用150行Python代码构建全文搜索引擎
全文搜索无处不在。无论是在Scribd上找书,Netflix上找电影,亚马逊上找卫生纸,还是通过谷歌在网络上搜索任何东西(比如如何做好软件工程师的工作),你今天已经多次搜索了大量的非结构化数据。更令人惊讶的是,尽管你搜索了数百万(甚至数十亿)条记录,你仍然能在几毫秒内得到结果。在这篇文章中,我们将探索全文搜索引擎的基本组成部分,并用它们构建一个能够在几毫秒内搜索数百万文档并根据相关性进行排序的搜索引擎,代码不超过150行Python!
数据
本文中的所有代码都可以在Github上找到。我们将使用英文维基百科的文章摘要作为搜索数据,目前这是一个约785MB的gzip压缩XML文件,包含约627万条摘要1。你可以手动下载这个文件,或者使用我写的简单函数来下载。
数据准备
文件是一个包含所有摘要的大型XML文件。每个摘要由一个<doc>元素包裹,大致如下所示(我们省略了不感兴趣的元素):
<doc>
<title>Wikipedia: London Beer Flood</title>
<url>https://en.wikipedia.org/wiki/London_Beer_Flood</url>
<abstract>The London Beer Flood was an accident at Meux & Co's Horse Shoe Brewery, London, on 17 October 1814. It took place when one of the wooden vats of fermenting porter burst.</abstract>
...
</doc>
我们感兴趣的部分是title、url和abstract文本本身。我们将使用Python的dataclass来表示文档,方便数据访问。我们还会添加一个属性,将标题和摘要内容拼接在一起。代码可以在这里找到。
from dataclasses import dataclass
@dataclass
class Abstract:
"""维基百科摘要"""
ID: int
title: str
abstract: str
url: str
@property
def fulltext(self):
return ' '.join([self.title, self.abstract])
接下来,我们将从XML中提取摘要数据并解析它,以便创建Abstract对象的实例。我们将流式读取gzip压缩的XML文件,而不将整个文件加载到内存中2。我们将为每个文档分配一个ID(即第一个文档的ID=1,第二个文档的ID=2,依此类推)。代码可以在这里找到。
import gzip
from lxml import etree
from search.documents import Abstract
def load_documents():
# 打开gzip压缩的维基百科文件
with gzip.open('data/enwiki.latest-abstract.xml.gz', 'rb') as f:
doc_id = 1
# iterparse会在找到`</doc>`标签时返回整个`doc`元素
for _, element in etree.iterparse(f, events=('end',), tag='doc'):
title = element.findtext('./title')
url = element.findtext('./url')
abstract = element.findtext('./abstract')
yield Abstract(ID=doc_id, title=title, url=url, abstract=abstract)
doc_id += 1
# 显式释放元素占用的内存
element.clear()
索引
我们将把这些数据存储在一个称为“倒排索引”或“倒排列表”的数据结构中。你可以把它想象成书后的索引,其中列出了相关的单词和概念,并告诉读者在哪些页码可以找到它们。

书后索引
实际上,这意味着我们将创建一个字典,将语料库中的所有单词映射到它们出现的文档ID。看起来像这样:
{
...
"london": [5245250, 2623812, 133455, 3672401, ...],
"beer": [1921376, 4411744, 684389, 2019685, ...],
"flood": [3772355, 2895814, 3461065, 5132238, ...],
...
}
注意,字典中的单词是小写的;在构建索引之前,我们将把原始文本分解为单词或“标记”。首先,我们将文本“分词”成单词,然后对每个标记应用零个或多个“过滤器”(如小写转换或词干提取),以提高查询与文本匹配的几率。
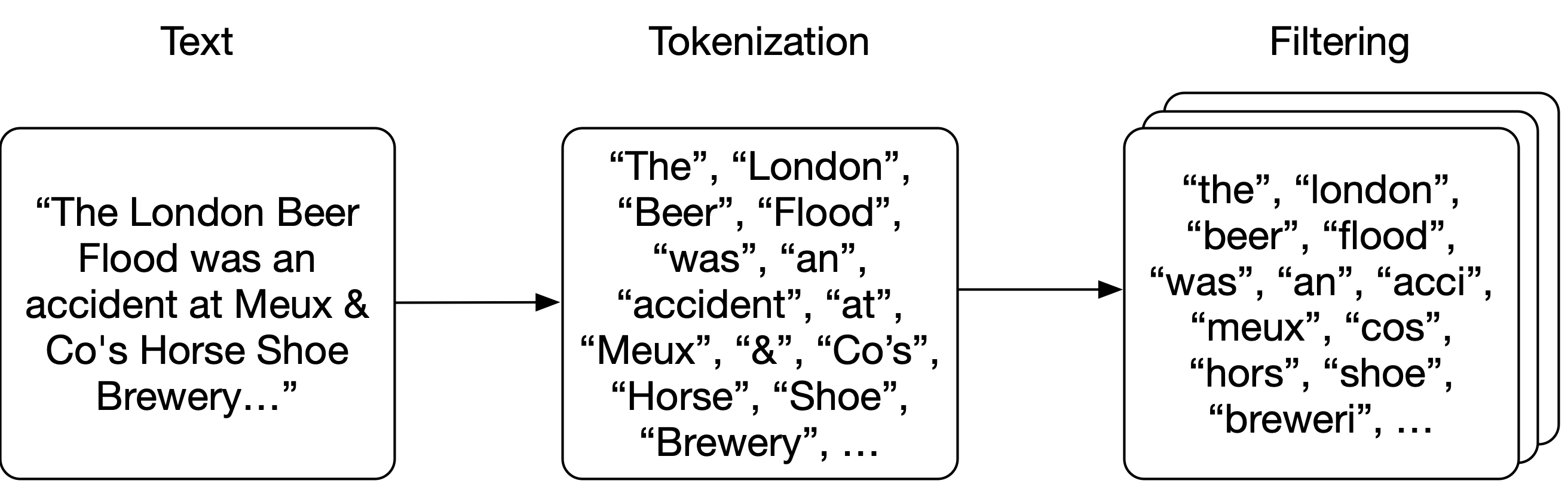
分词
分析
我们将应用非常简单的分词方法,即按空格分割文本。然后,我们将对每个标记应用几个过滤器:将每个标记转换为小写,删除任何标点符号,删除英语中最常见的25个单词(以及“wikipedia”,因为它出现在每个摘要的标题中),并对每个单词进行词干提取(确保不同形式的单词映射到相同的词干,如_brewery_和_breweries_3)。
分词和小写过滤器非常简单:
import Stemmer
STEMMER = Stemmer.Stemmer('english')
def tokenize(text):
return text.split()
def lowercase_filter(tokens):
return [token.lower() for token in tokens]
def stem_filter(tokens):
return STEMMER.stemWords(tokens)
标点符号只是一个正则表达式:
import re
import string
PUNCTUATION = re.compile('[%s]' % re.escape(string.punctuation))
def punctuation_filter(tokens):
return [PUNCTUATION.sub('', token) for token in tokens]
停用词是非常常见的单词,我们预计它们会出现在语料库中的几乎每个文档中。因此,当我们搜索这些词时,它们不会贡献太多(即几乎每个文档都会匹配),只会占用空间,所以我们将在索引时过滤掉它们。维基百科摘要语料库在每个标题中都包含“Wikipedia”这个词,所以我们也会把这个词添加到停用词列表中。我们删除了英语中最常见的25个单词。
# 英语中最常见的25个单词和“wikipedia”:
# https://en.wikipedia.org/wiki/Most_common_words_in_English
STOPWORDS = set(['the', 'be', 'to', 'of', 'and', 'a', 'in', 'that', 'have',
'I', 'it', 'for', 'not', 'on', 'with', 'he', 'as', 'you',
'do', 'at', 'this', 'but', 'his', 'by', 'from', 'wikipedia'])
def stopword_filter(tokens):
return [token for token in tokens if token not in STOPWORDS]
将这些过滤器组合在一起,我们将构建一个analyze函数,该函数将对每个摘要中的text进行操作;它将文本分词为单个单词(或更准确地说,标记),然后依次对标记列表应用每个过滤器。顺序很重要,因为我们使用的是未词干化的停用词列表,所以我们应该在stem_filter之前应用stopword_filter。
def analyze(text):
tokens = tokenize(text)
tokens = lowercase_filter(tokens)
tokens = punctuation_filter(tokens)
tokens = stopword_filter(tokens)
tokens = stem_filter(tokens)
return [token for token in tokens if token]
索引语料库
我们将创建一个Index类来存储index和documents。documents字典按ID存储数据类,index的键将是标记,值是该标记出现的文档ID:
class Index:
def __init__(self):
self.index = {}
self.documents = {}
def index_document(self, document):
if document.ID not in self.documents:
self.documents[document.ID] = document
for token in analyze(document.fulltext):
if token not in self.index:
self.index[token] = set()
self.index[token].add(document.ID)
搜索
现在我们已经索引了所有标记,搜索查询就变成了用与文档相同的分析器分析查询文本的问题;这样我们最终会得到与索引中标记匹配的标记。对于每个标记,我们将在字典中查找,找到该标记出现的文档ID。我们对每个标记都这样做,然后找到所有这些集合中文档的ID(即,文档要匹配查询,它需要包含查询中的所有标记)。然后,我们将获取生成的文档ID列表,并从documents存储中获取实际数据4。
def _results(self, analyzed_query):
return [self.index.get(token, set()) for token in analyzed_query]
def search(self, query):
"""
布尔搜索;这将返回包含查询中所有单词的文档,但不进行排序(集合很快,但无序)。
"""
analyzed_query = analyze(query)
results = self._results(analyzed_query)
documents = [self.documents[doc_id] for doc_id in set.intersection(*results)]
return documents
In [1]: index.search('London Beer Flood')
search took 0.16307830810546875 milliseconds
Out[1]:
[Abstract(ID=1501027, title='Wikipedia: Horse Shoe Brewery', abstract='The Horse Shoe Brewery was an English brewery in the City of Westminster that was established in 1764 and became a major producer of porter, from 1809 as Henry Meux & Co. It was the site of the London Beer Flood in 1814, which killed eight people after a porter vat burst.', url='https://en.wikipedia.org/wiki/Horse_Shoe_Brewery'),
Abstract(ID=1828015, title='Wikipedia: London Beer Flood', abstract="The London Beer Flood was an accident at Meux & Co's Horse Shoe Brewery, London, on 17 October 1814. It took place when one of the wooden vats of fermenting porter burst.", url='https://en.wikipedia.org/wiki/London_Beer_Flood')]
现在,这将使我们的查询非常精确,尤其是对于长查询字符串(查询中包含的标记越多,文档包含所有这些标记的可能性就越小)。我们可以通过允许用户指定只需要一个标记出现来优化搜索函数,以提高召回率而不是精确率:
def search(self, query, search_type='AND'):
"""
仍然是布尔搜索;这将返回包含查询中所有单词或仅其中一个单词的文档,具体取决于指定的search_type。
我们仍然没有对结果进行排序(集合很快,但无序)。
"""
if search_type not in ('AND', 'OR'):
return []
analyzed_query = analyze(query)
results = self._results(analyzed_query)
if search_type == 'AND':
# 所有标记必须在文档中
documents = [self.documents[doc_id] for doc_id in set.intersection(*results)]
if search_type == 'OR':
# 只需要一个标记在文档中
documents = [self.documents[doc_id] for doc_id in set.union(*results)]
return documents
In [2]: index.search('London Beer Flood', search_type='OR')
search took 0.02816295623779297 seconds
Out[2]:
[Abstract(ID=5505026, title='Wikipedia: Addie Pryor', abstract='| birth_place = London, England', url='https://en.wikipedia.org/wiki/Addie_Pryor'),
Abstract(ID=1572868, title='Wikipedia: Tim Steward', abstract='|birth_place = London, United Kingdom', url='https://en.wikipedia.org/wiki/Tim_Steward'),
Abstract(ID=5111814, title='Wikipedia: 1877 Birthday Honours', abstract='The 1877 Birthday Honours were appointments by Queen Victoria to various orders and honours to reward and highlight good works by citizens of the British Empire. The appointments were made to celebrate the official birthday of the Queen, and were published in The London Gazette on 30 May and 2 June 1877.', url='https://en.wikipedia.org/wiki/1877_Birthday_Honours'),
...
In [3]: len(index.search('London Beer Flood', search_type='OR'))
search took 0.029065370559692383 seconds
Out[3]: 49627
相关性
我们已经用一些基本的Python实现了一个相当快速的搜索引擎,但显然缺少一个方面,那就是相关性的概念。目前我们只是返回一个无序的文档列表,让用户自己去弄清楚他们真正感兴趣的是哪些。特别是对于大型结果集,这很痛苦甚至不可能(在我们的OR示例中,有近50,000个结果)。
这就是相关性概念的用武之地;如果我们能为每个文档分配一个分数,表示它与查询的匹配程度,并按该分数排序呢?一个简单的方法是为给定查询的文档分配一个分数,只需计算该文档中该单词出现的次数。毕竟,文档中提到的术语越多,它就越有可能是关于我们的查询的!
词频
让我们扩展Abstract数据类,以便在索引时计算并存储其词频。这样,当我们想要对无序的文档列表进行排序时,就可以轻松访问这些数字:
# in documents.py
from collections import Counter
from .analysis import analyze
@dataclass
class Abstract:
# snip
def analyze(self):
# Counter将创建一个字典,计算数组中的唯一值:
# {'london': 12, 'beer': 3, ...}
self.term_frequencies = Counter(analyze(self.fulltext))
def term_frequency(self, term):
return self.term_frequencies.get(term, 0)
我们需要确保在索引数据时生成这些频率计数:
# in index.py we add `document.analyze()
def index_document(self, document):
if document.ID not in self.documents:
self.documents[document.ID] = document
document.analyze()
我们将修改搜索函数,以便对结果集中的文档应用排序。我们将使用相同的布尔查询从索引和文档存储中获取文档,然后对于结果集中的每个文档,我们将简单地汇总每个术语在该文档中出现的次数。
def search(self, query, search_type='AND', rank=True):
# snip
if rank:
return self.rank(analyzed_query, documents)
return documents
def rank(self, analyzed_query, documents):
results = []
if not documents:
return results
for document in documents:
score = sum([document.term_frequency(token) for token in analyzed_query])
results.append((document, score))
return sorted(results, key=lambda doc: doc[1], reverse=True)
逆文档频率
这已经好多了,但有一些明显的缺点。我们在评估查询的相关性时,认为所有查询术语的价值是相等的。然而,某些术语在确定相关性时可能几乎没有或根本没有区分能力;例如,一个包含大量关于啤酒的文档的集合,预计“beer”这个词会出现在几乎每个文档中(事实上,我们已经通过从索引中删除25个最常见的英语单词来尝试解决这个问题)。在这种情况下搜索“beer”这个词,基本上会再次进行随机排序。
为了解决这个问题,我们将在评分算法中添加另一个组件,该组件将减少在索引中出现非常频繁的术语对最终分数的贡献。我们可以使用术语的_集合频率_(即该术语在所有文档中出现的次数),但在实践中,使用的是_文档频率_(即索引中有多少_文档_包含该术语)。毕竟,我们是在对文档进行排序,所以使用文档级别的统计是有意义的。
我们将通过将索引中的文档数量(N)除以包含该术语的文档数量,并取其对数来计算术语的_逆文档频率_。
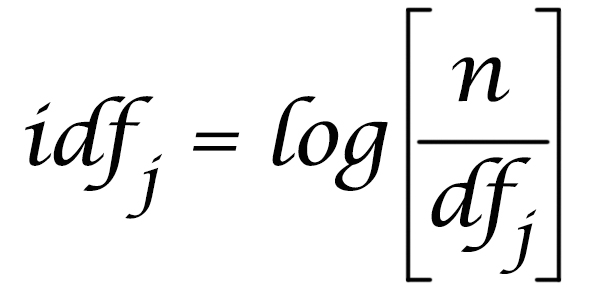
IDF;取自https://moz.com/blog/inverse-document-frequency-and-the-importance-of-uniqueness
然后,我们将在排序期间简单地将词频与逆文档频率相乘,因此对语料库中罕见的术语的匹配将对相关性分数贡献更多5。我们可以轻松地从索引中的数据计算逆文档频率:
# index.py
import math
def document_frequency(self, token):
return len(self.index.get(token, set()))
def inverse_document_frequency(self, token):
# Manning, Hinrich和Schütze使用log10,所以我们也这样做,尽管使用哪种对数并不重要
# https://nlp.stanford.edu/IR-book/html/htmledition/inverse-document-frequency-1.html
return math.log10(len(self.documents) / self.document_frequency(token))
def rank(self, analyzed_query, documents):
results = []
if not documents:
return results
for document in documents:
score = 0.0
for token in analyzed_query:
tf = document.term_frequency(token)
idf = self.inverse_document_frequency(token)
score += tf * idf
results.append((document, score))
return sorted(results, key=lambda doc: doc[1], reverse=True)
未来工作
这就是用几行Python代码构建的基本搜索引擎!你可以在Github上找到所有代码,我还提供了一个实用函数,可以下载维基百科摘要并构建索引。安装需求,在你选择的Python控制台中运行它,并享受摆弄数据结构和搜索的乐趣。
显然,这是一个说明搜索概念及其速度的项目(即使使用排序,我也可以在笔记本电脑上用“慢”语言如Python搜索和排序627万文档),而不是生产级软件。它完全在我的笔记本电脑内存中运行,而像Lucene这样的库利用超高效的数据结构,甚至优化磁盘查找,像Elasticsearch和Solr这样的软件将Lucene扩展到数百甚至数千台机器。
但这并不意味着我们不能思考这个基本功能的有趣扩展;例如,我们假设文档中的每个字段对相关性的贡献相同,而查询术语在标题中的匹配可能应该比在描述中的匹配权重更大。另一个有趣的项目可能是扩展查询解析;没有理由要求所有或仅一个术语必须匹配。为什么不排除某些术语,或在单个术语之间进行AND和OR操作?我们可以将索引持久化到磁盘并使其扩展到我的笔记本电脑RAM之外吗?
- 摘要通常是维基百科文章的第一段或前几句话。整个数据集目前约为±796MB的gzip压缩XML。如果你想自己实验和摆弄代码,有较小的子集可用;解析XML和索引需要一些时间,并且需要大量的内存。↩︎
- 我们也将整个数据集和索引放在内存中,所以我们可以跳过将原始数据保存在内存中。↩︎
- 词干提取是否是一个好主意是有争议的。它会减少索引的总大小(即更少的唯一单词),但词干提取是基于启发式的;我们正在丢弃可能非常有价值的信息。例如,考虑单词
university、universal、universities和universe,它们被词干化为univers。我们失去了区分这些单词含义的能力,这将对相关性产生负面影响。有关词干提取(和词形还原)的更详细文章,请阅读这篇优秀的文章。↩︎ - 我们显然只是使用笔记本电脑的RAM来实现这一点,但将实际数据存储在索引中是一种非常常见的做法。Elasticsearch将其数据作为普通的JSON存储在磁盘上,并且只在Lucene(底层的搜索和索引库)中存储索引数据,许多其他搜索引擎将简单地返回一个有序的文档ID列表,然后用于从数据库或其他服务中检索数据以显示给用户。这对于大型语料库尤其重要,因为对所有数据进行完全重新索引是昂贵的,通常你只想在搜索引擎中存储与相关性相关的数据(而不是仅与展示相关的属性)。↩︎
- 有关该算法的更深入文章,我推荐阅读https://monkeylearn.com/blog/what-is-tf-idf/和https://nlp.stanford.edu/IR-book/html/htmledition/term-frequency-and-weighting-1.html ↩︎