概述
基于去噪的生成模型,如扩散模型和基于流的模型,在生成高维视觉数据方面一直是可扩展的方法。最近的工作开始探索扩散模型作为表示学习器的应用;其核心思想是这些模型的隐状态可以捕获有意义、具有区分性的特征。
我们发现训练扩散模型的主要挑战在于需要学习高质量的内部表示。具体来说,我们展示了:
当扩散模型得到另一个模型(如自监督视觉编码器)提供的外部高质量表示支持时,其生成性能可以显著提升。
特别是,我们引入了表示对齐(REPA),这是一种基于近期扩散变压器架构的简单正则化技术。本质上,REPA将干净图像的预训练自监督表示蒸馏到噪声输入的扩散变压器表示中,从而更好地将扩散模型的表示与目标自监督表示对齐。


值得注意的是,模型训练变得显著更高效和有效,比基础模型的收敛速度快17.5倍以上。在最终生成质量方面,我们的方法使用分类器自由引导和引导间隔,达到了FID=1.42的最先进结果。
观察
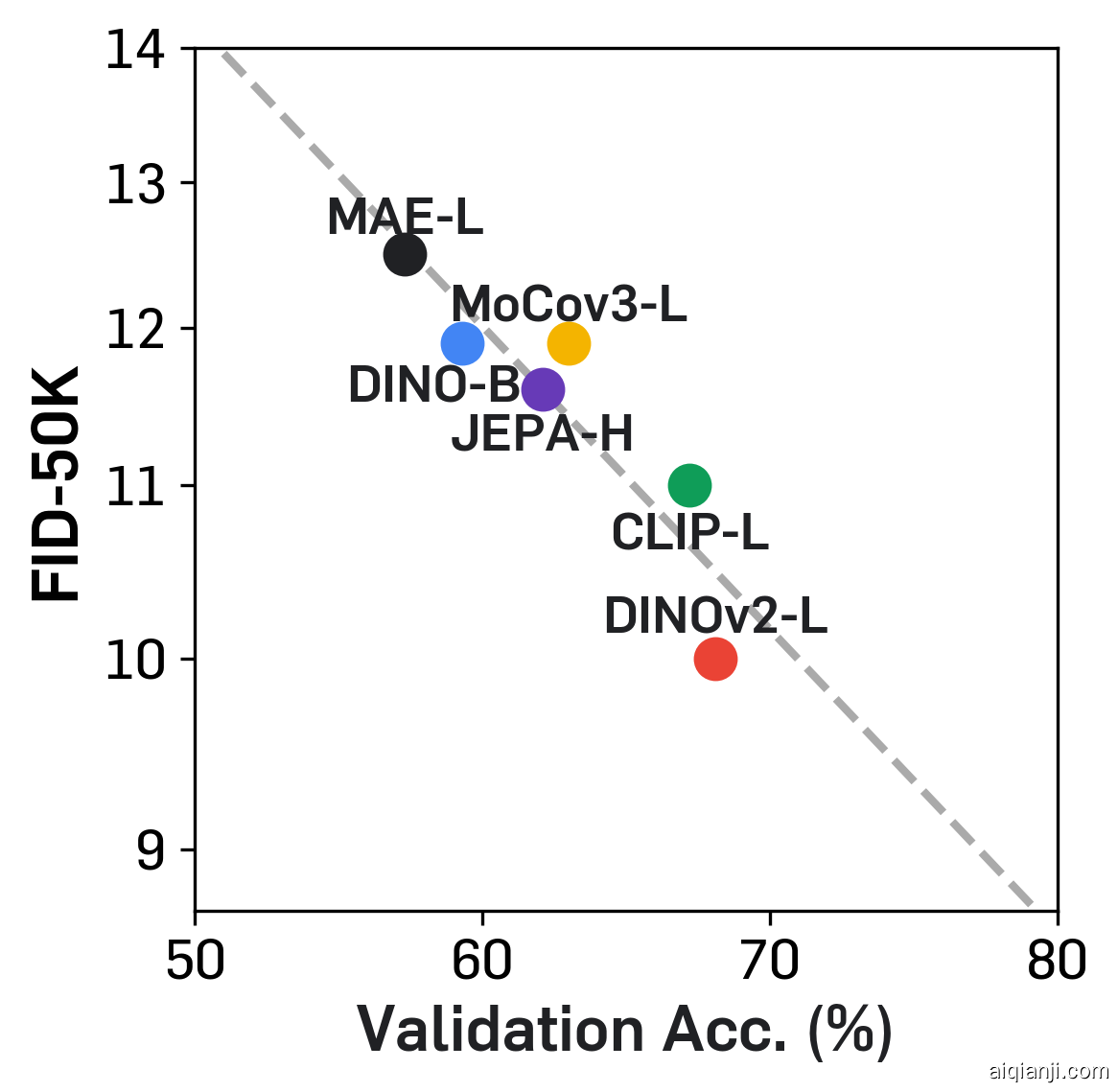
预训练SiT模型的对齐行为
我们通过实验研究了DINOv2-g和原始SiT-XL/2检查点(训练了700万次迭代)之间的特征对齐情况。类似于先前的研究,我们首先观察到预训练的扩散模型确实学习到了有意义的判别性表示。然而,这些表示远不如DINOv2产生的表示。接下来,我们发现扩散模型学习的表示与DINOv2的表示之间的对齐仍然较弱,这一点我们通过测量它们的表示对齐来研究。最后,我们观察到随着训练时间的增加和模型规模的扩大,扩散模型与DINOv2的对齐逐渐改善。



弥合表示差距
REPA减少了表示中的语义差距,并更好地将其与目标自监督表示对齐。有趣的是,通过仅对齐前几个变压器块,REPA能够实现足够的表示对齐。这反过来又允许扩散变压器的后续层专注于基于对齐表示捕捉高频细节,从而进一步提高生成性能。



结果
REPA 改进视觉缩放
我们首先比较了两个SiT-XL/2模型在前40万次迭代中生成的图像,其中一个模型应用了REPA。两个模型共享相同的噪声、采样器和采样步数,且都不使用分类器自由引导。使用REPA训练的模型显示出更好的进展。

REPA 在多个方面的可扩展性表现突出
我们还通过改变预训练编码器和扩散变压器模型的大小来考察REPA的可扩展性,结果显示,与更好的视觉表示对齐可以提高生成质量和线性探测结果。REPA在更大模型上提供了更显著的加速效果,与基础模型相比,实现了更快的FID-50K改进。此外,增加模型大小可以更快地提高生成和线性评估的表现。


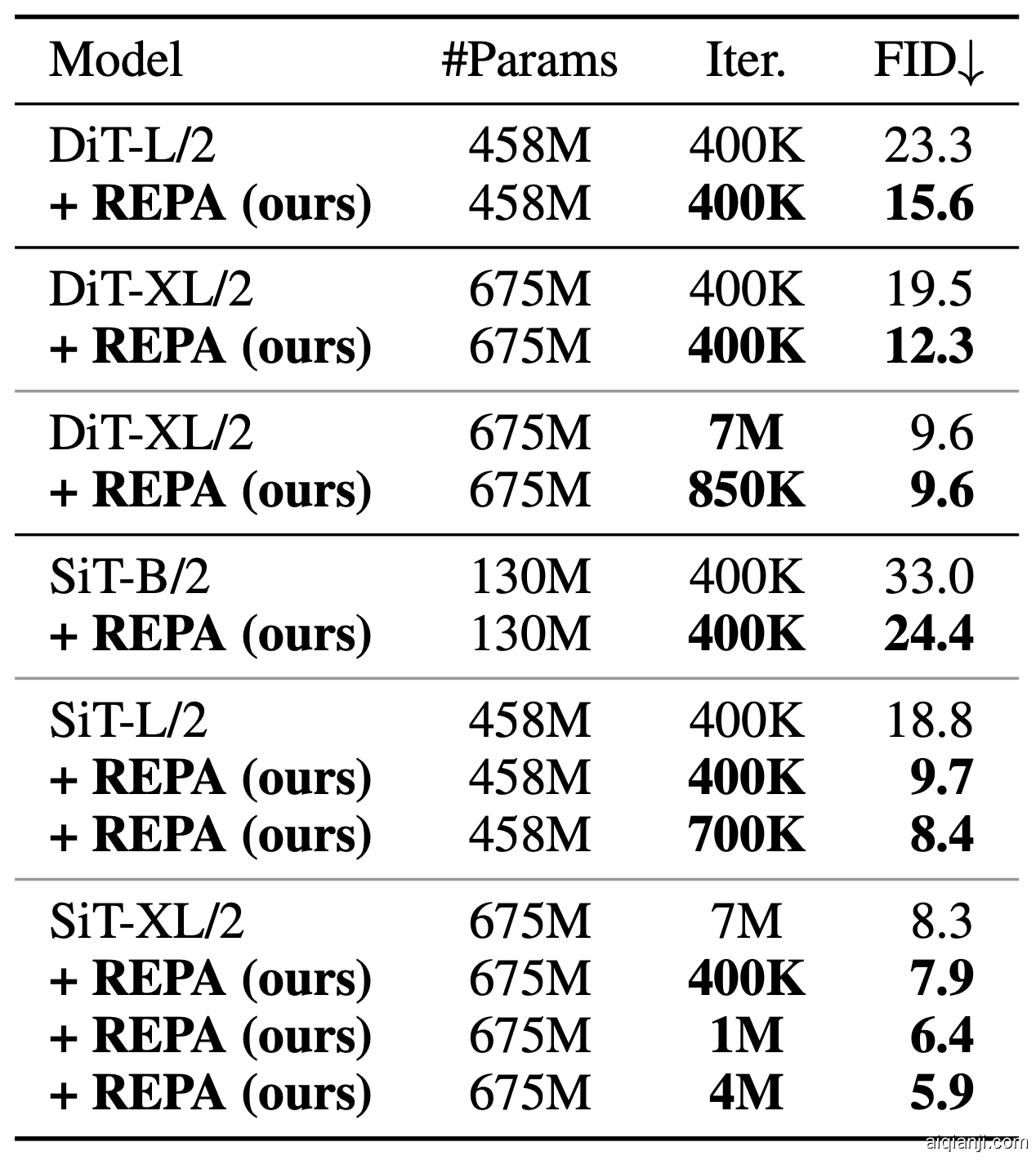
REPA 显著提高训练效率和生成质量
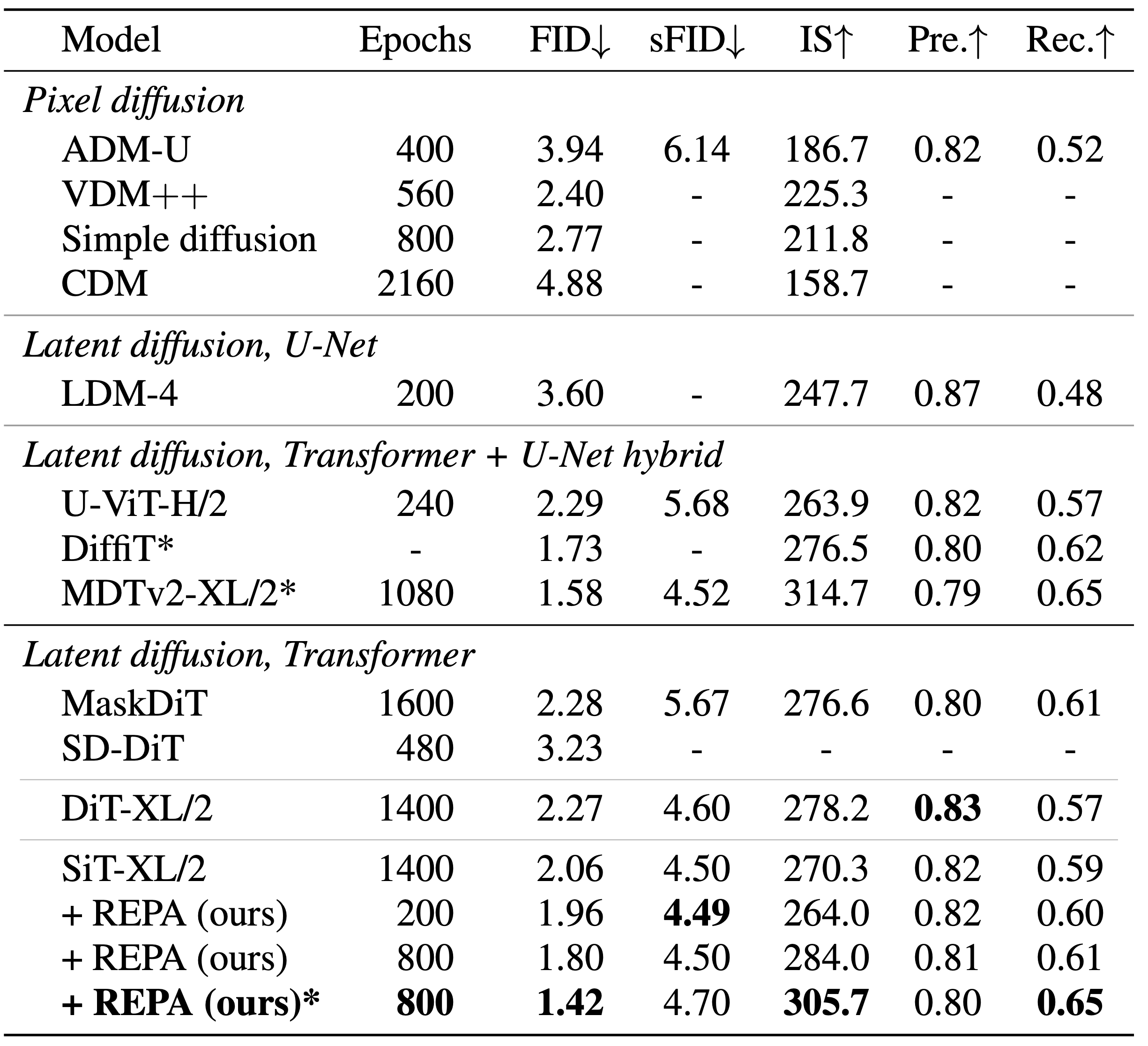
最后,我们比较了基础DiT或SiT模型与使用REPA训练模型的FID值。在不使用分类器自由引导的情况下,REPA在40万次迭代时达到FID=7.9,优于基础模型在700万次迭代时的性能。此外,使用分类器自由引导,带有REPA的SiT-XL/2在训练轮数减少7倍的情况下,仍超过了近期的扩散模型,并通过额外的引导调度达到了FID=1.42的最先进水平。
引用
@article{yu2024repa,
title={Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think},
author={Sihyun Yu and Sangkyung Kwak and Huiwon Jang and Jongheon Jeong and Jonathan Huang and Jinwoo Shin and Saining Xie},
year={2024},
journal={arXiv preprint arXiv:2410.06940},
}