OmniThink: Expanding Knowledge Boundaries in Machine Writing through Thinking
OmniThink:通过思考扩展机器写作的知识边界
Abstract
摘要摘要
Machine writing with large language models often relies on retrieval-augmented generation. However, these approaches remain confined within the boundaries of the model’s predefined scope, limiting the generation of content with rich information. Specifically, vanilla-retrieved information tends to lack depth, utility, and suffers from redundancy, which negatively impacts the quality of generated articles, leading to shallow, repetitive, and unoriginal out- puts. To address these issues, we propose OmniThink, a machine writing framework that emulates the human-like process of iterative expansion and reflection. The core idea behind OmniThink is to simulate the cognitive behavior of learners as they progressively deepen their knowledge of the topics. Experimental results demonstrate that OmniThink improves the knowledge density of generated articles without compromising metrics such as coherence and depth. Human evaluations and expert feedback further highlight the potential of OmniThink to address real-world challenges in the generation of long-form articles.
大大语言模型的机器写作通常依赖于检索增强生成。然而,这些方法仍局限于模型预定义的范围,限制了生成内容丰富的信息。具体而言,普通检索的信息往往缺乏深度和实用性,并且存在冗余,这影响了生成文章的质量,导致输出内容浅显、重复且缺乏原创性。为了解决这些问题,我们提出了 OmniThink,一种模拟人类迭代扩展和反思过程的机器写作框架。OmniThink 的核心思想是模拟学习者在逐步加深对主题理解过程中的认知行为。实验结果表明,OmniThink 在不影响连贯性和深度等指标的情况下,提高了生成文章的知识密度。人类评估和专家反馈进一步强调了 OmniThink 在生成成长篇内容方面应对现实挑战的潜力。
1 Introduction
1 引言
“Education is not the learning of facts, but the training of the mind to think.”
教育教育不是学习事实,而是训练思维。
— Albert Einstein
—— Albert Einstein
Writing is a continuous process of collecting information and thinking (Bean and Melzer, 2021). Recent advances in Large Language Models (LLMs) have demonstrated remarkable progress in machine writing such as open domain long-form generation (Liang et al., 2023; Yang et al., 2023; Zhao et al., 2024) or report generation on specific topics (Liu et al., 2018). To seek useful information, as shown in Figure 1, early attempts use Retrieval Augmented Generation (RAG) to expand new information on a given topic (Gao et al., 2024;
写作写作是一个不断收集信息和思考的过程 (Bean and Melzer, 2021)。近年来,大语言模型 (LLMs) 在机器写作方面取得了显著进展,例如开放领域的长篇生成 (Liang et al., 2023; Yang et al., 2023; Zhao et al., 2024) 或特定主题的报告生成 (Liu et al., 2018)。为了寻求有用信息,如图 1 所示,早期的尝试使用检索增强生成 (RAG) 来扩展给定主题的新信息 (Gao et al., 2024;

Figure 1: Previous machine writing approaches only expand new information or perspective via RAG and roleplaying. OmniThink expands knowledge boundaries through continuous reflection and exploration, attaching knowledge to an information tree and extracting it into a conceptual pool to deepen understanding and uncover more in-depth content.
图图 1: 以往的机器写作方法仅通过RAG(检索增强生成)和角色扮演来扩展新信息或视角。OmniThink通过持续的反思和探索扩展知识边界,将知识附加到信息树中并从中提取到概念池,以深化理解并揭示更深层次的内容。
Edge et al., 2024). However, vanilla RAG relies on a fixed set of search strategies (Ram et al., 2023), which lack diversity in generation, preventing a thorough exploration of the topic and result- ing in a fragmented and incomplete understanding of the subject (Spink et al., 1998). To address this issue, STORM (Shao et al., 2024a) and CoSTORM (Jiang et al., 2024) have proposed a roleplay approach designed to expand the perspective, which means collecting information from multiple perspectives, thus broadening the information space (Shen et al., 2023; Shanahan et al., 2023; Parmar et al., 2010). Yet these approaches are still being thought within the scope of one’s own role, making it difficult to generate deep content and break through one’s own knowledge boundaries(Ji et al., 2025). In particular, retrieved information often lacks depth, utility and redundancy, directly affecting the quality of generated articles, resulting in shallow, repetitive, and unoriginal outputs (Skarlinski et al., 2024).
EdgeEdge 等人, 2024)。然而,传统的 RAG 依赖于一组固定的搜索策略 (Ram 等人, 2023),这导致生成内容缺乏多样性,无法深入探索主题,导致对主题的理解碎片化且不完整 (Spink 等人, 1998)。为解决这一问题,STORM (Shao 等人, 2024a) 和 CoSTORM (Jiang 等人, 2024) 提出了一种角色扮演方法,旨在扩展视角,即从多个角度收集信息,从而拓宽信息空间 (Shen 等人, 2023; Shanahan 等人, 2023; Parmar 等人, 2010)。然而,这些方法仍然局限于角色自身的范围,难以生成深度内容并突破自身的知识边界 (Ji 等人, 2025)。特别是,检索到的信息往往缺乏深度、实用性和冗余性,直接影响生成文章的质量,导致输出内容浅显、重复且缺乏原创性 (Skarlinski 等人, 2024)。
Note that humans can naturally avoid such pitfalls in the writing process. This phenomenon can be explained through the theory of reflective practice, a concept rooted in cognitive science (Osterman, 1990). According to this theory, human writers continuously reflect on previously gathered information and personal experiences, allowing them to reorganize, filter, and refine their cognitive framework. This process prompts writers to iterative ly adjust their writing direction and mental pathways, ultimately allowing human authors to generate more profound, nuanced and original content (Bruce, 1978).
需要注意的是需要注意的是,人类在写作过程中能够自然地规避此类陷阱。这种现象可以通过反思实践理论来解释,该理论源于认知科学 [20]。根据这一理论,人类作者会不断地反思之前收集的信息和个人经验,从而重组、过滤并完善其认知框架。这一过程促使作者迭代地调整写作方向和思维路径,最终使人类作者能够生成更深刻、细致且原创的内容 [21]。
Motivated by this, we propose OmniThink, a new machine writing framework that emulates the human-like cognitive process of iterative expansion and reflection. The core idea behind OmniThink is to simulate the cognitive behavior of learners as they gradually deepen their understanding of complex topics to expand knowledge boundaries. By continuously reflecting on previously retrieved information, OmniThink can determine the optimal steps for further expansion. This expansionreflection mechanism enables the dynamic adjustment of the retrieval strategies, fostering a more thorough and comprehensive exploration of relevant information. Once a diverse set of information has been gathered, OmniThink transitions to the stages of outline construction and article generation. This iterative thinking process leads to the production of articles of higher quality that contain a higher knowledge density of useful, insightful, and original content.
为此为此,我们提出了 OmniThink,一种模仿人类迭代扩展与反思认知过程的机器写作框架。OmniThink 的核心思想是模拟学习者在逐步加深对复杂主题理解以扩展知识边界时的认知行为。通过对先前检索到的信息进行持续反思,OmniThink 能够确定进一步扩展的最佳步骤。这种扩展-反思机制使检索策略能够动态调整,从而促进对相关信息的更深入、更全面的探索。一旦收集到多样化的信息,OmniThink 就进入提纲构建和文章生成的阶段。这种迭代思维过程能够生成更高质量的文章,其中包含更多有用、有洞察力和原创内容的知识密度。
We evaluate OmniThink on the WildSeek datasets (Jiang et al., 2024) based on previous metrics as well as a new metric, named knowledge density. Experimental results demonstrate that OmniThink enhances the knowledge density of generated articles without compromising key metrics such as coherence and depth. Human evaluations and expert feedback further underscore the potential of our approach in addressing real-world challenges in the the generation of long-form articles. To conclude, our main contributions are as follows:
我们在我们在 WildSeek 数据集 (Jiang et al., 2024) 上基于之前的指标以及一个名为知识密度度的新指标对 OmniThink 进行了评估。实验结果表明,OmniThink 在生成的文章中提升了知识密度,同时并未损害诸如连贯性和深度等关键指标。人类评估和专家反馈进一步强调了我们的方法在解决生成长文形式文章中的现实挑战方面的潜力。总结来说,我们的主要贡献如下:
2 Background
2 背景
2.1 Task Definition
22.1 任务定义
We focus on the task of open-domain long-form generation for machine writing, which involves retrieving information from an open domain and synthesizing it into a coherent article (Fan et al., 2019; Su et al., 2022; Quan et al., 2024). Given an input topic T, the target of open-domain longform generation is to generate a long article $\boldsymbol{\mathcal{A}}$ . The current standard approach involves two major steps (Zhang et al., 2019; Zheng et al., 2023): $(i)$ Use a search engine $\mathcal{S}$ to retrieve information ${\mathcal{T}}={\mathcal{S}}(\mathrm{T})$ which is related to the topic T; (ii) Generate an outline O = Generate $(\mathcal{T},\mathrm{T})$ based on the retrieved information $\mathcal{T}$ and input topic T. Finally, the article is generated using the outline, expressed as $A=$ Generate $(O,{\mathcal{T}})$ .
我们我们关注机器写作中的开放域长文本生成任务,该任务涉及从开放域中检索信息并将其综合成一篇连贯的文章 (Fan et al., 2019; Su et al., 2022; Quan et al., 2024)。给定一个输入主题 T,开放域长文本生成的目标是生成一篇长文章 $\boldsymbol{\mathcal{A}}$。目前的标准方法包括两个主要步骤 (Zhang et al., 2019; Zheng et al., 2023):$(i)$ 使用搜索引擎 $\mathcal{S}$ 检索与主题 T 相关的信息 ${\mathcal{T}}={\mathcal{S}}(\mathrm{T})$;(ii) 根据检索到的信息 $\mathcal{T}$ 和输入主题 T 生成大纲 $O = Generate (\mathcal{T},\mathrm{T})$。最后,使用大纲生成文章,表示为 $A= Generate (O,{\mathcal{T}}$)。
2.2 Revisiting Previous Methods
2.2 回顾先前的方法
Previous works have made numerous efforts to improve the quality of open-domain long-form generation. Co-STORM (Jiang et al., 2024) introduces a user-participatory roundtable discussion in step $(i)$ to enhance the diversity of the retrieved information. STORM (Shao et al., 2024a) proposes a questioning mechanism to improve the quality and relevance of the generated outlines in step (ii).
先前先前的研究为提高开放域长文本生成的质量做出了诸多努力。Co-STORM (Jiang et al., 2024) 在步骤 $(i)$ 中引入了用户参与的圆桌讨论,以增强检索信息的多样性。STORM (Shao et al., 2024a) 则提出了一种提问机制,以提高步骤 (ii) 中生成提纲的质量和相关性。
Although substantial progress has been made in open-domain long-form generation, a persistent challenge remains: the generated content frequently suffers from excessive repetition and lacks substantial information. We present a case generated by STORM (Shao et al., 2024a) with GPT-4o as the backbone, as shown in Figure 2. In this article, the phrase “AlphaFold was developed by Deep
尽管尽管在开放域长文本生成领域已取得显著进展,但一个持续的挑战依然存在:生成的内容往往出现过多重复,且缺乏实质性信息。我们展示了由 GPT-4o 作为核心的 STORM (Shao et al., 2024a) 生成的案例,如图 2 所示。在这篇文章中,短语“AlphaFold 是由 Deep”
Mind” appears multiple times, whereas it could have been stated only once in the initial mention.
““Mind”多次出现,而它本可以在初次提及及时就只陈述一次。

Figure 2: A case generated by STORM using GPT4o on the topic of AlphaFold. We have marked the repeated expressions in the article regarding “AlphaFold is developed by DeepMind”.
图图 2: 使用 GPT4o 在 AlphaFold 主题上生成的 STORM 案例。我们标记了文章中关于“AlphaFold 由 DeepMind 开发”的重复表达。
2.3 Knowledge Density for the Article
2.3 文章的知识密度
Previous works mostly focus on whether the article is relevant and correct, but do not consider whether the article has sufficient depth(Li et al., 2024; Que et al., 2024; Liu et al., 2024). Many generated arti- cles contain a lot of redundant information, which is very inconsistent with human writing. To address this, we introduce the Knowledge Density (KD) for the generated article, which is defined as the ratio of meaningful content to the overall volume of text ( $\mathrm{Xu}$ and Reitter, 2017) as:
先前先前的工作大多关注文章是否相关和正确,但未考虑文章是否具有足够的深度(Li等,2024;Que等,2024;Liu等,2024)。许多生成的文章包含大量冗余信息,这与人类的写作方式非常不一致。为了解决这个问题,我们引入了生成文章的知识密度(Knowledge Density,KD),其定义为有意义内容与整体文本量的比率(Xu和Reitter,2017):

where $N$ is the total number of atomic knowledge units identified within the document. The function $\mathcal{U}(k_{i})$ indicates whether the $i$ -th unit information $k_{i}$ is unique. $L$ represents the total length of the text. In this formula, the numerator represents the sum of unique units of atomic knowledge extracted from a long article. The denominator corresponds to the length of the article.
其中其中 $N$ 是文档中识别的原子知识单元的总数。函数 $\mathcal{U}(k_{i})$ 表示第 $i$ 个单元信息 $k_{i}$ 是否唯一。$L$ 表示文本的总长度。在此公式中,分子表示从长文中提取的独特原子知识单元的总和。分母对应于文章的长度。
Note that the value of the knowledge density metric lies in its ability to measure the reading cost of generated text from the perspective of information acquisition (Bovair and Kieras, 1991; Dos Santos and Mookerjee, 1993). Readers encountering low KD content often experience fatigue, frustration, or disengagement due to redundant or irrelevant details. In contrast, high-density content provides a streamlined experience, enabling efficient knowledge transfer.
注意注意,知识密度 (Knowledge Density) 指标的价值在于它能够从信息获取的角度衡量生成文本的阅读成本 (Bovair and Kieras, 1991; Dos Santos and Mookerjee, 1993)。读者在遇到低知识密度内容时,往往会因为冗余或不相关的细节而感到疲劳、沮丧或失去兴趣。相比之下,高密度内容提供了简洁的体验,促进了高效的知识传递。
Previous methods exhibit limited performance on the proposed KD due to the fact that the generated content in open-domain long-form generation must be based on the retrieved information. When the retrieved information is not sufficiently diverse, it often contains large amounts of redundant and repetitive content, leading to repetition and redundancy in the generated article. This leaves room for optimizing the knowledge density in open-domain long-form generation. We can address this issue by incorporating reasoning and planning during Step $(i)$ , where we process the gathered content to extract non-overlapping, high-density information(Qiao et al., 2023; Zelikman et al., 2024).
先前先前的方法在建议的知识密度(KD)上表现出有限的性能,这是因为开放域长文本生成中的生成内容必须基于检索到的信息。当检索到的信息不够多样化时,通常包含大量冗余和重复内容,导致生成的文章重复和冗余。这为优化开放域长文本生成中的知识密度留下了空间。我们可以通过在步骤 $(i)$ 中引入推理和规划来解决这个问题,即处理收集到的内容以提取非重叠、高密度的信息 (Qiao et al., 2023; Zelikman et al., 2024)。

Figure 3: We divide OmniThink into three steps. During the Information Acquisition phase, OmniThink pri- marily forms an Information Tree and Conceptual Pool through continuous Expansion and Reflection, which serve as the foundation for subsequent outline structuring and article composition.
图图 3: 我们将 OmniThink 分为三个步骤。在信息获取阶段,OmniThink 主要通过持续的扩展和反思形成信息树和概念池,这些将成为后续大纲结构和文章撰写的基础。
3 OmniThink
3 OmniThink
As shown in Figure 3, we introduce a machine writing framework OmniThink, which emulates the human-like process of iterative reflection and expansion. OmniThink can be divided into three steps: Information Acquisition (§3.1), Outline Structuring (§3.2), and Article Composition (§3.3).
如图如图 3 所示,我们引入了一个机器写作框架 OmniThink,它模拟了类似人类的迭代反思和扩展过程。OmniThink 可以分为三个步骤:信息获取 (§3.1)、提纲构建 (§3.2) 和文章撰写 (§3.3)。
3.1 Information Acquisition
33.1 信息获取
To acquire diverse and comprehensive information, OmniThink emulates the human learning process, progressively deepening its understanding of the topic through iterative Expansion and Reflection. As shown in Figure 4, we illustrate the specific process of Expansion and Reflection. This iterative process culminates in the construction of an information tree $\tau$ , which organizes the retrieved information in a structured and hierarchical manner, and a conceptual pool $\mathcal{P}$ , which represents the LLMs’ current understanding of the topic at time step $m$ . Together, these components form the foundation of article generation.
为为获取多样且全面的信息,OmniThink 模拟人类学习过程,通过迭代的扩展(Expansion)和反思(Reflection)逐步加深对主题的理解。如图 4 所示,我们展示了扩展和反思的具体过程。这一迭代过程最终构建了一个信息树 $\tau$ ,它以结构化和层级化的方式组织检索到的信息,以及一个概念池 $\mathcal{P}$ ,它代表大语言模型在时间步 $m$ 时对主题的当前理解。这些组件共同构成了文章生成的基础。

Figure 4: The spec if Tih ce cop nrc e opt cs emsarske do wfi thE thxe spaamen csolioor snch eamne idn thRe dei a fg rla emc rte i pores ne nit n OmniThink. The concepts marked with the same color scheme in the dki in as hg ip rraelamtio nrsheipps r beets we een n tt hke ci on nc se hp tis.p relationships or progressive relationships between the concepts. $\left(\mathbb{1}\right)$ - $\textcircled{4},$ ) illustrate the specific process of a single Expansion and Reflection cycle in OmniThink.
图图 4: Tih ce cop nrc e opt cs emsarske do wfi thE thxe spaamen csolioor snch eamne idn thRe dei a fg rla emc rte i pores ne nit n OmniThink. 图中相同颜色方案标记的概念表示它们之间的层次关系或递进关系。$\left(\mathbb{1}\right)$ - $\textcircled{4},$ ) 展示了OmniThink中单个扩展与反思循环的具体过程。
Initialization The interactive process begins with the initialization of a root node based on the input topic T. OmniThink first utilizes search engines, e.g., Google, or Bing, to retrieve information related to $\mathrm{T}$ , using the retrieved knowledge to construct the initial root node of the information tree $N_{r}$ . This initial information in $N_{r}$ is then organized and analyzed to form a preliminary conceptual pool $\mathcal{P}_{0}$ , which serves as OmniThink’s foundational under standing of the topic and guides subsequent expansion and reflection processes.
初始化初始化
交互过程从根据输入主题 T 初始化根节点开始。OmniThink首先利用搜索引擎(例如 Google 或 Bing)检索与 $\mathrm{T}$ 相关的信息,并利用检索到的知识构建信息树的初始根节点 $N_{r}$。然后将 $N_{r}$ 中的初始信息进行组织和分析,形成初步的概念池 $\mathcal{P}_{0}$,这部分内容作为OmniThink对该主题的基础理解,并指导后续的扩展和反思过程。
3.1.1 Expansion
33.1.1 扩展
At time step $m$ , OmniThink analyzes all leaf nodes ${{L}{m}}\mathrm{=}{{{N}{0}},{{N}{1}},...,{{N}{n}}}$ of the information tree ${\mathcal{T}}{m}$ . These leaf nodes are first stored in the conceptual buffer $\mathcal{P}{b}$ , where each node is evaluated to determine if it requires further expansion. For nodes that need expansion, OmniThink uses the current conceptual pool ${\mathcal{P}}{m}$ to identify areas for deeper expansion or suitable directions for expansion. For each leaf node $N{i}$ , OmniThink generates $k_{N_{i}}$ sub-nodes, denoted as $\begin{array}{r l}{\mathbf{SUB}(N_{i})}&{{}=}\end{array}$ ${S_{0},S_{1},\ldots,S_{k_{N_{i}}}}$ , for expansion. Each sub-node represents a specific aspect or subtopic identified from the current node $N_{i}$ . For each sub-node, OmniThink retrieves relevant information and stores it within the respective node, subsequently adding the sub-node to the appropriate position in the updated information tree ${\tau_{m+1}}$ as follows:
在在时间步骤 $m$,OmniThink 分析信息树 ${\mathcal{T}}{m}$ 的所有叶节点 ${{L}{m}}\mathrm{=}{{{N}{0}},{{N}{1}},...,{{N}{n}}}$。这些叶节点首先被存储在概念缓冲区 $\mathcal{P}{b}$ 中,其中每个节点被评估以确定是否需要进一步扩展。对于需要扩展的节点,OmniThink 使用当前概念池 ${\mathcal{P}}{m}$ 来确定需要深入扩展的领域或适合的扩展方向。对于每个叶节点 $N{i}$,OmniThink 生成 $k_{N_{i}}$ 个子节点,记为 $\begin{array}{r l}{\mathbf{SUB}(N_{i})}&{{}=}\end{array}$ ${S_{0},S_{1},\ldots,S_{k_{N_{i}}}}$,以进行扩展。每个子节点代表从当前节点 $N_{i}$ 中识别出的特定方面或子主题。对于每个子节点,OmniThink 检索相关信息并将其存储在相应的节点中,随后将该子节点添加到更新后的信息树 ${\tau_{m+1}}$ 的适当位置,如下所示:

This targeted retrieval process ensures that OmniThink collects comprehensive and in-depth content for each sub-node, thereby enriching the hierarchical structure of the information tree.
这种这种定向检索过程确保 OmniThink 为每个子节点收集全面而深入的内容,从而丰富信息树的层次结构。
3.1.2 Reflection
33.1.2 反思
In this phase, OmniThink reflects the newly retrieved information in all leaf nodes $L_{m+1}~=$ ${N_{0},...N_{n}}$ . The information retrieved from each leaf node is analyzed, filtered, and synthesized to distill the core insights $I_{m+1}={\mathrm{INS}_{0},...,\mathrm{INS}_{n}}$ These refined insights are then incorporated into the conceptual pool ${\mathcal{P}}_{m}$ , which is continuously updated and enriched throughout the process as follows:
在此在此阶段,OmniThink 将所有叶子节点 $L_{m+1}~=$ ${N_{0},...N_{n}}$ 中新检索到的信息进行反映。从每个叶子节点中检索到的信息会被分析、过滤和综合,以提炼出核心洞察 $I_{m+1}={\mathrm{INS}_{0},...,\mathrm{INS}_{n}}$。这些提炼后的洞察随后被纳入概念池 ${\mathcal{P}}_{m}$ 中,该池在整个过程中持续更新和丰富,具体如下:
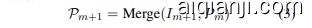
Using the updated conceptual pool $\mathscr{P}_{m+1}$ , OmniThink further expands the leaf nodes of the information tree iterative ly.
使用使用更新后的概念池 $\mathscr{P}_{m+1}$,OmniThink 进一步迭代地扩展信息树的叶节点。
This iterative cycle of expansion and reflection continues until OmniThink determines that sufficient information has been acquired or a predefined maximum retrieval depth $K$ has been reached. It ensures that the acquired information is relevant, detailed, and diverse, providing a robust foundation for generating structured and information-rich articles. The pseudo code of Expansion and Reflection can be found at Algorithm 1.
这种这种扩展和反思的循环迭代会持续进行,直到OmniThink确定已获取足够信息或达到预定义的最大检索深度$K$。这确保了获取的信息是相关、详细且多样化的,为生成结构化和信息丰富的文章提供了坚实的基础。扩展和反思的伪代码可以在算法1中找到。
3.2 Outline Structuring
33.2 大纲结构
Outline is the core of an article, determining its content direction, structural hierarchy, and logical progression. To create an outline that is wellguided, clearly structured, and logically coherent, it is essential to have a comprehensive and in-depth understanding of the topic. In the previous section, OmniThink maintains a concept pool closely related to the topic, which essentially represents the boundaries and depth of the LLM’s understanding of the topic. When generating the content outline, we first create a draft outline $O_{D}$ , and then ask the LLM to refine and link the content from the concept pool $\mathcal{P}$ , ultimately forming the final outline $O=\mathrm{Polish}(O_{D},\mathcal{P})$ . Through this approach, the LLM is able to comprehensively cover the key points of the topic in the outline and ensure logical consistency and content coherence in the article.
大纲大纲是一篇文章的核心,决定了其内容方向、结构层次和逻辑推进。要创建一个引导性强、结构清晰、逻辑连贯的大纲,必须对主题有全面而深入的理解。在前面的部分中,OmniThink 维护了一个与主题密切相关的概念池,这实质上代表了大语言模型对主题的理解边界和深度。在生成内容大纲时,我们首先创建一个草稿大纲 $O_{D}$,然后让大语言模型从概念池 $\mathcal{P}$ 中提炼和链接内容,最终形成最终大纲 $O=\mathrm{Polish}(O_{D},\mathcal{P})$。通过这种方法,大语言模型能够在大纲中全面覆盖主题的关键点,并确保文章的逻辑一致性和内容连贯性。
3.3 Article Composition
3.3 文章构成
After completing the outline $O$ , we begin writing the content for each section $S$ . At this stage, the LLM would work in parallel to write the content for each section. When writing the content of the section, we use the titles of each section and their hierarchical subsections to retrieve the most relevant $K$ documents from the information tree by calculating the semantic similarity (Sentence-BERT (Reimers and Gurevych, 2019) embeddings). After obtaining the relevant information, the LLM is prompted to generate the section content with citations based on the retrieved information. Once all sections are generated, they will be concatenated into a complete draft article $A_{D}=\left{S_{1},...S_{n}\right}$ . Since these sections are generated in parallel and the specific content of other sections is not yet clear, we prompt the LLM to process the concatenated article, remove redundant information, and form the final article $\boldsymbol{A}={S_{1}^{'},..S_{n}^{'}}$ .
在在完成大纲 $O$ 后,我们开始为每个部分 $S$ 编写内容。在这个阶段,大语言模型将并行工作,为每个部分生成内容。在编写部分内容时,我们使用每个部分的标题及其分层子部分,通过计算语义相似度 (Sentence-BERT (Reimers and Gurevych, 2019) 嵌入) ,从信息树中检索最相关的 $K$ 篇文档。在获得相关信息后,大语言模型会根据检索到的信息生成带有引用的部分内容。所有部分生成后,它们将被连接成一篇完整的草稿文章 $A_{D}=\left{S_{1},...S_{n}\right}$ 。由于这些部分是并行生成的,且其他部分的具体内容尚不清晰,我们会提示大语言模型处理连接后的文章,删除冗余信息,并形成最终文章 $\boldsymbol{A}={S_{1}^{'},..S_{n}^{'}}$ 。
4 Experiments
4 实验
4.1 Dataset and Baseline
4.1 数据集与基线
We use WildSeek as evaluation dataset to verify the effectiveness of our method, following previous work (Jiang et al., 2024; Shao et al., 2024a). WildSeek collects and filters data related to the open-source STORM web application, with each entry consisting of a specific topic and a user’s goal. We select representative baselines for comparison, including RAG, oRAG, and STORM (Shao et al., 2024a) and Co-STORM (Jiang et al., 2024). The baseline results are reproduced on the basis of STORM1.
我们我们使用 WildSeek 作为评估数据集,以验证我们方法的有效性,相关工作遵循了 Jiang 等人 (2024) 和 Shao 等人 (2024a) 的研究。WildSeek 收集并过滤了与开源 STORM Web 应用程序相关的数据,每个条目由一个特定主题和用户目标组成。我们选择了具有代表性的基线模型进行比较,包括 RAG、oRAG、STORM (Shao et al., 2024a) 和 Co-STORM (Jiang et al., 2024)。基线结果基于 STORM1 进行复现。
Table 1: Results of article quality evaluation. ∗means that this method is different from the original experimental setting, primarily in the human-machine collaboration component. Instead of simulating human involvement through an agent, as done in the original paper (Jiang et al., 2024), we remove the human participation step.
表表 1: 文章质量评估结果。∗表示该方法与原始实验设置不同,主要在人类-机器协作组件部分。与原始论文 (Jiang et al., 2024) 中通过 AI 智能体模拟人类参与不同,我们移除了人类参与步骤。
4.2 Evaluation Setup
44.2 评估设置
We employ both automatic and human evaluations to assess the generated long-form articles:
我们我们采用自动化和人工评估两种方法来评估生成长篇文章:
Automatic Evaluation. For automatic evaluation, we use Prometheus 2 (Kim et al., $2024)^{2}$ to score articles on a scale of 0 to 5, evaluating Relevance, Breadth, Depth, and Novelty. Furthermore, we measure information diversity (Jiang et al., 2024) (cosine similarity differences between web pages) and knowledge density (discussed in detail in $\S2.3)$ for information richness. Detailed procedures are provided in the Appendix C.
自动自动评估。在自动评估中,我们使用 Prometheus 2 (Kim et al., 2024) 对文章进行评分,评分范围为 0 到 5,评估内容包括相关性 (Relevance)、广度 (Breadth)、深度 (Depth) 和新颖性 (Novelty)。此外,我们还通过信息多样性 (Jiang et al., 2024)(网页之间的余弦相似度差异)和知识密度(在 §2.3 中详细讨论)来衡量信息的丰富性。具体步骤详见附录 C。
Human Evaluation. We randomly select 20 topics and compare articles generated by our method with those from the Co-STORM (the comprehensive best-performing baseline based on automatic evaluation), scoring them on the same four aspects. More details can be found in the Appendix D.
人工人工评估。我们随机选取 20 个主题,将我们方法生成的文章与 Co-STORM(基于自动评估的最佳基线)生成的文章进行比较,并在相同的四个方面进行评分。更多细节请参见附录 D。
4.3 Implementation Details
4.3 实现细节
We build OmniThink based on the DSpy framework (Khattab et al., 2023), and Appendix B contains the corresponding prompts we used. During generation, we set the temperature at 1.0 and top_p at 0.9. We use Bing’s API with the parameter for the number of web pages returned per query set to 5. For the computation of knowledge density, we utilize Factscore3 with GPT-4o-08-06 as the backbone to decompose atomic knowledge (Min et al., 2023). After decomposition, we proceed to use GPT-4o-08-06 for the de duplication of the split atomic knowledge. To avoid the impact of search engine changes over time, all the results in our table are completed within 3 days. More implementation details are presented in Appendix A.
我们我们基于 DSpy 框架 (Khattab et al., 2023) 构建了 OmniThink,附录 B 包含了我们使用的相应提示。在生成过程中,我们将温度设置为 1.0,top_p 设置为 0.9。我们使用 Bing 的 API,每个查询返回的网页数量参数设置为 5。为了计算知识密度,我们利用 Factscore3,以 GPT-4o-08-06 作为骨干,分解原子知识 (Min et al., 2023)。分解后,我们继续使用 GPT-4o-08-06 对分割的原子知识进行去重。为了避免搜索引擎随时间变化的影响,我们表中的所有结果在 3 天内完成。更多实现细节请参见附录 A。
5 Automatic Evaluation Results
5 自动评估结果
5.1 Main Results Table 2: Results of outline quality evaluation.
表表 2: 提纲质量评估结果
| 方法 | 内容引导 | 层次清晰度 | 逻辑一致性 |
|---|---|---|---|
| RAGo | 3.93 | 3.95 | 3.97 |
| STORM | 3.92 | 3.99 | 3.99 |
| Co-STORM* | 3.45 | 3.27 | 3.41 |
Article Generation. Table 1 presents the evaluation results on the WildSeek dataset employing GPT-4o and Qwen-Plus as backbones. Within the framework of four key grading criteria (Relevance, Breadth, Depth, and Novelty) OmniThink delivers exceptional performance across the board, with GPT-4o as its backbone, particularly distinguishing itself in the Novelty metric. This achievement can be credited to OmniThink’s robust reflective capabilities, which enable it to extract and thoroughly explore novel insights from existing knowledge. When employing Qwen-Plus as the backbone, OmniThink’s performance see a decline; however, it remains highly competitive.
文章文章生成。表 1 展示了在 WildSeek 数据集上使用 GPT-4o 和 Qwen-Plus 作为骨干模型的评估结果。在四个关键评分标准(相关性、广度、深度和新颖性)的框架下,OmniThink 以 GPT-4o 作为骨干模型表现出色,尤其在新颖性指标上表现突出。这一成就可以归功于 OmniThink 强大的反思能力,使其能够从现有知识中提取并深入探索新颖的见解。当使用 Qwen-Plus 作为骨干模型时,OmniThink 的性能有所下降,但仍具有高度竞争力。
OmniThink’s strength lies in its multifaceted and profound contemplation of retrieved information, which facilitates access to more profound layers of the external knowledge. This multi-perspective approach not only enriches the diversity of citation sources but also elevates the citation diversity level beyond that of other methodologies.
OmOmniThink 的优势在于其对检索信息的多方面和深入思考,这有助于访问外部知识的更深层次。这种多角度方法不仅丰富了引用来源的多样性,还将引用多样性水平提升至其他方法之上。
In terms of knowledge density, OmniThink employs a continuous and dynamic retrieval strategy to gather a wide array of information, which, in turn, allows it to draw upon a more extensive range of resources during the content generation phase. This strategic advantage positions OmniThink at an advantage in the knowledge density metric compared to existing benchmark methods.
在在知识密度方面,OmniThink采用了一种连续且动态的检索策略来收集广泛的信息,这使得其在内容生成阶段能够调用更广泛的资源。这一策略优势使OmniThink在知识密度指标上优于现有的基准方法。
Outline Generation. The outline serves as a critical intermediary in the process of article generation, with its quality exerting a direct impact on the coherence, logical consistency, and expressive clarity of the final article. We evaluate outline quality from the perspectives of structural soundness, logical consistency, and generative guidance. More details can be found in the Appendix C.1. From Table 2, we notice that OmniThink achieves superior performance in structural soundness and logical consistency. This improvement can be attributed to the unique design of OmniThink’s Concept Pool, which enables the LLMs to develop a more comprehensive and diverse understanding of the target topic during outline generation. Consequently, this facilitates better guidance for content production and enhances the overall structural coherence of the generated content. However, the logical consistency of the model showed only a marginal improvement compared to the baseline. This observation highlights a potential direction for future work, focusing on further enhancing logical consistency within the generation process.
大纲大纲生成。大纲在文章生成过程中作为一个关键的中介环节,其质量直接影响最终文章的连贯性、逻辑一致性和表达清晰度。我们从结构合理性、逻辑一致性和生成指导性三个角度评估大纲质量。更多细节详见附录 C.1。从表 2 中可以看出,OmniThink 在结构合理性和逻辑一致性方面表现更优。这一改进归功于 OmniThink 的 Concept Pool (概念池) 的独特设计,使得大语言模型在大纲生成过程中对目标主题有更全面和多样化的理解。因此,这为内容生成提供了更好的指导,并增强了生成内容的整体结构性连贯性。然而,与基线相比,模型的逻辑一致性仅略有提升。这一发现为未来的工作指明了潜在方向,即进一步在生成过程中增强逻辑一致性。
5.2 Ablation Study
5.2 消融研究
As discussed in $\S3.1$ , one of the main components of OmniThink is the introduction of dynamic expansion and reflection. We compare OmniThink with a version that does not implement dynamic expansion and reflection. As shown in Figure 5, the simplified version performs worse in various metrics related to article quality than the complete system, particularly in terms of Information Diversity and Novelty. This experiment demonstrates the powerful role of the dynamic expansion and reflection mechanism in enhancing information diversity and article novelty.
如如 $\S3.1$ 中所述,OmniThink 的主要组成部分之一是引入了动态扩展和反思。我们将 OmniThink 与未实现动态扩展和反思的版本进行了比较。如图 5 所示,简化版本在与文章质量相关的各项指标上表现不如完整系统,尤其是在信息多样性和新颖性方面。该实验证明了动态扩展和反思机制在增强信息多样性和文章新颖性方面的强大作用。
5.3 Expansion & Reflection Analysis
5.3 扩展与反射分析
We provide a further analysis of how the expansion and reflection processes shape the various aspects of the final articles and contribute to its overall quality. Given the interdependent nature of expansion and reflection in OmniThink, it is impractical to assess their individual impacts in isolation. To address this challenge, we adopt an indirect yet systematic approach to evaluate their collective influence on the final articles’ quality. During the information acquisition phase, we substitute the model used for expansion with a lower-performing model and measured the extent of performance decline in the generated article’s metrics, which served as an indicator of the impact of the expansion process on these metrics. Similarly, the same approach is applied to assess the impact of the reflection process. Specifically, based on the experimental results for Qwen-Plus in Table 1, we replace the models used for the expansion and reflection processes from Qwen-Plus to Qwen2.5-7binstruct (Team, 2024) and observe the decline in various evaluation results. This transition allows us to observe and document the subsequent changes in a range of evaluation metrics, providing insights into the expansion and reflection process’s influence on the articles’ overall assessment. We report the results in Figure 6.
我们我们进一步分析了扩展和反思过程如何影响最终文章的各个方面,并如何提升其整体质量。鉴于OmniThink中扩展和反思过程的相互依赖性,单独评估它们各自的影响是不切实际的。为解决这一挑战,我们采用了一种间接但系统的方法来评估它们对最终文章质量的集体影响。在信息获取阶段,我们将用于扩展的模型替换为性能较低的模型,并测量了生成文章指标的下降程度,以此作为扩展过程对这些指标影响的指标。同样地,该方法也用于评估反思过程的影响。具体而言,根据表 1 中Qwen-Plus的实验结果,我们将用于扩展和反思过程的模型从Qwen-Plus替换为Qwen2.5-7binstruct (Team, 2024),并观察各种评估结果的下降。这种过渡使我们能够观察并记录一系列评估指标的后续变化,从而深入理解扩展和反思过程对文章整体评估的影响。我们在图 6 中报告了结果。

Figure 5: The comparison between OmniThink and OmniThink w/o E&R, where OmniThink w/o E&R refers to OmniThink without expansion and reflection.
图图 5: OmniThink 和 OmniThink w/o E&R 的比较,其中 OmniThink w/o E&R 指的是 OmniThink 没有扩展和反思。
Continuous reflection expands knowledge boundaries. We observe that reflection is much more important than expansion with respect to novelty and informational diversity. Reflection endows the model with the capacity to not only re-evaluate and introspective ly consider existing knowledge but also to integrate this information in a way that stimulates the emergence of a more diverse and expansive range of ideas. This process of deep introspection is essential, as it diversifies the narrative with a spectrum of insights, thereby laying the groundwork for a piece of writing that is both innovative and diverse. Intrinsically, reflection module as a pivotal accelerator for creativity, allowing the model to surpass the constraints of simple information augmentation. It facilitates the crafting of a narrative that is uniquely informative, embodying the innovation that arises from a nuanced and varied approach to knowledge.
持续的持续的反思拓展了知识的边界。我们观察到,在新颖性和信息多样性方面,反思比扩展更为重要。反思赋予模型不仅重新评估和自省现有知识的能力,还能以激发更多样化和广泛想法的方式整合这些信息。这种深度自省的过程至关重要,因为它通过一系列见解使叙述多样化,从而为既创新又多样的写作奠定了基础。本质而言,反思模块是创造力的关键加速器,使模型能够超越简单信息增强的限制。它促进了一种独特信息丰富的叙述的构建,体现了从细致多样的知识方法中产生的创新。

Figure 6: The comparison of the impact of expansion and reflection on various metrics of the generated article.
图图 6: 扩展和反思对生成文章各项指标影响的比较。

Figure 7: The result of thinking depth with changes in knowledge density and information diversity.
图图 7: 知识密度和信息多样性变化下的思考深度结果。
Expansion enhances knowledge depth and improves information relevance. We notice that expansion is more important than reflection in breadth and depth. The rationale behind this is that expansion inherently sets the trajectory for the model’s subsequent information retrieval. By establishing more precise and effective directions for the model’s retrieval process, it becomes more adept at harnessing the retrieved information. This adeptness allows the model to seamlessly integrate the information into the text, thereby enriching the content with greater depth and breadth. This integration not only enhances the relevance of the content but also increases the knowledge density, as the text becomes more comprehensive and nuanced. Consequently, a better expansion strategy leads to a more sophisticated planner, capable of navigating the complexities of information retrieval and utilization with greater finesse.
扩展扩展增强了知识的深度并提高了信息的相关性。我们注意到,扩展在广度和深度上比反思更为重要。其背后的理由是,扩展本质上为模型的后续信息检索设定了轨迹。通过为模型的检索过程建立更精确和有效的方向,它变得更善于利用检索到的信息。这种能力使模型能够将信息无缝整合到文本中,从而丰富内容的深度和广度。这种整合不仅增强了内容的相关性,还增加了知识的密度,使文本更加全面和细致。因此,一个更好的扩展策略能够产生一个更复杂且精密的规划器,能够以更高的技巧驾驭信息检索和利用的复杂性。
5.4 Thinking Depth Analysis
55.4 思维深度分析
Our method has made numerous attempts to improve information retrieval, which are essentially scale-ups of the retrieved information. In this section, we discuss the impact of the quantity and depth of the retrieved information on the quality of the generation of articles. From Figure 7, we observe a rapid increase in the knowledge density and information diversity of the generated articles as the depth increases from 1 to 3. This indicates that as the depth increases, OmniThink can search for an increasing amount of diverse information on the Web and utilize this information in the generated articles. However, when the depth is raised to 4, the growth rate of knowledge density and information divinity slows down significantly. This may be because the available information on the subject approaches the search limit, making it difficult to retrieve more useful information on the topic.
我们的我们的方法在改进信息检索方面进行了多次尝试,实质上是检索信息的规模扩展。在本节中,我们讨论了检索信息的数量和深度对文章生成质量的影响。从图 7 中,我们观察到随着深度从 1 增加到 3,生成文章的知识密度和信息多样性迅速增加。这表明随着深度的增加,OmniThink 能够在网络上搜索到越来越多样的信息,并在生成的文章中利用这些信息。然而,当深度增加到 4 时,知识密度和信息多样性的增长速度显著放缓。这可能是因为该主题的可用信息接近搜索限制,使得难以检索到更多有用的信息。

Figure 8: Comparison of OmniThink and Co-STORM results under human evaluation. The values on the left side represent the average score from OmniThink human evaluators, while the values on the right side represent the average score from Co-STORM human evaluators.
图图 8: OmniThink 和 Co-STORM 在人工评估中的结果对比。左侧数值代表 OmniThink 人工评估者的平均评分,右侧数值代表 Co-STORM 人工评估者的平均评分。
6 Human Evaluation Results
6 人类评估结果
To better understand the strengths and weaknesses of OmniThink, we engage 15 well-educated volunteers to conduct a human evaluation. In Figure 8, we present the results of human scoring. The findings indicate that OmniThink’s average performance surpasses that of the current strongest baseline across various dimensions, with a notable $11%$ improvement in the Breadth metric compared to Co-STORM. However, in terms of the Novelty metric, although automated evaluation shows an $11%$ enhancement, human assessment reveals only a marginal advantage. This discrepancy suggests that the current automated evaluation may not yet be fully aligned with human judgment, highlighting a direction for future improvement in the evaluation of long texts.
为了更好地为了更好地了解 OmniThink 的优缺点,我们邀请了 15 名受过良好教育的志愿者进行人工评估。图 8 中展示了人工评分的结果。研究结果表明,OmniThink 在各个维度上的平均表现均超过了当前最强的基线,尤其是在广度(Breadth)指标上相比 Co-STORM 有显著的 11% 提升。然而,在创新性(Novelty)指标上,尽管自动化评估显示出 11% 的提升,但人工评估仅显示出微弱的优势。这种差异表明当前的自动化评估可能尚未完全与人类判断对齐,这为未来长文本评估的改进指明了方向。
It should also be noted that despite OmniThink’s overall superior performance in various dimensions, approximately $30%$ of the articles are considered equally excellent to the baseline by human evaluators. This could be attributed to the increasing difficulty for humans to discern subtle differences as the foundational writing capabilities of large models improve. Consequently, there is an urgent need to develop more rigorous and fine-grained evaluation methods to assess model performance more accurately.
还还应注意的是,尽管 OmniThink 在各种维度上整体表现优异,仍有约 $30%$ 的文章被人类评估者认为与基线同等优秀。这可能是由于随着大模型基础写作能力的提升,人类越来越难以察觉细微差异。因此,迫切需要开发更严格和细粒度的评估方法来更准确地评估模型性能。
and multi sub-query perspectives, they often fail to leverage the reasoning and introspective abilities of LLMs fully. Specifically, existing approaches do not fully exploit the potential of LLMs to dynamically adjust retrieval strategies and flexibly update information sources as the model’s understanding of the topic deepens(Qin et al., 2024). Unlike previous works, we propose a reflection-based dynamic retrieval framework OmniThink, which facilitates a more comprehensive and con textually responsive retrieval process by enabling context-aware, selfreflective adjustments to retrieval strategies.
从从多子查询的角度来看,它们往往未能充分利用大语言模型的推理和自省能力。具体而言,现有方法并未充分利用大语言模型的潜力,以动态调整检索策略并灵活更新信息源,随着模型对主题的理解加深 (Qin et al., 2024)。与之前的工作不同,我们提出了一种基于反思的动态检索框架 OmniThink,该框架通过实现上下文感知、自我反思的检索策略调整,促进了更全面且上下文敏感的检索过程。
7.2 Machine Writing
7.2 机器写作
7 Related Work
7 相关工作
7.1 Information Seeking in NLP
7.1 自然语言处理中的信息检索
Previous studies on information-seeking focused on designing question-answering (QA) systems (Wu et al., 2025). Early open-domain QA methods generally assumed that users could fulfill their information needs through a single query (Chen et al., 2017; Levy et al., 2021). Subsequent studies have recognized that, in real-world scenarios, users often struggle to satisfy their information needs with a single query (Chen et al., 2017; Levy et al., 2021). To address this limitation, researchers have explored multi sub-query retrieval methods, where a single query is decomposed into multiple sub-queries to retrieve distinct pieces of information (Mao et al., 2024; Chen et al., 2011; Peng et al., 2019). The information collected is then aggregated to provide a comprehensive answer. Building on these developments, recent advances in open-domain long-form generation require reasoning across multiple information sources (Fan et al., 2019; Ujwal et al., 2024; Wei et al., 2024; Tan et al., 2024). This line of open-domain long-form generatio underscores the importance of integrating information from multiple perspectives. For example, STORM introduces a retrieval paradigm that simulates multi-turn interactions from diverse perspectives, aiming to aggregate richer and more diverse information(Shao et al., 2024b). Similarly, Co-STORM employs a “roundtable discussion” paradigm to further expand the diversity of information sources considered during retrieval (Jiang et al., 2024). Although these approaches have made significant advancements from multi-perspective
先前先前关于信息检索的研究主要集中在设计问答系统 (QA) (Wu et al., 2025)。早期的开放域 QA 方法通常假设用户可以通过单个查询满足其信息需求 (Chen et al., 2017; Levy et al., 2021)。后续研究认识到,在现实场景中,用户往往难以通过单个查询满足其信息需求 (Chen et al., 2017; Levy et al., 2021)。为了解决这一限制,研究人员探索了多子查询检索方法,将单个查询分解为多个子查询以检索不同的信息片段 (Mao et al., 2024; Chen et al., 2011; Peng et al., 2019)。收集到的信息随后被汇总以提供全面的答案。基于这些发展,最近在开放域生成长文本方面的进展要求跨多个信息源进行推理 (Fan et al., 2019; Ujwal et al., 2024; Wei et al., 2024; Tan et al., 2024)。这一开放域生成长文本的研究方向强调了从多个角度整合信息的重要性。例如,STORM 引入了一种检索范式,模拟来自不同视角的多轮交互,旨在聚合更丰富和多样化的信息 (Shao et al., 2024b)。同样,Co-STORM 采用了“圆桌讨论”范式,以进一步扩展检索过程中考虑的信息来源的多样性 (Jiang et al., 2024)。尽管这些方法在多视角方面取得了显著进展
Due to the high costs associated with manual writing, machine writing has garnered significant research interest in recent years (Zhou et al., 2023; Pham et al., 2024; Wang et al., 2024a,b). The emer- gence of LLMs and Retrieval-Augmented Generation (RAG) has opened new possibilities for automated writing (Liang et al., 2024; Balepur et al., 2023; de la Torre-López et al., 2023). To ensure authenticity and real-time relevance, current RAG-based automated writing systems primarily rely on retrieved content to generate articles. For example, STORM (Shao et al., 2024a) introduces a role-playing question-and-answer approach to author Wikipedia-like articles, while Co-STORM (Jiang et al., 2024) proposes a userparticipated information retrieval paradigm. Besides, AutoSurvey (Wang et al., $2024\mathrm{c})$ extends this framework into the domain of academic paper writing. However, these methods tend to overlook the issue of information diversity, which can result in outputs with limited practical value. Although these methods demonstrate notable advancements in specific domains, they often neglect the perspective of content utility, resulting in outputs with limited practical value. Unlike previous works, we propose a reflection-based dynamic retrieval framework OmniThink, which facilitates a more comprehensive and con textually responsive retrieval process by enabling context-aware, self-reflective adjustments to retrieval strategies. The proposed OmniThink adopts the concept of knowledge density, enhancing the informative ness and overall utility of generated text while maintaining its original quality.
由于由于手动写作的高成本,机器写作近年来引起了广泛的研究兴趣 (Zhou et al., 2023; Pham et al., 2024; Wang et al., 2024a,b)。大语言模型和检索增强生成 (RAG) 的出现为自动化写作开辟了新的可能性 (Liang et al., 2024; Balepur et al., 2023; de la Torre-López et al., 2023)。为了确保真实性和实时相关性,当前基于 RAG 的自动化写作系统主要依赖检索到的内容来生成文章。例如,STORM (Shao et al., 2024a) 引入了一种角色扮演的问答方法来撰写类似维基百科的文章,而 Co-STORM (Jiang et al., 2024) 提出了一种用户参与的信息检索范式。此外,AutoSurvey (Wang et al., 2024c)将这一框架扩展到学术论文写作领域。然而,这些方法往往忽视了信息多样性的问题,可能导致输出内容的实用价值有限。尽管这些方法在特定领域展示了显著的进展,但它们通常忽略了内容效用的视角,导致输出内容的实际价值有限。与以往的工作不同,我们提出了一种基于反思的动态检索框架 OmniThink,它通过在检索策略中启用上下文感知和自我反思的调整,促进了更全面且上下文响应式的检索过程。所提出的 OmniThink 采用了知识密度的概念,在保持生成文本原有质量的同时增强了其信息量和整体效用。
8 Conclusion and Furture Work
8 结论与未来工作
We propose OmniThink, a machine writing framework that emulates the human-like process of iterative expansion and reflection. Automatic and human evaluations demonstrate that OmniThink can generate well-founded, high-quality long articles. Our approach is model-agnostic and can be integrated with existing frameworks. In the future, we will explore more advanced machine writing methods that combine deeper reasoning with roleplaying and human-computer interaction.
我们我们提出 OmniThink,一个模拟人类迭代扩展和反思过程的机器写作框架。自动化和人工评估表明,OmniThink 能够生成有根据、高质量的长篇文章。我们的方法与模型无关,可以集成到现有框架中。未来,我们将探索更先进的机器写作方法,将更深层次的推理与角色扮演和人机交互互相结合。
Limitations
局限性
Although the proposed OmniThink has demonstrated its advantages in both automatic and human evaluations, several limitations remain. Firstly, the current work is limited to search and text generation, while a vast amount of multimodal information in the open domain remains unused. Secondly, we have not considered personalized language styles in text production. As a result, the generated texts tend to be academic in nature, which may not be as suitable for general users’ reading preferences. We plan to address these limitations in future work.
尽管尽管提出的OmniThink在自动评估和人工评估中都展示了其优势,但仍存在一些限制。首先,当前的工作仅限于搜索和文本生成,而开放领域中的大量多模态信息尚未被利用。其次,我们尚未考虑文本生成中的个性化语言风格。因此,生成的文本往往具有学术性质,可能不太适合一般用户的阅读偏好。我们计划在未来的工作中解决这些限制。
systematic review of scientific literature. Computing, 105(10):2171–2194.
科学科学文献的系统性综述。计算,105(10):2171–2194。
References
参考文献
Papers), pages 223–241, Toronto, Canada. Associ- ation for Computational Linguistics.
论文论文), 第 223–241 页, 加拿大多伦多. 计算语言学协会.
Yi Liang, You Wu, Honglei Zhuang, Li Chen, Jiaming Shen, Yiling Jia, Zhen Qin, Sumit Sanghai, Xuanhui Wang, Carl Yang, and Michael Bendersky. 2024. Integrating planning into single-turn long-form text generation. Preprint, arXiv:2410.06203.
YiYi Liang, You Wu, Honglei Zhuang, Li Chen, Jiaming Shen, Yiling Jia, Zhen Qin, Sumit Sanghai, Xuanhui Wang, Carl Yang, 和 Michael Bendersky。2024。在单轮长文本生成中集成规划。预印本,arXiv:2410.06203。
Peter J. Liu, Mohammad Saleh, Etienne Pot, Ben Goodrich, Ryan Sepassi, Lukasz Kaiser, and Noam Shazeer. 2018. Generating wikipedia by summarizing long sequences. Preprint, arXiv:1801.10198.
PeterPeter J. Liu, Mohammad Saleh, Etienne Pot, Ben Goodrich, Ryan Sepassi, Lukasz Kaiser, and Noam Shazeer. 2018. 通过总结长序列生成维基百科. 预印本, arXiv:1801.10198.
Xiang Liu, Peijie Dong, Xuming Hu, and Xiaowen Chu. 2024. Long gen bench: Long-context genera- tion benchmark. Preprint, arXiv:2410.04199.
XXiang Liu, Peijie Dong, Xuming Hu, 和 Xiaowen Chu. 2024. Long gen bench: 长上下文生成基准. 预印本, arXiv:2410.04199.
Shengyu Mao, Yong Jiang, Boli Chen, Xiao Li, Peng Wang, Xinyu Wang, Pengjun Xie, Fei Huang, Huajun Chen, and Ningyu Zhang. 2024. RaFe: Ranking feedback improves query rewriting for RAG. In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 884–901, Miami, Florida, USA. Association for Computational Linguistics.
SShengyu Mao, Yong Jiang, Boli Chen, Xiao Li, Peng Wang, Xinyu Wang, Pengjun Xie, Fei Huang, Huajun Chen, 和 Ningyu Zhang。2024。RaFe:排序反馈改进RAG的查询重写。载于《计算语言学会发现:EMNLP 2024》,884-901页,美国佛罗里达州迈阿密。计算语言学会。
Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen tau Yih, Pang Wei Koh, Mohit Iyyer, Luke Z ett le moyer, and Hannaneh Hajishirzi. 2023. Factscore: Fine-grained atomic evaluation of factual precision in long form text generation. Preprint, arXiv:2305.14251.
SSewon Min、Kalpesh Krishna、Xinxi Lyu、Mike Lewis、Wen tau Yih、Pang Wei Koh、Mohit Iyyer、Luke Zettlemoyer 和 Hannaneh Hajishirzi。2023。Factscore:长文本生成中事实准确性的细粒度原子评估。预印本,arXiv:2305.14251。
Karen F Osterman. 1990. Reflective practice: A new agenda for education. Education and urban society, 22(2):133–152.
KarenKaren F Osterman. 1990. 反思实践:教育的新议程。Education and urban society, 22(2):133–152.
Bidhan L Parmar, R Edward Freeman, Jeffrey S Harrison, Andrew C Wicks, Lauren Purnell, and Simone De Colle. 2010. Stake holder theory: The state of the art. Academy of Management Annals, 4(1):403– 445.
BBidhan L Parmar, R Edward Freeman, Jeffrey S Harrison, Andrew C Wicks, Lauren Purnell 和 Simone De Colle. 2010. 利益相关者理论:现状. Academy of Management Annals, 4(1):403–445.
Peng Peng, Qi Ge, Lei Zou, M Tamer Özsu, Zhiwei Xu, and Dongyan Zhao. 2019. Optimizing multiquery evaluation in federated rdf systems. IEEE Transactions on Knowledge and Data Engineering, 33(4):1692–1707.
PengPeng Peng, Qi Ge, Lei Zou, M Tamer Özsu, Zhiwei Xu, 和 Dongyan Zhao. 2019. 在多查询评测中优化联邦 RDF 系统。 IEEE 知识工程与数据工程学报, 33(4):1692–1707.
Chau Minh Pham, Simeng Sun, and Mohit Iyyer. 2024. Suri: Multi-constraint instruction following for long-form text generation. arXiv preprint arXiv:2406.19371.
ChChau Minh Pham, Simeng Sun 和 Mohit Iyyer. 2024. Suri: 多约束指令跟随的长文本生成. arXiv 预印本 arXiv:2406.19371.
Shuofei Qiao, Yixin Ou, Ningyu Zhang, Xiang Chen, Yunzhi Yao, Shumin Deng, Chuanqi Tan, Fei Huang, and Huajun Chen. 2023. Reasoning with language model prompting: A survey. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5368–5393, Toronto, Canada. Association for Computational Linguistics.
ShShuofei Qiao, Yixin Ou, Ningyu Zhang, Xiang Chen, Yunzhi Yao, Shumin Deng, Chuanqi Tan, Fei Huang, Huajun Chen. 2023. 基于大语言模型提示的推理:综述. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5368–5393, Toronto, Canada. Association for Computational Linguistics.
Yiwei Qin, Xuefeng Li, Haoyang Zou, Yixiu Liu, Shijie Xia, Zhen Huang, Yixin Ye, Weizhe Yuan, Hector Liu, Yuanzhi Li, and Pengfei Liu. 2024. O1 replication journey: A strategic progress report – part 1. Preprint, arXiv:2410.18982.
YiYiwei Qin, Xuefeng Li, Haoyang Zou, Yixiu Liu, Shijie Xia, Zhen Huang, Yixin Ye, Weizhe Yuan, Hector Liu, Yuanzhi Li, and Pengfei Liu. 2024. O1 复现之旅:战略进展报告 – 第一部分. 预印本, arXiv:2410.18982.
Shang ha or an Quan, Tianyi Tang, Bowen Yu, An Yang, Dayiheng Liu, Bofei Gao, Jianhong Tu, Yichang Zhang, Jingren Zhou, and Junyang Lin. 2024. Language models can self-lengthen to generate long texts. Preprint, arXiv:2410.23933.
ShangShang ha or an Quan, Tianyi Tang, Bowen Yu, An Yang, Dayiheng Liu, Bofei Gao, Jianhong Tu, Yichang Zhang, Jingren Zhou, and Junyang Lin. 2024. 语言模型可以通过自我延长生成成长文本。预印本, arXiv:2410.23933.
Haoran Que, Feiyu Duan, Liqun He, Yutao Mou, Wang chun shu Zhou, Jiaheng Liu, Wenge Rong, Zekun Moore Wang, Jian Yang, Ge Zhang, Junran Peng, Zhaoxiang Zhang, Songyang Zhang, and Kai Chen. 2024. Hellobench: Evaluating long text generation capabilities of large language models. Preprint, arXiv:2409.16191.
HaHaoran Que, Feiyu Duan, Liqun He, Yutao Mou, Wang chun shu Zhou, Jiaheng Liu, Wenge Rong, Zekun Moore Wang, Jian Yang, Ge Zhang, Junran Peng, Zhaoxiang Zhang, Songyang Zhang, and Kai Chen. 2024. Hellobench: 大语言模型的长文本生成能力评估. 预印本, arXiv:2409.16191.
Ori Ram, Yoav Levine, Itay Dalmedigos, Dor Muhlgay, Amnon Shashua, Kevin Leyton-Brown, and Yoav Shoham. 2023. In-context retrieval-augmented language models. Preprint, arXiv:2302.00083.
OriOri Ram, Yoav Levine, Itay Dalmedigos, Dor Muhlgay, Amnon Shashua, Kevin Leyton-Brown, and Yoav Shoham. 2023. 上下文检索增强的语言模型. 预印本, arXiv:2302.00083.
Nils Reimers and Iryna Gurevych. 2019. SentenceBERT: Sentence embeddings using Siamese BERTnetworks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3982–3992, Hong Kong, China. Association for Computational Linguistics.
NNils Reimers 和 Iryna Gurevych. 2019. SentenceBERT: 使用孪生 BERT 网络的句子嵌入. 在 2019 年自然语言处理经验方法会议和第 9 届自然语言处理国际联合会议 (EMNLP-IJCNLP) 论文集, 第 3982–3992 页, 中国香港. 计算语言学协会.
Murray Shanahan, Kyle McDonell, and Laria Reynolds. 2023. Role play with large language models. Nature, 623(7987):493–498.
MurrayMurray Shanahan, Kyle McDonell, 和 Laria Reynolds. 2023. 大语言模型中的角色扮演. Nature, 623(7987):493–498.
Yijia Shao, Yucheng Jiang, Theodore A. Kanell, Peter Xu, Omar Khattab, and Monica S. Lam. 2024a. Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers).
YYijia Shao, Yucheng Jiang, Theodore A. Kanell, Peter Xu, Omar Khattab, Monica S. Lam. 2024a. 使用大语言模型辅助从零开始撰写类维基百科文章。见《2024年北美计算语言学协会会议论文集:人类语言技术,第1卷(长文与短文)》。
Yijia Shao, Vinay Samuel, Yucheng Jiang, John Yang, and Diyi Yang. 2024b. Collaborative gym: A framework for enabling and evaluating human-agent collaboration. Preprint, arXiv:2412.15701.
YYijia Shao, Vinay Samuel, Yucheng Jiang, John Yang, and Diyi Yang. 2024b. Collaborative gym: 一个支持与评估人机协作的框架. 预印本, arXiv:2412.15701.
Zejiang Shen, Tal August, Pao S ian gli ul ue, Kyle Lo, Jonathan Bragg, Jeff Hammer bac her, Doug Downey, Joseph Chee Chang, and David Sontag. 2023. Beyond sum mari z ation: Designing ai support for real-world expository writing tasks. Preprint, arXiv:2304.02623.
ZeZejiang Shen, Tal August, Pao Sian gli ul ue, Kyle Lo, Jonathan Bragg, Jeff Hammerbacher, Doug Downey, Joseph Chee Chang, and David Sontag. 2023. 超越摘要:为实际说明性写作任务设计AI支持。预印本,arXiv:2304.02623。
Michael D. Skarlinski, Sam Cox, Jon M. Laurent, James D. Braza, Michaela Hinks, Michael J. Hammerling, Manvitha Ponnapati, Samuel G. Rodriques, and Andrew D. White. 2024. Language agents achieve superhuman synthesis of scientific knowledge. Preprint, arXiv:2409.13740.
MichaelMichael D. Skarlinski, Sam Cox, Jon M. Laurent, James D. Braza, Michaela Hinks, Michael J. Hammerling, Manvitta Ponnapati, Samuel G. Rodriques, Andrew D. White. 2024. 语言智能体实现科学知识的超人合成. 预印本, arXiv:2409.13740.
Amanda Spink, Howard Greisdorf, and Judy Bateman. 1998. From highly relevant to not relevant: examining different regions of relevance. Information processing & management, 34(5):599–621.
AmAmanda Spink, Howard Greisdorf, Judy Bateman. 1998. 从高度相关到不相关:检视相关性的不同区域。信息处理与管理,34(5):599–621。
Dan Su, Xiaoguang Li, Jindi Zhang, Lifeng Shang, Xin Jiang, Qun Liu, and Pascale Fung. 2022. Read before generate! faithful long form question answering with machine reading. Preprint, arXiv:2203.00343.
DanDan Su, Xiaoguang Li, Jindi Zhang, Lifeng Shang, Xin Jiang, Qun Liu 和 Pascale Fung。2022。先读后生成!基于机器阅读的忠实长问题回答。预印本,arXiv:2203.00343。
Haochen Tan, Zhijiang Guo, Zhan Shi, Lu Xu, Zhili Liu, Yunlong Feng, Xiaoguang Li, Yasheng Wang, Lifeng Shang, Qun Liu, and Linqi Song. 2024. Proxyqa: An alternative framework for evaluating long-form text generation with large language models. Preprint, arXiv:2401.15042.
HaHaochen Tan, Zhijiang Guo, Zhan Shi, Lu Xu, Zhili Liu, Yunlong Feng, Xiaoguang Li, Yasheng Wang, Lifeng Shang, Qun Liu, and Linqi Song. 2024. Proxyqa: 一种评估大语言模型生成长文本的替代框架。预印本,arXiv:2401.15042。
Qwen Team. 2024. Qwen2.5: A party of foundation models.
QQwen Team. 2024. Qwen2.5: 基础模型系列
Utkarsh Ujwal, Sai Sri Harsha Surampudi, Sayantan Mitra, and Tulika Saha. 2024. " reasoning before responding": Towards legal long-form question answering with interpret ability. In Proceedings of the 33rd ACM International Conference on Information and Knowledge Management, pages 4922–4930.
UtUtkarsh Ujwal, Sai Sri Harsha Surampudi, Sayantan Mitra 和 Tulika Saha. 2024. "先推理后回答": 面向法律领域的长问答与可解释性. 第 33 届 ACM 国际信息与知识管理会议论文集, 4922–4930 页.
Qiyao Wang, Shiwen Ni, Huaren Liu, Shule Lu, Guhong Chen, Xi Feng, Chi Wei, Qiang Qu, Hamid AlinejadRokny, Yuan Lin, and Min Yang. 2024a. Autopatent: A multi-agent framework for automatic patent generation. Preprint, arXiv:2412.09796.
2022024a. 王祺尧, 倪世文, 刘华仁, 卢书乐, 陈谷鸿, 冯曦, 魏驰, 曲强, Hamid AlinejadRokny, 林远, 杨敏. Autopatent: 一个用于自动专利生成的AI智能体框架. 预印本, arXiv:2412.09796.
Tiannan Wang, Jiamin Chen, Qingrui Jia, Shuai Wang, Ruoyu Fang, Huilin Wang, Zhaowei Gao, Chunzhao Xie, Chuou Xu, Jihong Dai, et al. 2024b. Weaver: Foundation models for creative writing. arXiv preprint arXiv:2401.17268.
TTiannan Wang, Jiamin Chen, Qingrui Jia, Shuai Wang, Ruoyu Fang, Huilin Wang, Zhaowei Gao, Chunzhao Xie, Chuou Xu, Jihong Dai, 等. 2024b. Weaver: 创意写作的基础模型. arXiv 预印本 arXiv:2401.17268.
Yidong Wang, Qi Guo, Wenjin Yao, Hongbo Zhang, Xin Zhang, Zhen Wu, Meishan Zhang, Xinyu Dai, Min Zhang, Qingsong Wen, Wei Ye, Shikun Zhang, and Yue Zhang. 2024c. Autosurvey: Large language models can automatically write surveys. In The Thirty-eighth Annual Conference on Neural Information Processing Systems.
YYidong Wang, Qi Guo, Wenjin Yao, Hongbo Zhang, Xin Zhang, Zhen Wu, Meishan Zhang, Xinyu Dai, Min Zhang, Qingsong Wen, Wei Ye, Shikun Zhang, 和 Yue Zhang. 2024c. Autosurvey: 大语言模型可以自动撰写综述. 在第三十八届神经信息处理系统年会上.
Jerry Wei, Chengrun Yang, Xinying Song, Yifeng Lu, Nathan Hu, Dustin Tran, Daiyi Peng, Ruibo Liu,Da Huang, Cosmo Du, et al. 2024. Long-form factuality in large language models. arXiv preprint arXiv:2403.18802.
JerJerry Wei, Chengrun Yang, Xinying Song, Yifeng Lu, Nathan Hu, Dustin Tran, Daiyi Peng, Ruibo Liu, Da Huang, Cosmo Du, 等. 2024. 大语言模型中的长篇事实性. arXiv 预印本 arXiv:2403.18802.
Jialong Wu, Wenbiao Yin, Yong Jiang, Zhenglin Wang, Zekun Xi, Runnan Fang, Deyu Zhou, Pengjun Xie, and Fei Huang. 2025. Webwalker: Benchmarking llms in web traversal. Preprint, arXiv:2501.07572.
JJialong Wu, Wenbiao Yin, Yong Jiang, Zhenglin Wang, Zekun Xi, Runnan Fang, Deyu Zhou, Pengjun Xie, and Fei Huang. 2025. Webwalker: 大语言模型在网页遍历中的基准测试。预印本, arXiv:2501.07572。
Yang Xu and David Reitter. 2017. Spectral analysis of information density in dialogue predicts collaborative task performance. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 623–633, Vancouver, Canada. Associ- ation for Computational Linguistics.
YangYang Xu 和 David Reitter. 2017. 对话中信息密度的频谱分析预测协作任务表现. 在计算语言学协会第55届年会 (第一卷: 长论文) 会议录中, 623-633页, 加拿大温哥华. 计算语言学协会.
A Implementation Details
A 实现细节
We build OmniThink based on the DSpy framework (Khattab et al., 2023), and STORM. Appendix B contains the corresponding prompts we used. During article generation, we set the temperature at 1.0 and top_ $p$ at 0.9. The search engine employed is Bing’s API, with the parameter for the number of web pages returned per query configured to 5. To retrieve information based on the outline, we use Sentence BERT (Reimers and Gurevych, 2019) embeddings to calculate cosine similarity, thereby retrieving the three most similar web pages each time. For the computation of knowledge density, we utilize Factscore4 with GPT4o-08-06 as the backbone to decompose atomic knowledge (Min et al., 2023). After the decomposition, we proceed to use GPT-4o-08-06 for the de duplication of the split atomic knowledge.
我们我们基于DSpy框架(Khattab et al., 2023)和STORM构建了OmniThink。附录B包含我们使用的相应提示。在文章生成过程中,我们将温度设置为1.0,top_$p$设置为0.9。使用的搜索引擎是Bing的API,每次查询返回的网页数量参数配置为5。为了基于大纲检索信息,我们使用Sentence BERT(Reimers and Gurevych, 2019)嵌入来计算余弦相似度,从而每次检索出三个最相似的网页。对于知识密度的计算,我们使用Factscore4,并以GPT4o-08-06为骨干来分解原子知识(Min et al., 2023)。分解后,我们继续使用GPT-4o-08-06对分割后的原子知识进行去重。
B Full Prompts in OmniThink
B OmniThink 中的完整提示
In $\S3$ , we introduce the specific process of OmniThink, which is implemented using zero-shot prompting based on GPT-4o-2024-08-06. Lists 1, 2, 3, 4 and 5, respectively document the complete prompts for OmniThink’s Expand, Reflect, Write Outline, Write Article, and Polish Article stages. These prompts are designed to guide the model through iterative stages of content generation, ensuring coherence and depth in the produced text.
在在 $\S3$ 中,我们介绍了 OmniThink 的具体流程,该流程基于 GPT-4o-2024-08-06 使用零样本提示实现。列表 1、2、3、4 和 5 分别记录了 OmniThink 在扩展、反思、撰写大纲、撰写文章以及润色文章阶段的完整提示。这些提示旨在引导模型通过迭代的内容生成阶段,确保生成文本的一致性和深度。
The structured process leverages dynamic adjustments based on intermediate outputs, reflecting a balanced integration of retrieval and generation capabilities. This systematic approach highlights OmniThink’s ability to adaptively construct wellorganized and con textually relevant articles across diverse topics.
结构化结构化流程利用基于中间输出的动态调整,体现了检索与生成能力的平衡整合。这一系统化方法突显了OmniThink在多样主题下自适应构建结构良好且上下文相关文章的能力。
C Automatic Evaluation Details
C 自动评估细节
To further ensure reliability, we conducted multiple evaluation rounds using different prompts covering various aspects of outline coherence, structural logic, and topic relevance. This multi-faceted evaluation helps mitigate potential biases and enhances the robustness of the scoring results.
为进一步为进一步确保可靠性,我们使用不同的提示进行了多轮评估,涵盖了大纲连贯性、结构逻辑和主题相关性等多个方面。这种多方面的评估有助于减少潜在的偏见,并增强评分结果的稳健性。
C.1 Outline Evaluation
CC.1 评估大纲
Since Prometheus 2 (Kim et al., 2024) does not perform targeted optimization on the outline, we decided to use a more powerful model to score the outline. To ensure the results are consistent, we set the temperature to 0. Specifically, we use the Prometheus 2 framework but replace the underlying evaluation model with GPT-4o-08-06. The scoring criteria for outline quality evaluation and discourse quality evaluation can be found in Lstlisting 10. In addition, since Co-STORM does not have an intermediate outline generation step, we had to extract the outline from the final article for evaluation, which might be the reason for the relatively lower outline scores observed form Co-STORM.
由于由于 Prometheus 2 (Kim et al., 2024) 未对大纲进行针对性优化,我们决定使用更强大的模型来为大大纲评分。为确保结果一致,我们将温度设置为 0。具体而言,我们使用 Prometheus 2 框架,但将底层评估模型替换为 GPT-4o-08-06。大纲质量评估和论述质量评估的评分标准可在 Lstlisting 10 中找到。此外,由于 Co-STORM 没有中间大纲生成步骤,我们不得不从最终文章中提取大纲进行评估,这可能是 Co-STORM 大纲得分相对较低的原因。

Figure 9: The educational background distribution of assessors.
图图 9: 评估者的教育背景分布。
C.2 Article Evaluation
C.2 文章评估
Following Co-STORM (Jiang et al., 2024), we utilized the Prometheus-7b-v2.0 model for evaluation. Prometheus (Kim et al., 2024) is an open-source scoring model used to assess lengthy texts based on user-defined criteria. Its default temperature value is 1.0, and the top_p value is 0.9. Due to the model’s limited context window, we exclude reference sections from the article evaluation and trim the input text to fewer than 2000 words to fit within the model’s context window. This is consistent with STORM’s approach (Shao et al., 2024a), where the shortest section is removed each time until the article length meets the specified requirement. The scoring criteria for article quality evaluation can be found in Listing 11.
根据根据 Co-STORM (Jiang et al., 2024) ,我们使用 Prometheus-7b-v2.0 模型进行评估。Prometheus (Kim et al., 2024) 是一个开源的评分模型,用于根据用户定义的标准评估长篇文本。其默认温度值为 1.0,top_p 值为 0.9。由于模型的上下文窗口有限,我们排除文章评估中的引用部分,并将输入文本截断至 2000 字以内以适应模型的上下文窗口。这与 STORM 的方法一致 (Shao et al., 2024a) ,即每次移除最短的部分,直到文章长度符合要求。文章质量评估的评分标准见 Listing 11。
D Human Evaluation Details
D 人工评估细节
The participants in the evaluation voluntarily provided their highest educational qualification to demonstrate their ability to impartially assess the article. As shown in Figure 9, all of our human evaluators have an undergraduate degree or higher, with $53%$ having a graduate degree. As discussed in $\S6$ , to compare the merits of OmniThink and
参与参与评估的参与者自愿提供了他们的最高学历,以证明他们能够公正地评估文章。如图 9 所示,我们所有的人类评估者都拥有本科或更高的学历,其中 $53%$ 拥有研究生学历。如 $\S6$ 中所述,为了比较 OmniThink 的优劣...
Co-STORM, each human evaluator was given a scoring criterion and a pair of articles. They were required to compare and assign scores, with the scoring criteria being the same as Lstlisting 11. We compiled the average scores given by the human evaluators for OmniThink and Co-STORM and compared their wins and losses.
CoCo-STORM,每位人类评估者都收到了一份评分标准和一对文章。他们需要进行比较并分配分数,评分标准与Lstlisting 11相同。我们编译了人类评估者给OmniThink和Co-STORM的平均分数,并比较了它们的胜负。
E Case Study
E 案例研究
In Figure 12, we present an example of AlphaFold generated by OmniThink. It is generated using GPT-4o as the backbone. We can see that OmniThink’s language is more concise compared to other methods, and it contains more information per unit of text length.
图图 12: 我们展示了由 OmniThink 生成的 AlphaFold 示例。它是使用 GPT-4 作为主干生成的。我们可以看到,与其他方法相比,OmniThink 的语言更加简洁,并且在单位文本长度内包含更多信息。
F Clarification of Reflection
F 反射的澄清
In this paper, our reflection refers to the process where the LLM reflects on the retrieved information based on its current Conceptual Pool, evaluating which parts of the information can enrich the existing Conceptual Pool. The usable information is then extracted as insights and added to the Conceptual Pool.
本文本文中,我们的反思(reflection)指的是大语言模型(LLM)根据其当前的概念池(Conceptual Pool)对检索到的信息进行反思,评估信息的哪些部分可以丰富现有的概念池。然后将可用的信息提取为见解并添加到概念池中。
class Extend Concept(dspy.Signature): """ You are an analytical robot. I will provide you with a subject, the information I have searched about it, and our preliminary concept of it. I need you to generate a detailed, in-depth, and insightful report based on it, further exploring our initial ideas. First, break down the subject into several broad categories, then create corresponding search engine keywords for each category. Note: The new categories should not repeat the previous ones. Your output format should be as follows: -[Category 1] --{Keyword 1} --{Keyword 2} -[Category 2] --{Keyword 1} --{Keyword 2} """ info $=$ dspy.InputField(prefi $\mathrel{\mathop:}=\mathrel{\mathop:}$ The information you have collected from the webpage:', format=str) concept $=$ dspy.InputField(prefix='The summary of the previous concepts:', format=str) category $=$ dspy.InputField(prefix='The broader categories you need to further expand:', format=str) keywords $=$ dspy.Output Field(format=str)
classclass Extend Concept(dspy.Signature):
"""
你是一个分析机器人。我将为你提供一个主题、我搜索到的相关信息以及我们对该主题的初步概念。你需要基于这些信息生成一份详细、深入且有洞察力的报告,进一步探索我们的初步想法。首先,将主题分解为几个大类,然后为每个类别生成相应的搜索引擎关键词。注意:新类别不应重复之前的类别。你的输出格式应如下:
-[类别 1]
--{关键词 1}
--{关键词 2}
-[类别 2]
--{关键词 1}
--{关键词 2}
"""
info $=$ dspy.InputField(prefi $\mathrel{\mathop:}=\mathrel{\mathop:}$ 你从网页收集到的信息:', format=str)
concept $=$ dspy.InputField(prefix='先前概念的总结:', format=str)
category $=$ dspy.InputField(prefix='你需要进一步扩展的更广泛类别:', format=str)
keywords $=$ dspy.Output Field(format=str)
Listing 1: Prompts used for expanding in OmniThink.
列表列表 1: OmniThink 中用于扩展的提示词。
class GenConcept(dspy.Signature): """ Please analyze, summarize, and evaluate the following webpage information. Think like a person, distill the core point of each piece of information, and synthesize them into a comprehensive opinion. Present your comprehensive opinion in the format of 1. 2. ... """ info $=$ dspy.InputField(prefix='The webpage information you have collected:', format=str) concepts $=$ dspy.Output Field(format=str)
class GenConcept(dspy.Signature):
"""请分析、总结和评估以下网页信息。像人一样思考,提炼每条信息的核心点,并将它们综合成一个全面的观点。以1. 2. ... 的格式呈现您的全面观点。"""
info = dspy.InputField(prefix='您收集的网页信息:', format=str)
concepts = dspy.OutputField(format=str)
```
Listing 2: Prompts used for reflecting in OmniThink.
表表 2: OmniThink 中用于反思的提示

图图 1:
class Write Section(dspy.Signature): """Write a Wikipedia section based on the collected information. Here is the format of your writing: 1. Use \$^{\circ}\#"\$ Title" to indicate section title, "##" Title" to indicate subsection title, "###" Title" to indicate sub subsection title, and so on. 2. Use [1], [2], ..., [n] in line (for example, "The capital of the United States is Washington, D.C.[1][3]."). You DO NOT need to include a References or Sources section to list the sources at the end. 3. The language style should resemble that of Wikipedia: concise yet informative, formal yet accessible. info \$=\$ dspy.InputField(prefix="The Collected information:\n", format=str) topic \$=\$ dspy.InputField(prefix="The topic of the page: ", format=str) section \$=\$ dspy.InputField(prefix="The section you need to write: ", format=str) output \$=\$ dspy.Output Field( pref \$\mathrm{i}\mathbf{x}{=}^{m}\mathsf{W}\mathbf{r}\mathrm{i}\$ te the section with proper inline citations (Start your writing with # section title. Don't include the page title or try to write other sections): \${\mathsf{N}}^{\prime\prime}\$ , format=str)
``````markdown
class WriteSection(dspy.Signature):
"""根据收集的信息撰写维基百科章节。以下是写作格式:
1. 使用 `\$^{\circ}\#"\$` 标题" 表示章节标题,使用 `##` 标题" 表示子章节标题,使用 `###` 标题" 表示子子章节标题,以此类推。
2. 在行内使用 [1], [2], ..., [n](例如,"美国的首都是华盛顿特区。[1][3].")。你无需在最后包含参考文献或资料来源部分来列出出来源。
3. 语言风格应类似于维基百科:简洁而信息丰富,正式而易于理解。
info = dspy.InputField(prefix="收集的信息:\n", format=str)
topic = dspy.InputField(prefix="页面的主题: ", format=str)
section = dspy.InputField(prefix="需要撰写的章节: ", format=str)
output = dspy.OutputField(prefix="撰写带有适当行内引用的章节(从 # 章节标题开始撰写。不要包含页面标题或尝试撰写其他章节): ", format=str)
```
# Listing 4: Prompts used for writing section in OmniThink.
列表列表 4: OmniThink 中用于写作部分的提示词。
class PolishPage(dspy.Signature): """ You are a faithful text editor that is good at finding repeated information in the article and deleting them to make sure there is no repetition in the article. You won't delete any non-repeated part in the article. You will keep the inline citations and article structure (indicated by "#", "##", etc.) appropriately. Refine the statement to avoid vague and ambiguous expressions, making it more concise and clear. Do your job for the following article. """ article \$=\$ dspy.InputField(prefix="The article you need to polish: \${\mathsf{N}}^{\prime\prime}\$ , format=str) page \$=\$ dspy.Output Field( pref \$\dot{\mathbf{\eta}}_{1\times=\,^{m}}\$ Your revised article: \${\mathsf{N}}^{\prime\prime}\$ , format=str)
``````markdown
class PolishPage(dspy.Signature):
"""
您是一位忠实的文本编辑,擅长查找文章中的重复信息并将其删除,以确保文章没有重复内容。您不会删除文章中的任何非重复部分。您将适当地保留内联引用和文章结构(由"#", "##"等表示)。优化陈述,避免模糊和歧义表达,使其更加简洁明了。请对以下文章进行处理。
"""
article = dspy.InputField(prefix="需要润色的文章: \${\mathsf{N}}^{\prime\prime}\$, format=str)
page = dspy.OutputField(pref \$\dot{\mathbf{\eta}}_{1\times=\,^{m}}\$ 修订后的文章: \${\mathsf{N}}^{\prime\prime}\$, format=str)
```
# Listing 5: Prompts used for polishing article in OmniThink.
清单清单 5: OmniThink 中用于文章润色的提示词。
<html><body><table><tr><td>Criteria Description</td><td>1Guidance for Content Generation: Does the outline effectively guide content generation, ensuring comprehensive coverage of the topic?</td></tr><tr><td>Score 1 Description</td><td>The outline fails to guide content generation, omitting significant aspects of the topic or providing insufficient direction.</td></tr><tr><td>Score 2 Description</td><td>The outline provides limited guidance, covering some key areas but lacking depth or completeness in addressing the topic.</td></tr><tr><td>Score 3 Description</td><td></td></tr><tr><td>Score 4 Description</td><td></td></tr><tr><td>Score5Description</td><td>1The outline is exemplary in guiding content generation, thoroughly addressing all aspects of the topic with clear, detailed direction and no significant gaps.</td></tr><tr><td></td><td>Hierarchical Clarity: Does the outline clearly define a hierarchy of topics and subtopics, with a logical, diverse structure that is easy to understand?</td></tr><tr><td>Criteria Description</td><td>The outline exhibits no discernible hierarchical structure.</td></tr><tr><td>Score 1 Description</td><td>Topics and subtopics are jumbled together without logical separation or clear levels, making it nearly impossible to follow or identify any organization. The outline attempts to establish a hierarchy but fails to maintain logical consistency. Main topics and subtopics are frequently misclassified,</td></tr><tr><td>Score 2Description</td><td>and the structure is overly rigid or disjointed. Subtopics may be missing, misplaced, or redundant, making it hard to grasp the intent of the structure. The outline has a recognizable hierarchical structure but lacks diversity in organization style. While main topics are somewhat clear, subtopics occasionally overlap,</td></tr><tr><td>Score 3 Description</td><td>are misaligned, or follow a repetitive format. This restricts flexibility and introduces mild confusion in certain areas.</td></tr><tr><td>Score 4 Description</td><td>The outline displays a clear, logical, and diverse hierarchical structure. Main topics are distinct, and subtopics are properly nested. While most elements are well-placed, there may be minor redundancies or opportunities to introduce more diverse formats for subtopics. Slight adjustments could achieve better precision and variety in style.</td></tr><tr><td>Score 5 Description</td><td></td></tr><tr><td>Criteria Description</td><td>Logical Coherence: Does the outline logically organize topics and subtopics, ensuring a smooth and natural flow of ideas with clear logical transitions?</td></tr><tr><td>Score 1 Description</td><td>The outline is highly disjointed and incoherent. Topics and subtopics appear in a random, unordered manner, with no logical flow or sense of progression. Major conceptual gaps and illogical jumps are present throughout the structure.</td></tr><tr><td>Score 2 Description</td><td>The outline shows some attempt at logical organization, but it contains frequent inconsistencies, abrupt shifts, or logical missteps. Topics and subtopics are misaligned or lack proper transitions, making the reader work hard to follow the structure.</td></tr><tr><td>Score3Description</td><td>The outline demonstrates a basic level of logical coherence. Most topics follow a general sequence, but some sections feel forced, with weak or unclear transitions. There are small jumps in logic, causing slight confusion or loss of flow at certain points.</td></tr><tr><td></td><td></td></tr><tr><td>Score4Description</td><td>The outline exhibits a strong sense of logical flow, with ideas presented in a mostly smooth and connected manner.</td></tr><tr><td></td><td></td></tr><tr><td></td><td></td></tr><tr><td></td><td></td></tr><tr><td></td><td></td></tr><tr><td></td><td>Transitions between topics and subtopics are clear, but a few minor adjustments could make the flow more seamless or natural. The logic is sound, but room for refinement exists.</td></tr><tr><td>Score 5 Description</td><td>The outline achieves exceptional logical coherence. Each topic and subtopic follows a deliberate, thoughtful progression, with clear, natural, and intuitive transitions.</td></tr><tr><td></td><td>The reader experiences a seamless flow of ideas, and no adjustments are required to improve logical consistency or flow.</td></tr><tr><td></td><td></td></tr><tr><td></td><td></td></tr><tr><td></td><td></td></tr><tr><td></td><td></td></tr><tr><td></td><td></td></tr><tr><td></td><td></td></tr><tr><td></td><td></td></tr><tr><td></td><td></td></tr><tr><td></td><td></td></tr><tr><td></td><td></td></tr><tr><td></td><td></td></tr><tr><td></td><td></td></tr><tr><td></td><td></td></tr><tr><td></td><td></td></tr><tr><td></td><td></td></tr><tr><td></td><td></td></tr><tr><td></td><td></td></tr><tr><td></td><td></td></tr><tr><td></td><td></td></tr><tr><td></td><td></td></tr><tr><td></td><td></td></tr><tr><td></td><td></td></tr><tr><td></td><td></td></tr></table></body></html>
<html><body><table><tr><td>Criteria Description</td><td>Broad Coverage:Does the article provide an in-depth exploration of the topic and have good coverage?</td></tr><tr><td>Score 1 Description</td><td>Severely lacking; offers little to no coverage of the topic's primary aspects,resulting in a very narrow perspective.</td></tr><tr><td>Score 2 Description</td><td>Partial coverage; includes some of the topic's main aspects but misses others, resulting in an incomplete portrayal.</td></tr><tr><td>Score3Description</td><td>Acceptable breadth; covers most main aspects, though it may stray into minor unnecessary details or overlook some relevant points.</td></tr><tr><td>Score 4 Description</td><td></td></tr><tr><td>Score5Description</td><td>Exemplary in breadth; delivers outstanding coverage, thoroughly detailing all crucial aspects of the topic without including irrelevant information.</td></tr><tr><td>Criteria Description</td><td>Novelty:Does the report cover novel aspects that relate to the user's initialintent but are not directly derivedfrom it?</td></tr><tr><td>Score1 Description</td><td>Lacks novelty;the report strictlyfollows the user's initialintent with no additionalinsights.</td></tr><tr><td>Score 2 Description</td><td>Minimal novelty; includes few new aspects but they are not significantly related to the initial intent.</td></tr><tr><td>Score 3Description</td><td>Moderate novelty;introduces some new aspects that are somewhat related to the initial intent.</td></tr><tr><td>Score 4Description</td><td>Good novelty;covers several new aspects that enhance the understanding of the initial intent.</td></tr><tr><td>Score5Description</td><td>Excellent novelty;introduces numerous new aspects that are highly relevant and significantly enrich the initial intent.</td></tr><tr><td>Criteria Description</td><td>Relevance and Focus:How effectively does the report maintain relevance and focus,given the dynamic nature of the discourse?</td></tr><tr><td>Score 1 Description</td><td>Verypoorfocus;discourse divergessignificantlyfrom theinitial topic andintent withmanyirrelevant detours.</td></tr><tr><td>Score 2 Description</td><td></td></tr><tr><td>Score3 Description</td><td>Poor focus; some relevant information,but many sections diverge from the initial topic.</td></tr><tr><td>Score 4 Description</td><td>Moderatefocus;mostlystays on topicwith occasional digressions that still provideuseful information. Good focus; maintains relevance and focus throughout the discourse with minor divergences that add value.</td></tr><tr><td>Score5Description</td><td>Excellent focus; consistently relevant and focused discourse, even when exploring divergent but highly pertinent aspects.</td></tr><tr><td>Criteria Description</td><td>Depth of Exploration:How thoroughly does the report explore theinitial topic andits related areas,reflecting the dynamic discourse?</td></tr><tr><td>Score 1 Description</td><td></td></tr><tr><td>Score 2 Description</td><td></td></tr><tr><td>Score3Description</td><td>Moderate depth; coverskey aspects but maylack detailed exploration in some areas.</td></tr><tr><td>Score4Description</td><td>Good depth; explores most aspects in detail with minor gaps.</td></tr><tr><td>Score5Description</td><td>Excellent depth;thoroughly explores all relevant aspects with comprehensive detail,reflecting a deep and dynamic discourse.</td></tr></table></body></html>
|| 标准描述 | 广泛覆盖:文章是否对主题进行了深入探讨并具有良好的覆盖范围? || --- | --- |
| 分数 1 描述 | 严重缺乏;几乎没有覆盖主题的主要方面,导致视角非常狭窄。 |
| 分数 2 描述 | 部分覆盖;包括了一些主题的主要方面,但遗漏了其他方面,导致描述不完整。 |
| 分数 3 描述 | 可接受的广度;涵盖了大多数主要方面,尽管可能涉及一些不必要的小细节或遗漏了一些相关点。 |
| 分数 4 描述 | |
| 分数 5 描述 | 广度典范;提供了出色的覆盖范围,详细介绍了主题的所有关键方面,且不包含无关信息。 |
| 标准描述 | 新颖性:报告是否涵盖了与用户初始意图相关但并非直接从中衍生的新颖方面? |
| 分数 1 描述 | 缺乏新颖性;报告严格遵循用户的初始意图,没有额外的见解。 |
| 分数 2 描述 | 极少新颖性;包括了一些新的方面,但它们与初始意图并不显著相关。 |
| 分数 3 描述 | 适度新颖性;引入了一些与初始意图相关的新方面。 |
| 分数 4 描述 | 良好新颖性;涵盖了了几个新的方面,增强了对初始意图的理解。 |
| 分数 5 描述 | 卓越新颖性;引入了许多高度相关且显著丰富初始意图的新方面。 |
| 标准描述 | 相关性和聚焦性:在动态讨论中,报告如何有效保持相关性和聚焦性? |
| 分数 1 描述 | 聚焦性极差;讨论显著偏离初始主题和意图,有许多无关的迂回。 |
| 分数 2 描述 | |
| 分数 3 描述 | 聚焦性差;一些相关信息,但许多部分偏离了初始主题。 |
| 分数 4 描述 | 适度聚焦性;大部分时间保持在主题上,偶尔的偏离仍然提供了有用的信息。良好聚焦性;在整个讨论中保持相关性和聚焦性,偏离的部分也增加了价值。 |
| 分数 5 描述 | 卓越聚焦性;始终保持相关性和聚焦性的讨论,即使在探讨偏离但高度相关的方面时也是如此。 |
| 标准描述 | 探索深度:报告如何深入探索初始主题及其相关领域,反映动态讨论? |
| 分数 1 描述 | |
| 分数 2 描述 | |
| 分数 3 描述 | 适度深度;涵盖关键方面,但可能在某些领域缺乏详细探索。 |
| 分数 4 描述 | 良好深度;详细探索了大多数方面,仅存在小缺口。 |
| 分数 5 描述 | 卓越深度;全面探索所有相关方面,详细深刻,反映出深度和动态的讨论。 |

Figure 12: A case of AlphaFold generated by OmniThink.
图图 12: OmniThink 生成的 AlphaFold 案例。