be reasonable to make a much stronger hypothesis than the Inception hypothesis, and assume that cross-channel correlations and spatial correlations can be mapped completely separately?
卷积层尝试在3D空间中学习过滤器,该空间具有2个空间维度(宽度和高度)和一个通道维度;因此,单个卷积内核的任务是同时映射跨通道相关性和空间相关性。
Inception模块背后的想法是,通过将其明确地分解为一系列可独立查看跨通道相关性和空间相关性的操作,从而使此过程更轻松,更高效。更准确地说,典型的Inception模块首先通过一组1x1卷积查看跨通道相关性,将输入数据映射到小于原始输入空间的3或4个独立空间中,然后在这些较小的3D空间中映射所有相关性,通过常规3x3或5x5卷积。这在图1中示出。实际上,Inception背后的基本假设是跨通道相关性和空间相关性充分解耦,因此最好不要将它们一起映射(该过程的一种变体是独立查看宽度方向的相关性和高度方向的相关性。)这是由Inception V3中的某些模块实现的,这些模块交替进行7x1和1x7卷积。这种空间上可分离的卷积的使用在图像处理中具有悠久的历史,并且至少从2012年起(可能更早)就已在一些卷积神经网络实现中使用。。
考虑Inception模块的简化版本,该模块仅使用一种卷积大小(例如3x3),并且不包括平均池塔average pooling tower(图2)。可以将该Inception模块重新构造为大的1x1卷积,然后再进行空间卷积,这些卷积将在输出通道的非重叠段上进行操作(图3)。这种观察自然会引发一个问题:分区中的段数(及其大小)会产生什么影响?做出比Inception假设强得多的假设,并假设跨通道相关性和空间相关性可以完全分开映射,是否合理?
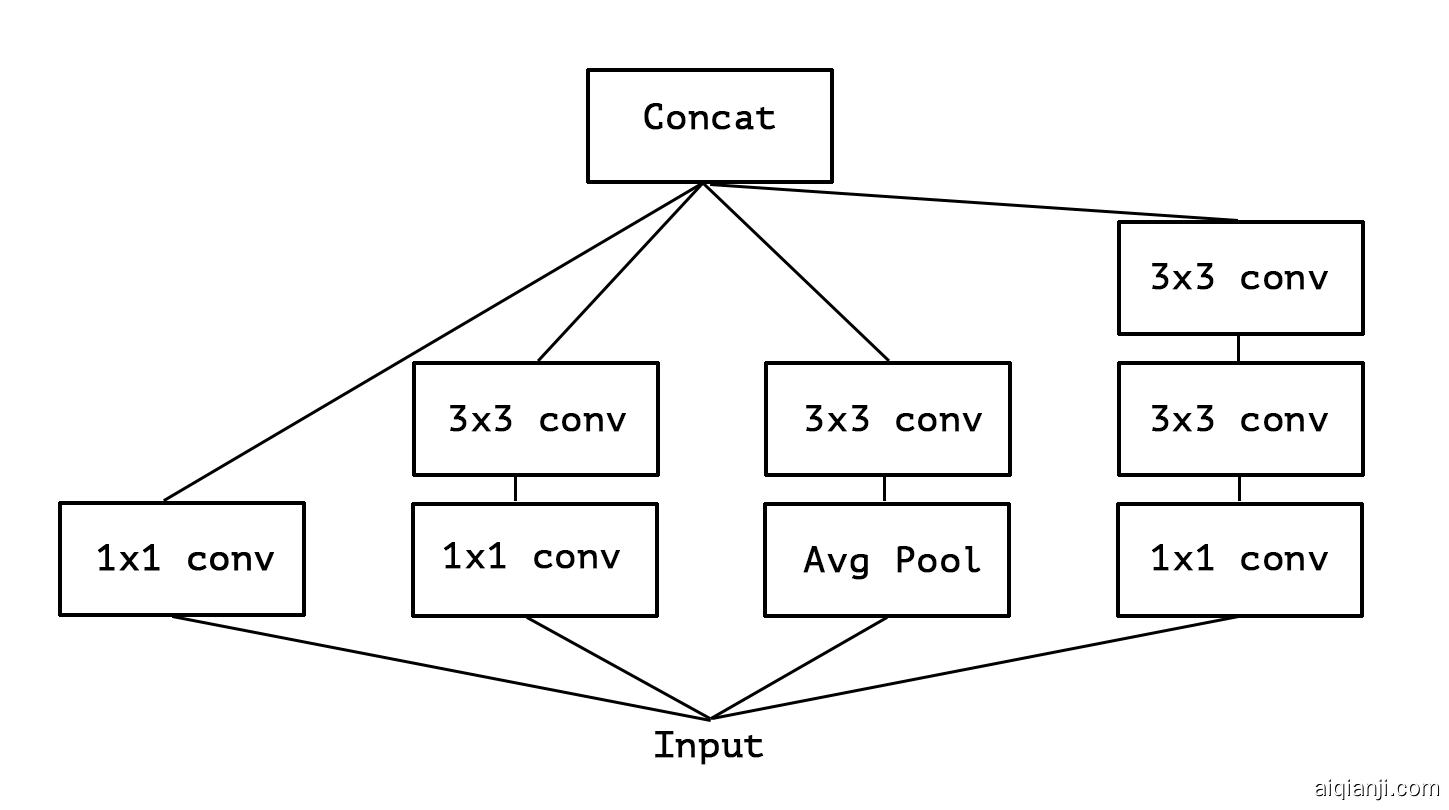
Figure 1: A canonical Inception module (Inception V3).
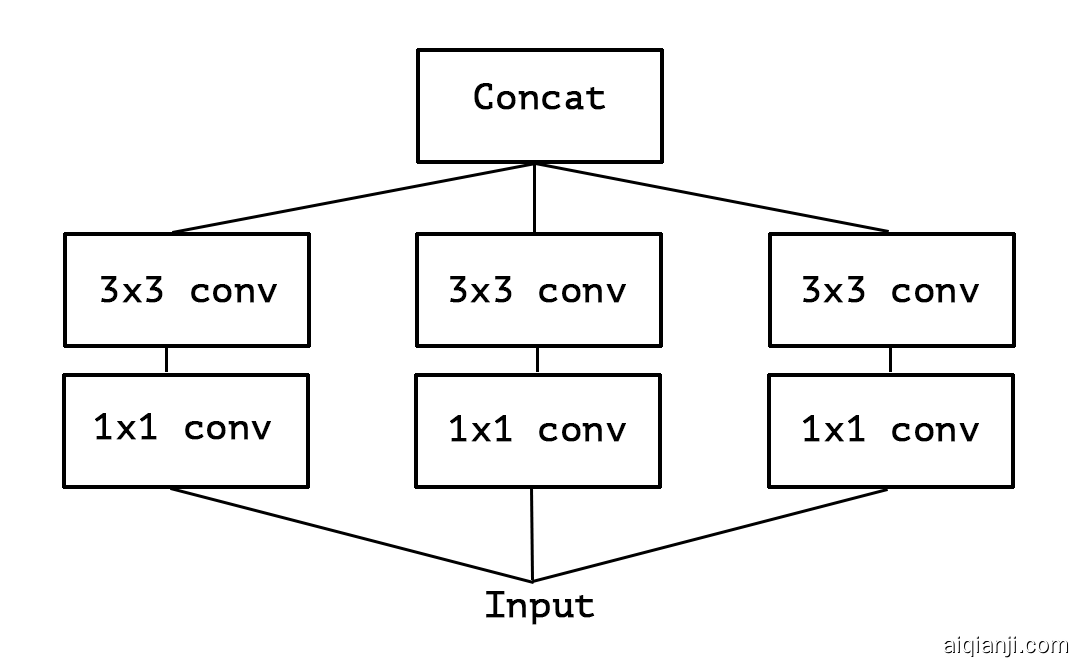
Figure 2: A simplified Inception module.

Figure 3: A strictly equivalent reformulation of the simplified Inception module.

Figure 4: An “extreme” version of our Inception module, with one spatial convolution per output channel of the 1x1 convolution.
The continuum between convolutions and separable convolutions 卷积和可分离卷积之间的连续性
An “extreme” version of an Inception module, based on this stronger hypothesis, would first use a 1x1 convolution to map cross-channel correlations, and would then separately map the spatial correlations of every output channel. This is shown in figure 4. We remark that this extreme form of an Inception module is almost identical to a depthwise separable convolution, an operation that has been used in neural network design as early as 2014 [15] and has become more popular since its inclusion in the TensorFlow framework [1] in 2016.
A depthwise separable convolution, commonly called “separable convolution” in deep learning frameworks such as TensorFlow and Keras, consists in a depthwise convolution, i.e. a spatial convolution performed independently over each channel of an input, followed by a pointwise convolution, i.e. a 1x1 convolution, projecting the channels output by the depthwise convolution onto a new channel space. This is not to be confused with a spatially separable convolution, which is also commonly called “separable convolution” in the image processing community.
Two minor differences between and “extreme” version of an Inception module and a depthwise separable convolution would be:
- The order of the operations: depthwise separable convolutions as usually implemented (e.g. in TensorFlow) perform first channel-wise spatial convolution and then perform 1x1 convolution, whereas Inception performs the 1x1 convolution first.
- The presence or absence of a non-linearity after the first operation. In Inception, both operations are followed by a ReLU non-linearity, however depthwise separable convolutions are usually implemented without non-linearities.
We argue that the first difference is unimportant, in particular because these operations are meant to be used in a stacked setting. The second difference might matter, and we investigate it in the experimental section (in particular see figure 10).
We also note that other intermediate formulations of Inception modules that lie in between regular Inception modules and depthwise separable convolutions are also possible: in effect, there is a discrete spectrum between regular convolutions and depthwise separable convolutions, parametrized by the number of independent channel-space segments used for performing spatial convolutions. A regular convolution (preceded by a 1x1 convolution), at one extreme of this spectrum, corresponds to the single-segment case; a depthwise separable convolution corresponds to the other extreme where there is one segment per channel; Inception modules lie in between, dividing a few hundreds of channels into 3 or 4 segments. The properties of such intermediate modules appear not to have been explored yet.
Having made these observations, we suggest that it may be possible to improve upon the Inception family of architectures by replacing Inception modules with depthwise separable convolutions, i.e. by building models that would be stacks of depthwise separable convolutions. This is made practical by the efficient depthwise convolution implementation available in TensorFlow. In what follows, we present a convolutional neural network architecture based on this idea, with a similar number of parameters as Inception V3, and we evaluate its performance against Inception V3 on two large-scale image classification task.
基于此更强的假设,Inception模块的“极端”版本将首先使用1x1卷积来映射跨通道相关性,然后分别映射每个输出通道的空间相关性。如图4所示。我们注意到,Inception模块的这种极端形式几乎与深度可分离卷积相同,该操作早在2014年就已在神经网络设计中使用[ 15 ],并且自于其在2016年的TensoRFlow框架中纳入以来已经更受欢迎 [1]。 ]。
深度可分离卷积在深度学习框架(如TensorFlow和Keras)中通常称为“可分离卷积”,其中包括深度卷积,即在输入的每个通道上独立执行的空间卷积,然后是逐点卷积,即1x1卷积,将通过深度卷积输出的通道投影到新的通道空间上。请勿将其与空间可分离卷积混淆,空间可分离卷积在图像处理社区中通常也称为“可分离卷积”。
Inception模块的“极端”版本与深度可分离卷积之间的两个小区别是:
- 操作顺序:通常实现的深度可分离卷积(例如在TensorFlow中)首先执行通道空间卷积,然后执行1x1卷积,而Inception首先执行1x1卷积。
- 第一次操作后是否存在非线性。在Inception中,所有操作后面都跟随ReLU这个非线性单元,但是深度可分离卷积通常在没有非线性单元。
In Inception, both operations are followed by a ReLU non-linearity, however depthwise separable convolutions are usually implemented without non-linearities. We argue that the first difference is unimportant, in particular because these operations are meant to be used in a stacked setting. The second difference might matter, and we investigate it in the experimental section (in particular see figure xception_imagenet_activations). We also note that other intermediate formulations of Inception modules that lie in between regular Inception modules and depthwise separable convolutions are also possible: in effect, there is a discrete spectrum between regular convolutions and depthwise separable convolutions, parametrized by the number of independent channel-space segments used for performing spatial convolutions. A regular convolution (preceded by a 1x1 convolution), at one extreme of this spectrum, corresponds to the single-segment case; a depthwise separable convolution corresponds to the other extreme where there is one segment per channel; Inception modules lie in between, dividing a few hundreds of channels into 3 or 4 segments. The properties of such intermediate modules appear not to have been explored yet. Having made these observations, we suggest that it may be possible to improve upon the Inception family of architectures by replacing Inception modules with depthwise separable convolutions, i.e. by building models that would be stacks of depthwise separable convolutions. This is made practical by the efficient depthwise convolution implementation available in TensorFlow. In what follows, we present a convolutional neural network architecture based on this idea, with a similar number of parameters as Inception V3, and we evaluate its performance against Inception V3 on two large-scale image classification task.
我们认为第一个区别并不重要,特别是因为这些操作是要在堆叠的环境中使用的。第二个差异可能很重要,我们将在实验部分对此进行研究(特别是参见图10)。
我们还注意到,位于常规Inception模块和深度可分离卷积之间的Inception模块的其他中间形式也是可能的:实际上,常规卷积和深度可分离卷积之间存在离散频谱,其参数由独立通道空间的数量参数化用于执行空间卷积的线段。在这种频谱的一个极端情况下,常规卷积(以1x1卷积为先)对应于单段情况;深度可分离卷积对应于每个通道有一个分段的另一个极端;初始模块位于两者之间,将数百个通道分为3或4个段。此类中间模块的属性似乎尚未探索。
进行了这些观察后,我们建议通过用深度可分离卷积代替Inception模块,即通过构建将是深度可分离卷积的堆栈的模型,来改进Inception系列体系结构是可能的。通过TensorFlow中可用的有效深度深度卷积实现,这变得切实可行。接下来,我们将基于此思想提出一种卷积神经网络体系结构,其参数数量与Inception V3相似,并针对两个大型图像分类任务针对Inception V3评估其性能。
Prior work 相关工作
The present work relies heavily on prior efforts in the following areas:
- Convolutional neural networks [10, 9, 25], in particular the VGG-16 architecture [18], which is schematically similar to our proposed architecture in a few respects.
- The Inception architecture family of convolutional neural networks [20, 7, 21, 19], which first demonstrated the advantages of factoring convolutions into multiple branches operating successively on channels and then on space.
- Depthwise separable convolutions, which our proposed architecture is entirely based upon. While the use of spatially separable convolutions in neural networks has a long history, going back to at least 2012 [12] (but likely even earlier), the depthwise version is more recent. Laurent Sifre developed depthwise separable convolutions during an internship at Google Brain in 2013, and used them in AlexNet to obtain small gains in accuracy and large gains in convergence speed, as well as a significant reduction in model size. An overview of his work was first made public in a presentation at ICLR 2014 [23]. Detailed experimental results are reported in Sifre’s thesis, section 6.2 [15]. This initial work on depthwise separable convolutions was inspired by prior research from Sifre and Mallat on transformation-invariant scattering [16, 15]. Later, a depthwise separable convolution was used as the first layer of Inception V1 and Inception V2 [20, 7]. Within Google, Andrew Howard [6] has introduced efficient mobile models called MobileNets using depthwise separable convolutions. Jin et al. in 2014 [8] and Wang et al. in 2016 [24] also did related work aiming at reducing the size and computational cost of convolutional neural networks using separable convolutions. Additionally, our work is only possible due to the inclusion of an efficient implementation of depthwise separable convolutions in the TensorFlow framework [1].
- Residual connections, introduced by He et al. in [4], which our proposed architecture uses extensively.
目前的工作在很大程度上取决于在以下领域的先前努力:
- 卷积神经网络[ 10,9,25 ],特别是VGG-16体系结构[ 18 ],这是示意性地类似于我们提出的架构在几个方面。
- Inception 系列卷积神经网络[ 20,7,21,19 ],首先展示了将卷积组合成多个分支结构,将其分解为在频道上的连续操作的优势
- 深度可分离卷积,这是我们提出的体系结构完全基于的。虽然在神经网络中使用空间上可分离的卷积已有很长的历史,但至少可以追溯到2012年[ 12 ](但可能更早),但深度版本是最近的。Laurent Sifre于2013年在Google Brain实习期间开发了深度可分离卷积,并在AlexNet中使用了它们,从而获得了较小的准确性和较大的收敛速度,并且显着减小了模型大小。在2014年ICLR上的一次演讲中首次公开了他的工作概述[ 23 ]。详细的实验结果在Sifre论文的6.2节中报告[ 15 ]。深度方向上的可分离卷积该初始工作是从Sifre和的Mallat上变换不变散射之前研究的启发[ 16,15 ]。之后,将深度可分离卷积用作用在InceptionV1和InceptionV2上的第一层[ 20,7 ]。在Google内部,安德鲁·霍华德[ 6 ]使用深度可分离卷积引入了称为MobileNets的高效移动模型。Jin等。在2014年[ 8 ]和Wang等。2016年[ 24 ]还做了相关工作,旨在减少使用可分离卷积的卷积神经网络的大小和计算成本。此外,由于TensorFlow框架[ 1 ]中包含深度可分离卷积的有效实现,因此我们的工作才有可能实现。
- 残差联系,由He等人介绍。在[ 4 ]中,我们提出的体系结构中广泛使用到它。
The Xception architecture Xception架构
We propose a convolutional neural network architecture based entirely on depthwise separable convolution layers. In effect, we make the following hypothesis: that the mapping of cross-channels correlations and spatial correlations in the feature maps of convolutional neural networks can be entirely decoupled. Because this hypothesis is a stronger version of the hypothesis underlying the Inception architecture, we name our proposed architecture Xception, which stands for “Extreme Inception”.
A complete description of the specifications of the network is given in figure 5. The Xception architecture has 36 convolutional layers forming the feature extraction base of the network. In our experimental evaluation we will exclusively investigate image classification and therefore our convolutional base will be followed by a logistic regression layer. Optionally one may insert fully-connected layers before the logistic regression layer, which is explored in the experimental evaluation section (in particular, see figures 7 and 8). The 36 convolutional layers are structured into 14 modules, all of which have linear residual connections around them, except for the first and last modules.
In short, the Xception architecture is a linear stack of depthwise separable convolution layers with residual connections. This makes the architecture very easy to define and modify; it takes only 30 to 40 lines of code using a high-level library such as Keras [2] or TensorFlow-Slim [17], not unlike an architecture such as VGG-16 [18], but rather unlike architectures such as Inception V2 or V3 which are far more complex to define. An open-source implementation of Xception using Keras and TensorFlow is provided as part of the Keras Applications module https://keras.io/applications/#xception , under the MIT license.
我们提出了一种完全基于深度可分离卷积层的卷积神经网络体系结构。实际上,我们做出以下假设:卷积神经网络的特征图中跨通道相关性和空间相关性的映射可以完全解耦。因为此假设是Inception体系结构假设的更强版本,所以我们将建议的体系结构Xception命名为“ Extreme Inception”。
网络规范的完整描述在图5中给出。Xception体系结构具有36个卷积层,构成了网络的特征提取基础。在我们的实验评估中,我们将专门研究图像分类,因此在我们的卷积基础之后将是逻辑回归层。可选地,可以在逻辑回归层之前插入完全连接的层,这将在实验评估部分中进行探讨(特别是,参见图7和8)。36个卷积层被构造为14个模块,除了第一个和最后一个模块外,所有这些模块周围都具有线性残差连接。
简而言之,Xception体系结构是具有残差连接的深度可分离卷积层的线性堆栈。这使得体系结构非常容易定义和修改。使用高级库(例如Keras [ 2 ]或TensorFlow-Slim [ 17 ])仅需要30至40行代码,这与VGG-16 [ 18 ]这样的体系结构没有什么不同,但与Inception V2或V3的定义却要复杂得多。作为Keras应用程序模块2的一部分,提供了使用Keras和TensorFlow的Xception的开源实现。 https://keras.io/applications/#xception,在MIT许可
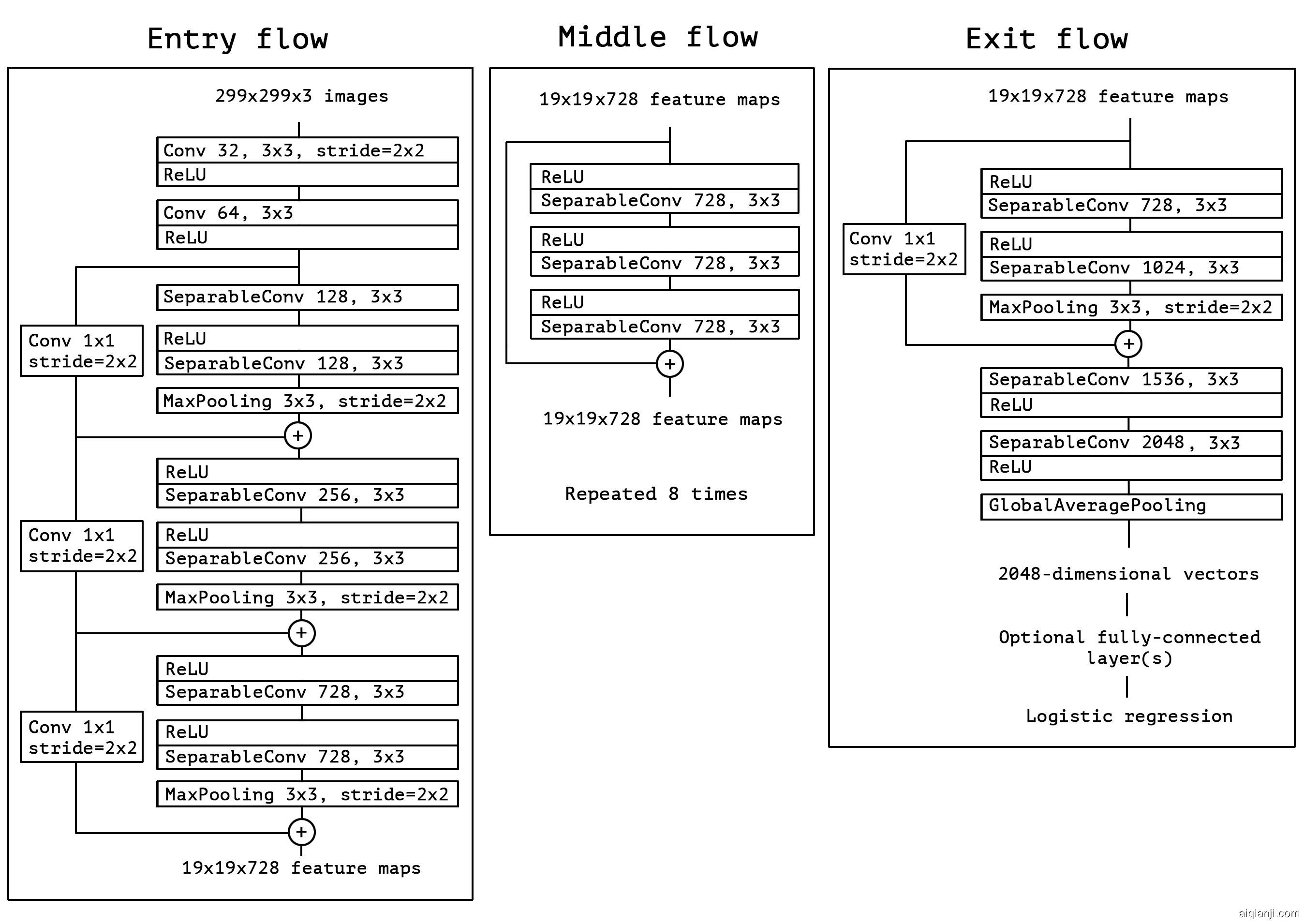
Figure 5: The Xception architecture: the data first goes through the entry flow, then through the middle flow which is repeated eight times, and finally through the exit flow. Note that all Convolution and SeparableConvolution layers are followed by batch normalization [7] (not included in the diagram). All SeparableConvolution layers use a depth multiplier of 1 (no depth expansion).
图5: Xception体系结构:数据首先经过入口流,然后经过重复八次的中间流,最后经过出口流。请注意,所有卷积和SeparableConvolution层之后均进行批处理归一化[ 7 ](图中未包括)。所有SeparableConvolution图层均使用深度倍数1(无深度扩展)。
Experimental evaluation 实验评估
We choose to compare Xception to the Inception V3 architecture, due to their similarity of scale: Xception and Inception V3 have nearly the same number of parameters (table sizeandspeed), and thus any performance gap could not be attributed to a difference in network capacity. We conduct our comparison on two image classification tasks: one is the well-known 1000-class single-label classification task on the ImageNet dataset , and the other is a 17,000-class multi-label classification task on the large-scale JFT dataset.
我们选择将xception与v3架构进行比较,由于它们的规模相似:xception和v3具有几乎相同数量的参数(表sizeandspeed),因此任何性能差距都无法归因于a网络容量差异。我们对两种图像分类任务进行比较:一个是ImageNet DataSet上的众所周知的1000级单个标签分类任务,另一个是大型JFT数据集上的17,000级多标签分类任务。
The JFT dataset JFT数据集
JFT is an internal Google dataset for large-scale image classification dataset, first introduced by Hinton et al. in , which comprises over 350 million high-resolution images annotated with labels from a set of 17,000 classes. To evaluate the performance of a model trained on JFT, we use an auxiliary dataset, . FastEval14k is a dataset of 14,000 images with dense annotations from about 6,000 classes (36.5 labels per image on average). On this dataset we evaluate performance using Mean Average Precision for top 100 predictions (MAP@100), and we weight the contribution of each class to MAP@100 with a score estimating how common (and therefore important) the class is among social media images. This evaluation procedure is meant to capture performance on frequently occurring labels from social media, which is crucial for production models at Google.
JFT是用于大型图像分类数据集的内部Google数据集,最早由Hinton等人引入。在[ 5 ]中,它包含超过3.5亿个高分辨率图像,这些图像带有来自17,000个类别的标签的注释。为了评估在JFT上训练的模型的性能,我们使用了辅助数据集FastEval14k。
FastEval14k是14,000张图像的数据集,其中包含来自大约6,000个类别的密集注释(平均每张图像36.5个标签)。在此数据集上,我们使用平均平均精度对前100个预测(MAP @ 100 )进行评估,并对每个类别对MAP @ 100的贡献进行加权,并给出一个分数,以估算该类别在社交媒体图像中的普遍程度(因此很重要) 。此评估程序旨在从社交媒体上捕获频繁出现的标签上的效果,这对于Google的生产模型至关重要。
Optimization configuration 优化配置
A different optimization configuration was used for ImageNet and JFT:
-
On ImageNet:
- Optimizer: SGD
- Momentum: 0.9
- Initial learning rate: 0.045
- Learning rate decay: decay of rate 0.94 every 2 epochs
-
On JFT:
- Optimizer: RMSprop [22]
- Momentum: 0.9
- Initial learning rate: 0.001
- Learning rate decay: decay of rate 0.9 every 3,000,000 samples
For both datasets, the same exact same optimization configuration was used for both Xception and Inception V3. Note that this configuration was tuned for best performance with Inception V3; we did not attempt to tune optimization hyperparameters for Xception. Since the networks have different training profiles (figure 6), this may be suboptimal, especially on the ImageNet dataset, on which the optimization configuration used had been carefully tuned for Inception V3.
Additionally, all models were evaluated using Polyak averaging [13] at inference time.
ImageNet和JFT使用了不同的优化配置:
-
在ImageNet上:
- 优化程序:SGD
- 动量:0.9
- 初始学习率:0.045
- 学习率衰减:每2个时代0.94的衰减率
-
在JFT上:
- 优化器:RMSprop [ 22 ]
- 动量:0.9
- 初始学习率:0.001
- 学习速率衰减:每3,000,000个样本速率下降0.9
对于两个数据集,Xception和Inception V3都使用了完全相同的优化配置。请注意,此配置已通过Inception V3进行了调整,以实现最佳性能。我们没有尝试针对Xception调整优化超参数。由于网络具有不同的训练配置文件(图6),因此这可能不是最佳的,尤其是在ImageNet数据集上,对于该数据库,针对Inception V3精心优化了使用的优化配置。
此外,在推断时使用Polyak平均[ 13 ]评估了所有模型。

Figure 6: Training profile on ImageNet
Regularization configuration 正则化配置
- Weight decay: The Inception V3 model uses a weight decay (L2 regularization) rate of 4e−5, which has been carefully tuned for performance on ImageNet. We found this rate to be quite suboptimal for Xception and instead settled for 1e−5. We did not perform an extensive search for the optimal weight decay rate. The same weight decay rates were used both for the ImageNet experiments and the JFT experiments.
- Dropout: For the ImageNet experiments, both models include a dropout layer of rate 0.5 before the logistic regression layer. For the JFT experiments, no dropout was included due to the large size of the dataset which made overfitting unlikely in any reasonable amount of time.
- Auxiliary loss tower: The Inception V3 architecture may optionally include an auxiliary tower which backpropagates the classification loss earlier in the network, serving as an additional regularization mechanism. For simplicity, we choose not to include this auxiliary tower in any of our models.
- 权重衰减: Inception V3模型使用权重衰减(L2正则化)速率为 4e-5 率,已对其进行了精心调整,以提高ImageNet的性能。我们发现,对于Xception来说,该速率是次优的,因此选择了1E-5 $。我们没有对最佳重量衰减速率进行广泛的搜索。对于Imagenet实验和JFT实验,使用相同的重量衰减率。
- dropout:对于ImageNet实验,两个模型在逻辑回归层之前都包含一个速率为0.5的dropout层。对于JFT实验,由于数据集的大小过大,因此在任何合理的时间内都不太可能进行过度拟合,因此不包括任何dropout。
- 辅助loss计算: Inception V3体系结构可以选择包括一个辅助计算,该辅助计算在网络早期地反向传播计算分类loss,用作附加的正则化机制。为简单起见,我们选择在任何模型中均不包括该辅助计算。
Training infrastructure 训练基础架构
All networks were implemented using the TensorFlow framework and trained on 60 NVIDIA K80 GPUs each. For the ImageNet experiments, we used data parallelism with gradient descent to achieve the best classification performance, while for JFT we used gradient descent so as to speed up training. The ImageNet experiments took approximately 3 days each, while the JFT experiments took over one month each. The JFT models were not trained to full convergence, which would have taken over three month per experiment.
所有网络均使用TensorFlow框架[ 1 ]实施,并分别在60个NVIDIA K80 GPU上进行了培训。对于ImageNet实验,我们使用具有同步梯度下降的数据并行性来获得最佳的分类性能,而对于JFT,我们使用异步梯度下降以加快训练速度。ImageNet实验每个大约花费3天,而JFT实验每个则花费一个多月。JFT模型没有经过完全收敛的训练,每个实验将花费三个月以上的时间。
Comparison with Inception V3 与Inception v3的比较
Classification performance 分类表现
All evaluations were run with a single crop of the inputs images and a single model. ImageNet results are reported on the validation set rather than the test set (i.e. on the non-blacklisted images from the validation set of ILSVRC 2012). JFT results are reported after 30 million iterations (one month of training) rather than after full convergence. Results are provided in table imagenetperf and table jftperf, as well as figure xception_imagenet, figure xception_jft_no_fc, figure xception_jft_with_fc. On JFT, we tested both versions of our networks that did not include any fully-connected layers, and versions that included two fully-connected layers of 4096 units each before the logistic regression layer. On ImageNet, Xception shows marginally better results than Inception V3. On JFT, Xception shows a 4.3% relative improvement on the FastEval14k MAP@100 metric. We also note that Xception outperforms ImageNet results reported by He et al. for ResNet-50, ResNet-101 and ResNet-152 .
所有评估都是通过单幅输入图像和单个模型进行的。ImageNet结果报告在验证集而非测试集上(即,在ILSVRC 2012验证集的未列入黑名单的图像上)。JFT的结果是经过3000万次迭代(一个月的培训)后报告的,而不是完全收敛之后的结果。结果在表1和表2以及图6,图7,图8中提供。在JFT上,我们测试了不包含任何完全连接层的两个版本的网络,以及在逻辑回归层之前包含两个4096个单位的完全连接层的版本。
在ImageNet上,Xception比Inception V3的结果略好。在JFT上,Xception对FastEval14k MAP @ 100指标显示出4.3%的相对改进。我们还注意到,Xception优于He等人报告的ImageNet结果。用于ResNet-50,ResNet-101和ResNet-152 [ 4 ]。
| Top-1 accuracy | Top-5 accuracy | |
|---|---|---|
| VGG-16 | 0.715 | 0.901 |
| ResNet-152 | 0.770 | 0.933 |
| Inception V3 | 0.782 | 0.941 |
| Xception | 0.790 | 0.945 |
Table 1: Classification performance comparison on ImageNet (single crop, single model). VGG-16 and ResNet-152 numbers are only included as a reminder. The version of Inception V3 being benchmarked does not include the auxiliary tower.
| FastEval14k MAP@100 | |
|---|---|
| Inception V3 - no FC layers | 6.36 |
| Xception - no FC layers | 6.70 |
| Inception V3 with FC layers | 6.50 |
| Xception with FC layers | 6.78 |
Table 2: Classification performance comparison on JFT (single crop, single model).

Figure 7: Training profile on JFT, without fully-connected layers

Figure 8: Training profile on JFT, with fully-connected layers
The Xception architecture shows a much larger performance improvement on the JFT dataset compared to the ImageNet dataset. We believe this may be due to the fact that Inception V3 was developed with a focus on ImageNet and may thus be by design over-fit to this specific task. On the other hand, neither architecture was tuned for JFT. It is likely that a search for better hyperparameters for Xception on ImageNet (in particular optimization parameters and regularization parameters) would yield significant additional improvement.
与ImageNet数据集相比,Xception体系结构在JFT数据集上显示出更大的性能改进。我们认为,这可能是由于Inception V3专注于ImageNet而开发的,因此可能是由于设计过分地适合此特定任务。另一方面,两种架构都不适合JFT。在ImageNet上搜索更好的Xception超参数(尤其是优化参数和正则化参数)可能会带来重大的额外改进。
Size and speed 大小和速度
In table sizeandspeed we compare the size and speed of Inception V3 and Xception. Parameter count is reported on ImageNet (1000 classes, no fully-connected layers) and the number of training steps (gradient updates) per second is reported on ImageNet with 60 K80 GPUs running synchronous gradient descent. Both architectures have approximately the same size (within 3.5%), and Xception is marginally slower. We expect that engineering optimizations at the level of the depthwise convolution operations can make Xception faster than Inception V3 in the near future. The fact that both architectures have almost the same number of parameters indicates that the improvement seen on ImageNet and JFT does not come from added capacity but rather from a more efficient use of the model parameters.
| Parameter count | Steps/second | |
|---|---|---|
| Inception V3 | 23,626,728 | 31 |
| Xception | 22,855,952 | 28 |
Table 3: Size and training speed comparison.
在表3中,我们比较了Inception V3和Xception的大小和速度。在ImageNet上报告参数计数(1000个类,没有完全连接的层),在具有60个运行同步梯度下降的K80 GPU的ImageNet上报告每秒的训练步骤(梯度更新)数。两种架构的大小大致相同(在3.5%以内),Xception的速度稍慢一些。我们期望深度卷积运算级别的工程优化可以使Xception在不久的将来比Inception V3更快。两种体系结构具有几乎相同数量的参数这一事实表明,在ImageNet和JFT上看到的改进不是来自增加的容量,而是来自更有效地使用模型参数。
Effect of the residual connections 残差连接的影响
To quantify the benefits of residual connections in the Xception architecture, we benchmarked on ImageNet a modified version of Xception that does not include any residual connections. Results are shown in figure xception_imagenet_nonresidual. Residual connections are clearly essential in helping with convergence, both in terms of speed and final classification performance. However we will note that benchmarking the non-residual model with the same optimization configuration as the residual model may be uncharitable and that better optimization configurations might yield more competitive results. Additionally, let us note that this result merely shows the importance of residual connections , and that residual connections are in no way in order to build models that are stacks of depthwise separable convolutions. We also obtained excellent results with non-residual VGG-style models where all convolution layers were replaced with depthwise separable convolutions (with a depth multiplier of 1), superior to Inception V3 on JFT at equal parameter count.
为了量化Xception体系结构中残留连接的好处,我们在ImageNet上对不包含任何残留连接的Xception的修改版本进行了基准测试。结果如图9所示。在速度和最终分类性能方面,残余连接显然对于帮助收敛至关重要。但是,我们将注意到,使用与残差模型相同的优化配置对非残差模型进行基准测试可能是不明智的,并且更好的优化配置可能会产生更具竞争力的结果。
另外,让我们注意,此结果仅显示了此特定体系结构的残差连接的重要性,并且不需要以建立深度可分离卷积堆栈的模型的方式来要求残差连接。我们还用非残留VGG样式的模型获得了优异的结果,其中所有卷积层都被深度可分离的卷积(深度乘数为1)替换,在相等参数数下优于JFT上的Inception V3。

Figure 9: Training profile with and without residual connections.
Effect of an intermediate activation after pointwise convolutions 点卷积后中间激活的影响
We mentioned earlier that the analogy between depthwise separable convolutions and Inception modules suggests that depthwise separable convolutions should potentially include a non-linearity between the depthwise and pointwise operations. In the experiments reported so far, no such non-linearity was included. However we also experimentally tested the inclusion of either ReLU or ELU as intermediate non-linearity. Results are reported on ImageNet in figure xception_imagenet_activations, and show that the absence of any non-linearity leads to both faster convergence and better final performance. This is a remarkable observation, since Szegedy et al. report the opposite result in for Inception modules. It may be that the depth of the intermediate feature spaces on which spatial convolutions are applied is critical to the usefulness of the non-linearity: for deep feature spaces (e.g. those found in Inception modules) the non-linearity is helpful, but for shallow ones (e.g. the 1-channel deep feature spaces of depthwise separable convolutions) it becomes harmful, possibly due to a loss of information.
前面我们提到过,深度可分离卷积和Inception模块之间的类比表明,深度可分离卷积可能应包括深度和点运算之间的非线性。在迄今为止报道的实验中,没有包括这样的非线性。但是,我们还通过实验测试了ReLU或ELU [ 3 ]的包含作为中间非线性。结果在ImageNet上的图10中进行了报告,结果表明,缺少任何非线性都会导致更快的收敛速度和更好的最终性能。
自从Szegedy等人以来,这是一个了不起的发现。在[ 21 ]中为Inception模块报告相反的结果。可能是在其上应用了空间卷积的中间特征空间的深度对于非线性的有效性至关重要:对于较深的特征空间(例如,在Inception模块中发现的那些),非线性是有帮助的,但对于较浅的特征它(例如深度可分离卷积的1通道深特征空间)变得有害,可能是由于信息丢失所致。

Figure 10: Training profile with different activations between the depthwise and pointwise operations of the separable convolution layers.
Future directions 未来发展方向
We noted earlier the existence of a discrete spectrum between regular convolutions and depthwise separable convolutions, parametrized by the number of independent channel-space segments used for performing spatial convolutions. Inception modules are one point on this spectrum. We showed in our empirical evaluation that the extreme formulation of an Inception module, the depthwise separable convolution, may have advantages over regular a regular Inception module. However, there is no reason to believe that depthwise separable convolutions are optimal. It may be that intermediate points on the spectrum, lying between regular Inception modules and depthwise separable convolutions, hold further advantages. This question is left for future investigation.
前面我们注意到,在规则卷积和深度可分离卷积之间存在离散频谱,其参数化是用于执行空间卷积的独立通道空间段的数量。初始模块是这一范围的重点。我们在经验评估中表明,与常规的常规Inception模块相比,Inception模块的极端公式化(深度方向上可分离的卷积)可能具有优势。但是,没有理由相信深度可分离卷积是最佳的。可能是频谱上的中间点位于常规的Inception模块和深度可分离的卷积之间,具有其他优势。这个问题留待将来调查。
Conclusions 结论
We showed how convolutions and depthwise separable convolutions lie at both extremes of a discrete spectrum, with Inception modules being an intermediate point in between. This observation has led to us to propose replacing Inception modules with depthwise separable convolutions in neural computer vision architectures. We presented a novel architecture based on this idea, named Xception, which has a similar parameter count as Inception V3. Compared to Inception V3, Xception shows small gains in classification performance on the ImageNet dataset and large gains on the JFT dataset. We expect depthwise separable convolutions to become a cornerstone of convolutional neural network architecture design in the future, since they offer similar properties as Inception modules, yet are as easy to use as regular convolution layers.
我们展示了卷积和深度可分离卷积如何位于离散频谱的两个极端,而Inception模块是介于两者之间的中间点。这种观察导致我们提出在神经计算机视觉体系结构中用深度可分离卷积替换Inception模块。我们基于此思想提出了一种新颖的架构,名为Xception,它的参数计数与Inception V3相似。与Inception V3相比,Xception在ImageNet数据集上的分类性能提高很小,而在JFT数据集上的分类性能提高了很多。我们期望深度可分离卷积在将来成为卷积神经网络体系结构设计的基石,因为它们提供与Inception模块相似的属性,但与常规卷积层一样容易使用。
REFERENCES
- [1] M. Abadi, A. Agarwal, P. Barham, E. Brevdo, Z. Chen, C. Citro, G. S. Corrado, A. Davis, J. Dean, M. Devin, S. Ghemawat, I. Goodfellow, A. Harp, G. Irving, M. Isard, Y. Jia, R. Jozefowicz, L. Kaiser, M. Kudlur, J. Levenberg, D. Mané, R. Monga, S. Moore, D. Murray, C. Olah, M. Schuster, J. Shlens, B. Steiner, I. Sutskever, K. Talwar, P. Tucker, V. Vanhoucke, V. Vasudevan, F. Viégas, O. Vinyals, P. Warden, M. Wattenberg, M. Wicke, Y. Yu, and X. Zheng. TensorFlow: Large-scale machine learning on heterogeneous systems, 2015. Software available from tensorflow.org.
- [2] F. Chollet. Keras. https://github.com/fchollet/keras, 2015.
- [3] D.-A. Clevert, T. Unterthiner, and S. Hochreiter. Fast and accurate deep network learning by exponential linear units (elus). arXiv preprint arXiv:1511.07289, 2015.
- [4] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. arXiv preprint arXiv:1512.03385, 2015.
- [5] G. Hinton, O. Vinyals, and J. Dean. Distilling the knowledge in a neural network, 2015.
- [6] A. Howard. Mobilenets: Efficient convolutional neural networks for mobile vision applications. Forthcoming.
- [7] S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of The 32nd International Conference on Machine Learning, pages 448–456, 2015.
- [8] J. Jin, A. Dundar, and E. Culurciello. Flattened convolutional neural networks for feedforward acceleration. arXiv preprint arXiv:1412.5474, 2014.
- [9] A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems, pages 1097–1105, 2012.
- [10] Y. LeCun, L. Jackel, L. Bottou, C. Cortes, J. S. Denker, H. Drucker, I. Guyon, U. Muller, E. Sackinger, P. Simard, et al. Learning algorithms for classification: A comparison on handwritten digit recognition. Neural networks: the statistical mechanics perspective, 261:276, 1995.
- [11] M. Lin, Q. Chen, and S. Yan. Network in network. arXiv preprint arXiv:1312.4400, 2013.
- [12] F. Mamalet and C. Garcia. Simplifying ConvNets for Fast Learning. In International Conference on Artificial Neural Networks (ICANN 2012), pages 58–65. Springer, 2012.
- [13] B. T. Polyak and A. B. Juditsky. Acceleration of stochastic approximation by averaging. SIAM J. Control Optim., 30(4):838–855, July 1992.
- [14] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, et al. Imagenet large scale visual recognition challenge. 2014.
- [15] L. Sifre. Rigid-motion scattering for image classification, 2014. Ph.D. thesis.
- [16] L. Sifre and S. Mallat. Rotation, scaling and deformation invariant scattering for texture discrimination. In 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, June 23-28, 2013, pages 1233–1240, 2013.
- [17] N. Silberman and S. Guadarrama. Tf-slim, 2016.
- [18] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014.
- [19] C. Szegedy, S. Ioffe, and V. Vanhoucke. Inception-v4, inception-resnet and the impact of residual connections on learning. arXiv preprint arXiv:1602.07261, 2016.
- [20] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1–9, 2015.
- [21] C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna. Rethinking the inception architecture for computer vision. arXiv preprint arXiv:1512.00567, 2015.
- [22] T. Tieleman and G. Hinton. Divide the gradient by a running average of its recent magnitude. COURSERA: Neural Networks for Machine Learning, 4, 2012. Accessed: 2015-11-05.
- [23] V. Vanhoucke. Learning visual representations at scale. ICLR, 2014.
- [24] M. Wang, B. Liu, and H. Foroosh. Factorized convolutional neural networks. arXiv preprint arXiv:1608.04337, 2016.
- [25] M. D. Zeiler and R. Fergus. Visualizing and understanding convolutional networks. In Computer Vision–ECCV 2014, pages 818–833. Springer, 2014.