简介
- 大型语言模型(LLM)推理框架已经遇到了“内存墙”,这是一种硬件强加的对内存受限代码的速度限制。这意味着LLM应用程序开发者不需要担心评估不同框架的各种细微差别,他们只需要了解自己系统的内存墙位置,选择一个接近它的框架即可继续。
- 请求/秒和标记/秒的指标可能存在误导性。根据MLPerf基准测试,在服务器和离线场景下的请求/秒数值通常比单流高得多。LLM开发者在选择推理框架时应理解如何计算请求/秒。
- 目前有很多关于量化和稀疏化等推理优化技术的讨论。虽然这些确实是深度学习中最重要的优化手段之一,但它们应该谨慎使用。过度剪枝或量化LLM可能会显著降低准确性,不如一开始就使用较小的模型。
- 我们通常建议使用经过验证的已发布模型以及它们的原始格式。例如,Meta发布的Llama 3.1 8B是采用bfloat16格式且不包含稀疏性的。而Mixtral-8x22B-v0.1则是在bfloat16格式下具有8路稀疏门控混合专家结构。专业团队可能能够更激进地进行量化或剪枝,但我们并不建议大多数用户这样做,因为其难度非常高。
- 我们构建我们的推理引擎时充分考虑到了这些因素。
- 我们的系统运行在AMD MI250和MI300 GPU以及Nvidia H100 GPU上,因此单流的内存墙分别是每秒200个标记、每秒331个标记及每秒209个标记。
- 我们为MLPerf服务器场景进行了优化,因为它提供了最佳的吞吐量并且灵活性最强。我们也可以处理单流和离线情况。
- 我们以有偏见的方式进行量化,在硬件支持加速的情况下选择模型发布的格式,例如MI250上的bfloat16 和MI300X上的float8。
- Lamini支持LLM的内存调优,可以将任何LLM转换为混合大规模专家模型(MoME)。我们的推理引擎无缝加载专家,并以高性能运行这些专家。
为了运行大型语言模型,你需要一个推理框架。有许多流行和新兴的推理框架,比如vLLM、TensorRT-LLM、llama.cpp和llm.c。模型在推理阶段是固定的,因此推理框架通常是基于性能——速度、延迟和吞吐量——或优化方法——量化、稀疏化、快速注意机制、KV缓存分页和推测解码进行竞争的。需要注意的是,准确性是由模型决定而不是由推理框架决定的,这也是为什么这些框架主要依据性能而不是准确性来竞争。在这篇文章中,我们将讨论为什么一些性能比较可能并不如你所期待的那样有用。
大型语言模型(LLM)的推理框架已经遇到了“内存墙”,即硬件施加的对于内存受限代码的速度限制。事实证明,支持LLM的Transformer模型在解码阶段是内存受限的。当一个程序受限于内存时,系统的内存速度决定了其性能。因此,不同的推理框架在同一硬件平台上且具有相同内存的情况下会得到近似相同的性能。
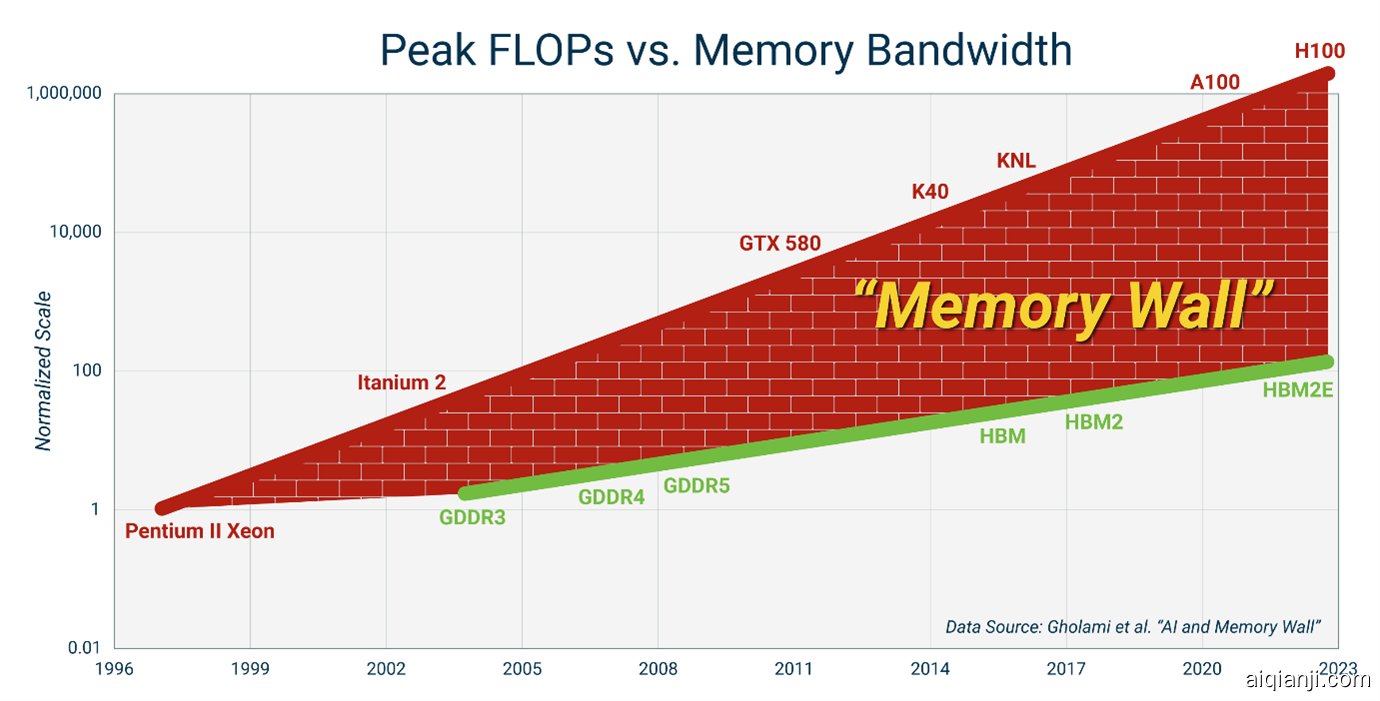
图1:来源
由于所有框架都受同一硬件速度的限制,因此LLM应用开发者面临的选择其实很简单:了解自己的系统的内存墙所在位置,选择一个接近它的框架,然后继续前进。当然,并没有下限表明某软件件到底能有多低效,你需要确保你的推理框架已经被良好地调优,但内存墙设定了一条上限。一旦接近此上限,就完成了任务。
这留给了进一步研究突破LLM推理中的“内存墙”的空间。然而,研究突破可能需要放弃有史以来最成功且最常用的模型之一——Transformer。
什么是内存墙?
内存墙是指处理器速度与内存带宽之间巨大且不断增大的差距。内存墙之所以产生是因为将数据从大容量内存(如HBM3)移动到GPU上的矩阵核心(如MI300x)所需的能量大于通过矩阵核心电路移动数据所需的能量。
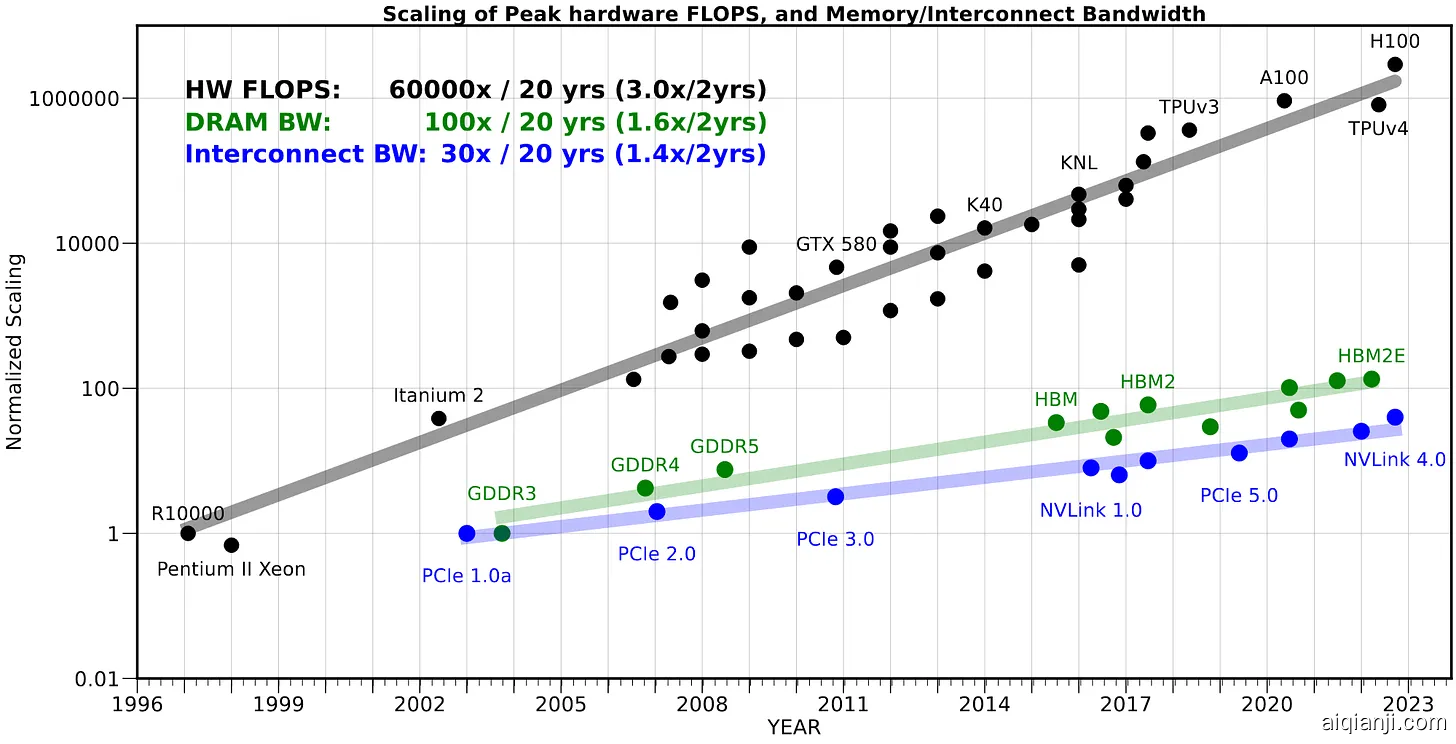
图2:图片来源图1展示了内存墙的实际表现。追踪GPU速度的灰色线条增长得比追踪内存带宽的绿色线条更快。注意,图表的尺度是对数的,所以差距比看起来更大且增长速度也更快。
为何Transformer的解码过程受到内存限制?
Transformers在过去十年中已经是最成功的深度学习模型,甚至在视觉领域挑战了卷积神经网络(CNNs)。它们在LLM领域占据主导地位,如Llama 3.1、Claude 3.5、GPT4、Deepseek 和Mistral等。
Transformer的关键创新在于它们训练过程中避免了内存墙,但在推断过程中仍然难以避免。在推断过程中,Transformer使用一种叫做自回归解码(Autoregressive Decoding)的算法,这意味着Transformer必须完全预测出前一个标记才能开始处理下一个标记。例如对于Llama 3.1 400B模型,意味着在其输出每个标记之前,400亿个权重都需要从内存中读取出来。这个操作使得LLM推断在现代系统(如带有HBM的GPU)上受到内存限制。
那么,Transformers是如何在训练过程中避免内存墙的呢?在Transformers出现之前,语言模型中最流行的模型是循环神经网络(RNNs)。RNN用穿越时间的反向传播(BPTT)算法进行训练。这种算法会为训练数据中的每一个标记加载神经网络中的每一个权重。它需要这样做来确定序列中的下一个标记如何受前一个标记的影响。这就直接撞上了内存墙,因为RNN的权重需要反复从内存中重新加载。
Transformers通过使用另一种称为“教师强制教学”(Teacher Forcing)的训练算法打破了训练过程中的内存墙,取代了BPTT。在教师强制教学中,一次性加载大量标记并用于更新LLM的权重。这种方法避免了内存墙,因为处理器可以一次加载一个权重并执行数千次浮点运算。先前的研究者曾试图对RNN实施教师强制教学,但由于准确度显著下降而失败,这是因RNN无法在没有反向传播的情况下确定下一个标记如何受前一个标记影响。
Transformers的关键在于它们依赖注意力机制(这是计算受限而非内存受限的)来确定下一个标记如何受到前一标记的影响。因此,对于变换器而言教师强制教学能够成功,而在RNN中却不能奏效。
不同类型的内存
如果LLM的推理受到内存瓶颈,那么应该可以通过使用更高带宽的内存来加速推理吗?不幸的是,情况并非如此,因为改变内存技术需要硬件的变更。因此,LLM不受推理框架选择或软件级别优化的影响。
Cerebras和Groq公司的推断系统声称在单个请求中的令牌/秒上有巨大的加速。这些加速是真实的,因为这些推断引擎正在使用SRAM(静态随机访问存储器)这种不同的内存技术。
本地SRAM的能量消耗比DRAM低100倍(因此带宽更高),但容量也低得多。典型的CDNA 3核在MI300X上拥有512KB的本地SRAM。在MI300X GPU上的38核(CU)和8块芯片中,总共拥有152MB的本地SRAM。要将单个Llama 3.1 70B模型放入本地SRAM中,需要921个GPU。因此,最新的GPU拥有的SRAM比HBM少1263倍。
GroqChip每处理器集成了更多的本地SRAM,达到了高达230MB。这意味着一个小于600个GroqChip集群即可服务一个Llama 3.1 70B的bfloat16参数模型。Cerebras的晶圆级引擎3.0更进一步,在单个处理器上集成了44GB的SRAM。Cerebras可以通过一个包含四个晶圆级引擎的集群来服务Llama 3.1 70B。

图3: HC2023-K2: Hardware for Deep Learning
当今大多数推理系统使用GPU,这些GPU通常将大语言模型(LLM)参数存储在一种称为高带宽内存(HBM)的内存中,这是由JEDEC内存标准组织定义的标准。像MI300X或H100这样的GPU包含192GB或80GB的第三代高带宽内存(HBMv3),足以在一个GPU中以bfloat16格式存储包含96亿或40亿参数的大语言模型。顾名思义,HBM通过三维堆叠技术和硅通孔实现了比大多数其他类型的DRAM更高的带宽。提高带宽的一种方法是使用更先进的HBM内存,例如从HBM3升级到未来的HBM4。另一种方法是构建具有更多HBM模块的系统,即更多的GPU。

图4: 图片来源
您可以通过改变硬件来极大地加速推理。增加更多的GPU会提高内存带宽。如果您有足够的GPU使其能够将LLM权重移动到本地SRAM中,那么您可以获得巨大的速度提升。但是,是否值得将这么多硬件资源(和金钱)投入到单一模型中以降低推理延迟,则是另一个问题。
MLPerf 场景
MLPerf推理基准测试是一个行业标准,该标准定义了如何衡量深度学习应用(包括大语言模型推理)的性能。
对于大语言模型推理,我们通常考虑的是能够处理LLM请求的大GPU服务器。由于大语言模型较大,因此GPU服务器也较大。MLPerf根据对工业界中最常见的LLM使用情况的调查,定义了四种场景。

图5: MLPerf推理场景大语言模型相关的典型场景包括单流、服务器和脱机模式。
单流
单流意味着有一个用户与大语言模型进行交互。例如,如果您在系统上启用了一个大语言模型推理服务,并且一个用户通过游戏界面与大语言模型对话。这就是单流的情况。首个标记的时间和每秒标记数量会影响这一场景下的用户体验。首个标记的时间影响用户按回车键后等待查看响应的时间。而每秒标记数量则决定了标记呈现到屏幕的速度。每秒标记数量还会影响大语言模型代理形成请求并调用功能或工具所需的时间。
单流运行时直接撞上了内存墙,因为大语言模型一次解码一个标记。因此推理框架别无选择,只能在每个标记中从内存加载整个大语言模型。
服务器
服务器场景是指有一个单一的推理系统接收来自多个用户的并发请求。这一情景给予推理系统更多自由。如果它可以将请求组合成批处理,那么它可以同时为批次中的每个请求处理一个标记。这增加了每次从模型加载权重所需的计算量。如果批次大小足够大,通常为数百或数千个请求,推理系统可以克服内存墙。这也是为什么在服务器场景下,GPU系统的每秒标记数会更高。
脱机模式
脱机模式非常类似于服务器场景。许多请求被同时处理。事实上,所有的请求都被立即呈现在推理系统面前,系统可以以任意方式处理这些请求。这使批量处理变得容易且计划清晰。脱机模式几乎总是受计算能力限制,因为可以最优地选择批量大小。
如果您查看获得胜利的MLPerf提交结果,推理系统在脱机模式下的表现最好,其次是服务器模式。这两种情况下都避免了内存墙,因此它们的每秒标记数会远高于单流模式。由于这种差异巨大,在推理框架报告每秒标记数时,您应该仔细考虑其是在报告服务器/脱机还是单流模式的结果。
从大语言模型应用程序开发者的角度来看,将应用程序归类为服务器或脱机场景而不是单流场景显然更有利。在Lamini框架中,我们提供了高层次的API,这些API自动将大语言模型调用映射到服务器场景,使得利用单流API进行推理的速度提高了52倍。
小心使用量化和稀疏性
但是关于推理优化不是有成百上千篇论文吗?
我不需要量化、稀疏性、闪存注意力、KV缓存分页、推测性解码等技术吗?
量化和稀疏性
量化和稀疏化是深度学习领域(包括大语言模型)中最有效的两种优化技术。它们确实有助于缓解内存墙的问题,因为它们缩小了神经网络的规模,因此减少了推理过程中从内存移动权重数据的需求。我们预期优化后的推理框架会使用它们,但这些技术应极其谨慎地采用,因为盲目的量化或剪枝可能会降低大语言模型的准确性。
在量化或剪枝基准测试中经常被忽视的一个基准仅仅是减少模型规模。例如,从Llama 3.1 400B减少到Llama 3.1 70B可以使需要从内存加载的数据量减少5.7倍。从bfloat16减少到FP8或INT8可以将其减少两倍。Llama 3.1 400B实现了88.6的MMLU评分,而Llama 3.1 70B实现了86.0的评分。一个将Llama 3.1 400B从bfloat16转换为FP8的量化过程需要极其小心,以免其MMLU以及所有其他指标下降超过1到2个百分点。否则,不如直接使用Llama 3.1 70B,既更好又更简单。
对发布最佳模型如Llama 3.1的过程需要做大量的验证工作。我们通常建议使用已发表并经过充分验证的模型及其发布格式。除了标准的度量指标外,它们通常还会经过红队评估。例如,Meta发布了bfloat16格式的Llama 3.1 8B而不含稀疏性;Mixtral发布了bfloat16格式带8路稀疏门控混合专家稀疏性的Mixtral-8x22B-v0.1。专业团队可能能够更加激进地进行量化或剪枝,但我们不建议大多数用户这样做,因为验证难度很高。如果您不熟悉如何重复Meta的MMLU指标评估Llama 3.1,那么您可能不应该验证量化或剪枝的模型。
注意力优化技术
除内存墙外,变压器架构也可能遇到其他瓶颈。其中一个最大的问题是处理非常长的序列。根本问题是默认的注意力算法要求序列长度的O(N^2)计算量和内存消耗。对于短序列,这并不显著。但对于较长的序列,O(N^2)计算量就会占据主导地位。

图6: 闪存注意

图7: KV缓存一个好的推理框架将包含这些优化技术,这将影响可处理的最大序列长度。然而,这些优化技术并不能解决内存墙的问题。即使将注意力过程的计算成本降到零,系统仍需要在自回归解码过程中加载每一个权重中的每一个标记。
内存墙在哪里?
如何判断你的推理框架是否已经足够优化,接近了内存墙?伯克利Roofline模型是一种简单且具有启发性的视觉性能模型,我们可以用它来找到内存墙。通过Roofline模型的快速计算,可以发现使用单个MI250 GPU运行Llama 3.1 8B的单流场景中的内存墙为每秒200个令牌。如果我们对推理框架进行计时,并且性能接近这个值,那么我们已经达到了硬件极限,进一步的软件优化将不会有效。
在LLM的解码阶段中,算术强度大约等于批次大小。转折点是MI250的批次大小为113,MI300X为492,H100为567。
考虑以单流场景运行Llama 3.1 8B,这将具有一个批次大小为1的情况。每个令牌需要从内存加载80亿个权重。在bfloat16中,每个权重占用2字节。MI250的内存带宽为3.2 TB/s。因此我们可以以每秒200个令牌的频率运行解码器 = 3.2e12(字节/秒)/(8e9 权重)*(2 字节/权重)。

图8:Roofline模型示例。该图表绘制了给定处理器的性能(TFLOP/s)与算术强度的关系。
是否有可能打破内存墙?
Transformer和教师迫导训练的成功引发了这样的问题:是否有可能出现一种新的模型,在推理过程中打破内存墙。自Ashish Vaswani等人发表了引入transformer的开创性论文《Attention Is All You Need》以来,已经过去了7年。在这段时间里,我们一直在承受由自回归解码所隐含的内存墙的影响。
到目前为止,研究人员尚未取得成功。
这里我们回顾了几种可能的研究方向,这些方向旨在打破内存墙。在这些或其他研究领域取得了突破,可能会带来数百甚至数千倍的推理速度提升。
量化和稀疏性优化
我们预期未来在量化和稀疏性方面的进展会逐步削弱内存墙,但它们不太可能提供H100所需的567倍网络规模减少才能打破内存墙。我们期待稀疏性取得突破已超过十年,然而最先进的模型如Llama 3.1仍然没有任何稀疏性。目前最先进的模型通常以bfloat16发布。现在有了新的格式如FP8和FP4,并且已经有了向下扩展至一位及以下的路线图,但预计需要几代硬件才能解决在这些格式下可靠地训练模型的问题。
专家混合模型提供了一些成功案例。Lamini发布了具有多达百万个专家的MoME模型,这将用于内存操作的活动参数数量减少了上百万倍,足以克服内存墙。Mixtral有一系列8路MoE模型,可以将活动参数数量减少至多8倍。
并行和预测解码
另一个研究方向是使LLM的解码更加并行化,有效地去除transformer中的自回归解码。
预测解码采用顺序自回归解码器,并在任何情况下都并行运行。它使用较小的神经网络来预测多数令牌,并且只有在做出错误时才会调用更大的LLM来检查其工作并纠正错误。预测解码可以缓解内存墙问题,但一般而言,模型只能向前推测几个令牌而不出错,限制了其效益。小的神经网络仍然受到内存墙的限制,只是其权重少于大的网络。在使用预测解码时还需注意不要因小型网络所做的预测而将错误引入解码过程。
并行解码改变了transformer架构,使其能够一次输出多个令牌。这允许重用不同令牌的权重。如果我们找到一种能够一次性输出数千个令牌的方法,则可以打破内存墙。更改解码头可以允许如论文"Better & Faster Large Language Models via Multi-token Prediction"中所述的一次生成4到8个令牌。扩散迫导结合了前沿算法和扩散过程以同时输出整个输出序列,如这里描述,可能一次性生成无限数量的令牌。尽管其中一些方法很有前景,但它们是新的模型,因此可能需要训练新的基础模型才能与领先的transformer如Llama 3.1竞争。试图训练这些模型却发现在并行性增加的同时准确性下降,将会是一个昂贵的错误。
总之,需要更多的研究才能打破内存墙。在下一次突破到来之前,要警惕那些声称其推理框架可提供顶级性能的主张,因为它们可能会在速度与准确性之间进行权衡,或者与未优化的基线进行比较。