超越cuBLAS的单精度通用矩阵乘法
1. 引言
我清楚地记得Andrej关于现有CUDA学习材料与高性能库中使用的CUDA代码之间差距的帖子:

确实,当涉及到SGEMM实现时,有一些优秀的教育博客文章,例如:
- 如何优化CUDA矩阵乘法内核以达到类似cuBLAS的性能(由Andrej提到)
- CUDA矩阵乘法优化
这些文章逐步分解了如何优化CUDA矩阵乘法内核。然而,就实现的性能而言,它们都无法接近cuBLAS或CUTLASS的速度,尤其是在使用最新的CUDA版本并进行适当基准测试时。根据我的实验,这些实现最多只能达到cuBLAS性能的50-70%。此外,我发现这两篇博客文章在最终优化步骤中的解释有些过于复杂。尽管如此,我仍然认为这些资源对于任何开始学习CUDA编程的人来说都是很好的,因为它们提供了良好的基础知识。
另一方面,我看到一些非常快的SGEMM实现,具有cuBLAS级别的性能:
问题是它们没有文档,难以找到和理解,尤其是对于CUDA初学者。CUTLASS也存在类似的问题。虽然它性能卓越,但缺乏解释其内部设计和如何在高效CUDA/PTX中实现的入门或教育材料。另一个值得注意的项目是MaxAs,这是Scott Gray十多年前为Maxwell架构开发的汇编器。该工具允许直接在SASS(NVIDIA GPU的汇编语言)中编程,直接与硬件通信,而不是依赖与硬件无关的CUDA/PTX。使用MaxAs,Scott编写了一个SGEMM实现,达到了GM204芯片理论最大FLOPS的约98%,平均比cuBLAS高出5%。虽然结果令人印象深刻,但用SASS编程缺乏灵活性,并且需要对底层硬件有深入的理解。此外,随着编译器的显著进步,直接使用SASS编程仅在特殊情况下才有优势(例如,如果您构建tinygrad)。CUTLASS仅使用CUDA/PTX代码就在各种GPU架构和矩阵大小上实现了与cuBLAS相当的性能。
但我们真的能超越cuBLAS的障碍吗?在接下来的章节中,我们将简要回顾CUTLASS中使用的高级SGEMM设计,并讨论如何将此设计转化为高效的CUDA/PTX。本指南仅假设您对CUDA编程模型和线性代数有基本了解。如果您是CUDA编程的新手,我强烈建议从这些简短的入门文章开始:
在继续实现之前,让我们谈谈如何在NVIDIA GPU上进行基准测试——这是一个经常被忽视的话题。正确地进行基准测试与代码本身同样重要,特别是在比较不同实现时。
2. 如何在CUDA设备上进行基准测试?
测量内核持续时间的最可靠方法是使用NVIDIA Nsight Compute进行性能分析,并手动提取性能数据。为了获得确定性和可重复的结果,Nsight Compute会自动应用以下设置:
- 时钟控制:将GPU时钟频率锁定为其基准值
- 缓存控制:在每次重放之前刷新所有GPU缓存
- 持久模式
或者,您可以手动应用这些设置,并在运行时测量内核持续时间,而不依赖外部性能分析工具。在Ubuntu上,您可以使用以下命令检索基准核心时钟频率:
nvidia-smi base-clocks
例如,在RTX 3090上,基准核心时钟频率为1395 MHz。接下来,您需要内存时钟频率,它与基准核心时钟频率配合使用:
nvidia-smi -q -d supported_clocks
从支持的频率列表中,选择与基准核心频率兼容的最快内存时钟。内存时钟速度通常比核心时钟速度更稳定。要锁定时钟频率并启用持久模式,请运行以下命令:
sudo nvidia-smi --persistence-mode=1
# NVIDIA RTX 3090
sudo nvidia-smi --lock-gpu-clocks=1395
sudo nvidia-smi --lock-memory-clocks=9501
要重置核心和内存时钟频率,您可以使用:
sudo nvidia-smi --reset-gpu-clocks
sudo nvidia-smi --reset-memory-clocks
sudo nvidia-smi --persistence-mode=0
GPU时钟频率可能会因GPU的热状态而下降,但对于高性能应用,节流通常是由功率限制引起的。硬件故障也可能导致节流。至少在测试运行期间监控GPU的状态是一个好主意。使用以下命令实时跟踪功耗、时钟速度和节流原因:
watch -n 0.1 nvidia-smi --query-gpu=power.draw,clocks.sm,clocks.mem,clocks_throttle_reasons.active --format=csv
示例输出可能如下所示:
308.50 W, 1395 MHz, 9501 MHz, 0x0000000000000000
位掩码0x0000000000000000表示没有节流,时钟以其最大速度运行。值0x0000000000000001表示空闲状态。任何其他值都表明正在发生节流。有关位掩码值及其含义的完整列表,请参阅NvmlClocksThrottleReasons文档。
一旦您锁定了时钟频率,您可以直接在CUDA中使用CUDA事件测量内核持续时间。以下是一个示例:
cudaEvent_t start, stop;
cudaEventCreate(&start); cudaEventCreate(&stop);
float elapsed_time_ms = 0.0;
cudaEventRecord(start);
kernel<<<...>>>(...);
cudaEventRecord(stop);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&elapsed_time_ms, start, stop);
为了获得可靠的测量结果,通常使用多次重放。在这种情况下,应在每次内核重放之前刷新GPU缓存。这可以使用cudaMemsetAsync完成,如nvbench所示:
// 刷新L2缓存
int dev_id{};
int m_l2_size{};
void* buffer;
checkCudaErrors(cudaGetDevice(&dev_id));
checkCudaErrors(cudaDeviceGetAttribute(&m_l2_size, cudaDevAttrL2CacheSize, dev_id));
if (m_l2_size > 0) {
checkCudaErrors(cudaMalloc(&buffer, static_cast<std::size_t>(m_l2_size)));
int* m_l2_buffer = reinterpret_cast<int*>(buffer);
checkCudaErrors(cudaMemsetAsync(m_l2_buffer, 0, static_cast<std::size_t>(m_l2_size)));
checkCudaErrors(cudaFree(m_l2_buffer));
}
将时钟频率锁定为其基准值是测量内核速度的可靠方法。然而,在现实场景中,算法通常不会在锁定时钟的情况下运行。为了实现最佳性能,您的算法需要既快速又节能。您的算法消耗的功率越少,硬件可以维持的时钟速度就越高。NVIDIA GPU通常在达到功率限制之前就积极降低时钟频率,这可能会显著降低应用程序性能。为了考虑到这一点,我们在锁定和解锁时钟条件下对实现进行基准测试,测试速度和功率效率。在我们的基准测试中,我们评估矩阵大小从1024到12,800,步长为128。对于每个矩阵大小,我们启动1000*exp((-matsize+1024)/3100.0))次内核重放,并将运行时间计算为后半部分重放的平均值。例如,给定矩阵大小问题m=n=k=4096,我们运行sgemm 1000*exp((-4096 + 1024)/3100.0))=371次,并测量最后185次运行的平均持续时间,确保时钟已经稳定。这种性能分析策略即使在GPU时钟解锁的情况下也能产生一致且可重复的结果。
避免使用WSL进行性能测量。为了确保准确和可靠的结果,请使用原生Linux环境。
3. 内存布局
在本实现中,我们假设矩阵以行主序存储。一个维度为M x N的矩阵A存储为长度为M*N的连续数组。元素A[row][col]通过一维原始C指针ptr[row*N + col]访问,其中0<=col<=N-1和0<=row<=M-1。矩阵乘法表示为C=AB,其中矩阵A, B, C的形状分别为M \times K, K \times N, 和 M \times N。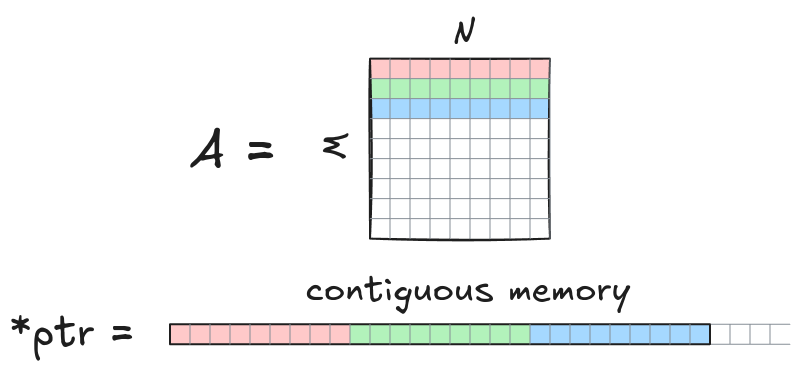
要将此实现调整为以列主序存储的矩阵,只需交换操作数A和B,因为:
\[C^\text{T} = (A B)^\text{T} = B^\text{T} A^\text{T},\]
这里,A, B, C是以行主序存储的矩阵,而A^\text{T}, B^\text{T}, C^\text{T}是对应的转置矩阵(即以列主序存储)。
cuBLAS提供了一个API来计算SGEMM:
cublasSgemm(m, n, k, A, lda, B, ldb, C, ldc); // 简化形式
其中m, n, k表示矩阵大小M, N, K。参数lda, ldb, ldc分别是矩阵A, B, C的_前导维度_。前导维度是迭代矩阵元素时变化最快的维度的长度(即第一维度的长度)。对于以行主序存储的矩阵,前导维度通常是列数,因此通常lda=k, ldb=n, ldc=n。然而,情况并非总是如此。在需要计算较大矩阵的子矩阵的情况下,前导维度可能大于列数。
矩阵也可能用零填充以支持向量化内存加载或张量核心。向量化加载指令允许使用一条指令一次加载多个元素。尽管向量化加载减少了指令总数并提高了带宽利用率,但它们也对输入数据施加了对齐约束,因此前导维度必须能被2(对于64位加载)或4(对于128位加载)整除。下图说明了128位(=4个浮点数)加载的情况。
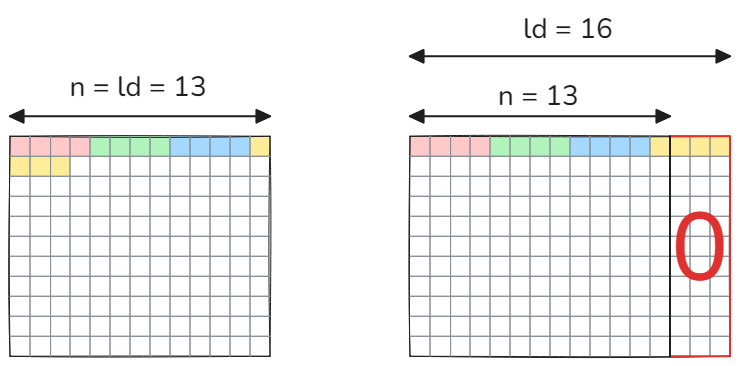
请注意,如果前导维度不能被4整除,则无法在不触及下一行元素的情况下加载第一行的元素。用零填充有助于解决这个问题,但需要额外的内存。另一种解决方案是在运行时检查前导维度是否能被4整除。如果是,则使用向量化加载,否则使用标量加载。此外,过去常用零填充来启用张量核心计算。例如,在cuBLAS版本<11中,Tensor Core FP16操作要求m, n, k是8的倍数。
4. 并行线程执行
CUDA编译.cu文件的轨迹如下:

在第一阶段,CUDA代码被编译为PTX(并行线程执行)指令——中间高级代码,可以视为虚拟GPU架构的汇编。这样的虚拟GPU完全由它提供给应用程序的功能或特性集定义。PTX不直接在任何真实架构上运行。它必须经过优化并转换为本地目标架构指令(第二阶段)。NVIDIA提供了一种机制,可以将PTX代码插入到您的CUDA程序中,这样您可以在源代码中混合使用CUDA/PTX,并在PTX生成期间仍能享受代码优化的好处。通过将部分代码重写为PTX,您可以1)减少生成的PTX指令总数2)精确指定所需的PTX指令3)通过限定符调整指令4)应用编译器缺乏或C++语言扩展禁止的优化。重要提示!使用内联PTX汇编不会自动使您的代码比用CUDA编写的代码更快。只有当您手写的PTX比编译器生成的更好时,它才会更快。
在本实现中,我们将直接以PTX编程算法的某些部分,因此如果您从未使用过内联PTX汇编,我强烈建议您查看内联PTX汇编的简短概述。PTX指令有详细文档,可在PTX指令集中找到。我们现在将简要回顾本实现中使用的PTX指令。
4.1. 全局内存加载
对于全局内存加载,我们将使用ld.global.f32指令。这里,“ld”表示“加载”,“f32”表示“32位浮点数”。以下CUDA代码
float reg; // 单个浮点寄存器
float* gmem_ptr = data_in_global_memory; // 指向全局内存的指针
reg = *gmem_ptr; // 全局内存 -> 寄存器传输
可以在PTX中实现为:
float reg; // 单个浮点寄存器
float* gmem_ptr = data_in_global_memory; // 指向全局内存的指针
asm volatile("ld.global.f32 %0, [%1];" : "=f"(reg) : "l"(gmem_ptr));
"=f"中的f表示float数据类型,=修饰符指定寄存器被写入。l表示无符号64位整数。我们还使用volatile关键字确保在生成PTX期间不会删除或移动该指令。
4.2. 全局内存存储
对于全局内存存储,有`st.global.f32指令:
float reg; // 单个浮点寄存器
float* gmem_ptr = data_in_global_memory; // 指向全局内存的指针
// *gmem_ptr = reg; 可以在PTX中实现为:
asm volatile("st.global.f32 [%0], %1;" : : "l"(gmem_ptr), "f"(reg));
4.3. 全局到共享内存传输
当您在CUDA中编写如下代码时:
__shared__ float smem_ptr[n]; // 指向共享内存的指针
float* gmem_ptr = data_in_global_memory; // 指向全局内存的指针
*smem_ptr = *gmem_ptr; // 全局到共享内存传输
会发生一个两步过程。首先,数据从全局内存提取到寄存器,然后将该数据从寄存器复制到共享内存。此外,在传输过程中数据会在所有缓存级别中缓存。
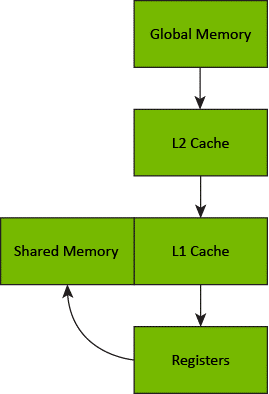
全局到共享内存传输
因此,PTX中的全局到共享内存传输由两个数据移动指令ld.global和st.shared组成:
__shared__ float smem_ptr[n]; // 指向共享内存的指针
uint64_t smem_addr;
// 将通用地址转换为共享地址(st.shared指令的存储位置)
asm volatile("cvta.to.shared.u64 %0, %1;" : "=l"(smem_addr) : "l"(smem_ptr));
float* gmem_ptr = data_in_global_memory; // 指向全局内存的指针
float buffer;
// 全局内存 -> 寄存器
asm volatile("ld.global.f32 %0, [%1];" : "=f"(buffer) : "l"(gmem_ptr));
// 寄存器 -> 共享内存
asm volatile("st.shared.f32 [%0], %1;" : : "l"(smem_addr), "f"(buffer));
在Ampere架构之前,无法将数据从全局内存直接传输到共享内存,绕过寄存器存储。从Ampere架构开始,有异步拷贝指令允许这样做。这些指令的使用将在后面演示。
4.4. 向量化共享内存加载和存储
在PTX中,您还可以实现向量化内存操作(使用一条指令加载/存储多个元素)。这里,v4表示包含四个元素的向量:
float reg0, reg1, reg2, reg3;
uint64_t addr;
...
// 共享内存128位加载
asm volatile("ld.shared.v4.f32 {%0, %1, %2, %3}, [%4];"
: "=f"(reg0), "=f"(reg1), "=f"(reg2), "=f"(reg3)
: "l"(addr));
// 共享内存128位存储
asm volatile("st.shared.v4.f32 [%0], {%1, %2, %3, %4};"
:
: "l"(addr), "f"(reg0), "f"(reg1), "f"(reg2), "f"(reg3));
4.5. 谓词执行
在PTX中,条件执行使用可选的保护谓词实现。以下CUDA代码:
float reg;
float* ptr; // 指向全局内存的指针
unsigned guard;
...
if (guard != 0) {
*ptr = reg;
}
可以转换为PTX:
float reg;
float* ptr;
unsigned guard;
...
asm volatile(".reg .pred p;\n\t" // 声明谓词'p'
".setp.ne.u32 p, %2, 0;\n\t" // 如果(guard != 0)则将'p'设置为true;ne="不等于"
"@p ld.global.f32 %0, [%1];\n\t" // 如果'p'为true则执行指令
: "=f"(reg)
: "l"(ptr), "r"(guard));
我们将保护谓词与全局加载/存储指令结合使用,仅在未越界的情况下执行全局内存访问。
5. SGEMM设计
现在让我们分解算法的高级设计。论文Strassen’s Algorithm Reloaded on GPUs包含了我认为CUTLASS库中SGEMM设计的最佳可视化之一。SGEMM算法大致可以分为三个主要部分:
- 将数据从全局内存传输到共享内存
- 从共享内存加载数据并执行算术操作
- 将结果写回全局内存
每个步骤都必须仔细优化,以实现整体高性能。在接下来的部分中,我们将详细探讨每个步骤,并讨论高效的实现策略。值得一提的是,第一步——“将数据从全局内存传输到共享内存”——是最难理解的部分。然而,一旦您理解了这一部分,其余步骤就会变得容易得多。
5.1. 将数据从全局内存传输到共享内存
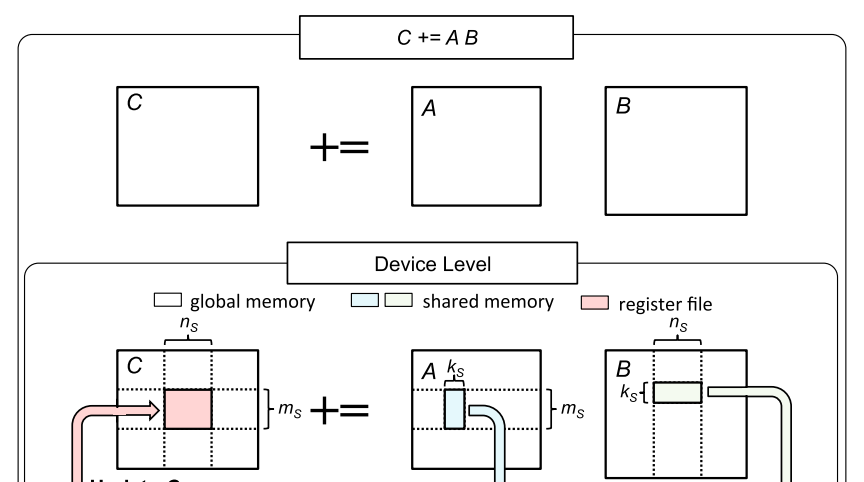
来源:Strassen’s Algorithm Reloaded on GPUs
为了在GPU上并行化C=AB,矩阵C被划分为大小为m_S \times n_S的子矩阵\tilde{C},并且这些子矩阵被并行处理,一个线程块独立于其他线程块计算一个子矩阵\tilde{C}。为了计算\tilde{C},我们遍历维度K。在每次迭代中,大小为m_s \times k_s的子矩阵\tilde{A}和大小为k_s \times n_s的子矩阵\tilde{B}从全局内存加载到共享内存(见上图)。然后这些子矩阵相乘,结果用于更新\tilde{C}为\tilde{C} += \tilde{A} \tilde{B}。子矩阵\tilde{A}, \tilde{B}, \tilde{C}通常称为_块_或_瓦片_。总共有K / k_s次迭代(假设最简单的情况,K能被k_s整除)。有限的共享内存容量是为什么维度K被划分为较小的k_s块的原因。完整的m_s \times K, K \times n_s块根本无法适应可用的共享内存。现在,不要被为什么矩阵被加载到共享内存以及如何精确地乘以矩阵\tilde{A}, \tilde{B}所分心,我们将在下一章讨论这一点。让我们专注于从全局内存到共享内存的高效数据传输,作为实现快速SGEMM的第一步。
从线程块的角度来看,算法的伪代码如下:
// block_a, block_b, block_c的形状分别为(ms x ks), (ks x ns), (ms x ns)
// 每个线程块计算C的一个块:
block_c = 0
__shared__ float block_a[block_a_size]
__shared__ float block_b[block_b_size]
for (i=0; i<K/ks; i++) {
block_a = 加载矩阵A的第i个块 // 从全局内存到共享内存
block_b = 加载矩阵B的第i个块 // 从全局内存到共享内存
block_c += block_a * block_b // 计算矩阵乘积并更新block_c
}
store(block_c) // 存储到全局内存
从全局内存到共享内存的数据传输具有比算术操作高得多的延迟。在此期间,线程被迫停滞,空闲等待计算block_a * block_b所需的数据。一种缓解这种延迟的方法是通过重叠数据传输与计算,利用指令级并行(ILP)。在GEMM实现中,通常使用一种称为_双缓冲_的技术来实现这种重叠:
block_c = 0
// 共享内存双缓冲
__shared__ float block_a[2][block_a_size] // 2倍共享内存使用
__shared__ float block_b[2][block_b_size] // 2倍共享内存使用
block_a[0] = 加载矩阵A的第一个块
block_b[0] = 加载矩阵B的第一个块
for (i=0; i<(K/ks-1); i++) {
idx = i%2
prefetch_idx = (i+1)%2
// 预取下一个块
block_a[prefetch_idx] = 加载矩阵A的下一个块
block_a[prefetch_idx] = 加载矩阵B的下一个块
// 使用前一次迭代中加载的块计算矩阵乘积
block_c += block_a[idx] * block_b[idx]
}
// 使用最后一个块更新累加器
block_c += block_a[prefetch_idx] * block_b[prefetch_idx]
store_to_global_memory(block_c)
请注意,block_c += block_a[idx] * block_b[idx]不依赖于blocks[prefetch_idx],允许算术指令与数据移动指令并行发出。然而,这是以共享内存使用量翻倍为代价的,因为我们需要存储两个块而不是一个。好消息是,现代GPU有足够的共享内存来支持双缓冲。
我们已经引入了几个参数,如块大小m_s, k_s, n_s和每个线程块的线程数。这些参数的选择高度依赖于操作数A, B, C的形状以及底层GPU架构。例如,cuBLAS实现了多个针对各种矩阵形状和GPU架构优化的SGEMM内核。在运行时,它使用启发式方法选择最合适的内核。块大小m_s, k_s, n_s不仅影响如何从全局内存获取数据,还影响所有后续步骤(共享内存加载、算术操作、全局内存存储)中线程之间的工作组织,以实现最佳性能。块大小和每个线程块的线程数的选择也会影响共享内存/寄存器使用,如果不加以考虑,可能会导致性能下降。正如您所料,确定最佳参数值需要对硬件有出色的理解并进行广泛的实验。幸运的是,SGEMM是一个经过充分研究的问题,我们可以利用cuBLAS和CUTLASS的前期研究结果。对于大型方阵(M=N=K > 1024),m_S \times n_S的组合如$128 \times 256、$128 \times 128和$256 \times 128会导致最佳性能。根据我的测试,配置m_s \times n_s \times k_s = 128 \times 128 \times 8$,每个线程块256个线程,在我的本地RTX 3090上,对于矩阵大小问题1024 <= M=N=K <= 2500,达到了最高的TFLOP/S。因此,我们将从实现128x128x8 SGEMM内核开始。现在我们知道块维度和每个线程块的线程数,让我们讨论如何有效地组织从全局内存加载数据并存储到共享内存。
首先,我们需要使用256个线程加载128x8子矩阵\tilde{A}。这导致每个线程从全局内存加载128*8/256 = 4个浮点元素。有几种不同的方法来组织块的加载。对于全局内存读取/存储,您总是希望您的访问是连续的或_合并的_,以便一个wrap中的32个线程访问内存中的32个连续浮点数。如果内存访问是合并的,则将使用最少数量的内存事务。然而,在\tilde{A}块的情况下,这是不可能的:块的每一行只包含8个连续元素。尽管如此,即使在这种情况下,wrap中的连续线程访问内存中的连续元素也是可取的,通常会导致更好的性能。下图显示了如何实现块\tilde{A}的加载。这里,不同的颜色代表不同的线程,而为了简单起见,只显示了前16个线程。连续的四行由8个连续线程加载:第1-4行由线程0-7加载,第5-8行由线程8-15加载,第9-12行由线程16-23加载,依此类推,最后第125-128行由线程248-255加载。我们还在存储到共享内存时转置块\tilde{A},以便在下一个计算步骤中获得更好的内存访问模式。请注意,每个线程在共享内存中存储4个连续元素。这允许我们使用PTX向量化存储st.shared.v4.f32。
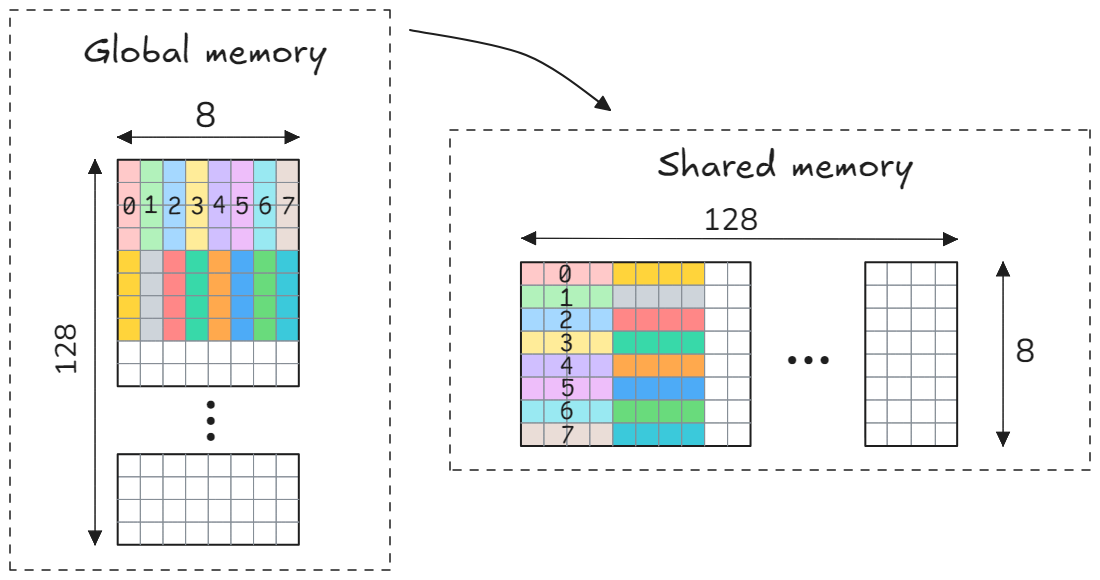
使用这种简单方案存储到共享内存会导致共享内存库冲突。根据CUDA编程指南:
为了实现高带宽,共享内存被划分为大小相等的内存模块,称为库,可以同时访问。任何由n个地址组成的内存读取或写入请求,如果落在n个不同的内存库中,则可以同时服务,从而产生比单个模块高n倍的总体带宽。然而,如果内存请求的两个地址落在同一个内存库中,则会发生库冲突,访问必须串行化。硬件将具有库冲突的内存请求拆分为尽可能多的无冲突请求,吞吐量降低的因子等于单独内存请求的数量。如果单独内存请求的数量为n,则初始内存请求被称为导致n路库冲突。
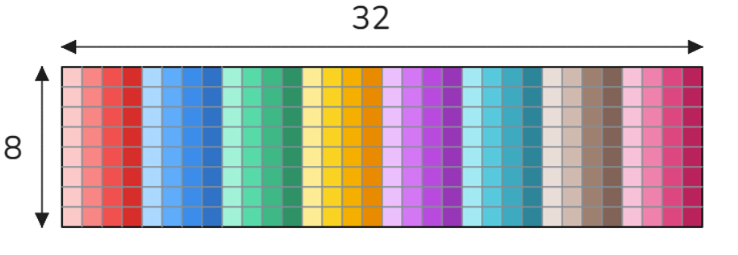
共享内存有32个库,组织方式使得连续的32位字映射到连续的库。想象一个大小为8x32的float32数组,以行主序存储,如下所示。
在这种情况下,颜色及其阴影代表内存库:每行对应32个不同的内存库,而每列代表一个内存库。关于共享内存库冲突,有两个重要的注意事项:
- 库冲突的确定是每次内存事务(或使用现代CUDA语言——每次wave),不是每次请求,不是每次wrap,不是每次指令。
- 对同一库和同一32位位置的两次请求不会创建库冲突(在CUDA编程指南中说明)。
当您每个线程存储(或加载)4字节(=1个浮点数),即每个wrap 4*32=128字节时,CUDA设备会发出单个内存事务(wrap-wide),因此共享内存访问必须在整个wrap(=32个线程)中无冲突。在我们的情况下,我们使用向量指令每个线程存储16字节(=4个浮点数)。Wrap-wide这将是一个请求总共512字节。GPU将请求拆分为4个内存事务(线程0-7组成一个事务,线程8-15组成一个事务,依此类推),每个事务128字节宽。如果我们按照我们的方案存储,那么线程0-7中的每个线程将存储到相同的四列(红色阴影)或换句话说,相同的四个内存库,导致库冲突。这同样适用于其他内存事务,即线程8-15,线程16-23等。完全避免库冲突的一种可能方法是使用16字节(=4个浮点数)填充前导维度,如下所示。
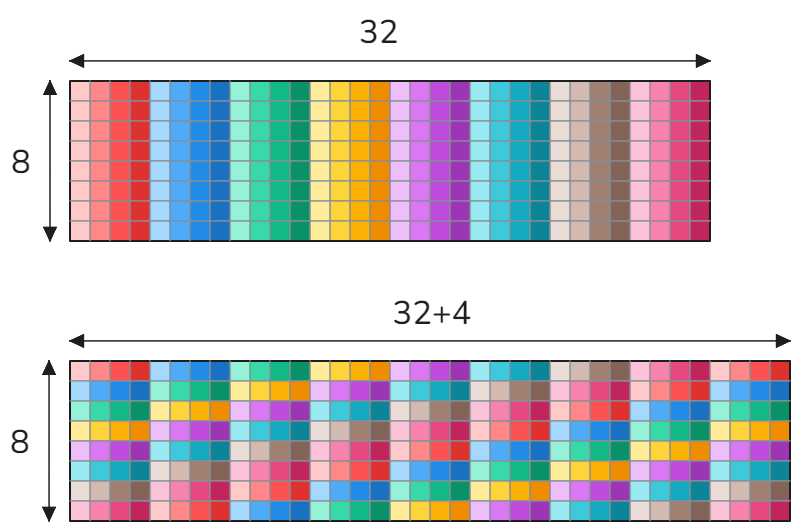
现在,如果我们按照我们的方案存储数据,线程0-7中的每个线程将访问不同的内存库,导致每次内存事务访问32个内存库。这同样适用于其余的内存事务,即t8-t15,t16-t23等。这就是为什么实现中的前导维度是132而不是128:
const int smem_a_ld = 132; // 128 + 4
为了实现双缓冲并存储两个\tilde{A}块,理论上我们需要大小为2*132*8*4字节的共享内存。然而,我们将大小增加到最接近的2的幂= 2*256*8*4,以实现快速切换。将以下代码与本章开头介绍的伪代码进行比较:
// 双缓冲(为简单起见省略了blocks_b)
__shared__ float __align__(2*256*8*sizeof(float)) blocks_a[2*256*8]
uint64_t lds_a_addr;
uint64_t sts_a_addr;
float* lds_a_ptr = blocks_a; // lds = 加载共享
float* sts_a_ptr = blocks_a; // sts = 存储共享
lds_a_addr = convert_to_addr(lds_a_ptr); // 将指针转换为PTX加载/存储指令的地址
sts_a_addr = convert_to_addr(sts_a_ptr); // 将指针转换为PTX加载/存储指令的地址
// 将第一个块存储到共享内存的前半部分
sts_ptx(sts_a_addr);
// 将地址切换到共享内存的后半部分
sts_a_addr ^= 8192;
for (int i=0; i<(K/ks-1); i++) {
...
// 将下一个块存储到共享内存的后半部分(前半部分)
sts_pt