在2017年,我们写了一篇关于如何存储数十亿条消息的博客文章。我们分享了从使用MongoDB开始但后来迁移数据到Cassandra的过程,因为我们正在寻找一个可扩展、具备容错能力且相对低维护的数据库。我们知道我们会成长,而我们也的确成长了!
我们希望找到一种能够伴随我们成长的数据库,但其维护需求不会随着存储需求的增长而增长。不幸的是,我们发现这并不是现实情况——我们的Cassandra集群出现了严重的性能问题,仅保持其运行就需要不断增加的努力,更不用说改进了。
近六年后,我们发生了很大的变化,我们存储消息的方式也发生了改变。
我们的Cassandra困局
我们将消息存储在一个名为cassandra-messages的数据库中。顾名思义,它运行Cassandra,并存储消息。在2017年,我们运行了12个Cassandra节点,存储了数十亿条消息。
到2022年初,节点数达到了177个,拥有万亿级别的消息。令我们沮丧的是,这是一套高消耗系统——我们的值班团队频繁因为数据库问题被呼叫,延迟不可预测,而且我们需要削减那些变得过于昂贵的维护操作。
是什么导致了这些问题?首先,让我们来研究下一条消息。
CREATE TABLE messages (
channel_id bigint,
bucket int,
message_id bigint,
author_id bigint,
content text,
PRIMARY KEY ((channel_id, bucket), message_id)
) WITH CLUSTERING ORDER BY (message_id DESC);
上述的CQL语句是我们消息模式的简化版本。我们所使用的每一个ID都是一个Snowflake,因此可以按照时间顺序排序。我们通过发送消息所在的频道以及一个桶来分区,该桶是一个静态的时间窗口。这种分区方式意味着在同一Cassandra中,对于给定频道和桶的所有消息都会存储在一起,并在三个节点(或由你设定的副本因子数量)之间复制。
潜在的性能问题是嵌套在这种分区中的:一个仅有少数朋友的服务器发送的消息数量远少于拥有成千上万用户的服务器。
在Cassandra中,读取操作比起写入来说更耗费资源。写入操作会被追加到提交日志中并写入内存结构(称为memtable),最终会刷新到磁盘上。然而,读取操作需要查询memtable和可能的多个SSTable(磁盘上的文件),这是一个更为耗费资源的操作。当用户与服务器互动时,大量的并发读取可能会形成热点分片,我们形象地称之为“热点分片”。结合我们的数据集规模和访问模式,这对我们的集群造成了很大压力。
当我们遇到热点分片时,通常会对整个数据库集群造成延迟影响。如果某个频道和桶对收到大量流量,则节点会愈发努力地试图提供服务,结果却是越来越落后。
其他对这个节点的查询同样受到影响,因为该节点跟不上进度。由于我们以quorum一致性级别执行读取和写入操作,所有服务热点分片的节点的查询都会经历延迟增加,进而影响到更多用户。
集群维护任务也经常产生麻烦。我们常常因未能及时进行压缩而落后(Cassandra压缩磁盘上的SSTable以优化读取性能)。这样一来,不仅我们的读取成本更高,还会看到当节点尝试压缩时造成的延迟级联效应。
我们曾频繁执行称为“小道舞”的操作,即从服务中移除一个节点以使其在没有流量的情况下完成压缩,然后将其重新添加进来以接收来自Cassandra的手动提示信息,再重复这一过程直到压缩积压完成。同时,我们花费大量时间调整JVM垃圾收集器和堆设置,因为GC暂停会导致显著的延迟峰值。
改变我们的架构
消息集群并不是我们唯一的Cassandra数据库。我们还有其他多个集群,每个集群都表现出类似的问题(虽然程度可能不一)。
在我们这篇文章的上一版本中,我们提到了对ScyllaDB的兴趣,这是一种用C++编写的与Cassandra兼容的数据库。它的高性能、更快速的修复、基于每核分配的工作负载隔离(shard-per-core架构)以及零垃圾回收的生活听起来都很吸引人。
尽管ScyllaDB肯定并非无懈可击,但它确实没有垃圾回收,因为它是用C++而不是Java编写的。历史上,我们团队在Cassandra的垃圾回收上经历过许多问题,从GC暂停影响延迟,到连续超长时间的GC暂停,严重到必须手动重启并监控相关节点才能恢复健康。这些问题导致了巨大的值班工作量,也是消息集群稳定性不佳的主要原因。
在试验ScyllaDB并观察到测试中有所改善后,我们决定迁移所有的数据库。虽然做出这一决定本身也可以撰写一篇博客来讨论,但简短地说,在2020年前后,我们已经将除了一个之外的所有数据库迁移到ScyllaDB。
唯一剩下的便是:我们的好友cassandra-messages。
为何还未迁移到ScyllaDB?一方面,它是一个庞大的集群。拥有数万亿条消息和将近200个节点,任何迁移都会是一项艰巨的任务。此外,我们需要确保新数据库在其性能表现上能达到最优。我们还需要更多地在生产环境中使用ScyllaDB,以便充分了解并熟悉它的优劣之处。
我们还致力于为我们的使用场景提升ScyllaDB性能。在测试中,我们发现按反向查询的性能达不到我们的要求。我们在尝试逆序扫描表(如扫描升序消息时)时会用到逆向查询。ScyllaDB团队优先解决了这一问题并实现了高效的逆向查询,这消除了我们迁移计划中的最后一个阻碍项。
我们怀疑仅仅更换数据库并不能让一切问题神奇般解决。ScyllaDB中同样会出现热点分片的现象,因此,我们也希望投资于数据库上游系统的改进,以帮助保护和提升数据库的整体性能。
数据服务处理数据
使用Cassandra时,我们一直面临热点分片的问题。某一分片的高流量会产生无界并发,导致后续查询的延迟不断累积。如果我们能控制到达热点分片的并发量,就能保护数据库免受过载的影响。
为此,我们编写了所谓的数据服务——位于我们的API集群与数据库集群之间的中介服务。编写数据服务时,我们选择了一种在Discord中越来越多使用的语言:Rust!我们之前在几个项目中已经开始使用Rust,它确实达到了宣传的效果。Rust提供了像C/C++那样的速度,而又不会牺牲安全性。
Rust强调无畏的并发作为其一大优势——语言应当轻松地写出安全的并发代码。其库也非常符合我们的目标。Tokio生态系统是构建异步I/O系统的良好基础,语言对Cassandra和ScyllaDB都有驱动支持。
此外,在编译器帮助下,清晰的错误信息、语言构造以及对安全性的重视也使得它非常适合作为开发工具。一旦编译通过时,通常就已经能工作了。最重要的是,它让我们可以说重构为了Rust(梗的信誉至关重要)。
数据服务位于API和ScyllaDB集群之间。它们大约有一个gRPC端点对应一个数据库查询,并且故意没有包含业务逻辑。数据服务提供的最大功能是请求聚合。如果多个用户同时请求相同的行,我们将只查询一次数据库。第一个发出请求的用户将触发服务中一项工作者任务的启动。随后的请求将检查该任务是否存在,并订阅它。那项工作者任务将查询数据库并将行的结果返回给所有订阅者。
这是Rust力量的体现:它使写出安全的并发代码变得容易。
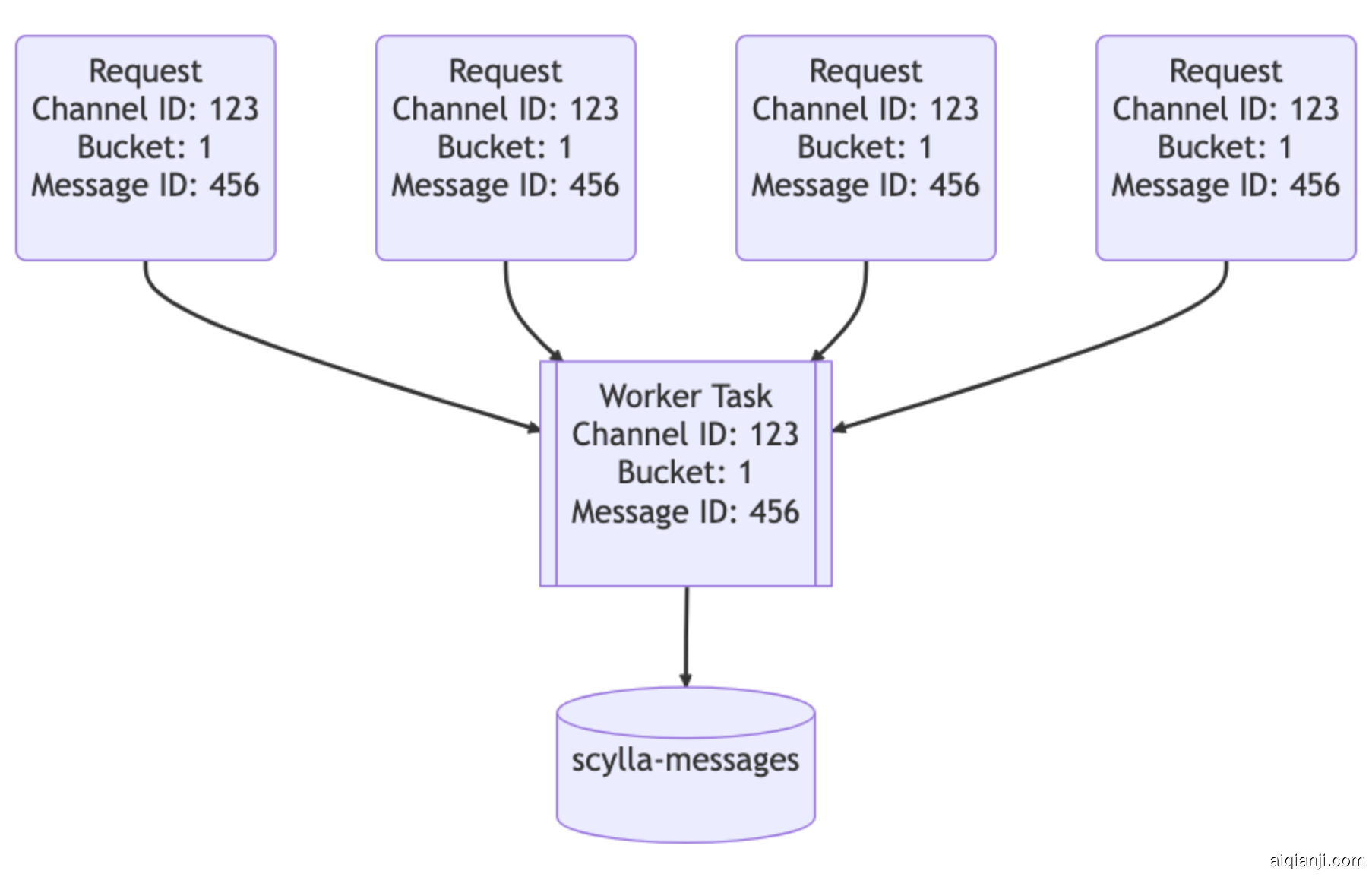
让我们想象一个大型服务器上有一个重要通知,通知所有用户 (@everyone):用户将会打开应用程序并阅读这一消息,导致大量流量涌入数据库。之前,这种情况可能会导致热点分区,并且可能需要值班人员介入帮助系统恢复。通过我们的数据服务,我们可以显著减少针对数据库的流量峰值。
神奇之处的第二部分在于我们数据服务的上游。我们实现了基于一致性哈希的路由到我们的数据服务,以实现更有效的汇聚。对于我们数据服务的每个请求,我们提供一个路由键。对于消息来说,这是一个频道ID,因此对同一频道的所有请求都转到同一个服务实例。这种路由方式进一步有助于降低我们数据库的负载。

这些改进帮助很大,但是它们并不能解决我们所有的问题。我们仍然看到Cassandra集群中的热点分区和延迟增加,只不过没有以前那么频繁了。这给了我们一些时间准备新的ScyllaDB集群,并执行迁移。
一次大规模的迁移
我们迁移的需求非常直接:我们需在不中断服务的情况下迁移数万亿条消息,并且需要快速完成,因为尽管Cassandra的情况已有所改善,但我们在频繁处理各种问题。
第一步很简单:我们使用超磁盘存储拓扑预配置一个新的ScyllaDB集群。通过使用本地SSD来提升速度,并利用RAID将数据镜像到一个持久性磁盘上,从而实现了既有本地磁盘的速度又有持久性磁盘的耐用性。随着集群的构建完毕,我们可以开始向其中迁移数据。
我们的第一稿迁移计划旨在快速取得价值。我们将首先在某个时间点后使用新的ScyllaDB集群来处理新数据,并其后迁移历史数据。这增加了复杂性,但任何大型项目不都是这样吗?
我们开始同时向Cassandra和ScyllaDB写入新数据,并同时启动ScyllaDB的Spark迁移器。它需要大量的调整,一旦设置好后,我们得出估计完成时间:三个月。
这个时间框架没能让我们感到舒服,我们更希望更快地获得价值。我们团队坐下来集思广益,直到想出了一个加快速度的方法。我们记得曾编写过一个快速高效的数据库库,可以将其扩展。于是,我们决定进行一些梗文化的工程活动,重写数据迁移器,用Rust重新开发。
在一个下午的时间里,我们扩展了我们的数据服务库以执行大规模的数据迁移。这种方法从数据库中读取令牌范围,通过SQLite本地检查点,然后像水流一样导入到ScyllaDB中。我们接入新的改进迁移器后得到的新估计时间:九天!如果能如此迅速地迁移数据,那么我们可以放弃复杂的基于时间的方法,而一次性切换所有内容。
我们开启它,并让它持续运行,在几天内,每秒最多传输320万条消息。数日后,我们一起观察进度达到100%,却发现进度卡在了99.9999%(真的)。这是因为我们的迁移器在读取最后几个数据令牌范围时超时了,因为这些令牌范围内含有庞大的Tombstone范围,而这些在Cassandra中从未被压缩掉。我们对这个令牌范围进行了压缩,几秒钟后,迁移完成!
我们通过将一小部分读取请求发送到两个数据库并比较结果来进行自动化数据验证,一切正常。集群在全生产流量下的表现良好,而Cassandra集群则面临着越来越频繁的延迟问题。我们在团队现场会面时,切换至以ScyllaDB作为主要数据库,并一起庆祝了一番!
几个月之后…
我们在2022年5月切换了消息数据库,但它此后表现如何?
它一直是一个安静的、表现良好的数据库(这么说没关系因为我这周不是值班人员)。我们不再需要整个周末时间来处理故障,也不再需要在集群节点间来回调整以保持服务正常运行。这是一个更为高效的数据库——我们将运行的Cassandra节点数从177个减少到了72个ScyllaDB节点。每个ScyllaDB节点有9TB的磁盘空间,而每个Cassandra节点平均只有4TB。
我们的尾部延迟也得到了显著改善。例如,在Cassandra上获取历史消息时p99延迟为40到125毫秒之间,而在ScyllaDB上这一数字稳定在15毫秒;消息插入性能方面,Cassandra上的p99延迟为5到70毫秒,而在ScyllaDB上稳定在5毫秒。由于上述性能改进,我们现在可以在信任的消息数据库支持下解锁新的产品使用案例。
到2022年底,全世界的人都在观看世界杯。我们很快发现进球情况会在我们的监控图上显示出来。这很酷是因为不仅能够在系统中看到实际事件的变化很有趣,而且还给团队提供了一个在会议期间‘主动监测系统性能表现’的借口。毕竟这不是在‘会议期间看球’,而是‘主动保证系统性能’。

我们可以通过消息发送图表讲述了世界杯决赛的故事。比赛十分精彩,莱昂内尔·梅西想要在职业生涯最后阶段再次证明自己的伟大,并带领阿根廷队夺冠,然而在他面前的是才华横溢的基利安·姆巴佩和他的法国队。
图表中每一个突增点都代表比赛中的一次重大事件:
- 梅西射入一粒点球,阿根廷1-0领先。
- 阿根廷再度进球,将比分改写为2-0。
- 中场休息时出现了长达十五分钟的平稳阶段,用户在讨论比赛。
- 姆巴佩为法国进一球,并在90秒后再下一城,比分被扳平!
- 正常比赛结束,进入加时赛。
- 在加时赛的前半段,几乎什么事情都没发生,但中场后用户们又开始讨论。
- 梅西再次进球,阿根廷再度领先!
- 姆巴佩反击得分,双方再次战平!
- 加时赛结束,进入点球大战。
- 点球大战过程中紧张而又充满期待,最终法国罚失一个点球而阿根廷全部命中,阿根廷夺冠!

全世界的观众都在紧张地观看这场比赛,但在整个过程中,Discord和我们的消息数据库完全没有压力。消息发送量暴增,但我们完全应对自如。通过基于Rust的数据服务和ScyllaDB,我们能够应付这一流量,并为用户提供交流平台。