Light-A-Video: Training-free Video Relighting via Progressive Light Fusion
Light-A-Video: 通过渐进式光照融合实现无训练视频重光照
Yujie Zhou1,6*, Jiazi $\mathbf{B}\mathbf{u}^{1,6^{*}}$ , Pengyang Ling2,6*, Pan Zhang6†, Tong $\mathrm{W}\mathbf{u}^{5}$ , Qidong Huang2,6, Jinsong $\mathrm{Li}^{3,6}$ , Xiaoyi Dong6, Yuhang Zang6, Yuhang ${\mathrm{Cao}}^{6}$ , Anyi Rao4, Jiaqi Wang6, Li Niu1† 1Shanghai Jiao Tong University 2 University of Science and Technology of China 3The Chinese University of Hong Kong 4Hong Kong University of Science and Technology 5Stanford University 6Shanghai AI Laboratory
Yujie Zhou1,6*, Jiazi $\mathbf{B}\mathbf{u}^{1,6^{*}}$, Pengyang Ling2,6*, Pan Zhang6†, Tong $\mathrm{W}\mathbf{u}^{5}$, Qidong Huang2,6, Jinsong $\mathrm{Li}^{3,6}$, Xiaoyi Dong6, Yuhang Zang6, Yuhang ${\mathrm{Cao}}^{6}$, Anyi Rao4, Jiaqi Wang6, Li Niu1† 1上海交通大学 2中国科学技术大学 3香港中文大学 4香港科技大学 5斯坦福大学 6上海人工智能实验室

Figure 1. Training-free video illumination control. Equipped with a pretrained image relighting model (e.g., IC-Light [63]) and a video diffusion model (e.g., CogVideoX [60] and AnimateD iff [13]), Light-A-Video enables training-free and zero-shot illumination control of any given video sequences or foreground sequences.
图 1: 无需训练的视频光照控制。配备预训练的图像重光照模型(如 IC-Light [63])和视频扩散模型(如 CogVideoX [60] 和 AnimateD iff [13]),Light-A-Video 实现了对任何给定视频序列或前景序列的无需训练和零样本光照控制。
Abstract
摘要
Recent advancements in image relighting models, driven by large-scale datasets and pre-trained diffusion models, have enabled the imposition of consistent lighting. However, video relighting still lags, primarily due to the excessive training costs and the scarcity of diverse, high-quality video relighting datasets. A simple application of image relighting models on a frame-by-frame basis leads to several issues: lighting source inconsistency and relighted appearance inconsistency, resulting in flickers in the generated videos. In this work, we propose Light-A-Video, a training-free approach to achieve temporally smooth video relighting. Adapted from image relighting models, LightA-Video introduces two key techniques to enhance lighting consistency. First, we design a Consistent Light Attention (CLA) module, which enhances cross-frame interactions within the self-attention layers to stabilize the generation of the background lighting source. Second, leveraging the physical principle of light transport independence, we apply linear blending between the source video’s appearance and the relighted appearance, using a Progressive Light Fusion (PLF) strategy to ensure smooth temporal transitions in illumination. Experiments show that Light-A-Video improves the temporal consistency of relighted video while maintaining the image quality, ensuring coherent lighting transitions across frames. Project page: https://bujiazi. github.io/light-a-video.github.io/.
最近,在大规模数据集和预训练扩散模型的推动下,图像重光照模型取得了显著进展,使得一致的光照施加成为可能。然而,视频重光照仍然滞后,主要原因是训练成本过高以及高质量、多样化的视频重光照数据集稀缺。简单地将图像重光照模型逐帧应用于视频会导致多个问题:光源不一致和重光照外观不一致,从而导致生成的视频出现闪烁。在这项工作中,我们提出了 Light-A-Video,一种无需训练的方法,以实现时间上平滑的视频重光照。Light-A-Video 从图像重光照模型改进而来,引入了两项关键技术以增强光照一致性。首先,我们设计了一个一致光照注意力 (Consistent Light Attention, CLA) 模块,该模块增强了自注意力层中的跨帧交互,以稳定背景光源的生成。其次,利用光传输独立的物理原理,我们在源视频外观和重光照外观之间应用线性混合,采用渐进光融合 (Progressive Light Fusion, PLF) 策略,确保光照在时间上的平滑过渡。实验表明,Light-A-Video 在保持图像质量的同时,提高了重光照视频的时间一致性,确保了帧与帧之间光照的连贯过渡。项目页面:https://bujiazi. github.io/light-a-video.github.io/。
1. Introduction
1. 引言
Illumination plays a crucial role in shaping our perception of visual content, impacting both its aesthetic quality and human interpretation of scenes. Relighting tasks [18, 25, 33, 35, 45, 48, 55, 66, 67], which focus on adjusting lighting conditions in 2D and 3D visual content, have long been a key area of research in computer graphics due to their broad practical applications, such as film production, gaming, and virtual environments. Traditional image relighting methods rely on physical illumination models, which struggle with accurately estimating real-world lighting and materials.
照明在塑造我们对视觉内容感知方面起着至关重要的作用,影响其美学质量和人类对场景的理解。重光照任务 [18, 25, 33, 35, 45, 48, 55, 66, 67], 专注于调整2D和3D视觉内容中的光照条件,由于其广泛的实际应用(如电影制作、游戏和虚拟环境),长期以来一直是计算机图形学研究的重点领域。传统的图像重光照方法依赖于物理光照模型,这些模型在准确估计现实世界中的光照和材质方面存在困难。
To overcome these limitations, data-driven approaches [10, 20, 23, 40, 61, 65] have emerged, leveraging large-scale, diverse relighting datasets combined with pre-trained diffusion models. As the state-of-the-art image relighting model, IC-Light [63] modifies only the illumination of an image while maintaining its albedo unchanged. Based on the physical principle of light transport independence, IC-Light allows for controlled and stable illumination editing, such as adjusting lighting effects and simulating complex lighting scenarios. However, video relighting is significantly more challenging due to maintaining temporal consistency across frames. The scarcity of video lighting datasets and the cost of training further complicate the task. Thus, existing video relighting methods [65] struggle to deliver consistently high-quality results or are limited to specific domains, such as portraits.
为了克服这些限制,数据驱动的方法 [10, 20, 23, 40, 61, 65] 应运而生,它们利用大规模、多样化的重光照数据集与预训练的扩散模型相结合。作为最先进的图像重光照模型,IC-Light [63] 仅修改图像的照明,同时保持其反照率不变。基于光传输独立的物理原理,IC-Light 允许进行可控且稳定的照明编辑,例如调整光照效果和模拟复杂的光照场景。然而,由于需要保持帧间的时间一致性,视频重光照的挑战性显著增加。视频光照数据集的稀缺性和训练成本的增加进一步加剧了这一任务的复杂性。因此,现有的视频重光照方法 [65] 难以持续提供高质量的结果,或者仅限于特定领域,如肖像。
In this work, we propose a training-free approach for video relighting, named Light-A-Video, which enables the generation of smooth, high-quality relighted videos without any training or optimization. As shown in Fig. 1, given a text prompt that provides a general description of the video and specified illumination conditions, our Light-A-Video pipeline can relight the input video in a zero-shot manner, fully leveraging the relighting capabilities of image-based models and the motion priors of the video diffusion model. To achieve this goal, we initially apply an image-relighting model to video-relighting tasks on a frame-by-frame basis, and observe that the generated lighting source is unstable across frames in the video. This instability leads to inconsistencies in the relighting of the objects’ appearances and significant flickering across frames. To stabilize the generated lighting source and ensure consistent results, we design a Consistent Light Attention (CLA) module within the selfattention layers of the image relighting model. As shown in Fig. 2, by incorporating additional temporally averaged features into the attention computation, CLA facilitates crossframe interactions, producing a structurally stable lighting source. To further enhance the appearance stability across frames, we utilize the motion priors of the video diffusion model with a novel Progressive Light Fusion (PLF) strategy. Adhering to the physical principles of light transport, PLF progressively employs linear blending to integrate relighted appearances from the CLA into each original denoising target, which gradually guides the video denoising process toward the desired relighting direction. Finally, Light-A-Video serves as a complete end-to-end pipeline, effectively achieving smooth and consistent video relighting. As a training-free approach, Light-A-Video is not restricted to specific video diffusion models, making it highly compatible with a range of popular video generation backbones, including UNet-based and DiT-based models such as AnimateDiff [13], CogVideoX [60] and LTX-Video [15]. Our contributions are summarized as follows:
在本工作中,我们提出了一种无需训练的视频重照明方法,名为 Light-A-Video,它能够在无需任何训练或优化的情况下生成平滑、高质量的重照明视频。如图 1 所示,给定一个提供视频一般描述和指定照明条件的文本提示,我们的 Light-A-Video 管道可以以零样本的方式对输入视频进行重照明,充分利用基于图像模型的重照明能力和视频扩散模型的运动先验。为了实现这一目标,我们首先将图像重照明模型逐帧应用于视频重照明任务,并观察到生成的照明源在视频帧之间不稳定。这种不稳定性导致物体外观的重照明不一致,并在帧之间出现显著的闪烁。为了稳定生成的照明源并确保一致的结果,我们在图像重照明模型的自注意力层中设计了一个一致光注意力 (Consistent Light Attention, CLA) 模块。如图 2 所示,通过将额外的时间平均特征纳入注意力计算,CLA 促进了跨帧交互,生成了结构稳定的照明源。为了进一步增强帧之间的外观稳定性,我们利用视频扩散模型的运动先验,采用了一种新颖的渐进光融合 (Progressive Light Fusion, PLF) 策略。遵循光传输的物理原理,PLF 逐步使用线性混合将 CLA 生成的重照明外观集成到每个原始去噪目标中,从而逐渐引导视频去噪过程朝向期望的重照明方向。最终,Light-A-Video 作为一个完整的端到端管道,有效地实现了平滑且一致的视频重照明。作为一种无需训练的方法,Light-A-Video 不受特定视频扩散模型的限制,使其与多种流行的视频生成骨干高度兼容,包括基于 UNet 和 DiT 的模型,如 AnimateDiff [13]、CogVideoX [60] 和 LTX-Video [15]。我们的贡献总结如下:

Figure 2. Comparison of relighted frames using IC-Light and CLA module frame-by-frame. The line chart depicts the average optical flow intensity per frame. IC-Light shows a noticeable jitter between frames. Conversely, our CLA module achieves more stable light source generation over time, making the motion trend more consistent with the source video.
图 2: 使用 IC-Light 和 CLA 模块逐帧比较重光照帧。折线图描绘了每帧的平均光流强度。IC-Light 在帧之间显示出明显的抖动。相比之下,我们的 CLA 模块随着时间的推移实现了更稳定的光源生成,使运动趋势与源视频更加一致。
• We present Light-A-Video, the first training-free video relighting model, which leverages the capabilities of image relighting models to generate high-quality, temporally consistent relighted videos.
• 我们提出了 Light-A-Video,这是首个无需训练的视频重光照模型,它利用图像重光照模型的能力生成高质量、时间一致的重光照视频。
• An end-to-end pipeline is proposed with two key designs: the Consistent Light Attention, which enhances the stability of lighting source across frames, and the Progressive Light Fusion, which gradually injects lighting information to ensure temporal consistency for video appearance. • Experiments show the effectiveness of our method across multiple settings. It not only supports relighting of the entire input video, but also supports relighting the input foreground sequences with background generation.
• 提出了一个端到端的管道,包含两个关键设计:一致光注意力 (Consistent Light Attention),它增强了帧间光源的稳定性;以及渐进光融合 (Progressive Light Fusion),它逐步注入光照信息以确保视频外观的时间一致性。
• 实验表明,我们的方法在多种设置下都有效。它不仅支持对整个输入视频进行重光照,还支持在生成背景的同时对输入的前景序列进行重光照。
2. Related Work
2. 相关工作
2.1. Video Diffusion Models.
2.1. 视频扩散模型
Video diffusion models [2–6, 13, 17, 51, 54, 60, 62] aim to synthesize temporally consistent image frames based on provided conditions, such as a text prompt or an image prompt. In the realm of text-to-video (T2V) generation, the majority of methods [3, 5, 6, 13, 51, 62] train additional motion modeling modules from existing text-to-image archi tec ture s to model the correlation between video frames, while others [17, 60] train from scratch to learn video priors. For image-to-video (I2V) tasks that enhance still images with reasonable motions, a line of research [7, 57] proposes novel frameworks dedicated to image animation. Some approaches [12, 14, 64] serve as plug-to-play adapters. Stable Video Diffusion [2] fine-tune pre-trained T2V models for I2V generation, achieving impressive performance. Numerous works [27, 30, 34] focus on controllable generation, providing more control l ability for users. Video diffusion models, due to their inherent video priors, are capable of synthesizing smooth and consistent video frames that are both content-rich and temporally harmonious.
视频扩散模型 [2–6, 13, 17, 51, 54, 60, 62] 旨在基于提供的条件(如文本提示或图像提示)合成时间上一致的图像帧。在文本到视频 (T2V) 生成领域,大多数方法 [3, 5, 6, 13, 51, 62] 从现有的文本到图像架构中训练额外的运动建模模块,以建模视频帧之间的相关性,而其他方法 [17, 60] 则从头开始训练以学习视频先验。对于通过合理运动增强静态图像的图像到视频 (I2V) 任务,一系列研究 [7, 57] 提出了专门用于图像动画的新框架。一些方法 [12, 14, 64] 作为即插即用的适配器。Stable Video Diffusion [2] 对预训练的 T2V 模型进行微调以进行 I2V 生成,取得了令人印象深刻的性能。许多工作 [27, 30, 34] 专注于可控生成,为用户提供更多的控制能力。视频扩散模型由于其固有的视频先验,能够合成内容丰富且时间上和谐的平滑一致视频帧。
2.2. Learning-based Illumination Control.
基于学习的照明控制
Over the past few years, a variety of lighting control techniques [33, 35, 48] for 2D and 3D visual content based on deep neural networks have been proposed, especially in the field of portrait lighting [1, 23, 44, 46, 47], along with a range of baselines [18, 45, 55, 66, 67] aimed at improving the effectiveness, accuracy, and theoretical foundation of illumination modeling. Recently, owing to the rapid development of diffusion-based generative models, a number of lighting control methods [10, 20, 40, 61] utilizing diffusion models have also been introduced. Relightful Harmonization [40] focuses on harmonizing sophisticated lighting effects for the foreground portrait conditioning on a given background image. Switch Light [23] suggests training a physically co-designed framework for human portrait relighting. IC-Light [63] is a state-of-the-art approach for image relighting. LumiSculpt [65] enables consistent lighting control in T2V generation models for the first time. However, in the domain of video lighting, the aforementioned approaches fail to simultaneously ensure precise lighting control and exceptional visual quality. This work incorporates a pre-trained image lighting control model into the denoising process of a T2V model through progressive guidance, leveraging the latter’s video priors to facilitate the smooth transfer of image lighting control knowledge, thereby enabling accurate and harmonized control of video lighting.
近年来,基于深度神经网络的各种2D和3D视觉内容光照控制技术 [33, 35, 48] 被提出,特别是在肖像光照领域 [1, 23, 44, 46, 47],同时还有一系列旨在提高光照建模效果、准确性和理论基础的基线方法 [18, 45, 55, 66, 67]。最近,由于基于扩散的生成模型的快速发展,一些利用扩散模型的光照控制方法 [10, 20, 40, 61] 也被引入。Relightful Harmonization [40] 专注于在给定背景图像的情况下为前景肖像协调复杂的光照效果。Switch Light [23] 提出了一个物理协同设计框架用于人像重光照训练。IC-Light [63] 是一种最先进的图像重光照方法。LumiSculpt [65] 首次在T2V生成模型中实现了一致的光照控制。然而,在视频光照领域,上述方法无法同时确保精确的光照控制和卓越的视觉质量。本工作通过渐进式引导将预训练的图像光照控制模型融入T2V模型的去噪过程中,利用后者的视频先验知识促进图像光照控制知识的平滑迁移,从而实现视频光照的准确和协调控制。
2.3. Video Editing with Diffusion Models.
2.3. 基于扩散模型的视频编辑
In recent years, diffusion-based video editing has undergone significant advancements. Some researches [29, 30, 32, 53, 56] adopt pretrained text-to-image (T2I) backbones for video editing. Another line of approaches [8, 19, 58, 59] leverages pre-trained optical flow models to enhance the temporal consistency of output video. Numerous studies [11, 21, 38] have concentrated on exploring zero-shot video editing approaches. COVE [52] leverages the inherent diffusion feature correspondence proposed by DIFT [49] to achieve consistent video editing. SDEdit [31] utilizes the intrinsic capability of diffusion models to refine details based on a given layout, enabling efficient editing for both image and video. Despite the remarkable performance of existing video editing techniques in various settings, there remains a lack of approaches specifically designed for controlling the lighting of videos.
近年来,基于扩散模型的视频编辑技术取得了显著进展。一些研究 [29, 30, 32, 53, 56] 采用预训练的文本到图像 (T2I) 骨干网络进行视频编辑。另一类方法 [8, 19, 58, 59] 则利用预训练的光流模型来增强输出视频的时间一致性。许多研究 [11, 21, 38] 专注于探索零样本视频编辑方法。COVE [52] 利用 DIFT [49] 提出的固有扩散特征对应关系来实现一致性的视频编辑。SDEdit [31] 利用扩散模型的内在能力,基于给定的布局细化细节,从而实现对图像和视频的高效编辑。尽管现有视频编辑技术在各种场景下表现优异,但仍缺乏专门用于控制视频光照的方法。
3. Preliminary
3. 初步
3.1. Diffusion Model
3.1. 扩散模型 (Diffusion Model)
Given an image $\mathbf{x}{\mathrm{0}}$ that follows the real-world data distribution, we first encode $\mathbf{x}{\mathrm{0}}$ into latent space ${\bf z}{0}=\mathcal{E}({\bf x}{0})$ using a pretrained auto encoder ${\mathcal{E}(\cdot),\mathcal{D}(\cdot)}$ . The forward diffusion process is a $T$ steps Markov chain [16], corresponding to the iterative introduction of Gaussian noise $\epsilon$ , which can be expressed as:
给定一张遵循现实世界数据分布的图像 $\mathbf{x}{\mathrm{0}}$,我们首先使用预训练的自编码器 ${\mathcal{E}(\cdot),\mathcal{D}(\cdot)}$ 将其编码到潜在空间 ${\bf z}{0}=\mathcal{E}({\bf x}_{0})$。前向扩散过程是一个 $T$ 步的马尔可夫链 [16],对应于高斯噪声 $\epsilon$ 的迭代引入,可以表示为:
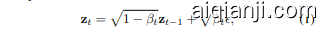
where $\beta_{t}\in(0,1)$ determines the amount of Gaussian noise introduced at time step $t$ . Mathematically, the above cumulative noise adding has the following closed-form:
其中 $\beta_{t}\in(0,1)$ 决定了在时间步 $t$ 引入的高斯噪声量。从数学上讲,上述累积噪声添加具有以下闭合形式:
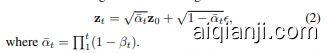
where $\begin{array}{r}{\bar{\alpha}{t}=\prod{1}^{t}(1-\beta_{t})}\end{array}$ .
其中 $\begin{array}{r}{\bar{\alpha}{t}=\prod{1}^{t}(1-\beta_{t})}\end{array}$。
For num erical stability, $\mathbf{v}$ -prediction [42] approach is employed, where the diffusion model outputs a predicted velocity $\mathbf{v}$ to represent the denoising direction. Defined as:
为了数值稳定性,采用了 $\mathbf{v}$ -预测 [42] 方法,其中扩散模型输出预测速度 $\mathbf{v}$ 来表示去噪方向。定义为:

During inference, the noise-free component $\hat{\mathbf{z}}{0\gets t}$ can be recovered from the model’s output $\mathbf{v}{t}$ as follows:
在推理过程中,无噪声分量 $\hat{\mathbf{z}}{0\gets t}$ 可以从模型的输出 $\mathbf{v}{t}$ 中恢复如下:
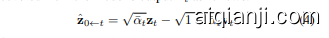
$\hat{\mathbf{z}}{0\gets t}$ represents the denoising target based on $\mathbf{v}{t}$
$\hat{\mathbf{z}}{0\gets t}$ 代表了基于 $\mathbf{v}{t}$ 的去噪目标

Figure 3. The pipeline of Light-A-Video. A source video is first noised and processed through the VDM for denoising across $T_{m}$ steps. At each step, the predicted noise-free component with details compensation serves as the Consistent Target $\mathbf{z}{0\leftarrow t}^{v}$ , inherently representing the VDM’s denoising direction. Consistent Light Attention infuses $\mathbf{z}{0\leftarrow t}^{v}$ with unique lighting information, transforming it into the Relight Target $\mathbf{z}{0\leftarrow t}^{r}$ . The Progressive Light Fusion strategy then merges two targets to form the Fusion Target $\tilde{\mathbf{z}}{0\gets t}$ , which provides a refined direction for the current step. The bottom-right part illustrates the iterative evolution of $\mathbf{z}_{0\leftarrow t}^{v}$ .
图 3: Light-A-Video 的流程。首先对源视频进行加噪处理,并通过 VDM 在 $T_{m}$ 步中进行去噪。在每一步中,带有细节补偿的预测无噪分量作为 Consistent Target $\mathbf{z}{0\leftarrow t}^{v}$,本质上代表了 VDM 的去噪方向。Consistent Light Attention 将 $\mathbf{z}{0\leftarrow t}^{v}$ 与独特的照明信息融合,将其转换为 Relight Target $\mathbf{z}{0\leftarrow t}^{r}$。随后,Progressive Light Fusion 策略将两个目标合并,形成 Fusion Target $\tilde{\mathbf{z}}{0\gets t}$,为当前步骤提供了精细的方向。右下部分展示了 $\mathbf{z}_{0\leftarrow t}^{v}$ 的迭代演变过程。
3.2. Light Transport
3.2. 光线传输
Light transport theory [9, 63] demonstrates that arbitrary image appearance ${\bf I}_{L}$ can be decomposed by the product of a light transport matrix $\mathbf{T}$ and environment illumination $L$ , which can be expressed as:
光线传输理论 [9, 63] 表明,任意图像外观 ${\bf I}_{L}$ 可以通过光线传输矩阵 $\mathbf{T}$ 和环境光照 $L$ 的乘积来分解,表达式为:

where $\mathbf{T}$ is a single matrix for linear light transform [9] and $L$ denotes variable environment illumination. Given the linearity of $\mathbf{T}$ , the merging between environment illumination $L$ is equal to the fusion of image appearance ${\bf I}_{L}$ , i.e.,
其中 $\mathbf{T}$ 是线性光变换的单个矩阵 [9],$L$ 表示可变环境光照。鉴于 $\mathbf{T}$ 的线性特性,环境光照 $L$ 之间的合并等同于图像外观 ${\bf I}_{L}$ 的融合,即

Such characteristic suggests the feasibility of lighting control by indirectly constraining image appearance, i.e., the consistent image light constraint in IC-Light [63].
这一特性表明,通过间接约束图像外观(即 IC-Light [63] 中的一致图像光照约束)来实现光照控制的可行性。
4. Light-A-Video
4. Light-A-Video
In Section 4.1, we define the objectives of the video relighting task. In Section 4.2, we reveal that per-frame image relighting for video sequence suffers from lighting source inconsistency and accordingly propose Consistent Lighting Attention (CLA) module for enhanced lighting stability in per-frame image relighting results. In Section 4.3, we provide a detailed description of the proposed Light-A-Video pipeline, which achieves stable lighting source generation and temporally consistent relighted video through Progressive Light Fusion (PLF) strategy.
在 4.1 节中,我们定义了视频重光照任务的目标。在 4.2 节中,我们揭示了视频序列的逐帧图像重光照存在光源不一致的问题,并相应地提出了 Consistent Lighting Attention (CLA) 模块,以增强逐帧图像重光照结果的光照稳定性。在 4.3 节中,我们详细描述了所提出的 Light-A-Video 流程,该流程通过渐进式光照融合 (Progressive Light Fusion, PLF) 策略实现了稳定的光源生成和时间一致的重光照视频。
4.1. Problem Formulation
4.1. 问题定义
Given a source video and a lighting condition $c$ , the objective of video relighting is to render the source video into the relighted video that aligns with the given condition $c$ . Unlike image relighting solely concentrates on appearance, video relighting raises extra challenges in maintaining temporal consistency and motion preservation, necessitating high-quality visual coherence across frames.
给定源视频和光照条件 $c$,视频重照明的目标是将源视频渲染为与给定条件 $c$ 对齐的重照明视频。与仅关注外观的图像重照明不同,视频重照明在保持时间一致性和运动保存方面提出了额外的挑战,需要在帧之间保持高质量的视觉一致性。
4.2. Consistent Light Attention
4.2. 一致性光注意力
Given the achievement in image relighting model [63], a straightforward approach for video relighting is to directly perform frame-by-frame image relighting under the same lighting condition. However, as illustrated in Fig. 2, this naive method fails to maintain appearance coherence across frames, resulting in frequent flickering of the generated light source and inconsistent temporal illumination.
鉴于图像重照明模型[63]的成就,视频重照明的一个直接方法是在相同照明条件下直接逐帧进行图像重照明。然而,如图2所示,这种简单的方法无法保持帧间外观一致性,导致生成的光源频繁闪烁和时间照明不一致。
To improve inter-frame information integration and generate a stable light source, we propose a Consistent Light Attention (CLA) module. Specifically, for each selfattention layer in the IC-Light model, a video feature map $\mathbf{h}\ \in\ \mathbb{R}^{(b\times\bar{f})\times(h\times w)\times c}$ serves as the input, where $b$ is the batch size and $f$ is the number of video frames, $h$ and $w$ denote the height and width of the feature map, with $h\times w$ representing the number of tokens for attention computation. With linearly projections, $\mathbf{h}$ is projected into query, key and value features $\mathit{\dot{Q}},K,V;\in;\mathbb{R}^{\bar{(}b\times\bar{f})\times(h\times w)\times c}$ . The attention computation is defined as follows:
为了提升帧间信息集成并生成稳定的光源,我们提出了一致性光照注意力(Consistent Light Attention, CLA)模块。具体来说,对于IC-Light模型中的每个自注意力层,视频特征图$\mathbf{h}\ \in\ \mathbb{R}^{(b\times\bar{f})\times(h\times w)\times c}$作为输入,其中$b$是批量大小,$f$是视频帧数,$h$和$w$表示特征图的高度和宽度,$h\times w$代表用于注意力计算的Token数量。通过线性投影,$\mathbf{h}$被投影为查询、键和值特征$\mathit{\dot{Q}},K,V;\in;\mathbb{R}^{\bar{(}b\times\bar{f})\times(h\times w)\times c}$。注意力计算定义如下:
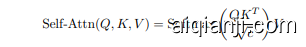
Note that the naive method treats the frame dimension as the batch size, performing self-attention frame by frame with the image relighting model, which results in each frame attending only to its own features. For our CLA module as shown in Fig. 3, a dual-stream attention fusion strategy is applied. Given the input $\mathbf{h}$ , the original stream directly feeds the feature map into the attention module to compute frame-by-frame attention, resulting in the output $\mathbf{h}{1}^{\prime}$ . The average stream first reshapes h into Rb×f×(h×w)×c, averages it along the temporal dimension, then expands it $f$ times to obtain $\bar{\mathbf{h}}$ . Specifically, the average stream mitigates high-frequency temporal fluctuations, thereby facilitating the generation of a stable background light source across frames. Meanwhile, the original stream retains the original high-frequency details, thereby compensating for the detail loss incurred by the averaging process. Then, $\bar{\mathbf{h}}$ is input into the self-attention module and the output is $\bar{\mathbf{h}}{2}^{\prime}$ . The final output $\mathbf{h}_{o}^{\prime}$ of the CLA module is a weighted average between two streams, with the trade-off parameter $\gamma$ ,
需要注意的是,朴素方法将帧维度视为批量大小,逐帧使用图像重光照模型进行自注意力计算,这导致每帧仅关注自身的特征。如图 3 所示,我们的 CLA (Cross-Layer Attention) 模块采用了双流注意力融合策略。给定输入 $\mathbf{h}$,原始流直接将特征图输入到注意力模块中,计算逐帧注意力,得到输出 $\mathbf{h}{1}^{\prime}$。平均流首先将 h 重塑为 Rb×f×(h×w)×c,沿时间维度进行平均,然后将其扩展 $f$ 次以获得 $\bar{\mathbf{h}}$。具体来说,平均流能够缓解高频时间波动,从而促进跨帧生成稳定的背景光源。同时,原始流保留了原始的高频细节,从而弥补了平均过程带来的细节损失。接着,$\bar{\mathbf{h}}$ 被输入到自注意力模块中,输出为 $\bar{\mathbf{h}}{2}^{\prime}$。CLA 模块的最终输出 $\mathbf{h}_{o}^{\prime}$ 是两个流的加权平均,权衡参数为 $\gamma$。
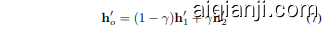
With the help of CLA, the result can capture global context across the entire video, and generated a more stable relighting result as shown in Fig. 2.
在 CLA 的帮助下,结果能够捕捉整个视频的全局上下文,并生成更稳定的重光照结果,如图 2 所示。
4.3. Progressive Light Fusion
4.3. 渐进式光融合
CLA module improves cross-frame consistency but lacks pixel-level constraints, leading to inconsistencies in appearance details. To address this, we leverage motion priors in Video Diffusion Model (VDM), which are trained on largescale video datasets and use temporal attention module to ensure consistent motion and lighting changes. The novelty of our Light-A-Video lies in progressively injecting the relighting results as guidance into the denoising process.
CLA 模块提高了跨帧一致性,但缺乏像素级约束,导致外观细节不一致。为了解决这个问题,我们在视频扩散模型 (Video Diffusion Model, VDM) 中利用了运动先验,该模型在大规模视频数据集上进行训练,并使用时间注意力模块来确保一致的运动和光照变化。我们提出的 Light-A-Video 的创新之处在于逐步将重光照结果作为指导注入到去噪过程中。
In the pipeline as shown in Fig 3, a source video is first encoded into latent space, and then add $T_{m}$ step noise to acquire the noisy latent ${\bf z}{m}$ . At each denoising step $t$ , the noise-free component $\hat{\mathbf{z}}{0\leftarrow t}$ in Eq. 4 is predicted, which serves as the denoising target for the current step. Prior work demonstrated the potential of applying tailored manipulation in denoising targets for guided generation, with significant achievements observed in high-resolution image synthesis [24] and text-based image editing [41].
在图 3 所示的流程中,源视频首先被编码到潜在空间,然后添加 $T_{m}$ 步噪声以获得噪声潜在 ${\bf z}{m}$。在每个去噪步骤 $t$ 中,预测公式 4 中的无噪声分量 $\hat{\mathbf{z}}{0\leftarrow t}$,它作为当前步骤的去噪目标。先前的工作展示了在去噪目标中应用定制化操作以进行引导生成的潜力,在高分辨率图像合成 [24] 和基于文本的图像编辑 [41] 中取得了显著成果。
Driven by the motion priors in the VDM, the denoising process encourage $\hat{\mathbf{z}}{0\gets t}$ to be temporally consistent. Thus, we define this target as the video Consistent Target z0v t with environment illumination $L{t}^{v}$ . However, discrepancies still exist between the predicted $\mathbf{z}{0\leftarrow t}^{v}$ and the original video. To address this issue, we incorporate the differences as details compensation into the Consistent Target at each step, thereby enhancing detail consistency between the relighted video and the original video. Then, $\mathbf{z}{0\leftarrow t}^{v}$ is sent into the CLA module to obtain the relighted latent, which serves as the Relight Target $\mathbf{z}{0\leftarrow t}^{r}$ with the illumination $L{t}^{r}$ for the $t$ -th denoising step. Aligning with the light transport theory in Section 3.2, a pre-trained VAE ${\mathcal{E}(\cdot),\mathcal{D}(\cdot)}$ is used to decode the two targets into pixel level, yielding the image appearances $\mathbf{I}{t}^{v}=\mathcal{D}(\mathbf{z}{0\leftarrow t}^{v})$ and $\mathbf{I}{t}^{r}=\mathcal{D}(\mathbf{z}{0\leftarrow t}^{r})$ , respectively. Refer to Eq. 6, the fusing appearance $\mathbf{I}_{t}^{f}$ can be formulated as,
在 VDM 中的运动先验驱动下,去噪过程鼓励 $\hat{\mathbf{z}}{0\gets t}$ 在时间上保持一致。因此,我们将这一目标定义为视频一致性目标 z0v t,并带有环境光照 $L{t}^{v}$。然而,预测的 $\mathbf{z}{0\leftarrow t}^{v}$ 与原始视频之间仍然存在差异。为了解决这个问题,我们将这些差异作为细节补偿纳入每一步的一致性目标中,从而增强重光照视频与原始视频之间的细节一致性。然后,$\mathbf{z}{0\leftarrow t}^{v}$ 被送入 CLA 模块以获得重光照的潜在表示,作为第 $t$ 步去噪的重光照目标 $\mathbf{z}{0\leftarrow t}^{r}$,并带有光照 $L{t}^{r}$。与第 3.2 节中的光传输理论一致,我们使用预训练的 VAE ${\mathcal{E}(\cdot),\mathcal{D}(\cdot)}$ 将这两个目标解码到像素级别,分别得到图像外观 $\mathbf{I}{t}^{v}=\mathcal{D}(\mathbf{z}{0\leftarrow t}^{v})$ 和 $\mathbf{I}{t}^{r}=\mathcal{D}(\mathbf{z}{0\leftarrow t}^{r})$。参考公式 6,融合外观 $\mathbf{I}_{t}^{f}$ 可以表示为:

Figure 4. Visualization of the PLF Strategy. During the denoising process of the VDM, the PLF strategy progressively replaces the original Consistent Target $P_{c}^{t}$ with the Fusion Target $P_{f}^{t}$ , guiding the denoising direction from $\mathbf{z}{0\leftarrow t}^{v}$ to $\tilde{{\bf v}}{t}$ .
图 4: PLF 策略的可视化。在 VDM 的去噪过程中,PLF 策略逐步将原始的一致性目标 $P_{c}^{t}$ 替换为融合目标 $P_{f}^{t}$,引导去噪方向从 $\mathbf{z}{0\leftarrow t}^{v}$ 到 $\tilde{{\bf v}}{t}$。

We observe that directly using encoded latent $\mathcal{E}(\mathbf{I}{t}^{f})$ as the new target at each step results in suboptimal performance. The reason is that the gap between the two targets is excessively large, surpassing the refinement capability of the VDM and causing visible temporal lighting jitter. To mitigate this gap, a progressive lighting fusion strategy is proposed. Specifically, a fusion weight $\lambda{t}$ is introduced, which decreases as denoising progresses, gradually reducing the influence of the relight target. The progressive light fusion appearance is defined as $\mathbf{I}_{t}^{p}$ ,
我们观察到,直接使用编码的潜在表示 $\mathcal{E}(\mathbf{I}{t}^{f})$ 作为每一步的新目标会导致次优性能。原因是两个目标之间的差距过大,超出了 VDM 的细化能力,导致可见的时间光照抖动。为了缓解这一差距,提出了一种渐进式光照融合策略。具体来说,引入了一个融合权重 $\lambda{t}$,随着去噪过程的进行而逐渐减小,逐步减少重光照目标的影响。渐进式光照融合外观定义为 $\mathbf{I}_{t}^{p}$。

The encoded latent $\widetilde{\mathbf{z}}{0\leftarrow t}=\mathcal{E}(\mathbf{I}{t}^{p})$ is utilized as the Fusion Target for step $t$ , replacing the original $\hat{\mathbf{z}}{0\gets t}$ . Based on the fusion target, the less noisy latent $\mathbf{Z}{t-1}$ can be computed with DDIM scheduler with $v$ -prediction:
编码后的潜在表示 $\widetilde{\mathbf{z}}{0\leftarrow t}=\mathcal{E}(\mathbf{I}{t}^{p})$ 被用作步骤 $t$ 的融合目标 (Fusion Target),替代原始的 $\hat{\mathbf{z}}{0\gets t}$。基于融合目标,可以通过 DDIM 调度器 (DDIM scheduler) 和 $v$ 预测 (prediction) 计算出噪声较少的潜在表示 $\mathbf{Z}{t-1}$。

From Eq. 4, the fusion target $\tilde{\mathbf{z}}_{0\leftarrow t}$ determines a new de
从公式 4 中,融合目标 $\tilde{\mathbf{z}}_{0\leftarrow t}$ 确定了一个新的去
noising direction, denoted as $\tilde{{\bf v}}_{t}$ ,
去噪方向,表示为 $\tilde{{\bf v}}_{t}$

which means our PLF strategy essentially refines $\mathbf{v}_{t}$ iteratively and guides the denoising process towards the relighting direction shown in Fig 4. Notably, other schedulers (e.g., Euler Scheduler [22], Flow Matching [28], etc.) with predicted noise-free components for each step are also applicable. Finally, as the denoising progresses, we achieve a smooth and consistent injection of illumination, ensuring coherent video relighting.
这意味着我们的PLF策略本质上是迭代优化 $\mathbf{v}_{t}$,并将去噪过程引导至图4所示的重光照方向。值得注意的是,其他在每个步骤中预测无噪声分量的调度器(例如Euler Scheduler [22]、Flow Matching [28]等)也同样适用。最终,随着去噪的进行,我们实现了光照的平滑且一致的注入,确保了视频重光照的连贯性。
5. Experiments
5. 实验
In this section, we provide comprehensive qualitative and quantitative evaluations to highlight the efficacy and generality of our method for zero-shot video illumination control. Furthermore, we conduct ablation studies to analyze the contributions of critical model components and provide additional results on text-conditioned video illumination modifying with background generation.
在本节中,我们提供了全面的定性和定量评估,以突出我们方法在零样本视频光照控制方面的有效性和通用性。此外,我们进行了消融研究,分析了关键模型组件的贡献,并提供了基于文本条件的视频光照修改与背景生成的额外结果。
5.1. Experimental Details
5.1. 实验细节
Baselines. In the absence of established video relighting methods, we adopt the state-of-the-art image relighting technique to perform frame-by-frame relighting on videos as a baseline. To verify the temporal smoothing effect of illumination using a VDM, we add $20%$ and $60%$ noise to the results obtained from IC-Light [63]. Subsequently, we apply SDEdit [31] on VDM for denoising, resulting in two sets of results named IC-Light $^+$ SDEdit-0.2 and IC-Light $^+$ SDEdit-0.6, respectively. Finally, AnyV2V [26] is utilized as another baseline to verify whether the temporal content migration method can be effectively applied to video relighting tasks. This baseline names IC-Light $^+$ AnyV2V, where the first frame of the IC-Light result and the source video are used as conditional inputs.
基线。由于缺乏成熟的视频重光照方法,我们采用最先进的图像重光照技术对视频进行逐帧重光照作为基线。为了验证使用VDM对光照进行时间平滑的效果,我们在IC-Light [63] 的结果上添加了 $20%$ 和 $60%$ 的噪声。随后,我们在VDM上应用SDEdit [31] 进行去噪,得到两组结果,分别命名为IC-Light $^+$ SDEdit-0.2和IC-Light $^+$ SDEdit-0.6。最后,AnyV2V [26] 被用作另一个基线,以验证时间内容迁移方法是否可以有效地应用于视频重光照任务。该基线命名为IC-Light $^+$ AnyV2V,其中IC-Light结果的第一帧和源视频被用作条件输入。
Evaluation metrics. We report three widely adopted metrics for quantitative evaluation. First, to evaluate the temporal consistency of the generated video, the average CLIP [39] score across consecutive video frames is utilized. Second, RAFT [50] is used to estimate the optical flow for each baseline video, and assess the motion preservation of each method by calculating the optical flow similarity with the source video. Third, to evaluate the quality of image relighting for each method, a video test dataset is collected, and the FID [43] score is calculated between each method’s results And the frame-by-frame IC-Light results, serving as the relight quality evaluation metric.
评估指标。我们报告了三个广泛采用的定量评估指标。首先,为了评估生成视频的时间一致性,使用了连续视频帧的平均CLIP [39] 分数。其次,RAFT [50] 用于估计每个基线视频的光流,并通过计算与源视频的光流相似性来评估每种方法的运动保持能力。第三,为了评估每种方法的图像重照明质量,收集了一个视频测试数据集,并计算了每种方法结果与逐帧IC-Light结果之间的FID [43] 分数,作为重照明质量评估指标。
Datasets. We constructed a video test dataset consisting of 73 videos. The majority of these videos were selected from the DAVIS [37] public dataset, which contains a diverse collection of semantically rich videos with pronounced motion. Additionally, some videos were collected from Pixabay [36], featuring high-quality videos with significant motion. All quantitative metrics are evaluated on our collected dataset. For each video, two lighting prompts are applied, and three lighting directions are randomly chosen.
数据集。我们构建了一个包含 73 个视频的视频测试数据集。这些视频大多选自 DAVIS [37] 公共数据集,该数据集包含了多种语义丰富且运动明显的视频。此外,部分视频来自 Pixabay [36],这些视频具有高质量且运动显著的特点。所有定量指标均在我们收集的数据集上进行评估。对于每个视频,应用两种光照提示,并随机选择三种光照方向。
Implementation details. If not specified, the default models employed for image relighting and VDM in the subse- quent experiments are IC-Light [63] and AnimateD iff [13] motion-adapter-v3, respectively. In the IC-Light model, the lighting conditions $c$ for image relighting are derived from two components. First, a text prompt that describes the characteristics of the light source (e.g., neon light, sunshine, etc.). Second, a lighting map is utilized to represent the light intensity across the scene. This lighting map is then encoded by a VAE and serves as the initial latent for the denoising process. During the inference stage, the source video is added with $50%$ noise. Then, the VDM employs a denoising process with $T_{m},=,25$ steps to progressively fusion the relight target. For the parameters in our LightA-Video model, the $\gamma,=,0.5$ in the CLA module is used to balance the original attention hidden state and the crossframe averaged hidden state. In our PLF strategy, the fusion weight $\lambda_{t}$ is decreases as denoising progresses, so we set $\lambda=1-t/T_{m}$ . All experiments were conducted on a single A100 GPU, with a memory consumption of approximately 23GB for a 16-frame relighted video generation.
实现细节。如果未特别说明,后续实验中用于图像重光照和VDM的默认模型分别为IC-Light [63]和AnimateDiff [13]的motion-adapter-v3。在IC-Light模型中,图像重光照的光照条件 $c$ 来自两个部分。首先,描述光源特性的文本提示(例如霓虹灯、阳光等)。其次,使用光照图来表示场景中的光照强度。该光照图通过VAE编码,并作为去噪过程的初始潜变量。在推理阶段,源视频添加了 $50%$ 的噪声。然后,VDM使用 $T_{m},=,25$ 步的去噪过程逐步融合重光照目标。对于我们的LightA-Video模型中的参数,CLA模块中的 $\gamma,=,0.5$ 用于平衡原始注意力隐藏状态和跨帧平均隐藏状态。在我们的PLF策略中,融合权重 $\lambda_{t}$ 随着去噪过程的进行而减小,因此我们设置为 $\lambda=1-t/T_{m}$ 。所有实验均在单块A100 GPU上进行,生成16帧重光照视频的内存消耗约为23GB。
5.2. Qualitative Results
5.2. 定性结果
As shown in Fig. 5, the frame-by-frame IC-Light method ensures single-frame quality. However, the absence of consistency design and VDM temporal priors results in significant flickering of the light source and overall appearance. By introducing VDM priors, IC-Light $^+$ SDEdit0.2 maintains content consistent with the source video, but still exhibits noticeable relight appearance jitter. IC-Light $^+$ SDEdit-0.6 further enhances temporal smoothness, yet object identity shifts occur. AnyV2V can transfer the appearance of the first relight frame to subsequent frames, but this type of temporal content migration method inherently performs only pixel-level migration without perceiving the given light source, leading to unreasonable changes in object illumination. In contrast, Light-A-Video achieves high-quality video relighting, demonstrating strong temporal consistency and high fidelity to the light source.
如图 5 所示,逐帧 IC-Light 方法确保了单帧质量。然而,由于缺乏一致性设计和 VDM 时间先验,导致光源和整体外观出现明显的闪烁。通过引入 VDM 先验,IC-Light $^+$ SDEdit0.2 保持了与源视频内容的一致性,但仍然表现出明显的重新光照外观抖动。IC-Light $^+$ SDEdit-0.6 进一步增强了时间平滑性,但出现了物体身份偏移。AnyV2V 可以将第一帧重新光照的外观迁移到后续帧,但这种类型的时间内容迁移方法本质上只执行像素级迁移,无法感知给定的光源,导致物体光照发生不合理的变化。相比之下,Light-A-Video 实现了高质量的视频重新光照,展示了强大的时间一致性和对光源的高保真度。
5.3. Video Relighting with Background Generation
5.3 视频重光照与背景生成
As depicted in Fig. 6, Light-A-Video not only supports the direct relighting of the input source video but also accepts a video foreground sequence and a text prompt provided by users as input, generating a corresponding video background and illumination that aligned with the prompt descriptions. Specifically, we first process the input foreground sequence with IC-Light for frame-by-frame relighting, while completely noising the background to serve as the initialization video for VDM. From step $T$ to $T_{m}$ , the background is gradually denoised, leveraging VDM’s inpainting capability to generate the background. Then, from step $T_{m}$ to 0, CLA and PLF are introduced to achieve a temporally consistent relighting appearance of the video. The results in Fig. 6 demonstrate that our pipeline can achieve high-quality video relighting results with consistent background generation.
如图 6 所示,Light-A-Video 不仅支持直接对输入源视频进行重光照,还接受用户提供的视频前景序列和文本提示作为输入,生成与提示描述一致的视频背景和光照。具体来说,我们首先使用 IC-Light 对输入的前景序列进行逐帧重光照处理,同时完全噪声化背景作为 VDM 的初始化视频。从步骤 $T$ 到 $T_{m}$,背景逐渐去噪,利用 VDM 的修复能力生成背景。然后,从步骤 $T_{m}$ 到 0,引入 CLA 和 PLF 以实现视频时间一致的重光照效果。图 6 中的结果表明,我们的流程能够实现高质量的视频重光照效果,并生成一致的背景。

Figure 5. Qualitative comparison of baseline methods. Given a source video and guidance text prompt, we compare the performance of Light-A-Video with other video editing methods. VDM used: AnimateD iff (Left), CogVideoX (Right).
图 5: 基线方法的定性比较。给定源视频和引导文本提示,我们将 Light-A-Video 与其他视频编辑方法的性能进行比较。使用的 VDM:AnimateD iff(左),CogVideoX(右)。
5.4. Quantitative Evaluation
5.4. 定量评估
The quantitative comparison of our method with various baselines is presented in Tab. 1. As shown, we introduced an additional baseline SDEdit-0.6, which denoises the source video with $60%$ noise. SDEdit-0.6 results in a high temporal Clip Score demonstrating relying solely on the relight prompt is insufficient for generating videos with the corresponding lighting characteristics using VDM.
我们的方法与各种基线的定量对比见表 1。如表所示,我们引入了一个额外的基线 SDEdit-0.6,它使用 $60%$ 的噪声对源视频进行去噪。SDEdit-0.6 产生了较高的时间 Clip Score,这表明仅依赖重新光照提示不足以使用 VDM 生成具有相应光照特性的视频。
When the frame-by-frame IC-Light results are used as the initialization video and then noised, IC-Light $^+$ SDEdit0.6 exhibits an increased FID score, indicating a tradeoff with temporal stability. Similarly, IC-Light $^+$ SDEdit0.2, which incorporates $20%$ noise, maintains a high consistency in lighting effects with frame-by-frame IC-Light, but it also suffers from unacceptable temporal flickering. For AnyV2V, a temporal content migration method, the first frame’s appearance is consistent with the IC-Light results. Yet, its inability to perceive the light source, coupled with the model’s inherent quality degradation in subsequent frames, results in a low motion preservation score. In contrast, our Light-A-Video method achieves a low FID score while maintaining a high level of temporal consistency, demonstrates the effectiveness in both relighted image quality and temporal stability.
当逐帧的 IC-Light 结果用作初始化视频并进行噪化处理时,IC-Light $^+$ SDEdit0.6 的 FID 分数有所增加,表明其与时间稳定性之间存在权衡。同样,IC-Light $^+$ SDEdit0.2 引入了 $20%$ 的噪声,在光照效果上与逐帧的 IC-Light 保持高度一致,但也存在不可接受的时间闪烁问题。对于 AnyV2V 这种时间内容迁移方法,其第一帧的外观与 IC-Light 结果一致,但由于无法感知光源,加上模型在后续帧中的固有质量下降,导致其运动保持得分较低。相比之下,我们的 Light-A-Video 方法在保持高水平时间一致性的同时,实现了较低的 FID 分数,展示了在重光照图像质量和时间稳定性方面的有效性。

Figure 6. Text-conditioned video illumination modifying with background generation. Given a video foreground sequence and a text description of the target illumination, our method synthesizes suitable backgrounds and harmonious illumination.
图 6: 基于文本条件的视频光照修改与背景生成。给定视频前景序列和目标光照的文本描述,我们的方法合成了合适的背景和和谐的光照。

“a dog in the room, sunshine from window” Figure 7. Ablation Study. We present the video relighted with background generation results by removing the CLA module or the PLF strategy.
“房间里的狗,阳光从窗户照进来” 图 7: 消融研究。我们展示了通过移除 CLA 模块或 PLF 策略进行背景生成后的视频重光照结果。
Table 1. Quantitative comparison of baseline methods. The best result is highlighted in bold, while the second-best result is underlined.
| 评估指标 | (a) 图像质量 | (b) 时间一致性 |
|---|---|---|
| FID 分数 (↓) | CLIP 分数 (↑) | |
| IC-Light [63] | / | 0.9040 |
| SDEdit-0.6 [31] | 64.03 | 0.9677 |
| IC-Light + SDEdit-0.2 | 13.79 | 0.9199 |
| IC-Light + SDEdit-0.6 | 62.61 | 0.9483 |
| IC-Light + AnyV2V [26] | 32.73 | 0.9436 |
| Light-A-Video (Ours) | 29.63 | 0.9655 |
表 1. 基线方法的定量比较。最佳结果以粗体显示,次佳结果以下划线显示。
5.5. Ablation Study
5.5 消融研究
We conduct an ablation study to understand the importance of our CLA and PLF modules. As shown in Fig. 7, for the video relighting with background generation task, frame-by-frame IC-Light ensures high single-frame relighting quality but lacks temporal consistency control, leading to lighting source inconsistency and relighted appearance inconsistency. With the help of CLA, cross-frame information exchange stabilizes the generation of background lighting sources. Furthermore, by introducing VDM motion priors and using PLF’s strategy to progressively fuse relight targets into the original denoising target, Light-AVideo achieves temporally smooth relighting of the video. The overall video quality is also significantly improved with the help of VDM priors.
我们进行了一项消融研究,以了解我们的 CLA 和 PLF 模块的重要性。如图 7 所示,对于带有背景生成的视频重光照任务,逐帧的 IC-Light 确保了高单帧重光照质量,但缺乏时间一致性控制,导致光照源不一致和重光照外观不一致。在 CLA 的帮助下,跨帧信息交换稳定了背景光照源的生成。此外,通过引入 VDM 运动先验并使用 PLF 的策略逐步将重光照目标融合到原始去噪目标中,Light-AVideo 实现了视频的时间平滑重光照。在 VDM 先验的帮助下,整体视频质量也得到了显著提升。
5.6. Limitation and Future Work.
5.6. 局限性与未来工作
Despite achieving impressive results, the performance of our training-free method is limited by the capabilities of both the image-relighting model and the VDM. While Light-A-Video excels at ensuring stable lighting and temporal consistency, the CLA module, which stabilizes the background lighting, is less effective for modeling dynamic lighting changes. To address this limitation, future work will focus on developing methods that can handle dynamic lighting conditions more effectively.
尽管取得了令人瞩目的成果,但我们无需训练的方法的性能仍受到图像重光照模型和 VDM 能力的限制。虽然 Light-A-Video 在确保稳定光照和时间一致性方面表现出色,但用于稳定背景光照的 CLA 模块在建模动态光照变化方面效果较差。为了解决这一局限性,未来的工作将专注于开发能够更有效处理动态光照条件的方法。
6. Conclusion
6. 结论
In summary, our paper introduces Light-A-Video, a training-free method that leverages the capabilities of stateof-the-art image relighting models to achieve temporally consistent video relighting. By integrating the Consistent Light Attention to stabilize lighting source generation and employ the Progressive Light Fusion strategy for smooth appearance transitions. Light-A-Video significantly enhances the temporal coherence of relighted videos while preserving the high-quality relighting of images. Experiments demonstrate the effective application of advanced image-relighting techniques in both video sequence relighting and foreground relighting with background generation.
总之,我们的论文介绍了 Light-A-Video,这是一种无需训练的方法,利用最先进的图像重照明模型的能力,实现时间一致的视频重照明。通过集成 Consistent Light Attention 以稳定光源生成,并采用 Progressive Light Fusion 策略来实现平滑的外观过渡。Light-A-Video 显著增强了重照明视频的时间一致性,同时保持了图像的高质量重照明。实验证明了在视频序列重照明和前景重照明与背景生成中,先进图像重照明技术的有效应用。