Agentic Reasoning: Reasoning LLMs with Tools for the Deep Research
智能推理:利用工具进行深度研究的大语言模型推理
Junde Wu, Jiayuan Zhu, Yuyuan Liu University of Oxford
Junde Wu, Jiayuan Zhu, Yuyuan Liu 牛津大学
Abstract
摘要
In this technical report, we introduce Agentic Reasoning, a framework' that enhances large language model (LLM) reasoning by integrating external tool-using agents. Unlike conventional LLM-based reasoning approaches, which rely solely on internal inference, Agentic Reasoning dynamically engages web search, code execution, and structured reasoning-context memory to solve complex problems requiring deep research and multistep logical deduction. Our framework introduces the Mind Map agent, which constructs a structured knowledge graph to track logical relationships, improving deductive reasoning. Additionally, the integration of web-search and coding agents enables real-time retrieval and computational analysis, enhancing reasoning accuracy and decision-making. Evaluations on PhD-level scientific reasoning (GPQA) and domain-specific deep research tasks demonstrate that our approach significantly outperforms existing models, including leading retrieval-augmented generation (RAG) systems and closed-source LLMs. Moreover, our results indicate that agentic reasoning improves expert-level knowledge synthesis, test-time s cal ability, and structured problem-solving. The code is at: https://github.com/ the world of agents/Agentic-Reasoning.
在本技术报告中,我们介绍了Agentic Reasoning,这是一个通过集成外部工具使用AI智能体来增强大语言模型(LLM)推理能力的框架。与传统的仅依赖内部推理的LLM推理方法不同,Agentic Reasoning动态地结合了网络搜索、代码执行和结构化推理上下文记忆,以解决需要深度研究和多步逻辑推理的复杂问题。我们的框架引入了Mind Map智能体,它构建了一个结构化知识图谱来跟踪逻辑关系,从而改进演绎推理。此外,通过集成网络搜索和编码智能体,能够实时检索和进行计算分析,提高推理准确性和决策能力。在博士级科学推理(GPQA)和特定领域深度研究任务上的评估表明,我们的方法显著优于现有模型,包括领先的检索增强生成(RAG)系统和闭源LLM。此外,我们的结果表明,智能体推理提升了专家级知识合成、测试时扩展能力和结构化问题解决能力。代码位于:https://github.com/the world of agents/Agentic-Reasoning。
1 Introduction
1 引言
Recently, large reasoning models, such as OpenAI's o1 (Jaech et al., 2024), Qwen-QwQ (Team), and DeepSeek-R1 (Team, 2024), have demonstrated impressive stepwise reasoning capabilities over long sequences through large-scale rein for cement learning. These advancements provide promising solutions to complex reasoning tasks (Wei et al., 2022; Lewkowycz et al., 2022; OpenAI) and have inspired foundational efforts to replicate
近期,OpenAI的o1 (Jaech et al., 2024)、Qwen-QwQ (Team)和DeepSeek-R1 (Team, 2024)等大规模推理模型通过大规模强化学习展示了在长序列上逐步推理的显著能力。这些进展为复杂推理任务提供了有前景的解决方案 (Wei et al., 2022; Lewkowycz et al., 2022; OpenAI),并激发了复制这些成果的基础性努力。
01-like reasoning patterns across a broader range of models (Qin et al., 2024; Huang et al., 2024; Zhang et al., 2024).
在更大范围的模型中观察到的类似01的推理模式 (Qin et al., 2024; Huang et al., 2024; Zhang et al., 2024)。
DeepSeek-R1, for example, relies exclusively on rule-based outcome rewards during training, such as evaluating whether a mathematical solution is correct or a piece of code executes successfully. While this approach has yielded remarkable reasoning capabilities, equaling o1's performance in domains like math and code, it comes with notable trade-offs. As even the authors acknowledge, this type of training diminishes the model's ability to articulate its reasoning process. DeepSeek-R1's responses are often logical and accurate but lack detailed explanations of transitions between ideas or the finer connections between arguments.
例如,DeepSeek-R1 在训练过程中完全依赖基于规则的结果奖励,例如评估数学解决方案是否正确或一段代码是否成功执行。虽然这种方法产生了显著的推理能力,在数学和代码等领域与 o1 的表现相当,但它也带来了显著的权衡。正如作者们所承认的那样,这种训练方式削弱了模型表达其推理过程的能力。DeepSeek-R1 的回答通常逻辑严密且准确,但缺乏对观点之间转换或论点之间细微联系的详细解释。
Although current reasoning methods excel in structured domains like math and code——-where outcomes are easily verifiable——-applying these techniques to less structured or subjective tasks remains a significant challenge. Adapting these strategies to areas where answers are not inherently definitive is a key research gap. How can models be trained to handle tasks that require judgment, interpretation, or nuanced understanding rather than binary correctness?
尽管当前的推理方法在数学和代码等结构化领域表现出色——这些领域的结果易于验证——但将这些技术应用于非结构化或主观任务仍然是一个重大挑战。将这些策略应用于答案本身并不明确的领域,是一个关键的研究空白。如何训练模型处理需要判断、解释或细微理解的任务,而不是简单的二元正确性?
Furthermore, not all problems benefit from formal reasoning approaches. Many fields, such as social sciences, ethics, or experiential disciplines, rely on abstract concepts, conventional wisdom, factual verification, understanding complex logical relationships, or moral reasoning. When models attempt to impose math- or coding-style reasoning onto such areas, they often produce flawed or overly rigid results. Developing approaches that account for these unique requirements is essential for advancing the applicability of reasoning model beyond their current domains.
此外,并非所有问题都受益于形式推理方法。许多领域,如社会科学、伦理学或经验学科,依赖于抽象概念、传统智慧、事实验证、理解复杂逻辑关系或道德推理。当模型试图将数学或编程风格的推理强加于这些领域时,往往会产生有缺陷或过于僵化的结果。开发考虑这些独特需求的方法对于提升推理模型在当前领域之外的适用性至关重要。
Deep, thoughtful answers to open-ended questions often require extensive research, repeated verification, information retrieval, computational analysis, and the organization of complex logical relationships—steps fundamental to human reasoning. In this process, humans rely heavily on external tools, such as internet searches for gathering information, computational tools for quantitative analysis, or whiteboards and Mind Maps for organizing thoughts. This raises an intriguing question: can large language models similarly leverage external tools to enhance their reasoning and tackle intensive knowledge work across diverse domains?
对开放性问题深入且深思熟虑的回答通常需要广泛的研究、反复的验证、信息检索、计算分析以及复杂逻辑关系的组织——这些步骤是人类推理的基础。在这一过程中,人类高度依赖外部工具,例如通过互联网搜索收集信息、使用计算工具进行定量分析,或者使用白板和思维导图来组织思路。这引发了一个有趣的问题:大语言模型是否也能类似地利用外部工具来增强其推理能力,并在不同领域应对密集的知识工作?
Previous efforts have attempted to integrate search or retrieval-augmented generation (RAG) into the reasoning process (Shao et al., 2024; Khaliq et al., 2024; Islam et al., 2024; Li et al., 2025), with notable examples including Gemini's Deep Research. However, these models are closed, their exact methodologies remain undisclosed. In contrast, open-source models typically focus exclusively on retrieval or web-searching during reasoning, leaving a significant performance gap compared to their closed-source counterparts.
先前的研究尝试将搜索或检索增强生成 (RAG) 整合到推理过程中 (Shao et al., 2024; Khaliq et al., 2024; Islam et al., 2024; Li et al., 2025),其中 Gemini 的深度研究是显著的例子。然而,这些模型是封闭的,其具体方法仍未公开。相比之下,开源模型通常在推理过程中专注于检索或网络搜索,导致其性能与闭源模型存在显著差距。
We introduce Agentic Reasoning, a framework that enhances the reasoning process by integrating external LLM-based agents as tools. This approach enables LLMs to perform multi-step reasoning and tackle complex problems more effectively by delegating specific tasks to these auxiliary agents. Through extensive experimentation with integrating various agents into the reasoning process, we identified three essential agents that prove highly effective for general reasoning across diverse problems. The web-search agent, which retrieves relevant information from the internet to supplement the model's knowledge. The code agent, capable of performing computational analyses and coding tasks to support quantitative reasoning. Finally, the memory agent, which we call Mind Map, constructs knowledge graphs based on the reasoning context, enabling the organization of complex logical relationships in a manner similar to human mind mapping. Together, these agents enhance the model's ability to tackle complex problems with greater efficiency and precision.
我们介绍了智能体推理 (Agentic Reasoning),这是一个通过集成外部基于大语言模型的智能体作为工具来增强推理过程的框架。该方法通过将特定任务委托给这些辅助智能体,使得大语言模型能够更有效地执行多步推理并解决复杂问题。通过将各种智能体集成到推理过程中的广泛实验,我们识别出了三个对解决多样化问题普遍有效的关键智能体。网络搜索智能体,它从互联网检索相关信息以补充模型的知识。代码智能体,能够执行计算分析和编码任务以支持定量推理。最后是记忆智能体,我们称之为思维导图 (Mind Map),它根据推理上下文构建知识图谱,能够以类似于人类思维导图的方式组织复杂的逻辑关系。这些智能体共同增强了模型以更高效率和精确度解决复杂问题的能力。
When integrated into current reasoning LLMs, Agentic Reasoning transforms their problemsolving capabilities by enabling them to plan and execute multi-step strategies autonomously. These models can identify and retrieve the necessary data, adapt dynamically to real-time information, and perform quantitative analyses to generate precise outcomes. This framework also allows LLMs to deliver comprehensive reports comparable to those of a research analyst or provide solutions on par with PhD-level expertise.
当Agentic Reasoning集成到当前的推理大语言模型中时,它通过使模型能够自主规划和执行多步骤策略,显著提升了其解决问题的能力。这些模型能够识别和检索必要的数据,动态适应实时信息,并执行定量分析以生成精确的结果。这一框架还使大语言模型能够提供与研究分析师相当的综合报告,或提供与博士水平专业知识相当的解决方案。
We evaluated our model on general knowledgeintensive benchmarks requiring complex reasoning capabilities, categorized into two key areas: (1) solving expert-level questions and (2) conducting deep research on real-world expert-level tasks.
我们在需要复杂推理能力的通用知识密集型基准上评估了我们的模型,分为两个关键领域:(1) 解决专家级问题 (2) 对现实世界的专家级任务进行深入研究。
For expert-level questions, we tested the model on the GPQA dataset, a PhD-level science multiplechoice QA benchmark with questions authored by domain experts in physics, chemistry, and biology. Our Agentic Reasoning framework achieved impressive accuracy rates: $58%$ in chemistry, $88%$ in physics, and $79%$ in biology, closely rivals the best and newest closed reasoning model, OpenAI o1. For real-world expert-level tasks, Agentic Reasoning was evaluated by domain experts, who noted that it effectively automated several hours of challenging, manual investigation. This highlights its potential to streamline labor-intensive processes and enhance productivity in knowledge-intensive domains.
对于专家级别的问题,我们在 GPQA 数据集上测试了模型,这是一个由物理学、化学和生物学领域的专家编写的博士级别科学多选题基准测试。我们的 AI 智能体推理框架取得了令人印象深刻的准确率:化学 $58%$,物理 $88%$,生物 $79%$,与最优秀且最新的封闭推理模型 OpenAI o1 不相上下。对于现实世界的专家级别任务,AI 智能体推理由领域专家进行了评估,他们指出它有效地自动化了几个小时具有挑战性的手动调查。这突显了其在简化劳动密集型流程和提升知识密集型领域生产力方面的潜力。
Additionally, we tested the model's s cal ability in test-time reasoning using the agentic framework as a verifier. The results showed significant improvements in test-time computational efficiency, demonstrating the framework's ability to optimize reasoning processes. This finding suggests that the agentic framework has strong potential to serve as a reward model for reinforcement learning, further advancing reasoning model training.
此外,我们使用智能体框架作为验证器测试了模型在测试时推理的可扩展性。结果显示,测试时计算效率显著提高,证明了该框架优化推理过程的能力。这一发现表明,智能体框架有潜力作为强化学习的奖励模型,进一步推动推理模型的训练。
These results position Agentic Reasoning as a powerful and versatile framework, capable of tackling complex, domain-specific challenges with depth and precision. Its ability to perform in-depth research, navigate intricate logical structures, and synthesize information effectively highlights its potential for solving knowledge-intensive problems and driving advancements in deep analytical exploration.
这些结果表明,AI智能体推理 (Agentic Reasoning) 是一个强大且多功能的框架,能够以深度和精确性应对复杂的特定领域挑战。其在深入研究、驾驭复杂逻辑结构和有效整合信息方面的能力,凸显了其在解决知识密集型问题和推动深度分析探索方面的潜力。
2 Method
2 方法
2.1 Preliminary
2.1 预备知识
We consider an expert-level task that requires multistep complex reasoning. In the process of model reasoning, it can retrieve external tool usage, and structured memory of its previous reasoning. Our objective is to generate, for each query $q$ ,both a logical reasoning chain $r$ and a final answer $a$ To achieve this, the reasoning model dynamically interacts with external tools $e$ , which are generally web search and python coding, and retrieves structured knowledge from an organized memory $k$ throughout the reasoning process.
我们考虑一个需要多步复杂推理的专家级任务。在模型推理过程中,它可以检索外部工具的使用情况,以及其先前推理的结构化记忆。我们的目标是为每个查询 $q$ 生成一个逻辑推理链 $r$ 和最终答案 $a$。为了实现这一目标,推理模型在整个推理过程中动态地与外部工具 $e$(通常是网络搜索和 Python 编程)进行交互,并从组织化的记忆 $k$ 中检索结构化知识。

Figure 1: The overall workflow of Agentic Reasoning.
图 1: Agentic Reasoning 的整体工作流程。
Formally, we identify four primary inputs in the problem-solving pipeline: task instruction $o$ ,defining the over arching task objective, query $q$ acomplex question requiring multi-step reasoning, external tool outputs $e$ , dynamically retrieved content from tools such as web search or coding, reasoning memory $k$ , containing structured knowledge graph.
在问题解决流程中,我们正式识别了四个主要输入:任务指令 $o$,定义了总体任务目标;查询 $q$,一个需要多步推理的复杂问题;外部工具输出 $e$,从诸如网络搜索或编程等工具中动态检索的内容;以及推理记忆 $k$,包含结构化的知识图谱。
The goal is to integrate $o,q,e,k$ to generate a coherent reasoning chain $r$ and a final answer $a$ This process can be expressed as the mapping:
目标是将 $o,q,e,k$ 整合以生成一个连贯的推理链 $r$ 和一个最终答案 $a$。这一过程可以表示为映射:
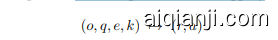
We model the generation of $r$ and $a$ using the following joint probability formulation:
我们使用以下联合概率公式来建模 $r$ 和 $a$ 的生成:

all previous tokens. The terms $e{\leq}t$ and $k_{\leq t}$ indicate all tool-generated outputs and knowledge-graph information retrieved up to step $t$ . Similarly, $a_{t}$ is the token at position $t$ in the final answer, and $a{<}t$ represents all previously generated answer tokens.
所有先前的Token。术语 $e{\leq}t$ 和 $k_{\leq t}$ 表示在步骤 $t$ 之前生成的所有工具输出和检索到的知识图谱信息。同样,$a_{t}$ 是最终答案中位置 $t$ 的Token,$a{<}t$ 表示所有先前生成的答案Token。
2.2 Agentic Reasoning Pipeline
2.2 Agentic Reasoning Pipeline
Our core idea is to enhance the model reasoning by deploying external LLM-based agents during reasoning. The framework enables the reasoning LLM model interacts with external information in an agentic way. During its reasoning process, it could call the external tools to help solve the problem and also with a structured memory, called Mind Map, to store its reasoning context. At its core, an agentic mechanism empowers the model to determine, in real-time, when additional information is required. whenever the model identify the external information is needed during its reasoning, it will pro actively embeds specialized tokens into its reasoning tokens. These tokens can be generally categorized to web-search token, coding token, and mind-map calling token. Together with token, the reasoning model would also generate a precise query as a message to interact with these external agents, based on the reasoning context developed so far.
我们的核心思想是通过在推理过程中部署基于外部大语言模型的 AI 智能体来增强模型推理能力。该框架使推理大语言模型能够以智能体的方式与外部信息进行交互。在其推理过程中,它可以调用外部工具来帮助解决问题,并使用一种称为思维导图的结构化内存来存储其推理上下文。其核心在于,智能体机制使模型能够实时判断何时需要额外信息。每当模型在推理过程中识别出需要外部信息时,它会主动将专门的 Token 嵌入其推理 Token 中。这些 Token 通常可以分为网络搜索 Token、编码 Token 和思维导图调用 Token。与 Token 一起,推理模型还会根据当前的推理上下文生成一个精确的查询,作为与这些外部智能体交互的消息。
where $T_{r}$ and $T_{a}$ represent the lengths (in tokens) of the reasoning chain $r$ and the final answer $a$ , respectively. Here, $r_{t}$ denotes the token at position $t$ in the reasoning sequence, with $r_{<t}$ representing
其中 $T_{r}$ 和 $T_{a}$ 分别表示推理链 $r$ 和最终答案 $a$ 的长度(以token为单位)。这里,$r_{t}$ 表示推理序列中位置 $t$ 的token,$r_{<t}$ 表示
Upon detecting such a token, the reasoning process temporarily halts to extract the query and its reasoning context. Those are then dispatched to external agents, such as search engines or Mind
在检测到此类Token时,推理过程会暂时停止以提取查询及其推理上下文。随后,这些内容会被发送到外部智能体,例如搜索引擎或Mind。
Map, to generate pertinent content. The generation would consider both the message received and the reasoning context to make sure returning the most relevant results. These results are then reintegrated into the reasoning chain, allowing the model to continue its inference with an updated and enriched knowledge.
地图,生成相关内容。生成过程将同时考虑接收到的消息和推理上下文,以确保返回最相关的结果。这些结果随后被重新整合到推理链中,使模型能够在更新和丰富的知识基础上继续其推理。
This iterative retrieval-and-reasoning cycle continues as needed, enabling the model to dynamically refine its conclusions until it reaches a fully reasoned final answer.
这种迭代的检索-推理循环根据需要继续进行,使模型能够动态优化其结论,直到得出一个完全推理的最终答案。
2.3 Mind Map Agent
2.3 思维导图智能体 (Mind Map Agent)
We construct a Mind Map to store and structure the real-time reasoning context of the reasoning model. This Mind Map is built by transforming raw reasoning chains into a structured knowledge graph. Specifically, we use a graph-construction LLM to extract entities from the reasoning chain and identify semantic relationships between related entities, following a process similar to that used in GraphRAG (Edge et al., 2024).
我们构建了一个思维导图来存储并结构化推理模型的实时推理上下文。该思维导图通过将原始推理链转换为结构化知识图谱来构建。具体而言,我们使用图构建的大语言模型从推理链中提取实体,并识别相关实体之间的语义关系,这一过程与 GraphRAG (Edge et al., 2024) 中使用的方法类似。
The Mind Map serves two primary functions. First, it clusters reasoning context into distinct groups and summarizes each theme. This is achieved by applying community clustering (Edge et al., 2024) on the knowledge graph and using an LLM to generate concise summaries for each group. Second, the knowledge graph can be queried with specific questions, such as "Who was Jason's maternal great-grandfather? Using standard retrievalaugmented generation (RAG) on the knowledge graph (Edge et al., 2024), we retrieve and return relevant information.
思维导图主要有两个功能。首先,它将推理上下文聚类成不同的组,并总结每个主题。这是通过在知识图谱上应用社区聚类 (Edge et al., 2024) 并使用大语言模型为每个组生成简洁的摘要来实现的。其次,知识图谱可以通过特定问题来查询,例如“Jason 的外曾祖父是谁?通过在知识图谱上使用标准的检索增强生成 (RAG) (Edge et al., 2024),我们检索并返回相关信息。
These functions integrate the Mind Map into various aspects of the Agentic Reasoning process. It provides contextual reasoning support to external tools, enabling them to generate more contextaware responses (as discussed in later sections). Additionally, when the reasoning model is uncertain about its claims or loses track in an extended reasoning process, it can query the Mind Map for relevant information, treating it as an external tool, and continue reasoning based on the retrieved answer.
这些功能将思维导图整合到AI智能体推理过程的各个方面。它为外部工具提供了上下文推理支持,使其能够生成更具上下文感知的响应(如后续章节所讨论的)。此外,当推理模型对其主张不确定或在扩展推理过程中迷失方向时,它可以查询思维导图以获取相关信息,将其视为外部工具,并基于检索到的答案继续推理。
2.4 Web-search Agent
2.4 网络搜索智能体
A search agent is invoked to retrieve the most relevant documents from the web. Rather than incorporating the web pages in their raw form, they are temporarily held for further processing. This ensures that only the most pertinent information is extracted and integrated into the main reasoning chain, maintaining coherence and relevance.
调用搜索代理从网络检索最相关的文档。这些网页不会以原始形式直接整合,而是暂时保存以便进一步处理。这确保了仅提取最相关的信息并整合到主要推理链中,从而保持连贯性和相关性。
Once the relevant web pages are retrieved by the search agent, we use LLM to extract a concise, rephrased summary of the content most relevant to the ongoing reasoning context. This agent processes the web pages in the context of both the user query and the reasoning context, distilling key insights that are directly applicable to the problem at hand. The format and length of the summary adapt dynamically based on the reasoning task, for example, for factual queries like “What is the population of the US in 2024? the result would be a simple numerical answer. For exploratory reasoning like finding a new perspective on a topic, the search agent would provide a summerized, detailed, nuanced viewpoint. For hypothesis validation like assessing supporting evidence for an assumption, the result would include the degree of support or contradiction found in the retrieved web-pages. This processed snippet is then integrated into the main reasoning process at the appropriate juncture, ensuring that external insights enhance rather than disrupt logical flow.
一旦搜索代理检索到相关网页,我们使用大语言模型提取与当前推理上下文最相关内容的简洁、重新表述的摘要。该代理在用户查询和推理上下文的背景下处理网页,提炼出直接适用于当前问题的关键见解。摘要的格式和长度根据推理任务动态调整,例如,对于诸如“2024年美国人口是多少?”这样的查询,结果将是一个简单的数字答案。对于探索性推理,如寻找对某个主题的新观点,搜索代理将提供总结性、详细且细致的观点。对于假设验证,如评估假设的支持证据,结果将包括在检索到的网页中发现的支持或矛盾的程度。然后,这个处理过的摘要片段在适当的时机被整合到主要推理过程中,确保外部见解增强而不是破坏逻辑流程。
2.5 Coding Agent
2.5 编码智能体
Instead of prompting the reasoning model to generate code directly, we find it more efficient to delegate coding tasks to a specialized coding LLM. The reasoning model sends the relevant context and query message to the coding LLM, which then writes the required code, executes it via a compiler, and returns the results. This approach ensures that the reasoning model remains focused on its core reasoning process without being disrupted by coding tasks, allowing for longer and more coherent reasoning chains. Specifically, we format the coding request as follows: "Write code to perform given the context
我们不是直接提示推理模型生成代码,而是发现将编码任务委托给专门的编码大语言模型更为高效。推理模型将相关上下文和查询消息发送给编码大语言模型,后者编写所需的代码,通过编译器执行,并返回结果。这种方法确保推理模型专注于其核心推理过程,而不会因编码任务而中断,从而实现更长、更连贯的推理链。具体来说,我们将编码请求格式化为:"编写代码以执行<来自推理模型的代码消息>,给定上下文<来自思维导图的推理上下文>,以回答查询<用户查询>。" 编码大语言模型被指示始终以自然语言返回其输出,确保与推理模型的无缝集成。
2.6 Main Findings
2.6 主要发现
Less is More Unlike general agentic frameworks that provide models with a large selection of external tools, we find that just two—web search and coding——are sufficient for most tasks, even those requiring expert-level proficiency. Adding more tools can degrade performance by increasing the risk of inappropriate tool selection. Moreover, inaccuracies in external tool outputs can negatively impact the overall response quality. While additional tools are not significantly beneficial for languagebased reasoning, they can be crucial for processing non-text modalities such as financial data, medical images, and genetic data. Developing specialized tools for different data modalities could further enhance LLM reasoning capabilities, and we will explore related results in future updates.
少即是多
与提供大量外部工具的一般AI智能体框架不同,我们发现仅需两种工具——网页搜索和编程——就足以应对大多数任务,即使是那些需要专家级水平的任务。添加更多工具可能会因增加不当工具选择的风险而降低性能。此外,外部工具输出的不准确性可能会对整体响应质量产生负面影响。虽然额外的工具对基于语言的推理没有显著益处,但对于处理非文本模态(如金融数据、医学图像和基因数据)可能至关重要。为不同数据模态开发专门的工具可以进一步增强大语言模型的推理能力,我们将在未来的更新中探索相关结果。
Delegating Tasks to LLM-Based Agents Distributing computational workloads across multiple LLM-based agents improves efficiency. Instead of having the main reasoning model handle all tool-related tasks (e.g., writing code or constructing a knowledge graph), or calling non-LLM tools like pure search engine or code compiler, we delegate these tasks to specialized LLM-Based Agents, like a coding LLM generates code based on the query and context from the main reasoning model, or a knowledge-graph LLM constructs structured representations (e.g., a Mind Map) from the reasoning chain. This approach offers two key advantages:1. Minimizing Disruptions. The main reasoning model can maintain longer, more coherent reasoning without being distracted by auxiliary tasks or exceeding token limits. 2. Leveraging Specialization. Different LLMs excel at different tasks——for instance, DeepSeek-R1 specializes in reasoning, while Claude-Sonnet excels at coding. By assigning tasks to models best suited for them, we achieve higher overall performance.
将任务委派给基于大语言模型的智能体
Question
问题
A 68-year-old male with a 12-year history of moderate-to-severe COPD $\mathrm{\Delta}^{\prime}\mathrm{FEV}{1}=45%$ of predicted, $\mathsf{P a O}{2}=58,\mathsf{m m H g}.$ $\mathsf{P a C O}_{2}=48$ mmHg) and newly diagnosed heart failure (left ventricular ejection fraction, $\mathsf{L V E F=}$ $35%$ presents with worsening dyspnea and reduced exercise tolerance. how can lung function be improved without exacerbating heart symptoms?
一名 68 岁男性,患有中重度 COPD 12 年 ( $\mathrm{\Delta}^{\prime}\mathrm{FEV}{1}=45%$ 预计值, $\mathsf{P a O}{2}=58,\mathsf{m m H g}.$ $\mathsf{P a C O}_{2}=48$ mmHg) 和新诊断的心力衰竭 (左心室射血分数, $\mathsf{L V E F=}$ $35%$ ),表现为呼吸困难加重和运动耐量下降。如何在不加重心脏症状的情况下改善肺功能?
Reasoning...
推理...
[Code] Target an Alveolar PAO2PAO2 of $\sim!140$ $\mathsf{m m H g},$ . anticipating an A-a gradient that might still yield an arterial $\mathsf{P a O}{2},{\geq}65{\geq}65\mathsf{\ m m H g}$ using Alveolar Gas Equation: $P{A}O_{2}=F_{i}O_{2}\times(P_{a t m}-P_{H_{2}O})-\frac{P_{a}C O_{2}}{R}$
[代码] 目标肺泡 PAO2 为 $\sim!140$ $\mathsf{m m H g}$,预计 A-a 梯度仍可使动脉 $\mathsf{P a O}{2},{\geq}65{\geq}65\mathsf{\ m m H g}$,使用肺泡气体方程:$P{A}O_{2}=F_{i}O_{2}\times(P_{a t m}-P_{H_{2}O})-\frac{P_{a}C O_{2}}{R}$
Thus, $\mathbf{28%}$ $\mathsf{F i O}{2}$ might be a reasonable starting point. In practice, clinicians often start with $24-28%$ supplemental ${0_{2}}$ via a Venturi mask(or nasal cannula approximations) and then titrate to keep $\pmb{500_{2}}$ around $88-92%$ in COPD to avoid excessive respiratory drive suppression or severe hyper cap nia.
因此,$\mathbf{28%}$ 的 $\mathsf{F i O}{2}$ 可能是一个合理的起点。在实际操作中,临床医生通常从 $24-28%$ 的补充 ${0_{2}}$ 开始(通过 Venturi 面罩或鼻导管近似),然后逐步调整,以保持 COPD 患者的 $\pmb{500_{2}}$ 在 $88-92%$ 之间,以避免过度抑制呼吸驱动或严重的二氧化碳潴留。
:
[Web-search] Optimal PEEP levels in COPD with heart failure
[Web-search] COPD合并心力衰竭的最佳PEEP水平
Low-to-moderate PEEP( $(5-10\ c m\ H_{2}0)$ is recommended to improve oxygenation without significantly reducing venous return in HF.
建议使用低至中等水平的 PEEP (5-10 cm H₂O) 以改善氧合,同时不会显著降低 HF 患者的静脉回流。
::
规则:
- 输出中文翻译部分的时候,只保留翻译的标题,不要有任何其他的多余内容,不要重复,不要解释。
- 不要输出与英文内容无关的内容。
- 翻译时要保留原始段落格式,以及保留术语,例如 FLAC,JPEG 等。保留公司缩写,例如 Microsoft, Amazon, OpenAI 等。
- 人名不翻译
- 同时要保留引用的论文,例如 [20] 这样的引用。
- 对于 Figure 和 Table,翻译的同时保留原有格式,例如:“Figure 1: ”翻译为“图 1: ”,“Table 1: ”翻译为:“表 1: ”。
- 全角括号换成半角括号,并在左括号前面加半角空格,右括号后面加半角空格。
- 在翻译专业术语时,第一次出现时要在括号里面写上英文原文,例如:“生成式 AI (Generative AI)”,之后就可以只写中文了。
- 以下是常见的 AI 相关术语词汇对应表(English -> 中文):
- Transformer -> Transformer
- Token -> Token
- LLM/Large Language Model -> 大语言模型
- Zero-shot -> 零样本
- Few-shot -> 少样本
- AI Agent -> AI智能体
- AGI -> 通用人工智能
- Python -> Python语言
策略:
分三步进行翻译工作:
- 不翻译无法识别的特殊字符和公式,原样返回
- 将HTML表格格式转换成Markdown表格格式
- 根据英文内容翻译成符合中文表达习惯的内容,不要遗漏任何信息
最终只返回Markdown格式的翻译结果,不要回复无关内容。
Administer $\sim!28%$ $\mathsf{F i O}{2},$ consider mild PEEP/CPAP of $4-5c m\ H{2}O.$ ,increase alveolar ventilation modestly,and t it rate diuretics to manage fluid overload without excessive preload reduction.
给予约 28% 的 $\mathsf{F i O}_{2}$, 考虑使用 4-5 cm H2O 的轻度 PEEP/CPAP, 适度增加肺泡通气量, 并调整利尿剂剂量以管理液体过负荷, 同时避免过度降低前负荷。
Figure 2: Case study on a complex medical decisionmaking problem.
图 2: 复杂医疗决策问题的案例分析
Agentic Test-time Scaling? For a single question, we find reasoning chains that utilize more tool calls tend to yield better results. While across different questions, those requiring excessive tool usage often indicate inherent ambiguity or inaccuracy in the initial reasoning. This insight can be leveraged as a test-time reasoning verifier. By selecting the reasoning chain with the highest tool usage, we can implement best-of-N selection or beam search, which are techniques commonly used in mathematical and coding reasoning tasks as they can easily build a verifier, to open-domain, knowledgeintensive Q&A, improving accuracy and robustness.
智能体测试时扩展?对于单个问题,我们发现使用更多工具调用的推理链往往能产生更好的结果。而在不同问题之间,那些需要过多工具使用的问题通常表明初始推理中存在固有的模糊性或不准确性。这一洞察可以作为测试时推理验证器来利用。通过选择工具使用最多的推理链,我们可以实施最佳-N选择或束搜索,这些技术通常用于数学和编码推理任务,因为它们可以轻松构建验证器,将其应用于开放域、知识密集型的问答中,从而提高准确性和鲁棒性。
3 Experiments
3 实验
3.1 Solving Hard Problems
3.1 解决难题
We evaluate our Agentic Reasoning model on the GPQA dataset, a PhD-level multiple-choice science QA benchmark. The dataset consists of expertauthored questions spanning physics, chemistry, and biology. Our primary experiments focus on the high-quality Diamond Set, which contains 198 questions, while Table 2 presents results on the broader Extended Set of 546 questions, allowing for a direct comparison with human experts.
我们在 GPQA 数据集上评估了我们的 AI 智能体推理模型,该数据集是一个博士级的多选科学问答基准。数据集涵盖了由专家编写的物理、化学和生物学问题。我们的主要实验集中在高质量的 Diamond Set 上,该集包含 198 个问题,而表 2 展示了更广泛的 Extended Set 的 546 个问题的结果,以便与人类专家进行直接比较。
As shown in Table 1, our findings show that large reasoning models such as DeepSeek-R1-Lite and
如表 1 所示,我们的研究发现 DeepSeek-R1-Lite 等大型推理模型
Table 1: Performance comparison on GPQA dataset across Physics, Chemistry, and Biology.
表 1: GPQA 数据集上物理、化学和生物学的性能比较。
方法
物理
化学
生物
直接推理 Qwen2.5-32B Qwen2.5-Coder-32B
57.0 37.2
33.3 25.8
52.6 57.9 68.4
QwQ-32B Qwen2.5-72B Llama3.3-70B GPT-4ot 01-previewt
75.6 57.0 54.7 59.5
39.8 37.6 31.2 40.2 59.9
68.4 52.6 61.6 65.9
检索/搜索推理 RAG-Qwen2.5-32B RAG-QwQ-32B
89.4 57.0 76.7
37.6 38.7
52.6
RAgent-Qwen2.5-32B
58.1
33.3
73.7 63.2
RAgent-QwQ-32B 搜索-o1 代理推理 我们的方法
76.7 77.9 88.1
46.2 47.3 58.3
68.4 78.9 79.6
QwQ-32B-Preview significantly outperform traditional instruction-tuned LLMs. This demonstrates the effectiveness of chain-of-thought reasoning in solving complex, expert-level problems. Additionally, models like RAgent-QwQ-32B and SearchO1, which autonomously retrieve relevant information at reasoning, outperform non-reasoning mod- els that simply utilize search tools. This confirms that calling tools is uniquely beneficial for enhancing reasoning accuracy.
QwQ-32B-Preview 显著优于传统的指令微调大语言模型。这证明了链式思维推理在解决复杂专家级问题中的有效性。此外,像 RAgent-QwQ-32B 和 SearchO1 这样的模型,在推理过程中自主检索相关信息,表现优于仅使用搜索工具的非推理模型。这证实了调用工具对于提高推理准确性具有独特的优势。
Agentic Reasoning, which integrates external agents during reasoning, further improves performance over search-enhanced models. Our model achieves superior results on the GPQA dataset, demonstrating the power of tool-assisted reasoning in tackling expert-level challenges.
智能体推理在推理过程中整合外部智能体,进一步提升了搜索增强模型的性能。我们的模型在GPQA数据集上取得了优异的结果,展示了工具辅助推理在应对专家级挑战中的强大能力。
To illustrate the effectiveness of Agentic Reasoning, we also present a case study on a complex medical decision-making problem, as shown in Figure 4 The model autonomously executes code to compute the optimal $F i O_{2}$ (Fraction of Inspired Oxygen) for a patient, performs a web search to retrieve the most accurate PEEP (Positive End-Expiratory Pressure) value, and synthesizes both results to determine the best treatment plan. This example highlights how integrating coding and web search enhances the model's ability to solve real-world medical challenges.
为了展示 AI 智能体推理 (Agentic Reasoning) 的有效性,我们还提供了一个关于复杂医疗决策问题的案例研究,如图 4 所示。该模型自主执行代码以计算患者的最佳吸入氧浓度 (Fraction of Inspired Oxygen, $F i O_{2}$),通过网络搜索获取最准确的呼气末正压 (Positive End-Expiratory Pressure, PEEP) 值,并综合这两个结果以确定最佳治疗方案。该示例展示了整合编码和网络搜索如何增强模型解决现实世界医疗挑战的能力。
We further compare our model with human experts in physics, chemistry, and biology using the
我们进一步将我们的模型与物理学、化学和生物学领域的专家进行了比较。
GPQA Extended Set. As shown in Table 2, our model surpasses human performance across all disciplines, achieving superior accuracy in all three subsets, and also outperforming human experts. These results highlight the model's ability to handle specialized scientific reasoning tasks at an expert level.
GPQA扩展集。如表 2 所示,我们的模型在所有学科中均超越了人类表现,在三个子集中均实现了更高的准确率,并且也优于人类专家。这些结果突显了模型在处理专家级科学推理任务方面的能力。
Table 2: Performance comparison with human experts on the GPQA extended set.
表 2: 在GPQA扩展集上与人专家的性能比较
方法
物理
化学
生物
人专家
物理学家
57.9
31.6
42.0
化学家
34.5
72.6
45.6
生物学家
30.4
28.8
68.9
推理模型
QwQ-32B
61.7
36.9
61.0
RAG-QwQ-32B
64.3
38.3
66.7
Search-o1
68.7
40.7
69.5
Agentic Reasoning
75.2
53.1
72.8
3.2 Deep Research
3.2 深度研究
We conduct an evaluation of Agentic Reasoning for deep research in open-ended Q&A tasks. A group of PhD-level experts in finance, medicine, and law were asked to formulate 15 to 30 professional research questions closely related to their respective fields. These questions were designed to require at least 20 minutes of in-depth research to answer comprehensively.
我们对开放式问答任务中的Agentic Reasoning进行了评估,以进行深入研究。一组金融、医学和法律领域的博士级专家被要求提出15到30个与其各自领域密切相关的专业研究问题。这些问题被设计为至少需要20分钟的深入研究才能全面回答。
We assess the accuracy and reliability of reports generated by our Agentic Reasoning model, measuring the pass rate—the percentage of responses deemed satisfactory by domain experts. We compare this pass rate against Gemini Deep Research Service (experiments with OpenAI's Deep Research are ongoing). As shown in Figure 3, our findings show that Agentic Reasoning outperforms Gemini Deep Research across all three domains, demonstrating the effectiveness of structured reasoning and tool-augmented frameworks in conducting deep research.
我们评估了由我们的AI智能体推理模型生成的报告的准确性和可靠性,测量了通过率——即领域专家认为满意的回答百分比。我们将这一通过率与Gemini深度研究服务(正在进行OpenAI深度研究的实验)进行了比较。如图3所示,我们的研究结果表明,AI智能体推理在所有三个领域均优于Gemini深度研究,展示了结构化推理和工具增强框架在进行深度研究中的有效性。
3.3 Analysis
3.3 分析
3.3.1 Test-time Scaling
3.3.1 测试时缩放
In our deep research study, we find that increased tool usage improves performance on the same question. As shown in Figure 3, a higher number of tool calls by the reasoning model correlates with an increased pass rate in deep research tasks. However, when comparing different questions, those requiring excessive tool usage tend to indicate an inherently more challenging or ambiguous question, leading to lower accuracy. The questions with a higher number of tool calls within the same field ultimately achieve a lower pass rate.
在我们的深入研究中发现,增加工具的使用可以提高同一问题的表现。如图 3 所示,推理模型调用的工具数量越多,深入研究任务中的通过率就越高。然而,当比较不同问题时,那些需要过多工具使用的问题往往表明问题本身更具挑战性或模糊性,导致准确率降低。在同一领域中,工具调用数量较多的问题最终通过率较低。
![]()
Figure 3: More calling for agentic tools, the better the model does. Red line denotes Gemini Deep Research
图 3: 越多的AI智能体工具调用,模型表现越好。红线表示Gemini深度研究
Such observations provide a practical approach for test-time scaling. During inference-time search (running the same question multiple times), we can use the frequency of tool calls as a heuristic to select better responses. A simple implementation, such as best-of-N selection, can effectively filter out weaker outputs. This method even outperforms LLM-as-a-judge evaluation, which is more computationally expensive, time-consuming, and prone to instability.
这些观察为测试时的扩展提供了实用方法。在推理时搜索(多次运行相同问题)过程中,我们可以使用工具调用的频率作为启发式方法来选择更好的响应。一个简单的实现,例如最佳N选择,可以有效过滤掉较弱的输出。这种方法甚至优于基于大语言模型的评估,后者计算成本更高、耗时更长且容易不稳定。
These findings suggest a promising direction for reinforcement learning for reasoning model on knowledge-intensive fields. By leveraging agentic tool usage as an implicit reward signal, we can further optimize reasoning models for more effective tool utilization, ultimately enhancing their problemsolving capabilities.
这些发现为知识密集型领域的推理模型强化学习提供了一个有前景的方向。通过利用工具使用作为隐式奖励信号,我们可以进一步优化推理模型,以实现更有效的工具利用,最终增强其问题解决能力。
![]()
3.3.2 The Role of Mind Map
图 1: 3.3.2 思维导图的作用
Figure 4: A tricky question that misleads most LLMs is correctly answered by us.
图 4: 一个误导大多数大语言模型的棘手问题被我们正确回答。
We find that Mind Maps are particularly effective in clarifying complex logical relationships, enabling the model to solve problems that often mislead traditional LLMs. We highlight two key cases where Mind Mapping maximizes its capabilities:
我们发现思维导图在理清复杂逻辑关系方面尤为有效,能够帮助模型解决传统大语言模型容易被误导的问题。我们重点展示了思维导图在以下两个关键场景中发挥最大效能的情况:
First, Mind Maps help correctly answer tricky logic-based questions that frequently fool LLMs. A well-known example is a modified riddle: "The surgeon, who is the boy's father, says 'I can't operate on this child, he's my son!' Who is the surgeon to the boy?" DeepSeek-R1 took 17 seconds to process this question but still produced the wrong answer, a failure also observed in models from the GPT and Gemini series models. These models often fall for a political-correct corpus contaminated response, failing to recognize the obvious logical structure. However, in our Agentic Reasoning framework, the use of a Mind Map allows the model to explicitly analyze the logical relationships between the entities [surgeon], [boy], and [father], leading to the correct answer.
首先,思维导图有助于正确回答那些经常欺骗大语言模型的基于逻辑的棘手问题。一个著名的例子是修改后的谜语:“外科医生,也就是男孩的父亲,说:‘我不能给这个孩子做手术,他是我的儿子!’外科医生与男孩是什么关系?”DeepSeek-R1 花了 17 秒处理这个问题,但仍然给出了错误答案,GPT 和 Gemini 系列模型也观察到了同样的失败。这些模型经常陷入政治正确语料库污染的响应中,无法识别明显的逻辑结构。然而,在我们的 AI智能体推理框架中,使用思维导图可以让模型明确分析 [外科医生]、[男孩] 和 [父亲] 之间的逻辑关系,从而得出正确答案。
Second, Mind Maps enhance deductive reasoning in strategic games. We test our approach in Werewolf, a classic social deduction game where players take on hidden roles as either villagers or werewolves. Villagers attempt to identify the werewolves, while werewolves deceive the group and eliminate players without being caught. The game alternates between "night", where werewolves secretly attack, and "day", where players debate and vote on eliminations. To evaluate our Agentic Reasoning model, we invited seven experienced Werewolf players $^{5+}$ years of experience) to play against it. The model achieved an impressive $72%$ win rate, significantly exceeding both the expected statistical win rate and the performance of human players in our experiment.
其次,思维导图增强了策略游戏中的演绎推理能力。我们在《狼人杀》这一经典社交推理游戏中测试了我们的方法。在该游戏中,玩家扮演隐藏角色,要么是村民,要么是狼人。村民试图识别狼人,而狼人则欺骗团队并淘汰玩家而不被抓住。游戏在“夜晚”(狼人秘密攻击)和“白天”(玩家辩论并投票淘汰)之间交替进行。为了评估我们的AI智能体推理模型,我们邀请了七位有5年以上经验的《狼人杀》玩家与之对战。该模型取得了72%的胜率,显著超过了预期统计胜率以及我们实验中人类玩家的表现。
We analyzed the Mind Maps generated by the Agentic Reasoning model over multiple rounds of play, as shown in Figure 5. These visual structures helped the model track the relationships between different players based on their spoken arguments, allowing it to more accurately identify deception strategies, anticipate voting behaviors, and optimize its own disguise tactics. This result demonstrates that Mind Mapping is not just a tool for logic puzzles but also a powerful strategy enhancer in dynamic reasoning environments.
我们分析了由 AI 智能体推理模型在多轮游戏中生成的思维导图,如图 5 所示。这些视觉结构帮助模型根据玩家的口头论证追踪他们之间的关系,使其能够更准确地识别欺骗策略,预测投票行为,并优化自身的伪装策略。这一结果表明,思维导图不仅是逻辑谜题的工具,还是动态推理环境中的强大策略增强器。
![]()
![]()
Figure 5: Mind Map in playing werewolf game. The first round and the second round.
图 5: 玩狼人游戏时的思维导图。第一轮和第二轮。
4 Conclusion
4 结论
We introduced Agentic Reasoning, a framework that enhances LLM reasoning by integrating external agents for structured memory (Mind Map), web search, and computational analysis. This approach improves logical coherence, factual accuracy, and deep research capabilities. Our evaluations show that Agentic Reasoning outperforms existing models on expert-level QA and real-world research tasks, demonstrating its ability to synthesize knowledge effectively. The structured use of external tools enables more interpret able and verifiable reasoning, paving the way for AI systems capable of expert-level problem-solving. Future work will explore extending this framework to multimodal data and real-time adaptability, further advancing AI's ability to tackle complex, real-world challenges.
我们引入了Agentic Reasoning,这是一个通过集成外部智能体来实现结构化记忆(思维导图)、网络搜索和计算分析的框架,旨在增强大语言模型的推理能力。该方法提升了逻辑一致性、事实准确性以及深度研究能力。我们的评估显示,Agentic Reasoning在专家级问答和现实世界研究任务上优于现有模型,展示了其有效综合知识的能力。结构化地使用外部工具使得推理过程更具可解释性和可验证性,为能够解决专家级问题的AI系统铺平了道路。未来的工作将探索将该框架扩展到多模态数据和实时适应性,进一步提升AI应对复杂现实世界挑战的能力。
OpenAI. Learning to reason with LLMs.
OpenAI. 学习大语言模型推理。
References
参考文献
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, and Jonathan Larson. 2024. From local to global: A graph rag approach to query-focused sum mari z ation. ar Xiv pre print arXiv:2404.16130.
Darren Edge、Ha Trinh、Newman Cheng、Joshua Bradley、Alex Chao、Apurva Mody、Steven Truitt 和 Jonathan Larson。2024。从局部到全局:基于图RAG的查询聚焦摘要方法。arXiv预印本 arXiv:2404.16130。
Zhen Huang, Haoyang Zou, Xuefeng Li, Yixiu Liu, Yuxiang Zheng, Ethan Chern, Shijie Xia, Yiwei Qin, Weizhe Yuan, and Pengfei Liu. 2024. O1 replication journey-part 2: Surpassing o1-preview through simple distillation, big progress or bitter lesson? arXiv preprint arXiv:2411.16489.
Zhen Huang, Haoyang Zou, Xuefeng Li, Yixiu Liu, Yuxiang Zheng, Ethan Chern, Shijie Xia, Yiwei Qin, Weizhe Yuan, 和 Pengfei Liu. 2024. O1 复制之旅-第二部分:通过简单蒸馏超越 O1-预览,重大进展还是苦涩教训?arXiv 预印本 arXiv:2411.16489.


