摘要
我们研究创建可以从动漫角色的单个图像实时控制的角色模型的问题。 这个问题的解决方案将大大降低创建头像、电脑游戏和其他交互式应用程序的成本。
Talking Head Anime 3 (THA3) 是一个开源项目,试图直接解决问题[34]。 它将 (1) 动漫角色上半身的图像和 (2) 45 维姿势向量作为输入,并输出采取指定姿势的同一角色的新图像。 对于个人化身和某些类型的游戏角色来说,可能的动作范围足以表达。 但该系统速度太慢,无法在普通 PC 上实时生成动画,图像质量还有待提高。
在本文中,我们通过两种方式改进 THA3。 首先,我们提出了基于 U-Net 的组成网络的新架构,该网络基于广泛应用于现代生成模型的具有注意力 [23] 的 U-Net 来旋转角色的头部和身体。 新架构始终能够产生比 THA3 基线更好的图像质量。 然而,它们也使整个系统变慢:生成一帧最多需要 150 毫秒。 其次,我们提出了一种将系统提炼为小型网络 (<2 MB) 的技术,该网络可以使用以下方法实时生成 512×512 动画帧 (≥30 FPS)消费级游戏 GPU,同时保持图像质量接近整个系统的图像质量。 这一改进使得整个系统对于实时应用来说非常实用。
1简介
我们感兴趣的是通过指定明确的姿势参数来为动漫角色的单个图像设置动画,就像控制一个装配好的 3D 模型一样。 我们的动机是最近流行的虚拟 YouTuber (VTuber),它们是演员在最新计算机图形技术的帮助下实时表演的动漫角色[44] 。 通常,VTuber 采用由 Live2D [42]、E-mote [45]< 等软件创建的可控分层图像(也称为 2.5D 模型)[41] /t2> 和脊柱 [17]。 由于创建这种模型的成本可能很高,因此解决方案将使获取可控化身以及制作电脑游戏和其他交互式媒体变得更加容易。
该问题已受到研究界[90, 35]、私营公司[26, 1]和个人开源开发者[34, 80]。 特别是,Khungurn 提出了一种名为“Talking Head Anime 3”(THA3)的神经网络系统,只需给出角色躯干正面视图的单个图像即可生成人形动漫角色的简单动画[34]. 当系统运行在强大的 GPU 上时,可以通过 45 个参数对角色进行交互控制,实现丰富的面部表情以及头部和身体小角度的旋转。 无需手动建模,该系统就可以生成类似于典型手工制作的 VTuber 模型的动作。
然而,THA3 系统有两个主要局限性。 首先是生成图像的质量。 当角色的被遮挡部分旋转并变得可见时,它们通常会变得模糊。 此外,该系统有去除薄结构的倾向,例如头部旋转后的毛发竖立。 第二个是系统的速度:只有使用非常强大的 GPU(例如 Nvidia Titan RTX [34])时才能实现交互式帧速率。 因此,它还不是一个适用于电脑游戏或 VTuber 流媒体等实时应用的实用系统。
本文对 THA3 系统提出了两项改进,以解决上述两个缺点。 第一个改进是旋转身体部位的子网络的新架构。 THA3 使用编码器-解码器网络和普通 U-Net,如原始论文 [65] 中所述。 我们的新架构基于带有注意力的 U-Net 变体 [81],通常用于扩散概率模型 [23, 16]。 它提高了三个常用指标下的图像质量,减少了遮挡中的模糊区域,并更好地保留薄结构。 不幸的是,这样做会牺牲推理速度,在 Titan RTX 上生成帧需要超过 100 毫秒。
第二个改进直接解决速度问题。 这个想法是将[22]整个系统的知识提炼到学生神经网络中,该网络很小(≈2 MB)并且可以生成512×512帧使用消费级游戏 GPU 的时间不超过 30 毫秒。 然而,学生专门处理特定的输入图像,无法对任何其他图像进行动画处理。 对于给定的角色图像,蒸馏需要数十个小时,但是一旦该过程完成,学生网络就可以用作可控的角色模型。 此功能使 THA 系统首次可用于实时应用。 虽然我们确实失去了改变角色并立即为其制作动画的能力,但该系统仍然实用,因为 VTuber 或游戏角色不会经常改变其外观(每秒或每分钟)。
学生网络的架构基于 SInusoidal REpresentation Network (SIREN) [72],我们对其进行了扩展,使其能够更快更好地保留输入图像的细节。 为了使 SIREN 更快,我们让它以多分辨率方式生成图像,类似于 GAN 生成图像的方式[62]:前几层生成一个低分辨率特征张量,即升级并传递到后面的层。 为了更好地保留输入图像的细节,我们使用 SIREN 生成外观流 [95] 用于扭曲输入图像。 然后通过 Alpha 混合将结果与另一个不太详细的输出相结合,该输出也是由 SIREN 直接生成的。 我们通过消融研究证明,我们提出的架构在速度和准确性之间实现了良好的权衡,能够在实时生成大图像的同时再现高频细节。 我们还提出了一个三阶段训练过程,该过程可以有效地训练我们提出的模型,并且我们验证所有阶段对于实现更好的图像质量都是必要的。
2相关作品
2.1隐式神经表示
学生网络是神经隐式表示 (INR) 的特例,其中神经网络用于近似信号而不是转换信号的函数。 INR 通常包含位置编码 [77] 或具有非常规激活函数 [72, 67] 或网络结构 [71]。 研究人员已将 INR 应用于图像 [75, 9]、3D 表面 [47, 57] 以及与辐射率相结合的体积密度 [52]< 等信号/t2>. INR 可用于构建高分辨率 3D 信号的生成模型,这在以前很难实现[10,6,7,69,76]。
虽然 INR 可用于直接表示铰接字符 [14, 89, 59, 97],但我们认为我们的信号是图像的参数化集合,如 Bemana 等人 [2] 而不是可变形的 3D 形状。 因此,我们的 INR 采用了相同的图像处理技术,例如扭曲和插值。 然而,我们的工作与 Bemana 等人的工作有两点不同。 首先,我们的图像集合的参数是混合形状权重和关节角度,而不是与视点、光照和时间相关的参数。 其次,我们使用 INR 来近似更大神经网络的输出,而不是填补稀疏测量之间的空白。
2.2单幅图像基于参数的摆姿
总的来说,我们希望从人形角色的单个图像创建简单的动画。 输入是主体的图像(目标图像),我们需要对其进行修改,以便主体根据某种规范摆出姿势。 根据姿势的指定方式,问题可分为基于参数的姿势(明确通过姿势向量)、动作转移(隐含通过另一主体的图像或视频)或视觉配音(通过语音记录推断)。 我们的系统解决了单个图像的基于参数的姿势问题。 因此,我们将审查解决相同问题的作品,不包括那些以视频或多个图像作为输入的作品。 据我们所知,可以通过三种方法来解决当前的问题。
2.2.1直接建模
我们可以根据目标图像创建主体几何形状的可控模型。 常见的方法是将 3D 可变形模型 (3DMM) [4, 5, 43, 39, 58, 55, 93] 拟合到图像。 虽然早期的作品在可控性方面受到限制,仅适用于图像处理[3,5,18],但最近的作品提供了更多的控制[19,24,40,21,13,37] 。 这种方法的局限性在于参数模型通常不会对所有可见部分进行建模。 例如,专门针对面部的模型可能会忽略头发 [40, 37, 37]、颈部 [24] 或两者 [19]。
尽管人们对人类照片建模进行了大量研究,但对其他图像领域的关注却少之又少。 Saragih 等人构建了非人脸的 3D 模型,然后对其进行变形以创建动画[68],但他们只能制作面具动画。 Jin 从单个动漫风格图像[28]创建 E 模式模型。 Chen 等人研究单个动漫角色图像 [8] 的 3D 重建,稍后可以借助现成组件将重建动画化 [87, 33]。
2.2.2潜在空间中的生成建模
我们首先训练一个生成模型,将潜在代码映射到图像,对其进行工程设计,以便可以通过姿势向量控制输出图像。 在测试时,我们将潜在代码拟合到目标图像。然后可以通过修复潜在代码并改变姿势向量来生成动画帧。
关于控制人脸已经进行了大量研究。 Tewari 等人训练网络根据 3DMM 参数 [78] 改变 StyleGAN [31, 30] 的潜在代码,并随后提出了一种专门的算法来拟合潜在代码肖像[79]。 Kowalski 等人 [36] 和 Deng 等人 [15] 使用不同的方法训练 GAN,每个潜在代码都具有显式可控的部分。 最近的作品扩展了 EG3D [7],一种 3D 感知的 GAN,以便可以控制面部表情[46,86,76]
2.2.3图像翻译
或者,我们可以将基于参数的姿势视为图像转换的特殊情况:根据某些标准将图像转换为另一图像。 Isola 等人[27]提出了一个基于条件生成对抗网络(cGAN)的通用框架[53],并通过后续研究在各个方面进行了扩展[ 96、11、12]。 最近,研究人员也开始探索使用扩散模型来完成任务[66,85,38]。
Pumarola 等人创建了一个网络,可以在给定面部表情[61]的动作单元 (AU)编码的情况下修改人类面部特征。 Ververas 和 Zafeiriou 执行相同的操作,但使用混合形状权重而不是 AU [82]。 Ren 等人的 PIRenderer 不仅可以处理面部表情,还可以处理头部旋转[63]。 张等人的 SadTalker [92] 可以通过 3DMM 参数控制人脸图像,将其映射到面部标志位置,然后将其输入到 Chen 等人的 Face-vid2vid 模型 [83] 移动输入图像。 Nagano 等人设计了一个条件 GAN,输出真实的面部纹理,将目标图像和模板网格的渲染作为输入,模板网格的表情可以自由控制[54]。
我们构建的 THA3 系统[34]基于 Pumarola 等人的面部特征处理技术和 Zhou 等人的图像旋转技术[94]。 张等人扩展了 THA 的第一个版本[32]以支持更大的旋转角度[90]。 Kim 等人创建了一个数据集,可用于训练基于参数的姿势者(例如 PIRenderer),以便它们可以处理动漫角色 [35]。
3基线
THA3 整体上是一个图像转换器,它以 (1) 人形动漫角色“半身镜头”的 512×512 图像和 (2) 45 维姿势向量作为输入,然后输出同一角色的新图像,现在已相应摆好姿势。 45 个参数使角色不仅可以表达各种情绪,还可以像典型的专业创建的 VTuber 模型一样移动头部和身体。 在 45 个参数中,39 个控制角色的面部表情,6 个控制面部和躯干的旋转。
该系统由 5 个神经网络组成,可分为两个模块。 三个网络组成一个名为面部变形器的模块,其职责是改变角色的面部表情。 我们不会修改此模块,但我们将在第 5 节中将其提炼为更小的网络。 其余两个网络称为半分辨率旋转器和编辑器。 它们一起形成一个名为身体旋转器的模块,其职责是根据 6 个非面部表情参数旋转头部和躯干。 半分辨率旋转器对通过缩小面部变形器的输出而获得的半分辨率 (256×256) 图像进行操作。 然后,其输出被放大为 512×512,然后传递给编辑器以提高图像质量,最后返回给用户。
这两个网络具有相同的整体结构。 每个都包含一个主干卷积神经网络(CNN):半分辨率旋转器使用编码器-解码器网络,编辑器使用 U-Net。 每个主干网络输出一个与输入图像具有相同分辨率的特征张量。 然后可以使用特征张量执行三个图像处理操作:
- 变形。 该特征被转换为外观流 ,这是一个映射,它告诉输出中的每个像素应从[95]复制输入中的哪个像素的数据。 然后将外观流应用于输入图像以获得其扭曲版本。
- 直接生成。 特征张量直接转换为像素值。 此操作不受输入图像中可见内容的限制。 它产生更合理的未遮挡部分,但无法保留可见部分中的所有细节。
- 混合。 特征张量被转换为 alpha 图,然后可用于将其他步骤的结果混合在一起,以获得两个操作的最佳特征。
网络的输出是使用上述操作的一些组合生成的。
4改进的网络架构
THA3 的主要问题之一是图像质量。 当身体部位旋转并且被遮挡的部分变得可见时,这些部分可能会变得模糊。 此外,如果这些部件很薄,系统往往会将它们完全移除。 为了缓解这个问题,我们修改了身体旋转器模块中的网络,但没有显着改变它们的功能。
4.1新的身体旋转器架构
半分辨率旋转器的接口没有变化。 它仍然需要 (1) 缩放到 256×256 的输入图像和 (2) 姿势向量,并且它仍然在 256×256 处输出外观流和姿势角色的图像。 > 分辨率。 另一方面,我们稍微改变了编辑器的界面。 它现在接受半分辨率旋转器的两个输出,放大到 512×512,而不是像 THA3 的编辑器那样只接受外观流。 改进后的身体旋转器的整体结构如图1所示。
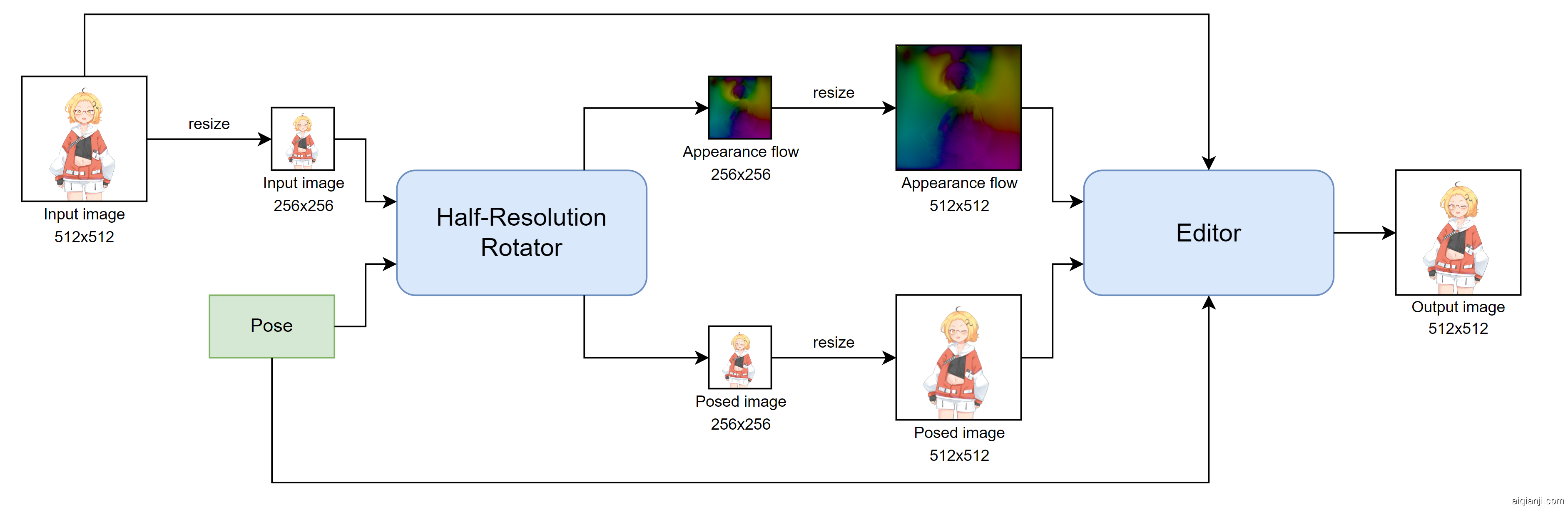
图 1:修改后的身体旋转器模块。我们将所有主干网络更改为带有注意层的 U-Net,目前广泛应用于扩散模型[23, 16],并被证明在图像生成方面表现出色。 我们还改变了网络处理输入和输出的方式。
- 半分辨率旋转器现在分三个步骤生成半分辨率姿势图像。 它 (1) 扭曲输入图像以生成一个候选输出,(2) 直接生成另一个候选输出,(3) 将两个结果进行 alpha 混合。 (参见图3的“图像形成”部分。) 在 THA3 中,缺少 alpha 混合步骤。
- 编辑器现在必须考虑一个额外的输入,因此我们在使用主干网络处理融合的张量之前,将输入图像和半分辨率旋转器的两个输出与卷积层融合。 网络的其余部分保持不变。
我们建议读者参阅附录A以获取有关更改的更完整描述。
4.2训练
我们使用从互联网上单独收集的大约 8,000 个可控 3D 动漫角色模型创建的数据集。 数据集中的每个示例都包含三个项目:(1)“休息”帖子中的角色图像,(2)姿势向量,以及(3)根据姿势向量摆出姿势后同一角色的另一张图像。 训练数据集包含 500,000 个示例,而测试数据集包含 10,000 个示例。 这两个数据集不共享 3D 模型,确保训练数据和测试数据之间的清晰分离。 如何准备数据集[34]请参阅 THA3 项目的文章。
我们使用两种类型的损失来训练网络:𝐿1损失和感知内容损失[29]。 半分辨率旋转器的训练分为两个阶段,第一阶段仅使用 𝐿1 损失,第二阶段则使用两者。 小编的训练分为三个阶段。 在前两个阶段,它像在 512×512 图像上运行的旋转器一样进行训练。 在最后阶段,我们添加考虑半分辨率旋转器输出的网络训练单元并继续。 有关训练过程的技术细节可以在附录B中找到。 它们包括损失函数、训练阶段、权重初始化、优化器和学习率计划的表达式。
4.3结果
4.3.1图像质量
我们将新的身体旋转器与旧的 THA3 身体旋转器进行比较。 为了进行定性比较,我们通过将网络生成的图像与测试数据集中的真实图像进行比较来评估网络。 我们使用三个指标来衡量图像相似度:(a) 峰值信噪比 (PSNR)、(b) 结构相似度 (SSIM) [84] 和 (c) LPIPS [ 91]。 表 1 报告了测试数据集 10,000 个示例的指标平均值。 我们可以看到,使用带有注意力的 U-Net 以及编辑器的额外输入改善了所有指标。 尤其是 LPIPS,比 THA3 提高了约 30%。
| Network | PSNR (↑) | SSIM (↑) | LPIPS (↓) |
|---|---|---|---|
| THA3 [34] | 22.369330 | 0.909369 | 0.048016 |
| Section 4 | 22.962184 | 0.919532 | 0.033566 |
表格 1:身体旋转器模型性能的定量比较。
图 2:身体旋转器模型生成的图像之间的定性比较。 这些艺术作品由 Mikatsuki Arpeggio [48,51,49,50]创作。为了进行定性比较,我们将网络应用于三个手绘角色,结果如图2所示。 角色的脸部和身体以尽可能大的角度旋转到观看者的左侧。 对于第 1 和第 2个角色,我们可以看到 THA3 旋转器无法生成清晰的左侧面部轮廓,以及第 2个角色佩戴的丝带接近被完全擦除。 另一方面,我们提出的架构产生了更清晰的轮廓,并更好地保留了丝带。 对于第3个角色,THA3 旋转器在右侧生成模糊的头发和丝带,而我们的旋转器生成更清晰的结果。 我们还可以在这里看到,我们提出的架构比基线更好地保留了该区域的纹理。
4.3.2模型大小和速度
表2比较了 THA3 系统和我们的建议的大小和速度。 新的编辑器网络比 THA3 的网络大 4 倍,但它并没有显着增加整个系统的大小,因为还有其他四个网络已经和它一样大了。 我们通过测量完全处理一张输入图像和一个姿势所需的时间来评估系统的速度,反映了它用于在应用程序中生成一个动画帧的情况。 我们在三台不同的计算机上进行了实验,用字母 A 到 C 标识,其详细信息在附录 C 中给出。这些计算机具有不同的 GPU,从面向研究的卡到面向消费者的游戏卡。 从表2中,我们可以看到我们提出的架构虽然能产生更高的图像质量,但速度比 THA3 系统慢约 3 到 4 倍。 就每秒帧数(FPS)而言,THA3 在最好的情况下可以在具有非常强大的 GPU 的机器上实现大约 30 FPS,但所提出的架构在相同设置下甚至无法达到 10 FPS。

表 2:THA3 系统与我们提议的系统之间的尺寸和速度比较。 生成一帧所需的时间是 1,000 次测量的平均值。
5蒸馏
上一节的结果表明,我们对提高图像质量的追求导致模型速度慢得多。 那么,我们的下一个任务是提高图像生成速度,以便在功能较弱的硬件上实现实时性能。
我们首先观察到该系统功能过于强大。 我们可以随时更改输入图像,并且更改会立即反映在输出图像上。 然而,在电脑游戏或流媒体中,角色不会每秒或每分钟都改变其外观。 因此这个功能是不必要的。 通过创建专门针对特定输入图像的模型,我们可以获得在实时约束下工作的更快模型。 如果我们提前准备很多这样的模型,我们可以交换模型来改变角色,或者让角色在需要时改变其外观。
为了创建这样一个专门的模型,我们依靠知识蒸馏 [22],这是训练较小模型(学生)的做法模仿更大模型(老师)的行为。 在我们的例子中,教师是上一节中提出的完整系统。
我们提出的所有学生模型都是基于坐标的网络[77],因为通过构造,它们允许以与子图像大小成比例的成本生成任何特定的子图像。 此外,与基于 CNN 的图像生成器不同,子图像生成无需生成整个图像即可完成。 此功能有利于游戏角色和实时流媒体,因为在某些情况下,用户可能只想描绘头部而不是整个躯干。 我们采用的具体架构是 SInusoidal REpresentation Network (SIREN)[72],因为我们发现它产生的平滑图像非常适合动漫风格。 另一方面,竞争方法(具有傅立叶特征的 ReLU MLP [77])往往会产生颗粒状伪影 [72]。
5.1学生架构
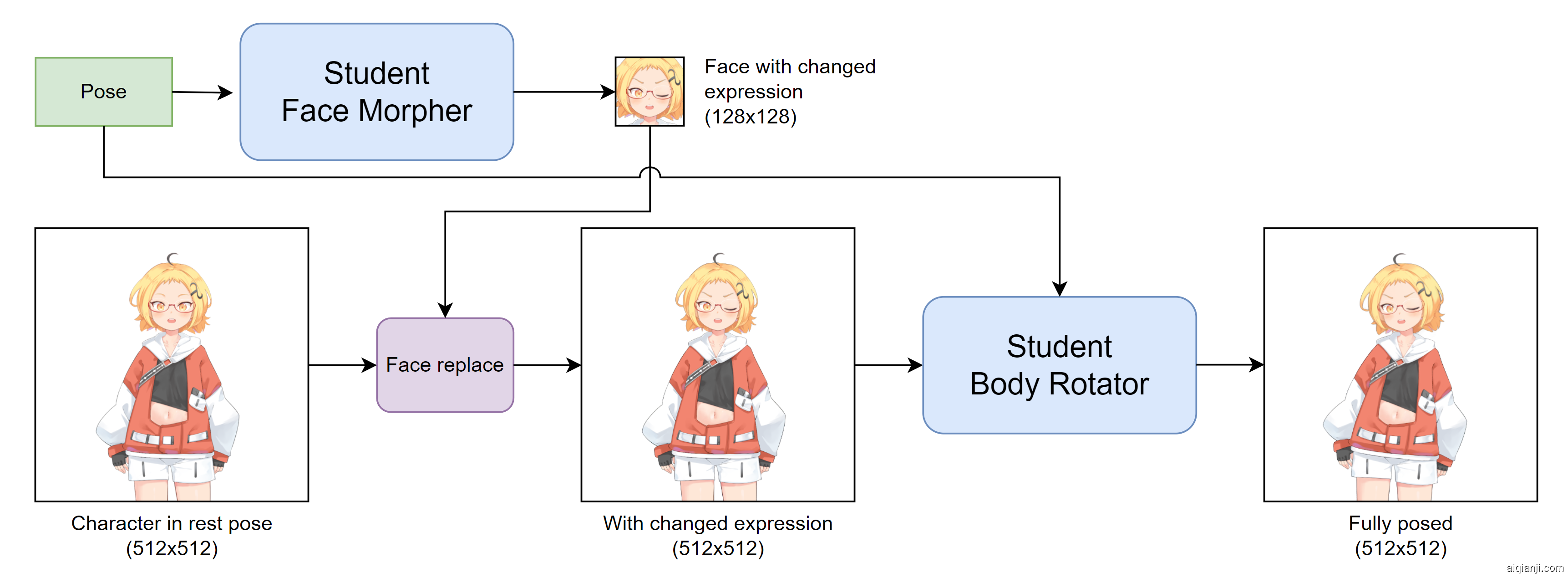
图 3:学生模型的总体架构。与完整系统一样,学生模型包含两个模块,面部变形器和身体旋转器,具有相同的功能。 它们不再是五个大型网络的集合,而是两个总大小不到 2 MB 的小型网络。 学生架构的概述如图3所示。

图 4:学生脸部变形者的架构。学生面部变形器是一个 SIREN,具有 9 个完全连接的层,其中每个隐藏层有 128 个神经元。 其架构如图4所示。 它被训练为生成输入图像的 128×128 区域,其中包含角色的可移动面部器官(眉毛、眼睛、嘴巴和下巴)。 SIREN 接收像素位置(2 维)和面部姿势(39 维)作为输入,并生成 RGBA 像素(4 维)。 其大小仅为 475 KB。

图 5:学生身体旋转器的架构。学生身体旋转器的架构更加复杂,因为它需要实时生成更大的输出(512×512图像)。 像学生脸部变形器这样的普通 SIREN 会太慢,因为它必须在其所有层上对空间大小为 512×512 的张量进行操作。 为了提高速度,我们将图像生成过程分为三个子步骤,其中网络首先对空间分辨率为 128×128 的张量进行操作,然后是 256×256,最后是 512×512。 每个子步骤都有 3 个全连接层,最后一个子步骤有 4 个全连接层,从而形成一个具有 10 个这样的层的网络。 此外,为了保留输入图像的精细细节,网络不会直接生成输出图像。 相反,它使用教师身体旋转器所采用的图像形成过程。 特别是,网络经过训练可生成 (1) 外观流、(2) RGBA 图像和 (3) alpha 图。 首先使用外观流扭曲输入字符图像,然后将扭曲的图像与直接生成的 RGBA 图像进行 alpha 混合,从而形成输出图像。 模型大小约为 1.3 MB。 学生身体旋转器的架构如图5所示。
5.2学生训练
5.2.1面部变形器
学生面部变形器经过训练,可最小化其输出与教师面部变形器生成的输出之间的 L1 差异。 损失函数有两项。 第一个是整个输出之间的 L1 差异,第二个是包含可移动面部部件的区域之间的 L1 差异。 我们将第二项的重量比第一项重 20 倍,因为可移动部分与整个面部相比较小。 损失的精确定义在附录D中给出。
在训练时,角色图像是固定的,姿势向量是从整个系统的训练数据集中统一采样的。 训练持续 2 个 epoch(1M 个示例),批量大小为 8。 我们将 Adam 优化器与$ 𝛽_{1}=0.9$ 和 $𝛽_{2}=0.999$ 一起使用。 学习率从 $10^{-4}$ 开始,在 200K、500K 和 800K 训练示例后分别衰减到 $3.33×10^{-5}$、$1×10^{-5}$ 和 $3.33×10^{-6}$ 。 在具有四个 V100 GPU 的计算机上训练大约需要一个半小时。
5.2.2身体旋转器
首先回想一下,身体旋转器使用与教师身体旋转器相同的图像形成过程。 最后一个全连接层的输出是(1)外观流$I_{flow}$,它立即用于从固定字符图像生成扭曲图像$𝐼_{warped}$,(2)RGBA 图像 $𝐼_{direct}$,以及 (3) alpha 贴图 $𝐼_{alpha}$。 然后,$𝐼_{warped}$、$𝐼_{direct}$ 和 $𝐼_{alpha}$ 与 Alpha 混合相结合,生成最终输出图像 $𝐼_{final}$。 由于教师也会生成这些数据,因此我们将学生生成的数据与上标“𝑆”(例如$𝐼_{flow}^𝑆$、$𝐼_{warped}^𝑆$)和学生生成的数据进行区分。由教师生成的带有上标“𝑇”(例如$𝐼_{direct}^𝑇$、$𝐼_{final}^𝑇$)的。
学生身体旋转器经过训练,可最大限度地减少 4 项损失,其中每项涉及上述生成的数据之一:
| $$ ℒ_{br}=𝜆_{flow}ℒ_{flow}+𝜆_{warped}ℒ_{warped}+𝜆_{direct}ℒ_{direct}+𝜆_{final}ℒ_{final} $$ |
|---|
其中$ℒ_{□}=‖𝐼_{□}^𝑆−𝐼_{□}^𝑇‖_1$和□可以替换为上式中的后缀。 𝜆变量是整个训练过程中变化的权重,训练过程分为三个阶段,如表3所示。 我们可以看到,第一阶段侧重于训练直接生成,第二阶段侧重于变形,第三阶段侧重于最终输出。
| Phase | # Examples | $𝜆_{flow}$ | $𝜆_{warped}$ | $𝜆_{direct}$ | $𝜆_{final}$ |
|---|---|---|---|---|---|
| #1 | ≤ 400K | 0.50 | 0.25 | 2.00 | 0.25 |
| #2 | ≤ 800K | 5.00 | 2.50 | 1.00 | 1.00 |
| #3 | ≤ 1.5M | 1.00 | 1.00 | 1.00 | 10.00 |
表 3:学生身体旋转器的训练阶段。就像我们对学生面部变形器所做的那样,我们还从完整系统的训练数据集中采样姿势向量,使用带有 $𝛽_{1}=0.9$ 和 $𝛽_{2}=0.999$ 的 Adam 优化器,并设置批次大小为 8。 然而,训练现在持续 3 个时期(150 万个例子)。 学习率从 $10^{−4}$ 开始,在我们展示 200K、600K 和 1.3M 训练后衰减到 $3×10^{−5}$、$10^{−5}$ 和 $3×10^{−6}$分别举例。 在具有四个 V100 GPU 的计算机上训练大约需要 10 小时。 我们尚未在其他计算机上测量训练时间,但我们推测在具有单个 GPU 的计算机上需要数十个小时。
5.3结果
我们通过使用模型根据 4.2 节中测试数据集的 1,000 个固定姿势来摆出角色姿势来评估模型。 对于每个姿势图像,我们计算相对于教师模型生成的相应图像的 PSNR。 然后我们记录 1,000 个结果 PSNR 值的平均值。
5.3.1与老师的比较

表 4:THA3 系统、教师模型(第4节)和学生模型生成一帧动画所需的平均时间的比较。
| Character | PNSR (dB) |
|---|---|
| Top [51] | 36.156 |
| Middle [49] | 36.048 |
| Bottom [50] | 34.543 |
表 5:由经过训练以对图 2 中的角色进行动画处理的学生模型生成的图像的平均 PSNR。正如 5.1 节中提到的,学生模型比整个系统小得多:1.8 MB 与 627 MB。 生成单个动画帧的速度也快了大约 8 倍,如表 4 所示。 与 THA3 系统相比,速度大约快 3 倍,因此现在可以在具有标准消费级 GPU 的计算机 C 上实现实时动画(≥ 30 FPS)。

至于生成图像的质量,我们在图2中的三个角色上训练了学生模型。 我们在表 5 中报告了平均 PSNR,范围从 34 dB 到 36 dB 左右。 这意味着平均误差约为最大像素值的 2%。 定性地讲,很难发现学生和教师输出之间的巨大差异,但学生模型可能会忽略极其精细的细节,例如代表鼻子的黑点,如图 6 所示和图7。
5.3.2学生网络架构消融研究
在本节中,我们将展示所提出的架构比更简单的替代方案取得了改进。 我们将我们的架构与(a)直接生成输出图像的普通 SIREN 和(b)我们提出的架构进行比较,其中身体旋转器被修改,以便它始终以 512×512 分辨率运行。 我们训练这三种架构来为特定角色图像 [74] 制作动画,并使用平均 PSNR 指标对其进行评估。 我们还测量了4.3.2节中使用的 3 台计算机上生成动画帧所需的平均时间。 统计数据如表6所示。 为了进行定性比较,我们在图 6 中显示了生成的图像。

图 6:教师和三个学生建筑生成的图像之间的定性比较。 该角色是 © Touhoku Zunko ⋅ Zundamon Project [73]。
我们在表 6 中看到,学生架构的 PSNR 值彼此相当。 然而,图6表明,普通的 SIREN 架构在质量上比其他两种架构差很多,因为它无法再现精细的面部细节,例如眉毛、嘴型和瞳孔的高光。 保留这些精细细节需要更复杂的图像形成步骤。 没有多分辨率 SIREN 的架构比所提出的架构稍微准确一些。 然而,很难发现图 6 中生成的图像之间的差异。 所提出的架构的优点是它的速度:表6显示它比没有多分辨率 SIREN 的架构快两倍。 换句话说,多分辨率设计在保持准确性的同时使网络速度显着加快。
5.3.3学生训练过程的消融研究

表 7:经过特定训练阶段和未经特定训练阶段训练的学生模型之间的定量比较。学生模型的训练过程有 3 个训练阶段,损失项的权重不同。 为了证明这些阶段的必要性,我们在上一节中在角色图像上训练了学生模型,取消了训练阶段,同时保持其余设置相同。 我们在表 7 中报告了模型的平均 PSNR 值。 我们发现采用所有阶段都获得了最好的分数。 省略第 1 阶段会导致图像质量明显变差。 这在质量上表现为图 7 中旋转面形状的明显差异。 经过第 1 阶段训练的模型的 PSNR 分数约为 38,表明它们很好地近似了教师的总体输出。 然而,细节上却存在明显的退化。 模型 D 没有再现瞳孔上的亮点。 E 型和 F 型在头带周围产生了伪影。 此外,F 型还在头部的一侧产生了锯齿状边缘。 经历了所有训练阶段的模型 G 获得了最高的 PSNR 分数并产生了最少的伪影,这表明了所有训练阶段的必要性。
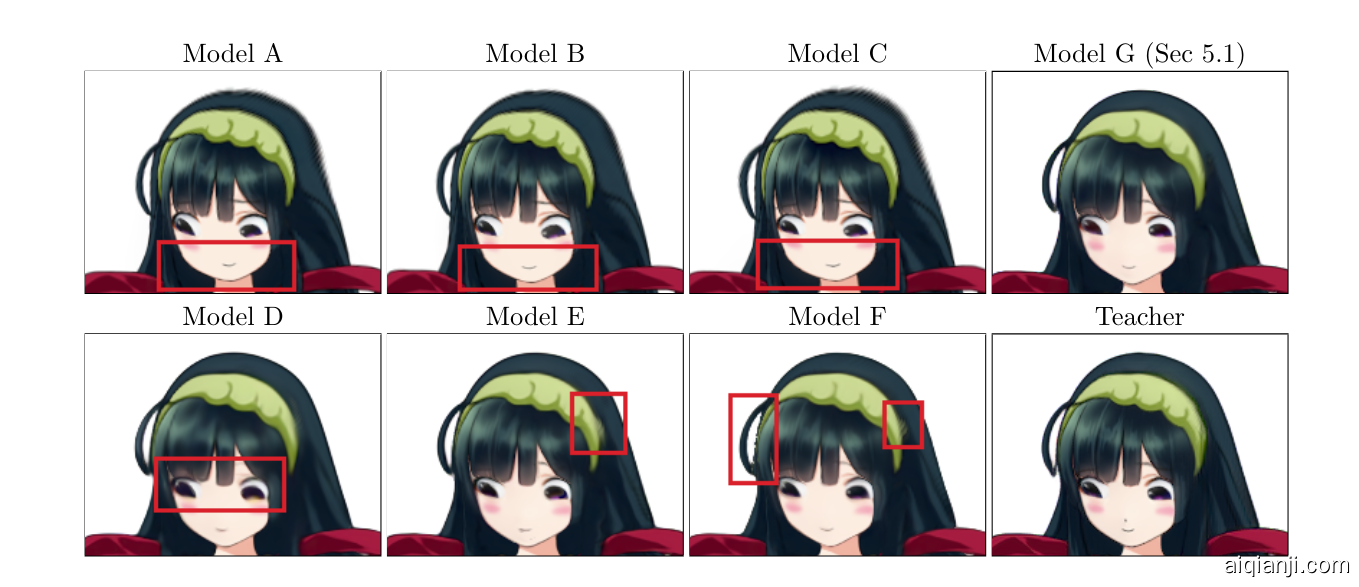
图 7:表7中模型输出的定性比较。 有问题的区域用红色矩形突出显示。
5.3.4其他结果
学生模型快速且轻量级,可以在网络浏览器中执行,并且仍然实时生成动画。 在补充材料中,我们包含两个演示 Web 应用程序。 其中一种允许用户通过操作 UI 小部件来摆出角色姿势。 另一种方法是让角色模仿网络摄像头捕捉到的用户动作。
6结论
我们对 Talking Head Anime 3 (THA3) 系统提出了改进,提高其图像质量并加快速度,以便它可以使用消费级游戏 GPU 实时生成流畅的动画。 后者的改进使得该系统首次作为流媒体工具变得实用。 主要的见解是,我们可以使用更昂贵的架构(带有注意力的 U-Net)来获得更好的图像质量,然后将改进的模型提炼给小而快的学生。 我们的技术贡献包括学生模型的有效架构(具有变形和混合的多分辨率 SIREN)以及训练它的算法。
我们的工作仍然存在一些局限性。 虽然身体旋转器的新架构大大提高了图像质量,但仍有进一步提高的空间。 该系统只能移动面部器官,使面部和躯干旋转小角度。 最后,虽然学生模型足够轻量级,可以在消费级游戏 GPU 上运行,但它仍然无法在平板电脑或手机等设备上运行。 我们希望在未来的工作中解决这些问题。
参考
- [1]Algoage Inc.DeepAnime: Automatically turning illustration to anime.https://lp.deepanime.com/, 2022.Accessed: 2023-08-07.
- [2]Bemana, M., Myszkowski, K., Seidel, H.-P., and Ritschel, T.X-fields: Implicit neural view-, light- and time-image interpolation.ACM Transactions on Graphics (Proc. SIGGRAPH Asia 2020) 39, 6 (2020).
- [3]Blanz, V., Scherbaum, K., Vetter, T., and Seidel, H.-P.Exchanging Faces in Images.Computer Graphics Forum (2004).
- [4]Blanz, V., and Vetter, T.A morphable model for the synthesis of 3d faces.In Proceedings of the 26th Annual Conference on Computer Graphics and Interactive Techniques (USA, 1999), SIGGRAPH ’99, ACM Press/Addison-Wesley Publishing Co., p. 187–194.
- [5]Cao, C., Weng, Y., Zhou, S., Tong, Y., and Zhou, K.Facewarehouse: A 3d facial expression database for visual computing.IEEE Transactions on Visualization and Computer Graphics 20, 3 (2014), 413–425.
- [6]Chan, E., Monteiro, M., Kellnhofer, P., Wu, J., and Wetzstein, G.pi-GAN: Periodic Implicit Generative Adversarial Networks for 3D-Aware Image Synthesis.In CVPR (2021).
- [7]Chan, E. R., Lin, C. Z., Chan, M. A., Nagano, K., Pan, B., Mello, S. D., Gallo, O., Guibas, L., Tremblay, J., Khamis, S., Karras, T., and Wetzstein, G.Efficient geometry-aware 3D generative adversarial networks.In CVPR (2022).
- [8]Chen, S., Zhang, K., Shi, Y., Wang, H., Zhu, Y., Song, G., An, S., Kristjansson, J., Yang, X., and Zwicker, M.Panic-3d: Stylized single-view 3d reconstruction from portraits of anime characters.In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2023).
- [9]Chen, Y., Liu, S., and Wang, X.Learning continuous image representation with local implicit image function.In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2021), pp. 8628–8638.
- [10]Chen, Z., and Zhang, H.Learning implicit fields for generative shape modeling.Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2019).
- [11]Choi, Y., Choi, M., Kim, M., Ha, J.-W., Kim, S., and Choo, J.Stargan: Unified generative adversarial networks for multi-domain image-to-image translation.In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2018).
- [12]Choi, Y., Uh, Y., Yoo, J., and Ha, J.-W.Stargan v2: Diverse image synthesis for multiple domains.In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2020).
- [13]Corona, E., Zanfir, M., Alldieck, T., Gabriel Bazavan, E., Zanfir, A., and Sminchisescu, C.Structured 3d features for reconstructing relightable and animatable avatars.In CVPR (2023).
- [14]Deng, B., Lewis, J. P., Jeruzalski, T., Pons-Moll, G., Hinton, G., Norouzi, M., and Tagliasacchi, A.Nasa neural articulated shape approximation.In Computer Vision – ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part VII (Berlin, Heidelberg, 2020), Springer-Verlag, p. 612–628.
- [15]Deng, Y., Yang, J., Chen, D., Wen, F., and Tong, X.Disentangled and controllable face image generation via 3d imitative-contrastive learning, 2020.
- [16]Dhariwal, P., and Nichol, A.Diffusion models beat gans on image synthesis.In Advances in Neural Information Processing Systems (2021), M. Ranzato, A. Beygelzimer, Y. Dauphin, P. Liang, and J. W. Vaughan, Eds., vol. 34, Curran Associates, Inc., pp. 8780–8794.
- [17]Esoteric Software.Spine: 2d animation for games.http://esotericsoftware.com/, 2023.Accessed: 2023-08-07.
- [18]Fried, O., Shechtman, E., Goldman, D. B., and Finkelstein, A.Perspective-aware manipulation of portrait photos.ACM Trans. Graph. 35, 4 (July 2016).
- [19]Geng, Z., Cao, C., and Tulyakov, S.3d guided fine-grained face manipulation.In CVPR (2019).
- [20]He, K., Zhang, X., Ren, S., and Sun, J.Deep residual learning for image recognition.In Proceedings of the IEEE conference on computer vision and pattern recognition (2016), pp. 770–778.
- [21]He, T., Xu, Y., Saito, S., Soatto, S., and Tung, T.Arch++: Animation-ready clothed human reconstruction revisited.In ICCV (2021).
- [22]Hinton, G., Vinyals, O., and Dean, J.Distilling the knowledge in a neural network, 2015.
- [23]Ho, J., Jain, A., and Abbeel, P.Denoising diffusion probabilistic models.CoRR abs/2006.11239 (2020).
- [24]Hong, Y., Peng, B., Xiao, H., Liu, L., and Zhang, J.Headnerf: A real-time nerf-based parametric head model.In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2022).
- [25]Huang, X., and Belongie, S.Arbitrary style transfer in real-time with adaptive instance normalization.In ICCV (2017).
- [26]IRIAM Inc.Character streaming service “iriam,” using technology contributed by preferred networks, becomes the first in the world to implement automatic character modeling by ai in smart phones. an illustration can move with rich expression through the power of ai.https://prtimes.jp/main/html/rd/p/000000006.000070082.html, 2021.Accessed: 2023-08-07.
- [27]Isola, P., Zhu, J.-Y., Zhou, T., and Efros, A. A.Image-to-image translation with conditional adversarial networks.In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2017).
- [28]Jin, Y.Crypko - a new workflow for anime character creation.https://codh.repo.nii.ac.jp/?action=pages_view_main&active_action=repository_view_main_item_detail&item_id=400&item_no=1&page_id=30&block_id=41, 2020.
- [29]Johnson, J., Alahi, A., and Fei-Fei, L.Perceptual losses for real-time style transfer and super-resolution.In Proceedings of European Conference on Computer Vision (ECCV) (2016).
- [30]Karras, T., Aittala, M., Hellsten, J., Laine, S., Lehtinen, J., and Aila, T.Training generative adversarial networks with limited data.In Proc. NeurIPS (2020).
- [31]Karras, T., Laine, S., Aittala, M., Hellsten, J., Lehtinen, J., and Aila, T.Analyzing and improving the image quality of stylegan, 2019.
- [32]Khungurn, P.Talking head anime from a single image.https://web.archive.org/web/20220401093041/https://pkhungurn.github.io/talking-head-anime/, 2019.Accessed: 2023-08-04.
- [33]Khungurn, P.Talking head anime from a single image 2: More expressive.https://web.archive.org/web/20220327163627/https://pkhungurn.github.io/talking-head-anime-2/, 2021.Accessed: 2023-08-04.
- [34]Khungurn, P.Talking head(?) anime from a single image 3: Now the body too.https://web.archive.org/web/20220606125417/https://pkhungurn.github.io/talking-head-anime-3/, 2022.Accessed: 2023-08-04.
- [35]Kim, K., Park, S., Lee, J., Chung, S., Lee, J., and Choo, J.Animeceleb: Large-scale animation celebheads dataset for head reenactment.In Proc. of the European Conference on Computer Vision (ECCV) (2022).
- [36]Kowalski, M., Garbin, S. J., Estellers, V., Baltrušaitis, T., Johnson, M., and Shotton, J.Config: Controllable neural face image generation.In European Conference on Computer Vision (ECCV) (2020).
- [37]Lattas, A., Moschoglou, S., Ploumpis, S., Gecer, B., Deng, J., and Zafeiriou, S.Fitme: Deep photorealistic 3d morphable model avatars.In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2023), pp. 8629–8640.
- [38]Li, B., Xue, K., Liu, B., and Lai, Y.-K.Bbdm: Image-to-image translation with brownian bridge diffusion models.In CVPR (2023).
- [39]Li, T., Bolkart, T., Black, M. J., Li, H., and Romero, J.Learning a model of facial shape and expression from 4D scans.ACM Transactions on Graphics, (Proc. SIGGRAPH Asia) 36, 6 (2017).
- [40]Lin, C. Z., Nagano, K., Kautz, J., Chan, E. R., Iqbal, U., Guibas, L., Wetzstein, G., and Khamis, S.Single-shot implicit morphable faces with consistent texture parameterization.In ACM SIGGRAPH 2023 Conference Proceedings (2023).
- [41]Litwinowicz, P. C.Inkwell: A 2-d animation system.In Proceedings of the 18th Annual Conference on Computer Graphics and Interactive Techniques (New York, NY, USA, 1991), SIGGRAPH ’91, ACM, pp. 113–122.
- [42]Live2D Inc.What is live2d.https://www.live2d.com/en/about/, 2023.Accessed: 2023-08-07.
- [43]Loper, M., Mahmood, N., Romero, J., Pons-Moll, G., and Black, M. J.SMPL: A skinned multi-person linear model.ACM Trans. Graphics (Proc. SIGGRAPH Asia) 34, 6 (Oct. 2015), 248:1–248:16.
- [44]Lufkin, B.The virtual vloggers taking over youtube.BBC Worklife (Oct 2018).
- [45]M2 Inc.Character animation tool e-mote.https://emote.mtwo.co.jp/, 2023.Accessed: 2023-08-07.
- [46]Ma, Z., Zhu, X., Qi, G., Lei, Z., and Zhang, L.Otavatar: One-shot talking face avatar with controllable tri-plane rendering.In IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2023).
- [47]Mescheder, L., Oechsle, M., Niemeyer, M., Nowozin, S., and Geiger, A.Occupancy networks: Learning 3d reconstruction in function space, 2019.
- [48]Mikatsuki Arpeggio.Mikatsuki Arpeggio.http://roughsketch.en-grey.com/, 2023.Accessed: 2023-09-14.
- [49]Mikatsuki Arpeggio.Mikatsuki Arpeggio, Koakuma Mei.http://roughsketch.en-grey.com/Entry/83/, 2023.Accessed: 2023-09-14.
- [50]Mikatsuki Arpeggio.Mikatsuki Arpeggio, Marietta.http://roughsketch.en-grey.com/Entry/67/, 2023.Accessed: 2023-09-14.
- [51]Mikatsuki Arpeggio.Mikatsuki Arpeggio, Taoist Boy.http://roughsketch.en-grey.com/Entry/110/, 2023.Accessed: 2023-09-14.
- [52]Mildenhall, B., Srinivasan, P. P., Tancik, M., Barron, J. T., Ramamoorthi, R., and Ng, R.Nerf: Representing scenes as neural radiance fields for view synthesis, 2020.
- [53]Mirza, M., and Osindero, S.Conditional generative adversarial nets.CoRR abs/1411.1784 (2014).
- [54]Nagano, K., Seo, J., Xing, J., Wei, L., Li, Z., Saito, S., Agarwal, A., Fursund, J., and Li, H.Pagan: Real-time avatars using dynamic textures.ACM Trans. Graph. 37, 6 (dec 2018).
- [55]Osman, A. A. A., Bolkart, T., and Black, M. J.STAR: A sparse trained articulated human body regressor.In European Conference on Computer Vision (ECCV) (2020), pp. 598–613.
- [56]Park, E., Yang, J., Yumer, E., Ceylan, D., and Berg, A. C.Transformation-grounded image generation network for novel 3d view synthesis.In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2017).
- [57]Park, J. J., Florence, P., Straub, J., Newcombe, R., and Lovegrove, S.Deepsdf: Learning continuous signed distance functions for shape representation, 2019.
- [58]Pavlakos, G., Choutas, V., Ghorbani, N., Bolkart, T., Osman, A. A. A., Tzionas, D., and Black, M. J.Expressive body capture: 3d hands, face, and body from a single image.In Proceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR) (2019).
- [59]Peng, S., Dong, J., Wang, Q., Zhang, S., Shuai, Q., Zhou, X., and Bao, H.Animatable neural radiance fields for modeling dynamic human bodies.In ICCV (2021).
- [60]Preechakul, K., Chatthee, N., Wizadwongsa, S., and Suwajanakorn, S.Diffusion autoencoders: Toward a meaningful and decodable representation.In IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2022).
- [61]Pumarola, A., Agudo, A., Martinez, A., Sanfeliu, A., and Moreno-Noguer, F.Ganimation: One-shot anatomically consistent facial animation.In International Journal of Computer Vision (IJCV) (2019).
- [62]Radford, A., Metz, L., and Chintala, S.Unsupervised representation learning with deep convolutional generative adversarial networks, 2016.
- [63]Ren, Y., Li, G., Chen, Y., Li, T. H., and Liu, S.Pirenderer: Controllable portrait image generation via semantic neural rendering.In ICCV (2021).
- [64]Roich, D., Mokady, R., Bermano, A. H., and Cohen-Or, D.Pivotal tuning for latent-based editing of real images.ACM Trans. Graph. (2021).
- [65]Ronneberger, O., Fischer, P., and Brox, T.U-net: Convolutional networks for biomedical image segmentation.In Medical Image Computing and Computer-Assisted Intervention (MICCAI) (2015), vol. 9351 of LNCS, Springer, pp. 234–241.(available on arXiv:1505.04597 [cs.CV]).
- [66]Saharia, C., Chan, W., Chang, H., Lee, C., Ho, J., Salimans, T., Fleet, D., and Norouzi, M.Palette: Image-to-image diffusion models.In ACM SIGGRAPH 2022 Conference Proceedings (New York, NY, USA, 2022), SIGGRAPH ’22, Association for Computing Machinery.
- [67]Saragadam, V., LeJeune, D., Tan, J., Balakrishnan, G., Veeraraghavan, A., and Baraniuk, R. G.Wire: Wavelet implicit neural representations.In CVPR (2023).
- [68]Saragih, J. M., Lucey, S., and Cohn, J. F.Real-time avatar animation from a single image.In 2011 IEEE International Conference on Automatic Face Gesture Recognition (FG) (2011), pp. 213–220.
- [69]Schwarz, K., Liao, Y., Niemeyer, M., and Geiger, A.Graf: Generative radiance fields for 3d-aware image synthesis, 2021.
- [70]Simonyan, K., and Zisserman, A.Very deep convolutional networks for large-scale image recognition.In Proceedings of the International Conference on Learning Representations (ICLR) (2015).
- [71]Singh, R., Shukla, A., and Turaga, P.Polynomial implicit neural representations for large diverse datasets.In CVPR (2023).
- [72]Sitzmann, V., Martel, J. N., Bergman, A. W., Lindell, D. B., and Wetzstein, G.Implicit neural representations with periodic activation functions.In Proc. NeurIPS (2020).
- [73]SSS LLC.Touhoku Zunko ⋅ Zundamon PJ Official HP.https://zunko.jp/, 2023.Accessed: 2023-10-03.
- [74]SSS LLC.zzm_a1zunko11.png.https://zunko.jp/sozai/zunkot_s/zzm_a1zunko11.png, 2023.Accessed: 2023-10-03.
- [75]Stanley, K. O.Compositional pattern producing networks: A novel abstraction of development.Genetic Programming and Evolvable Machines 8, 2 (jun 2007), 131–162.
- [76]Sun, J., Wang, X., Wang, L., Li, X., Zhang, Y., Zhang, H., and Liu, Y.Next3d: Generative neural texture rasterization for 3d-aware head avatars.In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2023), pp. 20991–21002.
- [77]Tancik, M., Srinivasan, P. P., Mildenhall, B., Fridovich-Keil, S., Raghavan, N., Singhal, U., Ramamoorthi, R., Barron, J. T., and Ng, R.Fourier features let networks learn high frequency functions in low dimensional domains.NeurIPS (2020).
- [78]Tewari, A., Elgharib, M., Bharaj, G., Bernard, F., Seidel, H.-P., Pérez, P., Zöllhofer, M., and Theobalt, C.Stylerig: Rigging stylegan for 3d control over portrait images, cvpr 2020.In IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (june 2020), IEEE.
- [79]Tewari, A., Elgharib, M., BR, M., Bernard, F., Seidel, H.-P., Pérez, P., Zöllhofer, M., and Theobalt, C.Pie: Portrait image embedding for semantic control.vol. 39.
- [80]Transpchan.Collaborative neural rendering using anime character sheets.https://github.com/transpchan/transpchan.github.io/blob/57efe17cdce35cf2c49c8d11ebd9bac108d1ac59/live3d/CoNR.pdf, 2022.Accessed: 2023-08-07.
- [81]Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L. u., and Polosukhin, I.Attention is all you need.In Advances in Neural Information Processing Systems (2017), I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, Eds., vol. 30, Curran Associates, Inc.
- [82]Ververas, E., and Zafeiriou, S.Slidergan: Synthesizing expressive face images by sliding 3d blendshape parameters.International Journal of Computer Vision (2020), 1–22.
- [83]Wang, T.-C., Mallya, A., and Liu, M.-Y.One-shot free-view neural talking-head synthesis for video conferencing.In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2021).
- [84]Wang, Z., Bovik, A. C., Sheikh, H. R., and Simoncelli, E. P.Image quality assessment: from error visibility to structural similarity.IEEE Transactions on Image Processing 13, 4 (April 2004), 600–612.
- [85]Wu, C. H., and la Torre, F. D.Unifying diffusion models’ latent space, with applications to cyclediffusion and guidance, 2022.
- [86]Xu, H., Song, G., Jiang, Z., Zhang, J., Shi, Y., Liu, J., Ma, W., Feng, J., and Luo, L.Omniavatar: Geometry-guided controllable 3d head synthesis.In IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2023).
- [87]Xu, Z., Zhou, Y., Kalogerakis, E., Landreth, C., and Singh, K.Rignet: Neural rigging for articulated characters.ACM Trans. on Graphics 39 (2020).
- [88]Yang, Y., Sundaramoorthi, G., and Soatto, S.Self-occlusions and disocclusions in causal video object segmentation.In 2015 IEEE International Conference on Computer Vision (ICCV) (2015), pp. 4408–4416.
- [89]Yenamandra, T., Tewari, A., Bernard, F., Seidel, H., Elgharib, M., Cremers, D., and Theobalt, C.i3dmm: Deep implicit 3d morphable model of human heads.In Proceedings of the IEEE / CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2021).
- [90]Zhang, J., Xian, K., Liu, C., Chen, Y., Cao, Z., and Zhong, W.Cptnet: Cascade pose transform network for single image talking head animation.In Proceedings of the Asian Conference on Computer Vision (ACCV) (November 2020).
- [91]Zhang, R., Isola, P., Efros, A. A., Shechtman, E., and Wang, O.The unreasonable effectiveness of deep features as a perceptual metric, 2018.
- [92]Zhang, W., Cun, X., Wang, X., Zhang, Y., Shen, X., Guo, Y., Shan, Y., and Wang, F.Sadtalker: Learning realistic 3d motion coefficients for stylized audio-driven single image talking face animation.In CVPR (2023).
- [93]Zheng, M., Yang, H., Huang, D., and Chen, L.Imface: A nonlinear 3d morphable face model with implicit neural representations.In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2022), pp. 20343–20352.
- [94]Zhou, T., Tulsiani, S., Sun, W., Malik, J., and Efros, A. A.View synthesis by appearance flow.In European Conference on Computer Vision (2016).
- [95]Zhou, T., Tulsiani, S., Sun, W., Malik, J., and Efros, A. A.View synthesis by appearance flow, 2017.
- [96]Zhu, J.-Y., Park, T., Isola, P., and Efros, A. A.Unpaired image-to-image translation using cycle-consistent adversarial networks.In Proceedings of the IEEE International Conference on Computer Vision (ICCV) (2017).
- [97]Zhuang, Y., Zhu, H., Sun, X., and Cao, X.Mofanerf: Morphable facial neural radiance field.In European Conference on Computer Vision (2022).
附录 A完整系统架构细节
A.1带注意力的 U-Net
半分辨率旋转器和编辑器的新主干是带有注意力[23]的 U-Net,它经常用于扩散模型。 我们的架构基于 Preechakul 等人 [60] 的扩散自动编码器论文中的条件 U-Net。 在那里,U-Net 将特征张量、时间值和一维条件向量作为输入。 时间值和条件向量是通过自适应实例归一化 (AdaIN) 单元 [25] 从输入特征张量导出的混合张量,这些单元是残差块 [20] 的一部分。 残差块将具有两个连续应用的 AdaIN 单元:第一个用于时间,第二个用于调节向量。 在扩散自动编码器论文中,条件向量是一个512维向量。 在我们的例子中,条件向量是 6 维姿态向量。对于我们的网络,时间值始终为 0 并且完全是多余的。 我们保留了与时间嵌入相关的代码,以减少实现工作。
| Hyperparameter | Half-resolution rotator | Editor |
|---|---|---|
| image resolution | 256×256 | 512×512 |
| # base channels | 64 | 32 |
| channel multipliers | 1, 2, 4, 4, 4 | 1, 2, 4, 8, 8, 8 |
| # residual blocks per level | 1 | 1 |
| # bottleneck residual blocks | 4 | 4 |
| resolution with attention blocks | 16 | 16 |
| # attention heads | 8 | 8 |
表 8:U-Net 的配置,具有半分辨率旋转器和编辑器的注意力主干。
表8给出了骨干网络的配置。 两个网络都将特征张量缩小到 16×16,然后再将其放大到原始分辨率。 注意力块仅出现在 16×16 分辨率下。 每个网络的瓶颈部分有 4 个残差块与 3 个注意力块交替。 (换句话说,总共有 3+2=5 个注意力块。) 每个注意力块有 8 个注意力头。
半分辨率旋转器和编辑器的不同之处不仅在于其主干的配置,还在于主干如何被额外的单元“包裹”以使其符合网络接口。 我们将在以下两小节中讨论这些额外的单元。
A.2半分辨率旋转器
 图 8:新的半分辨率旋转器。半分辨率旋转器如图8所示。 它作为输入
图 8:新的半分辨率旋转器。半分辨率旋转器如图8所示。 它作为输入
- $𝐼_{half}^{rest}$通过缩放原始输入图像获得的人物静止姿势的 4×256×256 RGBA 图像,以及
- 𝐩,6 维姿态向量。
由于具有注意力主干的 U-Net 以 64×256×256 张量作为输入,因此必须使用卷积层将$𝐼_{half}^{rest}$转换为该形状。 主干网生成另一个 64×256×256 特征张量,然后用于执行多个图像处理操作。 (参见3节。)
- 变形。 特征张量被传递到卷积层以产生大小为 2×256×256 的外观流 $𝐼_{half}^{flow}$。 然后使用它来扭曲输入图像 ($𝐼_{half}^{rest}$) 以生成扭曲图像 $𝐼_{half}^[warped}$。
- 直接生成。 特征张量转换为4×256×256 RGBA 图像,用$𝐼_{half}^{direct}$表示。
- 混合。 特征张量被转换为 1×256×256 alpha 贴图,然后用于将扭曲图像 $𝐼_{half}^{warped}$ 和直接生成的图像 $𝐼_{half}^{direct}$ 混合在一起。 结果称为$𝐼_{half}^{blended}$。
半分辨率旋转器输出 $𝐼_{half}^{flow}$、$𝐼_{half}^{warped}$、$𝐼_{half}^{direct}$和$𝐼_{half}^{blended}$。 这些图像用于训练。 但是,在测试时,$𝐼_{half}^{flow}$ 和$𝐼_{half}^{blended}$ 由下一个网络(编辑器)使用。
A.3编辑器
 图 9:新编辑。编辑器的架构如图9所示。 它需要 4 个输入:
图 9:新编辑。编辑器的架构如图9所示。 它需要 4 个输入:
- $𝐼_{full}^{rest}$,512×512分辨率下的原始字符图像,
- 𝐩,6 维姿态向量,
- $𝐼_{coarse}^{blended}$,将 $𝐼_{half}^{blended}$ 放大为 512×512,并且
- $𝐼_{coarse}^{flow}$,将 $𝐼_{half}^{flow}$ 放大为 512×512。
编辑器处理这些输入的方式与半分辨率旋转器的处理方式非常相似。 位姿向量直接传递到主干网。 输入图像 $𝐼_{full}^{rest}$ 进行卷积以创建 32×512×512 张量。 另外两个输入通过我们所说的“粗略输入处理子模块”传递,该子模块执行以下步骤。
- 首先,使用粗略外观流$𝐼_{coarse}^{flow}$对原始输入图像$𝐼_{full}^{rest}$进行扭曲以获得粗略扭曲图像$𝐼_{coarse}^{warped}$。
- 其次,将$𝐼_{coarse}^{blended}$、$𝐼_{coarse}^{flow}$ 和 $𝐼_{coarse}^{warped}$ 连接起来,并对所得张量进行卷积以形成 32×512×512 张量。
- 第三,最后一步的结果被添加到应用于原始图像的卷积层的输出中,以产生 32×512×512 张量。
然后将得到的张量通过注意力传递到主干 U-Net。 主干网的输出的处理方式与半分辨率旋转器的处理方式相同。 这会产生全分辨率的四个张量:$𝐼_{full}^{flow}$、$𝐼_{full}^{warped}$、$𝐼_{full}^{direct}$ 和 $𝐼_{full}^{blended}$。
请注意,如果我们删除粗略输入处理子模块,编辑器的架构将与半分辨率旋转器完全相同。 因此,编辑器可以被认为是一个网络,它也旋转原始图像 $𝐼_{full}^{rest}$ 中给出的身体,但它采用粗略输入 $𝐼_{coarse}^{blended}$ 和 $𝐼_{coarse}^{flow}$,作为提示。 我们将在编辑器的训练过程中利用这个属性。
附录 B完整系统训练详情
B.1半分辨率旋转器
半分辨率旋转器使用以下 6 项损失进行训练,该损失是 L1 损失和感知内容损失 [29] 的组合。 更具体地说,

$ℓ_{L1}$和$ℓ_{percept}$是损失权重,在训练过程中会改变一次。 (稍后会详细介绍。) 具有下标“L1”的损失项由下式给出

其中 𝐶、𝐻 和 𝑊 分别是张量的通道、高度和宽度。 $𝐼_{half}^{posed}$是训练数据集中按比例缩小到256×256的真实姿态图像,$𝐼_{half}^{□}$是第 A.2 节中定义的半分辨率旋转器的输出。 下标“percept”的损失由下式给出

和

这里,
- $𝜙_{𝑖}(⋅)$表示 VGG16 网络[70]中第𝑖使用层输出的特征张量,我们使用relu1_2 、relu2_2 和 relu3_3 层。
- $𝑐_{𝑖}$ 是$𝜙_{𝑖}(⋅)$分量数量的倒数。
- $𝐼^{rgb}$表示去掉图像𝐼的 alpha 通道形成的 3 通道图像。
- $𝐼^{aaa}$表示将𝐼的 alpha 通道重复 3 次形成的 3 通道图像。
我们将感知损失计算为两个 L1 损失项,因为 VGG16 网络接受 RGB 图像作为输入,而半分辨率旋转器输出的图像有 4 个通道。 为了加快 Φ(⋅,⋅) 的计算速度,我们对其进行随机评估。 我们抛一枚硬币,正面概率为3/4。 如果出现正面,我们用 $𝐼^{rgb}$ 评估该项;否则,我们用 $𝐼^{aaa}$ 评估该术语。 当然,这些项与概率的倒数成比例,以确保期望具有正确的值。
训练分为两个阶段。
- 在第一阶段,仅使用 L1 损耗。 换句话说,$ℓ_{L1}=1$ 和 $ℓ_{percept}=0$。 第一阶段持续 1 个 epoch(500K 个训练样本)。
- 在第二阶段,使用所有损失术语。 特别是,我们设置了$ℓ_{L1}=1$和$ℓ_{percept}=0.2$。 第二阶段持续 18 个 epoch(9M 个训练样本)。
我们将 Adam 优化器与 $𝛽_{1}=0.5$ 和 $𝛽_{2}=0.999$ 一起使用。 学习率从 0 开始,并在前 5,000 个训练示例中线性增加到 $10^{−4}$。 批量大小为 16。
B.2编辑器
训练分为三个阶段。 在前两个阶段,粗略输入处理子模块从编辑器中删除,使其暂时成为“全分辨率旋转器”。该网络使用半分辨率旋转器的训练过程进行训练,但现在使用全分辨率图像而不是半分辨率图像。
在第三阶段,我们添加了粗略输入处理子模块并训练网络以最小化以下损失:

我们修复了 $𝜆_{L1}=1$ 和 $𝜆_{percept}=0.2$。 L1 损失由下式给出

其中 $𝐼_{full}^{posed}$ 是来自数据集的 groundtruth 训练图像,$𝐼_{full}^{□}$ 是 A.3 节中定义的编辑器的输出。 损失$ℒ_{half}^{direct}$、$ℒ_{half}^{blended}$、$ℒ_{quad}^{direct}$和$ℒ_{quad}^{blended}$是感知损失。 上标表示我们用来计算损失的编辑器的输出,下标表示如何计算损失。 “half”下标表示图像缩小到 256×256:

其中 Down(⋅) 表示将 512×512 图像缩放至 256×256。 “quad”下标表示将图像分为四个象限,使得一个512×512图像变成四个4×256×256图像。 然后使用象限来评估感知损失。

其中 𝑄𝑖(⋅) 从参数中提取第 𝑖 象限。 我们发现,评估 256×256 处的感知损失而不是 512×512 会导致网络产生更清晰的图像。
同样,我们使用与半分辨率旋转器相同的优化器和学习率计划。 第一阶段持续 1 个 epoch(500K 个示例),第二个 18 个 epoch(9M 个示例),第三个 18 个 epoch(9M 个示例)。

图 10:覆盖角色可移动面部部分的二元蒙版。
附录 C用于速度测量的计算机
我们进行了实验,测量模型在以下 3 台台式计算机上生成单个动画帧所需的时间。
- 计算机 A 拥有两个 Nvidia Nvidia RTX A6000 GPU、一个 2.10 GHz Intel Xeon Silver 4310 CPU 和 128 GB RAM。 它代表主要用于机器学习研究的计算机。
- 计算机 B 配备 Nvidia Titan RTX GPU、3.60 GHz Intel Core i9-9900KF CPU 和 64 GB RAM。 它代表了高端游戏 PC。
- 计算机 C 配备 Nvidia GeForce GTX 1080 Ti GPU、3.70 GHz Intel Core i7-8700K CPU 和 32 GB RAM。 它代表了典型的(但有些过时的)游戏电脑。
附录 D学生脸部变形的损失函数
学生面部变形器经过训练可以最大限度地减少以下损失:

这里,