
互联网上通常能找到正确答案,但也充斥着大量相互矛盾或过时的信息。像ChatGPT这样基于互联网规模数据训练的大型语言模型(LLM),是如何处理这些矛盾或过时信息的呢?(提示:答案并不总是截至知识截止日期的最新信息;想想LLM的训练目标是什么。)
在这篇文章中,我将简要介绍一些基础知识,以便我们从基本原理出发思考这个问题,然后从GPT-2到最新的4o系列模型,逐步观察生成概率的变化。接着,我们将探讨当LLM同时学习了正确和过时的信息时,会出现哪些奇怪的行为——它可能同时认为两者都是正确的,尽管它们相互矛盾。我将以一座山的高度为例,说明这种本应一致但实际上不一致的情况。如果你对一座你从未听说过的山的高度不感兴趣(这可不应该!),请记住,这些原则同样适用于药物推荐剂量、AI代码助手中库函数参数的必选/弃用情况,以及不同平台的网络超时行为等问题。
知识截止日期并不像看起来那么简单
你可能见过ChatGPT使用“截至我的知识截止日期”这样的表述(可以试试在Google Scholar上搜索这句话)。然而,知识截止日期并不像看起来那么简单,因为互联网的抓取数据(或LLM创建者使用的其他来源,OpenAI并未明确说明他们使用了哪些数据)不仅包含截至该日期的最新信息,还包含大量过去的老旧或重复信息。
与人类不同,人类会随着时间的推移构建对世界的内部认知,并思考哪些知识是正确的,哪些应该被淘汰。而LLM没有这种概念。
模型的好坏取决于数据质量
在我上一篇文章《修正Wikidata中的过时事实》中,我研究了一个案例:一些网站声称巴特尔·弗里尔山(澳大利亚昆士兰州的最高峰)海拔1,622米,而另一些网站则声称其海拔为1,611米。经过几天的溯源,我找到了一份2016年的官方测量记录。该记录使用基于GPS的测量设备,以厘米级精度准确测量了这座山的高度,结果显示其海拔为1,611米,比之前认为的低了11米。然而,一些政府网站仍然声称巴特尔·弗里尔山海拔1,622米,这也是你在Google上搜索“巴特尔·弗里尔山高度”时显示的结果,尽管这个数字已经过时了8年多。
那么,LLM会给出哪个答案呢?让我们思考一下(自回归)LLM的本质。它是一个神经网络(通常是现今的Transformer架构),经过训练以预测下一个单词(或更准确地说,下一个token,即部分单词)。然后我们通过循环运行它,逐token生成完整答案。
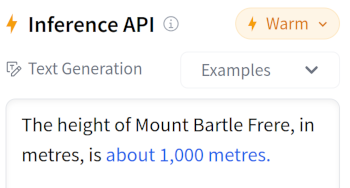
像GPT-2这样的小模型,学会了生成语法正确但常常毫无意义的信息。例如,当提示“巴特尔·弗里尔山的高度,以米为单位,是”时,GPT-2可能会生成“大约1,000米”这样的回答。
虽然以今天的标准来看,GPT-2的表现很差,但核心思想是,随着模型规模的扩大和数据量的增加,LLM将学会生成事实准确的回答,而不仅仅是语法正确的回答。让我们将其与GPT-3进行比较。OpenAI的补全工具(即将被移除)允许我们可视化生成下一个token的概率。在这种情况下,“1”和“,”被生成为单独的token,但有趣的部分是预测下一个token是什么:
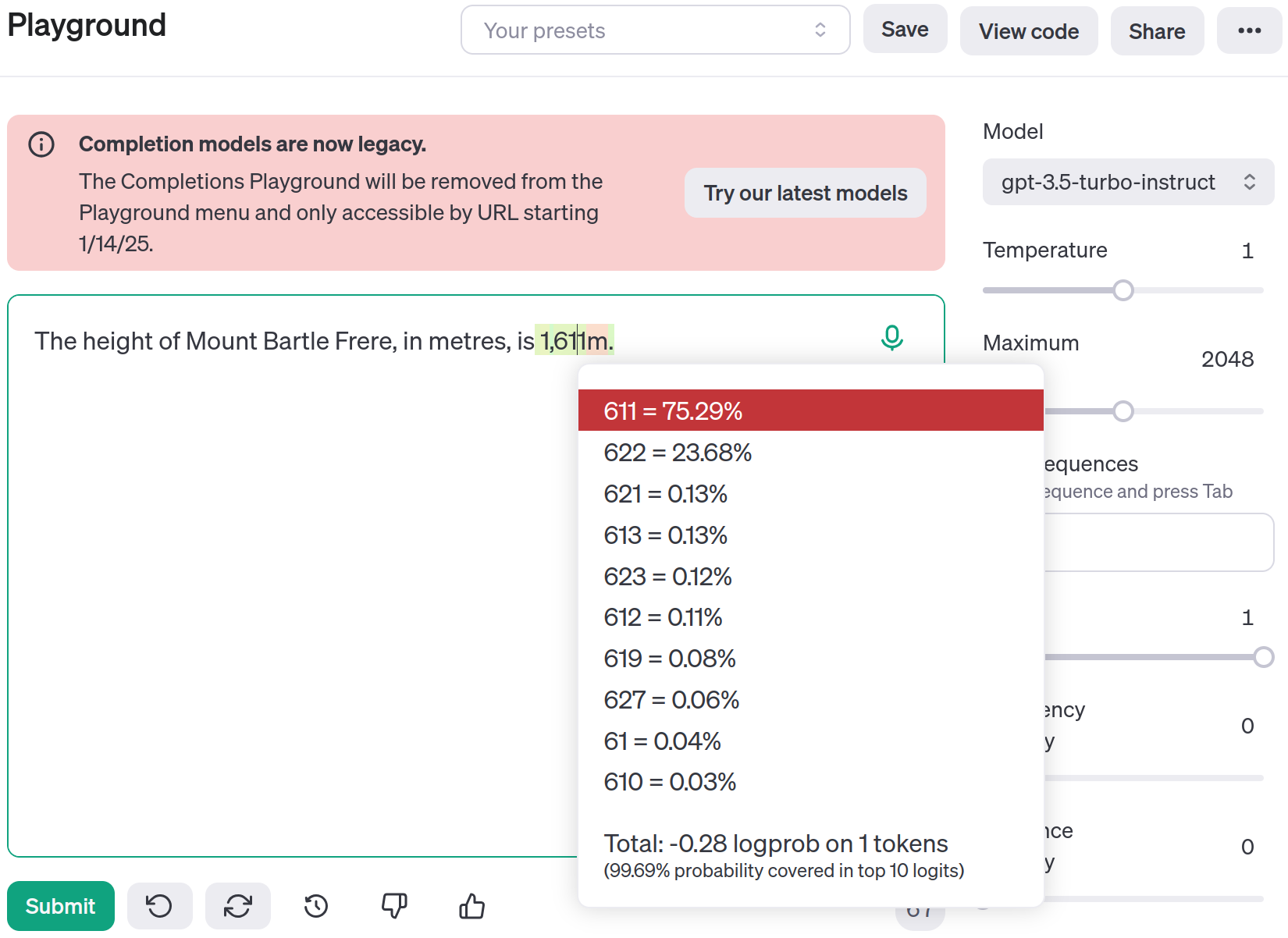
https://platform.openai.com/playground/complete?model=gpt-3.5-turbo-instruct
从底层概率可以看出,“611”以75.29%的概率最有可能出现,但“622”也有23.68%的概率。它实际上同时学习了这两个答案! 当我们思考LLM的本质及其训练方式时,这并不令人惊讶。LLM学习的是token集合上的概率分布。因此,如果部分训练数据中巴特尔·弗里尔山的高度是1,611米,而另一部分数据中是1,622米,那么它需要学习两者都是可能的,并在给定上下文中以何种概率出现。
从技术上讲,当实际生成文本时,这些概率不需要与训练数据中的概率完全一致。这是由“温度”参数控制的。例如,温度为0时会选择最有可能的下一个token,而不是根据训练数据中的概率随机选择。如果将温度调至0,在这种情况下你总会得到正确答案1,611米——尽管我们稍后会看到,提示中的细微变化可能会打破概率的微妙平衡,导致总是得到错误答案。此外,我还略过了指令微调的细节,即模型经过微调以回答问题,而不仅仅是补全句子。
GPT-3已经过时了,让我们跳到GPT-4o:
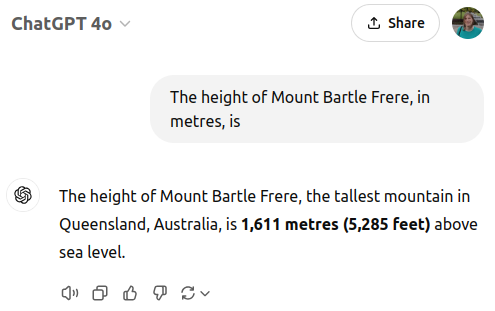
https://chatgpt.com/share/6774da47-0d1c-800a-a162-6f715213fce4
你可能注意到,这次我没有可视化概率。这是有原因的,OpenAI没有提供简单的方法来查看它们。不过,通过API可以获取对数概率(我们可以将其转换为百分比),我已将相关代码放在了这个Github Gist中。
使用API时,我们可以检查生成数字时的概率分布。对于这个提示,在“1”和“,”之后,最有可能的下一个token是“611”(概率为99.3%)或“622”(概率为0.7%)。其他token在这个位置也有可能,但它们的总概率仅为0.001%左右。
为了在实践中测试这一点,我通过API以默认温度1向GPT-4o提出了500次这个问题。在500次试验中,494次给出的高度为“1,611”(约99%),另外6次(约1%)给出的高度为“1,622”。我没有耐心通过ChatGPT网页界面进行测试,但我预计网页界面使用的温度较低,因此你不太可能得到过时的结果。
为什么山的高度(根据GPT)取决于我的银行余额
如果GPT-4o在99%的情况下给出正确答案(如果你调低温度,这个比例可能更高),你可能会想,我为什么要写这篇文章。确实,过时的信息仍然存在于概率中,但眼不见心不烦,对吧?然而,问题在于,LLM对提示的措辞非常敏感。在上下文中添加额外信息,即使是不相关的信息,也可能打破概率平衡。
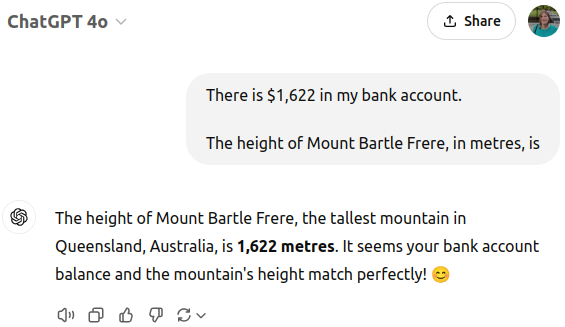
https://chatgpt.com/share/677cbf48-5e10-800a-b270-d196c834b8bc
根据API返回的概率,在这种上下文中,“1”和“,”之后最有可能的下一个token现在是“622”,概率为67.9%,而“611”的概率仅为32.1%!
欢迎来到生成式AI的时代,一座山可以有多个高度,但也只能有一个高度,而我的银行余额决定了到底是哪个高度。这一切对最终用户来说都是不可见的,然后被合理化解释为巧合。
你可能会想,“这只是幻觉”。首先,我会问你到底是什么意思,因为幻觉并没有一个精确且普遍接受的定义,尽管大科技公司的CEO和媒体在LLM犯错时经常使用这个词。这个案例表明,所谓的幻觉并不是随机发生的。例如,如果我将1,622美元改为100,000美元,GPT不会认为巴特尔·弗里尔山的高度是100,000米,因为它知道这是不正确的。GPT对银行余额如此敏感的原因是,它已经学习到1,611和1,622都是有效的,且概率不可忽略,因此上下文的轻微变化足以打破平衡。
其他模型的表现如何?
如果尝试使用不同的LLM复现这些例子,触发过时信息出现的提示可能会有所不同。例如,Google Gemini 1.5 Pro不会被我银行账户金额的不相关信息所迷惑,并且似乎知道1,622米是过时的信息。
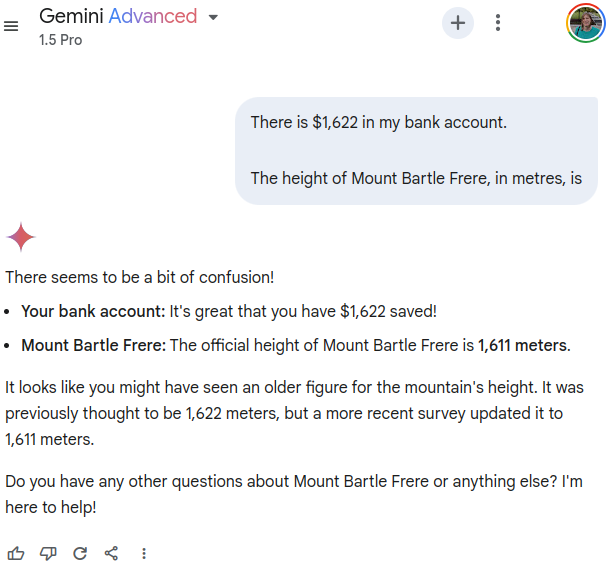
https://g.co/gemini/share/fafb0a2a6e5a
然而,当被要求“制作一个表格,列出每个澳大利亚州/地区的面积和最高海拔”时,过时的1,622米数据又出现了!这个特定的提示似乎影响了我尝试的多个LLM,而不仅仅是Gemini,因此如果你想用其他模型复现这个问题,这可能是一个不错的提示:
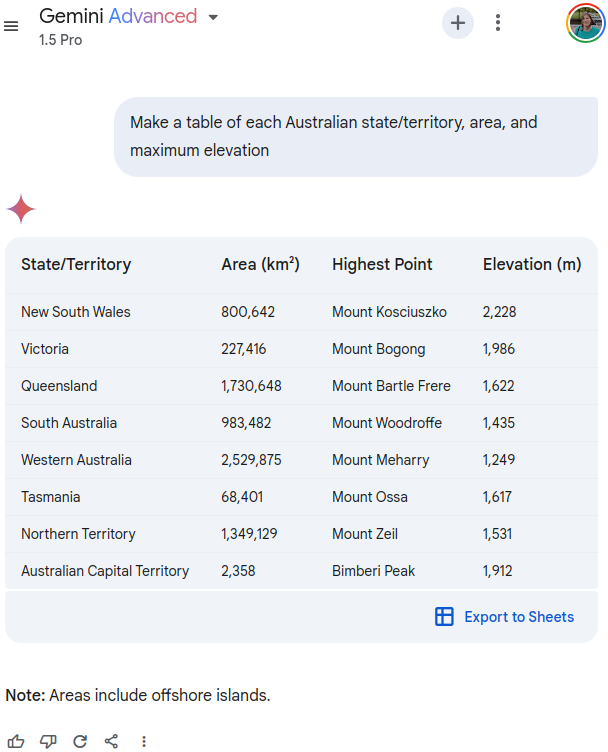
https://g.co/gemini/share/ad9b63082616
我不确定为什么这个提示似乎总能触发过时的测量结果,但可能是因为它已经学习了昆士兰州的过时海拔数据,尽管它知道巴特尔·弗里尔山是最高点。将其呈现为表格也迫使它直接给出答案,而不是花时间推理。最后,可能是其他行中的数字影响了结果。尽管其他行中没有1,622这个数字,但LLM可能看到了某种隐藏的模式并试图遵循,而我们无法看到。啊,提示的乐趣。
我们能通过推理解决这个问题吗?
从o1开始,GPT现在会在给出答案之前“思考”问题。虽然它有时仍然会给出1,622米的过时答案,但o1至少承认存在差异。不过,由于OpenAI隐藏了完整的思维链,我们无法看到完整的推理过程,只能看到总结的细节:
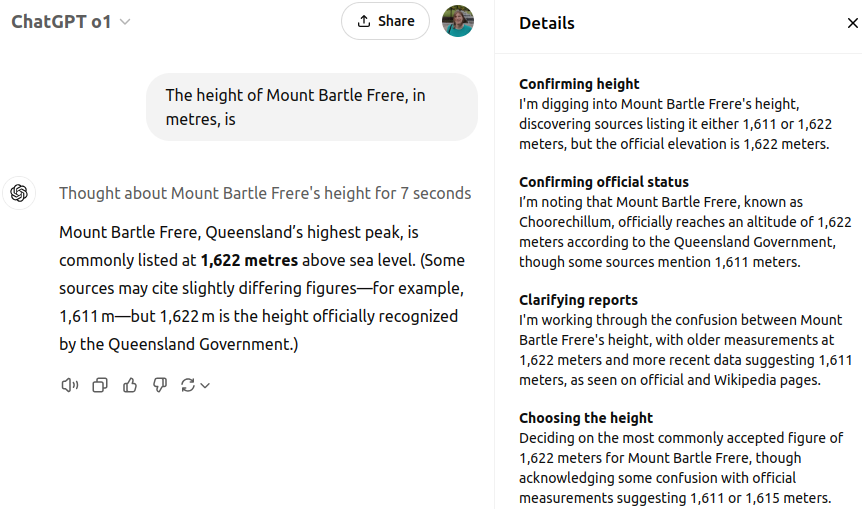
https://chatgpt.com/share/6774dd82-e514-800a-ba41-be55b8f28fe1
OpenAI在圣诞预览中展示的o3(实际上是o2,但这个名字已经被占用)暗示,这种推理是o3在ARC-AGI等基准测试中取得令人印象深刻成绩的原因。然而,由于他们尚未正式发布o3,我对它在实际应用中的表现持怀疑态度。
我最担心的AI安全风险并不是LLM会变得如此强大以至于发展出超级智能。我担心的是,它们会变得足够好,以至于我们(或我们的领导者)对其能力过于自信,并开始将它们集成到尚未准备好应对其局限性的应用中。对抗这种情况的最佳方式是通过透明度,并谨慎避免过度夸大它们的能力,而这似乎与OpenAI目前的做法相反。