Digital Twin Buildings: 3D Modeling, GIS Integration, and Visual Descriptions Using Gaussian Splatting, ChatGPT/Deepseek, and Google Maps Platform
数字孪生建筑:使用高斯溅射 (Gaussian Splatting)、ChatGPT/Deepseek 和 Google Maps 平台的 3D 建模、GIS 集成与可视化描述
Abstract—Urban digital twins are virtual replicas of cities that use multi-source data and data analytics to optimize urban planning, infrastructure management, and decision-making. Towards this, we propose a framework focused on the singlebuilding scale. By connecting to cloud mapping platforms such as Google Map Platforms APIs, by leveraging state-of-the-art multiagent Large Language Models data analysis using ChatGPT(4o) and Deepseek-V3/R1, and by using our Gaussian Splatting-based mesh extraction pipeline, our Digital Twin Buildings framework can retrieve a building’s 3D model, visual descriptions, and achieve cloud-based mapping integration with large language model-based data analytics using a building’s address, postal code, or geographic coordinates.
摘要:城市数字孪生 (urban digital twins) 是利用多源数据 (multi-source data) 和数据分析 (data analytics) 来优化城市规划、基础设施管理和决策的城市的虚拟复制品。为此,我们提出了一个专注于单栋建筑尺度的框架。通过连接到 Google Map Platforms API 等云地图平台,利用 ChatGPT(4o) 和 Deepseek-V3/R1 等最先进的多智能体大语言模型 (multi-agent Large Language Model) 进行数据分析,并使用基于高斯泼溅 (Gaussian Splatting) 的网格提取管道,我们的数字孪生建筑框架可以检索建筑物的 3D 模型、视觉描述,并通过建筑物的地址、邮政编码或地理坐标实现基于云的映射集成与基于大语言模型的数据分析。
Index Terms—Gaussian Splatting, ChatGPT, Deepseek, Large Language Models, Multi-Agent, AI, 3D Reconstruction, Google Maps, Remote Sensing, Urban Buildings, Urban Digital Twin
关键词—高斯溅射 (Gaussian Splatting)、ChatGPT、Deepseek、大语言模型、多智能体、AI、3D重建、Google Maps、遥感、城市建筑、城市数字孪生
I. INTRODUCTION
I. 引言
In this manuscript, we present Digital Twin Building (DTB), a framework which allows for the extraction of the 3D mesh model of a building, along with Cloud Mapping Service Integration and Multi-Agent Large Language Models (LLM) for data analysis. In the scope of this paper, we use the framework to retrieve Gaussian Splatting models and 3D mesh models. We also retrieve fundamental geocoding information, mapping information and 2D images, and perform visual analysis on the 2D images using the Multi-Agent LLM module. This is shown in Fig. 1.
在本论文中,我们提出了数字孪生建筑(Digital Twin Building, DTB)框架,该框架能够提取建筑物的3D网格模型,并结合云映射服务集成和多智能体大语言模型(LLM)进行数据分析。在本文的范围内,我们使用该框架来获取高斯点云模型和3D网格模型。我们还能获取基本的地理编码信息、映射信息和2D图像,并使用多智能体LLM模块对2D图像进行视觉分析。如图1所示。
Depending on need, the Google Maps Platform Integration can also retrieve local elevation maps, real-time traffic data, air quality data and access other data sources and services, which can then be analyzed.
根据需求,Google Maps Platform Integration 还可以检索本地高程地图、实时交通数据、空气质量数据,并访问其他数据源和服务,以便进行分析。
Our contributions are as follows.
我们的贡献如下。
II. BACKGROUND AND RELATED WORKS
II. 背景与相关工作
A. ChatGPT/Deepseek and API
A. ChatGPT/Deepseek 和 API
Large Language Models (LLMs) are neural networks, typically Transformer-based [1], pre-trained on extensive, diverse text/image corpora, typically sourced from web crawls. These models, designed for Natural Language Processing (NLP), typically interpret text-based prompts and generate text-based outputs. Certain models, such as ”DeepseekV3/R1” and their variants [2], [3], support object character recognition (OCR, i.e., reading text from images). Models like ”ChatGPT-4o” [4] and its variants additionally support full interpretation and analysis of image content.
大语言模型 (LLMs) 是神经网络,通常基于 Transformer [1],在广泛而多样的文本/图像语料库上进行预训练,这些语料库通常来自网络爬取。这些模型专为自然语言处理 (NLP) 设计,通常解释基于文本的提示并生成基于文本的输出。某些模型,如 “DeepseekV3/R1” 及其变体 [2]、[3],支持光学字符识别 (OCR,即从图像中读取文本)。像 “ChatGPT-4o” [4] 及其变体等模型还支持对图像内容的完整解释和分析。
LLMs have achieved widespread adoption since 2023. Beyond basic image and text interpretation, these models recently exhibited expert-level problem-solving in various scientific and engineering domains [5], [6].
自 2023 年以来,大语言模型 (LLMs) 已被广泛采用。除了基本的图像和文本解释外,这些模型最近还在各种科学和工程领域展示了专家级的问题解决能力 [5]、[6]。
Due to their large size, LLMs often face hardware constraints for local deployment. While popular LLM providers such as OpenAI and Deepseek, provide web browser interfaces for their models, they also offer Application Programming Interfaces (APIs). These APIs enable client-side software or code to query LLMs hosted on OpenAI or Deepseek servers, facilitating large-scale data processing without requiring humanin-the-loop manipulations via browser interfaces. Unlike traditional local deep learning, which necessitates GPUs for both training and inference, API-based LLM querying requires minimal local hardware and can be deloyed on devices such as mobile phones.
由于大语言模型规模庞大,本地部署时经常面临硬件限制。虽然 OpenAI 和 Deepseek 等知名大语言模型提供商为其模型提供了网页浏览器界面,但它们也提供了应用程序编程接口 (API)。这些 API 使得客户端软件或代码能够查询托管在 OpenAI 或 Deepseek 服务器上的大语言模型,从而无需通过浏览器界面进行人工干预即可实现大规模数据处理。与传统的本地深度学习需要在训练和推理时使用 GPU 不同,基于 API 的大语言模型查询对本地硬件要求极低,可以部署在手机等设备上。

Fig. 1: Diagram of our Digital Twin Building framework. External modules are boxed in red. Our own tools/modules are boxed in blue. The aspects specifically presented in this paper are in dark blue. Data (both inputs and outputs) are drawn in plain text.
图1: 数字孪生建筑框架示意图。外部模块用红色框标注。我们的工具/模块用蓝色框标注。本文特别展示的方面用深蓝色标注。数据(包括输入和输出)以纯文本形式绘制。
TABLE I: TABLE OF IMPORTANT DEEPSEEK AND OPENAI LLMs
Table compiled on 2025-01-31. OpenAI models are not open-sourced, their model sizes (parameters) are estimated ( $\mathbf{B}=\mathbf{\partial}$ billions, $\mathbf{M}=$ millions). 1We did not include gpt-o1 in our experiments due to cost, but we include its specifications for comparison. *The Deepseek V3 API call input token price is discounted by $90%$ if input caching is used for repeated identical prompting.*
表 1: IMPORTANT DEEPSEEK AND OPENAI LLMs 表
| ModelName | Model 1Class | Model Type | Image Processing | Parameters | APIcallp price/1M Input Tokens (USD) | API call price/1M Output Tokens (USD) |
|---|---|---|---|---|---|---|
| chatgpt4o-latest | GPT40 | Autoregressive | Analysis | ~1000+B | 2.5 | 10 |
| gpt-4o-mini | GPT4oMini | Autoregressive | Analysis | ~10'sofB | 0.15 | 0.6 |
| deepseek-chat | DeepseekV3 | Autoregressive | OCR | 617B | 0.14×0.1 | 1.10 |
| deepseek-reasoner | Deepseek R1 (V3-base) | Reasoning | OCR | 617B | 0.14 | 2.19 |
| gpt-o11 | GPT-o1 (GPT4-base) | Reasoning | None | ~175B | 15 | 60 |
表于2025-01-31编译。OpenAI模型未开源,其模型大小(参数量)为估计值($\mathbf{B}=\mathbf{\partial}$ billions, $\mathbf{M}=$ millions)。1由于成本原因,我们没有在实验中使用gpt-o1,但包含了其规格以进行比较。*如果对重复相同的提示使用了输入缓存,Deepseek V3 API调用输入Token的价格将享受$90%$的折扣。*
B. Google Maps Platform API
B. Google Maps Platform API
Google Map Platform is a cloud-based mapping service and a part of Google Cloud. Its API allows the client device to connect to various cloud-based GIS, mapping, and remote sensing services hosted on the Google Cloud servers.
Google Map Platform 是基于云的映射服务,是 Google Cloud 的一部分。其 API 允许客户端设备连接到托管在 Google Cloud 服务器上的各种基于云的地理信息系统(GIS)、映射和遥感服务。
The services utilized in this research include remote sensing image retrieval, map retrieval, elevation data retrieval, geocoding/reverse geocoding, and building polygon retrieval. However, Google Maps Platform also offers other APIs for urban and environmental research, including real-time traffic data, solar potential data, air quality data, and plant pollen data, in addition to the full suite of commonly used Google Maps navigation and mapping tools.
本研究所使用的服务包括遥感图像检索、地图检索、高程数据检索、地理编码/反向地理编码和建筑多边形检索。然而,Google Maps Platform 还提供了其他适用于城市和环境研究的 API,除了全套常用的 Google Maps 导航和地图工具外,还包括实时交通数据、太阳能潜力数据、空气质量数据和植物花粉数据。
Although less known in the remote sensing and GIS community than its sister application Google Earth Engine, Google Map Platform has been used in a variety of GIS research including navigation, object tracking, city modeling, image and map retrieval, geospatial data analysis for commercial and industrial applications [7]–[10]. It is also used as part of many commercial software for cloud-based mapping integration.
尽管在遥感和GIS(地理信息系统)社区中不如其姊妹应用Google Earth Engine知名,Google Map Platform已被用于多种GIS研究,包括导航、物体追踪、城市建模、图像和地图检索,以及商业和工业应用中的地理空间数据分析 [7]–[10]。它也被用作许多基于云的地图集成商业软件的一部分。
C. Google Earth Studio
C. Google Earth Studio
Google Earth Studio [11] is a web-based animation tool that leverages Google Earth’s satellite imagery and 3D terrain data. The tool is especially useful for creating geospatial visualizations, as it is integrated with Google Earth’s geographic data. It allows for the retrieval of images from user-specified camera poses at user-specified locations. In this research, we use Google Earth Studio to retrieve $360~^{\circ}$ multi-view remote sensing images of a building from its address, postal code, place name, or geographic coordinates following [12], [13].
Google Earth Studio [11] 是一款基于网络的动画工具,利用了 Google Earth 的卫星图像和 3D 地形数据。该工具特别适合创建地理空间可视化,因为它集成了 Google Earth 的地理数据。它允许从用户指定的相机姿势和用户指定的位置检索图像。在本研究中,我们使用 Google Earth Studio 根据建筑地址、邮政编码、地名或地理坐标检索其 $360~^{\circ}$ 多视角遥感图像,遵循 [12]、[13] 中的方法。
III. METHOD
III. 方法
A. Gaussian Building Mesh Extraction
高斯建筑网格提取
We use the mesh extraction procedure we introduced in December 2024 [13]. For conciseness, the process is briefly described here, and is not benchmarked. We refer the readers to [13] for the original implementation details and benchmark comparisons. We also refer the readers to [14] for background and theory on Gaussian Splatting.
我们使用了2024年12月引入的网格提取流程 [13]。为简洁起见,此处简要描述该流程,且不进行基准测试。关于原始实现细节和基准比较,请读者参阅 [13]。关于高斯泼溅的背景和理论,请读者参阅 [14]。
Gaussian Building Mesh (GBM) [13] is an end-to-end 3D building mesh extraction pipeline we recently proposed, leveraging Google Earth Studio [11], Segment Anything Model2 (SAM2) [15] and Grounding DINO [16], and a modified [17] Gaussian Splatting [14] model. The pipeline enables the extraction of a 3D building mesh from inputs such as the building’s name, address, postal code, or geographical coordinates. Since the GBM uses Gaussian Splatting (GS) as its 3D representation, it also allows for the synthesis of new photo realistic 2D images of the building under different viewpoints.
高斯建筑网格 (Gaussian Building Mesh, GBM) [13] 是我们最近提出的一种端到端三维建筑网格提取流程,它利用了 Google Earth Studio [11]、Segment Anything Model2 (SAM2) [15]、Grounding DINO [16] 以及改进的高斯溅射 (Gaussian Splatting) [14] 模型。该流程能够从建筑名称、地址、邮政编码或地理坐标等输入中提取三维建筑网格。由于 GBM 使用高斯溅射 (GS) 作为其三维表示方法,它还能够合成不同视角下建筑的照片级真实感二维图像。
B. Google Maps Platform Integration
B. Google Maps Platform 集成
We use the Python client binding for Google Maps Platform Services APIs to create an integration tool to automatically retrieve the GIS and mapping information of a building. For these image analysis experiments, the data is retrieved with four API calls. The first is a Google Maps Platform Geocoding/Reverse Geocoding API call which retrieves the complete address information including geographic coordinates, entrance(s) coordinates, and building polygon mask vertex coordinates. Then, a Google Maps Platform Elevation API call is used to retrieve the ground elevation using the building’s coordinates as input. Additional API calls to other Cloud Services can also be performed at this step. Finally, two API calls are made using the Google Maps Platform Static Maps API to retrieve map(s) and satellite/aerial image(s) at the desired zoom level. This process is illustrated in Figure 2. The aerial/satellite image(s) are then used as one of the inputs to our Multi-Agent LLM Module.
我们使用Google Maps Platform Services API的Python客户端绑定创建了一个集成工具,用于自动检索建筑物的GIS和地图信息。在这些图像分析实验中,数据通过四个API调用获取。第一个调用是Google Maps Platform地理编码/反向地理编码API,用于检索包括地理坐标、入口坐标和建筑物多边形遮罩顶点坐标在内的完整地址信息。接着,使用Google Maps Platform高程API,以建筑物的坐标为输入,检索地面高程。在此步骤中还可以执行对其他云服务的额外API调用。最后,使用Google Maps Platform静态地图API进行两次API调用,以获取所需缩放级别下的地图和卫星/航拍图像。该过程如图2所示。随后,航拍/卫星图像用作我们多智能体大语言模型模块的输入之一。
Our Google Map Platform Integration can easily be modified to retrieve additional data from the cloud-based mapping service by adding parallel API calls below the Geocoding/Reverse Geocoding API call. For example, if we wish to analyze real-time traffic data, we can simply perform API calls to the Traffic API.
我们的谷歌地图平台 (Google Map Platform) 集成可以轻松修改,通过在地理编码/反向地理编码 (Geocoding/Reverse Geocoding) API 调用下方添加并行 API 调用来从基于云的地图服务中检索更多数据。例如,如果我们希望分析实时交通数据,我们可以简单地调用交通 API (Traffic API)。

Satellite image(s) Street map(s) additional data of interest
卫星图像 街道地图 相关附加数据
Fig. 2: Diagram of our Google Map Services Integration Tool.
图 2: Google 地图服务集成工具示意图。
C. Multi-Agent LLM Analysis of Multi-View/Scale Images
C. 多视图/尺度图像的多智能体大语言模型分析
The motivation of this module is to create a multi-agent LLM system to analyze the data retrieved from Google Cloud Platform Services integration. In this paper, we restrict the scope of this paper to the multi-agent content analysis of multiview/scale images.
本模块的动机是创建一个多智能体大语言模型系统,以分析从Google Cloud Platform Services集成中检索到的数据。在本文中,我们将研究范围限制在多视图/多尺度图像的多智能体内容分析上。
For this analysis, the primary goal is to retrieve and store keywords describing the architectural style, function, landscape, and architectural elements of the building using keywords. With the idea that an accurate set of keywords will allow an agent to reconstruct a text-based description of the image without actually seeing the image, we also retrieve the caption using keywords as a secondary objective. This process is illustrated in Fig. 3.
在此分析中,主要目标是通过关键词检索和存储描述建筑风格、功能、景观和建筑元素的关键词。基于一组准确的关键词可以使AI智能体在没有实际看到图像的情况下重建基于文本的图像描述的设想,我们还通过关键词检索图像标题作为次要目标。该过程如图3所示。
agent and prompt it to analyze the image and retrieve a set of keywords for each image. We then initiate two agents, one to aggregate the keywords from all the images of the building, and one to turn the aggregated keywords into a human-readable caption description.
智能体并提示其分析图像并检索每张图像的关键词。然后,我们启动两个智能体,一个用于汇总建筑所有图像的关键词,另一个将汇总的关键词转换为人类可读的描述。

From a building’s address, place name, postal code, or geographic coordinates, we retrieve multi-view off-nadir images of the building of interest using Google Earth Studio (or use the ones previously retrieved in the GBM module). We also retrieve top-down view aerial/satellite image(s) at different scales using the building using Google Map Platform Integration. For each image, we initiate a GPT4o/GPT4o-mini
从建筑物的地址、地名、邮政编码或地理坐标中,我们使用 Google Earth Studio 检索目标建筑物的多视角非天底图像(或使用之前在 GBM 模块中检索的图像)。我们还使用 Google 地图平台集成检索了建筑物在不同比例下的俯视航拍/卫星图像。对于每张图像,我们启动 GPT4o/GPT4o-mini
Fig. 3: Diagram of Multi Agent LLM processing multi-viewmulti-scale images.
图 3: 多智能体大语言模型处理多视角多尺度图像的示意图。
D. Metrics
D. 指标
Although metrics such as BLEU and CIDEr are commonly used to evaluate captioning performance, they require supervised datasets with ground truth captions. However, our images lack ground truth captions. Therefore, we use the CLIP (Contrastive Language–Image Pre training) score [18]. A CLIP-trained Transformer is used to embed both the caption and image into a shared image-language latent space. Given the text embedding of the caption, t and the image embedding of the corresponding image, i, the CLIP score is given by
尽管BLEU和CIDEr等指标常用于评估字幕生成性能,但它们需要带有真实字幕的有监督数据集。然而,我们的图像缺乏真实字幕。因此,我们使用了CLIP(对比语言-图像预训练)得分[18]。一个经过CLIP训练的Transformer被用来将字幕和图像嵌入到一个共享的图像-语言潜在空间中。给定字幕的文本嵌入t和对应图像的图像嵌入i,CLIP得分由以下公式给出:
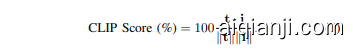
We also use perplexity to roughly assess LLM image-tokeyword extraction confidence. Perplexity is a measure of the model’s confidence in its response, and is given by
我们还使用困惑度(perplexity)来大致评估大语言模型(LLM)图像到关键词提取的置信度。困惑度是模型对其响应信心的度量,其计算公式为

where $\log{P(x_{i})}$ is the log-probability of the token $x_{i}$ as assessed by the model during text-token auto regression.
其中 $\log{P(x_{i})}$ 是模型在文本Token自回归过程中评估的Token $x_{i}$ 的对数概率。
IV. EXPERIMENTS AND DISCUSSIONS
IV. 实验与讨论
A. Experiments
A. 实验
We chose seven different buildings to test our framework. These include well-known landmarks, commercial, residential, and institutional buildings. We extract 31 multi-view images in a $360^{\circ}$ view pose around the building of interest, which we then use in conjunction with our GBM module to create the 3D colored mesh of the building. Then we subsample six images, one every $70^{\circ}$ , as inputs to the Multi-Agent LLM module. We also use the Google Map Platform integration to retrieve two aerial/satellite image(s), one at Google Maps zoom level 18, and one at Google Maps zoom level 19 as inputs to the Multi-Agent LLM module.
我们选择了七座不同的建筑来测试我们的框架。这些建筑包括知名地标、商业、住宅和机构建筑。我们提取了围绕目标建筑的 $360^{\circ}$ 视角下的 31 张多视图图像,然后将这些图像与我们的 GBM 模块结合,生成建筑的三维彩色网格。接着,我们对图像进行二次采样,每隔 $70^{\circ}$ 选取一张,共选取六张图像作为多智能体大语言模型的输入。我们还通过 Google Map Platform 集成,获取了两张航拍/卫星图像,一张在 Google Maps 的 18 级缩放,另一张在 19 级缩放,作为多智能体大语言模型的输入。
In preliminary experiments, we noticed a relatively large variation in final CLIP-score across different attempts even while using the same model and prompt, since the LLMs’ outputs are not deterministic (even when using LLM Temperature $\mathit{\Theta}=\mathit{\Theta}0_{\mathit{\Theta}_{\mathit{c}}}^{\mathit{\Theta}}$ ). As such, we perform two experiments. We want to understand the performance of the module when using different models as LLM agents, and we want to understand the distribution of scores across different attempts for both the keyword extraction step, and the captioning step.
在初步实验中,我们注意到即使使用相同的模型和提示,不同尝试之间的最终 CLIP 分数也存在较大差异,因为大语言模型的输出不具有确定性(即使使用 LLM Temperature $\mathit{\Theta}=\mathit{\Theta}0_{\mathit{\Theta}_{\mathit{c}}}^{\mathit{\Theta}}$)。因此,我们进行了两项实验。我们想了解在使用不同模型作为大语言模型智能体时该模块的性能,以及我们想了解在关键词提取步骤和字幕生成步骤中不同尝试之间的分数分布。

Fig. 4: Box plot of image-to-keyword perplexity distribution per model and level of image detail (2240 samples total).
图 4: 每个模型和图像细节级别的图像到关键词困惑度分布的箱线图(总样本数为 2240)。
- Keyword Extraction: For multi-agent image-to-keyword extraction, both chatgpt-4o-latest, and gpt-4o-mini are suitable. Additionally, both high-resolution and low-resolution image analysis are available. We test all 4 combinations for all 7 scenes, for 10 iterations, with 8 images and LLM agents, resulting in a total of 2240 API calls. We record the LLM responses and the perplexity scores. The results are shown in Fig.4.
- 关键词提取:对于多智能体图像到关键词提取任务,chatgpt-4o-latest 和 gpt-4o-mini 都适用。此外,支持高分辨率和低分辨率图像分析。我们对所有 7 个场景测试了 4 种组合,进行 10 次迭代,使用 8 张图像和大语言模型智能体,总共进行了 2240 次 API 调用。我们记录了大语言模型的响应和困惑度(perplexity)分数。结果如图 4 所示。
- Captioning: For the keyword-to-caption step, we fix the per-image keywords for each scene using the results from one of the gpt-4o high image resolution API calls. For each of the 7 buildings, we test 5 iterations of keyword-aggregation-caption for each of the four models: gpt-4o-mini, chatgpt-4o-latest, deepseek-chat, deepseek-reasoner. Each test requires two API calls, totaling 448 API calls. We additionally calculate CLIP scores for every single one of the input images. Resulting in $7\cdot5\cdot4\cdot8,=,1120$ CLIP scores. The per-model clip score distributions are visualized in Fig 5.
- 描述生成:在关键词到描述的步骤中,我们使用GPT-4O高分辨率API调用结果的每张图像关键词来固定每个场景的描述。对于7栋建筑中的每一栋,我们对四个模型(GPT-4O-mini、ChatGPT-4O-latest、Deepseek-chat、Deepseek-reasoner)各进行了5次关键词聚合描述测试。每次测试需要两次API调用,总共进行了448次API调用。此外,我们还为每张输入图像计算了CLIP分数,共得到$7\cdot5\cdot4\cdot8,=,1120$个CLIP分数。每个模型的CLIP分数分布如图5所示。
- Visualization: We present a visualization of the extracted 3D model, caption, keywords, and Google Maps Platformbased information for the Perimeter Institute (PI) building scene in Fig. 6. The Perimeter Institute for Theoretical Physics is an independent research centre located at 31 Caroline St. N, Waterloo, Ontario, Canada. We show the 3D mesh and depth maps extracted from the scene, the 2D map, and the aerial image with the building’s polygon at Google Maps zoom level 18, retrieved via the Google Maps Platform Static Maps API. We also plot the keywords extracted from a single view, as well as the caption generated by the Multi-Agent LLM module.
- 可视化:我们在图 6 中展示了Perimeter Institute (PI) 建筑场景提取的3D模型、描述、关键词以及基于Google Maps Platform的信息。Perimeter Institute for Theoretical Physics(圆周理论物理研究所)是位于加拿大安大略省滑铁卢市北卡罗琳街31号的一个独立研究中心。我们展示了从场景中提取的3D网格和深度图、2D地图,以及通过Google Maps Platform Static Maps API获取的建筑多边形的航拍图像(Google Maps缩放级别为18)。我们还绘制了从单一视角提取的关键词,以及由多智能体大语言模型模块生成的描述。
B. Discussion
B. 讨论
Fig. 4 shows the level of detail does not significantly affect the LLM agents’ confidence in their own predictions.
图 4 显示细节层次对大语言模型对自己预测的信心没有显著影响。

Fig. 5: Box plot of CLIP score distribution of building captions generated from aggregating multiple iterations of multi-view keywords and captioning (1280 samples total).
图 5: 从多视角关键词和描述的多轮迭代聚合生成的建筑物描述的 CLIP 分数分布的箱线图 (共 1280 个样本)。
Perhaps surprisingly, the much smaller gpt-4o-mini is more confident in its own responses on average. We note this does not necessarily denote keyword accuracy since it is possible the larger model considers many equivalent alternate visual descriptions, lowering its confidence in any individual description. Visual inspection of captions and images shows that across all four configurations, caption-to-image agreement is high. Although it is possible that the smaller model is enough for the visual captioning task, we nonetheless used the larger model with high visual quality for multi-view/multiscale keyword extraction to test the keyword-to-caption step.
或许令人惊讶的是,体积更小的 gpt-4o-mini 平均对其回答的置信度更高。我们注意到,这并不一定意味着关键词准确性更高,因为更大的模型可能考虑了多种等价的替代视觉描述,从而降低了对任何单个描述的置信度。对图像和描述的视觉检查表明,在所有四种配置中,描述与图像的一致性都很高。尽管较小的模型可能足以完成视觉描述任务,但我们仍使用视觉效果更好的较大模型来进行多视图/多尺度的关键词提取,以测试关键词到描述的步骤。
Deepseek-reasoner, the Deepseek-R1 model has the poorest captioning score. Additionally, this model sometimes failed at the task, shown as outliers in Fig. 5. This is perhaps because image captioning is an auto regressive text generation task and not a reasoning task. Consequently, we decided not to test OpenAI’s reasoning model, the GPT-o1. Its performance on reasoning tasks is comparable to Deepseek-R1 according to [3], yet it is more expensive by a factor of 30-100. Deepseek-chat. The Deepseek-V3 model has on average the best captioning performance, offering a very good best priceperformance ratio with performance comparable to GPT-4o, but prices similar to GPT-4o Mini (see Table I).
Deepseek-reasoner,Deepseek-R1 模型的字幕生成得分最差。此外,该模型有时在该任务上失败,如图 5 中的异常值所示。这或许是因为图像字幕生成是一项自回归文本生成任务,而非推理任务。因此,我们决定不测试 OpenAI 的推理模型 GPT-o1。根据 [3],它在推理任务上的表现与 Deepseek-R1 相当,但价格却高出 30-100 倍。Deepseek-chat。Deepseek-V3 模型在字幕生成上的平均表现最佳,提供了非常好的性价比,其性能可与 GPT-4o 相媲美,但价格与 GPT-4o Mini 相似(见表 I)。
Our future research aims to leverage the multi-agent LLM tool for geospatial data analysis, integrating various data sources from Google Cloud Platform services, including Google Maps Platform APIs and Google Earth Engine. Additionally, benchmarking the reasoning capabilities of large language models, such as GPT-o1/o3 and Deepseek-R1, for remote sensing and GIS tasks could yield valuable insights.
我们未来的研究目标是将多智能体大语言模型工具应用于地理空间数据分析,整合来自Google Cloud Platform服务的各种数据源,包括Google Maps Platform API和Google Earth Engine。此外,对GPT-o1/o3和Deepseek-R1等大语言模型在遥感和GIS任务中的推理能力进行基准测试,可能会带来有价值的见解。
V. CONCLUSION
五、结论
We have presented Digital Twin Buildings, a framework for extracting the 3D mesh of a building, for connecting the building to Google Maps Platform APIs, and for MultiAgent Large Language Models data analytics. We demonstrate this by extracting visual description keywords and captions of the building from multi-view multi-scale images of the building. The framework can also be used to process different data modalities sourced from Google Cloud Services. This approach enables richer semantic understanding, seamless integration with geospatial data, and enhanced interaction with real-world structures, paving the way for advanced applications in urban analytics, navigation, and virtual environments.
我们提出了数字孪生建筑框架,用于提取建筑的3D网格,将建筑与Google Maps Platform API连接,以及进行多智能体大语言模型数据分析。我们通过从建筑的多视角多尺度图像中提取视觉描述关键词和标题来展示这一框架。该框架还可用于处理来自Google Cloud Services的不同数据模态。该方法能实现更丰富的语义理解、与地理空间数据的无缝集成,以及增强与现实世界结构的互动,为城市分析、导航和虚拟环境中的高级应用铺平道路。

Fig. 6: Visualization of results. Top Left: colored 3D mesh; Bottom Left: depth map; Top Right: aerial image with keywords and captions and retrieved polygon mask. Bottom Right: retrieved map with map information (entrance is labelled with a red place marker).
图 6: 结果可视化。左上:彩色 3D 网格;左下:深度图;右上:带有关键词和标题的航拍图像以及检索到的多边形掩码。右下:带有地图信息的检索地图(入口用红色地点标记标注)。
REFERENCES
参考文献

Fig. A1: Average CLIP score of each building image captioning model for each different scene.
图 A1: 每个场景下各建筑图像描述模型的平均 CLIP 得分。
APPENDIX
附录
ADDITIONAL RESULTS
附加结果
The per-scene-per-model average CLIP scores are shown in Fig. A1. Deepseek-V3 achieves higher caption CLIP scores than other LLMs, except in two cases. The first is the ICON scene, which features twin high-rise buildings with retail spaces at the ground level. The second is the Parliament Hill of Canada scene overlooking the Ottawa River, characterized by its gothic-style architecture. Notably, the Parliament Hill scene also received the lowest overall CLIP scores.
每场景每模型的平均 CLIP 分数如图 A1 所示。除了两种情况外,Deepseek-V3 的标题 CLIP 分数均高于其他大语言模型。第一种情况是 ICON 场景,该场景以双子楼为特色,底层设有零售空间。第二种情况是俯瞰渥太华河的加拿大国会山场景,以其哥特式建筑风格为特色。值得注意的是,国会山场景的整体 CLIP 分数也是最低的。
INPUT IMAGES
输入图像
Input images for the Parliament Hill scene (Fig. A2) and the ICON scene (Fig. A3) are provided. These are the two scenes with the lowest multi-agent captioning CLIP scores.
议会山场景(图 A2)和 ICON 场景(图 A3)的输入图像已提供。这两个场景的多智能体描述 CLIP 得分最低。

Fig. A2: Parliament Hill of Canada input images. Top six: multi-view images (Google Earth Studio). Bottom two: multiscale images (Google Maps Platform).
图 A2: 加拿大国会山输入图像。上六张:多视角图像(Google Earth Studio)。下两张:多尺度图像(Google Maps Platform)。

Fig. A3: ICON building complex input images. Top six: multiview images (Google Earth Studio). Bottom two: multi-scale images (Google Maps Platform).
图 A3: ICON 建筑群输入图像。上部六张:多视角图像 (Google Earth Studio)。下部两张:多尺度图像 (Google Maps Platform)。