Temporal Working Memory: Query-Guided Segment Refinement for Enhanced Multimodal Understanding
时间工作记忆:基于查询引导的片段优化以增强多模态理解
Xingjian Diao∗, Chunhui Zhang∗, Weiyi Wu, Zhongyu Ouyang, Peijun Qing, Ming Cheng, Soroush Vosoughi, Jiang Gui Dartmouth College {xingjian.diao, chunhui.zhang, weiyi.wu}.gr@dartmouth.edu {soroush.vosoughi, jiang.gui}@dartmouth.edu
Xingjian Diao∗, Chunhui Zhang∗, Weiyi Wu, Zhongyu Ouyang, Peijun Qing, Ming Cheng, Soroush Vosoughi, Jiang Gui 达特茅斯学院 {xingjian.diao, chunhui.zhang, weiyi.wu}.gr@dartmouth.edu {soroush.vosoughi, jiang.gui}@dartmouth.edu
Abstract
摘要
Multimodal foundation models (MFMs) have demonstrated significant success in tasks such as visual captioning, question answering, and image-text retrieval. However, these models face inherent limitations due to their finite internal capacity, which restricts their ability to process extended temporal sequences—an essential requirement for comprehensive video and audio analysis. To overcome these challenges, we introduce a specialized cognitive module, temporal working memory (TWM), which aims to enhance the temporal modeling capabilities of MFMs. It selectively retains task-relevant information across temporal dimensions, ensuring that critical details are preserved throughout the processing of video and audio content. The TWM uses a query-guided attention approach to focus on the most informative multimodal segments within temporal sequences. By retaining only the most relevant content, TWM optimizes the use of the model’s limited capacity, enhancing its temporal modeling ability. This plug-and-play module can be easily integrated into existing MFMs. With our TWM, nine state-of-the-art models exhibit significant performance improvements across tasks such as video captioning, question answering, and video-text retrieval. By enhancing temporal modeling, TWM extends the capability of MFMs to handle complex, time-sensitive data effectively. Our code is available at https: //github.com/xid32/NA A CL 2025 TW M.
多模态基础模型(MFMs)在视觉描述、问答和图像文本检索等任务中取得了显著成功。然而,由于这些模型内部容量有限,它们在处理长时间序列时面临固有局限性,而这正是全面视频和音频分析所必需的。为了克服这些挑战,我们引入了一个专门的认知模块——时间工作记忆(TWM),旨在增强MFMs的时间建模能力。它选择性地在时间维度上保留与任务相关的信息,确保在处理视频和音频内容时关键细节得以保留。TWM采用查询引导的注意力方法,专注于时间序列中信息量最大的多模态片段。通过仅保留最相关的内容,TWM优化了模型有限容量的使用,提升了其时间建模能力。这个即插即用的模块可以轻松集成到现有的MFMs中。通过我们的TWM,九个最先进的模型在视频描述、问答和视频文本检索等任务中表现出显著的性能提升。通过增强时间建模,TWM扩展了MFMs有效处理复杂、时间敏感数据的能力。我们的代码可在https://github.com/xid32/NAACL2025TWM获取。
1 Introduction
1 引言
Multimodal foundation models (MFMs) have demonstrated impressive capabilities in tasks such as video captioning, question-answering, imagetext retrieval, and broader multimodal understanding (Zhang et al., 2022; Kim et al., 2024; He et al., 2024; Jian et al., 2024; Zhang et al., 2025; Yao et al., 2024a; Xie et al., 2024; Yao et al., 2024b; Xie et al., 2025; Han et al., 2024; Liu et al., 2024d; Lin et al., 2024). While MFMs excel at processing multimodal inputs, MFMs are often not equipped to explicitly reduce the input context burden, particularly in extracting query-relevant information from the input context for video understanding tasks.
多模态基础模型 (MFMs) 在视频字幕生成、问答、图像文本检索以及更广泛的多模态理解任务中展现了令人印象深刻的能力 (Zhang et al., 2022; Kim et al., 2024; He et al., 2024; Jian et al., 2024; Zhang et al., 2025; Yao et al., 2024a; Xie et al., 2024; Yao et al., 2024b; Xie et al., 2025; Han et al., 2024; Liu et al., 2024d; Lin et al., 2024)。尽管 MFMs 在处理多模态输入方面表现出色,但它们通常不具备显式减少输入上下文负担的能力,特别是在从输入上下文中提取与查询相关的信息以进行视频理解任务时。

Figure 1: Temporal Working Memory (TWM): TWM employs search engine and memory refresh mechanisms to retain key segments in long multimodal inputs.
图 1: 时间工作记忆 (TWM): TWM 采用搜索引擎和记忆刷新机制来保留长多模态输入中的关键片段。
In humans, working memory retains and processes information over short time spans with limited capacity (Baddeley, 2000), and similar constraints apply to MFMs (Liu et al., 2024a). For example, LLaMA has a context length limit of 2048 tokens (Touvron et al., 2023a,b; Dubey et al., 2024), while LLaVA (Liu et al., 2023) and BLIP-2 (Li et al., 2023b) can handle only 256 and 32 tokens per image, respectively. These limited capacities prevent models from effectively retaining sufficient information over extended temporal spans.
在人类中,工作记忆在短时间内以有限的容量保留和处理信息 (Baddeley, 2000),类似的限制也适用于 MFMs (Liu et al., 2024a)。例如,LLaMA 的上下文长度限制为 2048 个 Token (Touvron et al., 2023a,b; Dubey et al., 2024),而 LLaVA (Liu et al., 2023) 和 BLIP-2 (Li et al., 2023b) 每张图像分别只能处理 256 和 32 个 Token。这些有限的容量阻碍了模型在长时间跨度内有效地保留足够的信息。
While operating under similar constraints, the human cognitive system has evolved effective mechanisms for efficient information processing (Baddeley, 2000), such as selective retention and distraction filtering, to dynamically prioritize relevant information while discarding irrelevant details (Zhang et al., 2024; Gong et al., 2024). In contrast, current MFMs lack such selective mechanisms found in human working memory, preventing them from effectively filtering and retaining the most relevant temporal segments from multimodal inputs (e.g., video frames or audio clips). Consequently, MFMs tend to process the entire input sequences indiscriminately within their perceptual window, leading to inefficient utilization of the model’s capabilities.
在类似的约束条件下,人类认知系统已经进化出有效的信息处理机制 (Baddeley, 2000),例如选择性保留和干扰过滤,以动态优先处理相关信息,同时丢弃无关细节 (Zhang et al., 2024; Gong et al., 2024)。相比之下,当前的 MFMs 缺乏人类工作记忆中的这种选择性机制,导致它们无法有效过滤和保留多模态输入(如视频帧或音频片段)中最相关的时间片段。因此,MFMs 往往在其感知窗口内不加区分地处理整个输入序列,导致模型能力的低效利用。
Recent developments in the memory of LLMs have significantly improved their ability to manage temporal contexts. Various approaches have been proposed to address the inherent memory limitations of LLMs and thereby improve their performance on complex tasks. Li et al. (2023a) proposed a knowledge-aware fine-tuning method that instructs LLMs to prioritize relevant external context while minimizing reliance on internal pretrained knowledge, thereby enhancing their memory by filtering out irrelevant information. Building on this, Gong et al. (2024) demonstrated that ChatGPT’s working memory is similar to that of humans, suggesting that enhancing memory capacity is crucial for advancing the intelligence of AI systems. Further exploring these limitations, Zhang et al. (2024) recommended strategies for more efficient memory utilization, highlighting the importance of improving both memory retention and model autonomy for better reasoning capabilities. In the context of multimodal models, Wu and Xie (2024) integrated visual working memory mechanisms to help models focus on essential features in high-resolution images, significantly improving visual grounding performance.
大语言模型 (LLM) 记忆的最新发展显著提升了其处理时序上下文的能力。为解决大语言模型固有的记忆限制并提升其在复杂任务中的表现,研究者们提出了多种方法。Li 等人 (2023a) 提出了一种知识感知的微调方法,指导大语言模型优先考虑相关的外部上下文,同时减少对内部预训练知识的依赖,从而通过过滤无关信息来增强其记忆能力。基于此,Gong 等人 (2024) 证明 ChatGPT 的工作记忆与人类相似,表明增强记忆容量对于提升 AI 系统的智能至关重要。Zhang 等人 (2024) 进一步探讨了这些限制,并提出了更高效利用记忆的策略,强调了改进记忆保持和模型自主性对于提升推理能力的重要性。在多模态模型的背景下,Wu 和 Xie (2024) 整合了视觉工作记忆机制,帮助模型专注于高分辨率图像中的关键特征,显著提升了视觉基础性能。
Despite recent advances in LLM memory management, these models still face fundamental challenges in dynamic multimodal and temporal reasoning: (i) they lack effective mechanisms to filter and retain query-relevant information from multimodal inputs (e.g., audio, video, language), leading to indiscriminate processing of entire sequences regardless of their relevance. (ii) these models lack the ability to effectively capture temporal dependencies. They struggle with short-term changes (e.g., rapid changes in audio or visual content) and long-term relationships (e.g., understanding how earlier events relate to later ones). This reduces their ability to reason about sequential and timesensitive data, which is crucial for tasks involving events that unfold over time. (iii) the models’ inability to efficiently process large volumes of raw data leads to information overload, straining their limited capacity and degrading performance when dealing with complex and high-volume data.
尽管大语言模型在记忆管理方面取得了最新进展,这些模型在动态多模态和时间推理方面仍面临根本性挑战:(i) 它们缺乏有效的机制来过滤和保留与查询相关的多模态输入信息(例如音频、视频、语言),导致对整个序列进行不加区分地处理,无论其相关性如何。(ii) 这些模型缺乏有效捕捉时间依赖性的能力。它们在短期变化(例如音频或视觉内容的快速变化)和长期关系(例如理解早期事件与后期事件的关系)方面表现不佳。这降低了它们对顺序和时间敏感数据进行推理的能力,而这些能力对于涉及随时间展开事件的任务至关重要。(iii) 模型无法高效处理大量原始数据,导致信息过载,在应对复杂和高容量数据时,其有限的能力受到压力,性能下降。
Therefore, we draw on human working memory to effectively extract query-relevant multimodal information across temporal dimensions. We propose a multimodal Temporal Working Memory (TWM) mechanism for MFMs, as shown in Figure 1. This mechanism employs a query-guided attention mechanism to selectively retain only query- relevant audio and visual inputs, focusing on the most informative segments along the temporal axis. The TWM mechanism constructs a temporal memory buffer at the model input stage, enabling MFMs to efficiently store and manage critical information across time. By concentrating on the retention of the most relevant data, TWM significantly improves the model’s ability to reason over extended temporal sequences in a multimodal context. Our contributions are:
因此,我们借鉴人类的工作记忆,有效地跨时间维度提取与查询相关的多模态信息。我们提出了一种用于MFMs的多模态时间工作记忆 (Temporal Working Memory, TWM) 机制,如图 1 所示。该机制采用查询引导的注意力机制,选择性地仅保留与查询相关的音频和视觉输入,并沿着时间轴关注信息最丰富的片段。TWM机制在模型输入阶段构建了一个时间记忆缓冲区,使MFMs能够高效地存储和管理跨时间的关键信息。通过专注于保留最相关的数据,TWM显著提高了模型在多模态上下文中推理长时间序列的能力。我们的贡献包括:
• We propose a Temporal Working Memory (TWM) mechanism with an integrated queryguided selection module. This module directs the model to retain key segments in long video and audio sequences, optimizing the use of the model’s limited capacity. • We employ a multi-scale temporal attention mechanism for both local and global dependencies, enabling accurate identification of relevant video-audio segments across temporal inputs. • We integrate TWM into nine state-of-the-art MFMs and evaluate our approach on three largescale multimodal benchmarks, covering tasks including audio-visual question answering, video captioning, and video-text retrieval. Our approach effectively yields significant performance improvements across all tasks.
• 我们提出了一种带有集成查询引导选择模块的时序工作记忆(Temporal Working Memory, TWM)机制。该模块引导模型在长视频和音频序列中保留关键片段,优化模型有限容量的使用。
• 我们采用了一种多尺度时序注意力机制,用于处理局部和全局依赖关系,从而在时序输入中准确识别相关的视频-音频片段。
• 我们将 TWM 集成到九种最先进的多模态基础模型(MFMs)中,并在三个大规模多模态基准上评估了我们的方法,涵盖的任务包括视听问答、视频字幕生成和视频-文本检索。我们的方法在所有任务中均有效带来了显著的性能提升。
2 Related Works
2 相关工作
Temporal Modeling in MLLMs Multimodal LLMs (MLLMs) for long-video understanding aim to capture long-range temporal patterns. A common strategy is temporal pooling, as used in Video Chat GP T (Maaz et al., 2024), but this can limit performance due to inadequate temporal mod- eling. More advanced methods, such as videoLLAMA (Zhang et al., 2023), incorporate video query transformers to enhance temporal dynamics, but this comes with increased model complexity. To reduce computational demands, some models rely on pre-extracted features, avoiding joint training of backbone architectures (Hussein et al., 2019; Liu et al., 2024c; Wu and Krahenbuhl, 2021). Techniques like Vis4mer (Islam and Bertasius, 2022)
MLLMs中的时序建模
and S5 (Wang et al., 2023) utilize the S4 transformer architecture (Gu et al., 2022) for efficient long-range temporal modeling. Recent developments, such as online video processing (He et al., 2024), employ memory banks to track past content for long-term analysis. In contrast, we propose a TWM mechanism that retains only query-relevant multimodal inputs through search engines within a temporal context.
S5 (Wang 等人, 2023) 利用 S4 Transformer 架构 (Gu 等人, 2022) 进行高效的长程时间建模。最近的进展,如在线视频处理 (He 等人, 2024),采用记忆库来跟踪过去的内容以进行长期分析。相比之下,我们提出了一种 TWM 机制,通过搜索引擎在时间上下文中仅保留与查询相关的多模态输入。
Video Understanding Video understanding tasks evaluate a model’s ability to process multimodal content, focusing on both temporal and semantic aspects. Key tasks for long-video understanding include audio-visual question answering (AVQA), video captioning, and video-text retrieval, supported by extensive research and large-scale datasets (Liu et al., 2024b; Xu et al., 2016; Bain et al., 2020). Prior AVQA methods fine-tuned pre- trained visual models with adapters (Liu et al., 2024b; Lin et al., 2023; Duan et al., 2023; Diao et al., 2024), while recent approaches use unified multimodal encoders with LLMs (Han et al., 2024). Video captioning models employ graph neural networks (GNNs) (Hendria et al., 2023), simplified image-text architectures (Wang et al., 2022), or causal effect networks (CEN) to enhance temporal coherence (Nadeem et al., 2024). In video-text retrieval, adaptive frame aggregation reduces visual tokens to accelerate encoding (Ren et al., 2023). In contrast to previous work focusing on specific multimodal applications, this study emphasizes the role of TWM in enhancing fundamental temporal grounding across audio, video, and language.
视频理解
3 Temporal Working Memory
3 时序工作记忆
Our temporal working memory (TWM) framework is a complementary architecture for multimodal large language models, integrating visual and auditory buffer components. If the model does not involve audio, the auditory component can be omitted. The working pipeline of the TWM framework is outlined in Algorithm 1, while the search and memory update processes are depicted in Figure 2.
我们的时序工作记忆 (Temporal Working Memory, TWM) 框架是多模态大语言模型的补充架构,集成了视觉和听觉缓冲组件。如果模型不涉及音频,可以省略听觉组件。TWM 框架的工作流程在算法 1 中概述,而搜索和记忆更新过程在图 2 中描述。
3.1 Visual Memory Management
3.1 视觉记忆管理
3.1.1 Query-Relevant Video-Frame Search
3.1.1 查询相关视频帧搜索
Our mechanism emulates human cognitive strategies by identifying and retaining critical visual information from long video sequences. It alternates between two key operations—search and update—to dynamically adjust memory and focus on the most relevant segments, as shown in Figure 2.
我们的机制通过识别并保留长视频序列中的关键视觉信息来模拟人类认知策略。它在搜索和更新两个关键操作之间交替进行,以动态调整记忆并专注于最相关的片段,如图 2 所示。
Initially, $k$ frames are selected from the full sequence of $N$ frames and processed through a visual encoder to generate embeddings. Each frame $v_{i}$ is assigned a Similarity Score $(S(v_{i}))$ , defined as:
最初,从完整的 $N$ 帧序列中选择 $k$ 帧,并通过视觉编码器进行处理以生成嵌入。每帧 $v_{i}$ 被分配一个相似度分数 $(S(v_{i}))$,定义为:
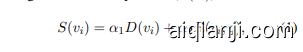
where $D(v_{i})$ is function representing the distinctiveness of frame $v_{i}$ , $R(v_{i},q)$ is function representing the relevance of frame $v_{i}$ to the query $q.~\alpha_{1}$ and $\alpha_{2}$ are adaptive weights that vary based on the nature of the downstream task and the duration of the video samples. The selection process is iterative. In each iteration, the frame with the highest similarity score $(S(v_{i}))$ is chosen as the midpoint, and $k$ frames are searched uniformly within a range of N around it. These frames are added to visual memory, excluding frames already present to maintain diversity. The process concludes upon convergence.
其中 $D(v_{i})$ 是表示帧 $v_{i}$ 独特性的函数,$R(v_{i},q)$ 是表示帧 $v_{i}$ 与查询 $q$ 相关性的函数。$\alpha_{1}$ 和 $\alpha_{2}$ 是根据下游任务性质和视频样本时长变化的自适应权重。选择过程是迭代的。在每次迭代中,选择相似度得分 $(S(v_{i}))$ 最高的帧作为中点,并在其周围 N 范围内均匀搜索 $k$ 帧。这些帧被添加到视觉记忆中,排除已存在的帧以保持多样性。该过程在收敛时结束。
3.1.2 Training Neural Search Engine
3.1.2 训练神经搜索引擎
To identify frames relevant to a given query, we use a cross-modal alignment strategy (Figure 3). Pretrained visual and language encoders are employed, with a linear projection layer that maps visual embeddings into the textual embedding space. The InfoNCE loss (Oord et al., 2018) is used to optimize this alignment:
为了识别与给定查询相关的帧,我们使用了一种跨模态对齐策略(图 3)。我们采用了预训练的视觉和语言编码器,并通过一个线性投影层将视觉嵌入映射到文本嵌入空间。使用 InfoNCE 损失 (Oord et al., 2018) 来优化这种对齐:


Figure 2: The temporal working memory (TWM) pipeline retains the most relevant segments from video and audio inputs based on a language query. The Language Encoder processes the query, guiding the Search Engine to identify and select key video and audio segments. TWM ensures the retention of only the most informative data, enabling the efficient utilization of multimodal foundation models’ capabilities.
图 2: 时序工作记忆 (TWM) 管道根据语言查询从视频和音频输入中保留最相关的片段。语言编码器处理查询,引导搜索引擎识别并选择关键视频和音频片段。TWM 确保仅保留信息最丰富的数据,从而有效利用多模态基础模型的能力。
Figure 3: Aligning frames with language query. A linear projection layer trained with InfoNCE loss aligns visual embeddings with query-based anchors.
图 3: 将帧与语言查询对齐。通过使用 InfoNCE 损失训练的线性投影层,将视觉嵌入与基于查询的锚点对齐。
where $\mathbf{e}{v}$ is the embedding of video frame $v$ , ${\bf e}{t_{i}}$ is the embedding of text description $t_{i}$ , $\mathrm{sim}(x,y)$ denotes the cosine similarity function, $\tau$ is the temperature parameter controlling the sharpness of the distribution, and $N$ represents the number of negative samples. The InfoNCE loss maximizes the similarity between the corresponding video and text embeddings while minimizing the similarity to unrelated samples. This ensures that the model effectively aligns the most relevant frames with their corresponding text, thereby optimizing its ability to retain meaningful visual information.
其中 $\mathbf{e}{v}$ 是视频帧 $v$ 的嵌入,${\bf e}{t_{i}}$ 是文本描述 $t_{i}$ 的嵌入,$\mathrm{sim}(x,y)$ 表示余弦相似度函数,$\tau$ 是控制分布锐度的温度参数,$N$ 表示负样本的数量。InfoNCE 损失函数最大化对应视频和文本嵌入之间的相似度,同时最小化与无关样本的相似度。这确保了模型能够有效地将最相关的帧与其对应的文本对齐,从而优化其保留有意义视觉信息的能力。

Figure 4: Similarity search for query-relevant audio segments. The audio encoder utilizes visual embeddings as a query to search for the most relevant audio segments, updating the auditory buffer to retain only the essential audio information.
图 4: 查询相关音频片段的相似性搜索。音频编码器利用视觉嵌入 (visual embeddings) 作为查询,搜索最相关的音频片段,并更新听觉缓冲区以保留仅有的必要音频信息。
3.2 Auditory Memory Management
3.2 听觉记忆管理
3.2.1 Query-Relevant Audio-Segment Search
3.2.1 查询相关音频段搜索
The search process for identifying key audio segments mirrors the methodology used for video frames. The audio sequence is divided into predefined segments, typically 5-6 segments depending on video length, to model adequate temporal dependencies for tasks like AVQA and video captioning. This segmentation allows the model to focus efficiently on relevant audio intervals, improving attention allocation across extended sequences.
识别关键音频片段的搜索过程与视频帧的处理方法类似。音频序列被划分为预定义的片段,通常根据视频长度分为5-6个片段,以便为AVQA和视频字幕生成等任务建模足够的时间依赖性。这种分段方式使模型能够高效地聚焦于相关音频区间,从而改善对长序列的注意力分配。
Building upon Pathformer’s dual-attention mechanism (Chen et al., 2024), we extend their approach to enhance the correlation between audio and video data. Specifically, visual embeddings are used as queries in both attentions (Figure 4). To enable multimodal audio-visual synchronization, we integrate audio patches derived from Mel-spec tro grams for temporal segmentation. This facilitates the alignment between the audio and visual inputs. Our audio encoder employs two key attention mechanisms:
基于 Pathformer 的双重注意力机制(Chen 等,2024),我们扩展了他们的方法以增强音频和视频数据之间的相关性。具体来说,视觉嵌入被用作两种注意力中的查询(图 4)。为了实现多模态的视听同步,我们整合了从梅尔频谱图中提取的音频片段进行时间分割。这有助于音频和视觉输入之间的对齐。我们的音频编码器采用了两种关键的注意力机制:
• Inter-segment attention is designed to model global dependencies across audio segments, enabling the model to capture broader relationships such as shifts in tone, mood, or overall sound context. Specifically, inter-segment attention calculates attention scores between the query $Q$ , which is derived from visual features, and the keys $K_{i}$ from the audio segments $A t t_{\mathrm{inter}}\ =$ softmax $\left(\frac{Q K_{i}^{T}}{\sqrt{d_{K}}}\right)V_{i},\quad i\in[\bar{1},n]$ . Here, $Q$ represents the visual embeddings, while $K_{i}$ and $V_{i}$ are the audio embeddings from segment $i$ . By using visual features as the query, this attention aligns audio information with relevant visual cues, effectively capturing how the audio context evolves to the video over time.
• 跨段注意力机制旨在建模音频片段之间的全局依赖关系,使模型能够捕捉更广泛的关系,如音调、情绪或整体声音背景的变化。具体来说,跨段注意力通过计算从视觉特征派生的查询 $Q$ 和音频片段的关键 $K_{i}$ 之间的注意力分数来实现,公式为 $A t t_{\mathrm{inter}}\ =$ softmax $\left(\frac{Q K_{i}^{T}}{\sqrt{d_{K}}}\right)V_{i},\quad i\in[\bar{1},n]$。其中,$Q$ 表示视觉嵌入,而 $K_{i}$ 和 $V_{i}$ 是来自片段 $i$ 的音频嵌入。通过将视觉特征作为查询,这种注意力机制将音频信息与相关视觉线索对齐,从而有效捕捉音频背景如何随时间随视频演变。
• Intra-segment attention aims to capture local dependencies within individual audio segments, thereby modeling fine-grained temporal patterns such as audio variations or sudden changes in sound effects. The result of intra-segment attention for each segment is computed as: $A t t_{\mathrm{intra}}=$ Concat $(A t t_{\mathrm{intra}_{i}};;|;;i;=;1,\ldots,n)$ . $A t t_{\mathrm{intra}_{i}}$ rep-resents the computed attention within each segment $i$ . The concatenation operation aggregates these intra-segment attention results across all segments, ensuring that short-term changes are captured and preserved for subsequent processing. This aggregation allows the model to retain a detailed representation of the short-term dynamics within each segment.
• 段内注意力旨在捕捉单个音频段内的局部依赖关系,从而对细粒度的时间模式进行建模,例如音频变化或音效的突变。每个段内注意力的结果计算为:$A t t_{\mathrm{intra}}=$ Concat $(A t t_{\mathrm{intra}_{i}};;|;;i;=;1,\ldots,n)$ 。$A t t_{\mathrm{intra}_{i}}$ 表示每个段 $i$ 内计算的注意力。通过拼接操作,这些段内注意力结果在所有段之间进行聚合,确保捕捉并保留短期变化以供后续处理。这种聚合使模型能够保留每个段内短期动态的详细表示。
In the fusion layer, we apply a cross-modal attention mechanism to synchronize features from both audio and visual streams. Additionally, multikernel pooling aggregates audio patches across different-scale temporal dependencies, enhancing the alignment and understanding of temporal multimodal inputs.
在融合层中,我们应用跨模态注意力机制来同步音频和视觉流的特征。此外,多核池化通过不同尺度的时间依赖性聚合音频片段,增强了时间多模态输入的对齐和理解。
As shown in Figure 5, a pretrained visual feature extractor is used to align the audio segments with their corresponding visual frames to establish crossmodal coherence. To identify query-relevant audio patches, we apply cosine similarity between audio embeddings $(\mathbf{e}{a{i}})$ and visual embeddings $\left(\mathbf{e}{v}\right)$ as $\begin{array}{r}{\mathrm{sim}(\mathbf{e}{a_{i}},\mathbf{e}{v})=\frac{\mathbf{e}{a_{i}}\cdot\mathbf{e}{v}}{\Vert\mathbf{e}{a_{i}}\Vert\Vert\mathbf{e}_{v}\Vert}}\end{array}$ . This similarity score is used to select the audio patches that are most relevant to the corresponding visual frames. The selected audio segments are then updated in the auditory buffer, ensuring that the most important audio information is retained. This iterative refinement enhances the synchronization and complement ari ty between audio and visual content.
如图 5 所示,使用预训练的视觉特征提取器将音频片段与其对应的视觉帧对齐,以建立跨模态一致性。为了识别与查询相关的音频片段,我们应用了音频嵌入 $(\mathbf{e}{a{i}})$ 和视觉嵌入 $\left(\mathbf{e}{v}\right)$ 之间的余弦相似度,公式为 $\begin{array}{r}{\mathrm{sim}(\mathbf{e}{a_{i}},\mathbf{e}{v})=\frac{\mathbf{e}{a_{i}}\cdot\mathbf{e}{v}}{\Vert\mathbf{e}{a_{i}}\Vert\Vert\mathbf{e}_{v}\Vert}}\end{array}$。该相似度分数用于选择与相应视觉帧最相关的音频片段。然后,选定的音频片段会在听觉缓冲区中更新,确保保留最重要的音频信息。这种迭代优化增强了音频和视觉内容之间的同步性和互补性。

Full Audio Segments Figure 5: Audio segments aligned with query-relevant frames. An audio encoder learns temporal distance and resolution for audio-visual embedding alignment.
完整音频片段 图 5: 与查询相关帧对齐的音频片段。音频编码器学习时间距离和分辨率,以实现音频-视觉嵌入对齐。
3.2.2 Training Audio Search Engine
3.2.2 训练音频搜索引擎
To identify query-relevant audio segments, we also use InfoNCE loss to achieve cross-modal alignment (see Figure 5). Let ${\bf e}{a{i}}$ denote the embedding of the audio patch $a_{i}$ , and let $\mathbf{e}_{v}$ denote the embedding of the video frame $v$ . The alignment loss is:
为了识别与查询相关的音频片段,我们还使用 InfoNCE 损失来实现跨模态对齐(见图 5)。设 ${\bf e}{a{i}}$ 表示音频片段 $a_{i}$ 的嵌入,$\mathbf{e}_{v}$ 表示视频帧 $v$ 的嵌入。对齐损失为:

where $\tau$ is a temperature parameter controlling the distribution’s sharpness, and $N$ is the number of negative samples. This approach ensures effective alignment between audio and visual embeddings, allowing the model to identify cross-modal relationships effectively and refine the auditory buffer.
其中 $\tau$ 是控制分布锐度的温度参数,$N$ 是负样本的数量。这种方法确保了音频和视觉嵌入之间的有效对齐,使模型能够有效识别跨模态关系并优化听觉缓冲。
4 Experiments
4 实验
We perform three major experiments to validate the effectiveness of the Temporal Working Memory mechanism discussed in the previous section. We evaluated the performance of state-of-the-art baseline models and the same models augmented with our Temporal Working Memory mechanism on the following downstream tasks: (1) audio-visual question answering (AVQA), (2) video captioning, and (3) video-text retrieval.
我们进行了三项主要实验,以验证前一节讨论的时序工作记忆机制的有效性。我们在以下下游任务上评估了最先进的基线模型以及增强了我们时序工作记忆机制的相同模型的性能:(1) 视听问答 (AVQA),(2) 视频字幕生成,以及 (3) 视频-文本检索。
4.1Setup
4.1 设置
Datasets We conduct experiments on AVQA, video captioning, and video-text retrieval:
数据集我们在AVQA、视频字幕生成和视频-文本检索任务上进行了实验:
• MUSIC-AVQA v2.0 (Liu et al., 2024b): MUSIC- AVQA v2.0 introduces 1,230 additional videos and 8,100 new question-answer (QA) pairs to further mitigate data bias. It builds on the original MUSIC-AVQA dataset (Li et al., 2022), which contains 9,288 videos of 22 musical instruments (over 150 hours) with 45,867 question-answer (QA) pairs across 33 templates in 9 categories. • MSR-VTT (Xu et al., 2016): Comprises 10,000 video clips (over 41 hours) from various online sources. Each video has 20 human-annotated captions, totaling 200,000 video-text pairs across diverse categories like music, sports, and gaming. • CMD (Bain et al., 2020): The Condensed Movies Dataset includes over 33,000 clips from 3,600 movies, averaging 2 minutes each, with annotations such as captions, dialogues, and action labels, ideal for video-text retrieval tasks.
• MUSIC-AVQA v2.0 (Liu et al., 2024b): MUSIC-AVQA v2.0 引入了 1,230 个额外视频和 8,100 个新的问答对 (QA),以进一步缓解数据偏差。它基于原始的 MUSIC-AVQA 数据集 (Li et al., 2022),该数据集包含 9,288 个视频,涵盖 22 种乐器(超过 150 小时),并在 9 个类别中的 33 个模板中包含了 45,867 个问答对 (QA)。
• MSR-VTT (Xu et al., 2016): 包含来自各种在线来源的 10,000 个视频片段(超过 41 小时)。每个视频有 20 个人工标注的字幕,总计 200,000 个视频-文本对,涵盖音乐、体育和游戏等多样化类别。
• CMD (Bain et al., 2020): Condensed Movies 数据集包含来自 3,600 部电影的 33,000 多个片段,每个片段平均 2 分钟,带有诸如字幕、对话和动作标签等标注,非常适合视频-文本检索任务。
Baselines Details of the baseline models can be found in Appendix A. We evaluate nine state-ofthe-art MFMs reproduced with open-source code and pretrained weights.
基线模型详情请参见附录 A。我们评估了使用开源代码和预训练权重复现的九种最先进的 MFM(多模态基础模型)。
Evaluation Metrics Below standard metrics reflect the accuracy, quality, and retrieval capabilities: • Audio-Visual Question Answering: Accuracy is measured for Audio (Counting, Comparative), Visual (Counting, Location), Audio-Visual (Existential, Counting, Location, Comparative, Temporal) question types, along with average accuracies for Audio, Visual, Audio-Visual, and overall. • Video Captioning: Metrics include ROUGEL, CIDEr, and SPICE, assessing overlap with ground truth, consensus with human annotations, and diversity of scene descriptions, respectively. • Video-Text Retrieval: Metrics are Recall $@1$ , Recall $@5$ , and Recall $@10$ , measuring retrieval performance within top 1, 5, and 10 predictions.
Implementations The settings of each dataset: • MUSIC-AVQA v2.0: Videos are 60 seconds long, with questions targeting specific portions of the video. We set $k=11$ and ran 6 iterations, using $\alpha_{1}=0.2$ and $\alpha_{2}=0.8$ , resulting in frame sampling rates consistent with 1 frame per second (fps). Audio segments are extracted every 5 seconds, selecting the highest-scoring segment from a total of 12 segments.
实现
每个数据集的设置:
- MUSIC-AVQA v2.0:视频时长为 60 秒,问题针对视频的特定部分。我们设置 $k=11$ 并运行 6 次迭代,使用 $\alpha_{1}=0.2$ 和 $\alpha_{2}=0.8$,结果帧采样率与每秒 1 帧 (fps) 一致。音频片段每 5 秒提取一次,从总共 12 个片段中选择得分最高的片段。
• MSR-VTT: With a frame rate of 21 fps, we set $k=3$ and ran 3 iterations, yielding 8–9 searched frames, with $\alpha_{1},=,0.5$ and $\alpha_{2},=,0.5$ for balanced frame selection.
• MSR-VTT: 帧率为 21 fps,我们设置 $k=3$ 并运行了 3 次迭代,生成了 8–9 个搜索帧,使用 $\alpha_{1},=,0.5$ 和 $\alpha_{2},=,0.5$ 进行平衡帧选择。
• CMD: With a frame rate of 30 fps, we used $k=5$ and ran 7 iterations, producing 30–35 frames in total, using $\alpha_{1}=0.6$ and $\alpha_{2}=0.4$ to prioritize frame diversity.
• CMD: 在帧率为 30 fps 的情况下,我们使用 $k=5$ 并运行 7 次迭代,总共生成 30–35 帧,使用 $\alpha_{1}=0.6$ 和 $\alpha_{2}=0.4$ 来优先考虑帧的多样性。
As depicted in Figure 3, the dimensions of the linear mapping layer, and similarly in Figure 5 for the fusion layer, correspond to the output embedding dimensions of the text encoder used by each model. The embedding dimensions typically span 768-D, 4096-D, or 16384-D, as detailed in Section 4.1 where the baseline models are referenced. Training is conducted on the NVIDIA H100 80GB GPUs using PyTorch. The Adam optimizer with a learning rate of $1e^{-4}$ is used, and each model is trained for 10 epochs. On the MUSIC-AVQA dataset, each model requires an average training time of 65.2 hours. For the MSR-VTT dataset, the average training time per model is 14.6 hours, while for the CMD dataset, each model takes approximate ly 146.6 GPU-hours to train.
如图 3 所示,线性映射层的维度与图 5 中的融合层类似,对应于每个模型所使用的文本编码器的输出嵌入维度。嵌入维度通常为 768-D、4096-D 或 16384-D,详见第 4.1 节中对基线模型的描述。训练在 NVIDIA H100 80GB GPU 上使用 PyTorch 进行。使用学习率为 $1e^{-4}$ 的 Adam 优化器,每个模型训练 10 个 epoch。在 MUSIC-AVQA 数据集上,每个模型平均需要 65.2 小时的训练时间。对于 MSR-VTT 数据集,每个模型的平均训练时间为 14.6 小时,而在 CMD 数据集上,每个模型大约需要 146.6 GPU 小时的训练时间。
4.2 Overall Comparisons
4.2 总体比较
4.2.1 Audio-Visual Question Answering
4.2.1 视听问答
TWM captures fine-grained multimodal dependencies for comparative reasoning In AVQA (Table 1), TWM excels in identifying and preserving fine-grained dependencies between audio and visual inputs, especially in complex comparative tasks. In audio-related comparative QA, LAV $\mathrm{isH{+}T W M}$ improves by $12.40%$ , DG-S $\scriptstyle\mathrm{CT}+\mathrm{TWM}$ gains $10.12%$ and LAST-Att+TWM shows an increase of $11.73%$ . Similarly, significant improvements are observed in the audiovisual comparative QA: LAVisH+TWM improves by $10.08%$ , DG- S $\mathrm{\Delta_{\lambda}^{\circ}T W M}$ by $13.56%$ and LAST-Att+TWM by $10.92%$ . TWM also leads to significant increases in overall average accuracy across all audiovisual tasks, with $\mathrm{LAVisH+TWM}$ improving by $6.35%$ , $\mathsf{D G-S C T+T W M}$ by $8.58%$ and LAST-Att+TWM by $5.01%$ . By focusing on query-relevant segments and filtering out irrelevant content, TWM ensures that the model attends to the most informative parts of each modality, thereby improving cross-modal reasoning accuracy. This selective attention mechanism allows the model to better isolate critical elements within audiovisual streams, enabling it to reason about context-dependent relationships between different inputs. The fine-tuned multimodal focus highlights TWM’s effectiveness in tasks requiring fine-grained comparisons, as it actively suppresses noise and enhances relevant signals.
TWM 在 AVQA 中捕捉细粒度多模态依赖关系以进行对比推理(表 1),TWM 在识别和保留音频与视觉输入之间的细粒度依赖关系方面表现出色,特别是在复杂的对比任务中。在音频相关的对比问答中,LAV $\mathrm{isH{+}T W M}$ 提升了 $12.40%$,DG-S $\scriptstyle\mathrm{CT}+\mathrm{TWM}$ 提升了 $10.12%$,而 LAST-Att+TWM 则提升了 $11.73%$。同样,在音视频对比问答中也观察到了显著的改进:LAVisH+TWM 提升了 $10.08%$,DG-S $\mathrm{\Delta_{\lambda}^{\circ}T W M}$ 提升了 $13.56%$,LAST-Att+TWM 提升了 $10.92%$。TWM 在所有音视频任务中的整体平均准确率也显著提升,其中 $\mathrm{LAVisH+TWM}$ 提升了 $6.35%$,$\mathsf{D G-S C T+T W M}$ 提升了 $8.58%$,LAST-Att+TWM 提升了 $5.01%$。通过关注与查询相关的片段并过滤掉不相关的内容,TWM 确保模型关注每种模态中最具信息量的部分,从而提高跨模态推理的准确性。这种选择性注意力机制使模型能够更好地隔离音视频流中的关键元素,使其能够推理不同输入之间的上下文依赖关系。经过微调的多模态焦点突出了 TWM 在需要细粒度对比的任务中的有效性,因为它主动抑制噪声并增强相关信号。
Table 1: Results of different models on the test set of MUSIC-AVQA 2.0 (Liu et al., 2024b). Bold results indicate the better performance.
4.2.2 Video Captioning
Table 2: Test results of different models on MSR-VTT.
4.2.2 视频字幕生成
| 方法 | ROUGE-L↑ | CIDEr↑ | SPICE↑ |
|---|---|---|---|
| Git (Wang et al.,2022) | 24.51 | 32.43 | 13.70 |
| Git+TWM | 26.10 | 39.25 | 14.31 |
| Gain () | +1.59 | +6.82 | +0.61 |
| AKGNN (Hendria et al.,2023) | 21.42 | 25.90 | 11.99 |
| AKGNN+TWM | 21.33 | 27.46 | 11.02 |
| Gain () | -0.09 | +1.56 | -0.97 |
| CEN(Nadeem et al.,2024) | 27.90 | 49.87 | 15.76 |
| CEN+TWM | 28.10 | 52.01 | 15.90 |
| Gain () | +0.20 | +2.14 | +0.14 |
表 2: 不同模型在 MSR-VTT 上的测试结果。
TWM enhances temporal coherence through selective attention to key events In video captioning tasks (Table 2), TWM’s selective attention mechanism significantly improves temporal coherence by focusing on key events and discarding irrelevant content. For example, $\mathrm{Git+TWM}$ achieves a $6.82%$ improvement in CIDEr and a $1.59%$ increase in ROUGE-L, highlighting the model’s enhanced ability to generate coherent narratives that follow the flow of events. By retaining only the most con textually relevant audio-visual segments, TWM helps to avoid disjointed or fragmented scene descriptions, which is critical for accurately representing long or complex narratives.
TWM 通过选择性关注关键事件增强时间一致性
TWM captures fine-grained scene transitions, enhancing descriptive richness TWM also excels at capturing fine-grained details within scenes, allowing the model to generate richer and more informative descriptions. For example, $\scriptstyle\mathrm{CEN+TWM}$ shows a $0.14%$ improvement in SPICE, reflecting the model’s enhanced ability to capture varied and accurate content in captions. In addition, $\scriptstyle{\mathrm{Git+TWM}}$ shows a $0.61%$ increase in SPICE, indicating an improved ability to capture changes in the audiovisual content of the video, such as changes in action or context. By dynamically updating memory with the most relevant visual and auditory elements, TWM ensures that critical details are highlighted, resulting in more con textually accurate and detailed output. This enhanced descriptive richness is essential in scenarios involving complex or rapidly changing scenes, where capturing semantic shifts in the narrative is key to generating informative captions.
TWM 捕捉细粒度场景转换,增强描述的丰富性。TWM 还擅长捕捉场景中的细粒度细节,使模型能够生成更丰富且信息量更大的描述。例如,$\scriptstyle\mathrm{CEN+TWM}$ 在 SPICE 上显示出 $0.14%$ 的提升,反映出模型在捕捉多样且准确的内容方面的能力增强。此外,$\scriptstyle{\mathrm{Git+TWM}}$ 在 SPICE 上显示出 $0.61%$ 的提升,表明其在捕捉视频中视听内容变化(如动作或背景的变化)方面的能力有所提高。通过动态更新最相关的视觉和听觉元素的记忆,TWM 确保关键细节得到突出,从而生成更符合上下文且更详细的输出。这种增强的描述丰富性在涉及复杂或快速变化场景的情况下尤为重要,捕捉叙事中的语义变化是生成信息丰富字幕的关键。
4.2.3 Video-Text Retrieval
Table 3: Test results of different models on CMD.
4.2.3 视频-文本检索
| 方法 | Recall@1↑ | Recall@5↑ | Recall@10↑ |
|---|---|---|---|
| VINDLU (Cheng et al., 2023) | 18.4 | 36.4 | 41.8 |
| VINDLU+TWM | 20.5 | 38.2 | 44.6 |
| Gain () | +2.1 | +1.8 | +2.8 |
| TESTA (Ren et al., 2023) | 21.5 | 42.4 | 50.7 |
| TESTA+TWM | 22.1 | 45.3 | 52.1 |
| Gain (△) | +0.6 | +2.9 | +1.4 |
| MovieSeq (Lin et al., 2024) | 25.8 | 45.3 | 50.3 |
| MovieSeq+TWM | 27.5 | 47.0 | 51.1 |
| Gain () | +1.7 | +1.7 | +0.8 |
表 3: 不同模型在 CMD 上的测试结果。
TWM maintains retrieval performance across broader scopes through adaptive segment retention TWM’s ability to enhance cross-modal alignment extends beyond immediate retrieval precision to broader retrieval tasks (Table 3). For instance, VINDLU $^+$ TWM achieves improvements of $2.1%$ in Recall $@1$ , $1.8%$ in Recall $@5$ , and $2.8%$ in Recall $@10$ . TESTA $^+$ TWM demonstrates gains of $2.9%$ in Recall $@5$ and $1.4%$ in Recall $@10$ , showcasing TWM’s capacity to retain relevant segments even in complex or diverse video datasets. Similarly, MovieSeq $^+$ TWM shows consistent improvements with a $1.7%$ increase in Recall $@1$ and Recall $@5$ , and a $0.8%$ gain in Recall $@10$ . These results indicate that TWM’s memory update mechanism is flexible enough to adapt to a wide range of retrieval tasks. By selectively focusing on the most important audio-visual elements, TWM improves the model’s ability to retrieve relevant content across larger candidate sets. This adaptive retention mechanism allows the model to effectively balance precision and scope, ensuring that both specific and broad retrieval queries benefit from TWM’s selective attention and memory update strategies.
TWM通过自适应片段保留在更广泛范围内保持检索性能
TWM在跨模态对齐方面的能力不仅限于即时检索精度,还扩展到更广泛的检索任务(表 3)。例如,VINDLU $^+$ TWM 在 Recall $@1$ 上提升了 $2.1%$,在 Recall $@5$ 上提升了 $1.8%$,在 Recall $@10$ 上提升了 $2.8%$。TESTA $^+$ TWM 在 Recall $@5$ 上提升了 $2.9%$,在 Recall $@10$ 上提升了 $1.4%$,展示了 TWM 在复杂或多样化的视频数据集中保留相关片段的能力。同样,MovieSeq $^+$ TWM 在 Recall $@1$ 和 Recall $@5$ 上均提升了 $1.7%$,在 Recall $@10$ 上提升了 $0.8%$。这些结果表明,TWM 的记忆更新机制足够灵活,能够适应广泛的检索任务。通过选择性地关注最重要的视听元素,TWM 提高了模型在更大候选集中检索相关内容的能力。这种自适应保留机制使模型能够有效地平衡精度和范围,确保特定和广泛的检索查询都能从 TWM 的选择性注意力和记忆更新策略中受益。

Figure 6: TWM-searched frames for the video captioning task, integrated with AKGNN (Hendria et al., 2023). Two examples of frames searched by TWM are presented alongside their ground truth captions. The total number of frames per clip in MSR-VTT (Xu et al., 2016) ranges from 210 to 630. TWM-searched 8 frames effectively encapsulate the key visual information required to generate the ground truth captions.
图 6: 结合 AKGNN (Hendria et al., 2023) 的视频字幕任务中 TWM 搜索到的帧。展示了 TWM 搜索到的两帧示例及其对应的真实字幕。MSR-VTT (Xu et al., 2016) 中每个片段的帧数在 210 到 630 之间。TWM 搜索到的 8 帧有效地涵盖了生成真实字幕所需的关键视觉信息。
4.3 The Impacts of Temporal Sequence Selection
4.3 时间序列选择的影响
To illustrate the effectiveness of TWM, we present a case study where TWM’s search engine selects highly relevant frames based on the input of the language query (Figure 6). Below, we provide a detailed analysis of how TWM ensures completeness of action representation, eliminates irrelevant noise, and optimizes model performance through selective frame reduction.
为了说明 TWM 的有效性,我们展示了一个案例研究,其中 TWM 的搜索引擎根据语言查询的输入选择高度相关的帧(图 6)。下面,我们详细分析了 TWM 如何确保动作表示的完整性、消除无关噪声,并通过选择性帧减少来优化模型性能。
Completeness of action representation TWM captures all the core stages of primary actions like chopping or mixing. For the chopping example, it captures the pepper being placed on the cutting board (Frames 0 and 72), the initiation of slicing (Frames 108 and 116), intermediate chopping stages (Frames 125 and 148), and the completion of the task (Frames 180 and 249). In the mixing example, it includes frames that depict the pouring of ingredients (Frames 40 and 44), the stirring process (Frames 48, 64, and 131), and the final state of the mixture. By covering all key moments, TWM provides the captioning model with a comprehensive understanding of the actions.
动作表示的完整性 TWM 捕捉了如切菜或搅拌等主要动作的所有核心阶段。以切菜为例,它捕捉了辣椒被放置在砧板上的时刻(帧 0 和 72)、切片开始的时刻(帧 108 和 116)、中间切菜阶段(帧 125 和 148)以及任务完成的时刻(帧 180 和 249)。在搅拌的例子中,它包括了描绘倾倒配料(帧 40 和 44)、搅拌过程(帧 48、64 和 131)以及混合物的最终状态的帧。通过覆盖所有关键时刻,TWM 为字幕模型提供了对动作的全面理解。
Elimination of irrelevant noise In cooking videos, various elements can distract from the main actions, such as the kitchen background, other utensils, or idle moments unrelated to the primary tasks like chopping. By selecting only the frames that focus on essential actions such as chopping or mixing in the examples, the TWM efficiently filters out these distractions, providing cleaner visual information for the captioning model. By minimizing distracting frames in the captioning inputs, the resulting descriptions of the events in the video become more accurate and useful.
消除无关噪音在烹饪视频中,各种元素可能会分散对主要动作的注意力,例如厨房背景、其他器具或与主要任务(如切菜)无关的空闲时间。通过仅选择聚焦于关键动作(如切菜或搅拌)的帧,TWM有效地过滤了这些干扰,为字幕模型提供了更清晰的视觉信息。通过最小化字幕输入中的干扰帧,视频事件的描述变得更加准确和有用。
Selective frame reduction for efficient model capacity utilization By selecting a limited number of informative frames that encompass all core stages, TWM optimizes memory usage and computational resources. It directs computational resources to the most relevant parts of the sequence by eliminating redundant or unrelated frames, thereby enhancing performance without overburdening the model. This selective retention not only allows for the precise capture of essential actions, but also facilitates efficient processing, significantly saving memory and speeding up the captioning model. Additional case studies on video-text retrieval and audio-visual question answering tasks are available in the Appendix C.
选择性帧减少以高效利用模型容量
5 Conclusion
5 结论
We introduce Temporal Working Memory (TWM), a cognitive module designed to enhance multimodal foundation models’ capabilities on complex video-audio-language tasks. Multimodal foundation models often struggle with dynamic multimodal input due to inefficient utilization of limited internal capacity. TWM addresses these limitations by $(i)$ maintaining memory states to process temporal multimodal sequences through selective segment retention; $(i i)$ modeling multi-scale temporal dependencies between video and audio inputs; and (iii) extracting query-relevant information from rich multimodal data for efficient memory utilization. Our approach effectively improves the performance of nine state-of-the-art multimodal models on three temporal reasoning tasks: audio-visual question answering, video captioning, and video-text retrieval.
我们引入了时序工作记忆 (Temporal Working Memory, TWM),这是一个旨在增强多模态基础模型在复杂视频-音频-语言任务上能力的认知模块。多模态基础模型在处理动态多模态输入时常常由于对有限内部容量的低效利用而表现不佳。TWM通过以下方式解决了这些限制:$(i)$ 通过选择性片段保留来维护记忆状态以处理时序多模态序列;$(i i)$ 建模视频和音频输入之间的多尺度时序依赖关系;以及 $(iii)$ 从丰富的多模态数据中提取与查询相关的信息以实现高效的内存利用。我们的方法有效地提升了九种最先进的多模态模型在三个时序推理任务上的表现:音频-视觉问答、视频字幕生成和视频-文本检索。
Limitations
局限性
The effectiveness of TWM has been demonstrated on specific multimodal tasks and benchmarks, such as video captioning, question answering, and videotext retrieval. However, its general iz ability to other in-the-wild domains remains unexplored. Extending TWM’s application to other more practical multimodal tasks would be future direction for realworld applications.
TWM 的有效性已在特定多模态任务和基准测试中得到验证,例如视频字幕生成、问答和视频文本检索。然而,其向其他现实领域泛化的能力尚未得到探索。将 TWM 的应用扩展到其他更实际的多模态任务将是未来实际应用的方向。
Ethical Considerations
伦理考量
We examined the study describing the publicly available datasets used in this research and identified no ethical issues regarding the datasets.
我们检查了描述本研究中使用的公开数据集的研究,未发现与数据集相关的伦理问题。
Acknowledgment
致谢
This study is supported by the Department of Defense grant HT9425-23-1-0267.
本研究由国防部资助 HT9425-23-1-0267 支持。
References
参考文献
Alan Baddeley. 2000. The episodic buffer: a new com- ponent of working memory? Trends in cognitive sciences.
Alan Baddeley. 2000. 情景缓冲器:工作记忆的新组成部分? 认知科学趋势。
Association for Computational Linguistics: EMNLP
计算语言学协会:EMNLP
Jiawei Yao, Qi Qian, and Juhua Hu. 2024b. Multimodal proxy learning towards personalized visual multiple clustering. In Conference on Computer Vision and Pattern Recognition.
Jiawei Yao, Qi Qian, 和 Juhua Hu. 2024b. 面向个性化视觉多重聚类的多模态代理学习。在计算机视觉与模式识别会议上。
A Baselines
基准
We evaluate nine MFMs reproduced with opensource code and pretrained weights:
我们评估了九个使用开源代码和预训练权重复现的 MFM:
• LAVisH (Lin et al., 2023): LAVisH adapter uses a small set of latent tokens, forming an attention bottleneck that reduces the quadratic cost of standard cross-attention. The trained LAVisH module alongside Swin-v2 serves as TWM visual encoder.
• LAVisH (Lin et al., 2023): LAVisH 适配器使用一小部分潜在 Token,形成一个注意力瓶颈,降低了标准交叉注意力的二次成本。训练好的 LAVisH 模块与 Swin-v2 一起作为 TWM 视觉编码器。
• DG-SCT (Duan et al., 2023): Adds cross-modal interaction layers to pretrained audio-visual encoders for adaptive extraction across spatial, channel, and temporal dimensions. All DG-SCT and Swin-T blocks serve as TWM visual encoder.
• DG-SCT (Duan 等, 2023):在预训练的音频-视觉编码器中添加跨模态交互层,以实现跨空间、通道和时间维度的自适应提取。所有 DG-SCT 和 Swin-T 模块作为 TWM 视觉编码器。
• LAST-Att (Liu et al., 2024b): Explores the interrelationships between audio-visual-text modalities. Swin-v2 serves as TWM visual encoder.
• LAST-Att (Liu et al., 2024b): 探索了音频-视觉-文本模态之间的相互关系。Swin-v2 作为 TWM 视觉编码器。
• Git (Wang et al., 2022): Simplifies the architecture to a single image encoder and a text decoder under a unified language modeling task. The pretrained image encoder serves as TWM visual encoder.
• Git (Wang et al., 2022): 将架构简化为在统一语言建模任务下的单一图像编码器和文本解码器。预训练的图像编码器作为TWM视觉编码器。
• AKGNN (Hendria et al., 2023): Introduces a grid-based node representation, where nodes are represented by features extracted from a grid of video frames. The trained graph neural network from AKGNN serve as TWM visual encoder.
• AKGNN (Hendria et al., 2023): 引入了一种基于网格的节点表示方法,其中节点由从视频帧网格中提取的特征表示。AKGNN训练后的图神经网络作为TWM视觉编码器。
• CEN (Nadeem et al., 2024): Utilizes independent encoders to capture causal dynamics and generate time-sequenced captions. The pretrained CLIP-ViT from CEN serves as TWM visual encoder.
• CEN (Nadeem et al., 2024):使用独立的编码器捕捉因果动态并生成时间序列描述。CEN中预训练的CLIP-ViT作为TWM视觉编码器。
• VINDLU (Cheng et al., 2023): Develops a stepwise approach for efficient VidL pre training. The trained video encoder from VINDLU serves as TWM visual encoder.
VINDLU (Cheng et al., 2023):开发了一种逐步方法用于高效的 VidL 预训练。VINDLU 训练的视频编码器作为 TWM 的视觉编码器。
• TESTA (Ren et al., 2023): Compresses video semantics by adaptively aggregating similar frames and similar blocks within each frame. The full video encoder blocks from TESTA serve as TWM visual encoder.
• TESTA (Ren et al., 2023): 通过自适应聚合每帧中的相似帧和相似块来压缩视频语义。TESTA 的完整视频编码块作为 TWM 视觉编码器。
• MovieSeq (Lin et al., 2024): Through instruction tuning, MovieSeq enables a language model to interact with videos using cross-modal instructions. CLIP vision encoder from MovieSeq serve as TWM visual encoder.
• MovieSeq (Lin et al., 2024): 通过指令微调,MovieSeq 使语言模型能够使用跨模态指令与视频交互。MovieSeq 的 CLIP 视觉编码器作为 TWM 视觉编码器。
B Ablation Studies
B 消融研究
To thoroughly investigate the effectiveness of two key components in TWM and analyze their relative contributions to model performance, we conduct comprehensive ablation experiments on the MUSIC-AVQA $\mathrm{v}2.0$ dataset (Liu et al., 2024b). Specifically, we examine two critical variants: (1)
为了深入探讨 TWM 中两个关键组件的有效性,并分析它们对模型性能的相对贡献,我们在 MUSIC-AVQA $\mathrm{v}2.0$ 数据集 (Liu et al., 2024b) 上进行了全面的消融实验。具体来说,我们研究了两个关键变体:(1)
TWM w/o VWM, where TWM is exclusively applied to the auditory modality while retaining the baseline model’s original distribution for visual features, and (2) TWM w/o AWM, where TWM is solely applied to visual modality while maintaining the original auditory distribution.
TWM w/o VWM,其中TWM仅应用于听觉模态,同时保留基线模型对视觉特征的原始分布;(2) TWM w/o AWM,其中TWM仅应用于视觉模态,同时保持原始的听觉分布。
As shown in Figure 7, the ablation studies reveal several notable findings. First, Visual Working Memory (VWM) demonstrates substantial impact on both visual perception and cross-modal understanding. Taking DG-SCT+TWM as an example, the removal of VWM leads to significant performance degradation in VQA $(-3.15%)$ and AVQA $(-8.39%)$ average scores, indicating VWM’s crucial role in capturing and refining temporal dependencies in visual features. Second, Auditory Working Memory (AWM) exhibits particularly strong effects on audio-related tasks, evidenced by a notable $4.67%$ decrease in AQA performance when
如图 7 所示,消融研究揭示了一些显著发现。首先,视觉工作记忆 (Visual Working Memory, VWM) 对视觉感知和跨模态理解具有重大影响。以 DG-SCT+TWM 为例,移除 VWM 会导致 VQA $(-3.15%)$ 和 AVQA $(-8.39%)$ 平均分数显著下降,表明 VWM 在捕捉和优化视觉特征中的时间依赖性方面起着关键作用。其次,听觉工作记忆 (Auditory Working Memory, AWM) 在音频相关任务中表现出特别强的影响,AQA 性能显著下降 $4.67%$。

Figure 7: Ablation studies on different components of TWM using MUSIC-AVQA $\mathrm{v}2.0$ dataset (Liu et al., 2024b). We evaluate the effectiveness of two key components in TWM: Visual Working Memory (VWM) which refines temporal features in visual modality, and Audio Working Memory (AWM) which refines temporal features in audio modality. TWM w/o VWM indicates TWM is only applied to auditory modality while visual features retain the baseline model’s distribution, and TWM w/o AWM indicates TWM is only applied to visual modality while maintaining the original auditory distribution.
图 7: 使用 MUSIC-AVQA $\mathrm{v}2.0$ 数据集 (Liu et al., 2024b) 对 TWM 不同组件的消融研究。我们评估了 TWM 中两个关键组件的有效性:视觉工作记忆 (VWM) 用于优化视觉模态的时间特征,以及听觉工作记忆 (AWM) 用于优化听觉模态的时间特征。TWM w/o VWM 表示 TWM 仅应用于听觉模态,而视觉特征保留基线模型的分布,TWM w/o AWM 表示 TWM 仅应用于视觉模态,同时保持原始的听觉分布。
removing AWM from LAVisH $\scriptstyle+$ TWM, while its impact on visual tasks remains relatively minimal (e.g., $-0.35%$ in LAST-Att+TWM’s VQA performance). Most notably, the complete TWM framework $(\mathrm{AWM+VWM})$ consistently achieves promising performance across all evaluation metrics, with particularly impressive gains in cross-modal scenarios. For example, DG-SCT+TWM shows substan- tial improvements over its ablated variants, achieving an $8.39%$ boost in AVQA average performance. These results empirically validate our hypothesis that AWM and VWM serve complementary functions in enhancing multimodal feature representations, which is essential for robust multimodal temporal reasoning.
从LAVisH $\scriptstyle+$ TWM中移除AWM,其对视觉任务的影响相对较小(例如,LAST-Att+TWM的VQA性能下降 $-0.35%$)。最值得注意的是,完整的TWM框架 $(\mathrm{AWM+VWM})$ 在所有评估指标上始终表现出色,尤其是在跨模态场景中取得了显著的提升。例如,DG-SCT+TWM相比其简化版本表现出显著的改进,在AVQA的平均性能上提升了 $8.39%$。这些结果从经验上验证了我们的假设,即AWM和VWM在增强多模态特征表示方面具有互补功能,这对于稳健的多模态时序推理至关重要。
To further validate the general iz ability of these findings across different tasks and datasets, we conduct additional quantitative evaluations illustrated in Figure 8 and Figure 9. Figure 8 presents a systematic performance evaluation of video-text retrieval models on the CMD dataset, where the comparative analysis demonstrates consistent performance improvements across multiple retrieval metrics after incorporating TWM. The empirical results from Figure 9 further validate TWM’s contribution through a comprehensive assessment of video captioning quality on the MSR-VTT dataset, where the evaluation spans multiple standard captioning metrics. These visualization s collectively substantiate TWM’s capability to enhance model performance across different architectures and tasks, with particularly pronounced improvements observed in certain evaluation criteria.
为了进一步验证这些发现在不同任务和数据集上的泛化能力,我们进行了额外的定量评估,如图 8 和图 9 所示。图 8 展示了在 CMD 数据集上对视频-文本检索模型的系统性性能评估,其中比较分析表明在引入 TWM 后,多个检索指标的性能均得到了持续提升。图 9 中的实证结果通过对 MSR-VTT 数据集上的视频字幕质量进行全面评估,进一步验证了 TWM 的贡献,评估涵盖了多个标准字幕指标。这些可视化结果共同证实了 TWM 在不同架构和任务中提升模型性能的能力,在某些评估标准中观察到的改进尤为显著。

Figure 8: TWM on video-text retrieval models using CMD dataset (Bain et al., 2020). Lighter bars indicate baseline models while darker bars represent baseline models enhanced with TWM.
图 8: 使用 CMD 数据集的视频-文本检索模型上的 TWM (Bain et al., 2020)。浅色条表示基线模型,深色条表示使用 TWM 增强的基线模型。

Figure 9: TWM on video captioning models using MSRVTT dataset (Xu et al., 2016). Lighter bars indicate baseline models while darker bars represent baseline models enhanced with TWM.
图 9: 使用 MSRVTT 数据集 (Xu et al., 2016) 的视频字幕模型上的 TWM。浅色条表示基线模型,而深色条表示使用 TWM 增强的基线模型。
C Additional Case Studies
C 附加案例研究
In addition to Section 4.3, we examine TWM’s integration with different state-of-the-art models through four detailed case studies: crowd scene under standing, indoor performance analysis, dynamic action sequences, and social interaction comprehension. These cases highlight TWM’s capability in frame selection, temporal coherence maintenance, and visual information preservation across diverse scenarios.
除了第 4.3 节,我们还通过四个详细的案例研究来探讨 TWM 与不同最先进模型的集成:人群场景理解、室内性能分析、动态动作序列和社交互动理解。这些案例突出了 TWM 在帧选择、时间一致性维护和跨多样场景的视觉信息保存方面的能力。
C.1 Crowd Scene Understanding
C.1 人群场景理解
Figure 10 shows TWM’s integration with DG-SCT (Duan et al., 2023) on the MUSIC-AVQA v2.0 dataset (Liu et al., 2024b), demonstrating its capabilities in handling complex crowd scenes in a street performance setting. The frame selection reveals TWM’s systematic approach to managing dynamic crowd environments. In early frames, TWM establishes the overall scene context, capturing the spatial layout and crowd distribution. During the main sequence, it maintains tracking of individual performers while preserving their spatial relationships within the crowd. This strategic frame selection enhances DG-SCT’s ability to understand complex crowd interactions while filtering out redundant or less informative frames.
图 10 展示了 TWM 在 MUSIC-AVQA v2.0 数据集 (Liu et al., 2024b) 上与 DG-SCT (Duan et al., 2023) 的集成,展示了其在处理街头表演场景中复杂人群场景的能力。帧选择揭示了 TWM 在管理动态人群环境中的系统性方法。在早期帧中,TWM 建立了整体场景上下文,捕捉了空间布局和人群分布。在主序列期间,它保持对个体表演者的跟踪,同时保留了他们在人群中的空间关系。这种策略性的帧选择增强了 DG-SCT 理解复杂人群交互的能力,同时过滤掉了冗余或信息较少的帧。
C.2 Indoor Scene Understanding
C.2 室内场景理解
Figure 11 demonstrates TWM’s effectiveness when integrated with LAVisH (Lin et al., 2023) on MUSIC-AVQA $\mathrm{v}2.0$ for analyzing indoor performance scenes. Within this controlled environment, TWM exhibits precise frame selection that captures the key moments of performance. The selection strategy begins with establishing shots of the performance space, followed by carefully chosen frames that track the performer’s movements. TWM’s enhancement enables LAVisH to better handle indoor lighting conditions and maintain focus on the main subject despite varying camera angles and performer positions, demonstrating strong visual coherence in indoor settings.
图 11 展示了 TWM 与 LAVisH (Lin et al., 2023) 在 MUSIC-AVQA $\mathrm{v}2.0$ 上集成时,用于分析室内表演场景的有效性。在此控制环境中,TWM 展示了精确的帧选择,捕捉了表演的关键时刻。选择策略从表演空间的建立镜头开始,随后是跟踪表演者动作的精心挑选的帧。TWM 的增强使 LAVisH 能够更好地处理室内照明条件,并在不同的相机角度和表演者位置下保持对主体的聚焦,展示了在室内环境中的强大视觉一致性。
C.3 Dynamic Action Sequences
C.3 动态动作序列
Figure 12 illustrates TWM’s enhancement of TESTA (Ren et al., 2023) on the CMD dataset (Bain et al., 2020) for handling fast-paced action in "Kid’s bike spins out in the middle of his race with Dogg". The frame selection shows TWM’s adaptive sampling strategy for dynamic events. The mechanism increases the sampling density during crucial moments of the action, particularly during the spin-out sequence. It maintains broader context through strategic selection of frames before and after the key event, enabling TESTA to better balance between capturing fine-grained action details and maintaining overall scene comprehension.
图 12 展示了 TWM 在 CMD 数据集 (Bain et al., 2020) 上对 TESTA (Ren et al., 2023) 的增强效果,用于处理 "Kid’s bike spins out in the middle of his race with Dogg" 中的快速动作。帧选择展示了 TWM 对动态事件的自适应采样策略。该机制在动作的关键时刻增加了采样密度,尤其是在旋转失控的序列中。它通过在关键事件前后策略性地选择帧来保持更广泛的上下文,使 TESTA 能够在捕捉细粒度动作细节和保持整体场景理解之间更好地平衡。
C.4 Social Interaction Analysis
C.4 社交互动分析
The case in Figure 13 showcases TWM’s integration with MovieSeq (Lin et al., 2024) on the CMD dataset (Bain et al., 2020) for capturing meaningful social interactions. Through the sequence "Walter introduces his employees to their new boss, The Beaver", TWM’s frame selection effectively traces the progression of this social event. The initial frames establish the gathering context, showing the assembly of employees. The middle sequence frames capture key moments of the introduction, while later frames document audience reactions and interaction outcomes. This selection pattern enhances MovieSeq’s ability to maintain narrative coherence through selective frame retention.
图 13 中的案例展示了 TWM 在 CMD 数据集 (Bain et al., 2020) 上与 MovieSeq (Lin et al., 2024) 的集成,用于捕捉有意义的社会互动。通过序列 "Walter 向他的员工介绍他们的新老板 The Beaver",TWM 的帧选择有效地追踪了这一社交事件的进展。初始帧建立了聚集的上下文,展示了员工的集合。中间序列帧捕捉了介绍的关键时刻,而后续帧则记录了观众的反应和互动结果。这种选择模式增强了 MovieSeq 通过选择性帧保留来维持叙事连贯性的能力。
C.5 Summary of Findings
C.5 研究发现总结
These real-world examples reveal several key aspects of TWM’s operation in visual processing. The mechanism exhibits sophisticated understanding of scene dynamics, shown through its adaptive frame selection patterns across diverse environments. In crowd scenes with DG-SCT, it maintains multiple subject tracking while effectively filtering out redundant background information. For indoor venues with LAVisH, TWM demonstrates precise control over frame selection despite challenging lighting conditions and varying camera angles. In social interactions through MovieSeq, it shows awareness of narrative structure, selecting frames that preserve story progression, while in action sequences with TESTA, it employs dynamic sampling rates that respond to motion intensity and event significance.
这些实际案例揭示了 TWM 在视觉处理中的几个关键操作方面。该机制通过对不同环境中的自适应帧选择模式,展示了对场景动态的复杂理解。在 DG-SCT 的拥挤场景中,它保持了多个主体的跟踪,同时有效过滤了冗余的背景信息。对于 LAVisH 的室内场所,TWM 在具有挑战性的光照条件和变化的摄像机角度下,展示了精确的帧选择控制。在 MovieSeq 的社交互动中,它表现出了对叙事结构的意识,选择了保持故事进展的帧,而在 TESTA 的动作序列中,它采用了动态采样率,以响应运动强度和事件的重要性。
TWM consistently achieves significant frame reduction while preserving essential visual information across different models and datasets. Its selection strategy ensures temporal coherence across selected frames, whether handling complex social scenes, dynamic actions, crowded environments, or indoor performances. This efficiency in frame selection, combined with maintenance of semantic continuity, highlights TWM’s effectiveness as a visual memory management system.
TWM 在不同模型和数据集上始终能够显著减少帧数,同时保留关键的视觉信息。其选择策略确保了所选帧之间的时间连贯性,无论是处理复杂的社交场景、动态动作、拥挤环境还是室内表演。这种帧选择的高效性,结合语义连续性的维护,突显了 TWM 作为视觉记忆管理系统的有效性。

Figure 10: TWM-searched frames with corresponding questions for audio-visual question answering, integrated with DG-SCT (Duan et al., 2023) on the MUSIC-AVQA v2.0 dataset (Liu et al., 2024b). The visualization demonstrates TWM’s capability to search and select key frames that capture comprehensive audio-visual information necessary for answering the posed questions.
图 10: 在 MUSIC-AVQA v2.0 数据集 (Liu et al., 2024b) 上与 DG-SCT (Duan et al., 2023) 集成的音频-视觉问答的 TWM 搜索帧及其对应问题。可视化展示了 TWM 搜索和选择关键帧的能力,这些帧捕捉了回答所提问题所需的全面音频-视觉信息。

Figure 11: TWM-searched frames with corresponding questions for audio-visual question answering, integrated with LAVisH (Lin et al., 2023) on the MUSIC-AVQA $\mathrm{v}2.0$ dataset (Liu et al., 2024b). This visualization showcases TWM’s capability in extracting frames that effectively capture the temporal-semantic information required to answer the given questions.
图 11: 在 MUSIC-AVQA $\mathrm{v}2.0$ 数据集 (Liu et al., 2024b) 上,与 LAVisH (Lin et al., 2023) 集成的 TWM 搜索帧及其对应问题,用于音视频问答。此可视化展示了 TWM 在提取能够有效捕捉回答问题所需的时序语义信息帧方面的能力。

Figure 12: TWM-searched frames with corresponding text description for video-text retrieval, integrated with TESTA (Ren et al., 2023) on the CMD dataset (Bain et al., 2020). The visualization demonstrates TWM’s effectiveness in searching and selecting key frames that preserve the temporal-semantic information from the video sequence.
图 12: 使用 TWM 搜索的帧及其对应的文本描述,用于视频-文本检索,集成在 CMD 数据集 (Bain et al., 2020) 上的 TESTA (Ren et al., 2023)。可视化展示了 TWM 在搜索和选择保留视频序列时间语义信息的关键帧方面的有效性。

Figure 13: TWM-searched frames with corresponding text description for video-text retrieval, integrated with MovieSeq (Lin et al., 2024) on the CMD dataset (Bain et al., 2020). This example illustrates TWM’s capability to select visual frames that effectively capture the essential temporal dynamics and semantic information.
图 13: 在 CMD 数据集 (Bain et al., 2020) 上,结合 MovieSeq (Lin et al., 2024) 进行视频-文本检索时,TWM 搜索到的帧及其对应的文本描述。该示例展示了 TWM 选择能够有效捕捉关键时间动态和语义信息的视觉帧的能力。