孟然,张星宇,李玉明,马成光 蚂蚁集团支付宝终端技术部 { mengrang.mr, zxy449919, luoque.lym, chenguang.mcg } @antgroup.com
项目页面: antgroup.github.io/a... v2
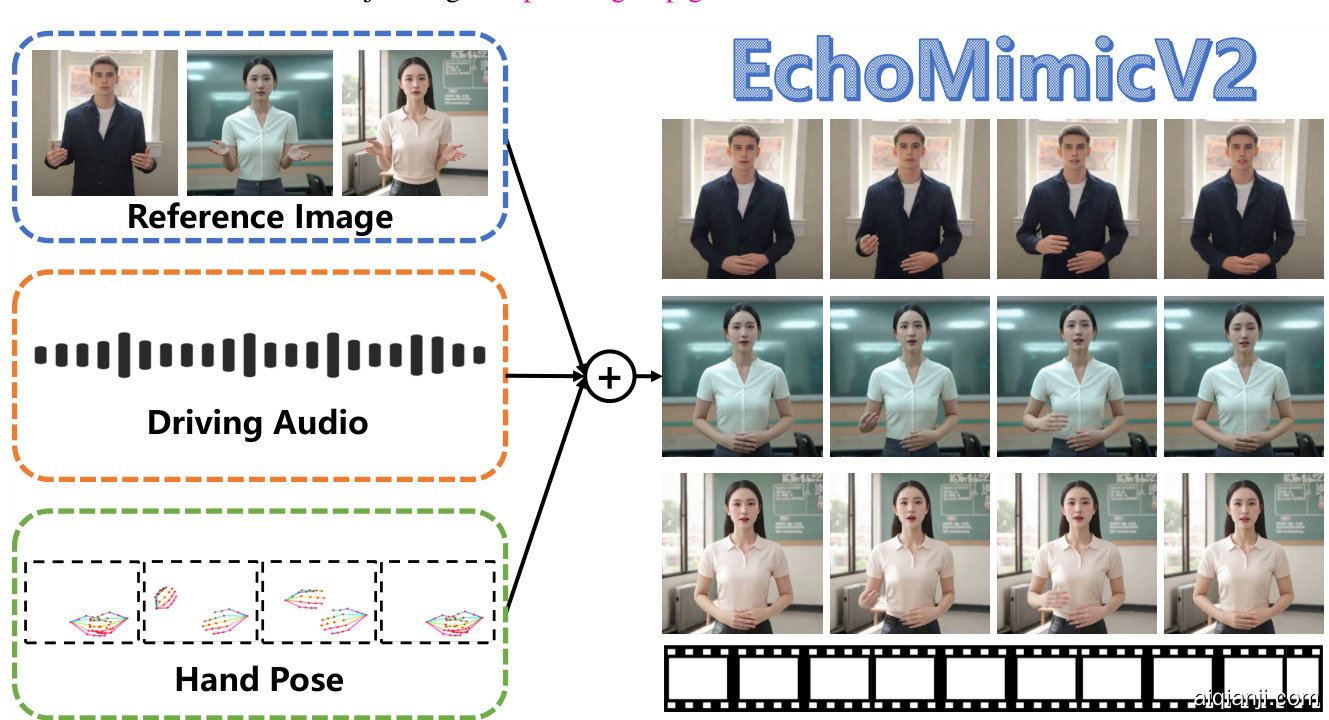
图 1. EchoMimicV2 利用参考图像、音频片段和一系列手部姿势来生成高质量的动画视频,确保音频内容与半身体动作之间的一致性。
摘要
最近关于人体动画的研究通常涉及音频、姿势或运动图谱条件,从而实现逼真的动画质量。 然而,这些方法往往面临实际挑战,例如额外的控制条件、繁琐的条件注入模块或头部区域驱动限制。 因此,我们想知道在简化不必要的条件的同时,是否可以实现令人惊艳的半身体人体动画。 为此,我们提出了一种半身体人体动画方法,名为 EchoMimicV2,该方法利用新颖的音频-姿势动态协调策略,包括姿势采样和音频扩散,以增强半身体细节、面部和姿态表达力,同时减少条件冗余。 为了弥补半身体数据稀缺的问题,我们利用头部局部注意力将头部照片数据无缝地融入我们的训练框架,这在推理过程中可以省略,为动画提供了一种免费的“午餐”。 此外,我们设计了特定阶段的去噪损失,分别指导动画在特定阶段的动作、细节和低级质量。 此外,我们还提出了一个新的基准来评估半身体人体动画的有效性。 广泛的实验和分析表明,EchoMimicV2 在定量和定性评估方面都超过了现有方法。
1. 引言
基于扩散的视频生成取得了显著进展[1, 3, 5, 8, 8, 9, 11, 12, 12, 21, 21, 33],推动了人体动画领域的广泛研究。 人体动画,作为视频生成领域的一个子集,旨在从参考人物图像合成自然逼真的以人为中心的视频序列。 当前关于人体动画的研究通常采用预训练的扩散模型作为骨干,并包含相应的条件注入模块来引入控制条件[6, 14, 17, 26, 30, 31, 37, 38],以便能够生成栩栩如生的动画。 不幸的是,学术研究和工业需求之间仍然存在差距:1)头部区域限制;2)条件注入的复杂性。 1)头部区域限制。 一方面,先前的人体动画工作[6, 30, 31, 37]主要集中在生成头部区域视频,而忽略了音频和肩部以下身体部位的同步。 最近的工作[17]通过辅助条件和超越音频驱动模块的注入模块改进了半身体动画。 2)条件注入的复杂性。 另一方面,常用的控制条件(例如 文本、音频、姿态、光流、运动图)可以为栩栩如生的动画提供坚实的基础。 特别是,当前的研究工作集中于聚合补充条件,这导致由于多条件不协调而导致训练不稳定,以及由于复杂的条件注入模块而导致推理延迟增加。
对于第一个挑战,存在一个简单的基线来累积与肩部以下身体相关的条件,例如半身体关键点图。 但是,我们发现这种方法由于条件的复杂性增加(对于第二个挑战)而仍然不可行。
在本文中,为了弥补上述问题,我们引入了一种新颖的端到端方法——EchoMimicV2,它基于肖像动画方法 EchoMimic [6]。 我们提出的 EchoMimicV2 力求实现高质量的半身体动画,同时简化条件。 为此,EchoMimicV2 利用音频姿态动态协调(APDH)训练策略来调节音频和姿态条件,同时减少姿态条件的冗余。 此外,它利用一个稳定的训练目标函数,称为特定阶段损失(PhD Loss),来增强运动、细节和低级质量,取代冗余条件的引导。
特别地,APDH 受华尔兹舞步的启发,其中音频和姿态条件如同同步的舞伴。 当姿态优雅地后退时,音频无缝地向前推进,完美地填充空间以创造和谐的旋律。 结果,音频条件的控制范围通过音频扩散从嘴部扩展到全身,同时姿态条件通过姿态采样从全身限制到手部。 鉴于负责音频表达的主要区域位于嘴唇,我们从嘴巴部分开始音频条件扩散。 此外,由于姿态和言语交流的互补性,我们保留了手部姿态条件以进行姿态动画,从而克服了头部区域限制的挑战,扩展到半身区域动画。
在整个过程中,我们发现了一种数据增强的捷径。 当音频条件仅控制头部

表 1. 我们提出的 EchoMimicV2 的简化说明。
区域通过头部局部注意力,我们可以无缝地结合填充的头部照片数据来增强面部表情,而无需像[17]那样需要额外的插件。 我们还在表 1 中列出了我们提出的 EchoMimicV2 的优点。
此外,我们提出了一种稳定的训练目标函数,即特定阶段损失函数(PhD Loss),它有两个目标:1)增强具有不完整姿态的运动表示;2)改进不受音频控制的细节和低级视觉质量。 虽然同时使用整合姿态、细节和低级视觉目标函数的多损失机制是很直观的,但这种方法通常需要额外的模型,包括姿态编码器和 VAE 解码器。 鉴于基于 ReferenceNet 的主干网络已经需要大量的计算资源[14],实施多损失训练变得不切实际。 通过实验分析,我们将去噪过程细分为三个不同的阶段,每个阶段都有其主要关注点:1)姿态主导阶段,其中首先学习运动姿态和人体轮廓;2)细节主导阶段,其中细化角色特定细节;3)质量主导阶段,其中模型增强颜色和其他低级视觉质量。 因此,提出的 PhD Loss 量身定制,以针对每个特定的去噪阶段优化模型,即早期阶段的姿态主导损失、中间阶段的细节主导损失和最终阶段的低级损失,从而确保更有效和稳定的训练过程。
此外,为了方便社区对半人体动画进行定量评估,我们策划了一个名为 EMTD 的测试基准,其中包含来自互联网的半人体视频。 我们进行了广泛的定性和定量实验和分析,证明我们的方法取得了最先进的结果。 总之,我们的贡献如下:
• 我们提出了 EchoMimicV2,这是一个端到端的音频驱动框架,用于生成引人注目的半人体动画,但由简化的条件驱动;
• 我们提出了 APDH 策略,以细致地调节音频和姿态条件,并减少姿态条件冗余;
• 我们提出了 HPA,一种无缝的数据增强方法,用于增强半人体动画中的面部表情,无需额外的模块;
• 我们提出了 PhD Loss,这是一个新颖的目标函数,用于增强运动表示、外观细节和低级视觉质量,交替引导完整的姿态条件;
• 我们提供了一个用于半人体动画的新颖评估基准;
• 进行了大量的实验和分析,以验证我们提出的框架的有效性,该框架超越了其他最先进的方法。
2. 相关工作
2.1. 姿态驱动的人体动画
许多人体动画方法都侧重于姿态驱动的设置,使用来自驱动视频的姿态序列。 姿态驱动的人体视频生成研究通常遵循标准流程,采用各种姿态类型,例如骨骼姿态、密集姿态、深度、网格和光流——作为引导模式,以及文本和语音输入。 条件生成模型已经随着稳定扩散 (SD) 或稳定视频扩散 (SVD) 作为了其骨干而发展起来。 像 MagicPose[4]这样的方法通过 ControlNet[36]将姿态特征集成到扩散模型中,而像 AnimateAnyone[14]、MimicMotion[38]、MotionFollower[24]和 UniAnimate[27]这样的方法则使用 DWPose[35]或 OpenPose[20]提取骨骼姿态。 这些方法使用具有少量卷积层的轻量级神经网络作为姿态引导,以在去噪过程中将骨骼姿态与潜在空间噪声对齐。 相反,DreamPose[15]和 MagicAnimate[32]使用 DensePose[10]提取密集姿态信息,将其与噪声连接起来,并作为 ControlNet[36]的去噪 UNet 的输入。 Human4DiT[22]受 Sora 启发,使用 SMPL[2]提取 3D 网格地图,并采用扩散 Transformer 进行视频生成。
2.2. 音频驱动的人体动画
音频驱动人体动画的目标是从语音音频中生成手势,确保动作在语义、情感和节奏上与音频对齐。 现有工作通常侧重于说话的头部。 EMO[23]引入了帧编码模块以确保一致性。 AniPortrait[30]将映射到 2D 姿态的 3D 面部结构推进到更高级别,以获得连贯的序列。 V-Express 使音频与唇部动作和表情同步,细化情感细微之处。 Hallo[31]使用扩散模型来增强对表情和姿态的控制。 Vlogger[39]通过扩散模型从单个图像生成说话视频,以实现高质量、可控的输出。 MegActor- Σ [34]将音频和视觉信号集成到带条件扩散 Transformer 的肖像动画中。 TANGO[18] 生成协同语音肢体动作视频,改善对齐并减少伪影。 此外,EchoMimic[6]不仅能够通过音频和面部姿态单独生成肖像视频,还可以通过音频和选定面部姿态的组合来生成。 CyberHost[17]支持来自多种模态的组合控制信号,包括音频、全身关键点地图、2D 手部姿态序列和身体运动地图。
3. 方法
3.1. 预备知识
潜在扩散模型。 我们的方法基于潜在扩散模型 (LDM)[21],该模型采用变分自动编码器 (VAE) 编码器[16]$E$将图像 $I$ 从像素空间映射到更紧凑的潜在空间,表示为$z_{0}\ =\ E(I)$。 在训练过程中,高斯噪声逐渐添加到$z_{0}$中的各个时间步长$t,\in,[1,.,.,.,,T]$,确保最终的潜在表示 $z_{T}$服从标准正态分布 N $\mathcal{N}(0,1)$。 LDM 的主要训练目标是估计每个时间步长$t$引入的噪声,
$L_{latent}=E_{z_{t},t,c,\epsilon\sim\mathcal{N}(0,1)}[||\epsilon-\epsilon_{\theta}(z_{t},t,c)||_{2}^{2}]$
其中$\epsilon_{\theta}$表示可训练的去噪 U-Net, $c$表示音频或文本等条件。 在推理阶段,使用预训练模型迭代地去除从高斯分布采样的潜在向量中的噪声。 随后,使用 VAE 解码器$D$ 将去噪后的潜在向量解码回图像。
基于 ReferenceNet 的主干网络。 与 EchoMimic[6] 和其他流行的肖像动画作品[30, 31, 37] 一样,我们利用基于 ReferenceNet 的扩散架构作为我们的主干网络。 在基于 ReferenceNet 的主干网络中,我们利用预训练的 2D U-Net 的一个副本作为 ReferenceNet,以从参考图像中提取参考特征。 然后,这些特征通过交叉注意力机制注入去噪 U-Net,以保持生成图像和参考图像之间的外观一致性。 此外,我们使用预训练的 Wav2Vec 模型作为音频编码器$E_{A}$来提取音频嵌入,然后通过去噪 U-Net 中的音频交叉注意力块将其注入作为音频条件$c_{a}$,以实现运动和音频之间的同步。 此外,我们还集成了姿态编码器$E_{p}$来提取关键点地图。 然后将这些关键点地图与噪声潜在向量连接起来,并馈送到去噪 U-Net 中,作为姿态条件。 最后,我们将时间注意力块注入到去噪 U-Net 中,以捕获帧间运动依赖关系,从而实现动画的运动平滑度。
3.2. 音频姿态动态协调
本节介绍 EchoMimicV2 的核心训练策略:音频姿态动态协调 (APDH)。 APDH 用于逐步降低条件复杂度,并以类似华尔兹舞步的方式调节音频和姿态条件。 此策略包含两个主要组成部分:姿态采样 (PS) 和音频扩散 (AD)。

图 2. 我们提出的 EchoMimicV2 的整体流程。
3.2.1. 姿态采样
初始姿态阶段。 我们从一个完全由姿态驱动的阶段开始训练我们的框架。 令$\mathcal{P}^{init}$表示半身人像的完整关键点地图,由姿态编码器$\mathbf{E}_{\mathbf{P}}$编码。 在此阶段,我们关闭音频交叉注意力模块,仅优化去噪 U-Net 中的其他模块,以提供对人体动作的全面识别。
迭代姿态采样阶段。 在迭代层面,我们逐步为姿态条件 dropout 采样一些迭代步骤,概率随迭代次数增加而增加。 这种渐进式 dropout 有助于减轻对姿态条件的过度依赖。
空间姿态采样阶段。 在空间层面,我们按照以下顺序移除关键点来采样姿态条件:首先是嘴唇部分,其次是头部,最后是身体部分。 我们分别将采样的姿态条件表示为$\mathcal{P}^{-lips}$, $\mathcal{P}^{-head}$, 和$\mathcal{P}^{hands}$。 通过这样做,姿态条件对嘴唇运动、面部表情和身体(呼吸节奏)的控制逐步减弱,从而为音频驱动程序创造空间,使音频条件发挥主导作用。
3.2.2. 音频扩散
在初始姿态和交互式姿态采样阶段,音频交叉注意力块完全冻结。 在空间级别姿态采样阶段,音频条件开始逐步集成。音频-嘴唇同步。 去除嘴唇的关键点后,嘴唇的空间掩码 $\mathcal{A}_{lips}$ 应用于音频交叉注意力块作为嘴唇局部注意力,强制音频条件仅控制嘴唇运动。 通过这样做,增强了音频-嘴唇同步。
音频-面部同步。去除关键点后,空间掩码$A_{lips}$扩散到头部作为A $ A_{head} $,并应用于音频交叉注意力块作为头部局部注意力。 这允许音频条件主导整体面部表情,增强音频-面部表情同步。
音频-身体关联。 使用仅包含手的关键点$\mathcal{P}^{hands}$,局部掩码扩散到全局空间。 这导致完全由音频驱动的半身体动画,并伴有对手的姿态强调。 请注意,手的部分作为音频和姿态条件之间的交集。因此,更多音频线索被转化为适当的手势,从而更好地捕捉音频-手势关联。
3.3. 用于数据增强的头部局部注意力
在音频-面部同步过程中,我们引入头部特写数据来弥补半身数据稀缺的问题并增强面部表情。 为此,我们对头部特写数据进行填充,以严格对齐半身图像的空间维度和头部位置。 然后,我们重用头部局部注意力机制来排除填充部分,如图 2 所示。 值得注意的是,不需要额外的交叉注意力块。 为了减轻填充对源分布的影响,我们在音频-面部同步阶段引入半身数据之前加入了这一步骤。

图 3. EchoMimicV2 在不同参考图像、手部姿态和音频下的结果。
3.4. 时间模块优化
沿用 EchoMimic[6],我们将时间交叉注意力块集成到去噪 U-Net 中,并使用 EchoMimic 初始化其权重。 在时间模块的优化过程中,我们使用 24 帧视频片段作为输入,并冻结其他模块以确保稳定性。
3.5. 阶段特定的去噪损失
除了上述条件设计和训练策略之外,我们还通过阶段特定的去噪损失(PhD Loss)$L_{\mathrm{PhD}}$提高了性能。 我们根据多时间步去噪过程的主要任务将其分为三个阶段:1)姿态主导阶段(早期)$S_{1}$ ;2)细节主导阶段(中间)$S_{2}$ ;3)质量主导阶段(最终)$S_{3}$。 相应地, $L_{\mathrm{PhD}}$包括三个定制的损失函数,分别表示为姿态主导损失$L_{\mathrm{pose}}$ 、细节主导损失$L_{\mathrm{dettail}}$和低级损失$L_{\mathrm{low}}$,这些损失函数在这三个阶段依次应用。
姿态主导损失$L_{pose}$:具体来说,我们首先采用一步采样来计算去噪 U-Net 对时间步长$t$的潜在输出$Z_{t}$的预测$Z_{0}^{t}$。 然后,我们通过 VAE 解码器 $D$解码潜在变量$Z_{0}^{pred}$,以获得$Z_{t}$的 RGB 形式$I_{0}^{t}$。 接下来,我们使用姿态编码器$E_{P}$提取$I_{0}^{t}$和目标图像$I_{target}$的关键点图,分别表示为$M_{0}^{t}$和$M_{target}$。 最后,我们在$M_{p}^{t}$和$M_{p}^{target}$上实现 MSE 损失来计算$S_{1}$中的$L_{pose}$,如下所示:
$$
L_{pose}=MSE(M_{p}^{t},M_{p}^{target})
$$
细节主导损失$L_{detail}$:我们使用 ControlNet[36]中使用的 Canny 算子来提取$I_{0}^{t}$和$I_{target}$的边缘和其他高频细节,分别表示为$M_{d}^{t}$和$M_{d}^{target}$。 并计算和的 MSE 损失作为 S $S_{2}$中的$L_{detail}$:
$$
L_{detail}=MSE(M_{d}^{t},M_{d}^{targe })
$$
低级损失$L_{low}$:我们利用 LPIPS,遵循 EchoMimic 的空间损失作为我们$S_{3}$中的$L_{low}$:
$$
L_{detail}=LPIPS(I_{0}^{t},I_{target})
$$
我们还遵循 LDM 中的潜在损失来优化模型,记为$L_{latent}$。 然后我们得到最终的 PhD 损失,如下所示:

其中$\lambda_{pose},\lambda_{detail}$和$\lambda_{low}$是损失权重。
4. 实验
在本节中,我们首先提供实现细节、训练数据集和我们实验中使用的评估基准。

图 4。 EchoMimicV2 的结果与基于姿态驱动的半身体人物动画基线进行比较。
在此之后,我们将通过与可比方法的定量和定性比较来评估我们方法的优越性能。 接下来,我们还进行了消融研究,以分析我们方法中每个组件的有效性。
4.1. 实验设置
实现细节。 我们的训练过程包括两个阶段。 在第一阶段,模型被训练以从参考图像生成目标帧,确保视觉一致性。 我们首先使用完整的关键点图$P^{init}$作为姿态条件,联合训练姿态编码器和去噪 U-Net,同时屏蔽音频交叉注意力。 此过程在 8 个 A100 GPU 上进行 10,000 次迭代,每个 GPU 的批量大小为 4,分辨率为。 然后,我们使用 AudioPose 动态协调训练我们的框架。 在迭代姿态采样阶段,我们对框架进行了 10,000 步的训练,姿态条件的 dropout 概率从增加到。 在空间姿态采样阶段,我们首先利用$P^{-lips}$和嘴唇局部注意力训练我们的框架 10,000 步,然后利用$P^{-head}$和头部局部注意力在 EchoMimic 的头照数据上训练我们的框架 10,000 步。 随后,我们使用半身体数据对框架进行了 10,000 次迭代的训练。 最后,我们进行了 10,000 次迭代$P^{hands}$和全局音频交叉注意力。 对于$L_{PhD}$,S$S_{1}$的范围是

图 5。 EchoMimicV2 的结果与基于音频驱动的半身体人体动画基线进行比较。
早期时间步,$S_{2}$的范围是接下来的60%时间步,其余时间步被分成 S$S_{3}$。 并且 $\lambda_{pose}$, $\lambda_{detail}$和$\lambda_{low}$的损失权重都设置为 0.1。 在第二阶段,我们仅优化时间注意力模块和其他冻结的模块,批量大小为 4,进行 30,000 步的训练。 对于这两个阶段,学习率都设置为$1e^{-5}$,参考图像和音频的无分类器引导 (CFG) 比例设置为 2.5。
训练数据集。 我们的训练数据集包含三个部分:完全姿态驱动的数据集、半身体数据集和头像数据集。 我们使用 HumanVid[29] 作为完全姿态驱动的数据集,其中包含大约 20,000 个高质量的以人为中心的视频,带有 2D 姿态标注。 半身体训练数据集是从互联网视频中整理出来的,重点关注半身体说话场景。 此数据集时长 160 小时,包含超过 10,000 个身份。 头像数据集源自 EchoMimic 中使用的训练数据集,包含 540 小时的说话头像视频。
新颖的半身体评估基准。 公开数据集通常评估音频驱动的说话头像或姿态驱动的角色动画,但没有专门针对音频驱动的半身体动画。 为填补这一空白,我们引入了 EchoMimicV2 测试数据集 (EMTD) 用于评估半身体角色动画。 EMTD 包含来自 YouTube 的 65 个高清 TED 视频 (1080P),其中包含 110 个带标注的、清晰的、正面朝向的半身体语音片段。 开源项目将提供可下载的脚本。

表 2。 我们提出的 EchoMimicV2 与其他 SOTA 方法的定量比较和消融研究。
用于评估这些视频的剪辑、切片和处理。 由于授权有限,我们只提供定性结果,不会显示可视化结果。 我们还发布了由 FLUX.1dev 1 生成的参考图像的人物角色。 这些资源支持比较实验,并促进进一步的研究和应用。
评估指标。 半身人动画方法使用 FID、FVD[25]、PSNR[13]、SSIM[28]、E-FID[7] 等指标进行评估。 FID、FVD、SSIM 和 PSNR 是用于评估低级视觉质量的指标。 E-FID 使用 Inception 网络特征评估图像真实性,利用面部重建方法提取表情参数,并计算其 FID 分数以衡量表情差异。 为了评估身份一致性,我们计算参考图像和生成的视频帧的面部特征之间的余弦相似度 (CSIM)。 此外,我们还使用 SyncNet[19] 计算 Sync-C 和 Sync-D 以验证音频唇部同步精度。 此外,为了评估手的部分动画,采用 HKC(手关键点置信度)平均值来评估音频驱动场景中的手部质量,并计算 HKV(手关键点方差)以指示手部运动的丰富程度。
4.2. 定性结果
为了评估我们提出的 EchoMimicV2 的定性结果,我们使用 FLUX.1-dev 生成的参考图像,然后基于这些参考图像进行半身动画。 我们的方法使用音频信号、参考图像和手部姿势序列生成高分辨率的半身人体视频。 图 3 展示了我们的方法在合成各种音频视觉输出方面的适应性和弹性,并与伴随的音频无缝同步。 这些结果肯定了其在推进音频驱动半身人体视频生成的最新技术方面的潜力,并说明我们提出的 EchoMimicV2 可以在不同的角色和复杂的手势中很好地泛化。
与姿态驱动身体方法的比较。 我们对 EchoMimicV2 进行了定性评估,并与最先进的姿态驱动方法(包括 AnimateAnyone[14] 和 MimicMotion[38])进行了比较,如图 5 所示。 我们可以看到,我们提出的 EchoMimicV2 在结构完整性和身份一致性方面优于当前最先进的结果,尤其是在手和脸等局部区域。 补充材料中提供了额外的视频比较结果。 与音频驱动人体方法的比较。 只有少数作品,例如 Vlogger[39]和 CyberHost[17],支持音频驱动的半人体动画。 遗憾的是,这些方法尚未开源,这对直接比较提出了挑战。 我们从这两个项目的首页获得了相关的实验结果,并使用相同的参考图像进行了实验。 如图 4 所示,我们提出的 EchoMimicV2 在生成的图像质量和运动的自然度方面都超过了 Vlogger 和 CyberHost。
4.3. 定量结果
如表 2 所示,我们将 EchoMimicV2 与最先进的人体动画方法进行了定量比较,包括 AnimateAnyone[14]和 MimicMotion[38]。 结果表明,EchoMimicV2 显著提高了整体性能。 具体而言,EchoMimicV2 在质量指标(FID、FVD、SSIM 和 PSNR)方面显示出显著的改进,并在同步指标(Sync-C 和 Sync-D)方面取得了具有竞争力的结果。 此外,EchoMimicV2 在一致性指标(CSIM)方面也超过了其他 SOTA 方法。 需要注意的是,EchoMimicV2 在与手相关的质量指标(HKV、HKC)方面取得了新的 SOTA。
4.4. 消融研究
我们在表 2 中分析了我们的音频姿态动态协调(APDH)策略、条件简化设计和 PhD 损失的有效性。
姿态采样的分析。 我们进行了消融研究,以验证姿态采样每个阶段的有效性。 具体来说,我们可以观察到初始姿态和迭代姿态采样阶段由于全身姿态条件提供的强大运动先验而有助于整体性能的提升。 另一方面,表 2 的第 7 行显示,完整的姿态条件(无空间姿态采样)对每个指标的影响有限,表明全身姿态的冗余性,并且我们的 APDH 策略仍然可以仅用手的姿态条件实现稳定的动画。
音频扩散分析。 如表 2 所示,第 9 行和第 10 行表明音频扩散增强了嘴唇运动和面部表情。 此外,第 10 行表明音频条件也改善了身体和手的动画,这表明 EchoMimicV2 捕获了细粒度的相关性,即与音频相关的呼吸节奏和与音频相关的姿态。
头像数据增强的分析。 表 2 中的第 8 行显示,头像数据增强显着影响同步指标(Sync-D、Sync-C)。
PhD 损失分析。 我们还验证了 EchoMimicV2 中 PhD 损失中每个组件的影响。 如表 2 的第 12 行到第 14 行所示,我们观察到$L_{pose}$对整体指标有重大影响,因为它弥补了姿态条件的不完整性。 此外,$L_{detail}$显着提高了局部质量指标(如 Sync-C、Sync-D、E-FID、HKC 和 HKV)的性能。 此外,$L_{low}$有助于提高质量指标(SSIM、PSNR)的性能。
直接基线分析。 我们还进行了一项消融研究,以验证整体 APDH 训练策略和 PhD 损失的有效性。 我们使用半身体音频和手部姿态条件训练骨干网络,没有采用渐进式 APDH 策略和 PhD 损失,作为一个直接的基线。 如表 2 最后一行所示,由于两种条件之间转换不足,该基线模型取得了次优的结果。 这些结果表明,APDH 和 PhD 损失对于简化条件下的稳定训练至关重要。
手部姿态条件分析。 当前的图像和视频生成方法在生成细节丰富的手部区域方面面临着固有的挑战。 如图 6 所示,即使是最先进的文本到图像方法(例如, FLUX.1)也难以进行手部合成,而在音频驱动的生成中,由于音频信号与运动之间的相关性较弱,这个问题被放大了。 为了解决这个问题,EchoMimicV2 结合了手部姿态和音频条件,尽管手部像素比例较低,但仍展现出强大的手部修复能力。

图 6. 当参考图像中没有手部或手部变形时,EchoMimicV2 生成高保真度的手部。
半身图像中的元素。 值得注意的是,即使在参考图像中不存在手部,EchoMimicV2 也能生成高保真度的手部,如图 6 所示。 通过移除所有姿态条件并保持其他设置,我们获得了一个完全由音频驱动的动画模型,该模型能够捕捉一般的姿态,并将手部节奏与音频音调相关联。 然而,该模型无法生成诸如握拳或敬礼等特定手势。 由于篇幅限制,视频结果已提供在补充材料中。
5. 限制
本文在音频驱动的半身人体动画方面取得了重大进展,但必须承认现有局限性和需要进一步改进的领域。 (1) 音频到手部姿态生成:该方法需要预定义的手部姿态序列,依赖于人工输入以获得高质量的动画,限制了实际应用。 未来工作将探索直接从音频生成手部姿态序列,采用端到端范式。 (2) 非裁剪参考图像的动画:虽然 EchoMimicV2 在裁剪的半身图像上表现稳健,但在非裁剪图像(例如全身图像)上的性能下降。
6. 结论
在这项工作中,我们提出了一种有效的 EchoMimicV2 框架,用于生成由简化条件驱动的引人注目的半身人体动画。 我们通过提出的 APDH 训练策略和特定时间步长的 PhD 损失实现了音频姿态条件协作和姿态条件简化,同时通过 HPA 无缝增强面部表情。 综合实验表明,EchoMimicV2 在定量和定性结果上都超过了当前最先进的技术。 此外,我们引入了一个新的基准来评估半身人体动画。 为了促进社区发展,我们将我们的源代码和测试数据集提供开源使用。
参考文献
[1] Andreas Blattmann,Tim Dockhorn,Sumith Kulal,Daniel Mendelevitch,Maciej Kilian,Dominik Lorenz,Yam Levi,Zion English,Vikram Voleti,Adam Letts 等人。稳定视频扩散:将潜在视频扩散模型扩展到大型数据集。arXiv 预印本 arXiv:2311.15127, 2023. 1
[2] Federica Bogo,Angjoo Kanazawa,Christoph Lassner,Peter Gehler,Javier Romero 和 Michael J Black。保持简单:从单张图像自动估计 3D 人体姿态和形状。在计算机视觉——ECCV 2016:第 14 届欧洲会议,荷兰阿姆斯特丹,2016 年 10 月 11-14 日,论文集,第五部分 14,第 561-578 页。Springer,2016。 3
[3] Tim Brooks,Bill Peebles,Connor Holmes,Will DePue,Yufei Guo,Li Jing,David Schnurr,Joe Taylor,Troy Luhman,Eric Luhman 等人。视频生成模型作为世界模拟器,2024。 1
[4] Di Chang,Yichun Shi,Quankai Gao,Hongyi Xu,Jessica Fu,Guoxian Song,Qing Yan,Yizhe Zhu,Xiao Yang 和 Mohammad Soleymani。Magicpose:具有身份感知扩散的逼真人体姿态和面部表情重新定位。在第四十一届国际机器学习会议,2023。 3
[5] Haoxin Chen,Menghan Xia,Yingqing He,Yong Zhang,Xiaodong Cun,Shaoshu Yang,Jinbo Xing,Yaofang Liu,Qifeng Chen,Xintao Wang 等人。Videocrafter1:用于高质量视频生成的开放扩散模型。arXiv 预印本 arXiv:2310.19512, 2023. 1
[6] Zhiyuan Chen,Jiajiong Cao,Zhiquan Chen,Yuming Li 和 Chenguang Ma。Echomimic:通过可编辑地标条件实现逼真的音频驱动肖像动画。arXiv 预印本 arXiv:2407.08136, 2024. 2, 3, 5
[7] Yu Deng,Jiaolong Yang,Sicheng Xu,Dong Chen,Yunde Jia 和 Xin Tong。 基于弱监督学习的精确三维人脸重建:从单图像到图像集。 2019 年 IEEE/CVF 计算机视觉与模式识别研讨会论文集,第 0-0 页。 7
[8] Prafulla Dhariwal 和 Alexander Nichol。 扩散模型在图像合成方面优于 GANs。 2021 年神经信息处理系统进展,34:8780-8794。 1
[9] Patrick Esser,Johnathan Chiu,Parmida Atighehchian,Jonathan Granskog 和 Anastasis Germanidis。 基于扩散模型的结构和内容引导视频合成。 2023 年 IEEE/CVF 国际计算机视觉会议论文集,第 7346-7356 页。 1
[10] Rıza Alp Güler,Natalia Neverova 和 Iasonas Kokkinos。 DensePose:野外密集人体姿态估计。 2018 年 IEEE 计算机视觉与模式识别会议论文集,第 7297-7306 页。 3
[11] Yuwei Guo,Ceyuan Yang,Anyi Rao,Zhengyang Liang,Yaohui Wang,Yu Qiao,Maneesh Agrawala,Dahua Lin 和 Bo Dai。Animatediff:无需特定调优即可动画化您的个性化文本到图像扩散模型。arXiv 预印本 arXiv:2307.04725, 2023。1
[12] Jonathan Ho,Ajay Jain 和 Pieter Abbeel。去噪扩散概率模型。2020 年神经信息处理系统进展,33:6840-6851。1
[13] Alain Hore 和 Djemel Ziou。 图像质量度量:PSNR 与 SSIM。 2010 年第 20 届国际模式识别会议论文集,第 2366-2369 页。 IEEE,2010。 7
[14] 李虎。 使任何人栩栩如生:用于角色动画的一致且可控的图像到视频合成。 2024 年 IEEE/CVF 计算机视觉与模式识别会议论文集,第 8153-8163 页。 2, 3, 7
[15] Johanna Karras,Aleksander Holynski,Ting-Chun Wang 和 Ira Kemelmacher-Shlizerman。 Dreampose:通过稳定扩散进行时尚图像到视频的合成。 2023 年 IEEE/CVF 国际计算机视觉会议(ICCV)论文集,第 22623-22633 页。 IEEE,2023。 3
[16] Diederik P Kingma。 自动编码变分贝叶斯。 arXiv 预印本 arXiv:1312.6114,2013。 3
[17] 林高杰,蒋建文,梁超,钟天云,杨佳琪和郑燕波。Cyberhost:使用区域码本注意力来驯服音频驱动的化身扩散模型。arXiv 预印本 arXiv:2409.01876,2024。2, 3, 7
[18] 刘海阳,杨兴超,秋山智也,黄元田,李乔格,栗山滋和竹富隆文。Tango:具有分层音频运动嵌入和扩散插值的伴音手势视频重演。arXiv 预印本 arXiv:2410.04221,2024。3
[19] KR Prajwal,Rudrabha Mukhopadhyay,Vinay P Namboodiri 和 CV Jawahar。 您只需要一个唇形同步专家即可进行野外语音到唇部的生成。 2020 年第 28 届 ACM 国际多媒体会议论文集,第 484-492 页。 7
[20] Sen Qiao,Yilin Wang 和 Jian Li。 基于 OpenPose 的实时人体姿态评分。 2017 年第 10 届国际图像和信号处理、生物医学工程和信息学大会(CISP-BMEI)论文集,第 1-6 页。 IEEE,2017 年。 3
[21] Robin Rombach,Andreas Blattmann,Dominik Lorenz,Patrick Esser 和 Bj¨orn Ommer。 使用潜在扩散模型进行高分辨率图像合成。 IEEE/CVF 计算机视觉和模式识别会议论文集,第 10684-10695 页,2022 年。 1, 3
[22] Ruizhi Shao,Youxin Pang,Zerong Zheng,Jingxiang Sun 和 Yebin Liu。Human4dit:使用 4D 扩散 Transformer 进行自由视角人体视频生成。arXiv 预印本 arXiv:2405.17405,2024 年。3
[23] Linrui Tian,Qi Wang,Bang Zhang 和 Liefeng Bo。 Emo:Emote 肖像复现——在弱条件下使用 Audio2Video 扩散模型生成富有表现力的肖像视频。 arXiv 预印本 arXiv:2402.17485,2024 年。 3
[24] Shuyuan Tu,Qi Dai,Zihao Zhang,Sicheng Xie,Zhi-Qi Cheng,Chong Luo,Xintong Han,Zuxuan Wu 和 Yu-Gang Jiang。MotionFollower:通过轻量级评分引导扩散编辑视频运动。arXiv 预印本 arXiv:2405.20325,2024 年。
[25] Thomas Unterthiner,Sjoerd Van Steenkiste,Karol Kurach,Raphael Marinier,Marcin Michalski 和 Sylvain Gelly。迈向精确的视频生成模型:一项新的指标和挑战。arXiv 预印本 arXiv:1812.01717,2018 年。7
[26] Cong Wang,Kuan Tian,Jun Zhang,Yonghang Guan,Feng Luo,Fei Shen,Zhiwei Jiang,Qing Gu,Xiao Han 和 Wei Yang。V-Express:用于肖像视频生成渐进式训练的条件 dropout。arXiv 预印本 arXiv:2406.02511,2024 年。2
[27] Xiang Wang,Shiwei Zhang,Changxin Gao,Jiayu Wang,Xiaoqiang Zhou,Yingya Zhang,Luxin Yan 和 Nong Sang。UniAnimate:驯服统一的视频扩散模型以实现一致的人体图像动画。arXiv 预印本 arXiv:2406.01188,2024 年。3
[28] Zhou Wang,Alan C Bovik,Hamid R Sheikh 和 Eero P Simoncelli. 图像质量评估:从错误可见性到结构相似性. IEEE 图像处理汇刊, 13(4):600–612, 2004. 7
[29] Zhenzhi Wang,Yixuan Li,Yanhong Zeng,Youqing Fang,Yuwei Guo,Wenran Liu,Jing Tan,Kai Chen,Tianfan Xue,Bo Dai 等人. Humanvid:揭秘相机可控人像动画的训练数据. arXiv 预印本 arXiv:2407.17438, 2024. 6
[30] Huawei Wei,Zejun Yang 和 Zhisheng Wang. Aniportrait:音频驱动的逼真肖像动画合成. arXiv 预印本 arXiv:2403.17694, 2024. 2, 3
[31] Mingwang Xu,Hui Li,Qingkun Su,Hanlin Shang,Liwei Zhang,Ce Liu,Jingdong Wang,Yao Yao 和 Siyu Zhu. Hallo:用于肖像图像动画的分层音频驱动视觉合成. arXiv 预印本 arXiv:2406.08801, 2024. 2, 3
[32] Zhongcong Xu,Jianfeng Zhang,Jun Hao Liew,Hanshu Yan,Jia-Wei Liu,Chenxu Zhang,Jiashi Feng 和 Mike Zheng Shou. Magicanimate:使用扩散模型进行时间一致的人像动画. IEEE/CVF 计算机视觉和模式识别会议论文集,第 1481–1490 页,2024. 3
[33] Shuai Yang,Yifan Zhou,Ziwei Liu 和 Chen Change Loy. 重新渲染视频:零样本文本引导的视频到视频转换. SIGGRAPH Asia 2023 会议论文集,第 1–11 页,2023. 1