AT Protocol 是由 Bluesky 开发的一项开放社交网络技术。在本文中,我们将从分布式后端工程的角度探索 AT 协议。
如果你曾经使用过 流处理 构建过后端,那么你会对我们即将探讨的系统非常熟悉。如果没有——也不用担心!我们将逐步带您了解。
扩展传统 Web 后端
经典的快乐 Web 架构是应用程序服务器背后的“一个大的 SQL 数据库”。应用程序与数据库通信并处理来自前端的请求。
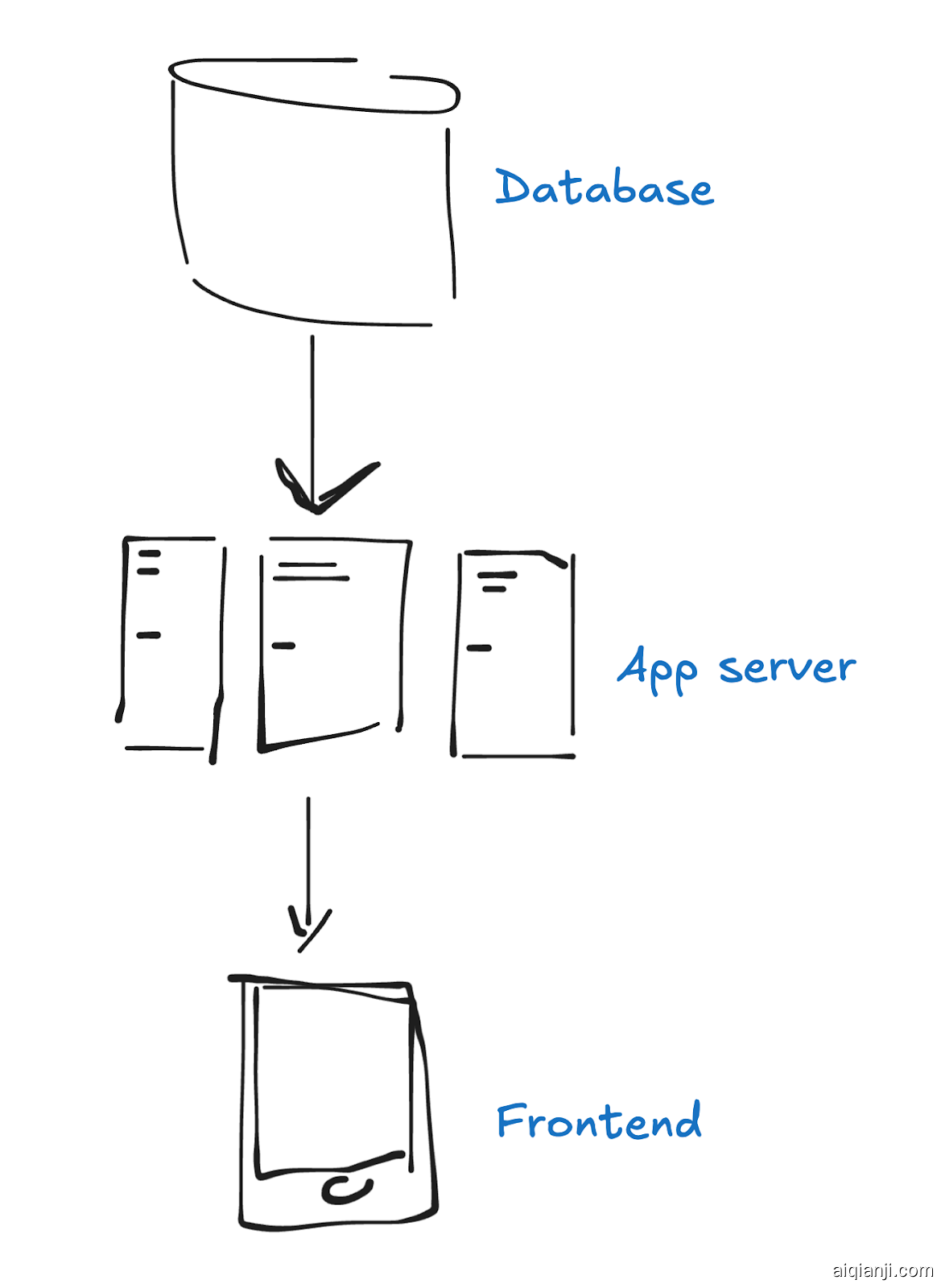
随着我们的应用扩展,我们会遇到一些性能瓶颈,所以我们会在整个系统中加入缓存。

然后我们会通过分片和复制来水平扩展我们的数据库。

这已经很好了,但是我们在构建一个拥有数亿用户的社交网络;即使这种模型也会达到极限。问题在于我们的 SQL 数据库是“强一致性的” 意味着状态在整个系统中保持统一同步。维持强一致性会产生性能成本,这是我们遇到的瓶颈。
如果我们能够放宽系统以使用 “最终一致性” ,我们可以更进一步地扩展。我们开始转向使用 NoSQL 集群。

这对扩展更有利,但没有 SQL,构建查询变得越来越难。实际上,SQL 数据库有很多有用的功能,像联接和聚合查询。事实上,我们的 NoSQL 数据库只是一个键值存储。编写功能变得痛苦起来!
为了解决这个问题,我们需要编写生成预计算视图数据集的程序。这些视图本质上就像缓存查询一样。我们甚至将规范数据复制到这些视图中,因此它们非常快。
我们将把这些称为我们的视图服务器。
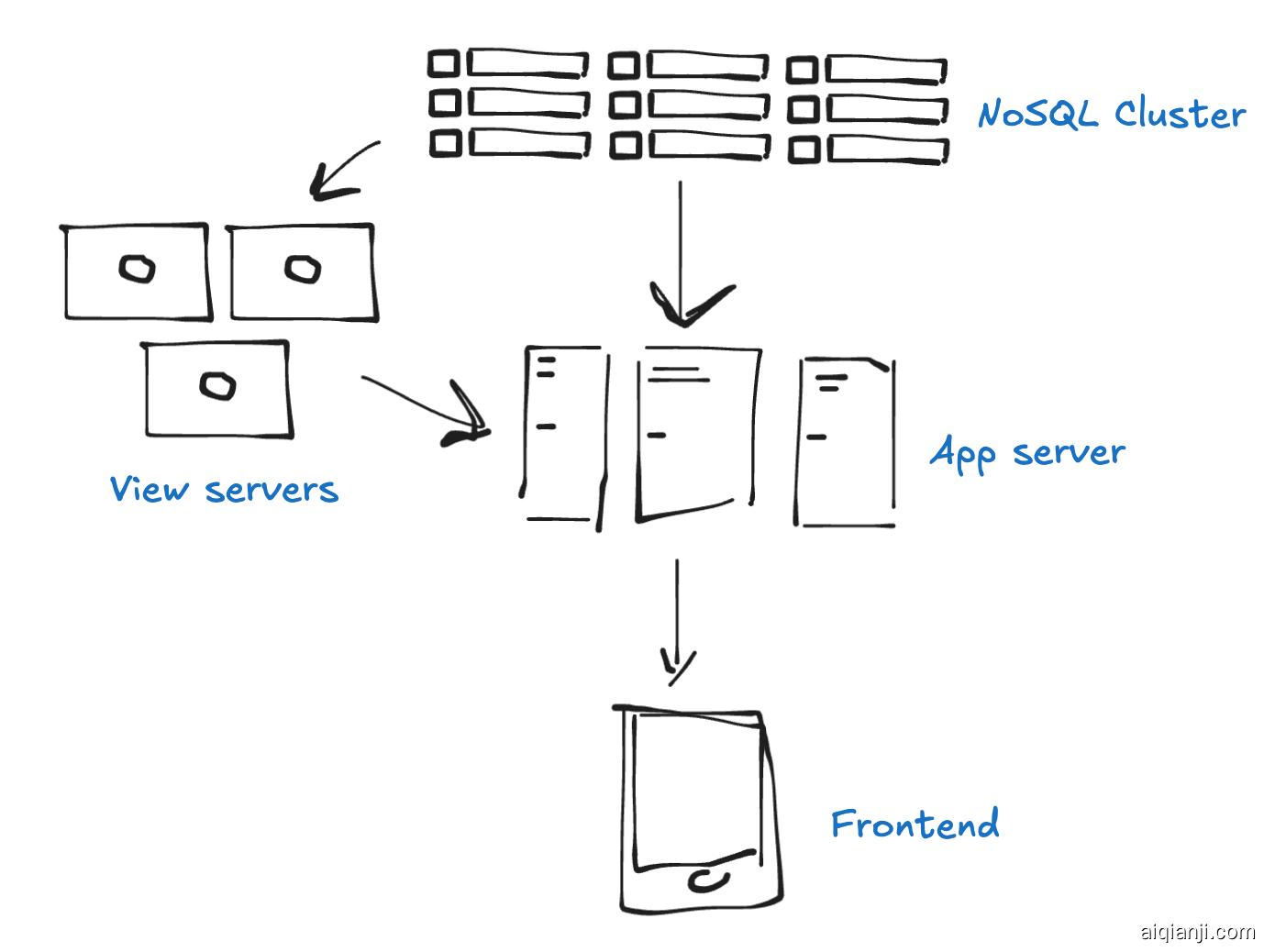
现在我们注意到要使我们的视图服务器与 NoSQL 集群中的规范数据保持同步很困难。有时视图服务器崩溃并且会丢失更新。我们必须确保我们的视图始终保持可靠更新。
为了解决这个问题,我们引入了一个事件日志(如 Kafka)。这个日志记录并将所有对 NoSQL 集群的变化广播出去。我们的视图服务器监听这个日志——并重播——确保它们不会错过任何更新,即使它们需要重新启动。
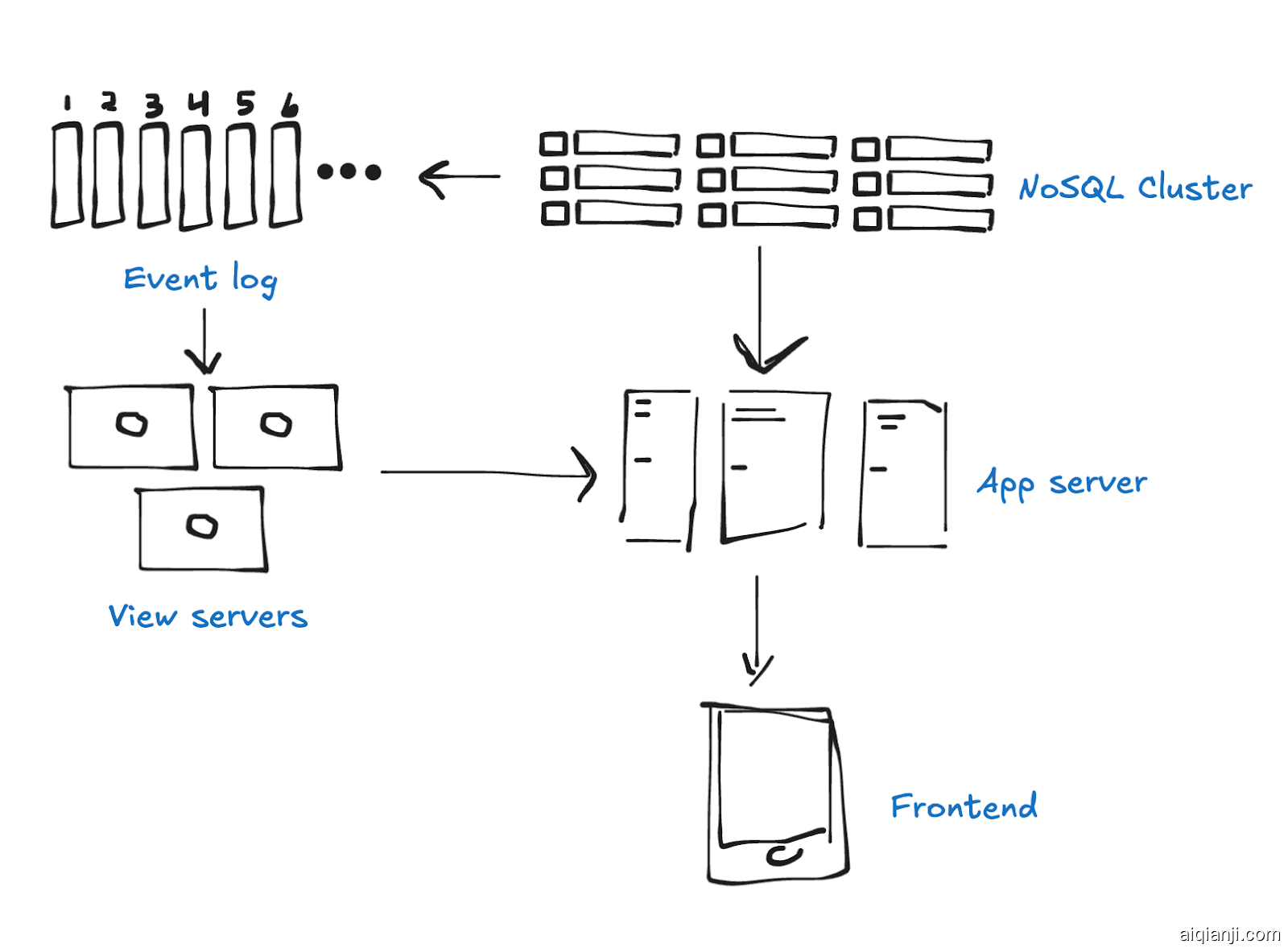
我们现在已经到达了一个 流处理架构。虽然还有很多细节可以覆盖,但这足以说明问题。
好消息是这种架构扩展得相当不错。我们放弃了强一致性,有时我们的读取查询落后于数据的最新版本,但服务并不会丢失写入或进入不正确状态。
从某种意义上说,我们通过 翻转内部结构 自行定制了一个数据库。我们将规范存储简化为 NoSQL 集群,然后通过视图服务器构建了自己的查询引擎。尽管这在构建时不方便,但它确实实现了扩展。
分布我们的大规模后端
AT 协议的目标是互相连接应用程序,使它们的后端分享状态,包括用户帐户和内容。
我们如何做到这一点?如果我们查看图表,可以发现该系统的大部分都是与外部世界隔离的,只有应用程序服务器提供了公共接口。

我们的目标是打破这种隔阂,让其他人也加入我们的 NoSQL 集群、事件日志、视图服务器等。
它是这样的:
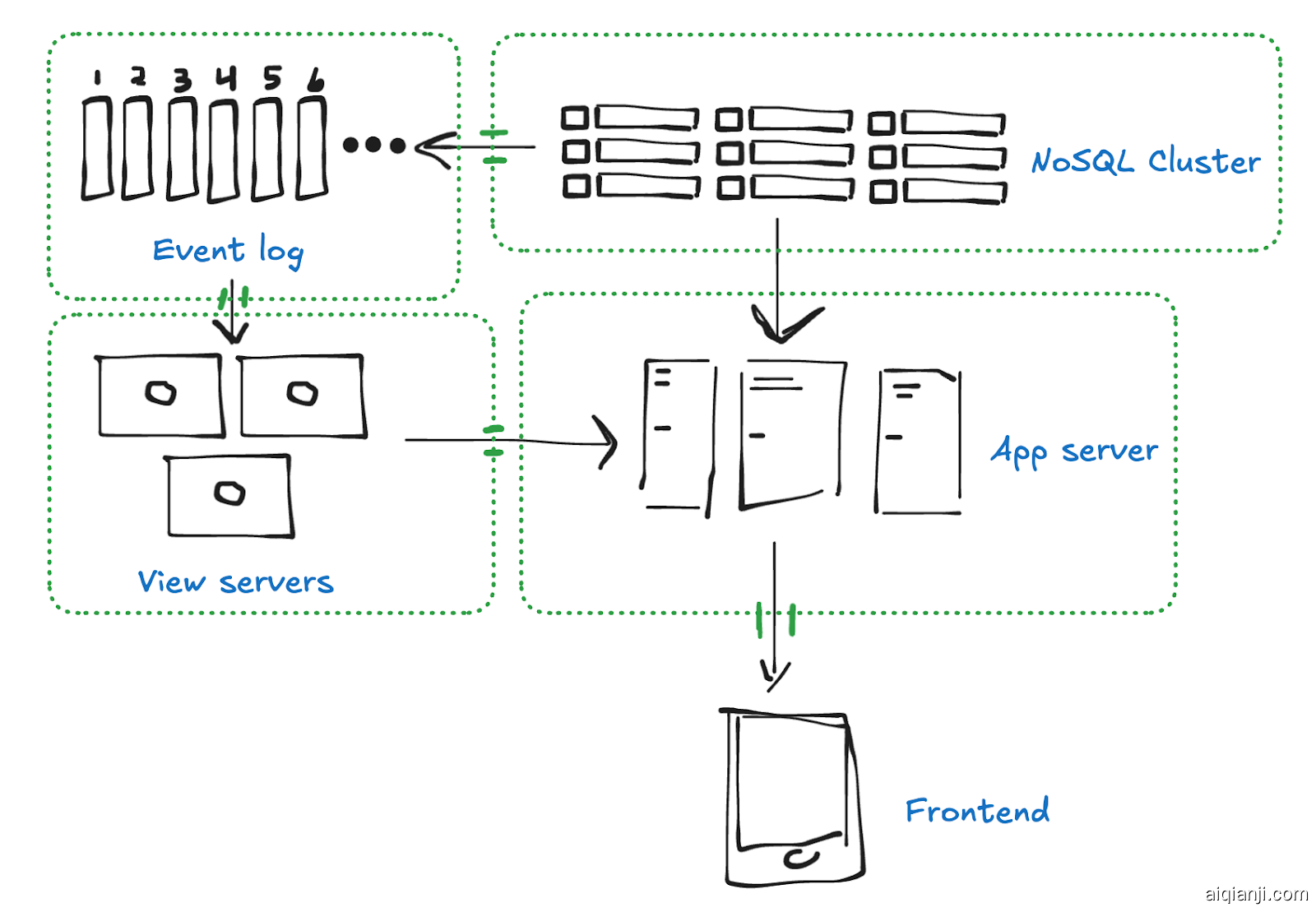
每个这些内部服务现在都变成了外部服务。任何人都可以消费它们的公共 API。而且,在此基础上,任何人都可以创建自己的服务实例。
我们的目标是让任何人能够贡献到这个去中心化的后端。这意味着我们不仅想要一个 NoSQL 集群或一个视图服务器。我们希望众多这样的服务器一起工作。因此,实际上更像是这样的:
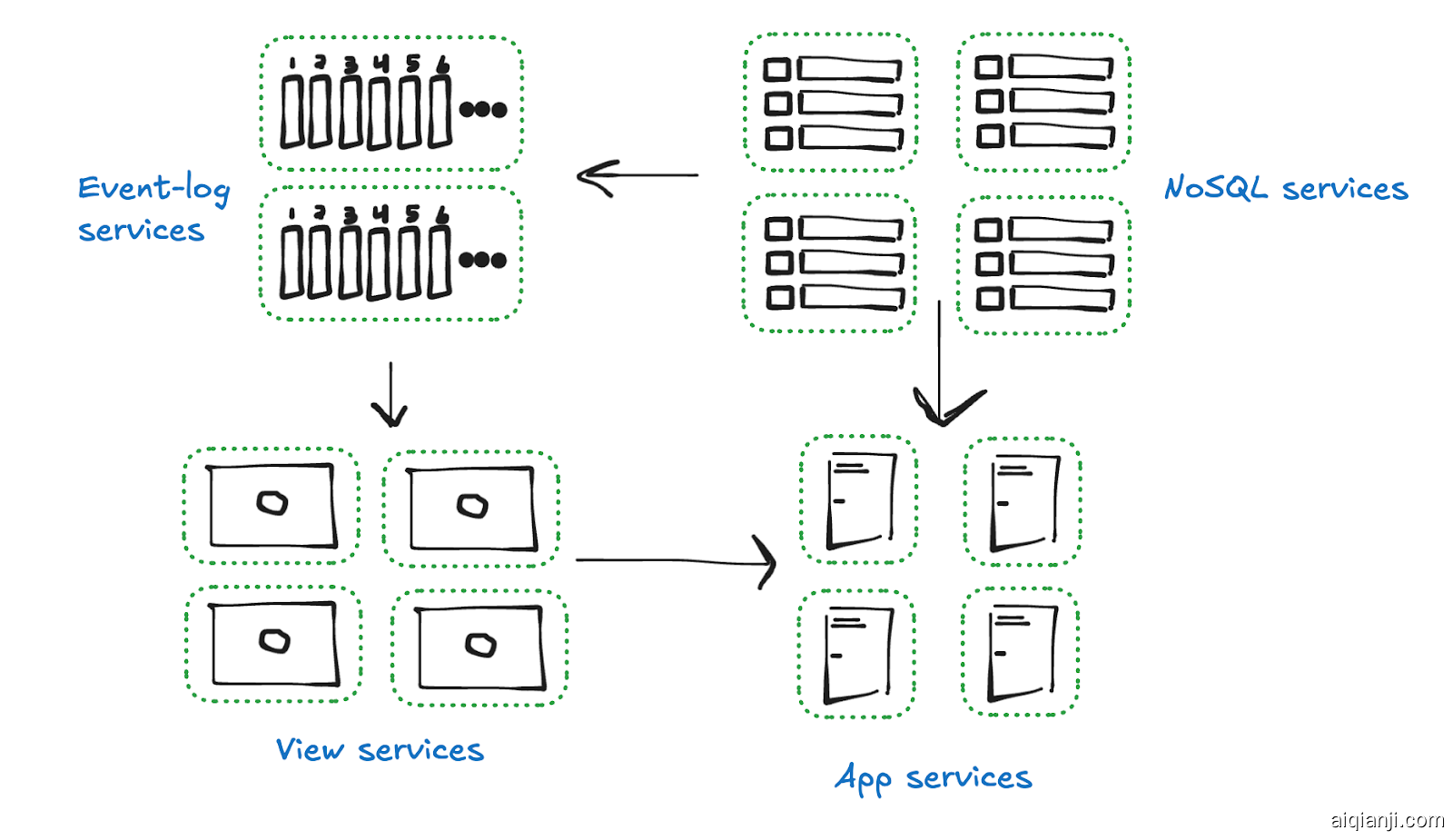
那么我们如何使这些服务协同工作?
统一数据模型
我们将建立一个共享的数据模型叫做 “[用户数据仓库]”(https://atproto.com/guides/data-repos)。

每个数据仓库包含 JSON 文档,我们将它们称之为“记录”。

为了管理目的,我们将这些记录分组到“集合”中。

现在我们将对 NoSQL 服务进行规范,使它们都使用这种 数据仓库 模型。
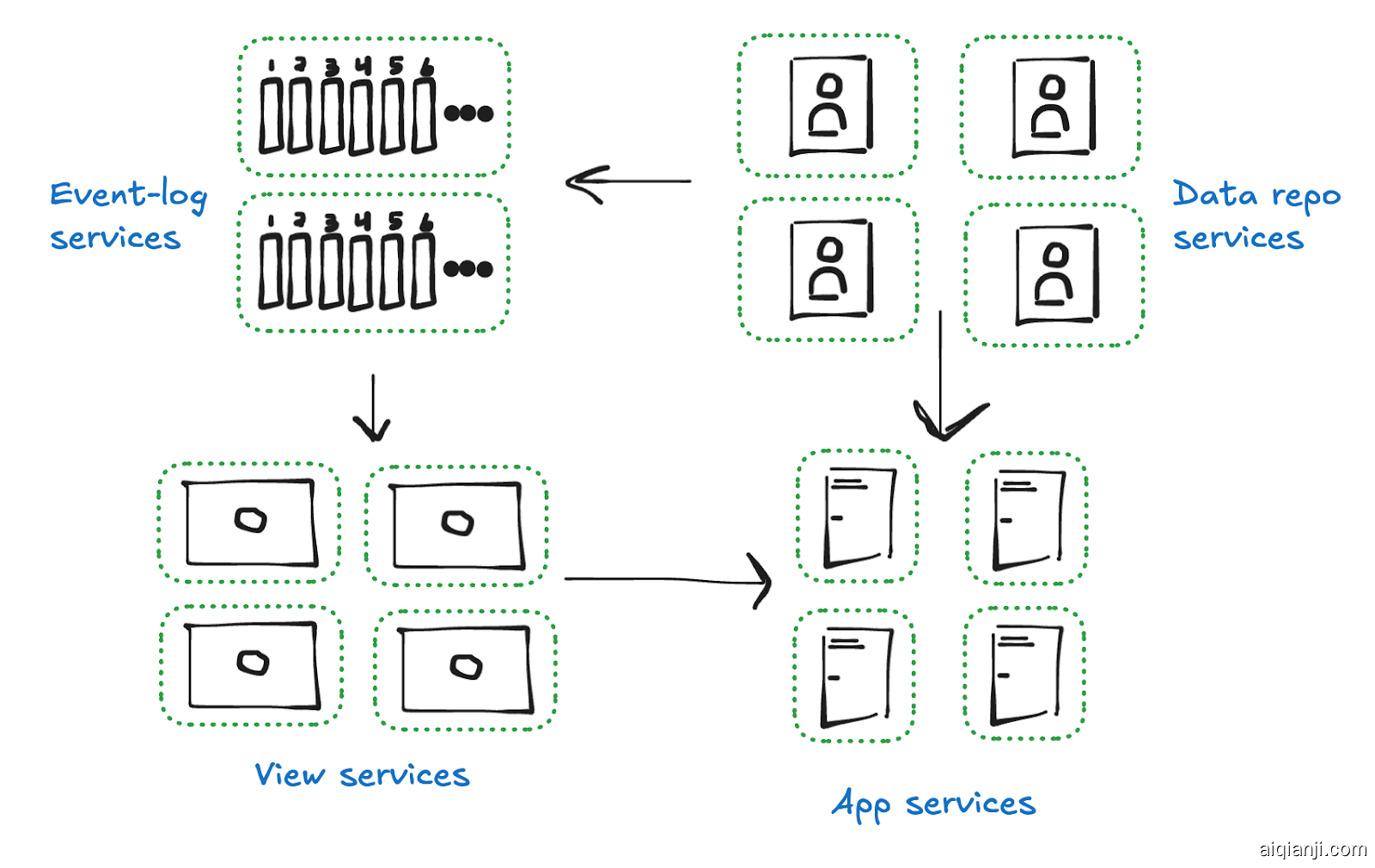
记住:数据仓库服务仍然是基本的 NoSQL 存储,只是它们现在以一种非常特殊的方式组织:
- 每个用户都有一个数据仓库。
- 每个仓库中有集合。
- 每个集合是一个有序的 JSON 文档键值存储。
由于数据仓库可以由任何人托管,因此我们需要给它们分配 URL。

顺带提一下,我们也将为我们的记录创建一个 完整 URL 方案。
太好了!同样,由于我们要在因特网上同步这些记录,最好对它们进行加密签名,以确保它们是真实的。
翻译 private_upload/icodebase/2024-10-07-20-19-57/1.md.part-1.md

数据流图解
现在我们已经构建了大规模的分布式后端,让我们看看应用程序在 ATProto 上的实际工作流程。
既然我们要开发一个新的应用,我们需要两件事:一个应用服务器(托管我们的 API 和前端)和一个视图服务器(从网络中收集数据)。我们通常将应用服务器和视图服务器捆绑在一起,因此我们可以称其为“Appview”。就从这里开始:

用户使用 OAuth 登录我们的应用。在此过程中,他们告诉我们哪个服务器托管他们的数据仓库,并给予我们对其进行读写操作的权限。

我们有了一个良好的开端——可以在用户的仓库中读写 JSON 文档。如果他们已经有来自其他应用的数据(例如个人资料),我们也同样可以读取这些数据。如果我们构建的是一款单机应用,则到这里就已经完成了。
但是我们来图解一下当我们写入一个 JSON 文档时会发生什么。

这将文档提交到仓库,然后触发进入监听该仓库的日志事件记录。

之后,事件会被发送至所有监听的视图服务——包括我们自己的!

为什么我们要监听事件流,即使是我们自己触发写操作?因为我们并不是唯一的一个执行写入操作的人!有很多用户仓库生成事件,也有很多应用写入其中!

因此,在我们的分布式后端中可以观察到一种循环式的数据流动模式,写入提交到数据仓库,通过日志事件传播到视图服务器,我们的应用可以从这些视图服务器读取。

并且(希望如此)这个网络能够继续扩展:不仅是为了增加容量,而且是为了创建更多类型的应用程序,共享在这个开放应用网络中。

建立实用的开放式系统
AT 协议结合了 P2P 技术与大规模系统的实践。我们的创始工程师是核心 IPFS[链接] 和 Dat[链接] 工程师,并且《数据密集型应用》一书的作者 Martin Kleppmann 也是我们的活跃技术顾问。
在启动 Bluesky 之前,我们明确要求“不走回头路”。我们希望这个网络的感觉像以前所有的社交应用那样便捷、全球化,同时仍然作为一个开放网络运作。这就是为什么我们在查看联邦制及区块链时,它们的架构规模限制便非常明显。我们的解决方案是采用大规模后端的标准实践,然后将我们在点对点系统中使用的技术应用于创建一个开放的网络。