
你的简单原型或临时脚本多久会变成完整的应用程序?
有机代码增长的简洁性有一面不利:变得难以维护。字典作为主要数据结构的泛滥是你的代码中技术债务的明显信号。幸运的是,现代 Python 提供了许多可行的替代方案来取代普通字典。
字典有什么问题?
字典不透明
接受字典的函数扩展和修改起来非常困难。通常,要更改接收字典的函数,你必须手动追溯调用路径回到该字典的创建点。通常存在多个调用路径,并且如果程序没有计划地增长,字典结构可能有不一致之处。
字典是可变的
为了适应特定工作流程而修改字典值是很诱人的,程序员经常滥用这种功能。原地修改可以有不同叫法:预处理、填充、充实、数据整理等。结果都是相同的。这种操作妨碍了你的数据结构,并让其依赖于你的应用程序的工作流程。
字典不仅允许你修改它们的数据,还允许你随意修改对象的结构。你可以添加或删除字段或改变类型。这样做是对你数据的最大伤害。
将字典视为线上传输格式
字典出现在代码中的常见来源是从 JSON 反序列化。例如,从第三方 API 响应中得到。
>>> requests.get("https://api.github.com/repos/imankulov/empty").json()
{'id': 297081773,
'node_id': 'MDEwOlJlcG9zaXRvcnkyOTcwODE3NzM=',
'name': 'empty',
'full_name': 'imankulov/empty',
'private': False,
...
}
API 返回的一个字典。
养成一种习惯,将字典视为“线上传输格式”并立即将其转换为提供语义的数据结构。
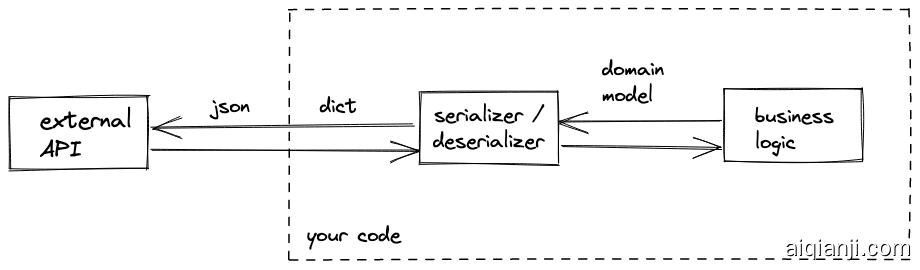
使用序列化器和反序列化器在传输格式与内部表示之间转换
实现方法很简单。
- 定义你的领域模型。领域模型仅仅是应用程序中的一个类。
- 在获取时同时进行反序列化。
在 Domain-Driven Design (领域驱动设计) 中,这种模式称为防腐层。除了提供语义清晰度外,领域模型还提供了一个自然的层次,隔离了外部架构与你应用程序的业务逻辑。
从 GitHub 检索仓库信息的两个函数实现:
返回字典
import requests
def get_repo(repo_name: str):
"""根据名称返回仓库信息。"""
return requests.get(f"https://api.github.com/repos/{repo_name}").json()
函数的输出是不透明的并且过于冗长。格式是在你的代码之外定义的。
>>> get_repo("imankulov/empty")
{'id': 297081773,
'node_id': 'MDEwOlJlcG9zaXRvcnkyOTcwODE3NzM=',
'name': 'empty',
'full_name': 'imankulov/empty',
'private': False,
# 数十行不必要的属性、URL 等。
# ...
}
返回领域模型
class GitHubRepo:
"""GitHub 仓库。"""
def __init__(self, owner: str, name: str, description: str):
self.owner = owner
self.name = name
self.description = description
def full_name(self) -> str:
"""获取仓库全名。"""
return f"{self.owner}/{self.name}"
def get_repo(repo_name: str) -> GitHubRepo:
"""根据名称返回仓库信息。"""
data = requests.get(f"https://api.github.com/repos/{repo_name}").json()
return GitHubRepo(data["owner"]["login"], data["name"], data["description"])
>>> get_repo("imankulov/empty")
<GitHubRepo at 0x103023520>
尽管下面的示例包含更多代码,但相比于前一个示例,在维护和扩展代码库时这一个更好。
让我们来看看两者之间的区别。
- 数据结构明确且我们可以详细记录它。
- 类还有一个
full_name()方法实现了一些类特定的业务逻辑。与字典不同,数据模型允许你将代码和数据一起存放。 - GitHub API 的依赖被隔离在
get_repo()函数中。GitHubRepo对象不需要知道任何关于外部 API 和对象如何创建的信息。通过这种方式,你可以独立于模型修改反序列化器或添加新方法来创建对象:如来自 pytest 固定装置,GraphQL API,本地缓存等。
☝️ 如果不需要,请忽略来自 API 的字段。仅保留你需要的字段。
在许多情况下,你可以也应该忽略来自 API 的大多数字段,仅添加应用程序使用的字段。不仅复制字段是浪费时间,还会使类结构变得僵硬,使得难以适应业务逻辑的变化或支持新版本的 API。从测试的角度来看,较少的字段意味着实例化对象时更少的麻烦。
流程化模型创建
包装字典需要创建大量类。你可以通过使用帮助你“创建更优秀类”的库简化工作。
使用 dataclasses 创建模型
自 Python 3.7 版本起,Python 提供了 数据类。
标准库中的 dataclasses 模块提供了装饰器和函数,可以自动为类添加生成的特殊方法,例如 __init__() 和 __repr__()。因此,你编写的样板代码更少。
我将 dataclasses 用于小项目或脚本,以免引入额外的依赖。 GitHubRepo 模型使用 dataclasses 将看起来如下所示。
from dataclasses import dataclass
@dataclass(frozen=True)
class GitHubRepo:
"""GitHub 仓库。"""
owner: str
name: str
description: str
def full_name(self) -> str:
"""获取仓库全名。"""
return f"{self.owner}/{self.name}"
当我创建数据类时,我的数据类几乎总是被定义为不可变的。相反,使用 dataclasses.replace() 来创建新的实例。只读属性给开发人员带来了安心感,他们在阅读和维护你的代码。
或者,使用 Pydantic 创建模型
最近,Pydantic 成为了我定义模型的首选工具,这是一个第三方数据验证库,比 dataclasses 强大得多。我特别喜欢它的序列化器和反序列化器、自动类型转换和自定义验证器。
序列化器简化了将记录存储到外部存储的过程,例如用于缓存。类型转换在将复杂的分层 JSON 转换为对象层次时特别有用。验证器对所有其他内容都有帮助。
使用 Pydantic,同样的模型可以如此定义。
from pydantic import BaseModel
class GitHubRepo(BaseModel):
"""GitHub 仓库。"""
owner: str
name: str
description: str
class Config:
frozen = True
def full_name(self) -> str:
"""获取仓库全名。"""
return f"{self.owner}/{self.name}"
在线服务 jsontopydantic.com能帮我快速从第三方 API 创建 Pydantic 模型。我在服务中输入他们的文档中的响应示例,服务便会返回 Pydantic 模型。

jsontopydantic.com 将 Todoist API 响应转换为 Pydantic 模型
在遗留代码库中标记字典为 TypeDict
Python 3.8 引入了所谓的 TypedDicts。在运行时,它们像普通的字典一样工作,但为开发者、类型验证器和集成开发环境提供额外的信息以描述其结构。
如果你遇到了大量字典的遗留代码,并且暂时无法重构所有代码,至少可以将这些字典注释为类型化的。
from typing import TypedDict
class GitHubRepo(TypedDict):
"""GitHub 仓库。"""
owner: str
name: str
description: str
repo: GitHubRepo = {
"owner": "imankulov",
"name": "empty",
"description": "An empty repository",
}
下面,我提供两张来自 PyCharm 的截图,以展示添加类型信息如何可以简化您的开发体验并防止错误。

PyCharm 知道值的类型并提供自动补全

PyCharm 知道缺少的键并发出警告
对于键值存储,请将字典注释为映射
字典的一种合法用例是键值存储,在这种存储中所有值都有相同的类型,并且通过键来查找这些值。
colors = {
"red": "#FF0000",
"pink": "#FFC0CB",
"purple": "#800080",
}
一个作为映射使用的字典。
在实例化或将此类字典传递给函数时,请考虑通过将变量类型注释为 Mapping 或 MutableMapping 来隐藏实现细节。一方面,这可能听起来像是过度设计。默认情况下字典是最常见的 MutableMapping 实现。另一方面,通过将变量注释为映射类型,您可以指定键和值的类型。此外,在 Mapping 类型的情况下,您发送了一个明确的消息,表明该对象应该是不可变的。
示例
我定义了一个颜色映射,并注释了一个函数。请注意函数是如何使用字典允许的操作但禁止 Mapping 实例使用这些操作的。
# file: colors.py
from typing import Mapping
colors: Mapping[str, str] = {
"red": "#FF0000",
"pink": "#FFC0CB",
"purple": "#800080",
}
def add_yellow(colors: Mapping[str, str]):
colors["yellow"] = "#FFFF00"
if __name__ == "__main__":
add_yellow(colors)
print(colors)
尽管类型错误,在运行时没有问题。
$ python colors.py
{'red': '#FF0000', 'pink': '#FFC0CB', 'purple': '#800080', 'yellow': '#FFFF00'}
为了验证有效性,我可以使用 mypy,它会引发一个错误。
$ mypy colors.py
colors.py:11: error: 不支持的索引赋值目标 ("Mapping[str, str]")
已找到 1 个错误(检查了 1 个源文件)
控制字典
密切关注您的字典。不要让它们控制您的应用程序。就像每种技术债务一样,您越晚引入适当的数据结构,转换就越复杂。