K1MI K1.5 : SCALING REINFORCEMENT LEARNING WITH LLMS
K1MI K1.5:使用大语言模型扩展强化学习
TECHNICAL REPORT OF KIMI K1.5
KIMI K1.5 技术报告
Kimi Team
Kimi 团队
ABSTRACT
摘要
Language model pre training with next token prediction has proved effective for scaling compute but is limited to the amount of available training data. Scaling reinforcement learning (RL) unlocks a new axis for the continued improvement of artificial intelligence, with the promise that large language models (LLMs) can scale their training data by learning to explore with rewards. However, prior published work has not produced competitive results. In light of this, we report on the training practice of Kimi k1.5, our latest multi-modal LLM trained with RL, including its RL training techniques, multi-modal data recipes, and infrastructure optimization. Long context scaling and improved policy optimization methods are key ingredients of our approach, which establishes a simplistic, effective RL framework without relying on more complex techniques such as Monte Carlo tree search, value functions, and process reward models. Notably, our system achieves state-of-the-art reasoning performance across multiple benchmarks and modalities—e.g., 77.5 on AIME, 96.2 on MATH 500, 94-th percentile on Codeforces, 74.9 on MathVista—matching OpenAI's o1. Moreover, we present effective long2short methods that use long-CoT techniques to improve short-CoT models, yielding state-of-the-art short-CoT reasoning results—e.g., 60.8 on AIME, 94.6 on MATH500, 47.3 on Live Code Bench—outperforming existing short-CoT models such as GPT-4o and Claude Sonnet 3.5 by a large margin (up to $+550%$
通过下一个Token预测进行语言模型预训练已被证明对计算扩展有效,但受限于可用训练数据的数量。扩展强化学习(RL)为人工智能的持续改进开辟了新维度,有望使大语言模型(LLMs)通过奖励探索来扩展其训练数据。然而,先前发表的工作尚未产生具有竞争力的结果。鉴于此,我们报告了Kimi k1.5的训练实践,这是我们最新采用RL训练的多模态大语言模型,包括其RL训练技术、多模态数据配方和基础设施优化。长上下文扩展和改进的策略优化方法是我们的关键要素,这些方法建立了一个简单有效的RL框架,无需依赖更复杂的技术,如蒙特卡罗树搜索、价值函数和过程奖励模型。值得注意的是,我们的系统在多个基准和模态上实现了最先进的推理性能——例如,AIME上77.5分,MATH 500上96.2分,Codeforces上94百分位,MathVista上74.9分——与OpenAI的o1相当。此外,我们提出了有效的长到短方法,利用长链思维(CoT)技术改进短链思维模型,取得了最先进的短链思维推理结果——例如,AIME上60.8分,MATH500上94.6分,Live Code Bench上47.3分——大幅超越现有的短链思维模型,如GPT-4o和Claude Sonnet 3.5(最高达$+550%$)。

Figure 1: Kimi k1.5 long-CoT results.
图 1: Kimi k1.5 长链推理 (long-CoT) 结果。

Figure 2: Kimi k1.5 short-CoT results.
图 2: Kimi k1.5 短链思维 (short-CoT) 结果。
1 Introduction
1 引言
Language model pre training with next token prediction has been studied under the context of the scaling law, where proportionally scaling model parameters and data sizes leads to the continued improvement of intelligence. (Kaplan et al. 2020; Hoffmann et al. 2022) However, this approach is limited to the amount of available high-quality training data (Villalobos et al. 2024; Mu en nigh off et al. 2023). In this report, we present the training recipe of Kimi $\mathrm{k}1.5$ our latest multi-modal LLM trained with reinforcement learning (RL). The goal is to explore a possible new axis for continued scaling. Using RL with LLMs, the models learns to explore with rewards and thus is not limited to a pre-existing static dataset.
语言模型通过下一个 Token 预测进行预训练的研究已经在扩展定律的背景下展开,其中按比例扩展模型参数和数据规模会持续提升智能水平 (Kaplan et al. 2020; Hoffmann et al. 2022)。然而,这种方法受限于可用高质量训练数据的数量 (Villalobos et al. 2024; Mu en nigh off et al. 2023)。在本报告中,我们介绍了 Kimi $\mathrm{k}1.5$ 的训练方法,这是我们最新的通过强化学习 (RL) 训练的多模态大语言模型。目标是探索一种可能的新扩展方向。通过将 RL 与大语言模型结合,模型学会通过奖励进行探索,从而不再局限于预先存在的静态数据集。
There are a few key ingredients about the design and training of k1.5 · Long context scaling. We scale the context window of RL to $128\mathbf{k}$ and observe continued improvement of performance with an increased context length. A key idea behind our approach is to use partial rollouts to improve training efficiency—i.e., sampling new trajectories by reusing a large chunk of previous trajectories, avoiding the cost to re-generate the new trajectories from scratch. Our observation identifies the context length as a key dimension of the continued scaling of RL with LLMs.
关于 k1.5 的设计和训练有几个关键要素:
- 长上下文扩展。我们将 RL 的上下文窗口扩展到 $128\mathbf{k}$,并观察到随着上下文长度的增加,性能持续提升。我们方法的一个关键思想是使用部分回放来提高训练效率——即通过重用大部分先前的轨迹来采样新的轨迹,从而避免从头重新生成新轨迹的成本。我们的观察表明,上下文长度是大语言模型 (LLM) 持续扩展 RL 的一个关键维度。
· Improved policy optimization. We derive a formulation of RL with long-CoT and employ a variant of online mirror descent for robust policy optimization. This algorithm is further improved by our effective sampling strategy, length penalty, and optimization of the data recipe. · Simplistic Framework. Long context scaling, combined with the improved policy optimization methods, establishes a simplistic RL framework for learning with LLMs. Since we are able to scale the context length, the learned CoTs exhibit the properties of planning, reflection, and correction. An increased context length has an effect of increasing the number of search steps. As a result, we show that strong performance can be achieved without relying on more complex techniques such as Monte Carlo tree search, value functions, and process reward models. · Multi modalities. Our model is jointly trained on text and vision data, which has the capabilities of jointly reasoning over the two modalities.
· 改进的策略优化。我们推导出了一种带有长链式思维(long-CoT)的强化学习(RL)公式,并采用了一种在线镜像下降的变体来进行鲁棒的策略优化。通过有效的采样策略、长度惩罚和数据配方的优化,该算法得到了进一步改进。
· 简洁的框架。长上下文扩展与改进的策略优化方法相结合,建立了一个简洁的强化学习框架,用于与大语言模型(LLM)一起学习。由于我们能够扩展上下文长度,学习到的链式思维表现出规划、反思和修正的特性。增加上下文长度具有增加搜索步骤数量的效果。因此,我们展示了在不依赖更复杂技术(如蒙特卡洛树搜索、价值函数和过程奖励模型)的情况下,可以实现强大的性能。
· 多模态。我们的模型在文本和视觉数据上联合训练,具备在这两种模态上进行联合推理的能力。
Our long-CoT version achieves state-of-the-art reasoning performance across multiple benchmarks and modalities- e.g.. 77.5 on AIME, 96.2 on MATH 500, 94-th percentile on Codeforces, 74.9 on MathVista-matching OpenAI's o1. Our model also achieves state-of-the-art short-CoT reasoning results-e.g., 60.8 on AIME, 94.6 on MATH500, 47.3 on Live Code Bench—-outperforming existing short-CoT models such as GPT-4o and Claude Sonnet 3.5 by a large margin (upto $+550%$ ). Results are shown in Figures 1 and 2.
我们的长链思维 (long-CoT) 版本在多个基准和模态上实现了最先进的推理性能,例如在 AIME 上达到 77.5,在 MATH 500 上达到 96.2,在 Codeforces 上达到 94 百分位,在 MathVista 上达到 74.9,与 OpenAI 的 o1 相当。我们的模型还在短链思维 (short-CoT) 推理上取得了最先进的结果,例如在 AIME 上达到 60.8,在 MATH500 上达到 94.6,在 Live Code Bench 上达到 47.3,大幅超越了现有的短链思维模型,如 GPT-4o 和 Claude Sonnet 3.5 (最高提升达 $+550%$ )。结果如图 1 和图 2 所示。
2 Approach: Reinforcement Learning with LLMs
2 方法:基于大语言模型的强化学习
The development of Kimi k1.5 consists of several stages: pre training, vanilla supervised fine-tuning (SFT), long-CoT supervised fine-turning, and reinforcement learning (RL). This report focuses on RL, beginning with an overview of the RL prompt set curation (Section 2.1) and long-CoT supervised finetuning (Section 2.2), followed by an in-depth discussion of RL training strategies in Section 2.3. Additional details on pre training and vanilla supervised finetuning can be found in Section 2.5.
Kimi k1.5 的开发包括多个阶段:预训练、基础监督微调 (SFT)、长链思维监督微调 (long-CoT) 和强化学习 (RL)。本报告重点介绍 RL,首先概述 RL 提示集整理 (第 2.1 节) 和长链思维监督微调 (第 2.2 节),然后在第 2.3 节深入讨论 RL 训练策略。关于预训练和基础监督微调的更多细节可以在第 2.5 节中找到。
2.1 RL Prompt Set Curation
2.1 RL 提示集整理
Through our preliminary experiments, we found that the quality and diversity of the RL prompt set play a critical role in ensuring the effectiveness of reinforcement learning. A well-constructed prompt set not only guides the model toward robust reasoning but also mitigates the risk of reward hacking and over fitting to superficial patterns. Specifically, three key properties define a high-quality RL prompt set:
通过我们的初步实验,我们发现 RL 提示集的质量和多样性在确保强化学习效果方面起着关键作用。一个构建良好的提示集不仅能够引导模型进行稳健的推理,还能降低奖励破解和过度拟合表面模式的风险。具体而言,高质量的 RL 提示集具有三个关键属性:
· Diverse Coverage: Prompts should span a wide array of disciplines, such as STEM, coding, and general reasoning, to enhance the model's adaptability and ensure broad applicability across different domains. · Balanced Difficulty: The prompt set should include a well-distributed range of easy, moderate, and difficult questions to facilitate gradual learning and prevent over fitting to specific complexity levels. · Accurate Eva lu ability: Prompts should allow objective and reliable assessment by verifiers, ensuring that model performance is measured based on correct reasoning rather than superficial patterns or random guess.
· 多样性覆盖:提示应涵盖广泛的学科领域,如 STEM、编程和一般推理,以增强模型的适应性并确保在不同领域的广泛应用。
· 难度平衡:提示集应包含分布均匀的简单、中等和困难问题,以促进渐进式学习并防止对特定复杂度的过度拟合。
· 准确评估性:提示应允许验证者进行客观可靠的评估,确保模型性能基于正确的推理而非表面模式或随机猜测。
To achieve diverse coverage in the prompt set, we employ automatic filters to select questions that require rich reasoning and are straightforward to evaluate. Our dataset includes problems from various domains, such as STEM fields, competitions, and general reasoning tasks, incorporating both text-only and image-text question-answering data. Furthermore, we developed a tagging system to categorize prompts by domain and discipline, ensuring balanced representation across different subject areas (M. Li et al. 2023; W. Liu et al. 2023).
为了实现提示集的多样化覆盖,我们采用自动过滤器来选择那些需要丰富推理且易于评估的问题。我们的数据集涵盖了多个领域的问题,例如 STEM 领域、竞赛和一般推理任务,包含了纯文本和图文问答数据。此外,我们开发了一个标签系统,按领域和学科对提示进行分类,确保不同学科领域的平衡代表性 (M. Li et al. 2023; W. Liu et al. 2023)。
We adopt a model-based approach that leverages the model's own capacity to adaptively assess the difficulty of each prompt. Specifically, for every prompt, an SFT model generates answers ten times using a relatively high sampling temperature. The pass rate is then calculated and used as a proxy for the prompt's difficulty-the lower the pass rate, the higher the difficulty. This approach allows difficulty evaluation to be aligned with the model's intrinsic capabilities, making it highly effective for RL training. By leveraging this method, we can prefilter most trivial cases and easily explore different sampling strategies during RL training.
我们采用了一种基于模型的方法,利用模型自身的能力自适应地评估每个提示的难度。具体来说,对于每个提示,一个SFT模型使用相对较高的采样温度生成十次答案。然后计算通过率,并将其作为提示难度的代理——通过率越低,难度越高。这种方法使得难度评估与模型的内在能力保持一致,从而在RL训练中非常有效。通过利用这种方法,我们可以在RL训练期间预先过滤大多数简单案例,并轻松探索不同的采样策略。
To avoid potential reward hacking (Everitt et al. 2021; Pan et al. 2022), we need to ensure that both the reasoning process and the final answer of each prompt can be accurately verified. Empirical observations reveal that some complex reasoning problems may have relatively simple and easily guessable answers, leading to false positive verification—-where the model reaches the correct answer through an incorrect reasoning process. To address this issue, we exclude questions that are prone to such errors, such as multiple-choice, true/false, and proof-based questions. Furthermore, for general question-answering tasks, we propose a simple yet effective method to identify and remove easy-to-hack prompts. Specifically, we prompt a model to guess potential answers without any CoT reasoning steps. If the model predicts the correct answer within $N$ attempts, the prompt is considered too easy-to-hack and removed. Wefound that setting $N=8$ can remove the majority easy-to-hack prompts. Developing more advanced verification models remains an open direction for future research.
为了避免潜在的奖励滥用 (Everitt et al. 2021; Pan et al. 2022),我们需要确保每个提示的推理过程和最终答案都能被准确验证。经验观察表明,一些复杂的推理问题可能具有相对简单且容易猜测的答案,从而导致误报验证——即模型通过错误的推理过程得出正确答案。为了解决这个问题,我们排除了容易产生此类错误的问题,例如选择题、判断题和基于证明的问题。此外,对于一般的问答任务,我们提出了一种简单但有效的方法来识别和删除容易被破解的提示。具体来说,我们提示模型在没有进行任何 CoT 推理步骤的情况下猜测可能的答案。如果模型在 $N$ 次尝试内预测出正确答案,则该提示被认为太容易被破解并被删除。我们发现,设置 $N=8$ 可以删除大多数容易被破解的提示。开发更先进的验证模型仍然是未来研究的一个开放方向。
2.2 Long-CoT Supervised Fine-Tuning
2.2 长链思维监督微调 (Long-CoT Supervised Fine-Tuning)
With the refined RL prompt set, we employ prompt engineering to construct a small yet high-quality long-CoT warmup dataset, containing accurately verified reasoning paths for both text and image inputs. This approach resembles rejection sampling (RS) but focuses on generating long-CoT reasoning paths through prompt engineering. The resulting warmup dataset is designed to encapsulate key cognitive processes that are fundamental to human-like reasoning, such as planning, where the model systematically outlines steps before execution; evaluation, involving critical assessment of intermediate steps; reflection, enabling the model to reconsider and refine its approach; and exploration, encouraging consideration of alternative solutions. By performing a lightweight SFT on this warm-up dataset, we effectively prime the model to internalize these reasoning strategies. As a result, the fine-tuned long-CoT model demonstrates improved capability in generating more detailed and logically coherent responses, which enhances its performance across diverse reasoning tasks.
通过优化后的RL提示集,我们采用提示工程构建了一个小而高质量的长链思维(long-CoT)预热数据集,其中包含针对文本和图像输入的经过准确验证的推理路径。这种方法类似于拒绝采样(RS),但侧重于通过提示工程生成长链思维推理路径。生成的预热数据集旨在封装关键的认知过程,这些过程是类人推理的基础,例如规划,模型在执行前系统地概述步骤;评估,涉及对中间步骤的批判性评估;反思,使模型能够重新考虑并优化其方法;以及探索,鼓励考虑替代解决方案。通过对该预热数据集进行轻量级的监督微调(SFT),我们有效地引导模型内化这些推理策略。因此,经过微调的长链思维模型在生成更详细且逻辑一致的响应方面表现出更强的能力,从而提升了其在多样化推理任务中的表现。
2.3 Reinforcement Learning
2.3 强化学习
2.3.1 Problem Setting
2.3.1 问题设置
Given a training dataset $D={(x_{i},y_{i}^{})}{i=1}^{n}$ of problems $x{i}$ and corresponding ground truth answers $y_{i}^{}$ , our goal is to train a policy model $\pi_{\theta}$ to accurately solve test problems. In the context of complex reasoning, the mapping of problem $x$ to solution $y$ is non-trivial. To tackle this challenge, the chain of thought $(\mathrm{CoT})$ method proposes to use a sequence of intermediate steps $z=(z_{1},z_{2},...~,z_{m})$ to bridge $x$ and $y$ where each $z_{i}$ is a coherent sequence of tokens that acts as a significant intermediate step toward solving the problem (J. Wei et al. 2022). When solving problem $x$ , thoughts $z_{t}\sim\bar{\pi_{\theta}}(\cdot|x,z_{1},\cdot\cdot\cdot,z_{t-1})$ are auto-regressive ly sampled, followed by the final answer $y\sim\pi_{\theta}(\cdot|x,z_{1},\ldots,z_{m})$ .We use $y,z\sim\pi_{\theta}$ to denote this sampling procedure. Note that both the thoughts and final answer are sampled as a language sequence.
给定一个训练数据集 $D={(x_{i},y_{i}^{})}{i=1}^{n}$,其中包含问题 $x{i}$ 和对应的真实答案 $y_{i}^{}$,我们的目标是训练一个策略模型 $\pi_{\theta}$,以准确解决测试问题。在复杂推理的背景下,问题 $x$ 到解决方案 $y$ 的映射并非易事。为了应对这一挑战,思维链 (CoT) 方法提出使用一系列中间步骤 $z=(z_{1},z_{2},...~,z_{m})$ 来连接 $x$ 和 $y$,其中每个 $z_{i}$ 都是一个连贯的 Token 序列,作为解决问题的重要中间步骤 (J. Wei et al. 2022)。在解决问题 $x$ 时,思维 $z_{t}\sim\bar{\pi_{\theta}}(\cdot|x,z_{1},\cdot\cdot\cdot,z_{t-1})$ 是自回归采样的,随后是最终答案 $y\sim\pi_{\theta}(\cdot|x,z_{1},\ldots,z_{m})$。我们用 $y,z\sim\pi_{\theta}$ 表示这一采样过程。需要注意的是,思维和最终答案都是作为语言序列采样的。
To further enhance the model's reasoning capabilities, planning algorithms are employed to explore various thought processes, generating improved CoT at inference time (Yao et al. 2024; Y. Wu et al. 2024; Snell et al. 2024). The core insight of these approaches is the explicit construction of a search tree of thoughts guided by value estimations. This allows the model to explore diverse continuations of a thought process or backtrack to investigate new directions when encountering dead ends. In more detail, let $\tau$ be a search tree where each node represents a partial solution $s,=,(x,z_{1:|s|})$ . Here $s$ consists of the problem $x$ and a sequence of thoughts $z_{1:|s|},=,(z_{1},.\dots,z_{|s|})$ leading up to that node, with $|s|$ denoting number of thoughts in the sequence. The planning algorithm uses a critic model $v$ to provide feedback $v(x,z_{1:|s|})$ which lev lu at thc ret pr gr st wad sling tro l madden a errors in the existing partial solution. We note that the feedback can be provided by either a disc rim i native score or a language sequence(L. Zhang et al. 2024). Guided by the feedbacks for all $s\in\tau$ , the planning algorithm selects the most promising node for expansion, thereby growing the search tree. The above process repeats iterative ly until a full solution is derived.
为了进一步增强模型的推理能力,采用了规划算法来探索各种思维过程,在推理时生成改进的思维链 (CoT) (Yao et al. 2024; Y. Wu et al. 2024; Snell et al. 2024)。这些方法的核心见解是通过价值估计显式构建思维搜索树。这使得模型能够探索思维过程的不同延续,或在遇到死胡同时回溯以调查新的方向。更详细地说,设 $\tau$ 为一个搜索树,其中每个节点代表一个部分解 $s,=,(x,z_{1:|s|})$。这里 $s$ 由问题 $x$ 和一系列思维 $z_{1:|s|},=,(z_{1},.\dots,z_{|s|})$ 组成,这些思维引导到该节点,$|s|$ 表示序列中的思维数量。规划算法使用一个评判模型 $v$ 来提供反馈 $v(x,z_{1:|s|})$,该反馈评估现有部分解中的错误。我们注意到,反馈可以由判别分数或语言序列提供 (L. Zhang et al. 2024)。在所有 $s\in\tau$ 的反馈指导下,规划算法选择最有希望的节点进行扩展,从而增长搜索树。上述过程迭代重复,直到得出完整解。
We can also approach planning algorithms from an algorithmic perspective. Given past search history available at the $t$ -th iteration $\bar{(s_{1},v(s_{1})},\ldots,\bar{s_{t-1}},v(s_{t-1}))$ ,. a planning algorithm $\boldsymbol{\mathcal{A}}$ iterative ly determines the next search direction $\mathcal{A}(s_{t}|s_{1},v(s_{1}),\ldots,s_{t-1},v(s_{t-1}))$ and provides feedbacks for the current search progress $\mathcal{A}(v(s_{t})|s_{1},v(s_{1}),\ldots,s_{t})$ Since both thoughts and feedbacks can be viewed as intermediate reasoning steps, and these components can both be represented as sequence of language tokens, we use $z$ to replace $s$ and $v$ to simplify the notations. Accordingly, we view a planning algorithm as a mapping that directly acts on a sequence of reasoning steps $\mathcal{A}(\cdot|z_{1},z_{2},\dots)$ . In this framework, all information stored in the search tre used by the planning algorithm is fattened into the full context provided to the algorithm. This provides an intriguing perspective on generating high-quality CoT: Rather than explicitly constructing a search tree and implementing a planning algorithm, we could potentially train a model to approximate this process. Here, the number of thoughts (i.e., language tokens) serves as an analogy to the computational budget traditionally allocated to planning algorithms. Recent advancements in long context windows facilitate seamless s cal ability during both the training and testing phases. If feasible, this method enables the model to run an implicit search over the reasoning space directly via auto-regressive predictions. Consequently, the model not only learns to solve a set of training problems but also develops the ability to tackle individual problems effectively, leading to improved generalization to unseen test problems.
我们也可以从算法的角度来探讨规划算法。给定在第 $t$ 次迭代时可用的过去搜索历史 $\bar{(s_{1},v(s_{1})},\ldots,\bar{s_{t-1}},v(s_{t-1}))$ ,规划算法 $\boldsymbol{\mathcal{A}}$ 迭代地确定下一个搜索方向 $\mathcal{A}(s_{t}|s_{1},v(s_{1}),\ldots,s_{t-1},v(s_{t-1}))$ ,并为当前的搜索进度提供反馈 $\mathcal{A}(v(s_{t})|s_{1},v(s_{1}),\ldots,s_{t})$ 。由于思维和反馈都可以被视为中间推理步骤,并且这些组件都可以表示为语言 Token 的序列,我们使用 $z$ 替换 $s$ 和 $v$ 以简化符号。因此,我们将规划算法视为直接作用于推理步骤序列的映射 $\mathcal{A}(\cdot|z_{1},z_{2},\dots)$ 。在这个框架中,规划算法使用的搜索树中存储的所有信息都被扁平化为提供给算法的完整上下文。这为生成高质量的思维链 (CoT) 提供了一个有趣的视角:与其显式构建搜索树并实现规划算法,我们可能可以训练一个模型来近似这个过程。在这里,思维的数量(即语言 Token)与传统上分配给规划算法的计算预算相类比。长上下文窗口的最新进展在训练和测试阶段都促进了无缝的可扩展性。如果可行,这种方法使模型能够通过自回归预测直接在推理空间中进行隐式搜索。因此,模型不仅学会解决一组训练问题,还发展出有效解决单个问题的能力,从而提高了对未见过的测试问题的泛化能力。
We thus consider training the model to generate CoT with reinforcement learning (RL) (OpenAI 2024). Let $r$ be a reward model that justifies the correctness of the proposed answer $y$ for the given problem $x$ based on the ground truth $y^{\ast}$ , by assigning a value $r(x,y,y^{})\in{0,1}$ . For verifiable problems, the reward is directly determined by predefined criteria or rules. For example, in coding problems, we assess whether the answer passes the test cases. For problems with free-form ground truth, we train a reward model $r(x,y,y^{})$ that predicts if the answer matches the ground truth. Given a problem $x$ , the model $\pi_{\theta}$ generates a CoT and the final answer through the sampling procedure $z\sim\pi_{\theta}(\cdot|x)$ , $y\sim\pi_{\theta}(\cdot|x,z)$ . The quality of the generated $\mathrm{CoT}$ is evaluated by whether it can lead to a correct final answer. In summary, we consider the following objective to optimize the policy
因此,我们考虑使用强化学习 (RL) (OpenAI 2024) 来训练模型生成 CoT。设 $r$ 为一个奖励模型,它通过分配一个值 $r(x,y,y^{})\in{0,1}$ 来证明给定问题 $x$ 的答案 $y$ 的正确性,基于真实答案 $y^{\ast}$。对于可验证的问题,奖励直接由预定义的标准或规则决定。例如,在编码问题中,我们评估答案是否通过测试用例。对于具有自由形式真实答案的问题,我们训练一个奖励模型 $r(x,y,y^{})$,预测答案是否与真实答案匹配。给定一个问题 $x$,模型 $\pi_{\theta}$ 通过采样过程 $z\sim\pi_{\theta}(\cdot|x)$ 和 $y\sim\pi_{\theta}(\cdot|x,z)$ 生成 CoT 和最终答案。生成的 $\mathrm{CoT}$ 的质量通过它是否能引导出正确的最终答案来评估。总之,我们考虑以下目标来优化策略
\operatorname*{max}_{\theta}\mathbb{E}_{(x,y^{*})\sim\mathcal{D},(y,z)\sim\pi_{\theta}}\left[r(x,y,y^{*})\right]\,.
By scaling up RL training, we aim to train a model that harnesses the strengths of both simple prompt-based CoT and planning-augmented CoT. The model still auto-regressive ly sample language sequence during inference, thereby circumventing the need for the complex parallel iz ation required by advanced planning algorithms during deployment. However, a key distinction from simple prompt-based methods is that the model should not merely follow a series of reasoning steps. Instead, it should also learn critical planning skills including error identification, backtracking and solution refinement by leveraging the entire set of explored thoughts as contextual information.
通过扩大强化学习 (RL) 训练的规模,我们的目标是训练一个模型,该模型能够结合简单基于提示的思维链 (CoT) 和增强规划的思维链的优势。在推理过程中,模型仍然自回归地采样语言序列,从而避免了在部署时使用高级规划算法所需的复杂并行化。然而,与简单基于提示的方法的一个关键区别在于,模型不应仅仅遵循一系列推理步骤。相反,它还应通过学习错误识别、回溯和解决方案优化等关键规划技能,利用整个探索过的思维集作为上下文信息。
2.3.2 Policy Optimization
2.3.2 策略优化
We apply a variant of online policy mirror decent as our training algorithm (Abbasi-Yadkori et al. 2019; Mei et al. 2019; Tomar et al. 2020). The algorithm performs iterative ly. At the $i$ -th iteration, we use the current model $\pi_{\theta_{i}}$ as a reference model and optimize the following relative entropy regularized policy optimization problem,
我们采用了一种在线策略镜像下降的变体作为训练算法 (Abbasi-Yadkori et al. 2019; Mei et al. 2019; Tomar et al. 2020)。该算法迭代执行。在第 $i$ 次迭代中,我们使用当前模型 $\pi_{\theta_{i}}$ 作为参考模型,并优化以下相对熵正则化的策略优化问题,
\operatorname*{max}_{\theta}\mathbb{E}_{(x,y^{*})\sim\mathcal{D}}\left[\mathbb{E}_{(y,z)\sim\pi_{\theta}}\left[r(x,y,y^{*})\right]-\tau\mathrm{KL}(\pi_{\theta}(x)||\pi_{\theta_{i}}(x))\right]\,,
where $\tau>0$ is a parameter controlling the degree of regular iz ation. This objective has a closed form solution
其中 $\tau>0$ 是控制正则化程度的参数。该目标函数有一个闭式解
\pi^{*}(y,z|x)=\pi_{\theta_{i}}(y,z|x)\exp(r(x,y,y^{*})/\tau)/Z\,.
Here $\begin{array}{r}{Z=\sum_{y^{\prime},z^{\prime}}\pi_{\theta_{i}}(y^{\prime},z^{\prime}|x)\exp(r(x,y^{\prime},y^{*})/\tau)}\end{array}$ is the normalization factor. Taking logarithm of both sides we have forany $(y,z)$ the following constraint is satisfied, which allows us to leverage off-policy data during optimization
这里 $\begin{array}{r}{Z=\sum_{y^{\prime},z^{\prime}}\pi_{\theta_{i}}(y^{\prime},z^{\prime}|x)\exp(r(x,y^{\prime},y^{*})/\tau)}\end{array}$ 是归一化因子。对两边取对数,我们得到对于任何 $(y,z)$ 满足以下约束条件,这使得我们能够在优化过程中利用离策略数据
r(x,y,y^{*})-\tau\log Z=\tau\log\frac{\pi^{*}(y,z|x)}{\pi_{\theta_{i}}(y,z|x)}\,.
This motivates the following surrogate loss
这促使了以下替代损失
L(\theta)=\mathbb{E}_{(x,y^{*})\sim\mathcal{D}}\left[\mathbb{E}_{(y,z)\sim\pi_{\theta_{i}}}\left[\left(r(x,y,y^{*})-\tau\log Z-\tau\log\frac{\pi_{\theta}(y,z|x)}{\pi_{\theta_{i}}(y,z|x)}\right)^{2}\right]\right]\,.
To approximate $\tau\log Z$ . we use samples $\begin{array}{r}{(y_{1},z_{1}),\dotsc,(y_{k},z_{k})\sim\pi_{\theta_{i}}\colon\tau\log Z\approx\tau\log\frac{1}{k}\sum_{j=1}^{k}\exp(r(x,y_{j},y^{*})/\tau)}\end{array}$ We also find that using empirical mean of sampled rewards $\overline{{r}}=\mathrm{mean}(r(x,y_{1},y^{*}),\ldots,r(x,y_{k},y^{*}))$ yields effective practical results. This is reasonable since $\tau\log Z$ approaches the expected reward under $\pi_{\theta_{i}}$ as $\tau\rightarrow\infty$ . Finally, we conclude our learning algorithm by taking the gradient of surrogate loss. For each problem $x$ , $k$ responses are sampled using the reference policy $\pi_{\theta_{i}}$ , and the gradient is given by
为了近似 $\tau\log Z$,我们使用样本 $\begin{array}{r}{(y_{1},z_{1}),\dotsc,(y_{k},z_{k})\sim\pi_{\theta_{i}}\colon\tau\log Z\approx\tau\log\frac{1}{k}\sum_{j=1}^{k}\exp(r(x,y_{j},y^{*})/\tau)}\end{array}$。我们还发现,使用采样奖励的经验均值 $\overline{{r}}=\mathrm{mean}(r(x,y_{1},y^{*}),\ldots,r(x,y_{k},y^{*}))$ 可以得到有效的实际结果。这是合理的,因为当 $\tau\rightarrow\infty$ 时,$\tau\log Z$ 接近 $\pi_{\theta_{i}}$ 下的期望奖励。最后,我们通过对代理损失求梯度来总结我们的学习算法。对于每个问题 $x$,使用参考策略 $\pi_{\theta_{i}}$ 采样 $k$ 个响应,梯度由下式给出:
\frac{1}{k}\sum_{j=1}^{k}\left(\nabla_{\theta}\log\pi_{\theta}(y_{j},z_{j}|x)(r(x,y_{j},y^{*})-\overline{{r}})-\frac{\tau}{2}\nabla_{\theta}\left(\log\frac{\pi_{\theta}(y_{j},z_{j}|x)}{\pi_{\theta_{i}}(y_{j},z_{j}|x)}\right)^{2}\right)\,.```
To those familiar with policy gradient methods, this gradient resembles the policy gradient of (2) using the mean of sampled rewards as the baseline (Kool et al. 2019; Ahmadian et al. 2024). The main differences are that the responses are sampled from \$\pi_{\theta_{i}}\$ rather than on-policy, and an \$l_{2}\$ -regular iz ation is applied. Thus we could see this as the natural extension of a usual on-policy regularized policy gradient algorithm to the off-policy case (Nachum et al. 2017). We sample a batch of problems from \$\mathcal{D}\$ and update the parameters to \$\theta_{i+1}\$ , which subsequently serves as the reference policy for the next iteration. Since each iteration considers a different optimization probiem due to the changing reference policy, we also reset the optimizer at the start of each iteration.
对于熟悉策略梯度方法的读者来说,这个梯度类似于使用采样奖励均值作为基线的策略梯度 (Kool et al. 2019; Ahmadian et al. 2024)。主要区别在于响应是从 \$\pi_{\theta_{i}}\$ 中采样得到的,而不是在策略上采样,并且应用了 \$l_{2}\$ 正则化。因此,我们可以将其视为通常的在策略正则化策略梯度算法在离策略情况下的自然扩展 (Nachum et al. 2017)。我们从 \$\mathcal{D}\$ 中采样一批问题,并将参数更新为 \$\theta_{i+1}\$,随后它作为下一次迭代的参考策略。由于每次迭代由于参考策略的变化而考虑不同的优化问题,因此我们在每次迭代开始时也会重置优化器。
We exclude the value network in our training system which has also been exploited in previous studies (Ahmadian et al. 2024). While this design choice significantly improves training efficiency, we also hypothesize that the conventional use of value functions for credit assignment in classical RL may not be suitable for our context. Consider a scenario where the model has ee rated a par iaC \$(z_{1},z_{2},\ldots,z_{t})\$ and the raw tent i al x tre an in \$z_{t+1}\$ and \$z_{t+1}^{\prime}\$ Assume that \$z_{t+1}\$ directly leads to the corect answer, while \$z_{t+1}^{\prime}\$ contains some errors. If an oracle value function were accessible, it would indicate that \$z_{t+1}\$ preserves ahigher value compared to \$z_{t+1}^{\prime}\$ . According to the standard credit assignment principle, selecting \$z_{t+1}^{\prime}\$ would be penalized as it has a negative advantages relative to the current policy. However, exploring \$z_{t+1}^{\prime}\$ is extremely valuable for training the model to generate long CoT. By using the justification of the final answer derived from a long CoT as the reward signal, the model can learn the pattern of trial and error from taking \$z_{t+1}^{\prime}\$ as long as it succes fully recovers and reaches the correct answer. The key takeaway from this example is that we should encourage the model to explore diverse reasoning paths to enhance its capability in solving complex problems. This exploratory approach generates a wealth of experience that supports the development of critical planning skills. Our primary goal is not confined to ataining high accuracy on training problems but focuses on equipping the model with effective problem-solving strategies, ultimately improving its performance on test problems.
我们在训练系统中排除了价值网络,这一设计在之前的研究中也被采用过 (Ahmadian et al. 2024) 。虽然这一选择显著提高了训练效率,但我们假设传统强化学习中使用价值函数进行信用分配的方式可能不适合我们的场景。考虑一个场景,模型已经生成了一个部分序列 \$(z_{1},z_{2},\ldots,z_{t})\$ ,并且潜在的下一步是 \$z_{t+1}\$ 和 \$z_{t+1}^{\prime}\$ 。假设 \$z_{t+1}\$ 直接导致正确答案,而 \$z_{t+1}^{\prime}\$ 包含一些错误。如果有一个理想的价值函数可用,它会表明 \$z_{t+1}\$ 比 \$z_{t+1}^{\prime}\$ 具有更高的价值。根据标准的信用分配原则,选择 \$z_{t+1}^{\prime}\$ 将会受到惩罚,因为它相对于当前策略具有负面的优势。然而,探索 \$z_{t+1}^{\prime}\$ 对于训练模型生成长链推理 (CoT) 非常有价值。通过使用从长链推理中得出的最终答案的合理性作为奖励信号,模型可以从选择 \$z_{t+1}^{\prime}\$ 中学习试错的模式,只要它成功恢复并达到正确答案。这个例子的关键启示是,我们应该鼓励模型探索多样化的推理路径,以增强其解决复杂问题的能力。这种探索性方法生成了丰富的经验,支持关键规划技能的发展。我们的主要目标不仅限于在训练问题上获得高准确率,而是专注于为模型配备有效的问题解决策略,最终提高其在测试问题上的表现。
# 2.3.3 Length Penalty
# 2.3.3 长度惩罚
We observe an over thinking phenomenon that the model's response length significantly increases during RL training. Although this leads to better performance, an excessively lengthy reasoning process is costly during training and inference, and over thinking is often not preferred by humans. To address this issue, we introduce a length reward to restrain the rapid growth of token length, thereby improving the model's token efficiency. Given \$k\$ sampled responses \$(y_{1},z_{1}),\ldots,(y_{k},z_{k})\$ of problem \$x\$ with true answer \$y^{\ast}\$ , let \$\mathrm{len}(i)\$ be the length of \$(y_{i},z_{i})\$ , \$\mathrm{min\_len}=\mathrm{min}_{i}\;\mathrm{len}(i)\$ and max_ \$\mathrm{len}=\operatorname*{max}_{i}\mathrm{len}(i)\$ . If max_ \$\mathrm{len}=\mathrm{min\_len}\$ , we set length reward zero for all responses, as they have the same length. Otherwise the length reward is given by
我们观察到一种过度思考现象,即模型在强化学习训练期间响应长度显著增加。虽然这带来了更好的性能,但过长的推理过程在训练和推理过程中成本高昂,而且人类通常不喜欢过度思考。为了解决这个问题,我们引入了一种长度奖励来抑制token长度的快速增长,从而提高模型的token效率。给定问题 \$x\$ 的 \$k\$ 个采样响应 \$(y_{1},z_{1}),\ldots,(y_{k},z_{k})\$ ,其中真实答案为 \$y^{\ast}\$ ,设 \$\mathrm{len}(i)\$ 为 \$(y_{i},z_{i})\$ 的长度, \$\mathrm{min\_len}=\mathrm{min}_{i}\;\mathrm{len}(i)\$ 且 max_ \$\mathrm{len}=\operatorname*{max}_{i}\mathrm{len}(i)\$ 。如果 max_ \$\mathrm{len}=\mathrm{min\_len}\$ ,我们将所有响应的长度奖励设为零,因为它们的长度相同。否则,长度奖励由以下公式给出:
\mathrm{len_reward(i)}=\left{!!\begin{array}{r l}{\lambda}&{\mathrm{If};r(x,y_{i},y^{})=1}\ {\mathrm{min}(0,\lambda)}&{\mathrm{If};r(x,y_{i},y^{})=0}\end{array}!!\right.,\quad\mathrm{where};\lambda=0.5-\frac{\mathrm{len}(i)-\mathrm{min}_l e n}{\mathrm{max_len}-\mathrm{min}_l e n},.
In essence, we promote shorter responses and penalize longer responses among correct ones, while explicitly penalizing long responses with incorrect answers. This length-based reward is then added to the original reward with a weighting parameter.
本质上,我们在正确的回答中鼓励较短的响应,并对较长的响应进行惩罚,同时明确惩罚那些回答错误的长响应。然后,这种基于长度的奖励会通过一个权重参数添加到原始奖励中。
In our preliminary experiments, length penalty may slow down training during the initial phases. To alleviate this issue, we propose to gradually warm up the length penalty during training. Specifically, we employ standard policy optimization without length penalty, followed by a constant length penalty for the rest of training.
在我们的初步实验中,长度惩罚可能会在初始阶段减缓训练速度。为了缓解这一问题,我们提出在训练过程中逐步预热长度惩罚。具体来说,我们首先采用不带长度惩罚的标准策略优化,然后在剩余的训练过程中使用恒定的长度惩罚。
# 2.3.4 Sampling Strategies
# 2.3.4 采样策略
Although RL algorithms themselves have relatively good sampling properties (with more difficult problems providing larger gradients), their training efficiency is limited. Consequently, some well-defined prior sampling methods can yield potentially greater performance gains. We exploit multiple signals to further improve the sampling strategy. First, the RL training data we collect naturally come with different difficulty labels. For example, a math competition problem is more difficult than a primary school math problem. Second, because the RL training process samples the same problem multiple times, we can also track the success rate for each individual problem as a metric of diffculty. We propose two sampling methods to utilize these priors to improve training efficiency.
尽管RL算法本身具有相对较好的采样特性(问题越难,梯度越大),但其训练效率有限。因此,一些定义明确的先验采样方法可能会带来更大的性能提升。我们利用多种信号来进一步改进采样策略。首先,我们收集的RL训练数据自然带有不同的难度标签。例如,数学竞赛题比小学数学题更难。其次,由于RL训练过程会多次采样同一个问题,我们还可以跟踪每个问题的成功率作为难度的度量。我们提出了两种采样方法,利用这些先验知识来提高训练效率。
Curriculum Sampling We start by training on easier tasks and gradually progress to more challenging ones. Since the initial RL model has limited performance, spending a restricted computation budget on very hard problems often yields few correct samples, resulting in lower training efficiency. Meanwhile, our collected data naturally includes grade and difficulty labels, making difficulty-based sampling an intuitive and effective way to improve training efficiency.
课程采样
我们从较简单的任务开始训练,逐渐过渡到更具挑战性的任务。由于初始的强化学习模型性能有限,将有限的计算资源用于非常困难的问题通常只会产生少量正确的样本,从而导致训练效率降低。同时,我们收集的数据自然包含难度等级标签,因此基于难度的采样是一种直观且有效的提高训练效率的方法。
Prioritized Sampling In addition to curriculum sampling, we use a prioritized sampling strategy to focus on problems where the model under performs. We track the success rates \$s_{i}\$ for each problem \$i\$ and sample problems proportional to \$1-s_{i}\$ , so that problems with lower success rates receive higher sampling probabilities. This directs the model's efforts toward its weakest areas, leading to faster learning and better overall performance.
优先级采样 除了课程采样外,我们还使用优先级采样策略来关注模型表现不佳的问题。我们跟踪每个问题 \$i\$ 的成功率 \$s_{i}\$,并按 \$1-s_{i}\$ 的比例对问题进行采样,使得成功率较低的问题获得更高的采样概率。这使模型能够将精力集中在最薄弱的领域,从而加快学习速度并提高整体性能。
# 2.3.5More Details on Training Recipe
# 2.3.5 训练方案的更多细节
Test Case Generation for Coding Since test cases are not available for many coding problems from the web, we design a method to automatically generate test cases that serve as a reward to train our model with RL. Our focus is primarily on problems that do not require a special judge. We also assume that ground truth solutions are available for these problems so that we can leverage the solutions to generate higher quality test cases.
代码测试用例生成
由于网络上许多编程问题没有可用的测试用例,我们设计了一种方法来自动生成测试用例,作为奖励来训练我们的强化学习模型。我们主要关注不需要特殊评判的问题。我们还假设这些问题有可用的标准答案,以便我们可以利用这些答案生成更高质量的测试用例。
We utilize the widely recognized test case generation library, CYaRon', to enhance our approach. We employ our base Kimi k1.5 to generate test cases based on problem statements. The usage statement of CYaRon and the problem description are provided as the input to the generator. For each problem, we first use the generator to produce 50 test cases and also randomly sample 10 ground truth submissions for each test case. We run the test cases against the submissions. A test case is deemed valid if at least 7 out of 10 submissions yield matching results. After this round of filtering, we obtain a set of selected test cases. A problem and its associated selected test cases are added to our training set if at least 9 out of 10 submissions pass the entire set of selected test cases.
我们利用广泛认可的测试用例生成库 CYaRon 来增强我们的方法。我们使用基础模型 Kimi k1.5 根据问题描述生成测试用例。CYaRon 的使用说明和问题描述作为生成器的输入。对于每个问题,我们首先使用生成器生成 50 个测试用例,并为每个测试用例随机抽取 10 个真实提交。我们针对这些提交运行测试用例。如果至少 7 个提交的结果匹配,则该测试用例被视为有效。经过这轮筛选后,我们得到一组选定的测试用例。如果至少 9 个提交通过了整个选定的测试用例集,则该问题及其相关的选定测试用例将被添加到我们的训练集中。
In terms of statistics, from a sample of 1,000 online contest problems, approximately 614 do not require a special judge. We developed 463 test case generators that produced at least 40 valid test cases, leading to the inclusion of 323 problems in our training set.
从统计数据来看,在1000个在线竞赛问题的样本中,大约有614个问题不需要特殊评判。我们开发了463个测试用例生成器,生成了至少40个有效的测试用例,最终将323个问题纳入了我们的训练集。
Reward Modeling for Math_ One challenge in evaluating math solutions is that different written forms can represent the same underlying ans wer. For instance, \$a^{\frac{\smile}{2}}-4\$ and \$(a+2)(a-2)\$ may both be valid solutions to the same problem. We adopted two methods to improve the reward model's scoring accuracy:
数学奖励建模:评估数学解决方案的一个挑战是,不同的书写形式可能代表相同的底层答案。例如,\$a^{\frac{\smile}{2}}-4\$ 和 \$(a+2)(a-2)\$ 可能是同一问题的有效解决方案。我们采用了两种方法来提高奖励模型的评分准确性:
1. Classic RM: Drawing inspiration from the Instruct GP T (Ouyang et al. 2022) methodology, we implemented a value-head based reward model and collected approximately \$800\mathrm{k}\$ data points for fine-tuning. The model ultimately
2. 经典奖励模型 (Classic RM):受 Instruct GPT (Ouyang et al. 2022) 方法的启发,我们实现了一个基于价值头的奖励模型,并收集了大约 \$800\mathrm{k}\$ 个数据点进行微调。模型最终
takes as input the “question,”’ the “reference answer,” and the “response,” and outputs a single scalar that indicates whether the response is correct. 2. Chain-of-Thought RM: Recent research (Ankner et al. 2024; McAleese et al. 2024) suggests that reward models augmented with chain-of-thought (CoT) reasoning can significantly outperform classic approaches, particularly on tasks where nuanced correctness criteria matter—such as mathematics. Therefore, we collected an equally large dataset of about 80ok CoT-labeled examples to fine-tune the Kimi model. Building on the same inputs as the Classic RM, the chain-of-thought approach explicitly generates a step-by-step reasoning process before providing a final correctness judgment in JSON format, enabling more robust and interpret able reward signals.
以“问题”、“参考答案”和“回答”作为输入,并输出一个标量,指示回答是否正确。
2. 思维链奖励模型 (Chain-of-Thought RM):最近的研究 (Ankner et al. 2024; McAleese et al. 2024) 表明,结合思维链 (CoT) 推理的奖励模型可以显著优于经典方法,尤其是在需要细微正确性标准的任务上——例如数学。因此,我们收集了约 80 万个带有 CoT 标签的示例数据集,用于微调 Kimi 模型。基于与经典奖励模型相同的输入,思维链方法在提供最终正确性判断之前,显式生成逐步推理过程,并以 JSON 格式输出,从而提供更稳健且可解释的奖励信号。
During our manual spot checks, the Classic RM achieved an accuracy of approximately 84.4, while the Chain-ofThought RM reached 98.5 accuracy. In the RL training process, we adopted the Chain-of-Thought RM to ensure more correct feedback.
在我们的手动抽查中,Classic RM 的准确率约为 84.4,而 Chain-of-Thought RM 的准确率达到了 98.5。在强化学习 (RL) 训练过程中,我们采用了 Chain-of-Thought RM 以确保更准确的反馈。
Vision Data To improve the model's real-world image reasoning capabilities and to achieve a more effective alignment between visual inputs and large language models (LLMs), our vision reinforcement learning (Vision RL) data is primarily sourced from three distinct categories: Real-world data, Synthetic visual reasoning data, and Text-rendered data.
视觉数据
为了提升模型在现实世界图像推理方面的能力,并实现视觉输入与大语言模型之间更有效的对齐,我们的视觉强化学习(Vision RL)数据主要来源于三个不同的类别:现实世界数据、合成视觉推理数据和文本渲染数据。
Each type of data is essential in building a comprehensive visual language model that can effectively manage a wide range of real-world applications while ensuring consistent performance across various input modalities.
每种数据类型对于构建一个全面的视觉语言模型都至关重要,该模型能够有效管理广泛的现实世界应用,同时确保在各种输入模态下保持一致的性能。
# 2.4 Long2short: Context Compression for Short-CoT Models
# 2.4 Long2short: 短链思维模型的上下文压缩
Though long-CoT models achieve strong performance, it consumes more test-time tokens compared to standard short-CoT LLMs. However, it is possible to transfer the thinking priors from long-CoT models to short-CoT models so that performance can be improved even with limited test-time token budgets. We present several approaches for this long2short problem, including model merging (Yang et al. 2024), shortest rejection sampling, DPO (Rafailov et al. 2024), and long2short RL. Detailed descriptions of these methods are provided below:
尽管长链思维模型(long-CoT)表现出色,但与标准的短链思维大语言模型(short-CoT LLMs)相比,它在测试时消耗的 Token 更多。然而,我们可以将长链思维模型的思维先验转移到短链思维模型中,从而在有限的测试 Token 预算下也能提升性能。我们提出了几种解决这一长链转短链(long2short)问题的方法,包括模型合并(Yang et al. 2024)、最短拒绝采样、DPO(Rafailov et al. 2024)以及长链转短链强化学习(long2short RL)。这些方法的具体描述如下:
Model Merging _ Model merging has been found to be useful in maintaining generalization ability. We also discovered its effectiveness in improving token efficiency when merging a long-cot model and a short-cot model. This approach combines a long-cot model with a shorter model to obtain a new one without training. Specifically, we merge the two models by simply averaging their weights.
模型合并 _ 模型合并在保持泛化能力方面已被证明是有用的。我们还发现,在合并长链思维(long-cot)模型和短链思维(short-cot)模型时,它在提高Token效率方面也非常有效。这种方法通过将长链思维模型与较短的模型结合,无需训练即可获得一个新模型。具体来说,我们通过简单地平均两个模型的权重来实现合并。
Shortest Rejection Sampling We observed that our model generates responses with a large length variation for the same problem. Based on this, we designed the Shortest Rejection Sampling method. This method samples the same question \$n\$ times (in our experiments, \$n=8\$ ) and selects the shortest correct response for supervised fine-tuning.
最短拒绝采样
我们观察到,我们的模型在相同问题上生成的响应长度差异较大。基于此,我们设计了最短拒绝采样方法。该方法对同一个问题采样 \$n\$ 次(在我们的实验中,\$n=8\$),并选择最短的正确响应用于监督微调。
DPO Similar with Shortest Rejection Sampling, we utilize the Long CoT model to generate multiple response samples. The shortest correct solution is selected as the positive sample, while longer responses are treated as negative samples, including both wrong longer responses and correct longer responses (1.5 times longer than the chosen positive sample). These positive-negative pairs form the pairwise preference data used for DPO training.
DPO 与最短拒绝采样类似,我们利用长链思维(Long CoT)模型生成多个响应样本。选择最短的正确解决方案作为正样本,而较长的响应则被视为负样本,包括错误的较长响应和正确的较长响应(比所选正样本长1.5倍)。这些正负样本对构成了用于DPO训练的成对偏好数据。
Long2short RL After a standard RL training phase, we select a model that offers the best balance between performance and token efficiency to serve as the base model, and conduct a separate long2short RL training phase. In this second phase, we apply the length penalty introduced in Section 2.3.3, and significantly reduce the maximum rollout length to further penalize responses that exceed the desired length while possibly correct.
长转短强化学习 (Long2short RL)
在标准的强化学习训练阶段之后,我们选择一个在性能和 Token 效率之间提供最佳平衡的模型作为基础模型,并进行单独的长转短强化学习训练阶段。在此第二阶段中,我们应用第 2.3.3 节中引入的长度惩罚,并显著减少最大生成长度,以进一步惩罚那些可能正确但超出期望长度的响应。
# 2.5 Other Training Details
# 2.5 其他训练细节
# 2.5.1 Pre training
# 2.5.1 预训练
The Kimi \$\mathrm{k}1.5\$ base model is trained on a diverse, high-quality multimodal corpus. The language data covers five domains: English, Chinese, Code, Mathematics Reasoning, and Knowledge. Multimodal data, including Captioning, Image-text Interleaving, OCR, Knowledge, and QA datasets, enables our model to acquire vision-language capabilities. Rigorous quality control ensures relevance, diversity, and balance in the overall pretrain dataset. Our pre training proceeds in three stages: (1) Vision-language pre training, where a strong language foundation is established, followed by gradual multimodal integration; (2) Cooldown, which consolidates capabilities using curated and synthetic data, particularly for reasoning and knowledge-based tasks; and (3) Long-context activation, extending sequence processing to 131,072 tokens. More details regarding our pre training efforts can be found in Appendix B.
Kimi \$\mathrm{k}1.5\$ 基础模型在一个多样化、高质量的多模态语料库上进行训练。语言数据涵盖五个领域:英语、中文、代码、数学推理和知识。多模态数据,包括字幕、图文交错、OCR、知识和问答数据集,使我们的模型能够获得视觉语言能力。严格的质量控制确保了整体预训练数据集的相关性、多样性和平衡性。我们的预训练分为三个阶段:(1) 视觉语言预训练,首先建立强大的语言基础,然后逐步整合多模态;(2) 冷却阶段,使用精选和合成数据巩固能力,特别是推理和基于知识的任务;(3) 长上下文激活,将序列处理扩展到 131,072 个 Token。有关我们预训练工作的更多细节可以在附录 B 中找到。
# 2.5.2 Vanilla Supervised Finetuning
# 2.5.2 普通监督微调
We create the vanilla SFT corpus covering multiple domains. For non-reasoning tasks, including question-answering, writing, and text processing, we initially construct a seed dataset through human annotation. This seed dataset is used to train a seed model. Subsequently, we collect a diverse of prompts and employ the seed model to generate multiple responses to each prompt. Annotators then rank these responses and refine the top-ranked response to produce the final version. For reasoning tasks such as math and coding problems, where rule-based and reward modeling based verification s are more accurate and efficient than human judgment, we utilize rejection sampling to expand the SFT dataset.
我们创建了一个涵盖多个领域的标准 SFT 语料库。对于非推理任务,包括问答、写作和文本处理,我们首先通过人工标注构建了一个种子数据集。该种子数据集用于训练种子模型。随后,我们收集了多样化的提示,并利用种子模型为每个提示生成多个响应。标注者对这些响应进行排序,并对排名最高的响应进行优化,以生成最终版本。对于数学和编程问题等推理任务,基于规则和奖励建模的验证方法比人工判断更准确和高效,我们利用拒绝采样来扩展 SFT 数据集。
Our vanilla SFT dataset comprises approximately 1 million text examples. Specifically, 50Ok examples are for general question answering, \$200\mathbf{k}\$ for coding, \$200\mathbf{k}\$ for math and science, \$5\mathrm{k}\$ for creative writing, and \$20\mathbf{k}\$ for long-context tasks such as sum mari z ation, doc-qa, translation, and writing. In addition, we construct 1 million text-vision examples encompassing various categories including chart interpretation, OCR, image-grounded conversations, visual coding, visual reasoning, and math/science problems with visual aids.
我们的基础 SFT 数据集包含大约 100 万条文本示例。具体来说,50k 条示例用于通用问答,\$200\mathbf{k}\$ 条用于编码,\$200\mathbf{k}\$ 条用于数学和科学,\$5\mathrm{k}\$ 条用于创意写作,\$20\mathbf{k}\$ 条用于长上下文任务,如摘要、文档问答、翻译和写作。此外,我们还构建了 100 万条文本-视觉示例,涵盖图表解读、OCR、基于图像的对话、视觉编码、视觉推理以及带有视觉辅助的数学/科学问题等多种类别。
We first train the model at the sequence length of \$32\mathbf{k}\$ tokens for 1 epoch, followed by another epoch at the sequence length of 128k tokens. In the first stage (32k), the learning rate decays from \$2\times10^{-5}\$ to \$2\times10^{-6}\$ , before it re-warmups to \$\bar{1}\times10^{-5}\$ in the second stage (128k) and finally decays to \$1\times10^{\dot{-}6}\$ . To improve training efficiency, we pack multiple training examples into each single training sequence.
我们首先在序列长度为 \$32\mathbf{k}\$ token 的情况下训练模型 1 个 epoch,然后在序列长度为 128k token 的情况下再训练 1 个 epoch。在第一阶段 (32k) 中,学习率从 \$2\times10^{-5}\$ 衰减到 \$2\times10^{-6}\$,然后在第二阶段 (128k) 重新预热到 \$\bar{1}\times10^{-5}\$,最后衰减到 \$1\times10^{\dot{-}6}\$。为了提高训练效率,我们将多个训练样本打包到每个训练序列中。
# 2.6 RL Infrastructure
# 2.6 RL 基础设施
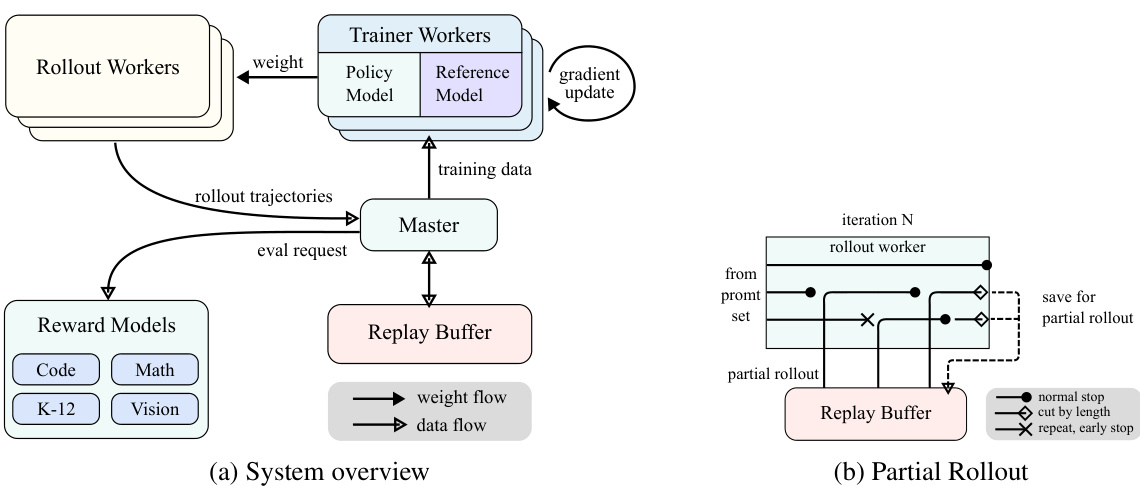
Figure 3: Large Scale Reinforcement Learning Training System for LLM
图 3: 大语言模型的大规模强化学习训练系统
# 2.6.1 Large Scale Reinforcement Learning Training System for LLM
# 2.6.1 面向大语言模型的大规模强化学习训练系统
In the realm of artificial intelligence, reinforcement learning (RL) has emerged as a pivotal training methodology for large language models (LLMs)(Ouyang et al. 2022)(Jaech et al. 2024), drawing inspiration from its success in mastering complex games like Go, StarCraft II, and Dota 2 through systems such as AlphaGo(Silver et al. 2017), AlphaStar(Vinyals et al. 2019), and OpenAI Dota Five (Berner et al. 2019). Following in this tradition, the Kimi k1.5 system adopts an iterative synchronous RL framework, meticulously designed to bolster the model's reasoning capabilities through persistent learning and adaptation. A key innovation in this system is the introduction of a Partial Rollout technique, designed to optimize the handling of complex reasoning trajectories.
在人工智能领域,强化学习 (Reinforcement Learning, RL) 已成为大语言模型 (LLMs) 的关键训练方法 (Ouyang et al. 2022)(Jaech et al. 2024),其灵感来源于在复杂游戏如围棋、星际争霸 II 和 Dota 2 中取得成功的系统,例如 AlphaGo (Silver et al. 2017)、AlphaStar (Vinyals et al. 2019) 和 OpenAI Dota Five (Berner et al. 2019)。秉承这一传统,Kimi k1.5 系统采用了迭代同步 RL 框架,精心设计以通过持续学习和适应来增强模型的推理能力。该系统的关键创新是引入了 Partial Rollout 技术,旨在优化复杂推理轨迹的处理。
The RL training system as illustrated in Figure 3a operates through an iterative synchronous approach, with each iteration encompassing a rollout phase and a training phase. During the rollout phase, rollout workers, coordinated by a central master, generate rollout trajectories by interacting with the model, producing sequences of responses to various inputs. These trajectories are then stored in a replay buffer, which ensures a diverse and unbiased dataset for training by disrupting temporal correlations. In the subsequent training phase, trainer workers access these experiences to update the model's weights. This cyclical process allows the model to continuously learn from its actions, adjusting its strategies over time to enhance performance.
图 3a 中展示的 RL 训练系统通过迭代同步的方式运行,每次迭代包括一个 rollout 阶段和一个训练阶段。在 rollout 阶段,由中央主节点协调的 rollout 工作器通过与模型交互生成 rollout 轨迹,产生对各种输入的响应序列。这些轨迹随后被存储在回放缓冲区中,通过打破时间相关性来确保训练数据的多样性和无偏性。在随后的训练阶段,训练工作器访问这些经验来更新模型的权重。这种循环过程使模型能够不断从其行为中学习,随着时间的推移调整其策略以提高性能。
The central master serves as the central conductor, managing the flow of data and communication between the rollout workers, trainer workers, evaluation with reward models and the replay buffer. It ensures that the system operates harmoniously, balancing the load and facilitating efficient data processing.
中央主节点作为中央调度器,管理着数据流和通信,协调 rollout 工作节点、训练工作节点、奖励模型评估以及回放缓冲区之间的交互。它确保系统和谐运行,平衡负载并促进高效的数据处理。
The trainer workers access these rollout trajectories, whether completed in a single iteration or divided across multiple iterations, to compute gradient updates that refine the model's parameters and enhance its performance. This process is overseen by a reward model, which evaluates the quality of the model's outputs and provides essential feedback to guide the training process. The reward model's evaluations are particularly pivotal in determining the effectiveness of the model's strategies and steering the model towards optimal performance.
训练器工作器访问这些 rollout 轨迹(无论是单次迭代完成还是跨多次迭代分割),以计算梯度更新,从而优化模型的参数并提升其性能。这一过程由奖励模型监督,奖励模型评估模型输出的质量,并提供必要的反馈以指导训练过程。奖励模型的评估在确定模型策略的有效性和引导模型实现最佳性能方面尤为关键。
Moreover, the system incorporates a code execution service, which is specifically designed to handle code-related problems and is integral to the reward model. This service evaluates the model's outputs in practical coding scenarios, ensuring that the model's learning is closely aligned with real-world programming challenges. By validating the model's solutions against actual code executions, this feedback loop becomes essential for refining the model's strategies and enhancing its performance in code-related tasks.
此外,该系统还集成了一个代码执行服务,专门用于处理与代码相关的问题,并且是奖励模型的重要组成部分。该服务在实际编码场景中评估模型的输出,确保模型的学习与现实世界的编程挑战紧密结合。通过将模型的解决方案与实际代码执行进行验证,这一反馈循环对于优化模型的策略和提升其在代码相关任务中的表现至关重要。
# 2.6.2 Partial Rollouts for Long CoT RL
# 2.6.2 长链思维强化学习中的部分展开
One of the primary ideas of our work is to scale long-context RL training. Partial rollouts is a key technique that effectively addresses the challenge of handling long-CoT features by managing the rollouts of both long and short trajectories. This technique establishes a fixed output token budget, capping the length of each rollout trajectory. If a trajectory exceeds the token limit during the rollout phase, the unfinished portion is saved to the replay buffer and continued in the next iteration. It ensures that no single lengthy trajectory monopolizes the system's resources. Moreover, since the rollout workers operate asynchronously, when some are engaged with long trajectories, others can independently process new, shorter rollout tasks. The asynchronous operation maximizes computational efficiency by ensuring that all rollout workers are actively contributing to the training proces, thereby optimizing the overall performance of the system.
我们工作的主要思想之一是扩展长上下文强化学习(RL)训练。部分展开(Partial rollouts)是一项关键技术,通过管理长轨迹和短轨迹的展开,有效解决了处理长上下文特征(long-CoT features)的挑战。该技术设定了固定的输出Token预算,限制了每次展开轨迹的长度。如果在展开阶段轨迹超过了Token限制,未完成的部分将被保存到回放缓冲区中,并在下一次迭代中继续处理。这确保了单个长轨迹不会独占系统资源。此外,由于展开工作器是异步运行的,当某些工作器处理长轨迹时,其他工作器可以独立处理新的、较短的展开任务。这种异步操作通过确保所有展开工作器都积极参与训练过程,最大限度地提高了计算效率,从而优化了系统的整体性能。
As illustrated in Figure 3b, the partial rollout system works by breaking down long responses into segments across iterations (from iter n-m to iter n). The Replay Buffer acts as a central storage mechanism that maintains these response segments, where only the current iteration (iter n) requires on-policy computation. Previous segments (iter n-m to \$\mathsf{n}\!-\!1\$ ) can be efficiently reused from the buffer, eliminating the need for repeated rollouts. This segmented approach significantly reduces the computational overhead: instead of rolling out the entire response at once, the system processes and stores segments increment ally, allowing for the generation of much longer responses while maintaining fast iteration times. During training, certain segments can be excluded from loss computation to further optimize the learning process, making the entire system both efficient and scalable.
如图 3b 所示,部分回放系统通过将长响应分解为跨迭代的片段(从迭代 n-m 到迭代 n)来工作。回放缓冲区 (Replay Buffer) 作为中央存储机制,维护这些响应片段,其中只有当前迭代 (iter n) 需要在线策略计算。之前的片段(迭代 n-m 到 \$\mathsf{n}\!-\!1\$)可以从缓冲区中高效地重复使用,从而消除了重复回放的需求。这种分段方法显著减少了计算开销:系统不是一次性回放整个响应,而是逐步处理和存储片段,从而能够在保持快速迭代时间的同时生成更长的响应。在训练过程中,某些片段可以从损失计算中排除,以进一步优化学习过程,使整个系统既高效又可扩展。
The implementation of partial rollouts also offers repeat detection. The system identifies repeated sequences in the generated content and terminates them early, reducing unnecessary computation while maintaining output quality. Detected repetitions can be assigned additional penalties, effectively discouraging redundant content generation in the promptset.
部分 rollout 的实现还提供了重复检测功能。系统会识别生成内容中的重复序列并提前终止它们,从而在保持输出质量的同时减少不必要的计算。检测到的重复可以被分配额外的惩罚,从而有效减少提示集中冗余内容的生成。
# 2.6.3 Hybrid Deployment of Training and Inference
# 2.6.3 训练与推理的混合部署
The RL training process comprises of the following phases:
RL训练过程包括以下几个阶段:

Figure 4: Hybrid Deployment Framework
图 4: 混合部署框架
We find existing works challenging to simultaneously support all the following characteristics.
我们发现现有工作难以同时支持以下所有特性。
As illustrated in Figure 4, we implement this hybrid deployment framework (Section 2.6.3) on top of Megatron and vLLM, achieving less than one minute from training to inference phase and about ten seconds conversely.
如图 4 所示,我们在 Megatron 和 vLLM 上实现了这种混合部署框架 (第 2.6.3 节),从训练到推理阶段的时间不到一分钟,反之则大约为十秒。
Hybrid Deployment Strategy We propose a hybrid deployment strategy for training and inference tasks, which leverages Kubernetes Sidecar containers sharing all available GPUs to collocate both workloads in one pod. The primary advantages of this strategy are:
混合部署策略
我们提出了一种用于训练和推理任务的混合部署策略,该策略利用 Kubernetes Sidecar 容器共享所有可用的 GPU,将两种工作负载共置在一个 Pod 中。该策略的主要优势是:
· It facilitates efficient resource sharing and management, preventing train nodes idling while waiting for inference nodes when both are deployed on separate nodes. · Leveraging distinct deployed images, training and inference can each iterate independently for better performance. · The architecture is not limited to vLLM, other frameworks can be conveniently integrated.
· 它促进了高效的资源共享和管理,防止训练节点在等待推理节点时闲置,当两者部署在单独的节点上时。
· 利用不同的部署镜像,训练和推理可以各自独立迭代以获得更好的性能。
· 该架构不仅限于 vLLM,其他框架也可以方便地集成。
Checkpoint Engine Checkpoint Engine is responsible for managing the lifecycle of the vLLM process, exposing HTTP APIs that enable triggering various operations on vLLM. For overall consistency and reliability, we utilize a global metadata system managed by the etcd service to broadcast operations and statuses.
Checkpoint Engine 负责管理 vLLM 进程的生命周期,并暴露 HTTP API,以便触发对 vLLM 的各种操作。为了确保整体一致性和可靠性,我们使用由 etcd 服务管理的全局元数据系统来广播操作和状态。
It could be challenging to entirely release GPU memory by vLLM offloading primarily due to CUDA graphs, NCCL buffers and NVIDIA drivers. To minimize modifications to vLLM, we terminate and restart it when needed for better GPU utilization and fault tolerance.
由于 CUDA 图、NCCL 缓冲区和 NVIDIA 驱动程序的限制,通过 vLLM 卸载完全释放 GPU 内存可能具有挑战性。为了尽量减少对 vLLM 的修改,我们在需要时终止并重新启动它,以提高 GPU 利用率和容错性。
The worker in Megatron converts the owned checkpoints into the Hugging Face format in shared memory. This conversion also takes Pipeline Parallelism and Expert Parallelism into account so that only Tensor Parallelism remains in these checkpoints. Checkpoints in shared memory are subsequently divided into shards and registered in the global metadata system. We employ Mooncake to transfer checkpoints between peer nodes over RDMA. Some modifications to vLLM are needed to load weight files and perform tensor parallelism conversion.
Megatron 中的工作器将拥有的检查点转换为共享内存中的 Hugging Face 格式。此转换还考虑了流水线并行 (Pipeline Parallelism) 和专家并行 (Expert Parallelism),因此这些检查点中仅保留张量并行 (Tensor Parallelism)。共享内存中的检查点随后被分片并注册到全局元数据系统中。我们使用 Mooncake 通过 RDMA 在对等节点之间传输检查点。需要对 vLLM 进行一些修改以加载权重文件并执行张量并行转换。
# 2.6.4 Code Sandbox
# 2.6.4 代码沙盒
We developed the sandbox as a secure environment for executing user-submitted code, optimized for code execution and code benchmark evaluation. By dynamically switching container images, the sandbox supports different use cases through MultiPL-E (Cassano, Gouwar, D. Nguyen, S. Nguyen, et al. 2023), DMOJ Judge Server 2, Lean, Jupyter Notebook, and other images.
我们开发了沙盒作为一个安全的环境,用于执行用户提交的代码,并针对代码执行和代码基准评估进行了优化。通过动态切换容器镜像,沙盒支持通过 MultiPL-E (Cassano, Gouwar, D. Nguyen, S. Nguyen, et al. 2023)、DMOJ Judge Server 2、Lean、Jupyter Notebook 等镜像实现不同的用例。
For RL in coding tasks, the sandbox ensures the reliability of training data judgment by providing consistent and repeatable evaluation mechanisms. Its feedback system supports multi-stage assessments, such as code execution feedback and repo-level editing, while maintaining a uniform context to ensure fair and equitable benchmark comparisons across programming languages.
在编码任务的强化学习 (Reinforcement Learning, RL) 中,沙盒通过提供一致且可重复的评估机制,确保训练数据判断的可靠性。其反馈系统支持多阶段评估,例如代码执行反馈和仓库级别的编辑,同时保持统一的上下文,以确保跨编程语言的基准比较公平公正。
We deploy the service on Kubernetes for s cal ability and resilience, exposing it through HTTP endpoints for external integration. Kubernetes features like automatic restarts and rolling updates ensure availability and fault tolerance.
我们将服务部署在 Kubernetes 上以实现可扩展性和弹性,并通过 HTTP 端点对外暴露以进行外部集成。Kubernetes 的自动重启和滚动更新等功能确保了可用性和容错性。
To optimize performance and support RL environments, we incorporate several techniques into the code execution service to enhance efficiency, speed, and reliability. These include:
为了优化性能并支持强化学习(RL)环境,我们在代码执行服务中引入了多种技术,以提高效率、速度和可靠性。这些技术包括:
· Using Crun: We utilize crun as the container runtime instead of Docker, significantly reducing container startup times.
· 使用 Crun:我们采用 crun 作为容器运行时,而非 Docker,这显著减少了容器的启动时间。
· Cgroup Reusing: We pre-create cgroups for container use, which is crucial in scenarios with high concurrency where creating and destroying cgroups for each container can become a bottleneck.
· Cgroup 重用:我们预先为容器使用创建 cgroups,这在并发量高的场景中至关重要,因为为每个容器创建和销毁 cgroups 可能会成为瓶颈。
· Disk Usage Optimization: An overlay filesystem with an upper layer mounted as tmpfs is used to control disk writes, providing a fixed-size, high-speed storage space. This approach is beneficial for ephemeral workloads.
磁盘使用优化:使用一个上层挂载为 tmpfs 的覆盖文件系统来控制磁盘写入,提供固定大小的高速存储空间。这种方法适用于临时工作负载。
| 方法 | 时间 (秒) |
| --- | --- |
| Docker Sandbox | 0.12 0.04 |
| 方法 | 容器/秒 |
| --- | --- |
| Docker Sandbox | 27 120 |
These optimization s improve RL efficiency in code execution, providing a consistent and reliable environment for evaluating RL-generated code, essential for iterative training and model improvement.
这些优化策略提高了代码执行中的强化学习(RL)效率,为评估RL生成的代码提供了一个一致且可靠的环境,这对于迭代训练和模型改进至关重要。
# 3 Experiments
# 3 实验
# 3.1 Evaluation
# 3.1 评估
Since k1.5 is a multimodal model, we conducted comprehensive evaluation across various benchmarks for different modalities. The detailed evaluation setup can be found in Appendix C. Our benchmarks primarily consist of the following three categories:
由于 k1.5 是一个多模态模型,我们在不同模态的多个基准上进行了全面评估。详细的评估设置可以在附录 C 中找到。我们的基准主要包括以下三类:
· Text Benchmark: MMLU (Hendrycks et al. 2020), IF-Eval (J. Zhou et al. 2023), CLUEWSC (L. Xu et al. 2020), C-EVAL (Y. Huang et al. 2023)
· 文本基准:MMLU (Hendrycks et al. 2020), IF-Eval (J. Zhou et al. 2023), CLUEWSC (L. Xu et al. 2020), C-EVAL (Y. Huang et al. 2023)
· Reasoning Benchmark: HumanEval-Mul, Live Code Bench (Jain et al. 2024), Codeforces, AIME 2024, MATH500 (Lightman et al. 2023)
· 推理基准:HumanEval-Mul、Live Code Bench (Jain et al. 2024)、Codeforces、AIME 2024、MATH500 (Lightman et al. 2023)
· Vision Benchmark: MMMU (Yue, Ni, et al. 2024), MATH-Vision (K. Wang et al. 2024), MathVista (Lu et al. 2023)
· 视觉基准:MMMU (Yue, Ni 等, 2024), MATH-Vision (K. Wang 等, 2024), MathVista (Lu 等, 2023)
# 3.2 Main Results
# 3.2 主要结果
K1.5 long-CoT model The performance of the Kimi k1.5 long-CoT model is presented in Table 2. Through long-CoT supervised fine-tuning (described in Section 2.2) and vision-text joint reinforcement learning (discussed in Section 2.3), the model's long-term reasoning capabilities are enhanced significantly. The test-time computation scaling further strengthens its performance, enabling the model to achieve state-of-the-art results across a range of modalities. Our evaluation reveals marked improvements in the model's capacity to reason, comprehend, and synthesize information over extended contexts, representing a advancement in multi-modal AI capabilities.
K1.5 long-CoT 模型
Kimi k1.5 long-CoT 模型的性能如表 2 所示。通过长链思维监督微调(如第 2.2 节所述)和视觉-文本联合强化学习(如第 2.3 节讨论),模型的长期推理能力得到了显著提升。测试时的计算扩展进一步增强了其性能,使模型能够在多种模态上达到最先进的结果。我们的评估表明,模型在扩展上下文中的推理、理解和信息综合能力有了显著提升,代表了多模态 AI 能力的一大进步。
K1.5 short-CoT model The performance of the Kimi \$\mathrm{k}1.5\$ short-CoT model is presented in Table 3. This model integrates several techniques, including traditional supervised fine-tuning (discussed in Section 2.5.2), reinforcement learning (explored in Section 2.3), and long-to-short distillation (outlined in Section 2.4). The results demonstrate that the k1.5 short-CoT model delivers competitive or superior performance compared to leading open-source and proprietary models across multiple tasks. These include text, vision, and reasoning challenges, with notable strengths in natural language understanding, mathematics, coding, and logical reasoning.
K1.5 short-CoT 模型
Kimi \$\mathrm{k}1.5\$ short-CoT 模型的性能如表 3 所示。该模型集成了多种技术,包括传统的监督微调(在第 2.5.2 节中讨论)、强化学习(在第 2.3 节中探讨)以及长到短蒸馏(在第 2.4 节中概述)。结果表明,k1.5 short-CoT 模型在多个任务中表现出与领先的开源和专有模型相当或更优的性能。这些任务包括文本、视觉和推理挑战,尤其在自然语言理解、数学、编码和逻辑推理方面表现出显著优势。
| | 基准 (指标) | 纯语言模型 | | 视觉-语言模型 | | |
| --- | --- | --- | --- | --- | --- | --- | --- |
| | | QwQ-32B Preview | OpenAI 01-mini | QVQ-72B Preview | OpenAI 01 | Kimi k1.5 |
| 推理 | MATH-500 (EM) | 90.6 | 90.0 | | 94.8 | 96.2 |
| | AIME 2024 (Pass@1) | 50.0 | 63.6 | | 74.4 | 77.5 |
| | Codeforces (百分位) | 62 | 88 | | 94 | 94 |
| | LiveCodeBench (Pass@1) | 40.6 | 53.1 | | 67.2 | 62.5 |
| 视觉 | MathVista-Test (Pass@1) | | | 71.4 | 71.0 | 74.9 |
| | MMMU-Val (Pass@1) | | | 70.3 | 77.3 | 70.0 |
| | Math Vision-Full (Pass@1) | | | 35.9 | | 38.6 |
Table 2: Performance of Kimi \$\mathrm{k}1.5\$ long-CoT and flagship open-source and proprietary models. Table 3: Performance of Kimi k1.5 short-CoT and flagship open-source and proprietary models. VLM model performance were obtained from the Open Compass benchmark platform (https://open compass.org.cn/).
表 2: Kimi \$\mathrm{k}1.5\$ 长链思维 (long-CoT) 与旗舰开源和专有模型的性能对比。
表 3: Kimi k1.5 短链思维 (short-CoT) 与旗舰开源和专有模型的性能对比。VLM 模型的性能数据来自 Open Compass 基准平台 (https://opencompass.org.cn/)。
| | Benchmark (指标) | 仅语言模型 | | | 视觉语言模型 | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| | | Qwen2.5LLaMA-3.1DeepSeek 72B-Inst. | 405B-Inst. | V3 | Qwen2-VL( Claude-3.5- Sonnet-1022 | GPT-40 0513 | Kimi k1.5 |
| 文本 | MMLU (EM) | 85.3 | 88.6 | 88.5 | | 88.3 86.5 | 87.2 87.4 |
| | IF-Eval (Prompt Strict) | 84.1 | 86.0 | 86.1 | | 84.3 | 87.2 |
| | CLUEWSC (EM) | 91.4 | 84.7 | 90.9 | | 85.4 87.9 | 91.7 |
| | C-Eval (EM) | 86.1 | 61.5 | 86.5 | | 76.7 76.0 | 88.3 |
| 推理 | MATH-500 (EM) | 80.0 | 73.8 | 90.2 | | 78.3 | 74.6 94.6 |
| | AIME 2024 (Pass@1) | 23.3 | 23.3 | 39.2 | | 16.0 9.3 | 60.8 |
| | HumanEval-Mul (Pass@1) | 77.3 | 77.2 | 82.6 | | 81.7 80.5 | 81.5 |
| | LiveCodeBench (Pass@1) | 31.1 | 28.4 | 40.5 | | 36.3 33.4 | 47.3 |
| 视觉 | MathVista-Test(Pass@1) | | | | 69.7 | 65.3 | 63.8 70.1 |
| | MMMU-Val (Pass@1) | | | | 64.5 | 66.4 69.1 | 68.0 |
| | MathVision-Full (Pass@1) | | | | 26.6 | 35.6 | 30.4 31.0 |
# 3.3 Long Context Scaling
# 3.3 长上下文扩展
We employ a mid-sized model to study the scaling properties of RL with LLMs. Figure 5 illustrates the evolution of both training accuracy and response length across training iterations for the small model variant trained on the mathematical prompt set. As training progresses, we observe a concurrent increase in both response length and performance accuracy. Notably, more challenging benchmarks exhibit a steeper increase in response length, suggesting that the model learns to generate more elaborate solutions for complex problems. Figure 6 indicates a strong correlation between the model's output context length and its problem-solving capabilities. Our final run of \$\mathrm{k}1.5\$ scalesto \$128\mathbf{k}\$ context length and observes continued improvement on hard reasoning benchmarks.
我们使用一个中等规模的模型来研究大语言模型 (LLM) 在强化学习 (RL) 中的扩展特性。图 5 展示了在数学提示集上训练的小模型变体在训练迭代过程中训练准确率和响应长度的变化。随着训练的进行,我们观察到响应长度和性能准确率同时增加。值得注意的是,更具挑战性的基准测试显示出响应长度的更陡峭增加,这表明模型学会了为复杂问题生成更详细的解决方案。图 6 表明模型的输出上下文长度与其解决问题的能力之间存在很强的相关性。我们最终的运行 \$\mathrm{k}1.5\$ 扩展到 \$128\mathbf{k}\$ 的上下文长度,并在困难的推理基准测试中观察到持续的改进。

Figure 5: The changes on the training accuracy and length as train iterations grow. Note that the scores above come from an internal long-cot model with much smaller model size than \$\mathrm{k}1.5\$ long-CoT model. The shaded area represents the \$95\%\$ percentile of the response length.
图 5: 训练准确率和长度随训练迭代次数增加的变化。请注意,上述分数来自一个内部的长链思维模型,其模型规模远小于 \$\mathrm{k}1.5\$ 长链思维模型。阴影区域表示响应长度的 \$95\%\$ 百分位。
# 3.4 Long 2 short
# 3.4 长到短
We compared the proposed long2short RL algorithm with the DPO, shortest rejection sampling, and model merge methods introduced in the Section 2.4, focusing on the token efficiency for the long2short problem (X. Chen et al. 2024), specifically how the obtained long-cot model can benefit a short model. In Figure 7, k1.5-long represents our long-cot model selected for long2short training. k1.5-short w/ rl refers to the short model obtained using the long2short RL training. k1.5-short w/ dpo denotes the short model with improved token efficiency through DPO training. k1.5-short w/ merge represents the model after model merging, while \$\mathrm{k}1.5\$ -short w/ merge \$+\,\mathbf{rs}\$ indicates the short model obtained by applying shortest rejection sampling to the merged model. k1.5-shortest represents the shortest model we obtained during the long2short training. As shown in Figure 7, the proposed long2short RL algorithm demonstrates the highest token efficiency compared other mehtods such as DPO and model merge. Notably, all models in the \$\mathrm{k}1.5\$ series (marked in orange) demonstrate superior token efficiency compared to other models (marked in blue). For instance, k1.5-short w/ rl achieves a Pass \$@1\$ score of 60.8 on AIME2024 (averaged over 8 runs) while utilizing only 3,272 tokens on average. Similarly, \$\mathrm{k}1.5\$ -shortest attains a \$\mathrm{Pass}(\varpi1\$ score of 88.2 on MATH500 while consuming approximately the same number of tokens as other short models.
我们将提出的 long2short RL 算法与第 2.4 节中介绍的 DPO