Quant if i cation of Biodiversity from Historical Survey Text with LLM-based Best-Worst Scaling
基于大语言模型最佳-最差缩放的历史调查文本生物多样性量化
Thomas Haider, Tobias Perschl, Malte Rehbein
Thomas Haider, Tobias Perschl, Malte Rehbein
Chair of Computational Humanities University of Passau firstname.lastname@uni-passau.de
帕绍大学计算人文学科主席 firstname.lastname@uni-passau.de
Abstract
摘要
In this study, we evaluate methods to determine the frequency of species via quantity estimation from historical survey text. To that end, we formulate classification tasks and finally show that this problem can be adequately framed as a regression task using Best-Worst Scaling (BWS) with Large Language Models (LLMs). We test Ministral-8B, DeepSeek-V3, and GPT-4, finding that the latter two have reasonable agreement with humans and each other. We conclude that this approach is more cost-effective and similarly robust compared to a fine-grained multi-class approach, allowing automated quantity estimation across species.
在本研究中,我们评估了通过历史调查文本中的数量估计来确定物种频率的方法。为此,我们制定了分类任务,并最终证明使用最佳-最差缩放(Best-Worst Scaling, BWS)和大语言模型(Large Language Models, LLMs)将这一问题作为回归任务来处理是合适的。我们测试了Ministral-8B、DeepSeek-V3和GPT-4,发现后两者与人类及彼此之间存在合理的吻合度。我们得出结论,与细粒度的多类方法相比,这种方法更具成本效益且同样稳健,能够实现跨物种的自动化数量估计。
1 Introduction
1 引言
Long-term observation data plays a vital role in shaping policies for preventing biodiversity loss caused by habitat destruction, climate change, pollution, or resource over exploitation (Dornelas et al., 2013; Hoque and Sultana, 2024). However, these efforts depend on the availability of reliable and relevant historical data and robust analytical methods, a significant challenge due to the heterogeneity of records representing such data.
长期观测数据在制定防止由栖息地破坏、气候变化、污染或资源过度开发导致的生物多样性丧失政策中起着至关重要的作用 (Dornelas et al., 2013; Hoque and Sultana, 2024)。然而,这些努力依赖于可靠且相关的历史数据的可用性以及强大的分析方法,由于代表此类数据的记录异质性,这是一个重大挑战。
The available biodiversity data varies widely in resolution, ranging from detailed records (e.g., point occurrences, trait measurements) to aggregated compilations (e.g., Floras, taxonomic monographs) (Ko¨nig et al., 2019). Many projects, such as the Global Biodiversity Information Facility (GBIF), focus largely on the d is aggregated end of the spectrum, particularly with presence/absence data (Dorazio et al., 2011; Iknayan et al., 2014). Furthermore, despite their utility, longitudinal data is largely confined to records from after 1970 (van Goethem and van Zanden, 2021), leaving significant historical gaps.
可用的生物多样性数据在分辨率上差异很大,从详细记录(例如,点分布、性状测量)到聚合汇编(例如,植物志、分类学专著)都有 (Ko¨nig et al., 2019)。许多项目,如全球生物多样性信息设施 (GBIF),主要集中在聚合端,特别是存在/缺失数据 (Dorazio et al., 2011; Iknayan et al., 2014)。此外,尽管纵向数据有其用途,但主要集中在1970年以后的记录 (van Goethem and van Zanden, 2021),留下了显著的历史空白。
Natural history collections and records from the archives of societies present valuable opportunities to extend data further back in time (Johnson et al., 2011; Bro¨nnimann et al., 2018). Such sources are rich, but typically unstructured and require sophisticated extraction tools to produce meaningful quantitative information. Recent advances in NLP have shown promising potential for retrieval-based biodiversity detection from (mostly scientific) literature (Kommineni et al., 2024; Langer et al., 2024; Lu¨cking et al., 2022).
自然历史馆藏和档案中的记录为我们提供了将数据回溯到更早时期的宝贵机会(Johnson 等, 2011;Brönnimann 等, 2018)。这些资源丰富,但通常是非结构化的,需要复杂的提取工具来生成有意义的定量信息。近年来,NLP(自然语言处理)的进展在从(主要是科学)文献中提取基于检索的生物多样性检测方面显示出巨大潜力(Kommineni 等, 2024;Langer 等, 2024;Lücking 等, 2022)。
This paper focuses on evaluating methods for biodiversity quant if i cation from semi-structured historical survey texts. To achieve this, we test tasks to distill meaningful metrics from textual information found in survey records. A particular focus lies on the feasibility of Best-Worst Scaling (BWS) with a Large Language Model (LLM) as an annotator, which promises greater efficiency and cost-effectiveness compared to manual annotation (Bagdon et al., 2024). In the following, we describe the data, outline the tasks and machine learning methods, and finally present a case study.
本文重点评估从半结构化历史调查文本中量化生物多样性的方法。为此,我们测试了从调查记录中的文本信息中提取有意义指标的任务。特别关注了使用大语言模型 (LLM) 作为标注者进行最佳-最差尺度 (BWS) 的可行性,与手动标注相比,该方法有望提高效率和成本效益 (Bagdon 等, 2024)。接下来,我们将描述数据,概述任务和机器学习方法,并最终呈现一个案例研究。
2 Data
2 数据
In 1845, the Bavarian Ministry of Finance issued a survey to evaluate biodiversity in the Bavarian Kingdom, a region that encompasses a variety of different ecosystems and landscapes. To that end, 119 forestry offices were contacted to complete a standardized questionnaire. Namely, trained local foresters recorded in free text how frequently 44 selected vertebrate species occurred in the respective administrative territory, and in which habitats and locations they could be found.
1845年,巴伐利亚财政部发起了一项调查,旨在评估巴伐利亚王国这一涵盖多种不同生态系统和景观的地区的生物多样性。为此,119个林业办公室被联系以完成一份标准化问卷。具体而言,经过培训的当地林务员以自由文本的形式记录了44种选定的脊椎动物在各自行政区域内出现的频率,以及它们所在的栖息地和位置。
Figure 1 shows the facsimile of a digitized survey page. It features a header containing instructions and a number of records describing animal species with their respective responses. These historical survey documents are preserved by the Bavarian State Archives (cf. Rehbein et al., 2024).
图 1: 显示了一张数字化调查页的传真。它包括一个包含说明的标题和一系列描述动物物种及其相应反应的记录。这些历史调查文件由巴伐利亚州立档案馆保存 (参见 Rehbein 等人, 2024)。
Table 1: Data Examples with Annotation (our own translations)
表 1: 带注释的数据示例(我们自己的翻译)
| 动物 | 文本 | 二元分类 | BWS | 多分类 | |
|---|---|---|---|---|---|
| 鸭子 | BedeckenIsar-Strom, wie Amper und Moosach in ganzen Schwarmen. Cover Isar-stream, likewise Amper and Moosach in whole swarms. | 1 | 1.00 | 5 | 丰富 |
| 狍子 | Ist hier zu Hause, und beinahe in allen Waldtheilen zu finden. Is at home here and can be found in almost all parts of the forest. | 1 | 0.88 | 4 | 常见 |
| 欧洲蝰蛇 | Kommt wohl aber eben nicht haufig vor. Does indeed appear but just not that often. | 1 | 0.44 | 3 | 常见至稀有 |
| 猞猁 | Hochst selten wechselnderlei Thiere von Tyrol heriber. Very rarely do such animals cross over from Tyrol. | 1 | 0.12 | 2 | 稀有 |
| 野鹅 | Kommt nur auBerst selten zur Winterszeit vor. Occurs only very rarely at winter time. | 1 | 0.06 | 1 | 非常稀有 |
| 猫头鹰 | Horstet da hier nicht und verstreicht sich auch nicht in diese Gegend. Does not nest there and does not stray into this area. | 0 | 0.00 | 0 | 不存在 |
| 狼 | Kommt nicht mehr vor. No longer occurs. | 0 | 0.00 | -1 | 灭绝 |
The archival sources were digitized, transcribed from the handwritten original and enriched with metadata, including, among others, taxonomic norm data according to the GBIF-database1 (Telenius, 2011) and geographical references to forestry offices. This data set is freely available on Zenodo (Rehbein et al., 2024).
档案资料被数字化,从手写原件转录,并丰富了元数据,包括但不限于根据GBIF数据库的标准化分类数据(Telenius, 2011)以及林业办公室的地理参考。该数据集在Zenodo上免费提供(Rehbein等, 2024)。

Figure 1: Facsimile of a survey page, Freysing forestry office in the Upper Bavaria district.
图 1: 上巴伐利亚地区弗赖辛林业办公室的调查页面传真。
In total, the data set contains 5,467 entries2 among which are also a number of empty (striked out) or ‘see above’-type responses. The unique set we used for our experiments contains 2,555 texts. We find that the foresters’ replies vary considerably in length where most texts contain 3 to 10 tokens and only a few texts more than 20 tokens. Table 1 provides examples with annotation according to the tasks detailed in the next section.
该数据集总共包含 5,467 个条目,其中还有一些空白(划掉)或“见上文”类型的回复。我们用于实验的唯一集合包含 2,555 条文本。我们发现,护林员的回复长度差异很大,大多数文本包含 3 到 10 个 Token,只有少数文本超过 20 个 Token。表 1 提供了根据下一节详述的任务进行标注的示例。
3 Tasks & Experiments
3 任务与实验
The main task in this paper is to assign a quantity label to a text, indicating the frequency with which an animal species occurs in a specific area. This can be operational i zed in various ways, either through a classification task or through regression. In both, it can be as difficult to obtain consistent labels by asking humans to assign a value from a rating scale (Schuman and Presser, 1996; Likert, 1932). Likewise, it is also difficult for researchers to design rating scales, considering design decisions such as scale point descriptions or granularity may bias the annotators.
本文的主要任务是为文本分配一个数量标签,表示某种动物在特定区域的出现频率。这可以通过不同方式实现,既可以是分类任务,也可以是回归任务。在这两种情况下,通过让人类从评分量表中选择一个值来获得一致的标签可能都很困难 (Schuman and Presser, 1996; Likert, 1932)。同样,研究人员设计评分量表也很困难,因为设计决策(如刻度点描述或粒度)可能会对标注者产生偏差。
We evaluate three different task setups,3 as detailed in Table 1: Binary ’Presence vs. Absence’ Classification, a 7-ary Multi-Class setup (Abundant to Extinct), and continuous values scaled to [0, 1]. For the first two tasks, we use manual annotation, while continuous values are derived through BWS with LLMs (Bagdon et al., 2024).
我们评估了三种不同的任务设置,详见表 1:二元分类(存在 vs 不存在)、七元多类分类(丰富到灭绝)、以及缩放到 [0, 1] 的连续值。对于前两项任务,我们使用手动标注,而连续值则通过大语言模型 (LLMs) 的最佳-最差缩放法 (BWS) 得出(Bagdon et al., 2024)。
3.1 Binary Classification
3.1 二分类
The simplest form of animal occurrence quantification is a binary distinction between the absence (0) or presence (1) of a given species, an anno- tation scheme as popular as it is problematic in biodiversity estimation.4 In our annotation, the label PRESENT is given when a species is described in the historical dataset as having been observed in that particular locality at the time of the survey (thus excluding mentions of past occurrences, i.e., extinctions). The annotation workflow consists of iterative steps with discussions. Agreement is nearly perfect. Overall, from the set of 2,555 unique texts, 1,992 $(78%)$ fall into class PRESENT, 563 $(22%)$ into ABSENT.5
最简单的动物出现量化形式是对给定物种的缺失(0)或存在(1)进行二元区分,这种注释方案在生物多样性估计中既流行又存在问题。在我们的注释中,当历史数据集中描述某个物种在调查时在该特定地点被观察到时,给出标签“存在”(因此不包括过去发生的情况,即灭绝)。注释工作流程包括迭代步骤和讨论。一致性几乎完美。总体而言,在2555个独特文本集中,1992个(78%)属于“存在”类,563个(22%)属于“缺失”类。
To test the feasibility of the binary task, we create training curves with different models, namely BERT against Logistic Regression, SVM, and Random Forest on Unigrams. We use $20%$ of the data for testing, and take another $20%$ from the training set for hyper parameter search at each cumulative 100 text increment. Despite the $78%$ majority baseline, we find that the models perform well and training requires only a few hundred texts to reach an F1-macro score in the high 90s.
为了测试二元任务的可行性,我们使用不同的模型创建了训练曲线,即 BERT 与基于单字的 Logistic Regression(逻辑回归)、SVM(支持向量机)和 Random Forest(随机森林)进行对比。我们使用 20% 的数据进行测试,并在每次累积增加 100 个文本时,从训练集中再取 20% 进行超参数搜索。尽管存在 78% 的多数类基线,我们发现这些模型表现良好,仅需几百个文本即可达到高 90 分段的 F1-macro 值。
Figure 2: Training Curves of different models on incremental training data (binary classification)
图 2: 不同模型在增量训练数据上的训练曲线 (二分类)
Upon feature weight interpretation of the Logistic Regression and LIME on BERT (Ribeiro et al., 2016), we find that there is some bias in the data: Classification decisions occur on tokens that are not explicit quantifiers and easily substitutable without changing the classification result (e.g., common toponyms such as ‘Danube’). This presents a case of spurious correlations—an interesting future research direction, but a matching (Wang and Culotta, 2020) or counter factual approach (Qian et al., 2021) appears challenging for this heterogeneous data. Yet, we annotate the best features with regard to their ‘spuriousness’ and find that class if i ers are still robust without spurious features. This annotation also gives us a list of quantifiers which we utilize for transfer learning of a regression model (section 3.3).
在Logistic Regression和LIME对BERT的特征权重解释中(Ribeiro等,2016),我们发现数据存在一些偏差:分类决策发生在那些并非显式量词且在不改变分类结果的情况下容易替换的Token上(例如,常见的专有名词如‘Danube’)。这呈现了一种虚假相关性——一个有趣的未来研究方向,但对于这种异构数据,匹配方法(Wang和Culotta,2020)或反事实方法(Qian等,2021)似乎具有挑战性。然而,我们为最佳特征标注了它们的“虚假性”,发现即使没有这些虚假特征,分类器仍然具有鲁棒性。这一标注还为我们提供了一个量词列表,我们将其用于回归模型的迁移学习(第3.3节)。

Table 2: Multi-class model performance.
表 2: 多分类模型性能。
A second person annotates a random sample of 100 texts, resulting in a Cohen’s $\kappa$ of 0.78, indicating high agreement.
第二个人对100份文本的随机样本进行注释,得到的Cohen’s $\kappa$ 为0.78,表明高度一致性。
We then train a few models with a 5-fold cross validation, and find that the language agnostic sentence encoder model LaBSE (Feng et al., 2022) performs better than monolingual BERT-models and a Logistic Regression. We also test a zero shot classification with GPT-4 and Deepseek-V3. See appendix for the prompt.
然后,我们使用 5 折交叉验证训练了几个模型,发现语言无关的句子编码模型 LaBSE (Feng et al., 2022) 比单语 BERT 模型和逻辑回归表现更好。我们还测试了 GPT-4 和 Deepseek-V3 的零样本分类。请参阅附录以获取提示。
3.3 Continuous Quant if i cation
3.3 连续量化
| Model | F1Micro | F1Macro |
|---|---|---|
| LogisticRegression | 0.69 | 0.61 |
| gbert-base | 0.63 | 0.51 |
| bert-base-german | 0.73 | 0.63 |
| LaBSE | 0.77 | 0.68 |
| GPT4ZeroShot | 0.70 | 0.56 |
| DsV3ZeroShot | 0.66 | 0.66 |
As seen in Table 2, this task is generally quite challenging. We find that the main problem is posed by the underrepresented classes, as shown by the discrepancy between micro and macro scores, indicating that more data would help, which is, however, expensive to obtain. Zero shot classification with GPT-4 in turn is biased towards the RARE classes, such that COMMON categories are harder to predict, while DeepSeek-V3 (DSV3) shows a more balanced response.
如表 2 所示,这项任务通常具有相当大的挑战性。我们发现主要由代表性不足的类别引发的问题,这通过微观与宏观评分之间的差异得以体现,表明更多数据将有所助益,然而获取这些数据的成本很高。GPT-4 的零样本分类则偏向于 RARE(稀有)类别,使得 COMMON(常见)类别更难预测,而 DeepSeek-V3 (DSV3) 则表现出更为均衡的响应。
Finally, we experiment with operational i zing our task as a regression problem with the aim of generalizing the quant if i cation problem to less arbitrary categories and a possibly imbalanced data set (Berggren et al., 2019). While a naı¨ve labeling of quantifiers showed promising results, it is a challenge to create a comprehensive test set based on heuristic annotation. Thus, we experiment with Best-Worst Scaling, aided by LLMs.
最后,我们尝试将任务操作化为回归问题,旨在将量化问题推广到不那么任意的类别和可能存在的不平衡数据集 (Berggren et al., 2019)。虽然量词的简单标注显示出有前景的结果,但基于启发式注释创建全面的测试集仍然是一个挑战。因此,我们在大语言模型的辅助下尝试了最佳-最差尺度法。
3.2 Multi-Classification
3.2 多分类
Since the quant if i cation of species frequency in practice exceeds the binary differentiation between presence and absence of animals, a multiclass approach provides more details. We use a 7-class system, categorizing texts based on the schema as shown by the descriptors in Table 1, ranging from ABUNDANT (5) to EXTINCT (-1). We decided to annotate data of four species for our case study (section 4): Roe deer, Eurasian Otter, Eurasian Beaver, Western Cape rca ille, each within the 119 forestry offices (with one annotator).
由于物种频率的量化在实践中超出了动物存在与否的二元区分,多分类方法提供了更多细节。我们采用 7 类系统,根据表 1 中的描述符模式对文本进行分类,范围从 ABUNDANT (5) 到 EXTINCT (-1)。我们决定为案例研究(第 4 节)中的四个物种进行数据注释:狍、欧亚水獭、欧亚海狸、西开普红羚,每个物种在 119 个林业办公室内进行注释(由一位注释者完成)。
3.3.1 Best-Worst Scaling with LLMs
3.3.1 大语言模型的最佳-最差尺度法
Best-Worst Scaling (BWS) is a comparative judgment technique that helps in ranking items by identifying the best and worst elements within a set. This approach is easier to accomplish than manual labeling and there are fewer design decisions to make. In a BWS setting, the amount of annotations needed to rank a given number of text instances depends on three variables, namely 1) corpus size (total number of texts used), 2) set size (number of texts in each comparison set), and 3) number of comparison sets each text appears in.
最佳-最差缩放 (Best-Worst Scaling, BWS) 是一种通过识别一组中的最佳和最差元素来帮助对项目进行排序的比较判断技术。这种方法比手动标注更容易实现,并且需要做出的设计决策更少。在 BWS 设置中,对给定数量的文本实例进行排序所需的标注量取决于三个变量,即 1) 语料库大小 (使用的文本总数),2) 集合大小 (每个比较集中的文本数量),以及 3) 每个文本出现的比较集数量。
The number of comparisons divided by set size is regarded as the variable $N$ , where $N=2$ generally yields good results in the literature (Kiritchenko and Mohammad, 2017). A reliable set size is 4, since choosing the best and worst text instance from a 4-tuple set essentially provides the same number of comparisons as five out of six possible pairwise comparisons (ibid).
比较次数除以集合大小被视为变量 $N$,其中 $N=2$ 通常在文献中能得到良好的结果 (Kiritchenko 和 Mohammad, 2017)。可靠的集合大小为 4,因为从 4 元组集合中选择最佳和最差文本实例,实际上提供了与六种可能的两两比较中的五种相同数量的比较(同上)。
We take a random sample of 1,000 texts (excluding texts with ABSENCE annotation, thus making the task harder, but giving us a more realistic distribution). With a set size of 4 and $N=2$ , every text occurs in exactly 8 different sets and we get 2,000 comparison sets (tuples). These are then individually prompted to three LLMs: the relatively small Ministral-8B,6 OpenAI’s GPT-4 (Achiam et al., 2023), and the DeepSeek-V3 open source model (Liu et al., 2024).
我们随机抽取了1,000个文本(排除了带有ABSENCE注释的文本,使任务更具挑战性,但提供了更现实的分布)。在集合大小为4且$N=2$的情况下,每个文本恰好出现在8个不同的集合中,我们得到了2,000个比较集(元组)。这些集合随后分别被提示给三个大语言模型:相对较小的Ministral-8B,OpenAI的GPT-4 (Achiam等, 2023),以及DeepSeek-V3开源模型 (Liu等, 2024)。
| Annotatorl | Annotator2 | B | W | B +W | |
|---|---|---|---|---|---|
| LLM- | GPT4 | DeepseekV3 | 0.73 | 0.69 | 0.56 |
| LLM | Ministral8B | DeepseekV3 | 0.54 | 0.54 | 0.36 |
| GPT4 | Ministral8B | 0.57 | 0.50 | 0.38 | |
| Average | 0.61 | 0.57 | 0.43 | ||
| AR | DS | 0.56 | 0.65 | 0.45 | |
| Human- | DS | KB | 0.56 | 0.62 | 0.40 |
| Human | MR | AR | 0.51 | 0.65 | 0.39 |
| TP | AO | 0.73 | 0.55 | 0.48 | |
| MP | MR | 0.59 | 0.52 | 0.41 | |
| Average | 0.59 | 0.60 | 0.43 | ||
| LLM | AO | Ministral8B | 0.43 | 0.31 | 0.23 |
| AR | Ministral8B | 0.47 | 0.58 | 0.38 | |
| Human- | DS | Ministral8B | 0.43 | 0.42 | 0.23 |
| KB | Ministral8B | 0.53 | 0.61 | 0.46 | |
| MP | Ministral8B | 0.45 | 0.43 | 0.30 | |
| MR | Ministral8B | 0.55 | 0.48 | 0.38 | |
| TP | Ministral8B | 0.49 | 0.31 | 0.24 | |
| Average | 0.48 | 0.45 | 0.32 | ||
| AO | GPT4 | 0.68 | 0.55 | 0.45 | |
| Human- | AR | GPT4 | 0.49 | 0.57 | 0.34 |
| DS | GPT4 | 0.44 | 0.71 | 0.43 | |
| LLM | KB | GPT4 | 0.47 | 0.68 | 0.41 |
| MP | GPT4 | 0.57 | 0.62 | 0.41 | |
| MR | GPT4 | 0.49 | 0.63 | 0.41 | |
| TP | GPT4 | 0.63 | 0.57 | 0.43 | |
| Average | 0.54 | 0.62 | 0.41 | ||
| AO | DeepseekV3 | 0.61 | 0.59 | 0.45 | |
| AR | DeepseekV3 | 0.55 | 0.68 | 0.41 | |
| Human- | DS | DeepseekV3 | 0.62 | 0.63 | 0.46 |
| LLM | KB | DeepseekV3 | 0.57 | 0.62 | 0.41 |
| MP | DeepseekV3 | 0.69 | 0.53 | 0.41 | |
| MR | DeepseekV3 | 0.59 | 0.68 | 0.46 | |
| TP | DeepseekV3 | 0.58 | 0.58 | 0.41 | |
| Average | 0.60 | 0.62 | 0.43 |
Table 3: Cohen’s $\kappa$ Agreement between humans and LLMs in Best-Worst-Annotation (B: Best, W: Worst, $\mathrm{B}{+}\mathrm{W}$ : Best $^+$ Worst). Two-letter short- hands for humans.
表 3: Cohen’s $\kappa$ 人类与大语言模型在最佳-最差标注中的一致性 (B: 最佳, W: 最差, $\mathrm{B}{+}\mathrm{W}$: 最佳 $^+$ 最差)。人类的两位字母缩写。
Whereas Ministral-8B is run locally, we use the OpenAI API to access GPT-4 and the fireworks.ai API endpoint for DeepSeek-V3, since the DeepSeek-web services are limited at the time of the experiment and hardware limitations hamper local deployment. Prompts are in the appendix.
虽然 Ministral-8B 在本地运行,但我们使用 OpenAI API 访问 GPT-4,并利用 fireworks.ai API 端点访问 DeepSeek-V3,因为实验时 DeepSeek-web 服务有限,且硬件限制阻碍了本地部署。提示信息详见附录。
We ask seven native German post-graduates to annotate one of two subsets of 50 tuples each with a custom browser-based annotation interface. Table 3 shows Cohen’s $\kappa$ agreement across humans and LLMs. We find that agreement among humans is largely on par with agreement between humans and the two larger LLMs, while the lower agreement between Ministral-8B and humans, as well as the other machine annotators, indicates a limited capability of this model for the task at hand. It appears that it is easier to identify the worst instance than the best, which is likely an artifact of our data. Interestingly, agreement between GPT4 and DeepSeek-V3 is the highest overall, which could lend itself either to a) the task being easier for the LLMs than for humans, or b) that the models are overall fairly similar. We find no significant difference $(p=.118)$ between GPT-4 and DeepSeek-V3 in Human-LLM comparison.
我们请七位以德语为母语的研究生使用一个基于浏览器的自定义标注工具,分别为两个包含 50 个元组的子集进行标注。表 3 展示了人类与LLM(大语言模型)之间的 Cohen $\kappa$ 一致性。我们发现,人类之间的一致性在很大程度上与人类与两个较大的LLM之间的一致性相当,而 Ministral-8B 与人类以及其他机器标注者之间的较低一致性表明该模型在当前任务上的能力有限。似乎识别最差实例比识别最佳实例更容易,这可能是我们数据的一个特征。有趣的是,GPT4 和 DeepSeek-V3 之间的一致性总体最高,这可能是由于以下两个原因:a) 该任务对LLM来说比对人更容易,或 b) 这些模型总体上非常相似。在人类与LLM的比较中,我们发现 GPT-4 和 DeepSeek-V3 之间没有显著差异 $(p=.118)$。
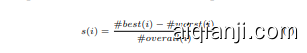
By counting how often each text was chosen as the best, worst, or as one of two other texts, we calculate a score $s(i)$ as detailed in equation (1), resulting in an interval scale $[-1,1]$ , which we normalize to a scale $[0,1]$ . This scales (and ranks) the entire dataset, so it can be used for regression. It should be noted that the scores come in increments of $\frac18$ (determined by number of comparisons of instance $i$ ), resulting in 17 discrete values. We find a flat unimodal inverted U-shape in the score distribution without notable outliers.
通过统计每个文本被选为最佳、最差或其他两个文本之一的频率,我们按照方程(1)中的详细说明计算得分$s(i)$,结果得到一个区间尺度$[-1,1]$,并将其归一化为$[0,1]$的尺度。该尺度(和排名)适用于整个数据集,因此可用于回归分析。需要注意的是,得分以$\frac18$的增量(由实例$i$的比较次数决定)出现,共有17个离散值。我们发现得分分布呈现平坦的单峰倒U形,没有显著的异常值。
3.3.2 Regression Models
3.3.2 回归模型
We train a variety of different regression models with 5-fold cross validation to optimize for the values generated by Best-Worst Scaling, as shown in Table 4. We compare a Kernel Ridge Regression (KRR) baseline against BERT-style-models with regression head, and test a transfer learning setup, for which we scale the $114\mathrm{n}$ -gram quantifiers as extracted from the binary Logistic Regression with another GPT-4 BWS, then match these scores to the texts and tune a LaBSE model on the same train/test split before using it for the final task.
我们使用5折交叉验证训练了多种不同的回归模型,以优化由Best-Worst Scaling生成的值,如表4所示。我们将核岭回归(Kernel Ridge Regression, KRR)基线模型与带有回归头的BERT风格模型进行比较,并测试了一种迁移学习设置,在该设置中,我们从二元逻辑回归中提取的$114\mathrm{n}$-gram量化器与另一个GPT-4 BWS进行缩放,然后将这些分数与文本匹配,并在相同的训练/测试集上微调LaBSE模型,最后将其用于最终任务。
Curiously, KRR with LaBSE embedding features benefits substantially from hyper parameter
有趣的是,采用 LaBSE 嵌入特征的 KRR 在超参数设置中受益匪浅
| 特征/训练策略 | 模型 | GPT4 | DSV3 | GPT4 | DSV3 |
|---|---|---|---|---|---|
| Unigrams | KRR | 0.159 | 0.158 | 0.514 | 0.515 |
| Frozen LaBSE Embeddings | KRR | 0.118 | 0.117 | 0.678 | 0.686 |
| RegressionHead | bert-base-german | 0.149 | 0.158 | 0.516 | 0.490 |
| RegressionHead | LaBSE | 0.133 | 0.127 | 0.607 | 0.657 |
| Reg. Head + Transfer | LaBSE | 0.107 | 0.117 | 0.730 | 0.710 |
Table 4: Comparison of different training strategies for regression based on BWS-Scaling. GPT4: GPT-4 BWS annotation, DSV3: Deepseek-V3 BWS annotation
表 4: 基于 BWS-Scaling 的不同训练策略比较。GPT4: GPT-4 BWS 标注, DSV3: Deepseek-V3 BWS 标注
tuning, reaching superior results over LaBSE with regression head. The Transfer Model on GPT4 BWS offers the best performance, with acceptably high explained variance $\left[R^{2}=.73\right]$ and only .11 Mean Absolute Error (MAE), which makes this model useful for downstream prediction as in the case study below. However, more data would likely also help, since training curves show continuous improvement.
微调,在带有回归头的 LaBSE 上取得了优异的结果。GPT4 BWS 上的 Transfer Model 提供了最佳性能,具有可接受的高解释方差 $\left[R^{2}=.73\right]$ 且均方误差 (MAE) 仅为 .11,这使得该模型在如下案例研究中可用于下游预测。然而,更多的数据可能也会有所帮助,因为训练曲线显示持续改进。
4 Case Study
4 案例研究
For a proof of concept, we map the predictions of the regression model (LaBSE transfer regression model based on GPT-4 BWS) to the multi-class human annotation. Figure 3 shows a strong relationship between multi-class labels and regression scores for the entire dataset (four species), but also that the extinction class is not properly represented in the regression, and furthermore that higher values are challenging to predict.
作为概念验证,我们将回归模型 (基于 GPT-4 BWS 的 LaBSE 迁移回归模型) 的预测结果映射到多类别人工标注。图 3 显示了整个数据集 (四个物种) 中多类别标签与回归分数之间的强相关性,但也表明回归模型未能正确表示灭绝类别,且较高值的预测具有挑战性。

Figure 3: Multi-Class vs. Regression Distribution
图 3: 多类别与回归分布
Figure 4 shows specie-specific distributions for Roe deer and Eurasian otter across all 119 offices, indicating a fairly good alignment between the regression result (top) and the multi-class annotation (bottom). However, the mapping is not unambiguous due to 1) shortcomings of the regression, such as the inability to model extinction and difficulty in predicting high values, and 2) imperfect alignment with class intervals, which are fuzzy with regard to the continuous values. However, pending further research, we find that our method performs well and produces plausible results.
图 4 展示了在 119 个办公室中狍和欧亚水獭的物种分布情况,表明回归结果(上方)与多类标注(下方)之间具有较好的一致性。然而,映射并不明确,原因在于:1) 回归的局限性,如无法模拟灭绝现象和难以预测高值;2) 与类别区间的对齐不完美,这些区间在连续值方面较为模糊。不过,在进一步研究之前,我们发现我们的方法表现良好,并产生了合理的结果。

Figure 4: Density histogram of regressor prediction (top) and multi-class (bottom) distribution for Roe deer (SP 0015, red) and Eurasian otter (SP 0005, grey).
图 4: 狍 (SP 0015, 红色) 和欧亚水獭 (SP 0005, 灰色) 的回归器预测密度直方图 (上) 和多类分布图 (下)。
5 Conclusion & Future Work
5 结论与未来工作
This study demonstrates that information of occurrence frequencies from semi-structured historical biodiversity survey texts can be adequately modeled with Best-Worst Scaling through LLMs. While a simple classification approach performs well with minimal training data, a more complex classification struggles with design decisions and imbalanced data. BWS meets this by eliminating rating scale design decisions. In addition, it is cognitively and computationally less expensive, since no manual annotation of training data is necessary, while still offering similarly accurate results with much finer granularity through regression.
本研究证明,通过大语言模型,可以利用最佳-最差比例缩放对半结构化历史生物多样性调查文本中的出现频率信息进行充分建模。虽然简单的分类方法在较少的训练数据下表现良好,但更复杂的分类方法却面临设计决策和数据不平衡的难题。最佳-最差比例缩放通过消除评分量表的设计决策,成功解决了这一问题。此外,它在认知和计算上成本较低,因为无需对训练数据进行手动标注,同时通过回归提供类似精度且更细粒度的结果。
The robustness of methods and models should be further tested, not exclusive to biodiversity surveys, lending itself to a number of tasks. Yet, similar data to ours likely exists, e.g., on 19th century Bavarian flora, Wu¨rttemberg is che Oberamts- be sch rei bung en (1824–1886), or data in biodiver- s it y library.org, making our methods valuable.
方法和模型的鲁棒性应进一步测试,不限于生物多样性调查,适用于多种任务。然而,类似我们的数据可能存在于其他地方,例如19世纪巴伐利亚植物志、Wu¨rttemberg的Oberamtsbeschreibungen (1824–1886),或biodiversitylibrary.org上的数据,这使得我们的方法具有重要价值。
Limitations
局限性
The accuracy of the method depends heavily on the capabilities of the specific LLM used. If a model lacks domain-specific knowledge or has biases, it may impact results. Furthermore, without a reliable dataset to benchmark against, it is difficult to assess the absolute accuracy of the BWSbased regression approach, because we also test on BWS values. While we measured agreement on the BWS task with humans, it is impractical to scale the entire dataset with both LLMs and humans, and thus our agreement calculation may suffer from sampling bias.
该方法的准确性高度依赖于所使用特定大语言模型的能力。如果模型缺乏领域特定知识或存在偏差,可能会影响结果。此外,没有可靠的数据集作为基准,很难评估基于 BWS 回归方法的绝对准确性,因为我们也在 BWS 值上进行了测试。虽然我们测量了人类在 BWS 任务上的一致性,但将整个数据集同时用大语言模型和人类进行扩展是不现实的,因此我们的一致性计算可能会受到抽样偏差的影响。
The effectiveness of the approach on different text sources or structured data remains uncertain. Differences in linguistic styles, terminologies, and data availability across domains may limit generalization. The approach assumes that frequencyrelated information in historical texts can be accurately mapped to numerical frequency estimates. If the original texts contain qualitative descriptions rather than explicit quantifiers, this may introduce errors. Also, older survey texts may reflect sampling biases, observer subjectivity, or incomplete data. If LLMs learn from these biases, the resulting quantity estimations may reinforce historical inaccuracies rather than correct them.
该方法在不同文本来源或结构化数据上的有效性仍不确定。领域间的语言风格、术语和数据可用性的差异可能会限制其泛化能力。该方法假设历史文本中的频率相关信息可以准确映射到数值频率估计。如果原始文本包含定性描述而非明确的量化词,可能会引入误差。此外,较早的调查文本可能反映了采样偏差、观察者主观性或数据不完整。如果大语言模型从这些偏差中学习,最终的量化估计可能会强化历史错误而非纠正它们。
Acknowledgements
致谢
We thank our annotators from the Journal Club, and the colleagues in the Computational Historical Ecology group at the Chair for Computational Humanities at the University of Passau for their feedback.
感谢Journal Club的标注者以及帕绍大学计算人文学系计算历史生态组的同事们的反馈。
References
参考文献
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Alten schmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774.
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, 等. 2023. GPT-4技术报告. arXiv预印本 arXiv:2303.08774.
Christopher Bagdon, Prathamesh Karmalkar, Harsha Gu ruling appa, and Roman Klinger. 2024. “you are an expert annotator”: Automatic best–worst-scaling annotations for emotion intensity modeling. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 7924–7936, Mexico City, Mexico. Association for Computational Linguistics.
Christopher Bagdon, Prathamesh Karmalkar, Harsha Gu ruling appa, 和 Roman Klinger. 2024. “你是一位专家标注者”:用于情感强度建模的自动最佳-最差缩放标注。在 2024 年北美计算语言学协会人类语言技术会议论文集(第1卷:长篇论文)中,第 7924–7936 页,墨西哥城,墨西哥。计算语言学协会。
Stig Johan Berggren, Taraka Rama, and Lilja Øvrelid. 2019. Regression or classification? automated essay scoring for Norwegian. In Proceedings of the Fourteenth Workshop on Innovative Use of NLP for Building Educational Applications, pages 92–102, Florence, Italy. Association for Computational Linguistics.
Stig Johan Berggren, Taraka Rama, 和 Lilja Øvrelid. 2019. 回归还是分类?挪威语自动作文评分。在第十四届创新使用 NLP 构建教育应用研讨会论文集,第 92-102 页,佛罗伦萨,意大利。计算语言学协会。
Stefan Bro¨nnimann, Christian Pfister, and Sam White. 2018. Archives of nature and archives of societies. In The Palgrave Handbook of Climate History, pages 27–36. Palgrave Macmillan UK, Lon- don.
Stefan Bro¨nnimann, Christian Pfister, 和 Sam White. 2018. 自然档案与社会档案. 载于《帕尔格雷夫气候史手册》, 第27-36页. 帕尔格雷夫麦克米伦英国公司, 伦敦.
Robert M Dorazio, Nicholas J Gotelli, and Aaron M Ellison. 2011. Modern methods of estimating biodiversity from presence-absence surveys. Biodiversity loss in a changing planet, pages 277–302.
Robert M Dorazio, Nicholas J Gotelli 和 Aaron M Ellison. 2011. 从存在-缺失调查中估算生物多样性的现代方法。变化行星中的生物多样性丧失,第 277–302 页。
Maria Dornelas, Anne E. Magurran, Stephen T. Buckland, Anne Chao, Robin L. Chazdon, Robert K. Colwell, Tom Curtis, Kevin J. Gaston, Nicholas J. Gotelli, Matthew A. Kosnik, Brian McGill, Jenny L. McCune, He´le`ne Morlon, Peter J. Mumby, Lise Øvrea˚s, Angelika Studeny, and Mark Vellend. 2013. Quantifying temporal change in biodiversity: challenges and opportunities. Proceedings of the Royal Society, 280.
Maria Dornelas、Anne E. Magurran、Stephen T. Buckland、Anne Chao、Robin L. Chazdon、Robert K. Colwell、Tom Curtis、Kevin J. Gaston、Nicholas J. Gotelli、Matthew A. Kosnik、Brian McGill、Jenny L. McCune、Hélène Morlon、Peter J. Mumby、Lise Øvreås、Angelika Studeny 和 Mark Vellend。2013。量化生物多样性的时间变化:挑战与机遇。英国皇家学会会刊,280。
Fangxiaoyu Feng, Yinfei Yang, Daniel Cer, Naveen Ari vaz hagan, and Wei Wang. 2022. Languageagnostic bert sentence embedding.
Fangxiaoyu Feng, Yinfei Yang, Daniel Cer, Naveen Arivazhagan, and Wei Wang. 2022. 语言无关的BERT句子嵌入。
Thomas van Goethem and Jan Luiten van Zanden. 2021. Biodiversity trends in a historical perspec- tive. In How Was Life? Volume II: New Perspectives on Well-being and Global Inequality since 1820. Organisation for Economic Co-Operation and Development (OECD).
Thomas van Goethem 和 Jan Luiten van Zanden. 2021. 历史视角下的生物多样性趋势。载于《生活如何?第二卷:1820年以来福祉与全球不平等的新视角》。经济合作与发展组织 (OECD)。
Sk Rezaul Hoque and Sk Rima Sultana. 2024. Addressing global environmental problems: Challenges, solutions, and opportunities. The Social Science Review: A Multidisciplinary Journal, 2(2):124–130.
Sk Rezaul Hoque 和 Sk Rima Sultana. 2024. 解决全球环境问题:挑战、解决方案与机遇. 社会科学评论:多学科期刊, 2(2):124–130.
Kelly J Iknayan, Morgan W Tingley, Brett J Furnas, and Steven R Beissinger. 2014. Detecting diversity: emerging methods to estimate species diversity. Trends in ecology & evolution, 29(2):97–106.
Kelly J Iknayan、Morgan W Tingley、Brett J Furnas 和 Steven R Beissinger。2014。多样性检测:估计物种多样性的新兴方法。生态学与进化趋势,29(2):97–106。
Kenneth G Johnson, Stephen J Brooks, Phillip B Fenberg, Adrian G Glover, Karen E James, Adrian M Lister, Ellinor Michel, Mark Spencer, Jonathan A Todd, Eugenia Valsami-Jones, Jeremy R Young, and John R Stewart. 2011. Climate change and biosphere response: Unlocking the collections vault. Bioscience, 61(2):147–153.
Kenneth G Johnson、Stephen J Brooks、Phillip B Fenberg、Adrian G Glover、Karen E James、Adrian M Lister、Ellinor Michel、Mark Spencer、Jonathan A Todd、Eugenia Valsami-Jones、Jeremy R Young 和 John R Stewart。2011。气候变化与生物圈响应:解锁收藏宝库。《生物科学》(Bioscience),61(2):147–153。
Mike Kestemont, Folgert Karsdorp, Elisabeth de Bruijn, Matthew Driscoll, Katarzyna A Kapitan, Pa´draig O´ Macha´in, Daniel Sawyer, Remco Sleiderink, and Anne Chao. 2022. Forgotten books: The application of unseen species models to the survival of culture. Science, 375(6582):765–769.
Mike Kestemont, Folgert Karsdorp, Elisabeth de Bruijn, Matthew Driscoll, Katarzyna A Kapitan, Pa´draig O´ Macha´in, Daniel Sawyer, Remco Sleiderink, 和 Anne Chao. 2022. 被遗忘的书籍:未见过物种模型在文化生存中的应用。科学, 375(6582):765–769.
Howard Schuman and Stanley Presser. 1996. Questions and answers in attitude surveys: Experiments on question form, wording, and context. Sage.
Howard Schuman and Stanley Presser. 1996. 态度调查中的问题与答案:关于问题形式、措辞和背景的实验. Sage.
Anders Telenius. 2011. Biodiversity information goes public: Gbif at your service. Nordic Journal of Botany, 29(3):378–381.
Anders Telenius. 2011. 生物多样性信息走向公众:GBIF 为您服务。Nordic Journal of Botany, 29(3):378–381.
Zhao Wang and Aron Culotta. 2020. Identifying spurious correlations for robust text classification. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 3431–3440, Online. Association for Computational Linguistics.
Zhao Wang 和 Aron Culotta. 2020. 识别虚假相关性以增强文本分类的鲁棒性. 载于《计算语言学协会2020年EMNLP会议论文集》, 第3431–3440页, 在线. 计算语言学协会.
Wu¨rttemberg is che Ober amt s be sch rei bung en. 1824– 1886. Wikisource. Accessed: 30 Jan. 2025.
Wu¨rttemberg 的 Ober amt 描述。1824–1886。维基文库。访问日期:2025年1月30日。
APPENDIX: PROMPTS
附录:提示词
Multi-Classification Prompt
多分类提示
System-prompt: You are a German native expert in text classification. Use the provided classification scheme to classify German texts based on species frequency descriptions.
系统提示:你是一位德语母语的文本分类专家。根据提供的分类方案,基于物种频率描述对德语文本进行分类。
Best-Worst Scaling Prompt
Best-Worst Scaling Prompt
System-prompt: You are an expert annotator specializing in Best-Worst Scaling of German texts based on quantity information about animal occurrences.
系统提示:您是专注于基于动物出现数量信息的德语文本最佳-最差量表的专家标注员。