XUI-TARS: Pioneering Automated GUI Interaction with Native Agents
XUI-TARS: 开创性自动 GUI 交互与原生智能体
Abstract
摘要
This paper introduces UI-TARS, a native GUI agent model that solely perceives the screenshots as input and performs human-like interactions (e.g., keyboard and mouse operations). Unlike prevailing agent frameworks that depend on heavily wrapped commercial models (e.g., GPT-4o) with expert-crafted prompts and workflows, UI-TARS is an end-to-end model that outperforms these sophisticated frameworks. Experiments demonstrate its superior performance: UI-TARS achieves SOTA performance in $^{10+}$ GUI agent benchmarks evaluating perception, grounding, and GUI task execution (see below). Notably, in the OsWorld benchmark, UI-TARS achieves scores of 24.6 with 50 steps and 22.7 with 15 steps, outperforming Claude's 22.0 and 14.9 respectively. In Android World, UI-TARS achieves 46.6, surpassing GPT-4o's 34.5. UI-TARS incorporates several key innovations: (1) Enhanced Perception: leveraging a large-scale dataset of GUI screenshots for context-aware understanding of UI elements and precise captioning; (2) Unified Action Modeling, which standardizes actions into a unified space across platforms and achieves precise grounding and interaction through large-scale action traces; (3) System-2 Reasoning, which incorporates deliberate reasoning into multi-step decision making, involving multiple reasoning patterns such as task decomposition, reflection thinking, milestone recognition, etc. (4) Iterative Training with Reflective Online Traces, which addresses the data bottleneck by automatically collecting, filtering, and reflective ly refining new interaction traces on hundreds of virtual machines. Through iterative training and reflection tuning, UI-TARS continuously learns from its mistakes and adapts to unforeseen situations with minimal human intervention. We also analyze the evolution path of GUI agents to guide the further development of this domain. UI-TARS is open sourced at https : / /github .Com/bytedance /UI-TARS.
本文介绍了 UI-TARS,一种原生 GUI 智能体模型,其仅以截图作为输入并执行类人交互(如键盘和鼠标操作)。与依赖高度封装的商业模型(如 GPT-4o)并配备专家精心设计的提示和工作流程的主流智能体框架不同,UI-TARS 是一个端到端模型,其性能优于这些复杂框架。实验证明了其卓越性能:UI-TARS 在评估感知、基础化和 GUI 任务执行的 $^{10+}$ 个 GUI 智能体基准测试中实现了 SOTA 性能(见下文)。值得注意的是,在 OsWorld 基准测试中,UI-TARS 在 50 步和 15 步中分别获得了 24.6 和 22.7 的分数,优于 Claude 的 22.0 和 14.9。在 Android World 中,UI-TARS 获得了 46.6 分,超过了 GPT-4o 的 34.5 分。UI-TARS 包含了几项关键创新:(1) 增强感知:利用大规模 GUI 截图数据集进行上下文感知的 UI 元素理解和精确标注;(2) 统一动作建模,将动作标准化为跨平台的统一空间,并通过大规模动作轨迹实现精确的基础化和交互;(3) 系统-2 推理,将深思熟虑的推理融入多步骤决策,涉及任务分解、反思思维、里程碑识别等多种推理模式;(4) 带反思在线轨迹的迭代训练,通过在数百台虚拟机上自动收集、过滤和反思性地优化新交互轨迹来解决数据瓶颈。通过迭代训练和反思调优,UI-TARS 不断从错误中学习,并以最少的人工干预适应意外情况。我们还分析了 GUI 智能体的演进路径,以指导该领域的进一步发展。UI-TARS 已在 https://github.com/bytedance/UI-TARS 开源。

Contents
目录
1 Introduction
1 引言
3
3
2 Evolution Path of GUI Agents
2 GUI智能体的演进路径
3 Core Capabilities of Native Agent Model
原生智能体模型的核心能力
4UI-TARS 13
4UI-TARS 13
5 Experiment 22
5 实验 22
6 Conclusion 27
6 结论 27
A Case Study 38
案例研究 38
B Data Example 41
B 数据示例 41
1 Introduction
1 引言
Autonomous agents (Wang et al., 2024b; Xi et al., 2023; Qin et al., 2024) are envisioned to operate with minimal human oversight, perceiving their environment, making decisions, and executing actions to achieve specific goals. Among the many challenges in this domain, enabling agents to interact seamlessly with Graphical User Interfaces (GUIs) has emerged as a critical frontier (Hu et al., 2024; Zhang et al., 2024a; Nguyen et al., 2024; Wang et al., 2024e; Ga0 et al., 2024). GUI agents are designed to perform tasks within digital environments that rely heavily on graphical elements such as buttons, text boxes, and images. By leveraging advanced perception and reasoning capabilities, these agents hold the potential to revolutionize task automation, enhance accessibility, and streamline workflows across a wide range of applications.
自主智能体 (Wang et al., 2024b; Xi et al., 2023; Qin et al., 2024) 被设想为在最少的人工监督下运行,感知其环境、做出决策并执行行动以实现特定目标。在该领域的众多挑战中,使智能体能够与图形用户界面 (GUI) 无缝交互已成为一个关键前沿 (Hu et al., 2024; Zhang et al., 2024a; Nguyen et al., 2024; Wang et al., 2024e; Ga0 et al., 2024)。GUI 智能体旨在执行严重依赖按钮、文本框和图像等图形元素的数字环境中的任务。通过利用先进的感知和推理能力,这些智能体有潜力彻底改变任务自动化、增强可访问性,并在广泛的应用中简化工作流程。
The development of GUI agents has historically relied on hybrid approaches that combine textual representations (e.g., HTML structures and accessibility trees) (Liu et al., 2018; Deng et al., 2023; Zhou et al., 2023). While these methods have driven significant progress, they suffer from limitations such as platform-specific inconsistencies, verbosity, and limited s cal ability (Xu et al., 2024). Textual-based methods often require system-level permissions to access underlying system information, such as HTML code, which further limits their applicability and general iz ability across diverse environments. Another critical issue is that, many existing GUI systems follow an agent framework paradigm (Zhang et al., 2023; Wang et al., 2024a; Wu et al., 2024a; Zhang et al., 2024b; Wang & Liu, 2024; Xie et al., 2024), where key functions are modular i zed across multiple components. These components often rely on specialized vision-language models (VLMs), e.g., GPT-4o (Hurst et al., 2024), for understanding and reasoning (Zhang et al., 2024b), while grounding (Lu et al., 2024b) or memory (Zhang et al., 2023) modules are implemented through additional tools or scripts. Although this modular architecture facilitates rapid development in specific domain tasks, it relies on handcrafted approaches that depend on expert knowledge, modular components, and task-specific optimization s, which are less scalable and adaptive than end-to-end models. This makes the framework prone to failure when faced with unfamiliar tasks or dynamically changing environments (Xia et al., 2024).
图形用户界面(GUI)智能体的发展历来依赖于结合文本表示(例如,HTML结构和可访问性树)的混合方法(Liu et al., 2018; Deng et al., 2023; Zhou et al., 2023)。尽管这些方法推动了显著进展,但它们也存在一些局限性,例如平台间的不一致性、冗长性以及有限的扩展性(Xu et al., 2024)。基于文本的方法通常需要系统级权限来访问底层系统信息,例如HTML代码,这进一步限制了它们在不同环境中的适用性和泛化能力。另一个关键问题是,许多现有的GUI系统遵循智能体框架范式(Zhang et al., 2023; Wang et al., 2024a; Wu et al., 2024a; Zhang et al., 2024b; Wang & Liu, 2024; Xie et al., 2024),其中关键功能被模块化分布在多个组件中。这些组件通常依赖于专门的视觉-语言模型(VLMs),例如GPT-4o(Hurst et al., 2024),用于理解和推理(Zhang et al., 2024b),而基础模块(Lu et al., 2024b)或记忆模块(Zhang et al., 2023)则通过额外的工具或脚本实现。尽管这种模块化架构促进了特定领域任务的快速开发,但它依赖于需要专家知识、模块化组件和任务特定优化的手工方法,这使得其扩展性和适应性不如端到端模型。因此,当面对不熟悉的任务或动态变化的环境时,该框架容易失败(Xia et al., 2024)。
These challenges have prompted two key shifts towards native GUI agent model: (1) the transition from textual-dependent to pure-vision-based GUI agents (Bavishi et al., 2023; Hong et al., 2024). “Pure-vision" means the model relies exclusively on screenshots of the interface as input, rather than textual descriptions (e.g., HTML). This bypasses the complexities and platform-specific limitations of textual representations, aligning more closely with human cognitive processes; and (2) the evolution from modular agent frameworks to end-to-end agent models (Wu et al., 2024b; Xu et al., 2024; Lin et al., 2024b; Yang et al., 2024a; Anthropic, 2024b). The end-to-end design unifies traditionally modular i zed components into a single architecture, enabling a smooth flow of information among modules. In philosophy, agent frameworks are design-driven, requiring extensive manual engineering and predefined workflows to maintain stability and prevent unexpected situations; while agent models are inherently data-driven, enabling them to learn and adapt through large-scale data and iterative feedback (Putta et al., 2024).
这些挑战促使了向原生GUI智能体模型的两个关键转变:(1) 从依赖文本的GUI智能体向纯视觉(pure-vision)GUI智能体的转变 (Bavishi et al., 2023; Hong et al., 2024)。"纯视觉"意味着模型仅依赖界面截图作为输入,而非文本描述(如HTML)。这绕过了文本表示的复杂性和平台特定限制,更贴近人类的认知过程;(2) 从模块化智能体框架向端到端(end-to-end)智能体模型的演进 (Wu et al., 2024b; Xu et al., 2024; Lin et al., 2024b; Yang et al., 2024a; Anthropic, 2024b)。端到端设计将传统模块化的组件统一到单一架构中,实现了模块间信息的流畅传递。在理念上,智能体框架是设计驱动的,需要大量手工工程和预定义工作流程来保持稳定性并防止意外情况;而智能体模型本质上是数据驱动的,能够通过大规模数据和迭代反馈进行学习和适应 (Putta et al., 2024)。
Despite their conceptual advantages, today's native GUI agent model often falls short in practical applications, causing their real-world impact to lag behind its hype. These limitations stem from two primary sources: (1) the GUI domain itself presents unique challenges that compound the difficulty of developing robust agents. (1.a) On the perception side, agents must not only recognize but also effectively interpret the high information-density of evolving user interfaces. (1.b) Reasoning and planning mechanisms are equally important in order to navigate, manipulate, and respond to these interfaces effectively. (1.c) These mechanisms must also leverage memory, considering past interactions and experiences to make informed decisions. (1.d) Beyond high-level decision-making, agents must also execute precise, low-level actions, such as outputting exact screen coordinates for clicks or drags and inputting text into the appropriate fields. (2) The transition from agent frameworks to agent models introduces a fundamental data bottleneck. Modular frameworks traditionally rely on separate datasets tailored to individual components. These datasets are relatively easy to curate since they address isolated functionalities. However, training an end-to-end agent model demands data that integrates all components in a unified workflow, capturing the seamless interplay between perception, reasoning, memory, and action. Such data, which comprise rich workflow knowledge from human experts, have been scarcely recorded historically. This lack of comprehensive, high-quality data limits the ability of native agents to generalize across diverse real-world scenarios, hindering their s cal ability and robustness.
尽管具有概念上的优势,当今的原生 GUI 智能体模型在实际应用中往往表现不佳,导致其实际影响远不及宣传。这些局限性主要源于两个原因:(1) GUI 领域本身存在独特的挑战,增加了开发健壮智能体的难度。(1.a) 在感知方面,智能体不仅需要识别,还需要有效解释不断变化的用户界面的高信息密度。(1.b) 推理和规划机制同样重要,以便有效地导航、操作和响应这些界面。(1.c) 这些机制还必须利用记忆,考虑过去的交互和经历,以做出明智的决策。(1.d) 除了高层次的决策,智能体还必须执行精确的低层次操作,例如输出点击或拖动的精确屏幕坐标,并在适当的字段中输入文本。(2) 从智能体框架到智能体模型的转变引入了一个基本的数据瓶颈。模块化框架传统上依赖于为各个组件量身定制的单独数据集。这些数据集相对容易整理,因为它们处理的是孤立的功能。然而,训练端到端智能体模型需要能够将所有组件整合到统一工作流中的数据,捕捉感知、推理、记忆和行动之间的无缝交互。此类数据包含来自人类专家的丰富工作流知识,历史上很少被记录。这种缺乏全面、高质量数据的情况限制了原生智能体在多样化现实场景中的泛化能力,阻碍了其扩展性和鲁棒性。
To address these challenges, this paper focuses on advancing native GUI agent model. We begin by reviewing the evolution path for GUI agents $(\S,2)$ . By segmenting the development of GUI agents into key stages based on the degree of human intervention and generalization capabilities, we conduct a comprehensive literature review. Starting with traditional rule-based agents, we highlight the evolution from rigid, framework-based systems to adaptive native models that seamlessly integrate perception, reasoning, memory, and action. We
为应对这些挑战,本文致力于推进原生GUI智能体模型的发展。我们首先回顾了GUI智能体的演进路径 $(\S,2)$ 。通过根据人类干预程度和泛化能力将GUI智能体的发展划分为关键阶段,我们进行了全面的文献综述。从传统的基于规则的智能体开始,我们强调了从僵化的、基于框架的系统到无缝集成感知、推理、记忆和动作的自适应原生模型的演进过程。

Find round trip flights from SEA to NYC on 5th next month and filtered by price in ascending order.
查找下月5日从SEA到NYC的往返航班,并按价格升序筛选。
UI-TARS
UI-TARS

Figure 1: A demo case of UI-TARS that helps user to find fights.
图 1: UI-TARS 帮助用户查找航班的演示案例。
also prospect the future potential of GUI agents capable of active and lifelong learning, which minimizes human intervention while maximizing generalization abilities. To deepen understanding, we provide a detailed analysis of the core capabilities of the native agent model, which include: (1) perception, enabling real-time environmental understanding for improved situational awareness; (2) action, requiring the native agent model to accurately predict and ground actions within a predefined space; (3) reasoning, which emulates human thought processes and encompasses both System 1 and System 2 thinking; and (4) memory, which stores task-specific information, prior experiences, and background knowledge. We also summarize the main evaluation metrics and benchmarks for GUI agents.
展望未来具有主动学习和终身学习能力的GUI智能体潜力,这类智能体能够最小化人类干预,同时最大化泛化能力。为了加深理解,我们对原生智能体模型的核心能力进行了详细分析,包括:(1) 感知能力,使智能体能够实时理解环境,提升情境感知;(2) 行动能力,要求原生智能体模型在预定义空间内准确预测和落地行动;(3) 推理能力,模拟人类思维过程,涵盖系统1和系统2思维;(4) 记忆能力,存储任务特定信息、先前经验和背景知识。我们还总结了GUI智能体的主要评估指标和基准。
Based on these analyses, we propose a native GUI agent model UI-TARS2, with a demo case illustrated in Figure 1. UI-TARS incorporates the following core contributions:
基于这些分析,我们提出了一个原生GUI智能体模型UI-TARS2,图1展示了一个演示案例。UI-TARS包含以下核心贡献:
· Enhanced Perception for GUI Screenshots $(\S\ 4.2)$ : GUI environments, with their high information density, intricate layouts, and diverse styles, demand robust perception capabilities. We curate a largescale dataset by collecting screenshots using specialized parsing tools to extract metadata such as element types, bounding boxes, and text content from websites, applications, and operating systems. The dataset targets the following tasks: (1) element description, which provides fine-grained, structured descriptions of GUI components; (2) dense captioning, aimed at holistic interface understanding by describing the entire GUI layout, including spatial relationships, hierarchical structures, and interactions among elements; (3) state transition captioning, which captures subtle visual changes in the screen; (4) question answering, designed to enhance the agent's capacity for visual reasoning; and (5) set-of-mark prompting, which uses visual markers to associate GUI elements with specific spatial and functional contexts. These carefully designed tasks collectively enable UI-TARS to recognize and understand GUI elements with exceptional precision, providing a robust foundation for further reasoning and action.
· 增强 GUI 截图的感知能力 $(S\ 4.2)$ :GUI 环境具有高信息密度、复杂布局和多样化的风格,需要强大的感知能力。我们通过使用专门的解析工具收集截图来构建一个大规模数据集,从网站、应用程序和操作系统中提取元素类型、边界框和文本内容等元数据。该数据集针对以下任务:(1) 元素描述,提供对 GUI 组件的细粒度、结构化描述;(2) 密集标注,旨在通过描述整个 GUI 布局(包括空间关系、层次结构和元素之间的交互)来实现对界面的整体理解;(3) 状态转换标注,捕捉屏幕中的细微视觉变化;(4) 问答,旨在增强智能体的视觉推理能力;(5) 标记集提示,使用视觉标记将 GUI 元素与特定的空间和功能上下文关联起来。这些精心设计的任务共同使 UI-TARS 能够以极高的精度识别和理解 GUI 元素,为进一步的推理和行动提供了坚实的基础。
· Unified Action Modeling for Multi-step Execution $(\S\ 4.3)$ : we design a unified action space to standardize semantically equivalent actions across platforms. To improve multi-step execution, we create a large-scale dataset of action traces, combining our annotated trajectories and standardized open-source data. The grounding ability, which involves accurately locating and interacting with specific GUI elements, is improved by curating a vast dataset that pairs element descriptions with their spatial coordinates. This data enables UI-TARS to achieve precise and reliable interactions.
· 多步执行的统一动作建模 $(\S\ 4.3)$:我们设计了一个统一的动作空间,以标准化跨平台的语义等价动作。为了改进多步执行,我们创建了一个大规模的动作轨迹数据集,结合了我们标注的轨迹和标准化的开源数据。通过整理一个庞大的数据集,将元素描述与其空间坐标配对,提升了定位能力,即准确找到并与特定GUI元素交互的能力。这些数据使UI-TARS能够实现精确可靠的交互。
· System-2 Reasoning for Deliberate Decision-making (§ 4.4): robust performance in dynamic environments demands advanced reasoning capabilities. To enrich reasoning ability, we crawl 6M GUI tutorials, meticulously filtered and refined to provide GUI knowledge for logical decision-making. Building on this foundation, we augment reasoning for all the collected action traces by injecting diverse reasoning patterns—such as task decomposition, long-term consistency, milestone recognition, trial&error, and reflection—-into the model. UI-TARS integrates these capabilities by generating explicit “thoughts" before each action, bridging perception and action with deliberate decision-making.
系统-2推理用于审慎决策(§ 4.4):在动态环境中实现稳健性能需要先进的推理能力。为了增强推理能力,我们爬取了600万条GUI教程,经过精心筛选和提炼,为逻辑决策提供GUI知识。在此基础上,我们通过向模型中注入多样化的推理模式(如任务分解、长期一致性、里程碑识别、试错和反思)来增强所有收集到的动作轨迹的推理能力。UI-TARS通过在每个动作之前生成明确的“思考”来整合这些能力,将感知与动作通过审慎决策连接起来。
· Iterative Refinement by Learning from Prior Experience $(\S\ 4.5)$ : a significant challenge in GUI agent development lies in the scarcity of large-scale, high-quality action traces for training. To overcome this data bottleneck, UI-TARS employs an iterative improvement framework that dynamically collects and refines new interaction traces. Leveraging hundreds of virtual machines, UI-TARS explores diverse real-world tasks based on constructed instructions and generates numerous traces. Rigorous multi-stage filtering——incorporating rule-based heuristics, VLM scoring, and human review—-ensures trace quality. These refined traces are then fed back into the model, enabling continuous, iterative enhancement of the agent's performance across successive cycles of training. Another central component of this online boots trapping process is reflection tuning, where the agent learns to identify and recover from errors by analyzing its own suboptimal actions. We annotate two types of data for this process: (1) error correction, where annotators pinpoint mistakes in agent-generated traces and label the corrective actions, and (2) post-reflection, where annotators simulate recovery steps, demonstrating how the agent should realign task progress after an error. These two types of data create paired samples, which are used to train the model using Direct Preference Optimization (DPO) (Rafailov et al., 2023). This strategy ensures that the agent not only learns to avoid errors but also adapts dynamically when they occur. Together, these strategies enable UI-TARS to achieve robust, scalable learning with minimal human oversight.
· 通过从先验经验中学习进行迭代优化(§ 4.5):GUI智能体开发中的一个重大挑战在于缺乏大规模、高质量的动作轨迹用于训练。为了克服这一数据瓶颈,UI-TARS采用了一种迭代改进框架,动态收集并优化新的交互轨迹。通过利用数百台虚拟机,UI-TARS基于构建的指令探索多样化的现实任务,并生成大量轨迹。严格的多阶段过滤——包括基于规则的启发式方法、VLM评分和人工审查——确保了轨迹的质量。这些优化后的轨迹随后反馈给模型,使得智能体在连续的训练周期中能够持续迭代提升性能。这一在线引导过程的核心组成部分之一是反思调优,智能体通过分析自身次优动作来学习识别并从中恢复。我们为此过程标注了两种类型的数据:(1) 错误修正,标注者指出智能体生成轨迹中的错误并标记纠正动作,(2) 事后反思,标注者模拟恢复步骤,展示智能体在错误发生后应如何重新调整任务进度。这两种类型的数据创建了配对样本,用于通过直接偏好优化(DPO)(Rafailov et al., 2023) 训练模型。这一策略确保智能体不仅学会避免错误,还能在错误发生时动态调整。这些策略共同使UI-TARS在最少人工监督下实现了稳健、可扩展的学习。
We continually train Qwen-2-VL 7B and 72B (Wang et al., 2024c) on approximately 50 billion tokens to develop UI-TARS-7B and UI-TARS-72B. Through extensive experiments, we draw the following conclusions:
我们持续训练 Qwen-2-VL 7B 和 72B (Wang et al., 2024c) 在大约 500 亿 Token 上,开发了 UI-TARS-7B 和 UI-TARS-72B。通过大量实验,我们得出以下结论:
2 Evolution Path of GUI Agents
2 GUI智能体的演进路径
GUI agents are particularly significant in the context of automating workflows, where they help streamline repetitive tasks, reduce human effort, and enhance productivity. At their core, GUI agents are designed to facilitate the interaction between humans and machines, simplifying the execution of tasks. Their evolution reflects a progression from rigid, human-defined heuristics to increasingly autonomous systems that can adapt, learn, and even independently identify tasks. In this context, the role of GUI agents has shifted from simple automation to ful-fledged, self-improving agents that increasingly integrate with the human workflow, acting not just as tools, but as collaborators in the task execution process.
GUI智能体在工作流自动化中的重要性
Over the years, agents have progressed from basic rule-based automation to an advanced, highly automated, and flexible system that increasingly mirrors human-like behavior and requires minimal human intervention to perform its tasks. As illustrated in Figure 2, the development of GUI agents can be broken down into several key stages, each representing a leap in autonomy, fexibility, and generalization ability. Each stage is characterized by how much human intervention is required in the workfow design and learning process.
多年来,AI智能体 (AI Agent) 已经从基于规则的基本自动化发展为先进的、高度自动化的灵活系统,越来越像人类行为,并且需要最少的人工干预来执行任务。如图 2 所示,GUI 智能体的发展可以分为几个关键阶段,每个阶段都代表着自主性、灵活性和泛化能力的飞跃。每个阶段的特点在于工作流设计和学习过程中需要多少人工干预。
2.1 Rule-based Agents
2.1 基于规则的AI智能体
Stage 1: Rule-based Agents In the initial stage, agents such as Robotic Process Automation (RPA) systems (Dobrica, 2022; Hofmann et al., 2020) were designed to replicate human actions in highly structured environments, often interacting with GUIs and enterprise software systems. These agents typically processed user instructions by matching them to predefined rules and invoking APIs accordingly. Although effective for well-defined and repetitive tasks, these systems were constrained by their reliance on human-defined heuristics and explicit instructions, hindering their ability to handle novel and complex scenarios. At this stage, the agent cannot learn from its environment or previous experiences, and any changes to the workflow require human intervention. Moreover, these agents require direct access to APIs or underlying system permissions, as demonstrated by systems like DART (Memon et al., 2003), WoB (Shi et al., 2017), Roscript (Qian et al., 2020) and FLIN (Mazumder & Riva, 2021). This makes it unsuitable for cases where such access is restricted or unavailable. This inherent rigidity constrained their applicability to scale across diverse environments.
第一阶段:基于规则的智能体
The limitations of rule-based agents underscore the importance of transitioning to GUI-based agents that rely on visual information and explicit operation on GUIs instead of requiring low-level access to systems. Through visual interaction with interfaces, GUI agents unlock greater fexibility and adaptability, significantly expanding the range of tasks they can accomplish without being limited by predefined rules or the need for explicit system access. This paradigm shift opens pathways for agents to interact with unfamiliar or newly developed interfaces autonomously.
基于规则的智能体的局限性突显了向基于图形用户界面(GUI)的智能体过渡的重要性,这些智能体依赖于视觉信息和对GUI的显式操作,而不是需要低级别系统访问权限。通过与界面的视觉交互,GUI智能体获得了更高的灵活性和适应性,显著扩展了它们能够完成的任务范围,而不受预定义规则或需要显式系统访问的限制。这种范式转变为智能体自主与不熟悉或新开发的界面交互开辟了途径。

Figure 2: The evolution path for GUI agents.
图 2: GUI 智能体的演进路径。
2.2 From Modular Agent Framework to Native Agent Model
2.2 从模块化智能体框架到原生智能体模型
Agent frameworks leveraging the power of large models (M)LLMs have surged in popularity recently. This surge is driven by the foundation models’ ability to deeply comprehend diverse data types and generate relevant outputs via multi-step reasoning. Unlike rule-based agents, which necessitate handcrafted rules for each specific task, foundation models can generalize across different environments and effectively handle tasks by interacting multiple times with environments. This eliminates the need for humans to painstakingly define rules for every new scenario, significantly simplifying agent development and deployment.
利用大模型 (M)LLMs 力量的智能体框架最近迅速流行起来。这一趋势的推动力在于基础模型能够深入理解多种数据类型,并通过多步推理生成相关输出。与基于规则的智能体不同,后者需要为每个特定任务手工制定规则,而基础模型能够在不同环境中进行泛化,并通过多次与环境交互有效地处理任务。这消除了人类为每个新场景费力定义规则的需要,极大地简化了智能体的开发和部署。
Stage 2: Agent Framework Specifically, these agent systems mainly leverage the understanding and reasoning capabilities of advanced foundation models (e.g., GPT-4 (OpenAI, 2023b) and GPT-4o (Hurst et al., 2024)) to enhance task execution fexibility, which become more fexible, framework-based agents. Early efforts primarily focused on tasks such as calling specific APIs or executing code snippets within text-based interfaces (Wang et al., 2023; Li et al., 2023a,b; Wen et al., 2023; Nakano et al., 2021). These agents marked a significant advancement from purely rule-based systems by enabling more automatic and fexible interactions. Autonomous frameworks like AutoGPT (Yang et al., 2023a) and LangChain allow agents to integrate multiple external tools, APIs, and services, enabling a more dynamic and adaptable workflow.
阶段 2: 智能体框架
Enhancing the performance of foundation model-based agent frameworks often involves designing taskspecific workflows and optimizing prompts for each component. For instance, some approaches augment these frameworks with specialized modules, such as short- or long-term memory, to provide task-specific knowledge or store operational experience for self-improvement. Cradle (Tan et al., 2024) enhances foundational agents' multitasking capabilities by storing and leveraging task execution experiences. Similarly, Song et al. (2024) propose a framework for API-driven web agents that utilizes task-specific background knowledge to execute complex web operations. The Agent Workflow Memory (AWM) module (Wang et al., 2024g) further optimizes memory management by selectively providing relevant workflows to guide the agent's subsequent actions. Another common strategy to improve task success is the incorporation of reflection-based, multi-step reasoning to refine action planning and execution. The widely recognized ReAct framework (Yao et al., 2023) integrates reasoning with the outcomes of actions, enabling more dynamic and adaptable planning. For multimodal tasks, MM Navigator (Yan et al., 2023) leverages summarized contextual actions and mark tags to generate accurate, executable actions. SeeAct (Zheng et al., 2024b) takes a different approach by explicitly instructing GPT-4V to mimic human browsing behavior, taking into account the task, webpage content, and previous actions. Furthermore, multi-agent collaboration has emerged as a powerful technique for boosting task completion rates. Mobile Experts (Zhang et al., 2024c), for example, addresses the unique challenges of mobile environments by incorporating tool formulation and fostering collaboration among multiple agents. In summary, current advancements in agent frameworks heavily rely on optimizing plan and action generation through prompt engineering, centered around the capabilities of the underlying foundation models, ultimately leading to improved task completion.
提升基于基础模型的AI智能体框架性能,通常涉及设计任务特定的工作流并优化每个组件的提示。例如,一些方法通过增加专门模块(如短期或长期记忆)来增强这些框架,以提供任务特定知识或存储操作经验以实现自我改进。Cradle (Tan et al., 2024) 通过存储和利用任务执行经验来增强基础智能体的多任务能力。同样,Song et al. (2024) 提出了一个API驱动的网页智能体框架,该框架利用任务特定的背景知识来执行复杂的网页操作。Agent Workflow Memory (AWM) 模块 (Wang et al., 2024g) 通过选择性提供相关工作流来进一步优化内存管理,以指导智能体的后续操作。另一个提高任务成功率的常见策略是结合基于反思的多步推理,以优化行动计划和执行。广为人知的ReAct框架 (Yao et al., 2023) 将推理与行动结果相结合,实现更动态和适应性强的计划。对于多模态任务,MM Navigator (Yan et al., 2023) 利用汇总的上下文操作和标记标签生成准确可执行的操作。SeeAct (Zheng et al., 2024b) 则采用不同方法,明确指示GPT-4V模仿人类浏览行为,同时考虑任务、网页内容和之前的操作。此外,多智能体协作已成为提高任务完成率的强大技术。例如,Mobile Experts (Zhang et al., 2024c) 通过工具制定和促进多个智能体之间的协作,解决了移动环境中的独特挑战。总之,当前智能体框架的进展在很大程度上依赖于通过提示工程优化计划和行动生成,围绕基础模型的能力,最终提高任务完成率。
Key Limitations of Agent Frameworks Despite greater adaptability compared to rule-based systems, agent frameworks still rely on human-defined workflows to structure their actions. The “agentic workflow knowledge" (Wang et al., 2024g) is manually encoded through custom prompts, external scripts, or tool-usage heuristics. This external iz ation of knowledge yields several drawbacks:
AI智能体框架的关键限制
Thus, while agent frameworks offer quick demonstrations and are fexible within a narrow scope, they ultimately remain brittle when deployed in real-world scenarios, where tasks and interfaces continuously evolve. This reliance on pre-programmed workflows, driven by human expertise, makes frameworks inherently non-scalable. They depend on the foresight of developers to anticipate all future variations, which limits their capacity to handle unforeseen changes or learn autonomously. Frameworks are design-driven, meaning they lack the ability to learn and generalize across tasks without continuous human involvement.
因此,尽管AI智能体框架能够快速展示并在有限范围内灵活应用,但在实际场景中部署时,由于任务和界面不断演变,它们最终仍然显得脆弱。这种依赖于人类专业知识预先编程的工作流程,使得框架本质上不具备可扩展性。它们依赖于开发者的远见来预测所有未来的变化,这限制了它们处理意外变化或自主学习的能力。框架是设计驱动的,这意味着在没有持续人类参与的情况下,它们缺乏跨任务学习和泛化的能力。
Stage 3: Native Agent Model In contrast, the future of autonomous agent development lies in the creation of native agent models, where workflow knowledge is embedded directly within the agent's model through orientation al learning. In this paradigm, tasks are learned and executed in an end-to-end manner, unifying perception, reasoning, memory, and action within a single, continuously evolving model. This approach is fundamentally data-driven, allowing for the seamless adaptation of agents to new tasks, interfaces, or user needs without relying on manually crafted prompts or predefined rules. Native agents offer several distinct advantages that contribute to their s cal ability and adaptability:
阶段 3: 原生智能体模型 (Native Agent Model)
· Holistic Learning and Adaptation: because the agent's policy is learned end-to-end, it can unify knowledge from perception, reasoning, memory, and action in its internal parameters. As new data or user demonstrations become available, the entire system (rather than just a single module or prompt) updates its knowledge. This empowers the model to adapt more seamlessly to changing tasks, interfaces, or user demands.
· 整体学习与适应:由于AI智能体的策略是端到端学习的,它可以在内部参数中统一来自感知、推理、记忆和行动的知识。随着新数据或用户演示的可用,整个系统(而不仅仅是单个模块或提示)会更新其知识。这使得模型能够更无缝地适应不断变化的任务、界面或用户需求。
· Reduced Human Engineering: instead of carefully scripting how the LLM/VLM should be invoked at each node, native models learn task-relevant workflows from large-scale demonstrations or online experiences. The burden of *hardwiring a workflow"' is replaced by data-driven learning. This significantly reduces the need for domain experts to handcraft heuristics whenever the environment evolves.
· 减少人工设计:原生模型从大规模演示或在线经验中学习任务相关的工作流程,而不是精心编写在每个节点上如何调用大语言模型/视觉语言模型(LLM/VLM)。通过数据驱动的学习取代了“硬编码工作流程”的负担。这显著减少了领域专家在环境变化时手动设计启发式规则的需求。
· Strong Generalization via Unified Parameters: Although manual prompt engineering can make the model adaptable to user-defined new tools, the model itself cannot evolve. Under one parameterized policy and a unified data construction and training pipeline, knowledge among environments like certain app features, navigation strategies, or UI patterns can be transferred across tasks, equipping it with strong generalization.
· 通过统一参数实现强泛化:尽管手动提示工程可以使模型适应用户自定义的新工具,但模型本身无法进化。在一个参数化的策略和统一的数据构建与训练流程下,某些应用功能、导航策略或UI模式等环境间的知识可以在任务之间转移,从而赋予其强大的泛化能力。
· Continuous Self-Improvement: native agent models lend themselves naturally to online or lifelong learning paradigms. By deploying the agent in real-world GUI environments and collecting new interaction data, the model can be fine-tuned or further trained to handle novel challenges.
· 持续自我改进:原生智能体模型自然适用于在线或终身学习范式。通过在真实世界的 GUI 环境中部署智能体并收集新的交互数据,可以对模型进行微调或进一步训练,以应对新的挑战。
This data-driven, learning-oriented approach stands in contrast to the design-driven, static nature of agent frameworks. As for now, the development of GUI agent gradually reached this stage, which representative works like Claude Computer-Use (Anthropic, 2024b), Aguvis (Xu et al., 2024), ShowUI (Lin et al., 2024b), OS-Atlas (Wu et al., 2024b), Octopus v2-4 (Chen & Li, 2024), etc. These models mainly utilize existing world data to tailor large VLMs specifically for the domain of GUI interaction.
这种数据驱动、以学习为导向的方法与AI智能体框架的设计驱动、静态特性形成对比。目前,GUI智能体的发展已逐步达到这一阶段,代表性工作包括Claude Computer-Use (Anthropic, 2024b)、Aguvis (Xu et al., 2024)、ShowUI (Lin et al., 2024b)、OS-Atlas (Wu et al., 2024b)、Octopus v2-4 (Chen & Li, 2024)等。这些模型主要利用现有的世界数据,专门为GUI交互领域定制大型视觉语言模型 (VLMs)。

Figure 3: An overview of core capabilities and evaluation for GUI agents
图 3: GUI 智能体的核心能力与评估概览
2.3 Active and Lifelong Agent (Prospect)
2.3 主动与终身智能体(展望)
Stage 4: Action and Lifelong Agent Despite improvements in adaptability, native agents still rely heavily on human experts for data labeling and training guidance. This dependence inherently restricts their capabilities, making them contingent upon the quality and breadth of human-provided data and knowledge.
阶段 4:行动与终身 AI智能体
The transition towards active and lifelong learning (Sur et al., 2022; Rama moor thy et al., 2024) represents a crucial next step in the evolution of GUI agents. In this paradigm, agents actively engage with their environment to propose tasks, execute them, and evaluate the outcomes. These agents can autonomously assign self-rewards based on the success of their actions, reinforcing positive behaviors and progressively refining their capabilities through continuous feedback loops. This process of self-directed exploration and learning allows the agent to discover new knowledge, improve task execution, and enhance problem-solving strategies without heavy reliance on manual annotations or explicit external guidance.
向主动学习和终身学习(Sur 等,2022;Rama moor thy 等,2024)的转变代表了 GUI 智能体(GUI agents)发展的关键下一步。在这一范式中,智能体主动与环境互动,提出任务、执行任务并评估结果。这些智能体可以根据其行动的成功与否自主分配自我奖励,通过持续的反馈循环强化积极行为,并逐步提升其能力。这种自我驱动的探索和学习过程使智能体能够发现新知识、改进任务执行并增强问题解决策略,而无需过度依赖人工标注或明确的外部指导。
These agents develop and modify their skills iterative ly, much like continual learning in robotics (Ayub et al., 2024; Soltoggio et al., 2024), where they can learn from both successes and failures, progressively enhancing their generalization across an increasingly broad range of tasks and scenarios. The key distinction between native agent models and active lifelong learners lies in the autonomy of the learning process: native agents still depend on humans, whereas active agents drive their own learning by identifying gaps in their knowledge and filling them through self-initiated exploration.
这些智能体迭代地开发和修改其技能,类似于机器人技术中的持续学习(Ayub et al., 2024;Soltoggio et al., 2024),它们可以从成功和失败中学习,逐步增强其在越来越广泛的任务和场景中的泛化能力。原生智能体模型与主动终身学习者的关键区别在于学习过程的自主性:原生智能体仍然依赖人类,而主动智能体通过识别自身知识的空白并通过自主探索填补这些空白来驱动其学习。
In this work, we focus on building a scalable and data-driven native agent model, which paves the way for this active and lifelong agent stage. We begin by exploring the core capabilities necessary for such a framework $(\S\ 3)$ and then introduce UI-TARS, our instantiation of this approach $(\S,4)$
在本工作中,我们专注于构建一个可扩展且数据驱动的原生智能体模型,为这一活跃且终身的智能体阶段铺平道路。我们首先探索了这种框架所需的核心能力 (见第 3 节),然后介绍了 UI-TARS,这是我们对该方法的实例化 (见第 4 节)。
3 Core Capabilities of Native Agent Model
3 原生 AI 智能体模型的核心能力
The native agent model internalizes modular i zed components from the previous agent framework into several core capabilities, thereby transitioning towards an end-to-end structure. To get a more profound understanding of the native agent model, this section delves into an in-depth analysis of its core capabilities and reviews the current evaluation metrics and benchmarks.
原生 AI智能体模型将先前 AI智能体框架中的模块化组件内化为几项核心能力,从而向端到端结构过渡。为了更深入地理解原生 AI智能体模型,本节将深入分析其核心能力,并回顾当前的评估指标和基准。
3.1 Core Capabilities
3.1 核心能力
As ilustrated in Figure 3, our analysis is structured around four main aspects: perception, action, reasoning (system-1&2 thinking), and memory.
如图 3 所示,我们的分析围绕四个主要方面展开:感知、行动、推理(系统1和系统2思维)以及记忆。
Perception A fundamental aspect of effective GUI agents lies in their capacity to precisely perceive and interpret graphical user interfaces in real-time. This involves not only understanding static screenshots, but also dynamically adapting to changes as the interface evolves. We review existing works based on their usage of input features:
感知
有效的 GUI 智能体的一个基本方面在于其能够实时精确感知和解释图形用户界面。这不仅涉及理解静态截图,还包括动态适应界面的变化。我们根据其对输入特征的使用回顾现有工作:
· Structured Text: early iterations (Li et al., 2023a; Wang et al., 2023; Wu et al., 2024a) of GUI agents powered by LLMs are constrained by the LLMs' limitation of processing only textual input. Consequently, these agents rely on converting GUI pages into structured textual representations, such as HTML, accessibility trees, or Document Object Model (DOM). For web pages, some agents use HTML data as input or leverage the DOM to analyze pages’ layout. The DOM provides a tree-like structure that organizes elements hierarchically. To reduce input noise, Agent-E (Abuelsaad et al., 2024) utilizes a DOM distillation technique to achieve more effective screenshot representations. Tao et al. (2023) introduce Web WISE, which iterative ly generates small programs based on observations from filtered DOM elements and performs tasks in a sequential manner.
结构化文本:早期由大语言模型驱动的 GUI 智能体(Li et al., 2023a; Wang et al., 2023; Wu et al., 2024a)受限于大语言模型只能处理文本输入的局限性。因此,这些智能体依赖于将 GUI 页面转换为结构化的文本表示,例如 HTML、无障碍树或文档对象模型 (DOM)。对于网页,一些智能体使用 HTML 数据作为输入或利用 DOM 来分析页面布局。DOM 提供了一种树状结构,以层次化的方式组织元素。为了减少输入噪声,Agent-E (Abuelsaad et al., 2024) 使用 DOM 蒸馏技术来实现更有效的截图表示。Tao et al. (2023) 引入了 Web WISE,它基于过滤后的 DOM 元素观察迭代生成小程序,并以顺序方式执行任务。
· Visual Screenshot: with advancements in computer vision and VLMs, agents are now capable of leveraging visual data from screens to interpret their on-screen environments. A significant portion of research relies on Set-of-Mark (SoM) (Yang et al., 2023b) prompting to improve the visual grounding capabilities. To enhance visual understanding, these methods frequently employ Optical Character Recognition (OCR) in conjunction with GUI element detection models, including ICONNet (Sunkara et al., 2022) and DINO (Liu et al., 2025). These algorithms are used to identify and delineate interactive elements through bounding boxes, which are subsequently mapped to specific image regions, enriching the agents? contextual comprehension. Some studies also improve the semantic grounding ability and understanding of elements by adding descriptions of these interactive elements in the screenshots. For example, SeeAct (Zheng et al., 2024a) enhances fine-grained screenshot content understanding by associating visual elements with the content they represent in HTML web.
· 视觉截图:随着计算机视觉和视觉语言模型(VLM)的进步,AI智能体现在能够利用屏幕中的视觉数据来解读其屏幕环境。大部分研究依赖于标记集(Set-of-Mark, SoM) (Yang et al., 2023b) 提示来增强视觉定位能力。为了提升视觉理解能力,这些方法经常结合光学字符识别(OCR)与图形用户界面(GUI)元素检测模型,包括 ICONNet (Sunkara et al., 2022) 和 DINO (Liu et al., 2025)。这些算法用于通过边界框识别和划分交互元素,随后将这些元素映射到特定的图像区域,从而增强AI智能体的上下文理解能力。一些研究还通过在截图中添加这些交互元素的描述,来提高语义定位能力和元素理解能力。例如,SeeAct (Zheng et al., 2024a) 通过将视觉元素与它们在HTML网页中代表的内容关联起来,增强了细粒度的截图内容理解能力。
· Comprehensive Interface Modeling: recently, certain works have employed structured text, visual snapshots, and semantic outlines of elements to attain a holistic understanding of external perception. For instance, Gou et al. (2024a) synthesize large-scale GUI element data and train a visual grounding model UGround to gain the associated references of elements in GUI pages on various platforms. Similarly, OSCAR (Wang & Liu, 2024) utilizes an A1ly tree generated by the Windows API for representing GUI components, incorporating descriptive labels to facilitate semantic grounding. Meanwhile, DUALVCR (Kil et al., 2024) captures both the visual features of the screenshot and the descriptions of associated HTML elements to obtain a robust representation of the visual screenshot.
全面界面建模:近期,部分研究通过使用结构化文本、视觉快照和元素的语义轮廓来全面理解外部感知。例如,Gou 等人 (2024a) 合成了大规模 GUI 元素数据,并训练了一个视觉基础模型 UGround,以获取不同平台 GUI 页面中元素的关联引用。类似地,OSCAR (Wang & Liu, 2024) 利用 Windows API 生成的 A1ly 树来表示 GUI 组件,并加入描述性标签以促进语义基础。同时,DUALVCR (Kil et al., 2024) 捕捉了截图的视觉特征和关联 HTML 元素的描述,以获得视觉截图的强大表示。
Another important point is the ability to interact in real-time. GUIs are inherently dynamic, with elements frequently changing in response to user actions or system processes. GUI agents must continuously monitor these changes to maintain an up-to-date understanding of the interface's state. This real-time perception is critical for ensuring that agents can respond promptly and accurately to evolving conditions. For instance, if a loading spinner appears, the agent should recognize it as an indication of a pending process and adjust its actions accordingly. Similarly, agents must detect and handle scenarios where the interface becomes unresponsive or behaves unexpectedly.
另一个重要的点是实时交互的能力。GUI 本质上是动态的,元素会随着用户操作或系统进程的变化而频繁变化。GUI 智能体必须持续监控这些变化,以保持对界面状态的最新理解。这种实时感知对于确保智能体能够及时准确地应对不断变化的条件至关重要。例如,如果出现加载动画,智能体应将其识别为待处理进程的指示,并相应地调整其操作。同样,智能体必须检测并处理界面无响应或行为异常的场景。
By effectively combining these above aspects, a robust perception system ensures that the GUI agent can maintain situational awareness and respond appropriately to the evolving state of the user interface, aligning its actions with the user's goals and the application's requirements. However, privacy concerns and the additional perceptual noise introduced by the DOM make it challenging to extend pure text descriptions and hybrid text-visual perceptions to any GUI environment. Hence, similar to human interaction with their surroundings, a native agent model should directly comprehend the external environment through visual perception and ground their actions to the original screenshot accurately. By doing so, the native agent model can generalize various tasks and improve the accuracy of actions at each step.
通过有效结合上述方面,一个强大的感知系统确保 GUI 智能体能够保持态势感知,并适应用户界面不断变化的状态,使其行为与用户目标和应用程序需求保持一致。然而,隐私问题以及 DOM 引入的额外感知噪声使得将纯文本描述和混合文本-视觉感知扩展到任何 GUI 环境变得具有挑战性。因此,类似于人类与周围环境的互动,原生智能体模型应通过视觉感知直接理解外部环境,并将其行为准确地基于原始截图。通过这样做,原生智能体模型可以泛化各种任务,并提高每一步动作的准确性。
Action Effective action mechanisms must be versatile, precise, and adaptable to various GUI contexts. Key aspects include:
行动有效的行动机制必须多样化、精确,并能适应各种GUI(图形用户界面)环境。关键方面包括:
· Unified and Diverse Action Space: GUI agents (Gur et al., 2023; Bonatti et al., 2024) operate across multiple platforms, including mobile devices, desktop applications, and web interfaces, each with distinct interaction paradigms. Establishing a unified action space abstracts platform-specific actions into a common set of operations such as cli ck, type, scroll, and drag. Additionally, integrating actions from language agents-such as API calls (Chen et al., 2024b; Li et al., 2023a,b), code interpretation (Wu et al., 2024a), and Command-Line Interface (CLI) (Mei et al., 2024) operations-enhances agent versatility. Actions can be categorized into atomic actions, which execute single operations, and compositional actions, which sequence multiple atomic actions to streamline task execution. Balancing atomic and compositional actions optimizes efficiency and reduces cognitive load, enabling agents to handle both simple interactions and the coordinated execution of multiple steps seamlessly.
· 统一且多样化的操作空间:GUI智能体(Gur et al., 2023; Bonatti et al., 2024)在多个平台上运行,包括移动设备、桌面应用程序和Web界面,每个平台都有其独特的交互范式。建立一个统一的操作空间将特定平台的操作抽象为一组通用操作,如点击、输入、滚动和拖动。此外,整合来自语言智能体的操作——如API调用(Chen et al., 2024b; Li et al., 2023a,b)、代码解释(Wu et al., 2024a)和命令行界面(CLI)(Mei et al., 2024)操作——增强了智能体的多功能性。操作可以分为原子操作(执行单一操作)和组合操作(将多个原子操作串联起来以简化任务执行)。平衡原子操作和组合操作可以优化效率并减少认知负担,使智能体能够无缝处理简单交互以及多步骤的协调执行。
· Challenges in Grounding Coordinates: accurately determining coordinates for actions like clicks, drags, and swipes is challenging due to variability in GUI layouts (He et al., 2024; Burger et al., 2020), differing aspect ratios across devices, and dynamic content changes. Different devices’ aspect ratios can alter the spatial arrangement of interface elements, complicating precise localization. Grounding coordinates requires advanced techniques to interpret visual cues from screenshots or live interface streams accurately.
· 坐标定位的挑战:由于 GUI 布局的可变性(He et al., 2024; Burger et al., 2020)、设备间不同的宽高比以及动态内容的变化,准确确定点击、拖动和滑动等操作的坐标具有挑战性。不同设备的宽高比可能会改变界面元素的空间排列,使得精确定位变得复杂。坐标定位需要先进的技术来准确解释从截图或实时界面流中提取的视觉信息。
Due to the similarity of actions across different operational spaces, agent models can standardize actions from various GUI contexts into a unified action space. Decomposing actions into atomic operations reduces learning complexity, facilitating faster adaptation and transfer of atomic actions across different platforms.
由于不同操作空间中的动作具有相似性,智能体模型可以将来自各种 GUI 上下文的标准动作统一到一个动作空间中。将动作分解为原子操作降低了学习复杂度,有助于在不同平台间更快地适应和迁移原子操作。
Reasoning with System 1&2 Thinking _ Reasoning is a complex capability that integrates a variety of cognitive functions. Human interaction with GUIs relies on two distinct types of cognitive processes (Groves & Thompson, 1970): system 1 and system 2 thinking.
基于系统1和系统2思维的推理
· System 1 refers to fast, automatic, and intuitive thinking, typically employed for simple and routine tasks, such as clicking a familiar button or dragging a file to a folder without conscious deliberation. · System 2 encompasses slow, deliberate, and analytical thinking, which is crucial for solving complex tasks, such as planning an overall workflow or reflecting to troubleshoot errors.
· System 1 指的是快速、自动和直觉的思维,通常用于简单和常规的任务,例如点击熟悉的按钮或将文件拖到文件夹中而不需要深思熟虑。· System 2 包含缓慢、深思熟虑和分析性的思维,这对于解决复杂任务至关重要,例如规划整体工作流程或反思以排查错误。
Similarly, autonomous GUI agents must develop the ability to emulate both system 1 and system 2 thinking to perform effectively across a diverse range of tasks. By learning to identify when to apply rapid, heuristic-based responses and when to engage in detailed, step-by-step reasoning, these agents can achieve greater efficiency, adaptability, and reliability in dynamic environments.
同样地,自主的 GUI 智能体必须发展出模拟系统 1 和系统 2 思维的能力,以便在各种任务中高效执行。通过学会识别何时应用快速的启发式响应,何时进行详细的逐步推理,这些智能体可以在动态环境中实现更高的效率、适应性和可靠性。
System 1 Reasoning represents the agent's ability to execute fast, intuitive responses by identifying patterns in the interface and applying pre-learned knowledge to observed situations. This form of reasoning mirrors human interaction with familiar elements of a GUI, such as recognizing that pressing ^“Enter” in a text field submits a form or understanding that clicking a certain button progresses to the next step in a workflow. These heuristic-based actions enable agents to respond swiftly and maintain operational efficiency in routine scenarios. However, the reliance on pre-defined mappings limits the scope of their decision-making to immediate, reactive behaviors. For instance, models such as large action models (Wu et al., 2024b; Wang et al., 2024a) excel at generating quick responses by leveraging environmental observations, but they often lack the capacity for more sophisticated reasoning. This constraint becomes particularly evident in tasks requiring the planning and execution of multi-step operations, which go beyond the reactive, one-step reasoning of system 1. Thus, while system 1 provides a foundation for fast and efficient operation, it underscores the need for agents to evolve toward more deliberate and reflective capabilities seen in system 2 reasoning.
系统1推理代表了AI智能体通过识别界面中的模式并将预先学习的知识应用于观察到的情境来执行快速、直观响应的能力。这种推理形式类似于人类与图形用户界面(GUI)中熟悉元素的交互,例如识别在文本字段中按下“Enter”键会提交表单,或理解点击某个按钮会推进工作流程中的下一步。这些基于启发式的行为使AI智能体能够在常规场景中快速响应并保持操作效率。然而,对预定义映射的依赖将其决策范围限制为即时、反应性的行为。例如,大动作模型(Wu et al., 2024b; Wang et al., 2024a)等模型擅长利用环境观察生成快速响应,但它们通常缺乏更复杂推理的能力。这一限制在需要规划和执行多步骤操作的任务中尤为明显,这些任务超出了系统1的反应性、单步推理范围。因此,虽然系统1为快速高效的操作提供了基础,但它强调了AI智能体需要向系统2推理中所见的更具深思熟虑和反思性的能力发展的必要性。
System 2 Reasoning represents deliberate, structured, and analytical thinking, enabling agents to handle complex, multi-step tasks that go beyond the reactive behaviors of system 1. Unlike heuristic-based reasoning, system 2 involves explicitly generating intermediate thinking processes, often using techniques like Chain-ofThought (CoT) (Wei et al., 2022) or ReAct (Ya0 et al., 2023), which bridge the gap between simple actions and intricate workfows. This paradigm of reasoning is composed of several essential components.
系统2推理代表了有目的、结构化和分析性的思维,使AI智能体能够处理超越系统1反应行为的复杂、多步骤任务。与基于启发式的推理不同,系统2涉及显式生成中间思维过程,通常使用诸如Chain-of-Thought (CoT) (Wei et al., 2022) 或 ReAct (Ya0 et al., 2023) 等技术,这些技术在简单动作和复杂工作流程之间架起桥梁。这种推理范式由几个关键组成部分构成。
· First, task decomposition focuses on formulating plannings to achieve over arching objectives by decomposing tasks into smaller, manageable sub-tasks (Dagan et al., 2023; Song et al., 2023; Huang et al., 2024). For example, completing a multi-field form involves a sequence of steps like entering a name, address, and other details, all guided by a well-structured plan.
· 首先,任务分解的重点是通过将任务分解为更小、更易管理的子任务来制定实现总体目标的计划 (Dagan et al., 2023; Song et al., 2023; Huang et al., 2024)。例如,完成一个多字段表单涉及一系列步骤,如输入姓名、地址和其他详细信息,所有这些步骤都由一个结构良好的计划指导。
· Second, long-term consistency is critical during the entire task completion process. By consistently referring back to the initial objective, agent models can effectively avoid any potential deviations that may occur during complex, multi-stage tasks, thus ensuring coherence and continuity from start to finish.
其次,在整个任务完成过程中,长期一致性至关重要。通过持续回顾初始目标,智能体模型能够有效避免在复杂、多阶段任务中可能出现的偏差,从而确保从头到尾的连贯性和连续性。
The development of UI-TARS places a strong emphasis on equipping the model with robust system 2 reasoning capabilities, allowing it to address complex tasks with greater precision and adaptability. By integrating high-level planning mechanisms, UI-TARS excels at decomposing over arching goals into smaller, manageable sub-tasks. This structured approach enables the model to systematically handle intricate workflows that require coordination across multiple steps. Additionally, UI-TARS incorporates a long-form CoT reasoning process, which facilitates detailed intermediate thinking before executing specific actions. Furthermore, UITARS adopts reflection-driven training process. By incorporating reflective thinking, the model continuously evaluates its past actions, identifies potential mistakes, and adjusts its behavior to improve performance over time. The model's iterative learning method yields significant benefits, enhancing its reliability and equipping it to navigate dynamic environments and unexpected obstacles.
UI-TARS 的开发高度重视为模型配备强大的系统 2 推理能力,使其能够以更高的精度和适应性处理复杂任务。通过集成高级规划机制,UI-TARS 擅长将总体目标分解为更小、可管理的子任务。这种结构化方法使模型能够系统地处理需要跨多个步骤协调的复杂工作流。此外,UI-TARS 采用了长链 CoT 推理过程,有助于在执行特定操作之前进行详细的中间思考。更进一步,UI-TARS 采用了反思驱动的训练过程。通过引入反思性思维,模型不断评估其过去的行动,识别潜在的错误,并调整其行为以逐步提高性能。模型的迭代学习方法带来了显著的好处,增强了其可靠性,并使其能够在动态环境和意外障碍中游刃有余。
Memory The memory is mainly used to store the supported explicit knowledge and historical experience that the agent refers to when making decisions. For agent frameworks, an additional memory module is often introduced to store previous interactions and task-level knowledge. Agents then retrieve and update these memory modules during decision-making progress. The memory module can be divided into two categories:
记忆模块主要用于存储智能体在决策时参考的显性知识和历史经验。对于智能体框架,通常会引入额外的记忆模块来存储之前的交互和任务级知识。智能体在决策过程中会检索和更新这些记忆模块。记忆模块可以分为两类:
· Short-term Memory: this serves as a temporary repository for task-specific information, capturing the agent's immediate context. This includes the agent's action history, current state details, and the ongoing execution trajectory of the task, enabling real-time situational awareness and adaptability. By semantically processing contextual screenshots, CoAT (Zhang et al., 2024d) extracts key interface details, thereby enhancing comprehension of the task environment. CoCo-Agent (Ma et al., 2024) records layouts and dynamic states through Comprehensive Environment Perception (CEP).
短期记忆:作为任务特定信息的临时存储库,捕获 AI 智能体的即时上下文。这包括 AI 智能体的行动历史、当前状态细节以及任务的持续执行轨迹,从而实现实时情境感知和适应性。CoAT (Zhang 等人, 2024d) 通过对上下文截图进行语义处理,提取关键界面细节,从而增强对任务环境的理解。CoCo-Agent (Ma 等人, 2024) 通过全面环境感知 (CEP) 记录布局和动态状态。
· Long-term Memory: it operates as a long-term data reserve, capturing and safeguarding records of previous interaction, tasks, and background knowledge. It retains details such as execution paths from prior tasks, offering a comprehensive knowledge base that supports reasoning and decision-making for future tasks. By integrating accumulated knowledge that contains user preferences and task operation experiences, OS-copilot (Wu et al., 2024a) refines its task execution over time to better align with user needs and improve overall efficiency. Cradle (Tan et al., 2024) focuses on enhancing the multitasking abilities of foundational agents by equipping them with the capability to store and utilize task execution experiences. Song et al. (2024) introduce a framework for API-driven web agents that leverage taskspecific background knowledge to perform complex web operations.
长期记忆:它作为长期数据储备,记录和保存之前的交互、任务和背景知识。它保留了之前任务的执行路径等细节,提供了一个全面的知识库,支持未来任务的推理和决策。通过整合包含用户偏好和任务操作经验的积累知识,OS-copilot (Wu et al., 2024a) 逐步优化其任务执行,以更好地适应用户需求并提高整体效率。Cradle (Tan et al., 2024) 专注于增强基础代理的多任务能力,使其具备存储和利用任务执行经验的能力。Song et al. (2024) 提出了一个API驱动的网络代理框架,利用任务特定的背景知识来执行复杂的网络操作。
Memory reflects the capability to leverage background knowledge and input context. The synergy between short-term and long-term memory storage significantly enhances the efficiency of an agent's decision-making process. Native agent models, unlike agent frameworks, encode long-term operational experience of tasks within their internal parameters, converting the observable interaction process into implicit, parameterized storage. Techniques such as In-Context Learning (ICL) or CoT reasoning can be employed to activate this internal memory.
记忆反映了利用背景知识和输入上下文的能力。短期记忆和长期记忆存储之间的协同作用显著提升了智能体决策过程的效率。与智能体框架不同,原生智能体模型在其内部参数中编码了任务的长期操作经验,将可观察的交互过程转化为隐式的参数化存储。可以采用上下文学习(In-Context Learning,ICL)或链式思维(Chain-of-Thought,CoT)推理等技术来激活这种内部记忆。
3.2 Capability Evaluation
3.2 能力评估
To evaluate the effectiveness of GUI agents, numerous benchmarks have been meticulously designed, focusing on various aspects of capabilities such as perception, grounding, and agent capabilities. Specifically, Perception Evaluation reflects the degree of understanding of GUI knowledge. Grounding Evaluation verifies whether agents can accurately locate coordinates in diverse GUI layouts. Agent capabilities can be primarily divided into two categories: Offine Agent Capability Evaluation, which is conducted in a predefined and static environment and mainly focuses on assessing the individual steps performed by GUI agents, and Online Agent Capability Evaluation, which is performed in an interactive and dynamic environment and evaluates the agent's overall capability to successfully complete the task.
为了评估 GUI 智能体的有效性,许多基准测试被精心设计,重点关注感知、定位和智能体能力等各个方面的能力。具体来说,感知评估反映了对 GUI 知识的理解程度。定位评估验证了智能体是否能够在不同的 GUI 布局中准确定位坐标。智能体能力主要分为两类:离线智能体能力评估,在预定义和静态的环境中进行,主要关注评估 GUI 智能体执行的各个步骤;在线智能体能力评估,在交互和动态的环境中进行,评估智能体成功完成任务的整体能力。
Perception Evaluation Perception evaluation assesses agents’ understanding of user interface (Ul) knowledge and their awareness of the environment. For instance, Visual Web Bench (Liu et al., 2024c) focuses on agents’ web understanding capabilities, while WebSRC (Chen et al., 2021) and ScreenQA (Hsiao et al., 2022) evaluate web structure comprehension and mobile screen content understanding through question-answering (QA) tasks. Additionally, GUI-World (Chen et al., 2024a) offers a wide range of queries in multiple-choice, free-form, and conversational formats to assess GUI understanding. Depending on the varying question formats, a range of metrics are employed. For instance, accuracy is utilized for multiple-choice question (MCQ) tasks as the key metric, and in the case of captioning or Optical Character Recognition (OCR) tasks, the ROUGE-L metric is adopted to evaluate performance.
感知评估 感知评估评估AI智能体对用户界面(UI)知识的理解及其对环境的意识。例如,Visual Web Bench (Liu et al., 2024c) 专注于AI智能体的网页理解能力,而WebSRC (Chen et al., 2021) 和 ScreenQA (Hsiao et al., 2022) 通过问答(QA)任务评估网页结构理解和移动屏幕内容理解。此外,GUI-World (Chen et al., 2024a) 提供了多种查询形式,包括选择题、自由形式和对话形式,以评估对图形用户界面(GUI)的理解。根据不同的提问形式,采用了一系列评价指标。例如,在选择题(MCQ)任务中,准确率作为关键指标,而在字幕或光学字符识别(OCR)任务中,采用ROUGE-L指标来评估性能。
Grounding Evaluation Given an instructions, grounding evaluation focuses on the ability to precisely locate GUI elements. ScreenSpot (Cheng et al., 2024) evaluates single-step GUI grounding performance across multiple platforms. ScreenSpot v2 (Wu et al., 2024b), a re-annotated version, addresses annotation errors present in the original ScreenSpot. ScreenSpot Pro (Li et al., 2025) facilitates grounding evaluation by incorporating real-world tasks gathered from diverse high-resolution professional desktop environments. Metrics for grounding evaluation are usually determined based on whether the model's predicted location accurately lies within the bounding box of the target element.
基于指令的定位评估
ScreenSpot (Cheng et al., 2024) 评估了跨平台单步GUI定位性能。ScreenSpot v2 (Wu et al., 2024b) 作为重新标注的版本,解决了原版ScreenSpot中的标注错误。ScreenSpot Pro (Li et al., 2025) 通过整合来自多种高分辨率专业桌面环境的真实任务,促进了定位评估。定位评估的指标通常基于模型预测的位置是否准确位于目标元素的边界框内。
Offline Agent Capability Evaluation Offine evaluation measures the performance of GUI agents in static, pre-defined environments. Each environment typically includes an input instruction and the current state of the environment (e.g., a screenshot or a history of previous actions), requiring agents to produce the correct outputs or actions. These environments remain consistent throughout the evaluation process. Numerous offine evaluation benchmarks, including AITW (Rawles et al., 2023), Mind2Web (Deng et al., 2023), MT-Mind2Web (Deng et al., 2024), AITZ (Zhang et al., 2024e), Android Control (Li et al., 2024c), and GUI-Odyssey (Lu et al., 2024a), provide agents with a task description, a current screenshot, and previous actions history, aimed at enabling accurate prediction of the next action. These benchmarks commonly employ step-level metrics , providing fine-grained supervision of their specific behaviors. For instance, the Action-Matching Score (Rawles et al., 2023; Zhang et al., 2024e; Li et al., 2024c; Lu et al., 2024a) considers an action correct solely when both the type of action and its specific details (e.g. arguments like typed content or scroll direction) are consistent with the ground truth. Some benchmarks (Li et al., 2020a; Burns et al., 2022) demand that agents produce a series of automatically executable actions from provided instructions and screenshots. These benchmarks predominantly assess performance using task-level metrics, which determine task success by whether the output results precisely match the pre-defined labels, like the complete and partial action sequence matching accuracy (Li et al., 2020a; Burns et al., 2022; Rawles et al., 2023).
离线智能体能力评估
Online Agent Capability Evaluation Online evaluation facilitates dynamic environments, each designed as an interactive simulation that replicates real-world scenarios. In these environments, GUI agents can modify environmental states by executing actions in real time. These dynamic environments span various platforms: (1) Web: WebArena (Zhou et al., 2023) and MMInA (Zhang et al., 2024g) provide realistic web environments. (2) Desktop: OSWorld (Xie et al., 2024), Office Bench (Wang et al., 2024f), ASSISTGUI (Ga0 et al., 2023), and Windows Agent Arena (Bonatti et al., 2024) operate within real computer desktop environments. (3) Mobile: Android World (Rawles et al., 2024a), LlamaTouch (Zhang et al., 2024f), and B-MOCA (Lee et al., 2024) are built on mobile operating systems such as Android. To assess performance in online evaluation, task-level metrics are employed, providing a comprehensive measure of the agents′ effectiveness. Specifically, in the realm of online agent capability evaluation, these task-level metrics primarily determine task success based on whether an agent successfully reaches a goal state. This verification process checks whether the intended outcome achieved or if the resulting outputs precisely align with the labels (Zhou et al., 2023; Xie et al., 2024; Wang et al., 2024f; Ga0 et al., 2023).
在线智能体能力评估
在线评估促进了动态环境的发展,每个环境都设计为模拟现实场景的交互式仿真。在这些环境中,GUI 智能体可以通过实时执行操作来修改环境状态。这些动态环境涵盖多个平台:(1) 网页:WebArena (Zhou et al., 2023) 和 MMInA (Zhang et al., 2024g) 提供了真实的网页环境。(2) 桌面:OSWorld (Xie et al., 2024)、Office Bench (Wang et al., 2024f)、ASSISTGUI (Ga0 et al., 2023) 和 Windows Agent Arena (Bonatti et al., 2024) 在真实的计算机桌面环境中运行。(3) 移动设备:Android World (Rawles et al., 2024a)、LlamaTouch (Zhang et al., 2024f) 和 B-MOCA (Lee et al., 2024) 基于 Android 等移动操作系统构建。为了评估在线评估中的表现,采用了任务级指标,全面衡量智能体的有效性。具体而言,在在线智能体能力评估领域,这些任务级指标主要根据智能体是否成功达到目标状态来确定任务成功与否。该验证过程检查是否实现了预期结果,或者生成的结果是否与标签完全一致 (Zhou et al., 2023; Xie et al., 2024; Wang et al., 2024f; Ga0 et al., 2023)。
4 UI-TARS
4 UI-TARS
In this section, we introduce UI-TARS, a native GUI agent model designed to operate without reliance on cumbersome manual rules or the cascaded modules typical of conventional agent frameworks. UI-TARS directly perceives the screenshot, applies reasoning processes, and generates valid actions autonomously. Moreover, UI-TARS can learn from prior experience, iterative ly refining its performance by leveraging environment feedback.
在本节中,我们介绍 UI-TARS,这是一种原生 GUI 智能体模型,旨在无需依赖繁琐的手动规则或传统智能体框架中典型的级联模块即可运行。UI-TARS 直接感知屏幕截图,应用推理过程,并自主生成有效操作。此外,UI-TARS 可以从先前的经验中学习,通过利用环境反馈迭代地优化其性能。

Figure 4: Overview of UI-TARS. We illustrate the architecture of the model and its core capabilities.
图 4: UI-TARS 概览。我们展示了模型的架构及其核心能力。
In the following, we begin by describing the overall architecture of UI-TARS (\$ 4.1), followed by how we enhance its perception $(\S,4.2)$ and action $(\S,4.3)$ capabilities. Then we concentrate on how to infuse system-2 reasoning capabilities into UI-TARS $(\S,^{4.4})$ and iterative improvement through experience learning $(\S,4.5)$
接下来,我们首先描述 UI-TARS 的整体架构 (\$ 4.1),然后介绍如何增强其感知 (\S,4.2) 和行动 (\S,4.3) 能力。接着,我们重点讨论如何将系统-2 推理能力融入 UI-TARS (\S,^{4.4}) 以及通过经验学习进行迭代改进 (\S,4.5)。
4.1 Architecture Overview
4.1 架构概述
As illustrated in Figure 4, given an initial task instruction, UI-TARS iterative ly receives observations from the device and performs corresponding actions to accomplish the task. This sequential process can be formally expressed as:
如图 4 所示,给定初始任务指令,UI-TARS 会迭代地从设备接收观察结果并执行相应的操作以完成任务。这个顺序过程可以正式表示为:

where $o_{i}$ denotes the observation (device screenshot) at time step $i$ , and $a_{i}$ represents the action executed by the agent. At each time step, UI-TARS takes as input the task instruction, the history of prior interactions $\left(o_{1},a_{1},\cdot\cdot\cdot,,o_{i-1},a_{i-1}\right)$ , and the current observation $o_{i}$ . Based on this input, the model outputs an action $a_{i}$ from the predefined action space. After executing the action, the device provides the subsequent observation, and these processes iterative ly continue.
其中 $o_{i}$ 表示时间步 $i$ 的观察(设备截图),$a_{i}$ 表示智能体执行的动作。在每个时间步,UI-TARS 将任务指令、先前的交互历史 $\left(o_{1},a_{1},\cdot\cdot\cdot,,o_{i-1},a_{i-1}\right)$ 以及当前观察 $o_{i}$ 作为输入。基于此输入,模型从预定义的动作空间中输出一个动作 $a_{i}$。执行动作后,设备提供后续观察,这些过程会迭代进行。
To further enhance the agent's reasoning capabilities and foster more deliberate decision-making, we integrate a reasoning component in the form of “thoughts" $t_{i}$ , generated before each action $a_{i}$ . These thoughts reflect the reflective nature of “System $2^{\bullet}$ thinking. They act as a crucial intermediary step, guiding the agent to reconsider previous actions and observations before moving forward, thus ensuring that each decision is made with intentional it y and careful consideration.
为了进一步增强智能体的推理能力并促进更谨慎的决策,我们在每个动作 $a_{i}$ 之前,以“思考” $t_{i}$ 的形式集成了一个推理组件。这些思考反映了“系统 $2^{\bullet}$ 思维”的反思性质。它们作为一个关键的中介步骤,引导智能体在继续前进之前重新考虑之前的动作和观察,从而确保每个决策都是有意图且经过深思熟虑的。
This approach is inspired by the ReAct framework (Yao et al., 2023), which introduces a similar refective mechanism but in a more straightforward manner. In contrast, our integration of “thoughts"” involves a more structured, goal-oriented deliberation. These thoughts are a more explicit reasoning process that guides the agent toward better decision-making, especially in complex or ambiguous situations. The process can now be formalized as:
该方法受到了 ReAct 框架 (Yao et al., 2023) 的启发,该框架引入了一种类似的反思机制,但采用了更直接的方式。相比之下,我们对“思考”的整合涉及更结构化、以目标为导向的深思熟虑。这些思考是一个更明确的推理过程,能够引导智能体做出更好的决策,尤其是在复杂或模糊的情况下。该过程现在可以形式化为:


Figure 5: Data example of perception and grounding data
图 5: 感知与基础数据示例
these intermediate thoughts guide the model's decision-making and enable more nuanced and reflective interactions with the environment.
这些中间思考指导模型的决策,并使其能够与环境进行更细致和反思性的互动。
In order to optimize memory usage and maintain efficiency within the typically constrained token budget (e.g.,. $32\mathrm{k}$ sequence length), we limit the input to the last $N$ observations. This constraint ensures the model remains capable of handling the necessary context without overwhelming its memory capacity. The full history of previous actions and thoughts is retained as short-term memory. UI-TARS predicts the thought $t_{n}$ and action $a_{n}$ outputs iterative ly, conditioned on both the task instruction and the previous interactions:
为了优化内存使用并在通常受限的 Token 预算(例如,$32\mathrm{k}$ 序列长度)内保持效率,我们将输入限制为最后 $N$ 个观察结果。这一约束确保模型能够处理必要的上下文,而不会超出其内存容量。之前的动作和思维的完整历史被保留为短期记忆。UI-TARS 根据任务指令和之前的交互,迭代地预测思维 $t_{n}$ 和动作 $a_{n}$ 的输出:

4.2 Enhancing GUI Perception
4.2 增强 GUI 感知
Improving GUI perception presents several unique challenges: (1) Screenshot Scarcity: while large-scale general scene images are widely available, GUI-specific screenshots are relatively sparse. (2) Information Density and Precision Requirement: GUI images are inherently more information-dense and structured than general scene images, often containing hundreds of elements arranged in complex layouts. Models must not only recognize individual elements but also understand their spatial relationships and functional interactions. Moreover, many elements in GUI images are small (e.g., $10!\times!10$ pixel icons in a $1920!\times!1080$ image), making it difficult to perceive and localize these elements accurately. Unlike traditional frameworks that rely on separate, modular perception models, native agents overcome these challenges by directly processing raw input from GUI screenshots. This approach enables them to scale better by leveraging large-scale, unified datasets, thereby addressing the unique challenges of GUI perception with greater efficiency.
提升 GUI (Graphical User Interface) 感知面临几个独特的挑战:(1) 截图稀缺性:虽然大规模的通用场景图像广泛可用,但 GUI 相关的截图相对稀少。(2) 信息密度与精度要求:GUI 图像本质上比通用场景图像更具信息密度和结构性,通常包含数百个元素,排列在复杂的布局中。模型不仅需要识别单个元素,还需要理解它们的空间关系和功能交互。此外,GUI 图像中的许多元素很小 (例如,在 $1920!\times!1080$ 图像中的 $10!\times!10$ 像素图标),这使得准确感知和定位这些元素变得困难。与依赖独立模块化感知模型的传统框架不同,原生 AI 智能体通过直接处理 GUI 截图的原始输入来克服这些挑战。这种方法使它们能够通过利用大规模的统一数据集更好地扩展,从而更高效地应对 GUI 感知的独特挑战。
Screenshot Collection To address data scarcity and ensure diverse coverage, we built a large-scale dataset comprising screenshots and metadata from websites, apps, and operating systems. Using specialized parsing tools, we automatically extracted rich metadata—such as element type, depth, bounding box, and text content for each element—-while rendering the screenshots. Our approach combined automated crawling and humanassisted exploration to capture a wide range of content. We included primary interfaces as well as deeper, nested pages accessed through repeated interactions. All data was logged in a structured format-—-(screenshot, element box, element metadata)—-to provide comprehensive coverage of diverse interface designs.
截图收集
We adopt a bottom-up data construction approach, starting from individual elements and progressing to holistic interface understanding. By focusing on small, localized parts of the GUI before integrating them into the broader context, this approach minimizes errors while balancing precision in recognizing components with the ability to interpret complex layouts. Based on the collected screenshot data, we curated five core task data (Figure5):
我们采用自下而上的数据构建方法,从单个元素开始,逐步推进到整体界面理解。通过先关注 GUI 的局部小部分,再将它们整合到更广泛的上下文中,这种方法在识别组件的精确性与解释复杂布局的能力之间取得了平衡,同时最大限度地减少了错误。基于收集的截图数据,我们整理了五项核心任务数据 (图5):
Element Description To enhance recognizing and understanding specific elements within a GUI, particularly tiny elements, we focus on creating detailed and structured descriptions for each element. Such descriptions are based on metadata extracted using parsing tools and further synthesized by a VLM, covering four aspects: (1) Element Type (e.g., windows control types): we classify elements (e.g., buttons, text fields, scrollbars) based on visual cues and system information; (2) Visual Description, which describes the element's appearance, including its shape, color, text content, and style, derived directly from the image; (3) Position Information: we describe the spatial position of each element relative to others; (4) Element Function, which describes the element's intended functionality and possible ways of interactions. We train UI-TARS to enumerate all visible elements within a screenshot and generate their element descriptions, conditioned on the screenshot.
元素描述
Dense Captioning We train UI-TARS to understand the entire interface while maintaining accuracy and minimizing hallucinations. The goal of dense captioning is to provide a comprehensive, detailed description of the GUI screenshot, capturing not only the elements themselves but also their spatial relationships and the overall layout of the interface. For each recorded element in the screenshot, we first obtain their element descriptions. For embedded images, which often lack detailed metadata, we also generate their descriptive captions. After that, we integrate all the image and element descriptions into a cohesive, highly detailed caption that preserves the structure of the GUI layout using a VLM. During training, UI-TARS is given only the image and tasked with outputting the corresponding dense caption.
密集标注
我们训练 UI-TARS 在保持准确性和最小化幻觉的同时理解整个界面。密集标注的目标是提供 GUI 截图的全面、详细描述,不仅捕捉元素本身,还包括它们的空间关系以及界面的整体布局。对于截图中记录的每个元素,我们首先获取它们的元素描述。对于通常缺乏详细元数据的嵌入图像,我们也生成它们的描述性标注。之后,我们使用 VLM 将所有图像和元素描述整合成一个连贯、高度详细的标注,保留 GUI 布局的结构。在训练过程中,UI-TARS 仅提供图像,并负责输出相应的密集标注。
State Transition Captioning While dense captioning provides a comprehensive description of a GUI interface, it does not capture state transitions, particularly the subtle effects of actions (e.g., a tiny button being pressed) on the interface. To address this limitation, we train the model to identify and describe the differences between two consecutive screenshots and determine whether an action, such as a mouse click or keyboard input, has occurred. We also incorporate screenshot pairs that correspond to non-interactive UI changes (e.g.. animations, screen refreshes, or background updates). During training, UI-TARS is presented with a pair of images and tasked with predicting the specific visual changes (and possible reasons) of the two images. In this way, UI-TARS learns the subtle UI changes, including both user-initiated actions and non-interactive transitions. This capability is crucial for tasks requiring fine-grained interaction understanding and dynamic state perception.
状态转换描述
Question Answering (QA) While dense captioning and element descriptions primarily focus on understanding the layout and elements of a GUI, QA offers a more dynamic and fexible approach to integrating these tasks with reasoning capabilities. We synthesize a diverse set of QA data that spans a broad range of tasks, including interface comprehension, image interpretation, element identification, and relational reasoning. This enhances UI-TARS's capacity to process queries that involve a higher degree of abstraction or reasoning.
问答 (QA)
Set-of-Mark (SoM) We also enhance the Set-of-Mark (SoM) prompting ability (Yang et al., 2023b) of UI-TARS. We draw visually distinct markers for parsed elements on the GUI screenshot based on their spatial coordinates. These markers vary in attributes such as form, color, and size, providing clear, intuitive visual cues for the model to locate and identify specific elements. In this way, UI-TARS better associates visual markers with their corresponding elements. We integrate SoM annotations with tasks like dense captioning and QA. For example, the model might be trained to describe an element highlighted by a marker.
Set-of-Mark (SoM)
4.3 Unified Action Modeling and Grounding
4.3 统一的动作建模与落地
The de-facto approach for improving action capabilities involves training the model to mimic human behaviors in task execution, i.e., behavior cloning (Bain & Sammut, 1995). While individual actions are discrete and isolated, real-world agent tasks inherently involve executing a sequence of actions, making it essential to train the model on multi-step trajectories. This approach allows the model to learn not only how to perform individual actions but also how to sequence them effectively (system-1 thinking).
提升行动能力的实际方法包括训练模型模仿人类执行任务的行为,即行为克隆 (Bain & Sammut, 1995)。尽管单个动作是离散且孤立的,但现实世界中的智能体任务本质上涉及执行一系列动作,因此有必要在多步轨迹上训练模型。这种方法使模型不仅能够学习如何执行单个动作,还能学习如何有效地将它们排序(系统-1思维)。
Unified Action Space Similar to previous works, we design a common action space that standardizes semantically equivalent actions across devices (Table 1), such as “click" on Windows versus “"tap" on mobile, enabling knowledge transfer across platforms. Due to device-specific differences, we also introduce optional actions tailored to each platform. This ensures the model can handle the unique requirements of each device while maintaining consistency across scenarios. We also define two terminal actions: Fini shed () , indicating task completion, and Ca11User () , invoked in cases requiring user intervention, such as login or authentication.
统一动作空间
与之前的工作类似,我们设计了一个通用的动作空间,标准化了跨设备的语义等效动作(表 1),例如 Windows 上的“click”与移动设备上的“tap”,从而实现跨平台的知识迁移。由于设备间的差异,我们还引入了针对每个平台的可选动作。这确保了模型能够处理每个设备的独特需求,同时保持跨场景的一致性。我们还定义了两个终止动作:Finished (),表示任务完成,以及 CallUser (),在需要用户干预的情况下调用,例如登录或身份验证。
Table 1: Unified action space for different platforms
表 1: 不同平台的统一动作空间
| 环境 | 动作 | 定义 |
|---|---|---|
| 共享 | Click(x,y) | 在坐标 (x,y) 处点击。 |
| Drag(x1,y1,x2,y2) | 从 (x1, y1) 拖动到 (x2, y2)。 | |
| Scroll(x,y,direction) | 在 (x,y) 处按给定方向滚动。 | |
| Type(content) | 输入指定内容。 | |
| WaitO | 暂停片刻。 | |
| FinishedO | 标记任务完成。 | |
| 桌面 | CallUserO | 请求用户干预。 |
| Hotkey(key) | 按下指定的快捷键。 | |
| LeftDouble(x,y) | 在 (x,y) 处双击。 | |
| RightSingle(x, y) | 在 (x,y) 处右击。 | |
| 移动 | LongPress(x, y) | 在 (x, y) 处长按。 |
| PressBackO | 按下“返回”按钮。 | |
| PressHomeO | 按下“主页”按钮。 | |
| PressEnterO) | 按下“回车”键。 |
| 数据类型 | 基础数据 (Grounding) | 多步骤 (MultiStep) |
|---|---|---|
| 元素 (Ele.) | 元素/图像 (Ele./lmage) | |
| 开源 (OpenSource) | Web | 14.8M |
| Mobile | 2.5M | |
| Desktop | 1.1M | |
| 我们的 (Ours) | * |
Action Trace Collection A significant challenge in training models for task execution lies in the limited availability of multi-step trajectory data, which has historically been under-recorded and sparse. To address this issue, we rely on two primary data sources: (1) our annotated dataset: we develop a specialized annotation tool to capture user actions across various software and websites within PC environments. The annotation process begins with the creation of initial task instructions, which are reviewed and refined by annotators to ensure clarity and alignment with the intended goals. Annotators then execute the tasks, ensuring that their actions fulfill the specified requirements. Each task undergoes rigorous quality filtering; and (2) open-source data: we also integrate multiple existing datasets (MM-Mind2Web (Zheng et al., 2024b), GUIAct (Chen et al., 2024c), AITW (Rawles et al., 2023), AITZ (Zhang et al., 2024d), Android Control (Li et al., 2024c), GUI-Odyssey (Lu et al., 2024a), AMEX (Chai et al., 2024)) and standardize them into a unified action space format. This involves reconciling varying action representations into a consistent template, allowing for seamless integration with the annotated data. In Table 2, we list the basic statistics of our action trace data.
动作轨迹收集
Improving Grounding Ability Grounding, the ability to accurately locate and interact with specific GUI elements, is critical for actions like clicking or dragging. Unlike multi-step action data, grounding data is easier to scale because it primarily relies on the visual and position properties of elements, which can be efficiently synthesized or extracted (Hong et al., 2024; Gou et al., 2024a; Wu et al., 2024b). We train UI-TARS to directly predict the coordinates of the elements it needs to interact with. This involves associating each element in a GUI with its spatial coordinates and metadata.
提升定位能力
定位,即准确找到并与其交互的能力,对于点击或拖动等操作至关重要。与多步操作数据不同,定位数据更容易扩展,因为它主要依赖于元素的视觉和位置属性,这些属性可以高效地合成或提取 (Hong et al., 2024; Gou et al., 2024a; Wu et al., 2024b)。我们训练 UI-TARS 直接预测其需要交互的元素的坐标。这涉及将 GUI 中的每个元素与其空间坐标和元数据关联起来。
As described in $\S\ 4.2$ , we collected screenshots and extracted metadata, including element type, depth, bounding boxes, and text content, using specialized parsing tools. For elements recorded with bounding boxes, we calculated the average of the corners to derive a single point coordinate, representing the center of the bounding box. To construct training samples, each screenshot is paired with individual element descriptions derived from metadata. The model is tasked with outputting relative coordinates normalized to the dimensions of the screen, ensuring consistency across devices with varying resolutions. For example, given the description "red button in the top-right corner labeled Submit", the model predicts the normalized coordinates of that button. This direct mapping between descriptions and coordinates enhances the model's ability to understand and ground visual elements accurately.
如 $\S\ 4.2$ 所述,我们收集了截图并使用专门的解析工具提取了元数据,包括元素类型、深度、边界框和文本内容。对于记录有边界框的元素,我们计算了角点的平均值以得出一个单点坐标,代表边界框的中心。为了构建训练样本,每个截图都与从元数据中提取的单个元素描述配对。模型的任务是输出归一化到屏幕尺寸的相对坐标,确保在不同分辨率的设备上保持一致。例如,给定描述“右上角标记为提交的红色按钮”,模型预测该按钮的归一化坐标。这种描述与坐标之间的直接映射增强了模型准确理解和定位视觉元素的能力。
To further augment our dataset, we integrated open-source data (Seeclick (Cheng et al., 2024), GUIAct (Chen et al., 2024c), MultiUI (Liu et al., 2024b), Rico-SCA (Li et al., 2020a), Widget Caption (Li et al., 2020b), MUG (Li et al., 2024b), Rico Icon (Sunkara et al., 2022), CLAY (Li et al., 2022), UIBERT (Bai et al., 2021), OmniACT (Kapoor et al., 2024), AutoGUI (Anonymous, 2024), OS-ATLAS (Wu et al., 2024b) and standardized them into our unified action space format. We provide the basic statiscs of the grounding data for training in Table 2. This combined dataset enables UI-TARS to achieve high-precision grounding, significantly improving its effectiveness in actions such as clicking and dragging.
为了进一步增强我们的数据集,我们整合了开源数据 (Seeclick (Cheng et al., 2024), GUIAct (Chen et al., 2024c), MultiUI (Liu et al., 2024b), Rico-SCA (Li et al., 2020a), Widget Caption (Li et al., 2020b), MUG (Li et al., 2024b), Rico Icon (Sunkara et al., 2022), CLAY (Li et al., 2022), UIBERT (Bai et al., 2021), OmniACT (Kapoor et al., 2024), AutoGUI (Anonymous, 2024), OS-ATLAS (Wu et al., 2024b) ) 并将其标准化为我们的统一动作空间格式。我们提供了用于训练的接地数据的基本统计数据,如表 2 所示。这个组合数据集使 UI-TARS 能够实现高精度的接地,显著提高了其在点击和拖动等动作中的有效性。
4.4 Infusing System-2 Reasoning
4.4 注入系统2推理
Relying solely on system-1 intuitive decision-making is insufficient to handle complex scenarios and everchanging environments. Therefore, we aim for UI-TARS to combine system-2 level reasoning, fexibly planning action steps by understanding the global structure of tasks.
仅依赖系统1的直觉决策不足以应对复杂场景和多变的环境。因此,我们希望UI-TARS能够结合系统2的推理能力,通过理解任务的全局结构灵活规划行动步骤。
Reasoning Enrichment with GUI Tutorials The first step focuses on reasoning enrichment, where we leverage publicly available tutorials that interweave text and images to demonstrate detailed user interactions across diverse software and web environments. These tutorials provide an ideal source for establishing foundational GUI knowledge while introducing logical reasoning patterns inherent to task execution.
推理增强与GUI教程
第一步侧重于推理增强,我们利用公开的教程,这些教程将文本和图像交织在一起,展示跨不同软件和网络环境中的详细用户交互。这些教程为建立基础GUI知识并引入任务执行中固有的逻辑推理模式提供了理想的来源。
We selected MINT (Awadalla et al., 2024) and OmniCorpus (Li et al., 2024a), two widely recognized imagetext interleaved pre-training datasets, as our initial data sources. However, these datasets contain substantial noise, with only a small fraction aligning with GUI tutorial criteria. To extract high-quality tutorial data, we implemented a multi-stage data collection and filtering pipeline: (1) Coarse-Grained Filtering: to isolate tutorial-like content, we trained a fastText classifier (Joulin et al., 2016) using a manually curated positive set of high-quality tutorials and random samples from MINT and OmniCorpus as the negative set. The trained classifier was then applied to perform an initial screening, filtering out irrelevant samples and generating a candidate dataset. (2) Fine-Grained Filtering: to further refine the candidate dataset, we employed an LLM to identify and remove false positives. This step ensured the remaining samples conformed to the characteristics of GUI tutorials. The coarse and fine filtering processes were iterated over multiple rounds to maximize the recall rate of high-quality GUI tutorials. (3) De duplication and Data Refinement: the filtered dataset was further refined to address duplicates, advertisements, and residual noise. De duplication was performed using URL-based and Locality-Sensitive Hashing (LSH) methods. Finally, we prompt an LLM to rephrase all the textual content in the tutorial, refining the content while eliminating irrelevant or low-quality ones.
我们选择了 MINT (Awadalla et al., 2024) 和 OmniCorpus (Li et al., 2024a) 这两个广泛认可的图文交错预训练数据集作为初始数据源。然而,这些数据集中存在大量噪声,只有一小部分符合 GUI 教程的标准。为了提取高质量的教程数据,我们实施了一个多阶段的数据收集和过滤流程:(1) 粗粒度过滤:为了分离出类似教程的内容,我们使用手动整理的高质量教程正样本集和来自 MINT 和 OmniCorpus 的随机样本作为负样本集,训练了一个 fastText 分类器 (Joulin et al., 2016)。训练好的分类器用于进行初步筛选,过滤掉不相关的样本并生成候选数据集。(2) 细粒度过滤:为了进一步优化候选数据集,我们使用大语言模型来识别和去除误报。这一步骤确保剩余的样本符合 GUI 教程的特征。粗粒度和细粒度过滤过程经过多轮迭代,以最大化高质量 GUI 教程的召回率。(3) 去重和数据优化:过滤后的数据集进一步优化以解决重复、广告和残留噪声问题。去重使用基于 URL 和局部敏感哈希 (LSH) 的方法进行。最后,我们提示大语言模型重新表述教程中的所有文本内容,优化内容的同时消除不相关或低质量的部分。
Through this multi-stage process, we curated approximately 6M high-quality GUI tutorials. On average, each tutorial contains 510 text tokens and 3.3 images. This data not only enhances the model's understanding of GUI operations but also lays a robust foundation for infusing reasoning capabilities.
通过这一多阶段过程,我们筛选出了大约 600 万份高质量的 GUI 教程。平均而言,每个教程包含 510 个文本 Token 和 3.3 张图片。这些数据不仅增强了模型对 GUI 操作的理解,还为注入推理能力奠定了坚实的基础。
Reasoning Stimulation with Thought Augmentation The action trace data we collect in $\S\ 4.3$ is inherently action-focused, containing sequences of observations and actions $(o_{i-1},a_{i-1},o_{i},a_{i},\ldots)$ but lacking explicit reasoning thoughts. To stimulate reasoning capabilities of UI-TARS, we augment the dataset by annotating “thoughts" to bridge the gap between perception and action. This transforms the data format to $\left(o_{i-1},t_{i-1},a_{i-1},o_{i},t_{i},a_{i},\ldots\right)$ ,where $t$ represents the reasoning thought. These thoughts enable the model to express its decision-making process explicitly, fostering better alignment with task objectives. To construct these thoughts, we employ two annotation stages:
通过思维增强激发推理能力
(1) ActRe (Yang et al., 2024b): as shown in (4), for each trace collected in $\S\ 4.3$ , we split them into multiple steps. For each step $n$ ,its thought $t_{n}$ is generated iterative ly by prompting a VLM with the previous context and the current target action $a_{n}$ . This method tries to make the generated thought logically grounded in the preceding context and aligned with the current action.
ActRe (Yang et al., 2024b): 如 (4) 所示,对于在 $\S\ 4.3$ 中收集的每条轨迹,我们将其分割为多个步骤。对于每个步骤 $n$,其思考 $t_{n}$ 是通过提示 VLM 生成,迭代地基于前文和当前目标动作 $a_{n}$。该方法试图使生成的思考在逻辑上基于前文,并与当前动作保持一致。

During ActRe annotation, we prompt the VLM toward exhibiting higher-order, system-2 reasoning, which involves deliberate, step-by-step decision-making and reflection. By promoting these reasoning patterns, we encourage the model to engage in thoughtful, long-term planning and reflection to solve complex tasks. As shown in Figure 6, the reasoning patterns we prompt the VLM to follow include:
在 ActRe 标注过程中,我们引导 VLM 展现出更高阶的系统 2 推理,这涉及有意识的、逐步的决策和反思。通过促进这些推理模式,我们鼓励模型进行深思熟虑的长期规划和反思,以解决复杂任务。如图 6 所示,我们引导 VLM 遵循的推理模式包括:
(2) Thought Boots trapping: reverse annotation of thoughts conditioned on ground-truth actions (i.e., ActRe) can lead to false positives because the generated thoughts may appear to match the corresponding actions at a superficial level, without establishing a true causal relationship. Specifically, the reasoning process underlying the action may be overlooked, causing the thought to align with the action only by coincidence rather than through logical reasoning. This issue arises because the annotation process relies on knowing the action in advance, which may bias the thought to conform to the action rather than refect the actual decision-making process leading to it.
(2) 思维引导:基于真实动作的反向注释(即 ActRe)可能导致误报,因为生成的思维可能在表面上与相应动作匹配,但并未建立真正的因果关系。具体来说,动作背后的推理过程可能被忽视,导致思维只是偶然与动作一致,而非通过逻辑推理。这一问题之所以出现,是因为注释过程依赖于预先知道动作,这可能会使思维偏向于符合动作,而未能反映实际导致该动作的决策过程。

Figure 6: Various reasoning patterns in our augmented thought
图 6: 我们增强思维中的各种推理模式
To address this, we adopt a boots trapping approach that generates thoughts without prior knowledge of the ground-truth action. By sampling multiple thought-action pairs, as shown in (5), we identify the thought that leads to the correct action, ensuring that the reasoning aligns causally with the chosen action. This approach produces higher-quality annotations because it forces the model to simulate a genuine decision-making process rather than merely justifying a pre-determined action (UI-TARSearly means an early-stage model checkpoint).
为了解决这个问题,我们采用了一种自举方法,该方法在没有先验知识的情况下生成思考。通过采样多个思考-动作对,如(5)所示,我们确定导致正确动作的思考,确保推理与所选动作在因果上保持一致。这种方法产生更高质量的标注,因为它迫使模型模拟一个真实的决策过程,而不仅仅是为预先确定的动作辩护(UI-TARSearly 表示早期模型检查点)。

We annotate thoughts in both Chinese and English, expanding linguistic diversity. Although we augment thoughts for all traces, we also involve the vanilla action traces (without thought) during training.

Figure 7: Overview of the online boots trapping process.
图 7: 在线引导过程的概述。
4.5 Learning from Prior Experience in Long-term Memory
4.5 从长期记忆的先前经验中学习
GUI agents face significant challenges in scaling to the level of LLMs, primarily due to the scarcity of large-scale, standardized, real-world process data for GUI operations. While LLMs can leverage abundant textual data that captures diverse knowledge and reasoning patterns, process data detailing user interactions and decision-making sequences within GUI environments is rarely recorded or systematically organized. This lack of data impedes the ability of GUI agents to scale effectively and generalize across a wide range of tasks. One promising solution lies in learning from prior experiences stored in long-term memory. By capturing and retaining knowledge from previous tasks, agents can leverage these past experiences to inform their future decisions, making their actions more adaptive and efficient.
GUI智能体在扩展到大语言模型水平时面临重大挑战,主要原因是缺乏大规模、标准化、真实的GUI操作流程数据。尽管大语言模型可以利用丰富的文本数据,这些数据捕捉了多样化的知识和推理模式,但记录GUI环境中用户交互和决策序列的流程数据却很少被记录或系统化组织。这种数据不足阻碍了GUI智能体有效扩展和泛化到广泛任务的能力。一个潜在的解决方案是从长期记忆中存储的先前经验中学习。通过捕捉和保留先前任务中的知识,智能体可以利用这些过去的经验来指导未来的决策,使其行动更加自适应和高效。
To facilitate this process, we enable UI-TARS to dynamically learn from interactions with real-world devices. Through semi-automated data collection, filtering, and refinement, the model continuously improves while minimizing the need for manual intervention. By leveraging long-term memory, UI-TARS builds on its accumulated knowledge, refining its performance over time and adapting to new tasks more effciently. Each iteration of this process results in a more capable model.
为了促进这一过程,我们使 UI-TARS 能够从与现实世界设备的交互中动态学习。通过半自动化的数据收集、过滤和精炼,模型在不断改进的同时,最大限度地减少人工干预的需求。通过利用长期记忆,UI-TARS 在其积累的知识基础上,逐步优化其性能,并更高效地适应新任务。每次迭代都会使模型变得更强大。
Online Trace Boots trapping As shown in Figure 7, we begin by obtaining a diverse set of task goals, combining both human-annotated and model-generated instructions. At iteration $n$ .the agent $M_{n}$ executes these instructions ${\mathcal{Z}}_{n}$ within the target GUI environments (e.g., a virtual PC), producing a raw set of traces:
在线轨迹自举
如图 7 所示,我们首先获得一组多样化的任务目标,结合人工标注和模型生成的指令。在第 $n$ 次迭代中,智能体 $M_{n}$ 在目标 GUI 环境(例如虚拟 PC)中执行这些指令 ${\mathcal{Z}}_{n}$,生成一组原始轨迹:

To ensure high-quality data, we apply a multi-level filtering function:
为确保高质量数据,我们应用了多级过滤功能:

which discards noisy or invalid traces through the following steps: (1) Rule-Based Reward: heuristic rules remove traces with obvious anomalies (e.g., redundant actions that do not alter the environment); (2) VLM Scoring: VLMs assign quality scores to the remaining traces, with traces scoring below a predefined threshold being removed; (3) Human Review: part of the traces are further inspected by annotators, who identify the step where an error occurs, discard any subsequent actions, and retain only the valid prefix. UI-TARS leverages the resulting filtered trace set $\tau_{\mathrm{filtered},n}$ for self-improvement:

For each round, we employ annotators to refine or expand the instruction set:

We iterate the above process on hundreds of virtual PCs for multiple rounds, continuously leveraging the latest model $M_{n+1}$ to generate new traces, thus expanding and refining the data.
Refection Tuning_ In realistic online deployments, agents often encounter situations where they get stuck due to a lack of self-reflection and error correction capabilities. For example, an agent might repeatedly click on an unresponsive button or attempt invalid operations due to misinterpretation of the interface. Without the ability to recognize these errors or adjust its strategy, the agent remains in a loop of ineffective actions, unable to progress toward the task objective. However, most offline datasets contain idealized, error-free trajectories because annotators ensure that each action meets expectations during the data labeling process. While such data helps reduce noise during model training, it also prevents the agent from learning how to recover from errors. To address this limitation, we propose a reflection tuning protocol that exposes the model to real-world errors made by itself with their corrections, enabling UI-TARS to learn how to recover from suboptimal decisions.
反思调优:在现实的在线部署中,AI智能体经常会因为缺乏自我反思和错误纠正能力而陷入困境。例如,AI智能体可能会反复点击一个无响应的按钮,或者由于对界面的误解而尝试无效操作。如果无法识别这些错误或调整其策略,AI智能体将陷入无效操作的循环中,无法朝着任务目标前进。然而,大多数离线数据集包含理想的、无错误的轨迹,因为标注者在数据标注过程中确保每个操作都符合预期。虽然这些数据有助于减少模型训练期间的噪声,但也阻碍了AI智能体学习如何从错误中恢复。为了解决这一限制,我们提出了一种反思调优协议,将模型暴露于其自身在现实世界中犯的错误及其纠正措施,使UI-TARS能够学习如何从次优决策中恢复。
For an online trace generated by UI-TARS: $\tau=$ (instruction, $\left(o_{1},t_{1},a_{1}\right),\left(o_{2},t_{2},a_{2}\right),\ldots,\left(o_{t},t_{t},a_{t}\right)\right)$ suppose that an error occurs at step $\tau$ , where the action $a_{\tau}$ is deemed invalid or suboptimal. We asked annotators to identify this error and label the corrected thought and action $t_{\tau}^{},a_{\tau}^{}$ . This results in an error correction trace pair:

Innovative ly, we further require annotators to continue labeling the subsequent step based on the incorrect action $a_{\tau}$ , simulating a scenario where the error has already occurred. When determining the thought for the nextstep $t_{\tau+1}^{}$ , annotators must acknowledge the impact of the previous mistake, compensate for its effects, and provide a correct action $a_{\tau+1}^{}$ to realign the task progress. For example, if the previous step intended to add a webpage to bookmarks but mistakenly clicked the close button, the next step should involve reopening the recently closed webpage to re-attempt clicking the bookmark button. Formally, we have a post-reflection trace pair:
创新地,我们进一步要求标注者基于错误动作 $a_{\tau}$ 继续标注后续步骤,模拟错误已经发生的情景。在确定下一步的思考 $t_{\tau+1}^{}$ 时,标注者必须承认前一个错误的影响,补偿其效果,并提供正确的动作 $a_{\tau+1}^{}$ 以重新调整任务进度。例如,如果前一步骤意图将网页添加到书签但不小心点击了关闭按钮,下一步应涉及重新打开最近关闭的网页以重新尝试点击书签按钮。形式上,我们有一个后反思轨迹对:
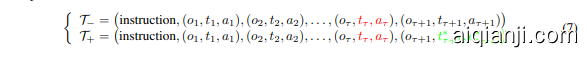
We utilize the positive samples $\mathcal{T}{+}$ for SFT training and calculate the loss only for the corrected steps (i.e., $(t{\tau}^{},a_{\tau}^{})$ and $(t_{\tau+1}^{},a_{\tau+1}^{}))$ , while the error steps (i.e., $(t_{\tau},a_{\tau}))$ are not considered for training. Through this process, UI-TARS gradually improves its ability to recognize and recover from errors, enabling it to make effective adjustments when faced with imperfect or uncertain conditions. Cultivating this refective ability enhances the agent's adaptability to dynamic environments and tasks.
Agent DPO _ During online boots trapping, a large number of erroneous steps (negative examples) are naturally generated. However, SFT only utilizes the corrected steps (i.e., “positive” examples), while ignoring the negative samples, which limits its ability to explicitly guide the agent away from suboptimal actions. To address this limitation, we turn to Direct Preference Optimization (DPO) (Rafailov et al., 2023), which leverages both the corrected and erroneous actions by introducing a reference-based objective. This approach optimizes UI-TARS by directly encoding a preference for corrected actions over erroneous ones, thereby making better use of the available data.
Agent DPO _ 在线引导训练过程中,会自然生成大量错误步骤(负面示例)。然而,SFT(监督微调)仅利用修正后的步骤(即“正面”示例),而忽略了负面样本,这限制了其明确引导智能体远离次优行为的能力。为了解决这一限制,我们转向直接偏好优化(Direct Preference Optimization,DPO) (Rafailov et al., 2023),该方法通过引入基于参考的目标,同时利用修正和错误行为。这种方法通过直接编码对修正行为优于错误行为的偏好来优化UI-TARS,从而更好地利用可用数据。
Consider a state $s_{\tau}$ where the agent initially performed an incorrect action $a_{\tau}$ , which was later corrected to a preferred action $a_{\tau}^{\prime}$ . Here, the state $s_{\tau}$ consists of the instruction and its interaction history up to the current step $\left(o_{1},t_{1},a_{1},\ldots,o_{\tau-1},t_{\tau-1},a_{\tau-1}\right)$ . This comprehensive representation provides the necessary context for the agent to make informed decisions. The key idea is to define a preference likelihood that quantifies how much the model favors the corrected action $a_{\tau}^{\prime}$ over the original action $a_{\tau}$ . Formally, we define a learned reward function $r_{\theta}(s,a)$ that estimates the desirability of taking action $a$ in state $s$ . Based on Bradley-Terry model (Bradley & Terry, 1952), we can express the pairwise preference likelihood as:
考虑一个状态 $s_{\tau}$,其中智能体最初执行了一个错误的动作 $a_{\tau}$,随后被纠正为更优的动作 $a_{\tau}^{\prime}$。这里,状态 $s_{\tau}$ 由指令及其到当前步骤的交互历史组成 $\left(o_{1},t_{1},a_{1},\ldots,o_{\tau-1},t_{\tau-1},a_{\tau-1}\right)$。这种全面的表示为智能体提供了做出明智决策所需的上下文。关键思想是定义一个偏好似然,量化模型对纠正动作 $a_{\tau}^{\prime}$ 相对于原始动作 $a_{\tau}$ 的偏好程度。形式上,我们定义了一个学习的奖励函数 $r_{\theta}(s,a)$,用于估计在状态 $s$ 中采取动作 $a$ 的合意性。基于 Bradley-Terry 模型 (Bradley & Terry, 1952),我们可以将成对偏好似然表示为:

where $a_{\tau}^{\prime}\succ a_{\tau}$ indicates that $a_{\tau}^{\prime}$ is preferred over $a_{\tau}$ . The numerator represents the exponential of the reward assigned to the corrected action, while the denominator sums the exponentials of the rewards for both actions, ensuring that the likelihood is properly normalized.
其中 $a_{\tau}^{\prime}\succ a_{\tau}$ 表示 $a_{\tau}^{\prime}$ 优于 $a_{\tau}$。分子表示分配给正确动作的奖励的指数值,而分母则是两个动作奖励的指数和,确保概率得到适当的归一化。
DPO derives the analytical optimal policy given the reward function from the reinforcement learning (RL) objective with a KL-divergence constraint. We follow DPO to replace the reward function $r_{\theta}$ with the optimal
DPO 从带有 KL 散度约束的强化学习 (RL) 目标中推导出给定奖励函数的解析最优策略。我们遵循 DPO,将奖励函数 $r_{\theta}$ 替换为最优策略。
policy and directly optimize the DPO objective on the preference dataset:
策略:直接在偏好数据集上优化DPO目标。
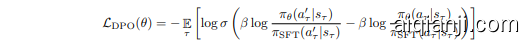
where $\tau$ goes over all timesteps for which error-correction pairs are available. $\pi_{\theta}$ denotes the optimal agent, $\boldsymbol{\pi}_{\mathrm{SFT}}$ denotes the SFT agent and $\beta$ as a hyper-parameter controls the divergence between the optimal agent and the SFT agent. By minimizing the DPO loss, we fit the agent to increase the likelihood of the corrected actions and decrease the likelihood of the erroneous actions with an implicit reward function.
其中,$\tau$ 遍历所有可获得纠错对的时间步。$\pi_{\theta}$ 表示最优智能体,$\boldsymbol{\pi}_{\mathrm{SFT}}$ 表示 SFT 智能体,$\beta$ 作为超参数控制最优智能体与 SFT 智能体之间的差异。通过最小化 DPO 损失,我们拟合智能体以增加纠正动作的可能性,并通过隐式奖励函数减少错误动作的可能性。
4.6 Training
4.6 训练
To ensure a fair comparison with existing works such as Aguvis (Xu et al., 2024) and OS-Atlas (Wu et al., 2024b), we use the same VLM backbone, Qwen-2-VL (Wang et al., 2024c), and adopt a three-phase training process. This process refines the model's capabilities across diverse GUI tasks, utilizing a total data size of approximately 50B tokens. Each phase progressively incorporates higher-quality data to enhance the model's performance on complex reasoning tasks.
为确保与现有工作如Aguvis (Xu等, 2024)和OS-Atlas (Wu等, 2024b)进行公平比较,我们使用相同的VLM骨干网络Qwen-2-VL (Wang等, 2024c),并采用三阶段训练过程。该过程利用总计约50B的Token数据量,在不同GUI任务中逐步提升模型能力。每个阶段逐步引入更高质量的数据,以增强模型在复杂推理任务上的表现。
· Continual Pre-training Phase: we utilize the full set of data described in $\S\ 4$ excluding the reflection tuning data, for continual pre-training with a constant learning rate. This foundational phase allows the model to learn all the necessary knowledge for automated GUI interaction, including perception, grounding, and action traces, ensuring robust coverage across diverse GUI elements and interactions.
· 持续预训练阶段:我们利用$\S\ 4$中描述的全部数据集(不包括反射调优数据)进行持续预训练,并保持恒定学习率。这一基础阶段使模型能够学习自动化GUI交互所需的所有知识,包括感知、定位和动作轨迹,确保在不同GUI元素和交互中的全面覆盖。
· Annealing Phase: we then select high-quality subsets of perception, grounding, action trace, reflection tuning data for annealing. The annealing process gradually adjusts the model's learning dynamics, promoting more focused learning and better optimization of its decision-making strategies in real-world GUI interaction scenarios. We denote the model trained after this phase as UI-TARS-SFT.
· 退火阶段:然后我们选择高质量的感知、接地、动作追踪和反思调优数据子集进行退火。退火过程逐步调整模型的学习动态,促进更专注的学习,并优化其在现实世界图形用户界面 (GUI) 交互场景中的决策策略。我们将此阶段训练后的模型称为 UI-TARS-SFT。
· DPO Phase: finally, we employ annotated reflective pairs from online boots trapping data for DPO training. During this process, the model refines its decision-making, reinforcing optimal actions while penalizing suboptimal ones. This process improves the model's ability to make precise, context-aware decisions in real-world GUI interactions. The final model is denoted as UI-TARS-DPO.
DPO 阶段:最后,我们使用来自在线自举数据的标注反射对进行 DPO 训练。在此过程中,模型优化其决策,强化最优行动同时惩罚次优行动。这一过程提升了模型在现实世界 GUI 交互中做出精确、上下文感知决策的能力。最终模型被表示为 UI-TARS-DPO。
5 Experiment
5 实验
In this section, we evaluate the performance of UI-TARS, trained on the dataset described in $\S\ 4$ consisting of approximately 50B tokens. We choose Qwen-2-VL (Wang et al., 2024c) as the base model for training and developed three model variants: UI-TARS-2B, UI-TARS-7B and UI-TARS-72B. Extensive experiments are conducted to validate the advantages of the proposed models. These experiments are designed to assess the models? capabilities in three critical dimensions: perception, grounding, and agent capabilities. Finally, we perform an ablation study to further investigate the impact of system 1 and system 2 reasoning on downstream tasks.Wesetthe $N$ in Eq. 3 to 5 throughout this section. We evaluate both UI-TARS-SFT and UI-TARS-DPO for OsWorld in $\S\ 5.4$ , as this benchmark benefits most from the iterative improvement from the DPO phase. For other benchmarks, however, we report the model trained after the annealing phase (i.e., UI-TARS-SFT).
在本节中,我们评估了 UI-TARS 的性能,该模型在 $\S\ 4$ 中描述的包含约 500 亿个 Token 的数据集上进行了训练。我们选择 Qwen-2-VL (Wang et al., 2024c) 作为基础模型进行训练,并开发了三个模型变体:UI-TARS-2B、UI-TARS-7B 和 UI-TARS-72B。我们进行了广泛的实验以验证所提出模型的优势。这些实验旨在评估模型在三个关键维度上的能力:感知、基础能力和 AI 智能体能力。最后,我们进行了消融研究,以进一步探讨系统 1 和系统 2 推理对下游任务的影响。在本节中,我们将公式 3 中的 $N$ 设为 5。我们在 $\S\ 5.4$ 中评估了 UI-TARS-SFT 和 UI-TARS-DPO 在 OsWorld 上的表现,因为该基准最能从 DPO 阶段的迭代改进中受益。然而,对于其他基准,我们报告了退火阶段后训练的模型(即 UI-TARS-SFT)。
Baseline We compare UI-TARS with various baselines, including commercial models such as GPT-4o (Hurst et al., 2024), Claude-3.5-Sonnet (Anthropic, 2024a), Gemini-1.5-Pro (Team et al., 2024), and Gemini-2.0 (Project Mariner) (Google Deep mind, 2024), as well as academic models from CogAgent (Hong et al., 2024), O mini Parser (Lu et al., 2024b), InternVL (Chen et al., 2024d), Aria-UI (Yang et al., 2024a), Aguvis (Xu et al., 2024), OS-Atlas (Wu et al., 2024b), UGround (Gou et al., 2024b), ShowUI (Lin et al., 2024a), SeeClick (Cheng et al., 2024), the Qwen series models QwenVL-7B (Bai et al., 2023b), Qwen2-VL (7B and 72B) (Wang et al., 2024c), UIX-Qwen2-7B (Liu et al., 2024a) and Qwen-VL-Max (Bai et al., 2023a).
基线
5.1 Perception Capability Evaluation
5.1 感知能力评估
We evaluate the perception capabilities of the UI-TARS models using three key benchmarks: VisualWebBench (Liu et al., 2024c), WebSRC (Chen et al., 2021), and ScreenQA-short (Hsiao et al., 2022). Visual Web Bench measures the model's ability to understand and ground web elements, covering tasks like webpage QA, webpage OCR, and action prediction. UI-TARS models achieve outstanding results, with the 72B variant scoring 82.8, significantly outperforming closed-source models like GPT-4o (78.5) and Cluade 3.5 (78.2), as shown in Table 3. For WebSRC and ScreenQA-short, which assess web structural comprehension and mobile screen content understanding through QA tasks, UI-TARS models show a clear advantage. WebSRC focuses on understanding the semantic content and layout of webpages in web contexts, while ScreenQA-short evaluates the interpretation of complex mobile screen layouts and interface-related questions. UI-TARS-7B achieves a leading score of 93.6 on WebSRC, while UI-TARS-72B excells in ScreenQA-short with a score of 88.6. These results demonstrate the superior perception and comprehension capabilities of UI-TARS in web and mobile environments. Such perceptual ability lays the foundation for agent tasks, where accurate environmental understanding is crucial for task execution and decision-making.
我们使用三个关键基准评估了 UI-TARS 模型的感知能力:VisualWebBench (Liu et al., 2024c)、WebSRC (Chen et al., 2021) 和 ScreenQA-short (Hsiao et al., 2022)。VisualWebBench 衡量模型理解和定位网页元素的能力,涵盖网页问答 (QA)、网页 OCR 和动作预测等任务。UI-TARS 模型取得了出色的成绩,其中 72B 版本得分为 82.8,显著优于 GPT-4o (78.5) 和 Claude 3.5 (78.2) 等闭源模型,如表 3 所示。对于 WebSRC 和 ScreenQA-short,它们通过问答任务评估网页结构理解和移动屏幕内容理解,UI-TARS 模型显示出明显优势。WebSRC 侧重于理解网页在网页上下文中的语义内容和布局,而 ScreenQA-short 评估对复杂移动屏幕布局和界面相关问题的解释。UI-TARS-7B 在 WebSRC 上取得了领先的 93.6 分,而 UI-TARS-72B 在 ScreenQA-short 中表现出色,得分为 88.6。这些结果证明了 UI-TARS 在网页和移动环境中的卓越感知和理解能力。这种感知能力为智能体任务奠定了基础,准确的环境理解对于任务执行和决策至关重要。
| Model | VisualWebBench | WebSRC | ScreenQA-short |
|---|---|---|---|
| Qwen2-VL-7B (Wang et al.,2024c) | 73.3 | 81.8 | 84.9 |
| Qwen-VL-Max(Baietal.,2023b) | 74.1 | 91.1 | 78.6 |
| Gemini-1.5-Pro(Team et al.,2024) | 75.4 | 88.9 | 82.2 |
| UIX-Qwen2-7B (Wang et al.,2024d) | 75.9 | 82.9 | 78.8 |
| Claude-3.5-Sonnet(Anthropic,2024a) | 78.2 | 90.4 | 83.1 |
| GPT-4o (Hurst et al.,2024) | 78.5 | 87.7 | 82.3 |
| UI-TARS-2B | 72.9 | 89.2 | 86.4 |
| UI-TARS-7B | 79.7 | 93.6 | 87.7 |
| UI-TARS-72B | 82.8 | 89.3 | 88.6 |
Table 3: Results on GUI Perception benchmarks. Table 4: Comparison of various models on ScreenSpot-Pro.
5.2 Grounding Capability Evaluation
5.2 基础能力评估
To evaluate the grounding capabilities of the UI-TARS, we focus on three benchmarks: ScreenSpot Pro (Li et al., 2025), ScreenSpot (Cheng et al., 2024), and ScreenSpot v2 (Wu et al., 2024b). These benchmarks assess the ability to understand and localize elements in GUIs. ScreenSpot Pro is designed for high-resolution professional environments, this benchmark includes expert-annotated tasks across 23 applications in five industries and three operating systems. It provides a rigorous assessment of model grounding performance in specialized, high-complexity scenarios. ScreenSpot and ScreenSpot v2 test GUI grounding across mobile, desktop, and web platforms. ScreenSpot evaluates models using both direct instructions and self-generated plans, while ScreenSpot v2 enhances the evaluation accuracy by correcting annotation errors.
为了评估 UI-TARS 的定位能力,我们重点关注三个基准:ScreenSpot Pro (Li 等, 2025)、ScreenSpot (Cheng 等, 2024) 和 ScreenSpot v2 (Wu 等, 2024b)。这些基准测试评估了理解和定位 GUI 元素的能力。ScreenSpot Pro 专为高分辨率的专业环境设计,该基准包括在五个行业和三个操作系统中的 23 个应用程序上由专家标注的任务。它在高度复杂和专业的场景中对模型的定位性能进行了严格评估。ScreenSpot 和 ScreenSpot v2 则测试了跨移动、桌面和网页平台的 GUI 定位能力。ScreenSpot 通过直接指令和自生成计划来评估模型,而 ScreenSpot v2 通过纠正标注错误提高了评估的准确性。
UI-TARS consistently outperforms baselines across multiple benchmarks. Specifically, in Table 4, UI-TARS72B achieves a score of 38.1 on ScreenSpot Pro, significantly exceeding the performance of UGround-V1-7B (31.1) and OS-Atlas-7B (18.9). Notably, we observe that increasing the input image resolution on ScreenSpot Pro led to a significant performance improvement. Additionally, UI-TARS-7B attains a leading score of 89.5 on ScreenSpot in Table 5. On ScreenSpot v2, as shown in Table 6, both UI-TARS-7B (91.6) and UI-TARS72B (90.3) outperform existing baselines, such as OS-Atlas-7B (87.1), further highlighting the robustness of our approach. In addition, the results show a significant improvement in grounding performance as we scale from UI-TARS-2B to UI-TARS-7B across all three grounding datasets. Comparing UI-TARS-7B and UI-TARS-72B, while ScreenSpot v1 and v2 exhibit no significant performance change, ScreenSpot Pro shows notable improvement in model scaling. This indicates that ScreenSpot v1 and v2 may not be sufficiently robust to fully capture the model's grounding capabilities at higher scales.
UI-TARS在多个基准测试中始终优于基线模型。具体而言,在表4中,UI-TARS72B在ScreenSpot Pro上获得了38.1的分数,显著超过了UGround-V1-7B(31.1)和OS-Atlas-7B(18.9)的表现。值得注意的是,我们观察到在ScreenSpot Pro上增加输入图像分辨率显著提高了性能。此外,UI-TARS-7B在表5中的ScreenSpot上获得了89.5的领先分数。在ScreenSpot v2上,如表6所示,UI-TARS-7B(91.6)和UI-TARS72B(90.3)均优于现有基线模型,如OS-Atlas-7B(87.1),进一步突显了我们方法的鲁棒性。此外,结果显示在从UI-TARS-2B扩展到UI-TARS-7B的过程中,所有三个基础数据集上的基础性能均有显著提升。比较UI-TARS-7B和UI-TARS-72B,虽然ScreenSpot v1和v2在性能上没有显著变化,但ScreenSpot Pro在模型扩展方面表现出显著的改进。这表明ScreenSpot v1和v2可能不够稳健,无法完全捕捉模型在更大规模下的基础能力。
Table 5: Comparison of various planners and grounding methods on ScreenSpot. Table 6: Comparison of various planners and grounding methods on ScreenSpot-V2.
In summary, these results highlight the robust grounding capabilities of UI-TARS across various scenarios, including mobile, desktop, web, and professional environments. The models? consistent performance across datasets and their ability to handle both general and high-complexity tasks underscore their versatility and effectiveness in real-world GUI grounding applications.
总之,这些结果突显了UI-TARS在移动、桌面、Web和专业环境等多种场景中的强大基础能力。模型在数据集上的一致表现及其处理一般和高复杂度任务的能力,强调了它们在现实世界GUI基础应用中的多功能性和有效性。
5.3 Offline Agent Capability Evaluation
5.3 离线智能体能力评估
To evaluate the GUI agent capabilities of UI-TARS in static, pre-defined environments, we conduct evaluations on three benchmarks: Multimodal Mind2Web (Zheng et al., 2024a) is designed to create and evaluate generalist web agents executing language instructions. It primarily assesses a model's performance in webbased environments. Metrics include element accuracy (Ele.Acc), operation F1 score (Op.F1), and step success rate (Step SR), as shown in Table 7. Android Control (Li et al., 2024c) evaluates planning and action-execution abilities in mobile environments. This dataset includes two types of tasks: (1) high-level tasks require the model to autonomously plan and execute multistep actions; (2) low-level tasks instruct the model to execute predefined, human-labeled actions for each step (Table 8). GUI Odyssey (Lu et al., 2024a) focuses on cross-app navigation tasks in mobile environments, featuring an average of $15+$ steps per task. Tasks span diverse navigation scenarios with instructions generated from predefined templates. The dataset includes human demonstrations recorded on an Android emulator, providing detailed and validated metadata for each task episode. For Multimodal Mind2Web, we adhere to the settings and metrics specified in the original framework. For Android Control and GUI Odyssey (Table 8), we follow the settings and metrics outlined in OS-Atlas (Wu et al., 2024b).
为了评估 UI-TARS 在静态、预定义环境中的 GUI 智能体能力,我们在三个基准上进行了评估:Multimodal Mind2Web (Zheng et al., 2024a) 旨在创建和评估执行语言指令的通用网页智能体。它主要评估模型在网页环境中的表现,指标包括元素准确率(Ele.Acc)、操作 F1 分数(Op.F1)和步骤成功率(Step SR),如表 7 所示。Android Control (Li et al., 2024c) 评估在移动环境中的规划和执行能力。该数据集包括两类任务:(1) 高级任务要求模型自主规划并执行多步操作;(2) 低级任务指示模型执行预定义的、人工标注的每步操作(表 8)。GUI Odyssey (Lu et al., 2024a) 专注于移动环境中的跨应用导航任务,每个任务平均包含 15+ 个步骤。任务涵盖多样化的导航场景,指令由预定义模板生成。该数据集包括在 Android 模拟器上记录的人工演示,为每个任务片段提供了详细且经过验证的元数据。对于 Multimodal Mind2Web,我们遵循原始框架中指定的设置和指标。对于 Android Control 和 GUI Odyssey(表 8),我们遵循 OS-Atlas (Wu et al., 2024b) 中概述的设置和指标。
Claude refers to Claude-computer-use.
Table 7: Performance comparison on Multimodal Mind2Web across different settings. We report element accuracy (Ele.Acc), operation F1 (Op.F1), and step success rate (Step SR). Table 8: Results on mobile tasks (Android Control and GUI Odyssey). For Android Control, we report two settings (Low and High).
Claude refers to Claude-computer-use.
Across the three evaluated datasets, UI-TARS demonstrates clear advancements in reasoning and execution capabilities. In Multimodal Mind2Web (Table 7), most of the agent models significantly outperform frameworkbased methods (using GPT-4o or GPT-4V as the core planner). Comparing different agent models, UI-TARS72B achieving SOTA performance across key metrics. UI-TARS-7B, despite having fewer parameters, surpass strong baselines such as Aguvis-72B model and Claude. On Android Control and GUI Odyssey (Table 7), UITARS-7B and UI-TARS-72B surpasses previous SOTA method (OS-Atlas-7B) with an absolute performance increase of 25, showing notable superiority in multistep offline tasks. We also find that Claude Computer-Use performs strongly in web-based tasks but significantly struggles with mobile scenarios, indicating that the GUI operation ability of Claude has not been well transferred to the mobile domain. In contrast, UI-TARS exhibits excellent performance in both website and mobile domain, highlighting its adaptability and generalization capabilities.
在评估的三个数据集中,UI-TARS 在推理和执行能力方面展示了明显的进步。在 Multimodal Mind2Web (表 7) 中,大多数智能体模型显著优于基于框架的方法 (使用 GPT-4o 或 GPT-4V 作为核心规划器)。比较不同的智能体模型,UI-TARS72B 在关键指标上达到了 SOTA 性能。UI-TARS-7B 尽管参数较少,但超越了 Aguvis-72B 模型和 Claude 等强基线。在 Android Control 和 GUI Odyssey (表 7) 中,UI-TARS-7B 和 UI-TARS-72B 超越了之前的 SOTA 方法 (OS-Atlas-7B),性能绝对提升了 25,在多步骤离线任务中表现出显著优势。我们还发现,Claude Computer-Use 在基于网页的任务中表现强劲,但在移动场景中表现明显不佳,表明 Claude 的 GUI 操作能力尚未很好地迁移到移动领域。相比之下,UI-TARS 在网站和移动领域都表现出色,突显了其适应性和泛化能力。
5.4 Online Agent Capability Evaluation
5.4 在线智能体能力评估
Online evaluations enable dynamic environments, each designed as an interactive simulation that mirrors real-world scenarios. In these environments, GUI agents can alter environmental states by executing actions in real time. We evaluate different models in online environments using two benchmarks: OsWorld (Xie et al., 2024) provides a scalable and diverse environment for evaluating multimodal agents on complex tasks across Ubuntu, Windows, and macOS platforms. It consists of 369 tasks involving real-world web and desktop applications, with detailed setups and evaluation scripts. The evaluation is conducted in screenshot-only mode. To mitigate potential interference from network instability and environmental factors, the final score is averaged over 3 runs. We also consider traces where our model decides to “CallUser” or traces our model fails to output “Finish" in the end as infeasible tasks for evaluation. Android World (Rawles et al., 2024b) is an environment designed for developing and benchmarking autonomous agents on a live Android emulator. It includes 116 tasks across 20 mobile apps, with dynamic task variations generated through randomized parameters. This dataset is ideal for evaluating agents? adaptability and planning abilities in mobile contexts.
在线评估支持动态环境,每个环境都是一个模拟现实世界场景的交互式仿真。在这些环境中,GUI 智能体可以通过实时执行操作来改变环境状态。我们在在线环境中使用两个基准来评估不同模型:OsWorld (Xie et al., 2024) 提供了一个可扩展且多样化的环境,用于评估跨 Ubuntu、Windows 和 macOS 平台的复杂任务上的多模态智能体。它包含 369 个涉及现实世界网页和桌面应用程序的任务,并提供了详细的设置和评估脚本。评估在仅截图模式下进行。为了减轻网络不稳定性和环境因素可能带来的干扰,最终分数取 3 次运行的平均值。我们还将模型决定“CallUser”或模型最终未能输出“Finish”的轨迹视为不可行的任务进行评估。Android World (Rawles et al., 2024b) 是一个专为在实时 Android 模拟器上开发和基准测试自主智能体而设计的环境。它包含 20 个移动应用程序中的 116 个任务,并通过随机参数生成动态任务变化。该数据集非常适合评估智能体在移动环境中的适应性和规划能力。
Table 9: Results on online benchmarks. We evaluate performance under the screenshot-only seting on OsWorld, limiting the maximum number of steps to 15.
The results are listed in Table 9. (1) On OSWorld, when given a budget of 15 steps, UI-TARS-7B-DPO (18.7) and UI-TARS-72B-DPO (22.7) significantly outperforms Claude (14.9), demonstrating its strong reasoning capabilities. Also, UI-TARS-72B-DPO with a 15-step budget (22.7) is comparable to Claude when the latter is given 50-step budget (22.0), showing great execution efficiency. Notably, UI-TARS-72B-DPO achieves a new SOTA result 24.6 on OsWorld with a budget of 50 steps, surpassing all the existing agent frameworks (e.g., GPT-4o with Aria-UI), highlighting the significant potential of agent models in addressing complex desktop-based tasks with higher efficiency and effectiveness. (2) Results on Android World deliver a similar conclusion, with UI-TARS-72B-SFT achieving a 46.6 performance, outperforming the best previous agent framework (GPT-4o with Aria-UI, 44.8) and agent model (Aguvis-72B, 26.1). (3) Comparing the results of SFT model and DPO model, we find that DPO significantly improves the performance on OSWorld, showing that involving “negative samples” during training enables the model to better distinguish between optimal and suboptimal actions. (4) Furthermore, comparing UI-TARS-72B and UI-TARS-7B, we find that the 72B model performs much better than the 7B model in online tasks, and the gap is larger compared to offline tasks (Table 7 and Table 8). This shows that scaling model size significantly improves system 2 reasoning, enabling more deliberate and logical decision-making. Moreover, the discrepancy suggests that evaluations based solely on offline benchmarks may fail to accurately capture the models? capabilities in real-time, dynamic environments. In general, these results validate the potential of agent models for reasoning-intensive tasks and emphasize the advantages of leveraging larger-scale models to tackle the challenges of online environments.
5.5 Comparing System 1 and System 2 Reasoning
5.5 比较系统1和系统2的推理
We compare the effects of system-1 and system-2 reasoning on model performance. System-1 reasoning refers to the model directly producing actions without chain-of-thought, while system-2 reasoning involves a more deliberate thinking process where the model generates reasoning steps before selecting an action. We train UI-TARS-7B to acquire both capabilities but we modify the model's reasoning behavior during inference through prompt engineering.
我们比较了系统1和系统2推理对模型性能的影响。系统1推理指的是模型在没有思维链的情况下直接生成动作,而系统2推理则涉及更慎重的思考过程,模型在选定动作之前会生成推理步骤。我们训练了UI-TARS-7B以具备这两种能力,但在推理过程中通过提示工程修改了模型的推理行为。
In-domain Evaluation We first evaluate performance across three in-domain agent benchmarks: Multimodal Mind2Web, Android Control, and GUI Odyssey, all of which have corresponding training data in UI-TARS. For efficiency in evaluation, we randomly sample 1,000 examples for the Android Control and GUI Odyssey benchmarks. We use the Best-of-N (BoN) sampling method, where UI-TARS samples $N$ candidate outputs per input, with $N$ set to 1, 16, and 64. The step success rate is used as the evaluation metric.
领域内评估
我们首先在三个领域内的智能体基准测试中进行性能评估:Multimodal Mind2Web、Android Control 和 GUI Odyssey,这些基准测试在 UI-TARS 中都有相应的训练数据。为了提高评估效率,我们随机抽取了 1,000 个示例用于 Android Control 和 GUI Odyssey 基准测试。我们使用了 Best-of-N (BoN) 采样方法,其中 UI-TARS 对每个输入采样 $N$ 个候选输出,$N$ 设置为 1、16 和 64。评估指标为步骤成功率。

Figure 8: Performance of system-1 (no-thought) and system-2 (with thought) in in-domain (Mind2Web, Android Control, GUI Odyssey) and out-of-domain (Android World) benchmarks.
图 8: 系统-1 (无思想) 和系统-2 (有思想) 在领域内 (Mind2Web, Android Control, GUI Odyssey) 和领域外 (Android World) 基准测试中的表现。
As shown in Figure 8, at $N{=}1$ , system-2 reasoning performs slightly worse than system-1 reasoning across all three in-domain benchmarks. While system-2 reasoning is generally expected to improve task execution by introducing a refective, multi-step process, this result suggests that under a single-sample condition, the complexity of system-2 reasoning can lead to suboptimal reasoning steps. Specifically, the model may introduce irrelevant or incorrect reasoning steps-such as referring to non-existent objects or making erroneous inferences—which increases the risk of hallucinations or failure to generate the correct action. In the absence of diverse candidate outputs, the model may fixate on a flawed reasoning path, resulting in a lower likelihood of choosing the correct action.
如图 8 所示,在 $N{=}1$ 时,系统 2 推理在所有三个域内基准测试中的表现略逊于系统 1 推理。虽然系统 2 推理通常通过引入反思性的多步骤过程来改善任务执行,但这一结果表明,在单样本条件下,系统 2 推理的复杂性可能导致次优的推理步骤。具体而言,模型可能会引入不相关或错误的推理步骤,例如引用不存在的对象或做出错误的推断,这增加了幻觉或无法生成正确操作的风险。在缺乏多样候选输出的情况下,模型可能会固守一个存在缺陷的推理路径,从而导致选择正确操作的可能性降低。
However,as $N$ increases to 16 and 64, the system-2 model begins to demonstrate a clear advantage over system-1 reasoning. The increased number of candidate outputs provides greater diversity in the decision space, allowing the model to overcome suboptimal reasoning paths. In particular, the system-2 model benefits from the opportunity to explore multiple reasoning chains, which compensates for the earlier issues seen with $N{=}1$ . The diversity of candidates increases the likelihood that the correct action is among the sampled outputs, even if some of the intermediate reasoning steps were not ideal. This shift in performance is particularly striking as it shows that the deliberate, multi-step reasoning of system-2 can effectively compensate for its initial disadvantages when sufficient candidate outputs are available.
然而,随着 $N$ 增加到 16 和 64,系统 2 模型开始展现出相对于系统 1 推理的明显优势。候选输出数量的增加为决策空间提供了更大的多样性,使得模型能够克服次优的推理路径。特别是,系统 2 模型受益于探索多条推理链的机会,这弥补了在 $N{=}1$ 时出现的问题。候选的多样性增加了正确动作出现在采样输出中的可能性,即使某些中间推理步骤并不理想。这种性能的转变尤为显著,因为它表明,当有足够的候选输出时,系统 2 的深思熟虑、多步推理能够有效弥补其最初的劣势。
A key insight is that while system-2 reasoning excels with sufficient diversity, achieving optimal performance with a single, decisive output (as in Bo1) remains a significant challenge. The ideal future direction involves leveraging system-2 reasoning's strengths in diverse, real-world scenarios while minimizing the need for multiple samples. This could be accomplished through techniques like reinforced fine-tuning (Jaech et al., 2024), which would guide the model to produce the correct action with high confidence in a single pass.
一个关键见解是,尽管系统2推理在多样性充足的情况下表现出色,但在单一、决定性输出(如Bo1)中实现最佳性能仍然是一个重大挑战。理想的未来方向是利用系统2推理在多样化的现实场景中的优势,同时尽量减少对多个样本的需求。这可以通过像强化微调(Jaech et al., 2024)这样的技术来实现,该类技术将指导模型在单次推理中以高置信度生成正确的动作。
Out-of-domain Evaluation Next, we evaluate both reasoning methods on Android World, an out-of-domain (OOD) benchmark without corresponding training data in UI-TARS. We evaluate UI-TARS-7B and UI-TARS72B at Bo1. Interestingly, the results from Android World reveal a significant shift compared to the in-domain benchmarks. While system-1 reasoning performs well in in-domain scenarios (Mind2Web, Android Control, and GUI Odyssey), system-2 reasoning significantly outperforms system-1 in the OOD setting (Android World). This suggests that although system-2 may face challenges in in-domain scenarios, particularly under singlesample conditions, its deeper reasoning capabilities provide a distinct advantage in OOD situations. In these cases, the increased reasoning depth helps the model generalize to previously unseen tasks, highlighting the broader applicability and potential of system-2 reasoning in real-world, diverse scenarios.
跨领域评估
接下来,我们在 Android World 上进行评估,这是一个没有在 UI-TARS 中对应训练数据的跨领域 (Out-of-Domain, OOD) 基准测试。我们在 Bo1 设置下评估了 UI-TARS-7B 和 UI-TARS72B。有趣的是,Android World 的结果与领域内基准测试相比发生了显著变化。虽然系统 1 推理在领域内场景(Mind2Web、Android Control 和 GUI Odyssey)中表现良好,但系统 2 推理在 OOD 设置(Android World)中显著优于系统 1。这表明,尽管系统 2 在领域内场景中可能面临挑战,尤其是在单样本条件下,但其更深的推理能力在 OOD 场景中提供了显著的优势。在这些情况下,增加的推理深度帮助模型泛化到以前未见过的任务,突显了系统 2 推理在现实世界多样化场景中的广泛适用性和潜力。
6 Conclusion
6 结论
In this paper, we introduced UI-TARS, a native GUI agent model that integrates perception, action, reasoning, and memory into a scalable and adaptive framework. Achieving state-of-the-art performance on challenging benchmarks such as OSWorld, UI-TARS outperforms existing systems like Claude and GPT-4o. We presented several novel innovations, including enhanced perception, unified action modeling, system-2 reasoning, and iterative refinement using online traces, all of which enable the agent to effectively handle complex GUI tasks with minimal human oversight. We also reviewed the evolution path of GUI agents, from rule-based systems to adaptive native models. We segment the development process into key stages based on the degree of human intervention and generalization capabilities, emphasizing the transition from text-based methods to pure-vision, end-to-end agent models. We also explored the core capabilities of the native agent model, including perception, action, reasoning, and memory, which form the foundation for future advancements in GUI agents. Looking ahead, while native agents represent a significant leap forward, the future lies in the integration of active and lifelong learning, where agents autonomously drive their own learning through continuous, real-world interactions.
在本文中,我们介绍了UI-TARS,这是一种原生GUI智能体模型,将感知、行动、推理和记忆集成到一个可扩展且自适应的框架中。在OSWorld等具有挑战性的基准测试中,UI-TARS表现优异,超越了Claude和GPT-4o等现有系统。我们提出了几项创新,包括增强感知、统一行动建模、系统2推理以及使用在线轨迹进行迭代优化,所有这些都使得智能体能够在最少人为监督的情况下有效处理复杂的GUI任务。我们还回顾了GUI智能体的演进路径,从基于规则的系统到自适应原生模型。我们根据人为干预程度和泛化能力将发展过程划分为关键阶段,强调了从基于文本的方法到纯视觉、端到端智能体模型的转变。我们还探讨了原生智能体模型的核心能力,包括感知、行动、推理和记忆,这些能力为未来GUI智能体的进步奠定了基础。展望未来,虽然原生智能体代表了重大飞跃,但未来在于主动学习和终身学习的结合,智能体通过持续的、现实世界的交互自主驱动其学习过程。
Acknowledgements
致谢
We thank Ziqian Wei, and Tianyu Zhang for figure drawing, Yiheng Xu, Tao Yu, Wenqian Wang, Xiaobo Qin, Zhiyong Wu, and Yi Lin, Junyuan Qi, Zihao Wang, Jiecao Chen, Mu Qiao, Congwu Shen, Ruo Wang, Mingxuan Wang, Lin Yan, Renjie Zheng, Guanlin Liu, Yuwen Xiong for suggestions, and Faming Wu, Sihang Yuan, Ziyuan Zhao, Jie Tang, Zhaoyi An, Yiran Wang, Linlin Ao, Bairen Yi, Yanghua Peng, Lishu Luo, Zhi Zhang, Zehua Wang, Lingjun Liu for supporting this work.
我们感谢 Ziqian Wei 和 Tianyu Zhang 绘制图表,感谢 Yiheng Xu、Tao Yu、Wenqian Wang、Xiaobo Qin、Zhiyong Wu、Yi Lin、Junyuan Qi、Zihao Wang、Jiecao Chen、Mu Qiao、Congwu Shen、Ruo Wang、Mingxuan Wang、Lin Yan、Renjie Zheng、Guanlin Liu、Yuwen Xiong 提出的建议,以及 Faming Wu、Sihang Yuan、Ziyuan Zhao、Jie Tang、Zhaoyi An、Yiran Wang、Linlin Ao、Bairen Yi、Yanghua Peng、Lishu Luo、Zhi Zhang、Zehua Wang、Lingjun Liu 对本工作的支持。
References
参考文献
Tamer Abuelsaad, Deepak Akkil, Prasenjit Dey, Ashish Jagmohan, Aditya Vempaty, and Ravi Kokku. Agent-e: From autonomous web navigation to foundational design principles in agentic systems. ArXiv preprint, abs/2407.13032,2024. URL https : / /arxiv.0rg/abs /2407.13032.
Tamer Abuelsaad, Deepak Akkil, Prasenjit Dey, Ashish Jagmohan, Aditya Vempaty, 和 Ravi Kokku. Agent-e: 从自主网页导航到智能体系统的基础设计原则. ArXiv 预印本, abs/2407.13032, 2024. URL https://arxiv.org/abs/2407.13032.
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Alten schmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. ArXiv preprint, abs/2303.08774, 2023. URL https : / /arxiv . 0rg /abs /2303 . 08774.
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Alten schmidt, Sam Altman, Shyamal Anadkat, et al. GPT-4 技术报告。ArXiv 预印本,abs/2303.08774, 2023. URL https://arxiv.org/abs/2303.08774.
Anonymous. AutoGUI: Scaling GUI grounding with automatic functionality annotations from LLMs. In Submitted to The Thirteenth International Conference on Learning Representations, 2024. URL ht t ps : / /openreview.net / forum?id=wl4c9jvcyY. under review.
Anonymous. AutoGUI:利用大语言模型自动功能注释扩展 GUI 基础。已提交至第十三届国际学习表征会议 (The Thirteenth International Conference on Learning Representations),2024。URL ht t ps : / /openreview.net / forum?id=wl4c9jvcyY。正在评审中。
Anthropic. Claude-3-5-sonnet. https://www.anthropic.com/news/claude-3-5-sonnet, 2024a.
Anthropic. Claude-3-5-sonnet. https://www.anthropic.com/news/claude-3-5-sonnet, 2024a.
Anthropic. Developing a computer use model, 2024b. URL ht tps : / /www . anthropic . com/ news / developing-computer-use.
Anthropic. 开发计算机使用模型,2024b. URL ht tps : / /www . anthropic . com/ news / developing-computer-use.
Anas Awadalla, Le Xue, Oscar Lo, Manli Shu, Hannah Lee, Etash Kumar Guha, Matt Jordan, Sheng Shen, Mohamed Awadalla, Silvio Savarese, et al. Mint-1t: Scaling open-source multimodal data by 10x: A multimodal dataset with one trillion tokens. ArXiv preprint, abs/2406.11271, 2024. URL ht tps : / /arxiv.0rg/abs/2406.11271.
Anas Awadalla, Le Xue, Oscar Lo, Manli Shu, Hannah Lee, Etash Kumar Guha, Matt Jordan, Sheng Shen, Mohamed Awadalla, Silvio Savarese, 等. Mint-1t: 将开源多模态数据扩展10倍:一个包含一万亿Token的多模态数据集. ArXiv 预印本, abs/2406.11271, 2024. URL ht tps : / /arxiv.0rg/abs/2406.11271.
Ali Ayub, Ch ry stop her L Nehaniv, and Kerstin Dautenhahn. Interactive continual learning architecture for long-term personalization of home service robots. In 2024 IEEE International Conference on Robotics and Automation (ICRA), Pp. 11289-11296. IEEE, 2024.
Ali Ayub, Christopher L Nehaniv 和 Kerstin Dautenhahn. 用于家庭服务机器人长期个性化交互的持续学习架构. 在 2024 IEEE 国际机器人与自动化会议 (ICRA) 上, Pp. 11289-11296. IEEE, 2024.
Chongyang Bai, Xiaoxue Zang, Ying Xu, Srinivas Sunkara, Abhinav Rastogi, Jindong Chen, and Blaise Aguera y Arcas. Uibert: Learning generic multimodal representations for UI understanding. In Zhi-Hua Zhou (ed.), Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI 2021, Virtual Event / Montreal, Canada, 19-27 August 2021, pp. 1705-1712. ijcai.org, 2021. doi: 10.24963/IJCA1.2021/ 235. URL https://doi.org/10.24963/ijcai.2021/235.
Chongyang Bai, Xiaoxue Zang, Ying Xu, Srinivas Sunkara, Abhinav Rastogi, Jindong Chen, 和 Blaise Aguera y Arcas. Uibert: 学习通用的多模态表示以理解 UI. 在 Zhi-Hua Zhou (编), 第三十届国际人工智能联合会议论文集, IJCAI 2021, 虚拟会议 / 加拿大蒙特利尔, 2021年8月19-27日, 第1705-1712页. ijcai.org, 2021. doi: 10.24963/IJCA1.2021/235. URL https://doi.org/10.24963/ijcai.2021/235.
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A frontier large vision-language model with versatile abilities. arXiv preprint arXiv:2308.12966, 2023a.
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, 和 Jingren Zhou. Qwen-vl: 具备多功能能力的前沿大视觉语言模型. arXiv preprint arXiv:2308.12966, 2023a.
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond, 2023b. URL https : / /arxiv .org /abs /2308 .12966.
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: 一种多功能视觉语言模型,用于理解、定位、文本阅读及其他, 2023b. URL https://arxiv.org/abs/2308.12966.
Michael Bain and Claude Sammut. A framework for behavioural cloning. In Machine Intelligence 15, pPp. 103-129,1995. URL http: / /www.cse.unsw.edu.au/~claude/papers/MI15.pdf.
Michael Bain 和 Claude Sammut。行为克隆框架。载于《机器智能 15》,第 103-129 页,1995 年。URL http://www.cse.unsw.edu.au/~claude/papers/MI15.pdf。
Rohan Bavishi, Erich Elsen, Curtis Hawthorne, Maxwell Nye, Augustus Odena, Arushi Somani, and Sagnak Tasirlar. Introducing our multimodal models, 2023. URL https : / / www . adept . ai /blog / fuyu- 8b.
Rohan Bavishi, Erich Elsen, Curtis Hawthorne, Maxwell Nye, Augustus Odena, Arushi Somani, 和 Sagnak Tasirlar. 介绍我们的多模态模型, 2023. URL https://www.adept.ai/blog/fuyu-8b.
Rogerio Bonatti, Dan Zhao, Francesco Bonacci, Dillon Dupont, Sara Abdali, Yinheng Li, Yadong Lu, Justin Wagle, Kazuhito Koishida, Arthur Bucker, Lawrence Jang, and Zack Hui. Windows agent arena: Evaluating multi-modal os agents at scale, 2024. URL https : / /arxiv .Org /abs /240 9 . 082 64.
Rogerio Bonatti、Dan Zhao、Francesco Bonacci、Dillon Dupont、Sara Abdali、Yinheng Li、Yadong Lu、Justin Wagle、Kazuhito Koishida、Arthur Bucker、Lawrence Jang 和 Zack Hui。Windows Agent Arena: 大规模评估多模态操作系统智能体,2024。URL https://arxiv.org/abs/2409.08264。
Ralph Allan Bradley and Milton E Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons. Biometrika, 39(3/4):324-345, 1952.
Ralph Allan Bradley 和 Milton E Terry. 不完全区组设计的秩分析:I. 成对比较法. Biometrika, 39(3/4):324-345, 1952.
Benjamin Burger, Phillip M Maffetone, Vladimir V Gusev, Catherine M Aitchison, Yang Bai, Xiaoyan Wang, Xiaobo Li, Ben M Alston, Buyi Li, Rob Clowes, et al. A mobile robotic chemist. Nature, 583(7815): 237-241,2020.
Benjamin Burger, Phillip M Maffetone, Vladimir V Gusev, Catherine M Aitchison, Yang Bai, Xiaoyan Wang, Xiaobo Li, Ben M Alston, Buyi Li, Rob Clowes, 等。移动机器人化学家。《自然》,583(7815): 237-241, 2020。
Andrea Burns, Deniz Arsan, Sanjna Agrawal, Ranjitha Kumar, Kate Saenko, and Bryan A. Plummer. A dataset for interactive vision-language navigation with unknown command feasibility._ In Computer Vision - ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23-27, 2022, Proceedings, Part VIII, pp. 312-328, Berlin, Heidelberg, 2022. Springer-Verlag. ISBN 978-3-031-20073-1. doi: 10.1007/978-3-031-20074-8_18. URL https: / /doi.0rg/10.1007/978-3-031-20074-8_18.
Andrea Burns, Deniz Arsan, Sanjna Agrawal, Ranjitha Kumar, Kate Saenko, 和 Bryan A. Plummer. 一个用于未知命令可行性的交互式视觉语言导航的数据集. 在《计算机视觉 - ECCV 2022: 第17届欧洲会议, 以色列特拉维夫, 2022年10月23-27日, 第八部分, 第312-328页, 柏林, 海德堡, 2022. Springer-Verlag. ISBN 978-3-031-20073-1. doi: 10.1007/978-3-031-20074-8_18. URL https://doi.org/10.1007/978-3-031-20074-8_18.
Yuxiang Chai, Siyuan Huang, Yazhe Niu, Han Xiao, Liang Liu, Dingyu Zhang, Peng Gao, Shuai Ren, and Hongsheng Li. Amex: Android multi-annotation expo dataset for mobile gui agents, 2024. URL https://arxiv.0rg/abs/2407.17490.
Yuxiang Chai, Siyuan Huang, Yazhe Niu, Han Xiao, Liang Liu, Dingyu Zhang, Peng Gao, Shuai Ren, and Hongsheng Li. Amex: 用于移动 GUI 智能体的 Android 多注释数据集, 2024. URL https://arxiv.0rg/abs/2407.17490.
Dongping Chen, Yue Huang, Siyuan Wu, Jingyu Tang, Liuyi Chen, Yilin Bai, Zhigang He, Chenlong Wang, Huichi Zhou, Yiqiang Li, Tianshuo Zhou, Yue Yu, Chujie Gao, Qihui Zhang, Yi Gui, Zhen Li, Yao Wan, Pan Zhou, Jianfeng Gao, and Lichao Sun. Gui-world: A dataset for gui-oriented multimodal llm-based agents, 2024a. URL https: / /arxiv.0rg /abs /2406.10819.
Dongping Chen, Yue Huang, Siyuan Wu, Jingyu Tang, Liuyi Chen, Yilin Bai, Zhigang He, Chenlong Wang, Huichi Zhou, Yiqiang Li, Tianshuo Zhou, Yue Yu, Chujie Gao, Qihui Zhang, Yi Gui, Zhen Li, Yao Wan, Pan Zhou, Jianfeng Gao, 和 Lichao Sun. Gui-world: 面向 GUI 的多模态大语言模型智能体数据集, 2024a. URL https://arxiv.org/abs/2406.10819.
Wei Chen and Zhiyuan Li. Octopus v2: On-device language model for super agent, 2024. URL ht tps : //arxiv.0rg/abs/2404.01744.
Wei Chen 和 Zhiyuan Li. Octopus v2: 用于超级AI智能体的设备端语言模型, 2024. URL ht tps : //arxiv.0rg/abs/2404.01744.
Wei Chen, Zhiyuan Li, and Mingyuan Ma. Octopus: On-device language model for function calling of software apis. ArXiv preprint, abs/2404.01549, 2024b. URL https : / /arxiv . 0rg / ab s / 2 40 4 . 0154 9.
Wei Chen, Zhiyuan Li, 和 Mingyuan Ma. Octopus: 面向软件 API 调用的设备端语言模型. ArXiv 预印本, abs/2404.01549, 2024b. URL https://arxiv.org/abs/2404.01549.
Wentong Chen, Junbo Cui, Jinyi Hu, Yujia Qin, Junjie Fang, Yue Zhao, Chongyi Wang, Jun Liu, Guirong Chen, Yupeng Huo, Yuan Yao, Yankai Lin, Zhiyuan Liu, and Maosong Sun. Guicourse: From general vision language models to versatile gui agents, 2024c. URL https : / /arxiv . org /abs /240 6 . 11317.
Wentong Chen, Junbo Cui, Jinyi Hu, Yujia Qin, Junjie Fang, Yue Zhao, Chongyi Wang, Jun Liu, Guirong Chen, Yupeng Huo, Yuan Yao, Yankai Lin, Zhiyuan Liu, Maosong Sun. Guicourse: 从通用视觉语言模型到多功能GUI智能体,2024c. URL https://arxiv.org/abs/2406.11317.
Xingyu Chen, Zihan Zhao, Lu Chen, JiaBao Ji, Danyang Zhang, Ao Luo, Yuxuan Xiong, and Kai Yu. WebSRC: A dataset for web-based structural reading comprehension. In Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih (eds.), Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Pp. 4173-4185, Online and Punta Cana, Dominican Republic, 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.emnlp-main.343. URL ht tps : //a cl anthology.0rg/2021.emnlp-main.343.
Xingyu Chen, Zihan Zhao, Lu Chen, JiaBao Ji, Danyang Zhang, Ao Luo, Yuxuan Xiong, and Kai Yu. WebSRC: 基于网页的结构化阅读理解数据集。 In Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih (eds.), 2021年自然语言处理实证方法会议论文集, Pp. 4173-4185, 在线和多米尼加共和国蓬塔卡纳, 2021. 计算语言学协会. doi: 10.18653/v1/2021.emnlp-main.343. URL ht tps : //a cl anthology.0rg/2021.emnlp-main.343.
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visuallinguistic tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Pp.24185-24198,2024d.
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, 等. Internvl: 扩展视觉基础模型并对齐通用视觉语言任务. 在 IEEE/CVF 计算机视觉与模式识别会议论文集, 第 24185-24198 页, 2024 年.
Kanzhi Cheng, Qiushi Sun, Yougang Chu, Fangzhi Xu, Yantao Li, Jianbing Zhang, and Zhiyong Wu. Seeclick: Harnessing gui grounding for advanced visual gui agents, 2024. URL https : / /arxiv . Org /abs / 2401.10935.
Kanzhi Cheng, Qiushi Sun, Yougang Chu, Fangzhi Xu, Yantao Li, Jianbing Zhang, 和 Zhiyong Wu. Seeclick: 利用 GUI 基础构建高级视觉 GUI 智能体, 2024. URL https://arxiv.org/abs/2401.10935.
Gautier Dagan, Frank Keller, and Alex Lascarides. Dynamic planning with a llm, 2023. URL https : //arxiv.0rg/abs/2308.06391.
Gautier Dagan, Frank Keller, and Alex Lascarides. 使用大语言模型进行动态规划, 2023. URL https://arxiv.org/abs/2308.06391.
Xiang Deng, _ Yu Gu, Boyuan Zheng, Shijie Chen, Samual Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2web: Towards a generalist agent for the web. In_Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, _and Sergey Levine (eds.), Advances in Neural Information Processing Systems 36:Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 -16, 2023, 2023. URL http://papers.nips.cc/paper files/paper/2023/hash/ 5950 bf 290 a 1570 ea 401 bf 98882128160-Abstract-Datasets and Benchmarks.html.
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Samual Stevens, Boshi Wang, Huan Sun, 和 Yu Su. Mind2web: 迈向通用的网页智能体。在 Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, 和 Sergey Levine (eds.), 《神经信息处理系统进展 36: 2023 年神经信息处理系统年会》, NeurIPS 2023, 美国路易斯安那州新奥尔良, 2023 年 12 月 10 日 -16 日, 2023. URL http://papers.nips.cc/paper files/paper/2023/hash/5950 bf 290 a 1570 ea 401 bf 98882128160-Abstract-Datasets and Benchmarks.html.
Yang Deng, Xuan Zhang, Wenxuan Zhang, Yifei Yuan, See-Kiong Ng, and Tat-Seng Chua. On the multi-turn instruction following for conversational web agents, 2024. URL https : / /arxiv . org /abs / 24 02 . 1505 7.
Yang Deng, Xuan Zhang, Wenxuan Zhang, Yifei Yuan, See-Kiong Ng, and Tat-Seng Chua. 关于对话式网络智能体的多轮指令跟随, 2024. URL https://arxiv.org/abs/2402.15057.
Liliana Dobrica. Robotic process automation platform uipath. Commun. ACM, 65(4):42-43, 2022. ISSN 0001-0782. doi: 10.1145/3511667. URL https : / /doi . 0rg /10 .1145/3511667.
Liliana Dobrica. 机器人流程自动化平台 UiPath. Commun. ACM, 65(4):42-43, 2022. ISSN 0001-0782. doi: 10.1145/3511667. URL https : / /doi . 0rg /10 .1145/3511667.
Difei Gao, Lei Ji, Zechen Bai, Mingyu Ouyang, Peiran Li, Dongxing Mao, Qinchen Wu, Weichen Zhang, Peiyi Wang, Xiangwu Guo, Hengxu Wang, Luowei Zhou, and Mike Zheng Shou. Assistgui: Task-oriented desktop graphical user interface automation, 2023. URL https : / /arxiv . 0rg / abs /2312 .13108.
Difei Gao, Lei Ji, Zechen Bai, Mingyu Ouyang, Peiran Li, Dongxing Mao, Qinchen Wu, Weichen Zhang, Peiyi Wang, Xiangwu Guo, Hengxu Wang, Luowei Zhou, and Mike Zheng Shou. AssistGUI: 面向任务的桌面图形用户界面自动化, 2023. URL https://arxiv.org/abs/2312.13108.
Minghe Gao, Wendong Bu, Bingchen Miao, Yang Wu, Yunfei Li, Juncheng Li, Siliang Tang, Qi Wu, Yueting Zhuang, and Meng Wang. Generalist virtual agents: A survey on autonomous agents across digital platforms. ArXiv preprint, abs/2411.10943, 2024. URL https : / / arxiv . 0rg / abs /2411. 10 943.
Minghe Gao, Wendong Bu, Bingchen Miao, Yang Wu, Yunfei Li, Juncheng Li, Siliang Tang, Qi Wu, Yueting Zhuang, and Meng Wang. 通用虚拟智能体:跨数字平台的自主智能体综述. ArXiv 预印本, abs/2411.10943, 2024. URL https://arxiv.org/abs/2411.10943.
Google Deep mind. Gemini-2.0 (project mariner), 2024. URL https : / /deepmind.google/ technologies/project-mariner.
Google DeepMind. Gemini-2.0 (project mariner), 2024. URL https://deepmind.google/technologies/project-mariner.
Boyu Gou, Ruohan Wang, Boyuan Zheng, Yanan Xie, Cheng Chang, Yiheng Shu, Huan Sun, and Yu Su. Navigating the digital world as humans do: Universal visual grounding for gui agents. ArXiv preprint, abs/2410.05243, 2024a. URL https : / /arxiv.0rg/abs /2410 .05243.
Boyu Gou, Ruohan Wang, Boyuan Zheng, Yanan Xie, Cheng Chang, Yiheng Shu, Huan Sun, and Yu Su. 像人类一样在数字世界中导航:GUI 智能体的通用视觉 grounding. ArXiv 预印本, abs/2410.05243, 2024a. URL https://arxiv.org/abs/2410.05243.
Boyu Gou, Ruohan Wang, Boyuan Zheng, Yanan Xie, Cheng Chang, Yiheng Shu, Huan Sun, and Yu Su. Navigating the digital world as humans do: Universal visual grounding for gui agents, 2024b. URL https: //arxiv.0rg/abs/2410.05243.
Boyu Gou, Ruohan Wang, Boyuan Zheng, Yanan Xie, Cheng Chang, Yiheng Shu, Huan Sun, 和 Yu Su。像人类一样在数字世界中导航:通用视觉接地用于 GUI 智能体,2024b。URL https://arxiv.org/abs/2410.05243。
Philip M Groves and Richard F Thompson. Habituation: a dual-process theory. Psychological review, 77(5): 419,1970.
Philip M Groves 和 Richard F Thompson. 习惯化:一个双过程理论. Psychological review, 77(5): 419,1970.
Izzeddin Gur, Hiroki Furuta, Austin Huang, Mustafa Safdari, Yutaka Matsuo, Douglas Eck, and Aleksandra Faust. A real-world webagent with planning, long context understanding, and program synthesis. ArXiv preprint, abs/2307.12856, 2023. URL https : / /arxiv . org /abs /2307 . 12856.
Izzeddin Gur, Hiroki Furuta, Austin Huang, Mustafa Safdari, Yutaka Matsuo, Douglas Eck, and Aleksandra Faust. 具备规划、长上下文理解和程序合成能力的真实世界网页智能体. ArXiv 预印本, abs/2307.12856, 2023. URL https://arxiv.org/abs/2307.12856.
Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hongming Zhang, Zhenzhong Lan, and Dong Yu. Webvoyager: Building an end-to-end web agent with large multimodal models. ArXiv preprint, abs/2401.13919, 2024. URL https : / /arxiv.0rg /abs /2401.13919.
Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hongming Zhang, Zhenzhong Lan, and Dong Yu. Webvoyager: 使用大型多模态模型构建端到端的网络智能体. ArXiv 预印本, abs/2401.13919, 2024. URL https://arxiv.org/abs/2401.13919.
Peter Hofmann, Caroline Samp, and Nils Urbach. Robotic process automation. Electronic Markets, 30 (1):99-106, 2020. doi: 10.1007/s12525-019-00365-. URL https : / /ideas . repec . org /a/spr/ elmark/v30y2020i1d10.1007_s12525-019-00365-8.html.
Peter Hofmann, Caroline Samp, 和 Nils Urbach. 机器人流程自动化. Electronic Markets, 30 (1):99-106, 2020. doi: 10.1007/s12525-019-00365-. URL https://ideas.repec.org/a/spr/elmark/v30y2020i1d10.1007_s12525-019-00365-8.html.
Wenyi Hong, Weihan Wang, Qingsong Lv, Jiazheng Xu, Wenmeng Yu, Junhui Ji, Yan Wang, Zihan Wang, Yuxiao Dong, Ming Ding, et al. Cogagent: A visual language model for gui agents. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Rec 0 gni tion, pp. 14281-14290, 2024.
Wenyi Hong, Weihan Wang, Qingsong Lv, Jiazheng Xu, Wenmeng Yu, Junhui Ji, Yan Wang, Zihan Wang, Yuxiao Dong, Ming Ding 等. Cogagent: 一种用于 GUI 智能体的视觉语言模型. 在 IEEE/CVF 计算机视觉与模式识别会议论文集, 第 14281-14290 页, 2024.
Yu-Chung Hsiao, Fedir Zubach, Gilles Baechler, Victor Carbune, Jason Lin, Maria Wang, Srinivas Sunkara, Yun Zhu, and Jindong Chen. Screenqa: Large-scale question-answer pairs over mobile app screenshots. ArXiv preprint, abs/2209.08199, 2022. URL https : / / arxiv . 0rg / abs /2209 . 08199.
Yu-Chung Hsiao, Fedir Zubach, Gilles Baechler, Victor Carbune, Jason Lin, Maria Wang, Srinivas Sunkara, Yun Zhu, and Jindong Chen. ScreenQA: 基于移动应用截图的大规模问答对。ArXiv 预印本, abs/2209.08199, 2022. URL https://arxiv.org/abs/2209.08199.
Xueyu Hu, Tao Xiong, Biao Yi, Zishu Wei, Ruixuan Xiao, Yurun Chen, Jiasheng Ye, Meiling Tao, Xiangxin Zhou, Ziyu Zhao, et al. Os agents: A survey on mllm-based agents for general computing devices use. 2024.
胡雪宇, 熊涛, 易彪, 魏子舒, 肖瑞轩, 陈雨润, 叶嘉晟, 陶美玲, 周向欣, 赵子钰, 等. 操作系统智能体: 基于大语言模型的通用计算设备使用智能体综述. 2024.
Xu Huang, Weiwen Liu, Xiaolong Chen, Xingmei Wang, Hao Wang, Defu Lian, Yasheng Wang, Ruiming Tang, and Enhong Chen. Understanding the planning of llm agents: A survey, 2024. URL https : //arxiv.0rg/abs /2402.02716.
Xu Huang, Weiwen Liu, Xiaolong Chen, Xingmei Wang, Hao Wang, Defu Lian, Yasheng Wang, Ruiming Tang, Enhong Chen. 理解大语言模型智能体的规划:综述, 2024. URL https://arxiv.0rg/abs/2402.02716.
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. ArXiv preprint, abs/2410.21276, 2024. URL https: / /arxiv.org/abs /2410.21276.
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, 等. GPT-4o 系统卡片. ArXiv 预印本, abs/2410.21276, 2024. 网址 https://arxiv.org/abs/2410.21276.
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai 01 system card. arXiv preprint arXiv:24i2.16720, 2024.
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, 等. OpenAI 01 系统卡. arXiv 预印本 arXiv:24i2.16720, 2024.
Armand Joulin, Edouard Grave, Piotr Bojanowski, Matthijs Douze, Hérve Jegou, and Tomas Mikolov. Fasttext.zip: Compressing text classification models. ArXiv preprint, abs/1612.03651, 2016. URL ht tps : //arxiv.0rg/abs /1612.03651.
Armand Joulin, Edouard Grave, Piotr Bojanowski, Matthijs Douze, Hérve Jégou, and Tomas Mikolov. Fasttext.zip: 压缩文本分类模型. ArXiv 预印本, abs/1612.03651, 2016. URL https://arxiv.org/abs/1612.03651.
Raghav Kapoor, Yash Parag Butala, Melisa Russak, Jing Yu Koh, Kiran Kamble, Waseem Alshikh, and Ruslan Salak hut dino v. Omniact: A dataset and benchmark for enabling multimodal generalist autonomous agents for desktop and web, 2024. URL https : / /arxiv.0rg /abs /2402 .17553.
Raghav Kapoor、Yash Parag Butala、Melisa Russak、Jing Yu Koh、Kiran Kamble、Waseem Alshikh 和 Ruslan Salakhutdinov: Omniact: 用于支持多模态通用自主智能体在桌面和网页环境中的数据集与基准, 2024. URL https://arxiv.org/abs/2402.17553.
Jihyung Kil, Chan Hee Song, Boyuan Zheng, Xiang Deng, Yu Su, and Wei-Lun Chao. Dual-view visual contextual iz ation for web navigation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 14445-14454, 2024.
Jihyung Kil, Chan Hee Song, Boyuan Zheng, Xiang Deng, Yu Su, 和 Wei-Lun Chao. 双视图视觉上下文化在网页导航中的应用。在 IEEE/CVF 计算机视觉与模式识别会议论文集,第 14445-14454 页,2024。
Juyong Lee, Taywon Min, Minyong An, Dongyoon Hahm, Haeone Lee, Changyeon Kim, and Kimin Lee. Benchmarking mobile device control agents across diverse configurations, 2024. URL ht tps : / / arxiv . 0rg/abs /2404 .16660.
Juyong Lee, Taywon Min, Minyong An, Dongyoon Hahm, Haeone Lee, Changyeon Kim, 和 Kimin Lee. 跨多样配置的移动设备控制 AI 智能体基准测试, 2024. URL ht tps : / / arxiv . 0rg/abs /2404 .16660.
Gang Li, Gilles Baechler, Manuel Tragut, and Yang Li. Learning to denoise raw mobile UI layouts for improving datasets at scale. In Simone D. J. Barbosa, Cliff Lampe, Caroline Appert, David A. Shamma, Steven Mark Drucker, Julie R. Williamson, and Koji Yatani (eds.), CHI '22: CHI Conference on Human Factors in Computing Systems, New Orleans, LA, USA, 29 April 2022 - 5 May 2022, pp. 67:1-67:13. ACM, 2022. doi: 10.1145/3491102.3502042. URL https : / /doi . 0rg/10 .1145/3491102 .3502042.
Gang Li, Gilles Baechler, Manuel Tragut, 和 Yang Li. 学习去噪原始移动UI布局以大规模改进数据集. 在 Simone D. J. Barbosa, Cliff Lampe, Caroline Appert, David A. Shamma, Steven Mark Drucker, Julie R. Williamson, 和 Koji Yatani (编), CHI '22: CHI 人机交互系统会议, 美国新奥尔良, 2022年4月29日 - 5月5日, pp. 67:1-67:13. ACM, 2022. doi: 10.1145/3491102.3502042. URL https://doi.org/10.1145/3491102.3502042.
Hongxin Li, Jingran Su, Yuntao Chen, Qing Li, and Zhaoxiang Zhang. Sheet copilot: Bringing software productivity to the next level through large language models. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine (eds.), Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, 2023a. URL http: / /papers .nips .cc /paper files /paper/
Hongxin Li, Jingran Su, Yuntao Chen, Qing Li, 和 Zhaoxiang Zhang. Sheet Copilot: 通过大语言模型将软件生产力提升到新水平。在 Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, 和 Sergey Levine (eds.) 编著的《Neural Information Processing Systems 36: 2023 年神经信息处理系统年会, NeurIPS 2023, 美国路易斯安那州新奥尔良, 2023 年 12 月 10 - 16 日》, 2023a. URL http: / /papers .nips .cc /paper files /paper/
2023/hash/0 ff 30 c 4 bf 31 db 0119 a 6219 e 0 d 250 e 037-Abstract-Conference.html.
2023/hash/0ff30c4bf31db0119a6219e0d250e037-Abstract-Conference.html
Kaixin Li, Ziyang Meng, Hongzhan Lin, Ziyang Luo, Yuchen Tian, Jing Ma, Zhiyong Huang, and Tat-Seng Chua. Screenspot-pro: Gui grounding for professional high-resolution computer use, 2025.
Kaixin Li, Ziyang Meng, Hongzhan Lin, Ziyang Luo, Yuchen Tian, Jing Ma, Zhiyong Huang, and Tat-Seng Chua. Screenspot-pro: 专业高分辨率计算机使用的 GUI 定位, 2025.
Qingyun Li, Zhe Chen, Weiyun Wang, Wenhai Wang, Shenglong Ye, Zhenjiang Jin, Guanzhou Chen, Yinan He, Zhangwei Gao, Erfei Cui, et al. Omnicorpus: An unified multimodal corpus of 10 billion-level images interleaved with text. ArXiv preprint, abs/2406.08418, 2024a. URL https : / / arxiv . 0rg / abs / 2 4 0 6 . 08418.
Qingyun Li, Zhe Chen, Weiyun Wang, Wenhai Wang, Shenglong Ye, Zhenjiang Jin, Guanzhou Chen, Yinan He, Zhangwei Gao, Erfei Cui, et al. Omnicorpus: 一个包含百亿级别图像与文本交织的统一多模态语料库。ArXiv 预印本, abs/2406.08418, 2024a. 链接 https://arxiv.org/abs/2406.08418.
Tao Li, Gang Li, Zhiwei Deng, Bryan Wang, and Yang Li. A zero-shot language agent for computer control with structured refection. In Houda Bouamor, Juan Pino, and Kalika Bali (eds.), Findings of the Association for Computational Linguistics: EMNLP 2023, pp. 11261-11274, Singapore, 2023b. Association for Computational Linguistics. doi: 10.18653/v1/2023.findings-emnlp.753. URL ht tps : //a cl anthology.org/2023.findings-emnlp.753.
Tao Li, Gang Li, Zhiwei Deng, Bryan Wang, and Yang Li. 用于计算机控制的零样本语言智能体与结构化反思。In Houda Bouamor, Juan Pino, and Kalika Bali (eds.), 计算语言学协会发现: EMNLP 2023, pp. 11261-11274, 新加坡, 2023b. 计算语言学协会. doi: 10.18653/v1/2023.findings-emnlp.753. URL https://acl anthology.org/2023.findings-emnlp.753.
Tao Li, Gang Li, Jingjie Zheng, Purple Wang, and Yang Li. MUG: Interactive multimodal grounding on user interfaces. In Yvette Graham and Matthew Purver (eds.), Findings of the Association for Computational Linguistics: EACL 2024, pp. 231-251, St. Julian's, Malta, 2024b. Association for Computational Linguistics. URL https: //a cl anthology.org/2024.findings-eacl.17.
Tao Li, Gang Li, Jingjie Zheng, Purple Wang, 和 Yang Li. MUG: 用户界面上的交互式多模态 grounding. 在 Yvette Graham 和 Matthew Purver (eds.), 《计算语言学协会发现: EACL 2024》, 第 231-251 页, 马耳他圣朱利安, 2024b. 计算语言学协会. URL https: //a cl anthology.org/2024.findings-eacl.17.
Wei Li, William E Bishop, Alice Li, Christopher Rawles, Folawiyo Campbell-Ajala, Divya T yama gund lu, and Oriana Riva. On the effects of data scale on UI control agents. In The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024c. URL ht t ps : / / openreview . net/forum?id=yUEBXN3cvX.
Wei Li, William E Bishop, Alice Li, Christopher Rawles, Folawiyo Campbell-Ajala, Divya T yama gund lu, 和 Oriana Riva. 数据规模对UI控制智能体 (UI Control Agents) 的影响研究. 在第三十八届神经信息处理系统会议数据集与基准赛道 (The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track), 2024c. URL https://openreview.net/forum?id=yUEBXN3cvX.
Yang Li, Jiacong He, Xin Zhou, Yuan Zhang, and Jason Baldridge. Mapping natural language instructions to mobile UI action sequences. In Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault (eds.), Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 8198-8210, Online, 2020a. Association for Computational Linguistics. doi: 10.18653/v1/2020.acl-main.729. URL https://a cl anthology.0rg/2020.acl-main.729.
Yang Li, Jiacong He, Xin Zhou, Yuan Zhang, and Jason Baldridge. 将自然语言指令映射到移动UI操作序列。载于 Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault (编), 第58届计算语言学协会年会论文集, 页8198-8210, 在线, 2020a. 计算语言学协会. doi: 10.18653/v1/2020.acl-main.729. URL https://a cl anthology.0rg/2020.acl-main.729.
Yang Li, Gang Li, Luheng He, Jingjie Zheng, Hong Li, and Zhiwei Guan. Widget captioning: Generating natural language description for mobile user interface elements. In Bonnie Webber, Trevor Cohn, Yulan He, and Yang Liu (eds.), Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 5495-5510, Online, 2020b. Association for Computational Linguistics. doi: 10. 18653/v1/2020.emnlp-main.443. URL https : / /aclanthology.0rg/2020 .emnlp-main. 443.
Yang Li, Gang Li, Luheng He, Jingjie Zheng, Hong Li, and Zhiwei Guan. 移动用户界面元素自然语言描述生成. In Bonnie Webber, Trevor Cohn, Yulan He, and Yang Liu (eds.), 2020年自然语言处理实证方法会议论文集 (EMNLP), pp. 5495-5510, 在线, 2020b. 计算语言学协会. doi: 10.18653/v1/2020.emnlp-main.443. URL https://aclanthology.org/2020.emnlp-main.443.
Kevin Qinghong Lin, Linjie Li, Difei Gao, Zhengyuan Yang, Shiwei Wu, Zechen Bai, Weixian Lei, Lijuan Wang, and Mike Zheng Shou. Showui: One vision-language-action model for gui visual agent, 2024a. URL https: //arxiv.0rg/abs/2411.17465.
Kevin Qinghong Lin, Linjie Li, Difei Gao, Zhengyuan Yang, Shiwei Wu, Zechen Bai, Weixian Lei, Lijuan Wang, 和 Mike Zheng Shou. Showui: 一个视觉-语言-动作模型的GUI视觉智能体, 2024a. URL https://arxiv.org/abs/2411.17465.
Qinghong Lin, Linjie Li, Difei Gao, Zhengyuan Yang, Shiwei Wu, Zechen Bai, Weixian Lei, Lijuan Wang, and Mike Zheng Shou. Showui: One vision-language-action model for gui visual agent. arXiv e-prints, pp. arXiv-2411, 2024b.
Qinghong Lin, Linjie Li, Difei Gao, Zhengyuan Yang, Shiwei Wu, Zechen Bai, Weixian Lei, Lijuan Wang, 和 Mike Zheng Shou. Showui: 一种用于 GUI 视觉智能体的视觉-语言-动作模型. arXiv e-prints, pp. arXiv-2411, 2024b.
Evan Zheran Liu, Kelvin Guu, Panupong Pasupat, Tianlin Shi, and Percy Liang. Reinforcement learning on web interfaces using workflow-guided exploration. In 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings. OpenReview.net, 2018. URL https : / /openreview.net / forum?id=ryTp3f-0-.
Evan Zheran Liu, Kelvin Guu, Panupong Pasupat, Tianlin Shi, and Percy Liang. 基于工作流引导探索的网页界面强化学习. 在第六届国际学习表征会议, ICLR 2018, 加拿大不列颠哥伦比亚省温哥华, 2018年4月30日至5月3日, 会议论文集. OpenReview.net, 2018. URL https://openreview.net/forum?id=ryTp3f-0-.
Junpeng Liu, Tianyue Ou, Yifan Song, Yuxiao Qu, Wai Lam, Chenyan Xiong, Wenhu Chen, Graham Neubig, and Xiang Yue. Harnessing webpage uis for text-rich visual understanding. arXiv preprint arXiv:2410.13824, 2024a.
Junpeng Liu, Tianyue Ou, Yifan Song, Yuxiao Qu, Wai Lam, Chenyan Xiong, Wenhu Chen, Graham Neubig, 和 Xiang Yue. 利用网页UI进行文本丰富的视觉理解. arXiv预印本 arXiv:2410.13824, 2024a.
Junpeng Liu, Tianyue Ou, Yifan Song, Yuxiao Qu, Wai Lam, Chenyan Xiong, Wenhu Chen, Graham Neubig, and Xiang Yue. Harnessing webpage uis for text-rich visual understanding, 2024b. URL ht tpS : //arxiv.0rg/abs/2410.13824.
Junpeng Liu, Tianyue Ou, Yifan Song, Yuxiao Qu, Wai Lam, Chenyan Xiong, Wenhu Chen, Graham Neubig, and Xiang Yue. 利用网页用户界面进行文本丰富的视觉理解, 2024b. URL ht tpS : //arxiv.0rg/abs/2410.13824.
Junpeng Liu, Yifan Song, Bill Yuchen Lin, Wai Lam, Graham Neubig, Yuanzhi Li, and Xiang Yue. Visualwebbench: How far have multimodal llms evolved in web page understanding and grounding? ArXiv preprint, abs/2404.05955, 2024c. URL https : / /arxiv . 0rg / abs /24 04 . 05 955.
Junpeng Liu, Yifan Song, Bill Yuchen Lin, Wai Lam, Graham Neubig, Yuanzhi Li, 和 Xiang Yue. Visualwebbench: 多模态大语言模型在网页理解与落地中的进展如何?ArXiv 预印本, abs/2404.05955, 2024c. URL https://arxiv.org/abs/2404.05955.
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. In European Conference on Computer Vision, pp. 38-55. Springer, 2025.
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su 等。Grounding dino: 将 DINO 与接地预训练结合用于开放集目标检测。在欧洲计算机视觉会议上,第 38-55 页。Springer, 2025。
Quanfeng Lu, Wenqi Shao, Zitao Liu, Fanqing Meng, Boxuan Li, Botong Chen, Siyuan Huang, Kaipeng Zhang, Yu Qiao, and Ping Luo. Gui odysey: A comprehensive dataset for cross-app gui navigation on mobile devices. ArXiv preprint, abs/2406.08451, 2024a. URL https : / /arxiv . 0rg / abs /2 40 6 . 08451.
Quanfeng Lu, Wenqi Shao, Zitao Liu, Fanqing Meng, Boxuan Li, Botong Chen, Siyuan Huang, Kaipeng Zhang, Yu Qiao, and Ping Luo. Gui odysey: 移动设备跨应用程序 GUI 导航的综合数据集. ArXiv 预印本, abs/2406.08451, 2024a. URL https://arxiv.org/abs/2406.08451.
Yadong Lu, Jianwei Yang, Yelong Shen, and Ahmed Awadallah. Omniparser for pure vision based gui agent. ArXiv preprint, abs/2408.00203, 2024b. URL https : / /arxiv . 0rg /abs /2408 . 00203.
Yadong Lu, Jianwei Yang, Yelong Shen, Ahmed Awadallah. 基于纯视觉 GUI 智能体的 Omniparser. ArXiv 预印本, abs/2408.00203, 2024b. URL https://arxiv.org/abs/2408.00203.
Xinbei Ma, Zhuosheng Zhang, and Hai Zhao. Comprehensive cognitive llm agent for smartphone gui automation. ArXiv preprint, abs/2402.11941, 2024. URL https : / /arxiv.0rg /abs /2402 .11941.
Xinbei Ma, Zhuosheng Zhang, 和 Hai Zhao. 智能手机 GUI 自动化的全面认知大语言模型智能体. ArXiv 预印本, abs/2402.11941, 2024. URL https://arxiv.org/abs/2402.11941.
Sahisnu Mazumder and Oriana Riva. FLIN: A flexible natural language interface for web navigation. In Kristina Toutanova, Anna Rumshisky, Luke Z ett le moyer, Dilek Hakkani-Tur, Iz Beltagy, Steven Bethard, Ryan Cotterell, Tanmoy Chakra bor ty, and Yichao Zhou (eds.), Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 2777-2788, Online, 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.naacl-main. 222. URL https://a cl anthology.0rg/2021.naacl-main.222.
Sahisnu Mazumder 和 Oriana Riva. FLIN: 一种灵活的网页导航自然语言接口. In Kristina Toutanova, Anna Rumshisky, Luke Zettlemoyer, Dilek Hakkani-Tur, Iz Beltagy, Steven Bethard, Ryan Cotterell, Tanmoy Chakraborty, and Yichao Zhou (eds.), 2021年北美计算语言学协会人类语言技术会议论文集, pp. 2777-2788, 在线, 2021. 计算语言学协会. doi: 10.18653/v1/2021.naacl-main.222. URL https://aclanthology.org/2021.naacl-main.222.
Kai Mei, Zelong Li, Shuyuan Xu, Ruosong Ye, Yingqiang Ge, and Yongfeng Zhang. Aios: Llm agent operating system. arXiv e-prints, pp. arXiv-2403, 2024.
Kai Mei, Zelong Li, Shuyuan Xu, Ruosong Ye, Yingqiang Ge, and Yongfeng Zhang. AIOS: 大语言模型 AI智能体操作系统. arXiv e-prints, pp. arXiv-2403, 2024.
A. Memon, I. Banerjee, N. Hashmi, and A. Nagarajan. Dart: a framework for regression testing "nightly/daily builds" of gui applications. In International Conference on Software Maintenance, 2003. ICSM 2003. Proceedings., Pp. 410-419, 2003. doi: 10.1109/ICSM.2003.1235451.
A. Memon, I. Banerjee, N. Hashmi, 和 A. Nagarajan. Dart: 一个用于回归测试 GUI 应用程序“每晚/每日构建”的框架。在《国际软件维护会议》中,2003年。ICSM 2003. 会议录., 第410-419页, 2003. doi: 10.1109/ICSM.2003.1235451.
Reichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, et al. Webgpt: Browser-assisted question-answering with human feedback. ArXiv preprint, abs/2112.09332, 2021. URL https : / /arxiv. org /abs /2112. 09332.
Reichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders 等。WebGPT: 基于浏览器辅助的问答与人类反馈。ArXiv 预印本,abs/2112.09332,2021。URL https://arxiv.org/abs/2112.09332。
Dang Nguyen, Jian Chen, Yu Wang, Gang Wu, Namyong Park, Zhengmian Hu, Hanjia Lyu, Junda Wu, Ryan Aponte, Yu Xia, et al. Gui agents: A survey. ArXiv preprint, abs/2412.13501, 2024. URL ht tps : / /arxiv.0rg/abs /2412.13501.
Dang Nguyen, Jian Chen, Yu Wang, Gang Wu, Namyong Park, Zhengmian Hu, Hanjia Lyu, Junda Wu, Ryan Aponte, Yu Xia 等. GUI 智能体:综述. ArXiv 预印本, abs/2412.13501, 2024. URL https://arxiv.org/abs/2412.13501.
OpenAl. Gpt-3.5. https: //platform.openai.com/docs/models#gpt-3-5-turbo,2022.
OpenAl. Gpt-3.5. https://platform.openai.com/docs/models#gpt-3-5-turbo, 2022.
OpenAI. Gpt-4v(ision) system card. https: / /cdn. openai.com/papers /GP TV System Card. pdf,2023a.
OpenAI. Gpt-4v(ision) 系统卡. https://cdn.openai.com/papers/GPTV_System_Card.pdf, 2023a.
OpenAI. Gpt-4 technical report, 2023b
OpenAI. Gpt-4 技术报告, 2023b
Pranav Putta, Edmund Mills, Naman Garg, Sumeet Motwani, Chelsea Finn, Divyansh Garg, and Rafael Rafailov. Agent q: Advanced reasoning and learning for autonomous ai agents. ArXiv preprint, abs/2408.07199, 2024. URL https : / /arxiv.0rg /abs /2408 .07199.
Pranav Putta, Edmund Mills, Naman Garg, Sumeet Motwani, Chelsea Finn, Divyansh Garg, and Rafael Rafailov. Agent q: 自主AI智能体的高级推理与学习. ArXiv preprint, abs/2408.07199, 2024. URL https://arxiv.org/abs/2408.07199.
Ju Qian, Zhengyu Shang, Shuoyan Yan, Yan Wang, and Lin Chen. Roscript: A visual script driven truly non-intrusive robotic testing system for touch screen applications. In 2020 IEEE/ACM 42nd International Conference on Software Engineering (ICSE), pp. 297-308, 2020.
Ju Qian, Zhengyu Shang, Shuoyan Yan, Yan Wang, Lin Chen. Roscript: 一种视觉脚本驱动的真正非侵入式触摸屏应用机器人测试系统. 发表于2020年 IEEE/ACM 第42届国际软件工程会议 (ICSE), 第297-308页, 2020.
Yujia Qin, Shengding Hu, Yankai Lin, Weize Chen, Ning Ding, Ganqu Cui, Zheni Zeng, Xuanhe Zhou, Yufei Huang, Chaojun Xiao, Chi Han, Yi Ren Fung, Yusheng Su, Huadong Wang, Cheng Qian, Runchu Tian, Kunlun Zhu, Shihao Liang, Xingyu Shen, Bokai Xu, Zhen Zhang, Yining Ye, Bowen Li, Ziwei Tang, Jing Yi, Yuzhang Zhu, Zhenning Dai, Lan Yan, Xin Cong, Yaxi Lu, Weilin Zhao, Yuxiang Huang, Junxi Yan, Xu Han, Xian Sun, Dahai Li, Jason Phang, Cheng Yang, Tongshuang Wu, Heng Ji, Guoliang Li, Zhiyuan Liu, and Maosong Sun. Tool learning with foundation models. ACM Comput. Surv., 57(4), 2024. ISSN 0360-0300. doi: 10.1145/3704435. URL https : / /doi . 0rg/10 .1145 /3704435.
Yujia Qin, Shengding Hu, Yankai Lin, Weize Chen, Ning Ding, Ganqu Cui, Zheni Zeng, Xuanhe Zhou, Yufei Huang, Chaojun Xiao, Chi Han, Yi Ren Fung, Yusheng Su, Huadong Wang, Cheng Qian, Runchu Tian, Kunlun Zhu, Shihao Liang, Xingyu Shen, Bokai Xu, Zhen Zhang, Yining Ye, Bowen Li, Ziwei Tang, Jing Yi, Yuzhang Zhu, Zhenning Dai, Lan Yan, Xin Cong, Yaxi Lu, Weilin Zhao, Yuxiang Huang, Junxi Yan, Xu Han, Xian Sun, Dahai Li, Jason Phang, Cheng Yang, Tongshuang Wu, Heng Ji, Guoliang Li, Zhiyuan Liu, and Maosong Sun. 基于基础模型的工具学习。ACM Comput. Surv., 57(4), 2024. ISSN 0360-0300. doi: 10.1145/3704435. URL https://doi.org/10.1145/3704435.
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D. Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine (eds.), Advances in Neural Information Processing Systems 36:Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 -16, 2023, 2023. URL http://papers.nips.cc/paper files/paper/2023/hash/ a 85 b 405 ed 65 c 6477 a 4 fe 8302 b 5 e 06 ce 7-Abstract-Conference.html.
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D. Manning, Stefano Ermon, 和 Chelsea Finn. 直接偏好优化:你的语言模型实际上是一个奖励模型。在 Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, 和 Sergey Levine (eds.) 编著的《神经信息处理系统进展 36: 2023 年神经信息处理系统年度会议》, NeurIPS 2023, 美国路易斯安那州新奥尔良, 2023 年 12 月 10 -16 日, 2023. URL http://papers.nips.cc/paper files/paper/2023/hash/ a 85 b 405 ed 65 c 6477 a 4 fe 8302 b 5 e 06 ce 7-Abstract-Conference.html.
Hari pra sau th Rama moor thy, Shubhankar Gupta, and Suresh Sundaram. Distributed online life-long learning (dol3) for multi-agent trust and reputation assessment in e-commerce. ArXiv preprint, abs/2410.16529, 2024. URL https: / /arxiv.0rg/abs/2410.16529.
Hari Pra Sau Th Rama Moor Thy, Shubhankar Gupta, 和 Suresh Sundaram. 电子商务中多智能体信任与声誉评估的分布式在线终身学习 (DOL3). ArXiv 预印本, abs/2410.16529, 2024. URL https://arxiv.org/abs/2410.16529.
Christopher Rawles, Alice Li, Daniel Rodriguez, Oriana Riva, and Timothy P. Lillicrap. Android in the wild: A large-scale dataset for android device control. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine (eds.), Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023,2023. URL http://papers.nips.cc/paper files/paper/2023/hash/ bbbh6308h402fe909.39dd29950c32e0-Ahstract-Datasets and Benchmarks.html
Christopher Rawles, Alice Li, Daniel Rodriguez, Oriana Riva, 和 Timothy P. Lillicrap. Android in the wild: A large-scale dataset for android device control. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, 和 Sergey Levine (eds.), Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, 2023. URL http://papers.nips.cc/paper files/paper/2023/hash/ bbbh6308h402fe909.39dd29950c32e0-Ahstract-Datasets and Benchmarks.html
Christopher Rawles, Sarah Cl in ck email lie, Yifan Chang, Jonathan Waltz, Gabrielle Lau, Marybeth Fair, Alice Li, William Bishop, Wei Li, Folawiyo Campbell-Ajala, Daniel Toyama, Robert Berry, Divya T yama gund lu, Timothy Lillicrap, and Oriana Riva. Android world: A dynamic benchmarking environment for autonomous agents, 2024a. URL https: / /arxiv.0rg /abs /2405.14573.
Christopher Rawles, Sarah Clinckemailie, Yifan Chang, Jonathan Waltz, Gabrielle Lau, Marybeth Fair, Alice Li, William Bishop, Wei Li, Folawiyo Campbell-Ajala, Daniel Toyama, Robert Berry, Divya Tyamagundlu, Timothy Lillicrap, 和 Oriana Riva. Android world: 一个用于自主AI智能体的动态基准测试环境, 2024a. URL https://arxiv.org/abs/2405.14573.
Christopher Rawles, Sarah Cl in ck email lie, Yifan Chang, Jonathan Waltz, Gabrielle Lau, Marybeth Fair, Alice Li, William Bishop, Wei Li, Folawiyo Campbell-Ajala, et al. Android world: A dynamic benchmarking environment for autonomous agents. ArXiv preprint, abs/2405.14573, 2024b. URL ht t ps : / / arxi v . 0rg/abs /2405.14573.
Christopher Rawles, Sarah Cl in ck email lie, Yifan Chang, Jonathan Waltz, Gabrielle Lau, Marybeth Fair, Alice Li, William Bishop, Wei Li, Folawiyo Campbell-Ajala, 等. Android world: 一个用于自主AI智能体的动态基准测试环境. ArXiv 预印本, abs/2405.14573, 2024b. URL https://arxiv.org/abs/2405.14573.
Matthew Renze and Erhan Guven. Self-reflection in llm agents: Effects on problem-solving performance, 2024. URL https: //arxiv.0rg/abs /2405.06682.
Matthew Renze 和 Erhan Guven. 大语言模型中 AI 智能体的自我反思:对问题解决性能的影响, 2024. URL https://arxiv.org/abs/2405.06682.
Tianlin Shi, Andrej Karpathy, Linxi Fan, Jonathan Hernandez, and Percy Liang. World of bits: An opendomain platform for web-based agents. In Doina Precup and Yee Whye Teh (eds.), Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6-11 August 2017, volume 70 of Proceedings of Machine Learning Research, pp. 3135-3144. PMLR, 2017. URL http://proceedings.mlr.press/v70/shil7a.html.
Tianlin Shi, Andrej Karpathy, Linxi Fan, Jonathan Hernandez, 和 Percy Liang. World of bits: An open-domain platform for web-based agents. 在 Doina Precup 和 Yee Whye Teh (编), 第 34 届国际机器学习会议 (ICML 2017) 论文集, 2017 年 8 月 6-11 日, 澳大利亚新南威尔士州悉尼, 第 70 卷, 机器学习研究论文集, 第 3135-3144 页. PMLR, 2017. URL http://proceedings.mlr.press/v70/shil7a.html.
Noah Shinn, Beck Labash, and Ashwin Gopinath. Reflexion: an autonomous agent with dynamic memory and self-refection. ArXiv preprint, abs/2303.11366, 2023. URL https : / /arxiv . 0rg /abs /23 03 . 11366.
Noah Shinn、Beck Labash 和 Ashwin Gopinath。Reflexion:具有动态记忆和自我反思能力的自主代理。ArXiv 预印本,abs/2303.11366,2023。URL https://arxiv.org/abs/2303.11366。
Andrea Soltoggio, Eseoghene Ben-Iwhiwhu, Vladimir Braverman, Eric Eaton, Benjamin Epstein, Yunhao Ge, Lucy Halperin, Jonathan How, Laurent Itti, Michael A Jacobs, et al. A collective ai via lifelong learning and sharing at the edge. Nature Machine Intelligence, 6(3):251-264, 2024.
Andrea Soltoggio, Eseoghene Ben-Iwhiwhu, Vladimir Braverman, Eric Eaton, Benjamin Epstein, Yunhao Ge, Lucy Halperin, Jonathan How, Laurent Itti, Michael A Jacobs 等. 一种通过边缘终身学习和共享的集体 AI. Nature Machine Intelligence, 6(3):251-264, 2024.
Chan Hee Song, Brian M. Sadler, Jiaman Wu, Wei-Lun Chao, Clayton Washington, and Yu Su. Llm-planner: Few-shot grounded planning for embodied agents with large language models. In IEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023, pp. 2986-2997. IEEE, 2023. doi: 10.1109/ICCV51070.2023.00280. URL https : / /doi.org/10.1109/ICCV51070 . 2023.00280.
Chan Hee Song, Brian M. Sadler, Jiaman Wu, Wei-Lun Chao, Clayton Washington, 和 Yu Su. LLM-Planner: 基于大语言模型的少样本接地规划用于具身智能体. 在 IEEE/CVF 国际计算机视觉会议, ICCV 2023, 法国巴黎, 10月1-6日, 2023, 第 2986-2997 页. IEEE, 2023. doi: 10.1109/ICCV51070.2023.00280. URL https://doi.org/10.1109/ICCV51070.2023.00280.
Yueqi Song, Frank F Xu, Shuyan Zhou, and Graham Neubig. Beyond browsing: Api-based web agents. 2024.
Yueqi Song, Frank F Xu, Shuyan Zhou, 和 Graham Neubig。超越浏览:基于 API 的网页智能体。2024。
Srinivas Sunkara, Maria Wang, Lijuan Liu, Gilles Baechler, Yu-Chung Hsiao, Jindong Chen, Abhanshu Sharma, and James W. W. Stout. Towards better semantic understanding of mobile interfaces. In Nicoletta Calzolari, Chu-Ren Huang, Hansaem Kim, James Pus te j ov sky, Leo Wanner, Key-Sun Choi, Pum-Mo Ryu, Hsin-Hsi Chen, Lucia Donatelli, Heng Ji, Sadao Kurohashi, Patrizia Paggio, Nianwen Xue, Seokhwan Kim, Younggyun Hahm, Zhong He, Tony Kyungil Lee, Enrico Santus, Francis Bond, and Seung-Hoon Na (eds.), Proceedings of the 29th International Conference on Computational Linguistics, pp. 5636-5650, Gyeongju, Republic of Korea, 2022. International Committee on Computational Linguistics. URL ht t p s : //a cl anthology.0rg/2022.coling-1.497.
Srinivas Sunkara, Maria Wang, Lijuan Liu, Gilles Baechler, Yu-Chung Hsiao, Jindong Chen, Abhanshu Sharma, 和 James W. W. Stout。迈向更好的移动界面语义理解。在 Nicoletta Calzolari, Chu-Ren Huang, Hansaem Kim, James Pustejovsky, Leo Wanner, Key-Sun Choi, Pum-Mo Ryu, Hsin-Hsi Chen, Lucia Donatelli, Heng Ji, Sadao Kurohashi, Patrizia Paggio, Nianwen Xue, Seokhwan Kim, Younggyun Hahm, Zhong He, Tony Kyungil Lee, Enrico Santus, Francis Bond, 和 Seung-Hoon Na (eds.) 编著的《第29届国际计算语言学会议论文集》中,第5636-5650页,韩国庆州,2022年。国际计算语言学委员会。URL https://aclanthology.org/2022.coling-1.497。
Indranil Sur, Zachary Daniels, Abrar Rahman, Kamil Faber, Gianmarco Gallardo, Tyler Hayes, Cameron Taylor, Mustafa Burak Gurbuz, James Smith, Sahana Joshi, et al. System design for an integrated lifelong reinforcement learning agent for real-time strategy games. In Proceedings of the Second International Conference on AI-ML Systems, pp. 1-9, 2022.
Indranil Sur, Zachary Daniels, Abrar Rahman, Kamil Faber, Gianmarco Gallardo, Tyler Hayes, Cameron Taylor, Mustafa Burak Gurbuz, James Smith, Sahana Joshi, 等. 实时战略游戏中集成终身强化学习智能体的系统设计. 第二届人工智能-机器学习系统国际会议论文集, 第 1-9 页, 2022.
Weihao Tan, Ziluo Ding, Wentao Zhang, Boyu Li, Bohan Zhou, Junpeng Yue, Haochong Xia, Jiechuan Jjiang, Longtao Zheng, Xinrun Xu, et al. Towards general computer control: A multimodal agent for red dead redemption i as a case study. In ICLR 2024 Workshop on Large Language Model (LLM) Agents, 2024.
Weihao Tan, Ziluo Ding, Wentao Zhang, Boyu Li, Bohan Zhou, Junpeng Yue, Haochong Xia, Jiechuan Jjiang, Longtao Zheng, Xinrun Xu, et al. 迈向通用计算机控制:以《荒野大镖客》为例的多模态智能体。在 ICLR 2024 大语言模型 (LLM) 智能体研讨会上,2024。
Heyi Tao, Sethuraman TV, Michal Shl a pen to kh-Rothman, and Derek Hoiem. Webwise: Web interface control and sequential exploration with large language models. ArXiv preprint, abs/2310.16042, 2023. URL https: //arxiv.0rg/abs/2310.16042.
He Tao, Sethuraman TV, Michal Shl a pen to kh-Rothman, 和 Derek Hoiem. Webwise: 大语言模型的网页界面控制与顺序探索. ArXiv 预印本, abs/2310.16042, 2023. URL https://arxiv.org/abs/2310.16042.
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. ArXiv preprint, abs/2403.05530, 2024. URL https : / / arxiv . org /abs / 24 03 . 05530.
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, 等. Gemini 1.5: 解锁跨数百万Token上下文的多模态理解. ArXiv 预印本, abs/2403.05530, 2024. URL https://arxiv.org/abs/2403.05530.
Bryan Wang, Gang Li, and Yang Li. Enabling conversational interaction with mobile UI using large language models. In Albrecht Schmidt, Kaisa Vaananen, Tesh Goyal, Per Ola Kristen s son, Anicia Peters, Stefanie Mueller, Julie R. Williamson, and Max L. Wilson (eds.), Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems, CHI 2023, Hamburg, Germany, April 23-28, 2023, pp. 432:1- 432:17. ACM, 2023. doi: 10.1145/3544548.3580895. URL https : / /doi . 0rg /10 .1145 /3544548 . 3580895.
Bryan Wang, Gang Li, 和 Yang Li. 使用大语言模型实现与移动 UI 的对话交互. 在 Albrecht Schmidt, Kaisa Vaananen, Tesh Goyal, Per Ola Kristensson, Anicia Peters, Stefanie Mueller, Julie R. Williamson, 和 Max L. Wilson (编), 2023 年 CHI 计算系统人因会议论文集, CHI 2023, 德国汉堡, 2023 年 4 月 23-28 日, 第 432:1-432:17 页. ACM, 2023. doi: 10.1145/3544548.3580895. URL https://doi.org/10.1145/3544548.3580895.
Junyang Wang, Haiyang Xu, Jiabo Ye, Ming Yan, Weizhou Shen, Ji Zhang, Fei Huang, and Jitao Sang. Mobile-agent: Autonomous multi-modal mobile device agent with visual perception. ArXiv preprint, abs/2401.16158, 2024a. URL https : / /arxiv. 0rg/abs /2401.16158.
Junyang Wang, Haiyang Xu, Jiabo Ye, Ming Yan, Weizhou Shen, Ji Zhang, Fei Huang, and Jitao Sang. Mobile-agent: 具有视觉感知的自主多模态移动设备 AI智能体. ArXiv 预印本, abs/2401.16158, 2024a. URL https://arxiv.org/abs/2401.16158.
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang. Xu Chen, Yankai Lin, et al. A survey on large language model based autonomous agents. Frontiers of Computer Science, 18(6):186345, 2024b.
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, 等. 基于大语言模型的自主AI智能体研究综述. 计算机科学前沿, 18(6):186345, 2024b.
Peng Wang, Shuai Bai, Sinan Tan, Shije Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. Qwen2-vl: Enhancing vision-language model's perception of the world at any resolution, 2024c. URL https : / /arxiv.0rg/abs /2409.12191.
Wang, Shuai Bai, Sinan Tan, Shije Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. Qwen2-vl: 提升视觉语言模型对任意分辨率的感知能力, 2024c. URL https://arxiv.org/abs/2409.12191.
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model's perception of the world at any resolution. ArXiv preprint, abs/2409.12191, 2024d. URL https : / /arxiv . 0rg /abs /24 0 9 . 12191.
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, 等. Qwen2-vl: 提升视觉语言模型在任何分辨率下对世界的感知能力. ArXiv 预印本, abs/2409.12191, 2024d. URL https://arxiv.org/abs/2409.12191.
Shuai Wang, Weiwen Liu, Jingxuan Chen, Weinan Gan, Xingshan Zeng, Shuai Yu, Xinlong Hao, Kun Shao, Yasheng Wang, and Ruiming Tang. Gui agents with foundation models: A comprehensive survey. ArXiv preprint, abs/2411.04890, 2024e. URL https : / /arxiv .0rg /abs /2411. 04890.
Shuai Wang, Weiwen Liu, Jingxuan Chen, Weinan Gan, Xingshan Zeng, Shuai Yu, Xinlong Hao, Kun Shao, Yasheng Wang, and Ruiming Tang. 基于基础模型的 GUI 智能体:全面综述. ArXiv 预印本, abs/2411.04890, 2024e. URL https://arxiv.org/abs/2411.04890.
Xiaoqiang Wang and Bang Liu. Oscar: Operating system control via state-aware reasoning and re-planning. ArXiv preprint, abs/2410.18963, 2024. URL https : / / arxiv . 0rg / abs /2410 .18963.
Xiaoqiang Wang 和 Bang Liu. Oscar: 通过状态感知推理和重新规划实现操作系统控制. ArXiv 预印本, abs/2410.18963, 2024. URL https : / / arxiv . 0rg / abs /2410 .18963.
Zilong Wang, Yuedong Cui, Li Zhong, Zimin Zhang, Da Yin, Bill Yuchen Lin, and Jingbo Shang. Offcebench: Benchmarking language agents across multiple applications for office automation, 2024f. URL ht t ps : //arxiv.0rg/abs/2407.19056.
Zilong Wang, Yuedong Cui, Li Zhong, Zimin Zhang, Da Yin, Bill Yuchen Lin, and Jingbo Shang. Offcebench: 跨多应用的语言智能体办公自动化基准测试, 2024f. URL ht t ps : //arxiv.0rg/abs/2407.19056.
Zora Zhiruo Wang, Jiayuan Mao, Daniel Fried, and Graham Neubig. Agent workflow memory. ArXiv preprint, abs/2409.07429, 2024g. URL https : / /arxiv. 0rg /abs /2409 . 07429.
Zora Zhiruo Wang, Jiayuan Mao, Daniel Fried, 和 Graham Neubig. AI智能体工作流记忆. ArXiv 预印本, abs/2409.07429, 2024g. URL https://arxiv.org/abs/2409.07429.
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. In Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh (eds.), Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, 和 Denny Zhou。思维链提示激发大语言模型中的推理。在 Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Belgrave, K. Cho, 和 A. Oh (编), 《神经信息处理系统进展 35: 2022 年神经信息处理系统年会, NeurIPS 2022》, 美国路易斯安那州新奥尔良, 11 月 28 日
December9,2022,2022.URL http: / /papers.nips.cc /paper files /paper/2022/hash/ 9 d 5609613524 ecf 4 f 15 af 0 f 7 b 31 abc a 4-Abstract-Conference.html.
2022年12月9日. URL http: / /papers.nips.cc /paper files /paper/2022/hash/ 9 d 5609613524 ecf 4 f 15 af 0 f 7 b 31 abc a 4-Abstract-Conference.html.
Hao Wen, Hongming Wang, Jiaxuan Liu, and Yuanchun Li. Droidbot-gpt: Gpt-powered ui automation for android. ArXiv preprint, abs/2304.07061, 2023. URL https : / / arxiv . 0rg / abs /2304 . 0 70 61.
Hao Wen, Hongming Wang, Jiaxuan Liu, 和 Yuanchun Li. Droidbot-gpt: GPT驱动的Android UI自动化. ArXiv preprint, abs/2304.07061, 2023. URL https://arxiv.org/abs/2304.07061.
Zhiyong Wu, Chengcheng Han, Zichen Ding, Zhenmin Weng, Zhoumianze Liu, Shunyu Yao, Tao Yu, and Lingpeng Kong. Os-copilot: Towards generalist computer agents with self-improvement. ArXiv preprint, abs/2402.07456, 2024a. URL https : / /arxiv. 0rg /abs /2402 . 07456.
吴志勇、韩成成、丁子辰、翁振民、刘周勉泽、姚顺宇、于涛和孔令鹏。Os-copilot:通过自我改进实现通用计算机智能体。ArXiv 预印本,abs/2402.07456,2024a。URL https://arxiv.org/abs/2402.07456。
Zhiyong Wu, Zhenyu Wu, Fangzhi Xu, Yian Wang, Qiushi Sun, Chengyou Jia, Kanzhi Cheng, Zichen Ding, Liheng Chen, Paul Pu Liang, et al. Os-atlas: A foundation action model for generalist gui agents. ArXiv preprint, abs/2410.23218, 2024b. URL https : / /arxiv.0rg /abs /2410 .23218.
Zhiyong Wu, Zhenyu Wu, Fangzhi Xu, Yian Wang, Qiushi Sun, Chengyou Jia, Kanzhi Cheng, Zichen Ding, Liheng Chen, Paul Pu Liang, et al. Os-atlas: 通用 GUI 智能体的基础动作模型. ArXiv 预印本, abs/2410.23218, 2024b. URL https://arxiv.org/abs/2410.23218.
Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, Ming Zhang, Junzhe Wang, Senjie Jin, Enyu Zhou, et al. The rise and potential of large language model based agents: A survey. ArXiv preprint, abs/2309.07864, 2023. URL https : / /arxiv . 0rg /abs /2309 . 07864.
Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, Ming Zhang, Junzhe Wang, Senjie Jin, Enyu Zhou, et al. 基于大语言模型的智能体的崛起与潜力:综述。ArXiv 预印本,abs/2309.07864,2023。URL https://arxiv.org/abs/2309.07864。
Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang. Agentless: De mystifying llm-based software engineering agents. ArXiv preprint, abs/2407.01489, 2024. URL ht tps : / / arxiv . 0rg / ab s / 2407.01489.
Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang. Agentless: 揭秘基于大语言模型的软件工程AI智能体. ArXiv preprint, abs/2407.01489, 2024. URL https://arxiv.org/abs/2407.01489.
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, and Tao Yu. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments, 2024. URL https : / /arxiv.0rg /abs /2404. 07972.
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, and Tao Yu. Osworld: 在真实计算机环境中评估多模态智能体在开放任务中的表现, 2024. URL https://arxiv.org/abs/2404.07972.
Yiheng Xu, Zekun Wang, Junli Wang, Dunjie Lu, Tianbao Xie, Amrita Saha, Doyen Sahoo, Tao Yu, and Caiming Xiong. Aguvis: Unified pure vision agents for autonomous gui interaction. ArXiv preprint, abs/2412.04454, 2024. URL https : / /arxiv.0rg /abs /2412 .04454.
Yiheng Xu, Zekun Wang, Junli Wang, Dunjie Lu, Tianbao Xie, Amrita Saha, Doyen Sahoo, Tao Yu, and Caiming Xiong. Aguvis: 用于自主GUI交互的统一纯视觉智能体。ArXiv预印本, abs/2412.04454, 2024. URL https://arxiv.org/abs/2412.04454.
An Yan, Zhengyuan Yang, Wanrong Zhu, Kevin Lin, Linjie Li, Jianfeng Wang, Jianwei Yang, Yiwu Zhong, Julian McAuley, Jianfeng Gao, Zicheng Liu, and Lijuan Wang. Gpt-4v in wonderland: Large multimodal models for zero-shot smartphone gui navigation, 2023. URL https : / / arxiv . 0rg /abs /2311 . 075 62.
An Yan, Zhengyuan Yang, Wanrong Zhu, Kevin Lin, Linjie Li, Jianfeng Wang, Jianwei Yang, Yiwu Zhong, Julian McAuley, Jianfeng Gao, Zicheng Liu, 以及 Lijuan Wang. GPT-4V 的奇幻之旅:零样本智能手机 GUI 导航的大规模多模态模型, 2023. 网址 https://arxiv.org/abs/2311.07562.
Hui Yang, Sifu Yue, and Yunzhong He. Auto-gpt for online decision making: Benchmarks and additional opinions. ArXiv preprint, abs/2306.02224, 2023a. URL https : / / arxiv . 0rg / abs /230 6 . 02224.
Hui Yang, Sifu Yue, 和 Yunzhong He. Auto-GPT 用于在线决策:基准测试与附加意见. ArXiv 预印本, abs/2306.02224, 2023a. URL https://arxiv.org/abs/2306.02224.
Jianwei Yang, Hao Zhang, Feng Li, Xueyan Zou, Chunyuan Li, and Jianfeng Gao. Set-of-mark prompting unleashes extraordinary visual grounding in gpt-4v. ArXiv preprint, abs/2310.11441, 2023b. URL ht tps : //arxiv.0rg/abs/2310.11441.
Jianwei Yang, Hao Zhang, Feng Li, Xueyan Zou, Chunyuan Li, 和 Jianfeng Gao. Set-of-mark prompting unleashes extraordinary visual grounding in gpt-4v. ArXiv 预印本, abs/2310.11441, 2023b. URL ht tps : //arxiv.0rg/abs/2310.11441.
Yuhao Yang, Yue Wang, Dongxu Li, Ziyang Luo, Bei Chen, Chao Huang, and Junnan Li. Aria-ui: Visual grounding for gui instructions. ArXiv preprint, abs/2412.16256, 2024a. URL htt ps : / / arxi v . 0rg / abs /2412.16256.
Yuhao Yang, Yue Wang, Dongxu Li, Ziyang Luo, Bei Chen, Chao Huang, 和 Junnan Li. Aria-ui: 图形用户界面指令的视觉定位. ArXiv 预印本, abs/2412.16256, 2024a. URL https://arxiv.org/abs/2412.16256.
Zonghan Yang, Peng Li, Ming Yan, Ji Zhang, Fei Huang, and Yang Liu. React meets actre: When language agents enjoy training data autonomy, 2024b. URL https : / /arxiv . 0rg /abs / 2403 .1458 9.
杨宗翰, 李鹏, 严明, 张吉, 黄飞, 刘洋. React meets actre: 当语言智能体享受训练数据自主性, 2024b. URL https://arxiv.org/abs/2403.14589.
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Yuan Cao. React: Syne rg i zing reasoning and acting in language models. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023. URL https: / /openreview.net/pdf?id=WE_vluYUL-X.
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, 和 Yuan Cao. React: 在大语言模型中同步推理与行动. 在第十一届国际学习表示会议, ICLR 2023, 卢旺达基加利, 2023年5月1-5日. OpenReview.net, 2023. URL https://openreview.net/pdf?id=WE_vluYUL-X.
A Case Study
案例研究
We list a few cases executed by UI-TARS in Figure 9, Figure 10, Figure 11, and Figure 12.
我们在图 9、图 10、图 11 和图 12 中列出了 UI-TARS 执行的几个案例。

Figure 9: Test case on Ubuntu impress scene from UI-TARS. The task is: Make the background color of slide 2 same as the color of the title from slide 1.
图 9: 在 Ubuntu impress 场景中来自 UI-TARS 的测试案例。任务是:将幻灯片 2 的背景颜色设置为与幻灯片 1 的标题颜色相同。

Figure 10: Test case on Android from UI-TARS. The task is: Play the song under Mount Fuji
图 10: UI-TARS 在 Android 上的测试用例。任务是:播放富士山下的歌曲

Figure 11: Test case on Ubuntu VSCode scene from UI-TARS. The task is: Please help me install the auto Doc string extension inVs Code.
图 11: UI-TARS 在 Ubuntu VSCode 场景中的测试案例。任务是:请帮助我在 VSCode 中安装自动文档字符串扩展。

Figure 12: Test case on Windows chrome scene from UI-TARS. The task is: I want to show bookmarks bar by default in chrome.
图 12: 来自 UI-TARS 的 Windows Chrome 场景测试案例。任务是:我想在 Chrome 中默认显示书签栏。
B Data Example
B 数据示例
We show several data examples for perception training in Figure 13, Figure 14, Figure 15, and Figure 16.
我们在图13、图14、图15和图16中展示了一些用于感知训练的数据示例。

Input: Provide a detailed description of the_GUI screenshot, including all visible elements, layout, and styling.
输入:提供_GUI截图详细描述,包括所有可见元素、布局和样式。
Input:
输入:
Given two consecutive GUI screenshots, describe what has changed and what user interaction likely occurred between them, as if you were describing a scene transition in amovie.
给定两张连续的 GUI 截图,描述它们之间的变化以及用户可能进行的交互,就像描述电影中的场景转换一样。
Requirements:
需求:
Output: The first screenshot shows the interface of Creo Parametric 8.0 software (as indicated by the light gray text at the top center of the screen).On the left side,there is a window labeled "Model Tree" which lists multiple files and folders, including "TRAYOOO1.ASM","ASM_RIGHT", "ASM_TOP","ASM_FRONT","AS M DEF CS YS", and "TRAY_BOX". These files and folders are organized in a tree structure, showing the components of the current project. At the top of the interface is a toolbar with multiple tabs in the first row ("File","Tray"), and the second row contains various tool buttons such as "Printer", "Assemble", "Arrange on Tray", "Pattern", "Generate Support","Edit Support Parameters","Measure","Print ability Validation","Global Interference","Calculate Build","Note", and "Preview 3D Printing".
输出:第一个截图显示了 Creo Parametric 8.0 软件的界面(屏幕顶部中央的浅灰色文字所示)。左侧是一个标记为“模型树”的窗口,列出了多个文件和文件夹,包括“TRAYOOO1.ASM”、“ASM_RIGHT”、“ASM_TOP”、“ASM_FRONT”、“AS M DEF CS YS”和“TRAY_BOX”。这些文件和文件夹以树形结构组织,显示了当前项目的组件。界面顶部是一个工具栏,第一行有多个标签(“文件”、“托盘”),第二行包含各种工具按钮,如“打印”、“装配”、“在托盘上排列”、“模式”、“生成支撑”、“编辑支撑参数”、“测量”、“可打印性验证”、“全局干涉”、“计算构建”、“注释”和“预览 3D 打印”。

Figure 14: State transition caption example.
图 14: 状态转换标题示例。
In the center of the software, there is a file open dialog box containing multiple files: Bolt.prt, Bushing.prt, Clips.prt (which appears to be selected by the mouse),Handles1.prt,Handles2.prt,and Handlebar grip.prt. Below shows a yellow clip-shaped part with two connected cylindrical structures,which appears to be Clips.prt,with a modification time of 16-Jan-21 12:10:34 AM. At the bottom are several buttons,including a blue "0pen" button and a "Cancel"button ontheright.
在软件的中心,有一个包含多个文件的文件打开对话框:Bolt.prt、Bushing.prt、Clips.prt(似乎被鼠标选中)、Handles1.prt、Handles2.prt 和 Handlebar grip.prt。下方显示了一个黄色的夹子形状的零件,带有两个连接的圆柱结构,似乎是 Clips.prt,修改时间为 2021 年 1 月 16 日 12:10:34 AM。底部有几个按钮,包括一个蓝色的“打开”按钮和右侧的“取消”按钮。
The second screenshot still shows the Creo Parametric 8.0 software interface and file open dialog box. However, the displayed image has changed to a handle part. The preview window shows a silver and green cylindrical handle component. The 3D preview shows it has two sections: a longer silver cylindrical main body,and a shorter green protruding section,likely used for gripping or fixing. From the file list,we can see that Handlebar grip.prt is currently selected, and the file name "Handlebar-grip.prt" is displayed at the bottom of the file dialog box. Overall, it appears the user clicked on Handlebar-grip.prt in the file open dialog box, causing the 3D file preview areabelow toswitch to thesilver handle component.
第二张截图仍然显示 Creo Parametric 8.0 软件界面和文件打开对话框。然而,显示的图像已更改为一个手柄部件。预览窗口中展示了一个银绿色圆柱形手柄组件。3D 预览显示它有两个部分:一个较长的银色圆柱形主体,以及一个较短的绿色突出部分,可能用于握持或固定。从文件列表中可以看到,当前选择了 Handlebar grip.prt,文件名 "Handlebar-grip.prt" 显示在文件对话框的底部。总体来看,用户似乎在文件打开对话框中点击了 Handlebar-grip.prt,导致下方的 3D 文件预览区域切换为银色手柄组件。

Question Answering
问答
Set of Mark Question Answering
Set of Mark问答

Figure 15: Question answering and set of mark example.
图 15: 问答与标记集示例。

Figure 16: Element description example, the target element is highlighted with a pink bounding box in the image.
图 16: 元素描述示例,目标元素在图像中用粉色边界框突出显示。