
我们正在构建一个AI应用安全工程师,帮助开发者自动排查并修复不安全的代码。我们的技术能够减少30%的SAST发现中的误报,并将修复时间加速约80%。为了在大型企业中实现这一目标,我们不得不对模型进行微调,以确保其部署是安全且私密的。
我们为什么对自己的LLM进行微调?
企业,尤其是那些处于受监管行业的企业,对于数据驻留、隐私和安全有着严格的要求。这些组织通常需要私有云部署,并需要避免依赖可能带来数据暴露风险的第三方LLM。我们的微调LLM通过提供完全的数据隔离并避免客户需要签署《商务伙伴协议》(BAAs)来实现HIPAA合规性。此外,这种方法允许我们以低成本的方式部署模型,同时在相关基准测试中甚至超越像OpenAI这样的大规模模型。
模型结构:我们解决方案的核心
我们的解决方案核心为Llama 3.1 8B,这是一个拥有80亿参数的主模型。我们对所有流行的较小模型(包括Mistral、Mixtral、Codestral mamba和Deepseek coder)进行了对照。我们选择Llama 3.1 8B是因为其规模、易于微调、在我们需要的关键领域的可测量性能以及新特性。
该模型有多套微调权重,针对特定任务如误报检测、自动修复和质量检查进行了优化。这种模块化方法使我们在推理时可以使用每项任务的最佳权重。结果表明,合并并扁平化模型会导致效果更差。

你可能会问,你们会部署五次模型吗?不是的,我们会部署核心模型并将请求路由到所需的实际权重。例如,在进行修复时,模型会加载实际的修复权重,并在需要时切换到其他任务。这样我们可以仅用一块A10 24GB GPU 即能实现高性能的切换,延迟约为10毫秒。
这一切为什么重要呢?因为这能节省客户在其私有云端托管大型模型所需的资源。需要更多GPU内存和更强GPU的大型模型是非常昂贵的。而我们的解决方案则极具成本效益。
微调过程:从假设到部署
微调起初看起来像是一个巨大的任务。“垃圾进,垃圾出”,因此对我们来说,挑选最适合跨多种编程语言、框架和漏洞的各种修正方案并尽量减少误报至关重要。作为一家初创公司,我们没有大量人员来标记问题为误报并挑选最佳修复方案来喂给模型进行训练。我们必须创新解决。
我们的数据集是什么?
我们的模型是在一个多样化的数据集上进行训练的,其中包括数百个存储库:我们的闭源项目、设计上易受攻击的开源项目(如Juice Shop),以及其他开源代码库。重要的是,我们在训练过程中从不使用任何客户数据。该数据集涵盖了多种编程语言,包括Python、JavaScript、TypeScript、Java、Go、Ruby和C#,反映了我们客户所在的不同生态系统。我们还需要考虑各种不同框架(如Ruby-on-rails、Django、Flask、Kotlin等)如何处理安全漏洞,因为不同的框架处理方式不同。例如,修复SQL注入漏洞的方法多达30种,这取决于使用的编程语言、框架和数据库。
训练是如何工作的?
通过使用无监督训练技术及我们的误报检测功能和测试框架,我们建立了微调系统,使我们能够扩大数据集的选择范围。
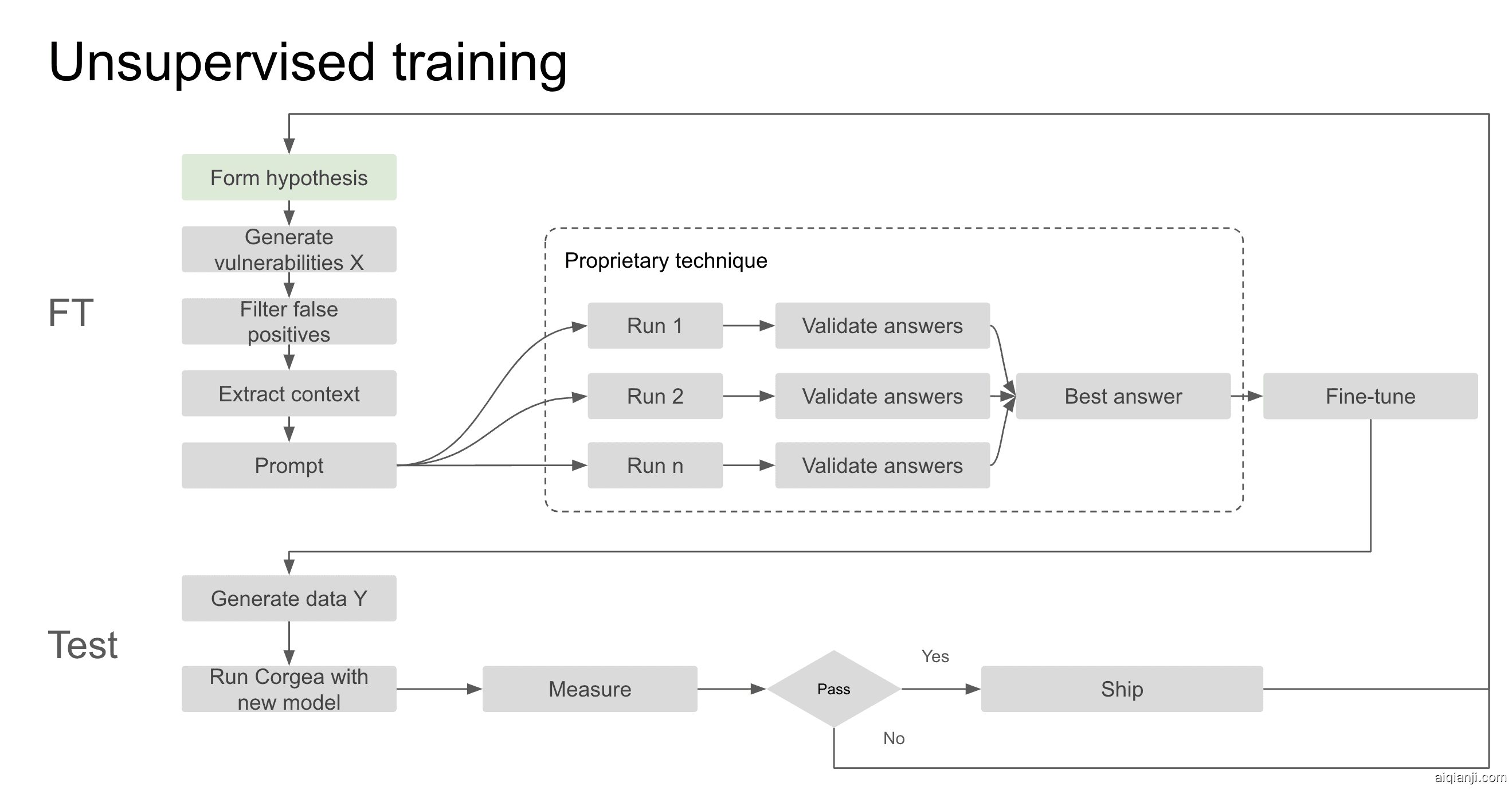
微调过程始于基于要构建或改进的具体领域所形成的一个假设。我们从上述数据集中生成了数千个漏洞。然后利用Corgea中的自动化误报功能排除坏的发现结果。这是至关重要的一步,以确保模型不会被未受攻击的代码的修复方案误导。
随后,我们自动提取相关上下文信息,例如检测使用的语言、调用的导入模块、易受攻击的功能代码块、漏洞以及其他元数据。这些信息会被输入到修复提示中,生成修复方案并与前沿模型进行比较。
我们开发了一种专有技术,涉及多次使用前沿模型进行修复和验证周期,确保选出最佳答案然后再进行最终的微调。过去需要数周时间才能完成的数据标注工作现在可以在不到24小时内并在没有任何人工干预的情况下完成。这些成为我们的训练数据,并且被输入到微调过程中。
一旦微调完成,模型需要通过我们测试框架进行详尽测试。在测试框架中,我们在不同的数据集上对这个新模型进行压力测试,验证模型性能并将其与OpenAI和Anthropic等前沿模型进行对比。只有在达标后才会部署。我们检查的内容包括修复覆盖率、误报率、语法问题、语义问题等。整个过程,从假设到部署,只需2-3天时间,让我们能迅速适应反馈和技术的新发展。
结果:性能和效率
基准测试结果说明了一切:Corgea的安全LLM比OpenAI的模型性能提高了7%,且体积小约90%。几乎每一个漏洞类型都有所改善。
例如,XSS和代码注入问题分别减少了约30%和77%,涵盖所有语言。我们观察到某些类型的漏洞显著改善,是因为微调的缘故。例如,路径遍历(CWE-22)的有效修复增加了2.85倍,不充分的正则表达式复杂度(CWE-1333)有效修复多了4倍。某些特定语言中的修复准确性有所提高,例如JavaScript的修复有效性提高了12%。
更具体地说,我们还发现模型在简单任务上的表现更好了,如无需不必要的空格更改、修改无关代码、过度修复以及凭空假设等。小型模型通常不太遵守指令,会遗漏我们提供的某些输出格式指令。微调真正减少了这些方面的不足。
这些性能提升对于需要高准确度而又不需要大规模计算资源的企业至关重要。而且,由于我们模型较小,可以更加经济高效地部署,进一步降低了总体拥有成本。除了误报检测、解释漏洞及其差异总结方面,我们的模型与OpenAI的表现相当。
结论
Corgea的微调LLM旨在满足企业独特的应用安全需求,提供了强大的、注重隐私的解决方案,从而增强应用程序安全性。通过利用我们的微调流程和精心策划的数据集,我们提供了一个性能卓越且具有成本效益的模型。这确保了企业可以在自己的私有云中自信地部署我们的解决方案,确保数据安全并且受益于最新漏洞管理技术。
这项微调计划不仅仅是关于增强一个模型;而是解决企业在应用安全方面面临的具体挑战。有了Corgea,企业可以期待更快、更准确的漏洞管理,同时完全掌控自己的数据。