OpenRLHF: An Easy-to-use, Scalable and High-performance RLHF Framework
OpenRLHF: 一个易用、可扩展且高性能的 RLHF 框架
Abstract
摘要
As large language models (LLMs) continue to grow by scaling laws, reinforcement learning from human feedback (RLHF) has gained significant attention due to its outstanding performance. However, unlike pre training or fine-tuning a single model, scaling reinforcement learning from human feedback (RLHF) for training large language models poses coordination challenges across four models. We present OpenRLHF, an open-source framework enabling efficient RLHF scaling. Unlike existing RLHF frameworks that co-locate four models on the same GPUs, OpenRLHF re-designs scheduling for the models beyond 70B parameters using Ray, vLLM, and DeepSpeed, leveraging improved resource utilization and diverse training approaches. Integrating seamlessly with Hugging Face, OpenRLHF provides an out-of-the-box solution with optimized algorithms and launch scripts, which ensures user-friendliness. OpenRLHF implements RLHF, DPO, rejection sampling, and other alignment techniques. Empowering state-of-the-art LLM development, OpenRLHF’s code is available at https://github.com/OpenRLHF/OpenRLHF.
随着大语言模型 (LLMs) 通过扩展定律不断增长,基于人类反馈的强化学习 (RLHF) 因其出色的表现而受到广泛关注。然而,与预训练或微调单个模型不同,扩展基于人类反馈的强化学习 (RLHF) 来训练大语言模型在协调四个模型方面提出了挑战。我们提出了 OpenRLHF,这是一个开源框架,能够实现高效的 RLHF 扩展。与现有的 RLHF 框架将四个模型部署在同一 GPU 上不同,OpenRLHF 使用 Ray、vLLM 和 DeepSpeed 重新设计了超过 70B 参数模型的调度,利用改进的资源利用率和多样化的训练方法。OpenRLHF 与 Hugging Face 无缝集成,提供了开箱即用的解决方案,包含优化算法和启动脚本,确保了用户友好性。OpenRLHF 实现了 RLHF、DPO、拒绝采样等对齐技术。OpenRLHF 的代码可在 https://github.com/OpenRLHF/OpenRLHF 获取,助力最先进的大语言模型开发。
1 Introduction
1 引言
Although large language models (LLM) have shown remarkable performance improvements following scaling laws, a critical challenge that intensifies with is aligning these models with human values and intentions. Reinforcement Learning from Human Feedback (RLHF) [19] has emerged as a powerful technique to address this longstanding challenge. However, as models grow larger, vanilla RLHF typically requires maintaining multiple models and a more complex learning pipeline, leading to increased demands for memory and computational resources. To illustrate, Proximal Policy Optimization (PPO) [23, 19], a commonly used algorithm in RLHF, requires maintaining four models during training. As a result, as language models increase in size beyond 70 billion parameters, the computational resources and scheduling complexity required for training and coordinating these multiple models grow significantly, posing new demands and challenges for current framework designs.
尽管大语言模型 (LLM) 在遵循缩放定律后表现出显著的性能提升,但随着模型规模的扩大,一个关键的挑战是如何将这些模型与人类价值观和意图对齐。从人类反馈中进行强化学习 (Reinforcement Learning from Human Feedback, RLHF) [19] 已成为解决这一长期挑战的强大技术。然而,随着模型规模的增大,传统的 RLHF 通常需要维护多个模型和更复杂的学习流程,导致内存和计算资源需求的增加。例如,RLHF 中常用的算法近端策略优化 (Proximal Policy Optimization, PPO) [23, 19] 在训练过程中需要维护四个模型。因此,随着语言模型的规模超过 700 亿参数,训练和协调这些多个模型所需的计算资源和调度复杂性显著增加,对当前框架设计提出了新的要求和挑战。
Existing open-source RLHF frameworks such as Transformer Reinforcement Learning (TRL), ColossalChat (CAIChat), and DeepSpeed-Chat (DSChat) rely on parallel iz ation approaches like Zero Redundancy Optimizer (ZeRO) to co-locate the four models involved in RLHF training on the same GPU[15, 30, 21]. However, as models continue to grow past 70 billion parameters, this scheduling approach becomes increasingly inefficient with limited GPU memory. To address the limitations of co-location, some frameworks like TRL compromise on memory usage by merging the actor and critic models or employing techniques like Low-Rank Adaptation (LoRA) [11]. However, these can reduce model performance, and the merged actor-critic architecture is incompatible with the recommended practice of initializing the critic model’s weights using those of the reward model [19]. An alternative solution for large models is to leverage tensor parallelism and pipeline parallelism techniques from NVIDIA Megatron [26]. However, Megatron is not compatible with the popular
现有的开源RLHF框架,如Transformer Reinforcement Learning (TRL)、ColossalChat (CAIChat)和DeepSpeed-Chat (DSChat),依赖于Zero Redundancy Optimizer (ZeRO)等并行化方法,将RLHF训练中涉及的四个模型放置在同一GPU上[15, 30, 21]。然而,随着模型参数超过700亿,这种调度方法在有限的GPU内存下变得越来越低效。为了解决共置的限制,一些框架如TRL通过合并actor和critic模型或采用Low-Rank Adaptation (LoRA)等技术来妥协内存使用[11]。然而,这些方法可能会降低模型性能,并且合并的actor-critic架构与使用奖励模型权重初始化critic模型的推荐做法不兼容[19]。对于大型模型,另一种解决方案是利用NVIDIA Megatron的张量并行和流水线并行技术[26]。然而,Megatron与流行的
Hugging Face library [29], and adapting new models requires extensive source code modifications, hindering usability.
Hugging Face 库 [29],并且适配新模型需要进行大量的源代码修改,阻碍了可用性。
To enable easy RLHF training at scale, OpenRLHF redesigns model scheduling using Ray [18], vLLM [14], and DeepSpeed [22], enabling training of models beyond 70 billion parameters. OpenRLHF seamlessly integrates with Hugging Face Transformers [29] and supports popular technologies such as Mixture of Experts (MoE) [13], Jamba [17] and QLoRA [4]. Furthermore, OpenRLHF implements multiple alignment algorithms, including Direct Preference Optimization (DPO) [20], KahnemanTversky optimization (KTO) [10], conditional SFT [12], and rejection sampling [28], providing an accessible full-scale RLHF training framework. Table 1 compares popular RLHF frameworks.
为实现大规模RLHF训练的便捷性,OpenRLHF利用Ray [18]、vLLM [14]和DeepSpeed [22]重新设计了模型调度机制,使得训练超过700亿参数的模型成为可能。OpenRLHF与Hugging Face Transformers [29]无缝集成,并支持专家混合(Mixture of Experts, MoE)[13]、Jamba [17]和QLoRA [4]等流行技术。此外,OpenRLHF实现了多种对齐算法,包括直接偏好优化(Direct Preference Optimization, DPO)[20]、KahnemanTversky优化(KTO)[10]、条件SFT [12]和拒绝采样 [28],提供了一个易于使用的全方位RLHF训练框架。表1对比了流行的RLHF框架。
| 特性 | OpenRLHF | DSChat | CAIChat | TRL |
|---|---|---|---|---|
| 全量微调模型大小 | ||||
| 70B PPO | 有限 | × | × | |
| 7B PPO 带 4 RTX 4090 | × | |||
| 34B DPO 带 8 A100-80G | × | × | × | |
| 易用性 | ||||
| 兼容 HuggingFace | < | |||
| 训练技术 | ||||
| QLoRA MoE in PPO | < | × | × | < |
| × | × | |||
| Jamba in DPO | × | < | ||
| 未合并的 Actor-Critic 推理引擎 in PPO | < | × | ||
| 对齐算法 | ||||
| PPO 实现技巧 | < | × | × × | < |
| 多奖励模型 | ||||
| DPO | × | × < | ||
| KTO | ||||
| 拒绝采样 | < | |||
| 条件 SFT | < | × | × | × |
Table 1: RLHF frameworks comparison. OpenRLHF supports multi-reward models using Ray, and accelerates popular Hugging Face models using vLLM. The compatibility with the Hugging Face library ensures the framework’s user-friendliness. Limited: DSChat’s Hybrid Engine only supports a limited range of model architectures, such as https://github.com/microsoft/DeepSpeed/ issues/4954. In contrast, OpenRLHF supports all mainstream architectures including MoE using DeepSpeed and vLLM, see the docs https://docs.vllm.ai/en/latest/models/supported_ models.html.
表 1: RLHF 框架对比。OpenRLHF 支持使用 Ray 的多奖励模型,并使用 vLLM 加速流行的 Hugging Face 模型。与 Hugging Face 库的兼容性确保了框架的用户友好性。受限:DSChat 的混合引擎仅支持有限范围的模型架构,例如 https://github.com/microsoft/DeepSpeed/ issues/4954。相比之下,OpenRLHF 支持所有主流架构,包括使用 DeepSpeed 和 vLLM 的 MoE,详见文档 https://docs.vllm.ai/en/latest/models/supported_ models.html。
2 Background
2 背景
2.1 Reinforcement Learning from Human Feedback
2.1 基于人类反馈的强化学习
The classic training of large language models [19] based on a pre-trained Generative Pre-trained Transformer (GPT) involves three steps: Supervised Fine-tuning (SFT), Reward Model (RM) training, and PPO training:
基于预训练的生成式预训练 Transformer (GPT) 训练大语言模型的经典方法 [19] 包括三个步骤:监督微调 (SFT)、奖励模型 (RM) 训练和 PPO 训练:
• Supervised Fine-tuning: The developers fine-tuned a GPT model on human demonstrations from their labelers using a supervised learning loss, as shown in Eq.1.
• 监督微调:开发者使用监督学习损失,根据标注者提供的人类演示数据对 GPT 模型进行了微调,如公式 1 所示。
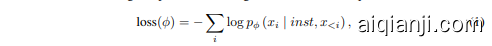
where $x_{i}$ is the $i_{t h}$ token in the sequence, inst is the human instructions and prompts, and $\phi$ is the parameter of the model.
其中 $x_{i}$ 是序列中的第 $i_{t h}$ 个 Token,inst 是人类的指令和提示,$\phi$ 是模型的参数。
• Reward Model training: Starting from the SFT model with the final un embedding layer removed, the developers trained a model to take in a prompt and response and output a scalar reward. Specifically, the loss function for the reward model is given by Eq.2,
• 奖励模型训练:从移除了最终嵌入层的 SFT 模型开始,开发者训练了一个模型,该模型接收提示和响应并输出标量奖励。具体来说,奖励模型的损失函数由公式 2 给出。

where $r_{\theta}(x,y)$ is the scalar output of the reward model with parameters $\theta$ for prompt $x$ and response $y,y_{w}$ is the preferred response out of the pair of $y_{w}$ and $y_{l}$ , and $D$ is the dataset of human comparisons.
其中 $r_{\theta}(x,y)$ 是奖励模型在参数 $\theta$ 下对提示 $x$ 和响应 $y$ 的标量输出,$y_{w}$ 是 $y_{w}$ 和 $y_{l}$ 中更优的响应,$D$ 是人类比较的数据集。
• PPO training: The developers fine-tuned the language model on their bandit environment using Proximal Policy Optimization (PPO). In this environment, a random customer prompt is presented, and a response is expected. The environment then produces a reward determined by the reward model and ends the episode, given the prompt-response pair. Additionally, a per-token Kullback-Leibler (KL) divergence penalty from the SFT model is added at each token to mitigate over-optimization of the reward model. Initializing the value function from the RM weights provides a stable starting point for Reinforcement Learning (RL) fine-tuning. The loss function of PPO is shown in Eq.3.
• PPO训练:开发者在他们的赌博机环境中使用近端策略优化(PPO)对大语言模型进行了微调。在这个环境中,随机呈现一个客户提示,并期望得到一个响应。环境随后根据奖励模型生成一个奖励,并在给定提示-响应对后结束该回合。此外,在每个Token上添加了来自SFT模型的每个Token的Kullback-Leibler(KL)散度惩罚,以减轻奖励模型的过度优化。从RM权重初始化价值函数为强化学习(RL)微调提供了稳定的起点。PPO的损失函数如公式3所示。

where $\pi^{\mathrm{RL}}$ is the learned reinforcement learning policy, $\pi^{\mathrm{SFT}}$ is the supervised fine-tuned model, and $\beta$ is the KL reward coefficient that controls the strength of the KL penalty.
其中,$\pi^{\mathrm{RL}}$ 是学习到的强化学习策略,$\pi^{\mathrm{SFT}}$ 是经过监督微调的模型,$\beta$ 是控制KL惩罚强度的KL奖励系数。
2.2 Ray
2.2 Ray
Ray [18] is a distributed execution framework that provides powerful scheduling and scaling capabilities for parallel and distributed computing workloads. It employs a built-in distributed scheduler to efficiently assign tasks across available resources in a cluster, enabling seamless scaling from a single machine to large-scale deployments with thousands of nodes. Ray’s scheduling mechanism intelligently manages task parallelism, distributing computations as smaller tasks that can be executed concurrently across multiple cores and machines. Ray’s scalable architecture and adept scheduling make it well-suited for accelerating a wide range of data-intensive workloads spanning machine learning, scientific computing, and high-performance data processing pipelines. It provides the compute layer for parallel processing so that users don’t need to be a distributed systems expert.
Ray [18] 是一个分布式执行框架,为并行和分布式计算工作负载提供了强大的调度和扩展能力。它采用了内置的分布式调度器,能够高效地在集群中的可用资源上分配任务,从而实现了从单台机器到拥有数千个节点的大规模部署的无缝扩展。Ray 的调度机制智能地管理任务并行性,将计算任务分解为较小的任务,这些任务可以在多个核心和机器上并发执行。Ray 的可扩展架构和熟练的调度使其非常适合加速各种数据密集型工作负载,包括机器学习、科学计算和高性能数据处理管道。它提供了并行处理的计算层,因此用户无需成为分布式系统专家。
2.3 vLLM
2.3 vLLM
vLLM [14] is a fast and easy-to-use library for LLM inference and serving. It delivers state-ofthe-art serving throughput through efficient management of attention key and value memory with Paged Attention, continuous batching of incoming requests, and fast model execution with CUDA graph. vLLM’s flexibility and ease of use are evident in its seamless integration with popular Hugging Face models, high-throughput serving with various decoding algorithms, tensor parallelism support for distributed inference, and streaming outputs. It supports experimental features like prefix caching and multi-LoRA support. vLLM seamlessly supports the most popular open-source models on Hugging Face, including Transformer-like LLMs (e.g., Llama), Mixture-of-Expert LLMs (e.g., Mixtral [13]).
vLLM [14] 是一个快速且易于使用的库,用于大语言模型推理和服务。它通过高效的注意力键值内存管理(Paged Attention)、对传入请求的连续批处理以及使用 CUDA 图的快速模型执行,提供了最先进的服务吞吐量。vLLM 的灵活性和易用性体现在其与流行的 Hugging Face 模型的无缝集成、使用各种解码算法的高吞吐量服务、分布式推理的张量并行支持以及流式输出。它支持实验性功能,如前缀缓存和多 LoRA 支持。vLLM 无缝支持 Hugging Face 上最受欢迎的开源模型,包括类 Transformer 大语言模型(例如 Llama)、专家混合大语言模型(例如 Mixtral [13])。
2.4 DeepSpeed
2.4 DeepSpeed
DeepSpeed [22] is an optimization library designed to enhance the efficiency of large-scale deeplearning models. Its Zero Redundancy Optimizer (ZeRO) [21] significantly reduces memory consumption by partitioning model states, gradients, and optimizer states across data-parallel processes, enabling the training of models with trillions of parameters. Additionally, DeepSpeed’s offloading features seamlessly transfer data between CPU and GPU memory, further optimizing resource utilization and enabling efficient training of extensive models on hardware with limited GPU memory. DeepSpeed also seamlessly supports the most popular open-source models on Hugging Face.
DeepSpeed [22] 是一个旨在提升大规模深度学习模型效率的优化库。它的零冗余优化器 (ZeRO) [21] 通过在数据并行过程中对模型状态、梯度和优化器状态进行分区,显著减少了内存消耗,从而能够训练具有数万亿参数的模型。此外,DeepSpeed 的卸载功能在 CPU 和 GPU 内存之间无缝传输数据,进一步优化了资源利用率,并使得在 GPU 内存有限的硬件上高效训练大规模模型成为可能。DeepSpeed 还可以无缝支持 Hugging Face 上最受欢迎的开源模型。
3 Design of OpenRLHF
3 OpenRLHF 设计
3.1 Scheduling Optimization
3.1 调度优化
Scaling RLHF training to larger models requires efficiently allocating at least four component models (actor, critic, reward, reference) across multiple GPUs due to the memory limit of each accelerator (e.g., under $80:\mathrm{GB}$ for NVIDIA A100). OpenRLHF innovates on model scheduling by leveraging the Ray [18] for model placement and fine-grained orchestration. Meanwhile, the Ray-based scheduler manages inference-optimized libraries such as vLLM [14] and training-optimized libraries such as deepspeed. OpenRLHF distributes the four models across multiple GPUs instead of co-locating them on the same GPU, as illustrated in Figure 1. This design naturally supports multi-reward models [28] (as shown in Figure 2) during the RLHF training process for different algorithm implementation choices. Algorithm engineers could quickly build up various alignment strategies such as usefulness and harmfulness separation without concerning the detail of the underlying data flow.
将 RLHF 训练扩展到更大的模型需要高效地在多个 GPU 上分配至少四个组件模型(actor、critic、reward、reference),原因是每个加速器的内存限制(例如,NVIDIA A100 的内存低于 $80:\mathrm{GB}$)。OpenRLHF 通过利用 Ray [18] 进行模型放置和细粒度编排,在模型调度上进行了创新。同时,基于 Ray 的调度器管理着推理优化的库(如 vLLM [14])和训练优化的库(如 deepspeed)。OpenRLHF 将这四个模型分布在多个 GPU 上,而不是将它们放在同一个 GPU 上,如图 1 所示。这种设计自然支持在 RLHF 训练过程中使用多奖励模型 [28](如图 2 所示),以适应不同的算法实现选择。算法工程师可以快速构建各种对齐策略,例如有用性和有害性分离,而无需关心底层数据流的细节。

Figure 1: Ray Architecture of OpenRLHF. The four models in RLHF are distributed across different GPUs by Ray, which can also be freely merged or offloaded to save GPUs. The vLLM is used to accelerate actor generation. OpenRLHF synchronizes the weights of the ZeRO engine to the vLLM engine using the NVIDIA Collective Communications Library (NCCL).
图 1: OpenRLHF 的 Ray 架构。RLHF 中的四个模型通过 Ray 分布在不同 GPU 上,也可以自由合并或卸载以节省 GPU。vLLM 用于加速 actor 生成。OpenRLHF 使用 NVIDIA 集体通信库 (NCCL) 将 ZeRO 引擎的权重同步到 vLLM 引擎。
Our scheduler design allows flexible model merging or offloading strategies using Ray and DeepSpeed. For example, the actor-reference or critic-reward models can be merged to save GPU resources. Besides the benefits of highly customizable algorithm implementation, the scheduler improves the overall training performance by optimally orchestrating GPUs. More details will be discussed in the next section, but scheduler optimization is the cornerstone for further efficiency improvements.
我们的调度器设计允许使用 Ray 和 DeepSpeed 实现灵活的模型合并或卸载策略。例如,可以将 actor-reference 或 critic-reward 模型合并以节省 GPU 资源。除了高度可定制的算法实现带来的优势外,调度器通过优化 GPU 编排提高了整体训练性能。更多细节将在下一节讨论,但调度器优化是进一步提高效率的基石。

Figure 2: Flow diagram of RLHF in generation stage: the design of OpenRLHF supports flexible placement of multiple models with various algorithm implementations.
图 2: RLHF 在生成阶段的流程图:OpenRLHF 的设计支持灵活部署多种模型,并提供多种算法实现。

Figure 3: Flow diagram of RLHF in learning stage: two learnable models are scheduled by OpenRLHF to maximize the overall training throughput
图 3: 学习阶段中 RLHF 的流程图:OpenRLHF 调度两个可学习模型以最大化整体训练吞吐量
The performance of RLHF algorithms depends on both training and inference efficiency. From the profiling result using LLaMA2 7B and NVIDIA A100 (as shown in Figure 4a), the primary bottleneck is at the PPO sample generation stage which takes up $80,%$ of overall training time. This is because, in the generation stage, the autoregressive decoding complexity is at $O(n^{2})$ and memory-bound. Figure 4b shows that the larger inference batch size can significantly improve the generation throughput. RLHF Frameworks such as Deep Speed Chat and TRL that share GPUs across all models lead to insufficient available memory during the generation stage, preventing an increase in batch size and exacerbating the issue of low memory access efficiency. OpenRLHF distributes the four models across multiple GPUs using Ray, effectively alleviating the problem.
RLHF 算法的性能取决于训练和推理效率。根据使用 LLaMA2 7B 和 NVIDIA A100 的分析结果(如图 4a 所示),主要瓶颈在于 PPO 样本生成阶段,该阶段占用了整体训练时间的 $80,%$。这是因为在生成阶段,自回归解码的复杂度为 $O(n^{2})$,并且受内存限制。图 4b 显示,较大的推理批次大小可以显著提高生成吞吐量。Deep Speed Chat 和 TRL 等 RLHF 框架在所有模型之间共享 GPU,导致生成阶段可用内存不足,无法增加批次大小,从而加剧了内存访问效率低下的问题。OpenRLHF 使用 Ray 将四个模型分布在多个 GPU 上,有效缓解了这一问题。

(a) RLHF stages (b) Infer Batch Size Figure 4: Performance Profiling using LLaMA2 7B and NVIDIA A100.
图 4: 使用 LLaMA2 7B 和 NVIDIA A100 的性能分析
To further accelerate sample generation and support larger LLMs such as 70B models that can’t located in a single GPU, OpenRLHF leverages vLLM’s tensor parallelism and other advanced techniques (e.g., continuous batching and paged attention [14]) for the generation, as shown in Figure 1. In the RLHF learning stage, OpenRLHF also employs the following techniques as additional improvements, see Figure 3:
为了进一步加速样本生成并支持无法在单个 GPU 上运行的 70B 等大型大语言模型,OpenRLHF 利用了 vLLM 的张量并行性及其他先进技术(例如连续批处理和分页注意力 [14])进行生成,如图 1 所示。在 RLHF 学习阶段,OpenRLHF 还采用了以下技术作为额外改进,见图 3:
• Offloading Adam optimizer states to the CPU frees up GPU memory, allowing for larger batch sizes during generation (without vLLM) and training. This approach enhances computational efficiency and reduces ZeRO communication costs. Pinned memory and gradient accumulation are applied to mitigate GPU-CPU communication overhead during gradient aggregation. • Employing Flash Attention 2 [3] accelerates Transformer model training. • Remove redundant padding from training samples using PyTorch tensor slicing.
• 将 Adam 优化器状态卸载到 CPU 可以释放 GPU 内存,从而在生成(不使用 vLLM)和训练期间支持更大的批量大小。这种方法提高了计算效率,并减少了 ZeRO 通信成本。在梯度聚合过程中,使用固定内存和梯度累积来缓解 GPU-CPU 通信开销。
• 使用 Flash Attention 2 [3] 加速 Transformer 模型训练。
• 使用 PyTorch 张量切片去除训练样本中的冗余填充。
The remaining three models shown in Figure 2 use ZeRO stage 3 (sharding the model, gradients, and optimizer). OpenRLHF synchronizes the weights between the ZeRO and vLLM engines using NVIDIA NCCL and the vLLM weight loader, ensuring fast and simple integration. We compare the performance of OpenRLHF with our carefully tuned DSChat in Section 4.1.
图 2 中显示的其余三个模型使用了 ZeRO 阶段 3(对模型、梯度和优化器进行分片)。OpenRLHF 使用 NVIDIA NCCL 和 vLLM 权重加载器在 ZeRO 和 vLLM 引擎之间同步权重,确保快速且简单的集成。我们将在第 4.1 节中比较 OpenRLHF 与我们精心调优的 DSChat 的性能。
3.3 PPO Implementation Tricks
3.3 PPO 实现技巧
Reinforcement learning (RL) algorithms like PPO can be prone to instability when training large language models (LLMs). We have verified the implementation details to our best effort and the general inference and learning procedure has been shown in Figure 2 and 3 for reference. Furthermore, OpenRLHF applies several tricks to stabilize training in the PPO implementation [8] including
在训练大语言模型 (LLMs) 时,像 PPO 这样的强化学习 (RL) 算法可能会容易出现不稳定的情况。我们已经尽最大努力验证了实现细节,并且在图 2 和图 3 中展示了通用的推理和学习过程以供参考。此外,OpenRLHF 在 PPO 实现中应用了一些技巧来稳定训练 [8],包括
More details are in the blog [25].
更多细节请参阅博客 [25]。
3.4 Ease of Use
3.4 易用性
For user-friendliness, OpenRLHF provides one-click trainable scripts for supported algorithms, fully compatible with the Hugging Face library for specifying model and dataset names or paths. Below is the configuration for RLHF training of the 70B model on 16 A100s:
为方便用户使用,OpenRLHF 针对支持的算法提供了一键可训练的脚本,完全兼容 Hugging Face 库,用于指定模型和数据集名称或路径。以下是 16 个 A100 上 70B 模型的 RLHF 训练配置:

Listing 1: PPO startup method based on Deepspeed and Ray
图 1: 基于 Deepspeed 和 Ray 的 PPO 启动方法
4 Experiments
4 实验
| 规模 | NVIDIA A800 GPUs | 优化后的 DSChat | OpenRLHF | 加速比 |
|---|---|---|---|---|
| 7B | 16 | 855.09 | 471.11 | 1.82x |
| 13B | 32 | 1528.93 | 608.93 | 2.5x |
| 34B | 32 | 3634.98 | 1526.4 | 2.4x |
| 70B | 32 | 10407.0 | 4488.53 | 2.3x |
Table 2: The average time (seconds) it took to train 1024 prompts with 1 PPO epoch using the Optimized DSChat and OpenRLHF.
表 2: 使用 Optimized DSChat 和 OpenRLHF 训练 1024 个提示并运行 1 个 PPO epoch 的平均时间(秒)。
| 规模 | 总 GPU 数 | Actor | Critic | Ref | RM | vLLMEngine |
|---|---|---|---|---|---|---|
| 7B | 16 | 4 | 4 | 2 | 2 | DP=4,TP=1,MBS=16 |
| 13B | 32 | 8 | 8 | 4 | 4 | DP=8,TP=1,MBS=8 |
| 34B | 32 | 8 | 8 | 4 | 4 | DP=4,TP=2,MBS=8 |
| 70B | 32 | 4 | 4 | 4 | 4 | DP=4,TP=4,MBS=4 |
Table 3: OpenRLHF configurations. The numbers in the table indicate the number of GPUs assigned to each model. We enabled Adam offload for all models. DP: data parallel size, TP: tensor prallesim size, MBS: micro batch size (per GPU)
Table 4: DSChat configurations. DP: data parallel size, TP: tensor prallesim size, MBS: micro batch size (per GPU).
表 3: OpenRLHF 配置。表中的数字表示分配给每个模型的 GPU 数量。我们为所有模型启用了 Adam offload。DP: 数据并行大小,TP: 张量并行大小,MBS: 微批次大小(每个 GPU)
| 大小 | 总 GPU 数量 | 优化器 | 奖励和参考模型 | 混合引擎 |
|---|---|---|---|---|
| 7B | 16 | AdamOffload PinnedMemory | ZeRO-3, | DP=16,TP=1,MBS=8 |
| 13B | 32 | AdamOffload PinnedMemory | ParamOffload, Pinned Memory | DP=32,TP=1,MBS=4 |
| 34B | 32 | AdamOffload PinnedMemory | DP=4,TP=8,MBS=4 | |
| 70B | 32 | AdamOffload PinnedMemory | DP=4,TP=8,MBS=2 |
表 4: DSChat 配置。DP: 数据并行大小,TP: 张量并行大小,MBS: 微批次大小(每个 GPU)
4.1 Performance Benchmark
4.1 性能基准
In Tables 3 and 4, we present the configurations used for the RLHF performance experiments. We train the LLaMA2 models using NVIDIA A800 GPUs with NVLINK for data transfer. We optimized DSChat’s performance to the greatest extent possible by employing techniques such as enabling Adam offload, along with reward model (RM) and reference model (Ref) offload to increase the micro-batch size during the inference stage and avoid out-of-memory issues. We even fixed some bugs in DSChat to enable the Hybrid Engine (HE) for LLaMA2 1.
在表 3 和表 4 中,我们展示了用于 RLHF 性能实验的配置。我们使用配备 NVLINK 的 NVIDIA A800 GPU 训练 LLaMA2 模型。通过采用 Adam offload、奖励模型 (RM) 和参考模型 (Ref) offload 等技术,我们最大程度地优化了 DSChat 的性能,以增加推理阶段的微批次大小并避免内存不足的问题。我们甚至修复了 DSChat 中的一些错误,以启用 LLaMA2 1 的混合引擎 (HE)。
Table 5 and 6 illustrate the detailed time consumption of each stage of PPO in OpenRLHF and Optimized DSChat, respectively. Despite not fully optimizing the PPO performance of OpenRLHF, such as consolidating the actor and reference models nodes, as well as the critic and reward models nodes to reduce GPU resources, the experimental results demonstrate that OpenRLHF still exhibits considerable performance advantages in Table 2.
表5和表6分别展示了OpenRLHF和Optimized DSChat中PPO各阶段的详细时间消耗。尽管OpenRLHF的PPO性能尚未完全优化,例如未将actor和reference模型节点以及critic和reward模型节点合并以减少GPU资源,但实验结果表明,OpenRLHF在表2中仍展现出显著的性能优势。
The performance advantages of OpenRLHF over DSChat primarily stem from vLLM and Ray. On the one hand, the generation acceleration of vLLM is substantially better than that of Hybrid Engine. On the other hand, Ray distributes the model across different nodes, which may seem to reduce GPU utilization. However, it avoids excessive model splitting and model weights offloading, thereby saving GPU memory and reducing communication overhead. This allows for an increase in the micro-batch size per GPU and the size of matrix multiplication in tensor parallelism, improving overall performance.
OpenRLHF 相对于 DSChat 的性能优势主要源于 vLLM 和 Ray。一方面,vLLM 的生成加速效果显著优于 Hybrid Engine。另一方面,Ray 将模型分布在不同节点上,虽然看似降低了 GPU 利用率,但避免了过度的模型分割和模型权重卸载,从而节省了 GPU 内存并减少了通信开销。这使得每个 GPU 的微批次大小和张量并行中的矩阵乘法规模得以增加,从而提升了整体性能。
Table 5: The time consumption (seconds) of each stage of PPO to train 1024 prompts with 1 PPO epoch in OpenRLHF.
| 大小 | GPU数量 | 生成 | vLLM权重同步 | 获取Logits、奖励 | 训练 | 总计 |
|---|---|---|---|---|---|---|
| 7B | 16 | 262.96 | 4.32 | 32.7 | 171.13 | 471.11 |
| 13B | 32 | 372.14 | 10.03 | 29.58 | 197.18 | 608.93 |
| 34B | 32 | 720.50 | 35.47 | 326.00 | 444.43 | 1526.40 |
| 70B | 32 | 2252.79 | 111.65 | 323.38 | 1800.71 | 4488.53 |
表 5: OpenRLHF中使用1个PPO轮次训练1024个提示时,PPO各阶段的时间消耗(秒)。
Table 6: The time consumption (seconds) of each stage of PPO to train 1024 prompts with 1 PPO epoch in Optimized DSChat.
表 6: 在 Optimized DSChat 中使用 1 个 PPO epoch 训练 1024 个提示时,每个阶段的时间消耗(秒)。
| 大小 | GPU 数量 | 生成 | HE 权重同步 | 获取 Logits, 奖励 | 训练 | 总计 |
|---|---|---|---|---|---|---|
| 7B | 16 | 590.157 | 65.573 | 73.68 | 125.68 | 855.09 |
| 13B | 32 | 1146.614 | 156.356 | 87.28 | 138.68 | 1528.93 |
| 34B | 32 | 1736.024 | 434.006 | 443.12 | 1021.83 | 3634.98 |
| 70B | 32 | 3472.68 | 1157.56 | 2013.44 | 3763.32 | 10407.00 |
4.2 Training Stability and Convergence
4.2 训练稳定性与收敛性

Figure 5: PPO training curves.
图 5: PPO 训练曲线。
We then evaluated the training convergence of the OpenRLHF framework based on the LLaMA2 7B model, where the supervised fine-tuning (SFT) stage utilized a $50\mathrm{k}$ dataset from OpenOrca 2, and the preference dataset for training the reward model was a mixture of around $200\mathbf{k}$ samples from the Anthropic $\mathrm{HH}^{,3}$ , LMSys Arena 4, and Open Assistant 5 datasets. The Proximal Policy Optimization (PPO) training used 80k prompts randomly sampled from these previous datasets. Direct Policy Optimization (DPO) training used the same dataset as the reward model training.
我们随后基于 LLaMA2 7B 模型评估了 OpenRLHF 框架的训练收敛性,其中监督微调 (SFT) 阶段使用了来自 OpenOrca 2 的 $50\mathrm{k}$ 数据集,而用于训练奖励模型的偏好数据集则是来自 Anthropic $\mathrm{HH}^{,3}$、LMSys Arena 4 和 Open Assistant 5 数据集的约 $200\mathbf{k}$ 样本的混合。近端策略优化 (PPO) 训练使用了从这些先前数据集中随机抽取的 80k 提示。直接策略优化 (DPO) 训练使用了与奖励模型训练相同的数据集。
To stabilize the PPO training, we use a low learning rate $5e^{-7}$ for the actor model and a higher learning rate $9e^{-6}$ for the critic model. The PPO epoch is set to 1, the rollout batch size is 1024, the clip range is 0.2, and the mini-batch size is 128. For DPO, we set the learning rate to $5e^{-7}$ , batch size to 128, and $\beta$ to 0.1.
为了稳定 PPO 训练,我们对 actor 模型使用较低的学习率 $5e^{-7}$,而对 critic 模型使用较高的学习率 $9e^{-6}$。PPO epoch 设置为 1,rollout batch size 为 1024,clip range 为 0.2,mini-batch size 为 128。对于 DPO,我们将学习率设置为 $5e^{-7}$,batch size 设置为 128,$\beta$ 设置为 0.1。
Table 7: AlpacaEval results using GPT-4. We evaluated the win rates of PPO and DPO against the SFT model using the 160 prompts from the MT Bench and Vicuna Bench [31].
| 算法 | 胜率 (%) | 标准误差 | 平均长度 |
|---|---|---|---|
| PPO vs SFT | 63.52 | 3.83 | 2165 |
| DPO vs SFT | 60.06 | 3.83 | 1934 |
表 7: 使用 GPT-4 的 AlpacaEval 结果。我们使用来自 MT Bench 和 Vicuna Bench 的 160 个提示 [31] 评估了 PPO 和 DPO 相对于 SFT 模型的胜率。
Thanks to the implementation tricks and previous hyper-parameters for PPO, Figure 5 shows the PPO training curves, where the reward and return value rise steadily, and the Kullback–Leibler (KL) divergence and loss values remain stable. Table 7 presents the evaluation results on AlpacaEval [16]. The winning rates indicate that the PPO model and DPO model outperform the SFT model, and the PPO model outperforms the DPO model. This may be because DPO is more sensitive to out-of-distribution samples.
图 5: PPO 训练曲线显示奖励和返回值稳步上升,而 Kullback–Leibler (KL) 散度和损失值保持稳定。表 7: AlpacaEval [16] 的评估结果显示,PPO 模型和 DPO 模型优于 SFT 模型,且 PPO 模型优于 DPO 模型。这可能是因为 DPO 对分布外样本更为敏感。
We provided the pre-trained checkpoints in https://hugging face.co/OpenRLHF.
我们在 https://huggingface.co/OpenRLHF 提供了预训练的检查点。
5 Conclusion
5 结论
We introduce OpenRLHF, an open-source framework enabling full-scale RLHF training of models with over 70B parameters, by distributing models across GPUs via Ray and optimizing efficiency leveraging vLLM. OpenRLHF also implements multiple alignment algorithms. Seamless integration with Hugging Face provides out-of-the-box usability.
我们介绍 OpenRLHF,一个开源框架,通过 Ray 将模型分布在 GPU 上并利用 vLLM 优化效率,实现了超过 700 亿参数模型的全规模 RLHF 训练。OpenRLHF 还实现了多种对齐算法。与 Hugging Face 的无缝集成提供了开箱即用的可用性。
References
参考文献
A Appendix: Supported Algorithms
A 附录:支持的算法
OpenRLHF currently supports the following alignment algorithms, with more in continuous development:
OpenRLHF 目前支持以下对齐算法,更多算法正在持续开发中:
A.1 Supervised FineTuning
A.1 监督微调
Supervised Finetuning (SFT) is a method for guiding pre-trained models to conform to human instructions, primarily achieved through a specific series of data forms using supervised learning. This process allows the pre-trained language model, after fine-tuning, to accept specific input formats and produce the required outputs. Typically, Supervised Finetuning serves as the preceding step for alignment. To better support the RLHF pipeline, the OpenRLHF framework can support Supervised Finetuning for various pre-trained models, making it relatively straightforward to expand new models within OpenRLHF.
监督微调 (Supervised Finetuning, SFT) 是一种引导预训练模型遵循人类指令的方法,主要通过使用监督学习的特定数据形式来实现。这一过程使得预训练语言模型在微调后能够接受特定的输入格式并生成所需的输出。通常情况下,监督微调是对齐 (alignment) 的前置步骤。为了更好地支持 RLHF 流程,OpenRLHF 框架可以支持对各种预训练模型进行监督微调,这使得在 OpenRLHF 中扩展新模型变得相对简单。
A.2 Reward Model Training
A.2 奖励模型训练
Typically, reinforcement learning algorithms require a definitive reward signal to guide optimization. However, in many natural language domains, such a clear reward signal is often absent. [27] has collected human preference data and trained a reward model through comparative methods to obtain the necessary reward signals for the reinforcement learning process. Similar to the training stage of Supervised FineTuning (SFT), to better support the RLHF pipeline, the OpenRLHF framework supports the corresponding reward model training approach.
通常,强化学习算法需要明确的奖励信号来指导优化。然而,在许多自然语言领域中,这样明确的奖励信号往往是不存在的。[27] 收集了人类偏好数据,并通过对比方法训练了一个奖励模型,以获取强化学习过程中所需的奖励信号。与监督微调 (SFT) 的训练阶段类似,为了更好地支持 RLHF 流程,OpenRLHF 框架支持相应的奖励模型训练方法。
A.3 Proximal Policy Optimization
A.3 近端策略优化 (Proximal Policy Optimization)
Proximal Policy Optimization (PPO) is a reinforcement learning algorithm widely used in fields such as gaming and robotic control[23, 2]. In the domain of large language model fine-tuning, [19] has improved the stability of model fine-tuning by incorporating an approximate KL divergence with the base model as part of the reward and leveraging PPO’s clipped surrogate objective function to optimize model outputs while constraining the magnitude of output variations. This approach avoids over-optimizing language models for reward scores, effectively enhancing the stability of the model fine-tuning process.
近端策略优化 (Proximal Policy Optimization, PPO) 是一种广泛应用于游戏和机器人控制等领域的强化学习算法[23, 2]。在大语言模型微调领域,[19] 通过将近似 KL 散度与基础模型结合作为奖励的一部分,并利用 PPO 的裁剪替代目标函数来优化模型输出,同时限制输出变化的幅度,从而提高了模型微调的稳定性。这种方法避免了语言模型对奖励分数的过度优化,有效增强了模型微调过程的稳定性。
A.4 Direct Preference Optimization
A.4 直接偏好优化
To address issues such as over optimization during the reward model training process and to prevent the misjudgment of newly generated responses by the reward model, Direct Preference Optimization (DPO) has redesigned the alignment formula into a simple loss function [20], which allows direct optimization of model outputs on preference datasets. However, DPO suffers from over fitting on preference datasets. Identity Preference Optimization (IPO) introduces a regular iz ation term based on the DPO loss to reduce the risk of over fitting [1]. [9] further discusses the differences between IPO and DPO and introduces conservative DPO (cDPO), achieving an effect similar to introducing a regular iz ation term in IPO by smoothing the sample labels. OpenRLHF has implemented the above method to ensure the stability of the training process.
为了解决奖励模型训练过程中的过度优化问题,并防止奖励模型对新生成响应的误判,直接偏好优化 (Direct Preference Optimization, DPO) 将对齐公式重新设计为一个简单的损失函数 [20],这使得模型可以直接在偏好数据集上进行优化。然而,DPO 存在对偏好数据集过拟合的问题。身份偏好优化 (Identity Preference Optimization, IPO) 在 DPO 损失的基础上引入了一个正则化项,以降低过拟合的风险 [1]。[9] 进一步讨论了 IPO 和 DPO 之间的差异,并引入了保守 DPO (cDPO),通过平滑样本标签实现了类似于 IPO 中引入正则化项的效果。OpenRLHF 已经实现了上述方法,以确保训练过程的稳定性。
A.5 Kahneman-Tversky Optimization
A.5 Kahneman-Tversky 优化
Kahneman-Tversky Optimization (KTO) is a specific implementation of Human-Aware Loss Functions (HALOs). Unlike methods such as PPO and DPO, KTO individually labels each response as good or bad, defining the loss function based on this, thus requiring only a binary signal indicating whether the output for a given input is desirable. This approach avoids the challenges of collecting pairwise preference data. The implementation in OpenRLHF is consistent with the official open-source implementation of KTO [10].
Kahneman-Tversky 优化 (KTO) 是人类感知损失函数 (HALOs) 的一种具体实现。与 PPO 和 DPO 等方法不同,KTO 将每个响应单独标记为好或坏,并基于此定义损失函数,因此只需要一个二元信号来指示给定输入的输出是否理想。这种方法避免了收集成对偏好数据的挑战。OpenRLHF 中的实现与 KTO 的官方开源实现 [10] 一致。
A.6 Iterative Direct Preference Optimization
A.6 迭代式直接偏好优化
Iterative Direct Preference Optimization (Iterative DPO) [6] enhances vanilla DPO by continuously using an online approach to refine language models based on human feedback. The process involves three steps: (1) initially fine-tuning the model on instruction-following data, (2) collecting new preference data by sampling prompts and generating responses, and (3) iterative ly updating the model with this new data. This method allows the model to adapt, improving its ability to generate high-quality responses and handle diverse inputs effectively.
迭代直接偏好优化 (Iterative DPO) [6] 通过不断使用在线方法基于人类反馈来优化语言模型,从而增强原始的 DPO。该过程包括三个步骤:(1) 首先在指令跟随数据上对模型进行微调,(2) 通过采样提示并生成响应来收集新的偏好数据,(3) 使用这些新数据迭代地更新模型。这种方法使模型能够适应,提高其生成高质量响应和有效处理多样化输入的能力。
A.7 Rejection Sampling Finetuning
A.7 拒绝采样微调
The approach for implementing Rejection Sampling (RS) Finetuning in OpenRLHF is similar to that in [28] and RAFT [5], where sampling from the model’s output and selecting the best candidates based on existing rewards is done. For each response, the sample with the highest reward score is considered the new gold standard. Similar to [24], after selecting the best response, OpenRLHF treats it as a positive sample and fine-tunes the current model, enabling the model’s output to achieve greater reward values.
在 OpenRLHF 中实现拒绝采样(Rejection Sampling,RS)微调的方法与 [28] 和 RAFT [5] 中的方法类似,即从模型输出中采样并根据现有奖励选择最佳候选。对于每个响应,奖励分数最高的样本被视为新的黄金标准。与 [24] 类似,在选择最佳响应后,OpenRLHF 将其视为正样本并对当前模型进行微调,使模型的输出能够获得更大的奖励值。
A.8 Conditional Supervised Finetuning
A.8 条件监督微调
By introducing the method of model fine-tuning using conditionals, we collectively refer to it as Conditional Supervised Finetuning[12, 7]. Taking SteerLM as an example[7], by using a dataset with multidimensional scoring, we refine the training objectives, and after fine-tuning, by controlling input conditions, the model outputs customized effects. OpenRLHF naturally supports the training needs of Conditional Supervised Finetuning by providing the corresponding Batch infer and naive Supervised Finetuning.
通过引入使用条件进行模型微调的方法,我们将其统称为条件监督微调 (Conditional Supervised Finetuning) [12, 7]。以 SteerLM 为例 [7],通过使用具有多维评分的数据集,我们细化了训练目标,并在微调后通过控制输入条件,模型输出定制化效果。OpenRLHF 通过提供相应的批量推理 (Batch infer) 和简单监督微调 (naive Supervised Finetuning),自然支持条件监督微调的训练需求。