搜索引擎已经成为广告和AI生成内容的荒地。
Google曾是互联网的冠军,其搜索结果的质量和速度无人能及。在现代社会中,Google变得臃肿且缓慢。和所有事物一样,Google也屈服于疲软的经济中,搜索质量下降。
作为一名软件工程师,搜索是一个极其重要的工具。文档往往非常密集,在某些情况下甚至不存在。没有一个强大的搜索引擎,找到解决方案或具体的代码示例几乎变得不可能。
为了改变这一现状,我决定自己开发一个个人搜索引擎。虽然这看起来是一项艰巨的任务,但许多曾经新颖的技术(如向量化数据库)如今已成为常见技术。尽管网页爬虫仍然不完全成熟,但在人工智能从互联网各个角落抓取训练数据的今天,它们已变得更加普遍。
要求
免费: 必须免费运营并且使用也是免费的。Kagi是一个很好的付费搜索引擎选项,但我相信我可以通过免费的方式构建一个“足够好”的搜索引擎。这也意味着我不打算使用像Google的API之类的服务,因为这些服务每次查询都要收费。
快速: 它必须像其他替代产品一样迅速。现在是2024年,没有人愿意等待数分钟才能得到结果。为此,我需要一种支持异步处理的语言,以便让单一服务器上的有限线程可以为尽可能多的用户服务。由于我希望成本低廉,所以服务器不仅不会很快,也不会拥有大量内存,这意味着我更倾向于使用编译语言。此外我还需要进行一些网页抓取工作,这使得语言需要具备高性能。
安全: 我希望这个系统是合法的……我不希望通过法律诉讼或违反服务条款。我也相信开放的互联网不应该跟踪用户。因此,我决定不引入账户系统或记录搜索信息。我也希望我的代码尽可能安全,这意味着不会选择C或C++。
基于这些原因并考虑到我对学习该语言的浓厚兴趣,我选择用Rust编写。
我仍处于职业生涯早期阶段,并且对Rust生态系统更是新手。在直接构建搜索引擎之前,我可以采用几个小技巧来获得较快的结果。
搜索引擎提供商Kagi以其高质量结果而闻名,并且主动使用来自Google、DuckDuckGo和Bing的数据作为其数据源之一以实现这一点。我每天大部分时间都在使用DuckDuckGo搜索,相比于现代的Google,我更偏爱它。然而,Google的图像搜索非常出色。由于Google规模庞大,它可以记录用户在搜索特定术语时点击了哪些图片,下次有人搜索该内容时会优先显示该图片,从而形成一种自我强化循环。最终,这将导致高质量的数据来源,使这些图片与相应搜索相关联。当然这只是Google在寻找相关图片时采取的众多方法之一,但这确实是Google图像搜索始终出类拔萃的主要原因之一。
按照第一步计划,我的引擎将提供DuckDuckGo的搜索结果和Google的图像。
DuckDuckGo的主要网站相当复杂,提供了大量的数据。为了限制这一点,我决定使用DuckDuckGo lite。DuckDuckGo lite有明显较少的样式,并且承诺不含JavaScript,这使得它成为更容易抓取的对象。
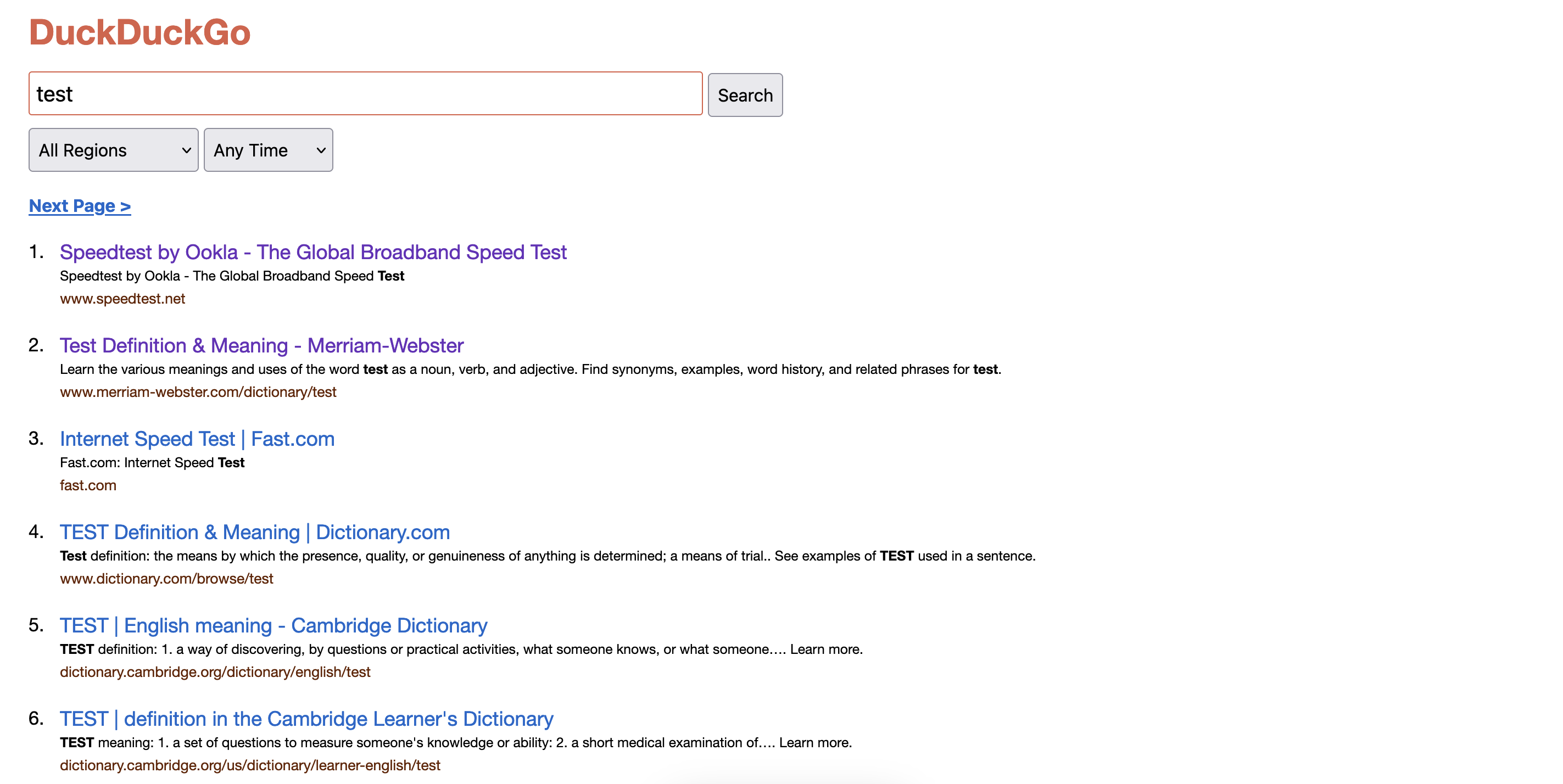
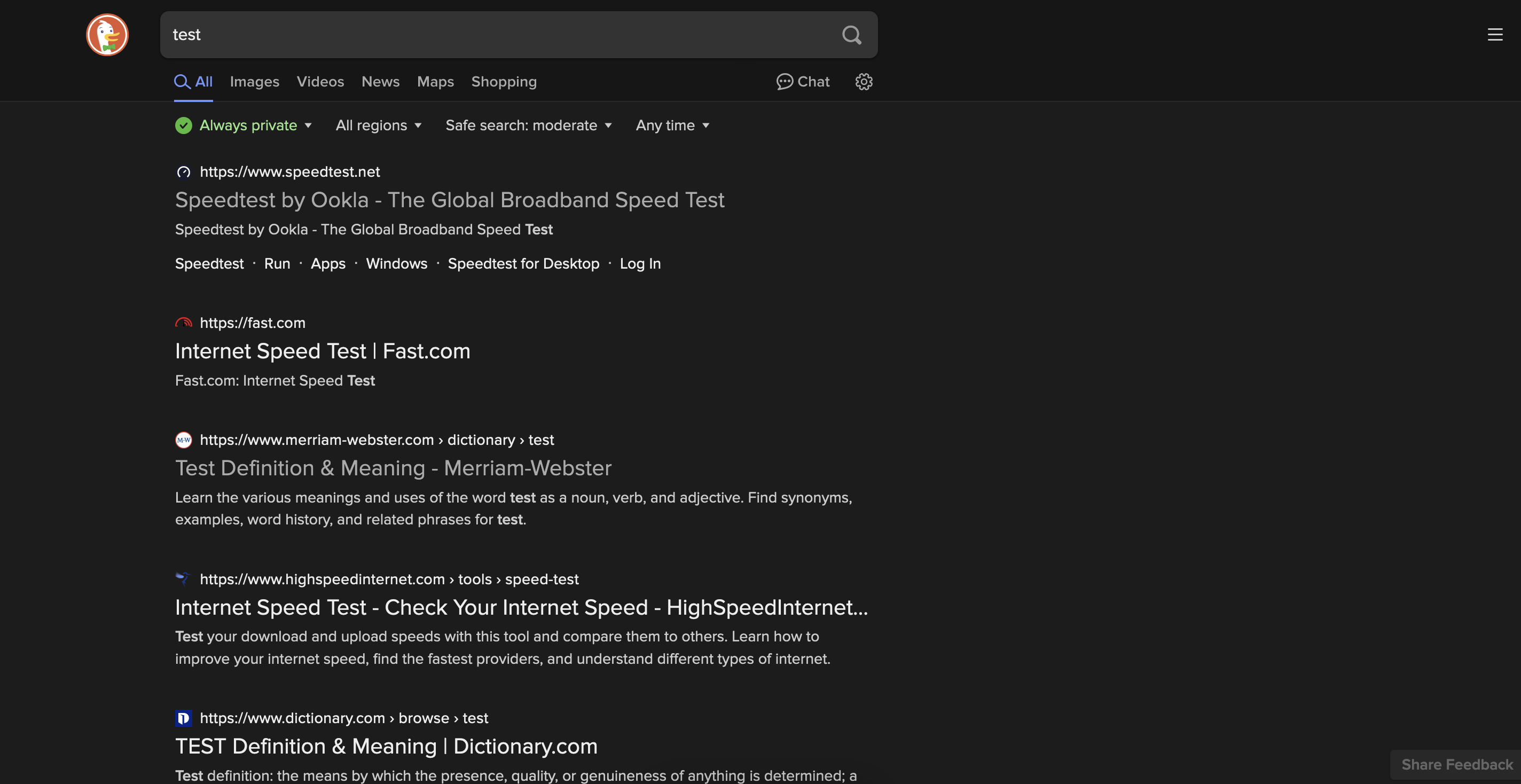
使用DuckDuckGo搜索提供了一个通过GET请求的简单接口。
https://lite.duckduckgo.com/lite?q=TERM
其中TERM替换为用户想要搜索的内容。
这种方法确实很好,会返回一个HTML页面,可以进一步解析,但是如果想要超过最初的30个结果又会怎样?
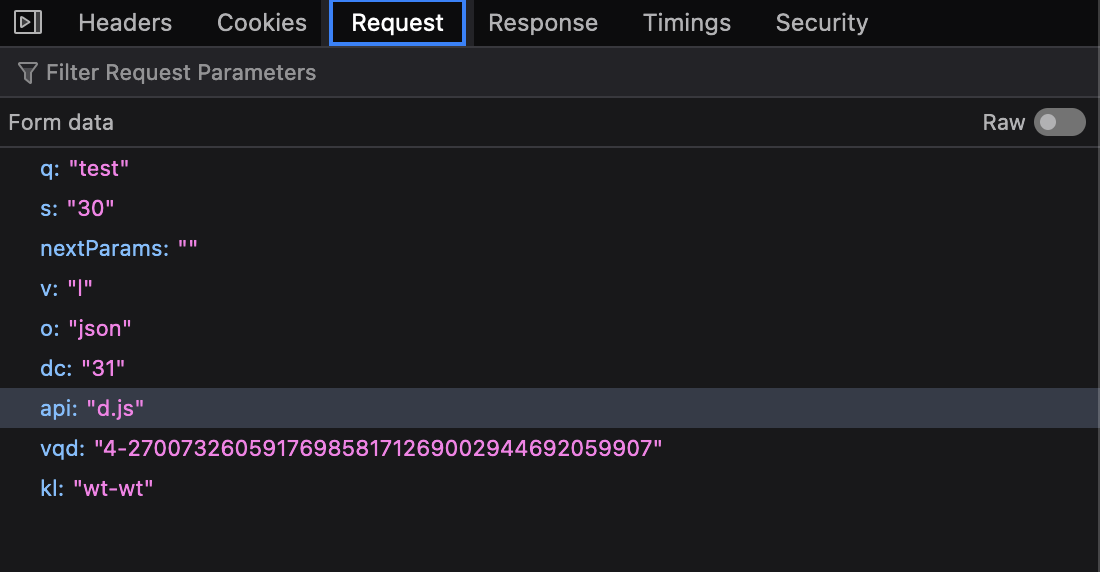 这之后就会变成带以下参数的POST请求。乍一看,这种形式似乎很容易添加,参数"s"和"dc"显然操纵了结果数量和分页功能。
这之后就会变成带以下参数的POST请求。乍一看,这种形式似乎很容易添加,参数"s"和"dc"显然操纵了结果数量和分页功能。
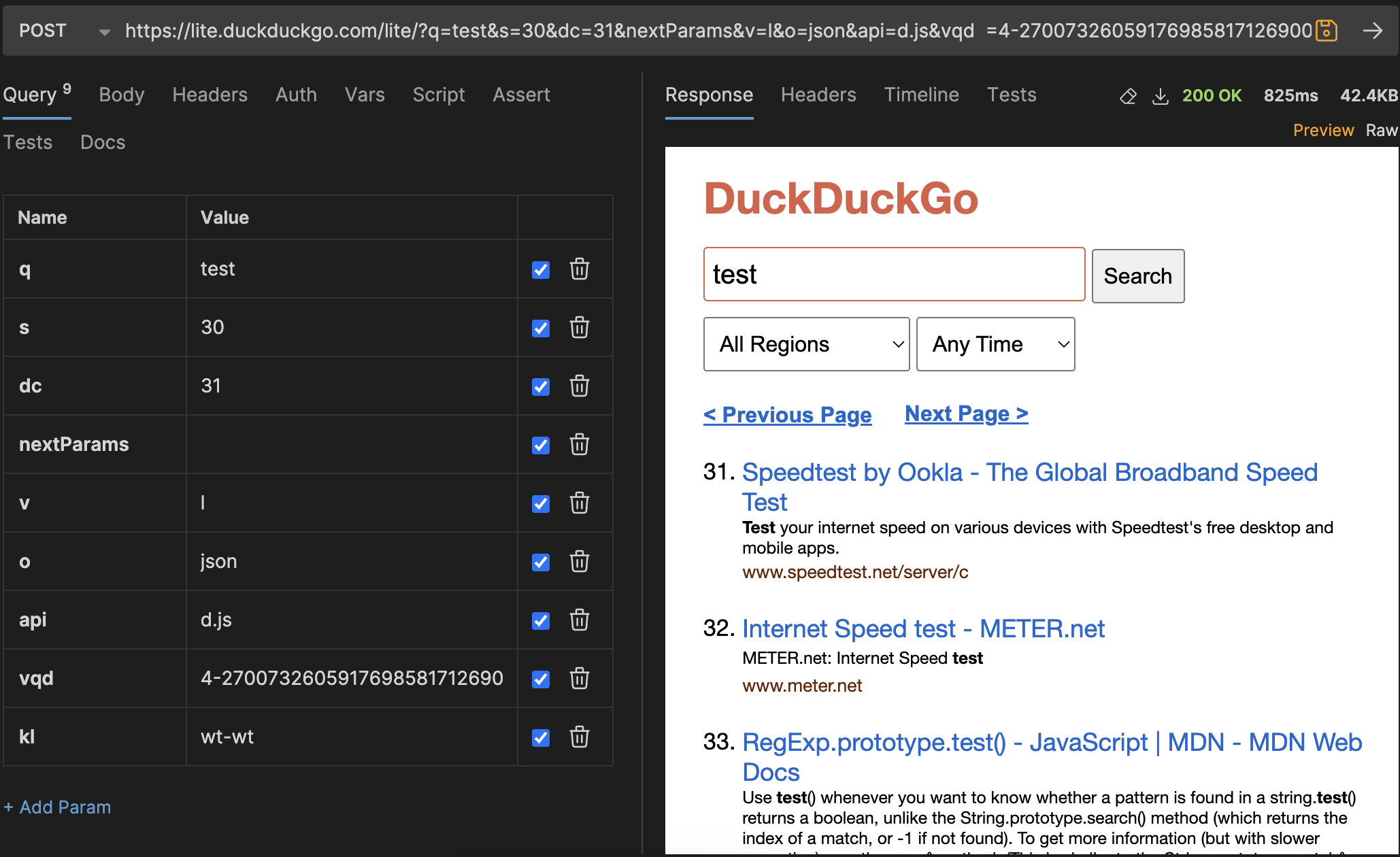 尽管模仿了这些参数,HTML页面却似乎没有返回下一页的结果。调整参数"s"和"dc"会改变HTML页面中的数字,但并没有实际的链接变化。我还需要进一步调查是否与此有关于某种会话机制。第一次测试中我只会利用前30条结果。
尽管模仿了这些参数,HTML页面却似乎没有返回下一页的结果。调整参数"s"和"dc"会改变HTML页面中的数字,但并没有实际的链接变化。我还需要进一步调查是否与此有关于某种会话机制。第一次测试中我只会利用前30条结果。
代码开始比较简单。这个站点已经运行在一个axum服务器上,所以我们只需构造一个JSON API。为此,我使用了reqwest 进行非阻塞API调用,scraper 高效地解析DOM,以及urlencoding 用于提取a标签中的href。
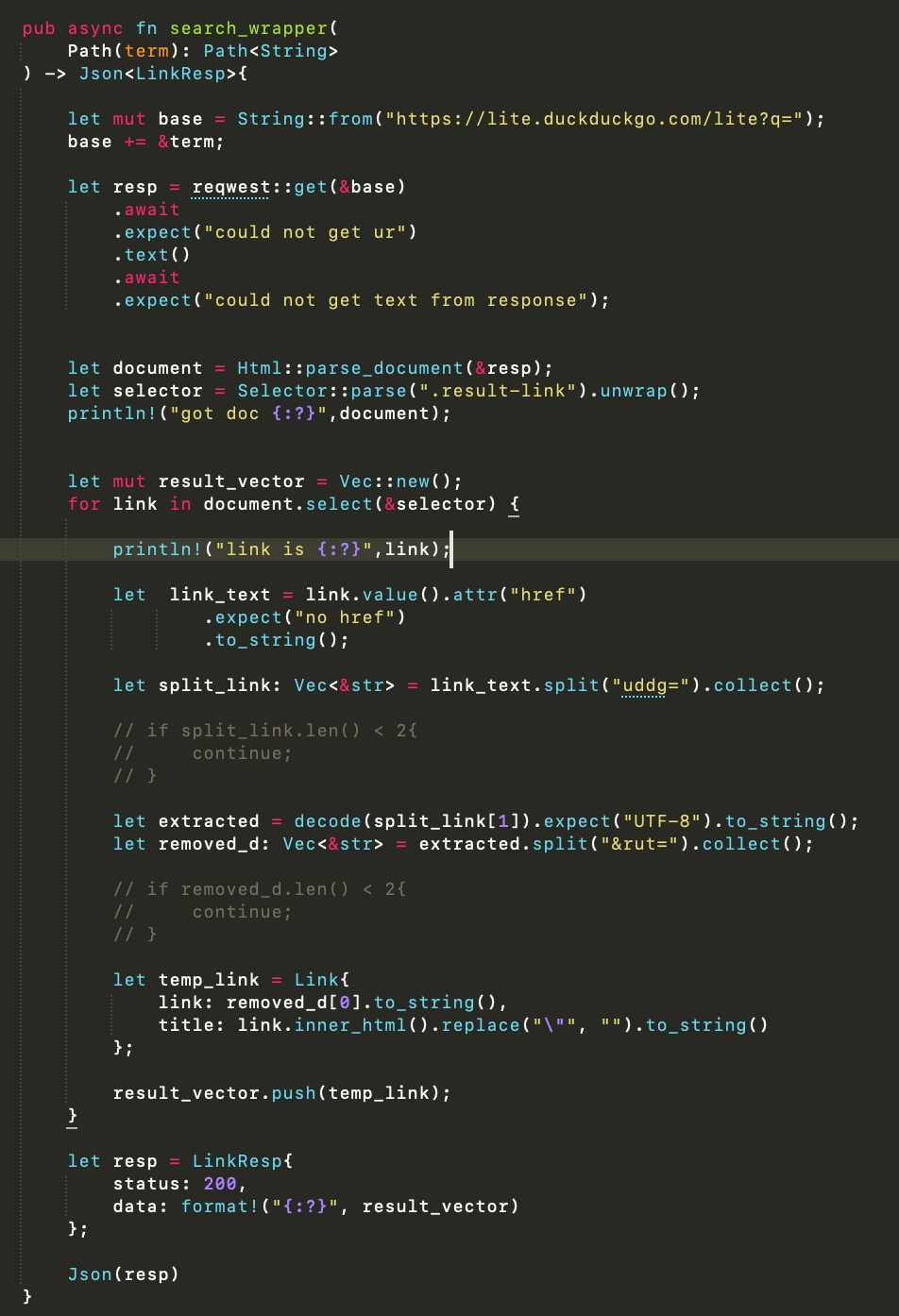 上面的代码涵盖了整个函数。我们发送请求,解析结果,然后对URL进行字符串操作。最后一部分很重要,这是因为DuckDuckGo HTML中URL的格式问题。
上面的代码涵盖了整个函数。我们发送请求,解析结果,然后对URL进行字符串操作。最后一部分很重要,这是因为DuckDuckGo HTML中URL的格式问题。
虽然无法在“元素检查”中看到,但查询DuckDuckGo端点的响应包含带有不同链接的a标签。
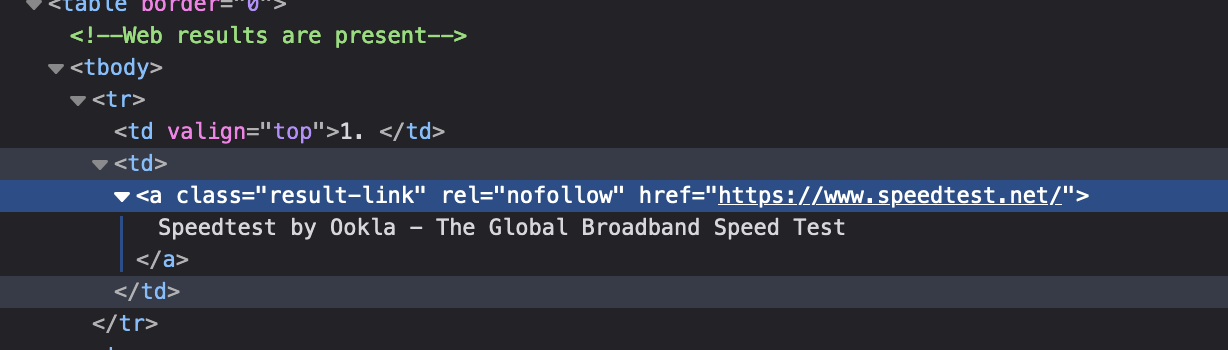 而我的解析器所看到的是这样的响应:
而我的解析器所看到的是这样的响应:
"a class="result-link" rel="nofollow" href="//duckduckgo.com/l/?uddg=https%3A%2F%2Fwww.speedtest.net%2F&rut=e22e2d095d31b01205099e099b7965b4a292dc8d26f8a4e98054643a5b304744"
要获取实际链接,我们首先使用urlencoding crate 解码URL,然后用几个split得到原始链接。在这种情况下:
https://www.speedtest.net/
将这一切整合在一起加上一些JavaScript和HTML,我得到了下面图示中可用的结果。
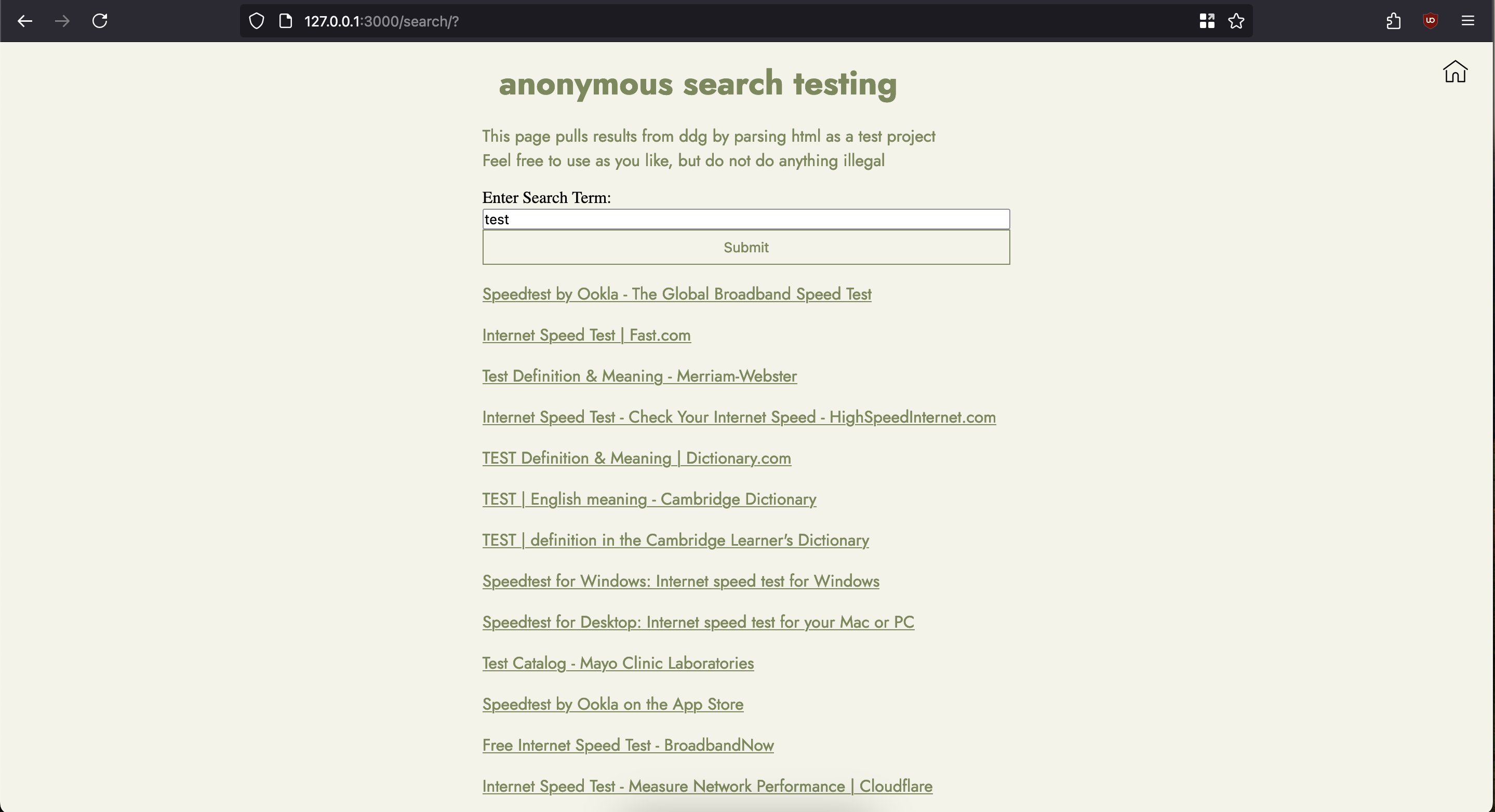 遗憾的是,只有某些术语有效。当我搜索“猫猫”时,我发现解析器立即崩溃了。
遗憾的是,只有某些术语有效。当我搜索“猫猫”时,我发现解析器立即崩溃了。
got doc Html { errors: ["Found special tag while closing generic tag", "Found special tag while closing generic tag"
最终我认为这是所使用的crate存在的问题。私下测试了多个其他库也都遇到了类似的错误。暂时我只能把问题放着,直到找到解决办法或替换库为止。
可能的解决方案是查看Servo的代码库。Servo是一个基于Rust的浏览器引擎,主要被Mozilla放弃,只在一个与微软HoloLens浏览器的合作项目(Edge取消了增强现实支持后)中短暂使用过。
像Servo这样的浏览器引擎很可能会有一个快速的解析器,但是它们可能有更好的替代方案。目前搜索引擎对任何人都可以访问,但不要期望有好的结果,因为它可能在大多数搜索请求上失败。
另一可能的问题与速率限制有关,在同一个时间段内出现多个用户很可能会迅速被封禁。鉴于这种原因,我并未直接在我的博客中提供搜索链接(即便找到它非常容易)。
随着我继续学习更好的抓取方法和搜索引擎技术,这个项目将会继续扩展。