2024年国际机器人与自动化会议(ICRA)已经结束,或许是时候总结一下我对机器人学与人工智能研究中所面临问题的差异的思考,并澄清一些误解了。这篇文章主要面向技术爱好者,但我尽量保持轻松和通俗易懂的风格,以便分享给朋友们。文中会提到一些2024年的最新进展,这部分可能会稍微技术化一些。
背景
作为一名机器人学研究者,我经常需要解释机器人学与人工智能(AI)之间的区别。这两个领域有明显的重叠,但随着技术的发展,尤其是在最近,自动化方法上的差异也越来越大。然而,在大众的认知中,这两个领域常常被混为一谈。

当人们谈论AI威胁时,他们脑海中常常浮现的是这张脸。
随着大型语言模型(LLM)如ChatGPT的进展,AI话题再次成为热点,我也因此更频繁地解释两者的区别。一个常见的问题是:“既然AI(LLM)进展如此迅速,为什么机器人学没有同样的突破?既然有了ChatGPT,给机器人造个‘大脑’能有多难?”

当我第26次听到这个问题时的表情
我反复强调的核心观点是:感知运动任务比你想象的要难得多,而LLM的进展并不能直接转化为机器人感知运动任务的性能(至少目前还不能)。用通俗的话来说,我常常会这样开头:“大家都把天网和T900终结者混为一谈,但这是两个完全不同的问题,需要不同的解决方案。”虽然这只是我的个人观点,但后者(T900)确实是一个更复杂的问题。
因此,我决定写下我的思考和论据,以便日后可以直接引用这篇文章。这篇文章主要面向对技术和科学有一定了解的人。我想讨论的特定观点可以总结为这条(现已删除的)推特回复,一位机器人学教授发布了他的研究成果后,有人回复道:“LLM已经这么厉害了,机器人学怎么还没跟上?”
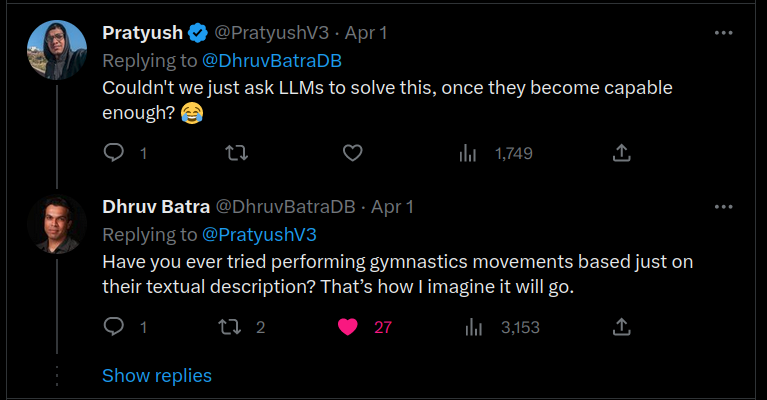
推特上的LLM爱好者回复一位机器人学教授,后者刚刚发布了他的新研究论文。
这篇文章将分为三个部分。首先,我会简要介绍当前AI解决方案的工作原理(相关部分),然后解释机器人学问题的不同之处,以及为什么AI/LLM的方法可能不足以解决这些问题。最后,我会简要探讨为什么许多人难以接受这一核心观点,并分享一些相关的见解。
需要注意的是,这里提到的许多问题仍在激烈讨论中,存在合理的分歧。因此,我可能很快会被证明是错的。另外,当我在本文中提到“机器人”时,我指的是通用机器人,而不是所有特殊用途的机器人。
当前的AI解决方案是如何工作的?(简要介绍)
自2009-2012年深度学习算法在图像和模式识别领域取得突破以来,许多后续开发的方法都归属于同一类算法。这包括生成式AI算法,如现在著名的ChatGPT,以及所有AI合成语音和图像生成工具,如StableDiffusion、Midjourney等。
在不深入技术细节的情况下,这些方法有几个关键支撑因素。首先是计算能力。2011年的突破(AlexNet、DanNet)发生在人们使用图形处理单元(GPU)这种特定芯片大幅加速深度学习模型训练时。其次是对海量数据的需求。从2010年代初的数万张猫图片训练模型识别猫,到现在使用互联网上大部分免费数据来训练生成图像或文本的模型。Richard Sutton在他的文章《苦涩的教训》[5]中写道,计算能力的提升是AI进步的主要驱动力。
这两个因素在我们的讨论中非常重要。计算能力和数据是这些方法的主要支柱。虽然它们不是唯一的因素,但在机器人学的背景下,计算能力和数据需求,尤其是后者,是需要牢记的。
什么是“难”?什么是复杂?
让我先引用Jacob Browning在这场辩论中的一句话(时间戳56:21)[3]:
1966年,MIT的夏季视觉项目旨在用三个月的时间教会计算机“看”。当时普遍认为,让计算机使用语言和推理是AI的难题,而感知则被认为是简单的,只是将输入放入认知系统。这个项目失败了。事实证明,视觉真的很难……这个项目的背景假设是,认知本质上是语言学的,而感知、动作和运动等非语言过程是非认知的,更容易解决。
通俗地说,他的意思是,人们曾假设对图片中的事物(如猫)进行推理比**识别图片中哪些部分(像素)是事物(猫)**更难。然而,直到2011年,我们才能稍微可靠地识别图片中的猫(而且仍然会出现一些搞笑的错误)。
我想通过上述引用强调的是:我们对问题难度的直觉判断往往是一个糟糕的指标。我们可能只比1966年的人们稍微聪明了一点。
自80年代以来的已知事实
上述观察并不是我的原创。事实上,自80年代以来,人们就已经意识到了这一点,并给它起了一个名字:莫拉维克悖论:
莫拉维克悖论是人工智能和机器人学研究者观察到的一个现象,与传统假设相反,推理需要的计算量很少,但感知运动和感知技能需要巨大的计算资源。这一原则由Hans Moravec、Rodney Brooks、Marvin Minsky等人在1980年代提出。
莫拉维克的意思是,当你试图逆向工程(复制)一项技能时,那些低于意识水平的技能是更难解决的问题。
想象一下教一个孩子骑自行车,再对比教同一个孩子做矩阵乘法。前者是孩子在进入小学前就能学会的技能,而后者则是高中或更高年级的内容。在教学中,你可能会将每个任务分解为一系列步骤或概念。但对于骑自行车来说,这些步骤或概念可能并不那么有用,而对于矩阵乘法,即使是计算机也能轻松掌握。前者涉及的潜意识过程比后者多得多,通常需要孩子通过反复试验才能“掌握”如何平衡自行车、踩踏板和转向。而矩阵乘法则完全可以通过纸笔教学(尽管需要很多纸张,如果你考虑到理解它所需的数学知识)。
让我们思考一下日常任务,比如泡一杯咖啡。试着分解这个任务:“拿起桌上的咖啡杯,喝一口。”假设你知道杯子的位置。你需要将每个步骤分解为动作,比如“右手向前移动,速度为X或Y厘米/秒。食指和拇指移动Z厘米。”这是一个你甚至可以在不专心的情况下完成的任务(比如在阅读这篇文章时)。虽然繁琐,但“拿起杯子”应该是相当直接的。现在,如果我在拿杯子的路径上放置其他物体,你的解决方案会如何改变?如果杯子是空的还是满的(不洒出内容物),你会如何抓取它?如果杯子上面有东西呢?如果桌子上有粘性物质(如蜂蜜)将杯子粘在桌子上呢?你的潜意识可以快速轻松地适应这些情况,但你可能需要每次都完全重写“移动指令”表。如果你有编程背景,你可能会想到可以加入if和while循环,并保持指令表的大部分不变。这在受控环境中可能暂时有效,但在现实世界中,变化量很快就会变得难以应对。
现在,我让你将任务分解为“动作组件”。但实际上,要让一个机器人(形状类似于人类)完成这个任务,我们需要将其分解为手臂每块肌肉的收缩和伸展以及用力。这看起来可能没有太大区别,但潜意识中,你的所有“动作”都以某种方式转化为肌肉的预期力量输出。“右手向前移动”,你如何用肌肉运动和力量来表达?机器人没有肌肉,但有关节和执行器,因此我们用力/扭矩来表达这些动作。当这个力出错时,我们有时会看到一些搞笑的行为,比如这个机器人因为以为自己在转动门把手并施加了所需的力,预期会有阻力而摔倒。

机器人试图开门
这个思维实验还有一个陷阱:你可以假设你知道杯子的位置。这看起来很简单,但如果我让你以毫米或厘米的精度估计杯子在桌子上的位置,相对于你的位置,这是一个相当困难的任务!
请记住,所有这些计算都必须非常快速地完成,所有的边缘情况都必须识别(估计)并及时推理。例如,如果不及时将咖啡倒入杯子中,咖啡就会溢出!就像自行车与矩阵乘法的例子一样,仅用语言来完成整个过程是不够的。
我甚至还没有涉及到设计机械系统的需求,这只是问题的软件部分。因此,常见的反驳(尤其是来自机器学习领域的人)是……
“硬件还没跟上”
这是我多次听到的另一个论点,尽管最近少了一些:硬件能力还不足以充分利用AI的进展。这绝对是机器学习从业者加入机器人公司时的头号借口。(免责声明:这个论点是我在职业生涯中多次需要反驳的,因为某些专业人士试图推卸责任,所以这部分可能会显得有些抱怨。)
这里有一个
展示了一个人类控制机器人的场景

人类远程控制一个上半身机器人,用于便利店应用。拍摄于2020年左右
这是我曾经合作过的一个远程操作机器人。它的核心是一个非常简单(且廉价)的设置。由于机器人目标是量产,许多传感器被剥离,部分组件被替换为更便宜但可靠性较低的部件。但即使在这个平台上,用AI自动化下面的任务也是非常复杂的。然而,人类可以毫不费力地完成这个任务;仅凭视觉反馈,一个完全的新手也可以在几分钟内完成这个任务,而不会损坏机器人。更令人印象深刻的是,我们可以轻松适应轻微的偏差。
这个机器人在5年前就已经存在。现在还有更复杂的远程操作设置和机器人,比如1X Technologies(前身为Halodi Robotics)或带有触觉反馈的Shadowhand远程操作,以及本文撰写时的Tesla-bot、Unitree H1和Agility Robotics的Digit等。在学术界,像Mobile-Aloha这样廉价但高效的设置可以通过远程操作完成相当灵巧的任务。因此,硬件已经展示了它在由人脑操作时的能力。当你有了这个设置,尽管传感器有限且硬件廉价,但它能在人类操作下完成复杂任务时,很难说“硬件还没跟上”。(至于它是否经济可行,则是另一个问题。)

两只机器人手试图给玩具青蛙戴隐形眼镜(我觉得是青蛙……?)原始速度的7倍,远程操作。
所以,当他们说“硬件还没跟上”时,他们的实际意思是:
“我们没有那种已经收集了互联网规模的数据集的硬件,这些数据集包含了所有可能的人类任务,完美执行并由人类标注,且无噪声、高精度。哦,还有能在1毫秒内运行ChatGPT大小模型的计算硬件。”
这是事实,我们最接近的可能是Meta的Ego4D数据集。但如果这是机器学习提供有效解决方案的要求,那么大部分工作已经为你完成了。在机器人学中收集数据是困难的。“硬件还没跟上”是一个方便的借口。当多个不同的(廉价)硬件平台在人类操作下能够完成精确任务,但在AI操作下却不能时,这个借口就显得很无力。
旁注:我们需要更好的硬件来学习吗?
上述观点是,即使硬件有限,当由人类操作时,它也能完成有用且复杂的任务。因此,执行任务的硬件限制并不是问题。然而,这并没有回答硬件是否限制了AI能学什么。例如,上述提到的仿人机器人没有触觉,或者在人类操作时,没有重量感。但我们人类通过生活经验学会了这些,当通过VR头显操作机器人时,可以替代这些感觉,仍然能很好地控制机器人。
这是一个我们还没有答案的问题[3]。一些研究人员认为我们不需要任何复杂的硬件(触觉等),仅凭视频就足够了,而另一些人则认为,要学习物理基础,即对物理世界如何运作的有用理解,我们需要来自物理实体(机器人)的数据,而不仅仅是观察。
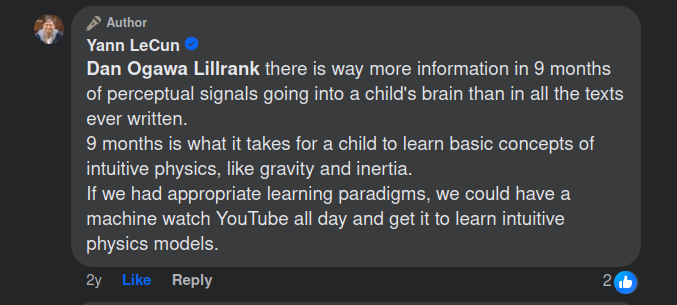
Meta研究负责人在2021年12月20日的Facebook讨论中分享的观点
我个人对仅凭视频或互联网数据就足够的观点持怀疑态度。但这还取决于学习的目标是什么。对于一个能完成健康成年人期望的仿人机器人,我持怀疑态度。但对于一个能在工厂里走动并执行预定任务的简单机器人,或许可以。
支撑AI进步的因素在机器人学中尚不可期
从上述硬件示例中可以看出,人们正在努力为远程操作创建硬件平台。这里的假设是,就像深度学习通过扩展数据(互联网规模)的人类演示(视频、图像、文本、声音)取得成功一样,如果我们收集足够多的机器人执行特定任务的数据,并用文本描述进行标注,我们就可以训练一个模型,使其能够学习抽象动作,从而跳过我们之前思考的“动作组件”过程,模型可以稳健地执行它最初没有训练过的任务。创建这种称为大型行为模型(LBM)[8]的努力正在不同实验室进行。我认为Russ Tedrake和丰田研究所的工作值得一提,还有Google(之前的Everyday Robots)。学术界也在努力创建训练这些模型的数据集(RT-X)。
我相信这些方法会让我们走得更远,我们可能会看到更多多功能且灵巧的机器人从工业和学术实验室中诞生。
但这可能无法满足我们对机器人的期望。机器人系统的故障通常不像LLM模型那样被容忍。当ChatGPT或Midjourney给出错误答案或生成有六根手指的人类图像时,我们可以一笑置之,并继续使用。但自动驾驶汽车或机器人电工剪错电线导致房屋起火,即使是轻微的故障也是不可接受的。

想象一下,如果有一个像这样的机器人,故障率与ChatGPT一样
现实世界比互联网更加动态和混乱。语言模型的边缘故障在互联网用例中是可以容忍的,但这些故障在动态的现实世界中更为普遍,对于机器人学来说不可忽视。复制所有这些边缘案例将是一项艰巨而漫长的数据收集任务。
即使在当前阶段,似乎收集的数据质量比数量更重要,这与LLM模型的情况形成对比。对于机器人学来说,在我们讨论硬件之前,数据是瓶颈。这里的瓶颈不仅仅是指数据的数量,这正在通过公司和LBM的努力得到解决。数据的内容,包括其多样性和精确性,也很重要。
另一个因素是计算能力。ChatGPT和Midjourney可以非常快速地为你写信、解决编程问题、绘制图画,与人类相比速度快得惊人。然而,这些模型输出结果的速度对于灵巧地穿越和与现实环境互动来说仍然太慢。即使我们能够为机器人收集精确的数据,以大约250毫秒的速度(人类的平均反应时间,我们的反射甚至更快[6]),我们能否在当前模型的基础上以所需的速度部署这些数据?
例如,假设你在食堂排队时端着午餐托盘,有人从后面撞了你一下。从识别发生了什么,到在保持午餐托盘水平的同时稳住平衡,整个过程发生得非常快。这是目前LBM或LLM模型难以实现的要求。

机器人可能对我们保持食物托盘平稳的能力感到惊讶,就像我们对蜘蛛侠电影中的蜘蛛感应感到惊讶一样
值得一提的是,这种平衡问题是一些机器人解决得非常优雅的。你可能见过波士顿动力公司“欺负”他们的机器人来展示这种能力。这些机器人使用了完全不同的方法,因此要求LLM模型做到这一点可能不公平,相反,我们可以研究如何将这些方法结合起来。但这又是一个棘手的问题,可能超出了我们对深度学习的期望。如何连接这些方法也是模糊的。从午餐托盘的例子中,我们知道有一些高级推理直接影响了低级的平衡控制;如果你撞到一个端着午餐托盘的小孩,他可能会过度专注于用腿保持平衡,而忽略托盘的平衡。

你的大脑中发生了很多事情
与此同时,你的平衡系统明白保持托盘水平也是一个高优先级目标。你会非常快速地调整反应。
我们对此习以为常,但一个无法应对现实世界中这些意外和陷阱的机器人将难以在街头生存。目前,街头“通用机器人”面临的障碍已经足够多了。

我们需要一个更“街头”的机器人,懂吗?(使用Stable Diffusion 2.1生成。提示词没有指定机器人的颜色,只提到了“潮”)
为什么我们难以接受感知运动可能比抽象推理更难?
好吧,这部分完全是我个人的非专业推测,我希望你带着一大把盐来阅读。我加入这部分是为了可能的趣味讨论。
当我提到复杂的运动协调任务比下围棋/国际象棋、写代码/数学,甚至数字艺术等创造性工作更难时,大多数人本能地拒绝这个想法。这有时让我感到沮丧,让我想起了喜剧小品《专家》,因为常常有一种偏见:“因为我在做这些事时不需要思考,所以它一定很简单。”奇怪的是,即使我周围的人都具备专业知识,理解我正在解释的问题的复杂性,这个观点似乎也不太能让人接受!
我的推测是,认为某些运动任务比我们社会认为的“高智力任务”更难,这种想法让人感到不安,因为它质疑了我们对人类例外论的信仰。

Bill Sanderson的插图,New Scientist,1976年5月13日
毕竟,运动协调在某种程度上,动物也能做到。(莫拉维克在他的悖论中假设,悖论的原因可能是人类大脑的感知和运动部分经过数十亿年的经验和自然选择进行了微调,而抽象思维可能只有十万年或更短的历史。)出于明显的意识形态和宗教原因,说这些比抽象推理更复杂,让许多人感到不适。
这可能不仅仅是关于人类例外论,还涉及到我们社会如何为某些等级制度辩护。一个白领职员在电子表格上打字,似乎比电工、木匠、农民等蓝领工作更受尊重,且收入更高。这背后有明显的经济原因,受供需关系和其他因素驱动。但任何在办公室从事过某种“狗屁工作”的人,一定曾在某个时刻想过:“天哪,猴子都能做这个”,而他们的收入却是蓝领工人的数倍,实际上只做了些琐碎的工作。通常,这些工作还要求员工具备大学学历(甚至更高)。在某种程度上,我们需要制造认知失调来为这种情况辩护。认为感知运动任务比大学几年更难的观点,确实让人难以接受。
甚至早期的社会主义者也认为,根据智力分配统治权是可以的;来自《社会主义1.0:原始社会主义者的最初著作,1803-1813》:
我意识到,我的朋友们,你们是多么沮丧;但请注意,尽管占有者在数量上较少,但他们比你们拥有更多的智慧,为了共同的利益,统治权必须根据智力的份额进行分配。
只是为了记录,我在这里并不采取任何道德立场。社会为何以某种方式运作,超出了我的专业范围。我只是想指出我们不可避免的偏见,当涉及到判断任务的难度时,可能会产生冲突;这与1966年研究人员在推理与感知上的错误观察并无不同。
当一个人的薪水依赖于他不理解某件事时,很难让他理解这件事。——Upton Sinclair
我还应该补充一点,问题的复杂性和实用性并不是一回事。在工程和科学中,一个非常简单的解决方案往往比复杂的方案更有价值。
结语
我对这个主题的思考最初源于我在2021年机器人学习会议上看到一些有希望的结果后,开始应用LLM模型。结果是有希望的,但正如每个机器人学家都会证明的那样,你测试一个系统越多,你就越会思考它的局限性以及运行它所需的条件。现实世界与互联网不同,在互联网上,你和我主要通过文本、语音、视频互动,现实世界是如此多变、混乱和复杂。但对于那些试图让机器人做有用的事情的人来说,这并不是什么新鲜事,所以我并没有太早写下这些,2022年的初稿充满了技术术语,主要是为了我自己,并经常作为与同事讨论的基础材料,他们的背景不是机器人学,而是机器学习和神经科学。
但在Stable Diffusion(图像生成AI)和随后的ChatGPT发布后,我开始收到朋友们发来的消息,比如:
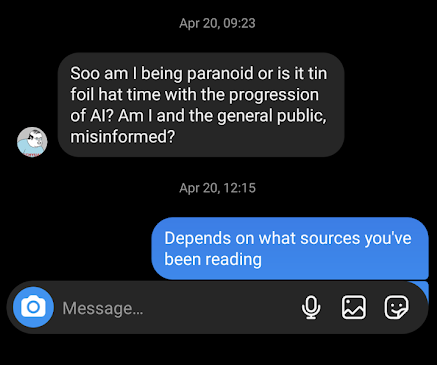
2023年ChatGPT发布后,我在Instagram上收到的一条朋友的消息
所以我想,也许这个观点值得分享,至少与一些朋友分享。在ICRA 2024之后,我也觉得这是许多机器人学研究者的共同感受。如果你觉得它有用,或者只是有趣,我很高兴,但请带着一点怀疑态度阅读。如果你有建设性的批评,我洗耳恭听。
另外,如果有人觉得我在贬低最近的AI进展,我并没有。我认为这些进展是显著的,我也认为它们对我们的社会将产生重大影响,无论是积极的还是消极的。我的观点只是,由于我们对什么是难题的理解存在偏差,人们可能会错误地推断当前AI发展的影响,从而因不同原因产生不必要的焦虑。我个人认为,深度伪造和基于LLM的欺诈的规模和便利性将对互联网、社会和文化产生深远影响。但我的立场与这篇文章[4]类似,我们的文化将适应这项新技术,就像以前一样。但就像2013年自动驾驶的炒作未能兑现承诺(至少目前还没有)一样,我不确定当前的炒作是否会兑现。
正如我的一位前同事,现在是人形机器人行业的研究者所说:人形机器人的进展是显著的,它让我想起了CPU的发展速度。但其中很多是由炒作和对AI进展将如何转化为人形机器人的乐观预期驱动的,因此我认为大多数从事人形机器人的公司不会兑现他们的承诺。但有些可能会,这可能会带来迭代改进,逐渐看到它们在社会中更广泛的应用。作为机器人学研究者,这是一个令人兴奋的时代!

Unitree在ICRA2024上的演示。
感谢Rousslan Dossa帮我校对,否则这篇文章可能会变成一篇充满拼写错误、难以阅读的抱怨。
如果你想要一篇更技术性、更严肃(更好)的文章,带有解决方案导向的观点,我推荐你阅读Eric Jang的文章[1]
参考文献
[1] Eric Jang - 我们如何让机器人学更像生成式建模?
[2] Sarah Constantin - 小脑到底有什么用?(注:我的神经科学家同事告诉我,这篇文章中的一些说法需要谨慎对待,所以你也应该如此!)
[3] 辩论:语言模型是否需要感官基础来获得意义和理解?
[4] AI:柠檬市场与大注销
[5] 苦涩的教训 - Rich Sutton
[6] 了解你的脊髓——反射通路
[7] 辩论3:生成式AI将使许多传统机器人学方法过时
[8] EI研讨会 - Siyuan Feng & Ben Burchfiel - 迈向大型行为模型
[9] 自动化与焦虑
附录
旁注:我们的大脑与有意识/无意识任务的分工
作为人类的例子,我们知道大脑分为不同功能的区域。
但在小脑之上,我们还发展出了一种完全不同的过程,用于需要更快感知运动协调的情况:反射。当你踩到乐高(哎哟)时,你的反射会让你迅速收回腿,甚至不需要思考。但与此同时,另一个反射也会告诉你的另一条腿帮助你保持平衡,这样你就不会失去平衡摔倒[6]。这种感知运动协调需要如此快速的动作,以至于大脑的无意识过程甚至都太慢,它发生在脊髓中。
对于熟悉Daniel Kahneman工作的人来说,他以《思考,快与慢》[思考,快与慢]一书闻名,他提出了一个框架,将思维过程分为“系统2”(较慢、更深思熟虑和逻辑的思考)和“系统1”(更快、本能、潜意识和情感的思考)。到目前为止,用AI方法解决的问题大多来自系统2。在Kahneman的框架中,可以用“系统1”过程更难理解来解释莫拉维克悖论。
另一个类似的概念是成为专家的有意识过程。国际象棋世界冠军Magnus Carlsen在一次采访中说,大多数时候,他只是知道该做什么,而不需要去思考。如果你学会了骑自行车、开车或掌握了任何其他技能,你也经历过这个过程。一开始你需要更多的专注,有意识地努力,使用你的“系统2”,在Kahneman的术语中,直到经过足够的重复,它变得毫不费力。
我们可能不需要按照生物大脑的工作方式来设计事物。机器人的解决方案可能看起来截然不同。尽管如此,我们需要一个解决方案来解决那些在现实世界中不可避免会发生的问题。认为一个能够模仿人类认知过程部分的AI模型,具备所有上述因素,也能解决这些难题,这是一个尚未回答的问题。
关于小脑(控制运动的大脑部分)的有趣阅读,我推荐这篇文章(尽管我的神经科学家前同事告诉我,其中一些结果被夸大了)小脑到底有什么用?