当前的语言模型在理解非文字所能轻易描述的世界层面有所欠缺,对于复杂且篇幅较长的任务处理也显得力不从心。视频序列提供了语言和静态图像中缺失的宝贵时间信息,使其成为与语言联合建模的理想选择。这样的模型有望融合人类的文字知识与物理世界的理解,从而开启更广泛的人工智能辅助人类的能力。然而,从数百万个视频和语言序列令牌中学习面临着内存限制、计算复杂度高以及数据集有限的挑战。
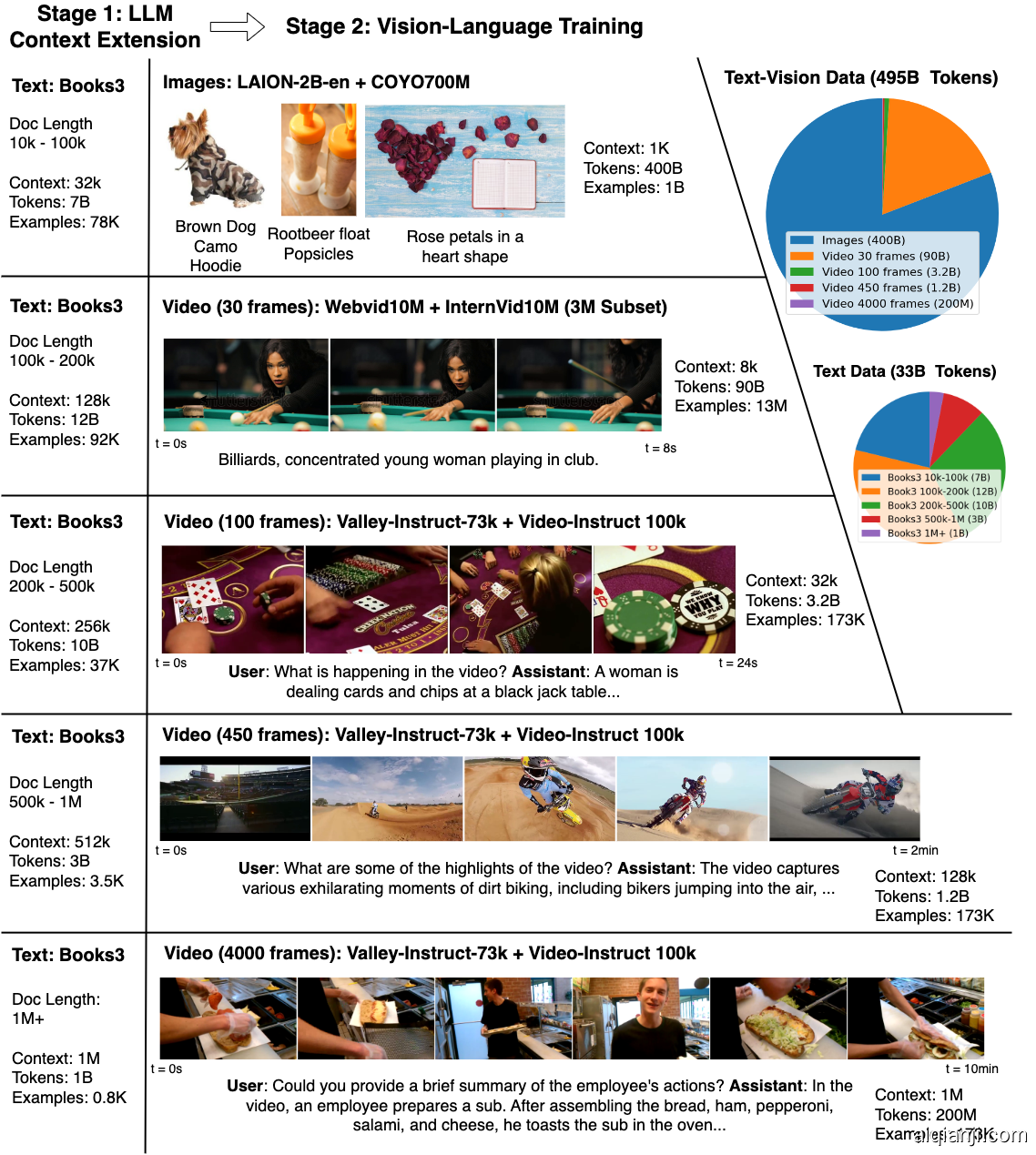
为了解决这些问题,我们汇编了一个包含多样化视频和书籍的大规模数据集,采用RingAttention技术以可扩展的方式训练长序列,并逐步将上下文大小从4千增加到1百万令牌。本文的主要贡献如下:
(a) 最大的上下文尺寸神经网络:我们在长时间视频和语言序列上训练了最大上下文尺寸的变换器之一,为困难的检索任务和长期视频理解树立了新的基准。
(b) 克服视觉-语言训练难题的方法,包括使用掩码序列打包混合不同长度的序列,损失加权以平衡语言和视觉,以及模型生成的QA数据集用于长序列对话。
(c) 高度优化的实现,结合RingAttention、掩码序列打包和其他关键特性,用于训练长达数百万的多模态序列。
(d) 完全开源了一组70亿参数的模型家族,能够处理超过1百万令牌的长文本文档(LWM-Text, LWM-Text-Chat)和视频(LWM, LWM-Chat)。
这项工作为通过大规模的长视频和语言数据集训练以理解人类知识和多元模态世界,以及开发更广泛的AI能力铺平了道路。