快速开始
本指南将帮助您快速部署和运行千集助理项目。
本指南中部署的配置为 Ollama + sherpa-onnx-asr (SenseVoiceSmall) + edge_tts。如需深度定制,请参阅用户指南中的相关部分。
如果您将 Ollama 替换为 OpenAI Compatible,并将 sherpa-onnx-asr (SenseVoiceSmall) 替换为 groq_whisper_asr,您只需要配置 API Key 即可使用。无需下载模型文件,可以跳过配置本地 GPU 的步骤。
本项目仅推荐使用 Chrome 浏览器。Edge 和 Safari 等浏览器存在已知问题,��如模型表情不工作等。
如果您位于中国大陆,建议在部署和使用本项目之前启用代理,以确保所有资源都能顺利下载。
如果您在启用代理后发现本地服务(ollama、deeplx、gptsovits)无法访问,但禁用代理后可以访问,请确保您的代理绕过了本地地址(localhost),或在所有资源下载完成后运行项目前关闭代理。更多信息请参考设置代理绕过。
Groq Whisper API、OpenAI API 等国外大模型/推理平台 API 通常无法使用香港代理。
设备要求
最低要求
本项目的大部分重型组件(ASR、LLM、TTS 和翻译)可以选择使用 API 代替本地计算,允许您选择希望在本地运行的组件,同时使用那些本地系统无法处理的组件。
因此,本项目的最低设备要求为:
- 一台计算机
- 如果您坚持的话,树莓派也可以
本地运行的推荐设备要求
- 配备 M 系列芯片的 Mac
- Nvidia GPU
- 较新的 AMD GPU(如果支持 ROCm 就很好)
- 其他 GPU
- 或者足够强大的 CPU 来替代 GPU
本项目支持语音识别(ASR)�、大语言模型(LLM)和文本转语音(TTS)的各种后端。请根据您的硬件能力明智选择。如果您发现操作太慢,请选择较小的模型或使用 API。
对于本快速入门指南中选择的组件,您将需要速度正常的 CPU(用于 ASR)、Ollama 支持的 GPU(用于 LLM)和网络连接(用于 TTS)。
环境准备
安装 Git
- Windows
- macOS
- Linux
# 在命令行中运行
winget install Git.Git
关于 winget
如果您使用的是较旧版本的 Windows(Windows 11 (21H2) 之前),您的计算机可能没有内置 winget 包管理器。您可以从 Microsoft Store 搜索并下载 winget。
如果您使用的版本在 Windows 10 1809 (build 17763) 之前,您的计算机可能不支持 winget。请访问 Git 官方网站 下载并安装 Git。关于 ffmpeg,请在线搜索 ffmpeg 安装指南。
# 如果未安装 Homebrew,请运行此命令安装,或参考 https://brew.sh/zh-cn/ 进行安装
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
# 安装 Git
brew install git
# Ubuntu/Debian
sudo apt install git
# CentOS/RHEL
sudo dnf install git
安装 FFmpeg
FFmpeg 是必需的依赖项。没有 FFmpeg,会出现与缺少音频文件相关的错误。
- Windows
- macOS
- Linux
# 在命令行中运行
winget install ffmpeg
# 如果未安装 Homebrew,请运行此命令安装,或参考 https://brew.sh/zh-cn/ 进行安装
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
# 安装 ffmpeg
brew install ffmpeg
# Ubuntu/Debian
sudo apt install ffmpeg
# CentOS/RHEL
sudo dnf install ffmpeg
验证 ffmpeg 安装
在命令行中运行以下命令:
ffmpeg -version
如果您看到类似于以下内容的文本:
ffmpeg version 7.1 Copyright (c) 2000-2024 FFmpeg developers
...(后面跟着一长串文本)
这表示您已成功安装 ffmpeg。
NVIDIA GPU 支持
如果您有 NVIDIA GPU 并希望使用它来运行本地模型,您需要�:
- 安装 NVIDIA GPU 驱动程序
- 安装 CUDA 工具包(推荐版本 11.8 或更高版本)
- 安装对应版本的 cuDNN
Windows 安装步骤:
以下路径仅供参考,需要根据版本和实际安装路径进行修改。
-
检查 GPU 驱动程序版本
- 右键点击桌面并选择"NVIDIA 控制面板"
- 帮助 -> 系统信息 -> 组件,检查驱动程序版本
- 或访问 NVIDIA 驱动程序下载页面 下载最新驱动程序
-
安装 CUDA 工具包
- 访问 CUDA 版本兼容性 检查您的驱动程序版本支持的 CUDA 版本
- 访问 CUDA 工具包下载页面 下载对应版本
- 安装后,将以下路径添加到系统环境变量 PATH:
C:\NVIDIA GPU Computing Toolkit\CUDA\v<version>\bin
C:\NVIDIA GPU Computing Toolkit\CUDA\v<version>\lib\x64
-
安装 cuDNN
- 访问 cuDNN 下载页面(需要 NVIDIA 账户)
- 下载与您的 CUDA 版本匹配的 cuDNN 版本
- 解压后,将文件复制到 CUDA 安装目录:
- 将
cuda/bin中的文件复制到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v<version>\bin - 将
cuda/include中的文件复制到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v<version>\include - 将
cuda/lib/x64中的文件复制到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v<version>\lib\x64
- 将
#### 验证安装:
1. 检查驱动程序安装:
```bash
nvidia-smi
- 检查 CUDA 安装:
nvcc --version
Python 环境管理
从 v1.0.0 版本开始,我们推荐使用 uv 作为依赖管理工具。
如果您更喜欢使用 conda 或 venv,也可以使用这些工具。项目完全兼容标准的 pip 安装方法。
- Windows
- macOS/Linux
# 方法 1:PowerShell
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
# 或者如果您没有 curl,使用 wget -qO- https://astral.sh/uv/install.sh | sh
# 方法 2:winget
winget install --id=astral-sh.uv -e
# 重要:如果您选择 winget,请重启 shell 或获取 shell 配置文件。
# 方法 1:curl
curl -LsSf https://astral.sh/uv/install.sh | sh
# 或者如果您没有 curl,使用 wget -qO- https://astral.sh/uv/install.sh | sh
# 方法 2:homebrew(如果已安装)
brew install uv
# 重要:如果您选择 curl 或 wget,请重启 shell 或获取 shell 配置文件。
有关更多 uv 安装方法,请参考:安装 uv
手动部署指南
1. 获取项目代码
有两种方法获取项目代码。
- 从 GitHub 下载稳定版本
- Git 命令拉取
访问最新的 发布页面 并下载名为 vtuber-client-v1.x.x.zip 的 ZIP 文件。
如果您想要桌面宠物模式或桌面客户端版本,也可以下载以 vtuber-client-electron 开头的文件 - Windows 用户下载 exe 文件,而 macOS 用户下载 dmg 文件。此桌面客户端可以在您配置后端并成功启动后端服务器后启动宠物模式。
使用 Git 时请确保网络连接稳定。中国大陆用户可能需要使用代理。
从 v1.0.0 开始,前端代码(用户界面)已移至单独仓库。我们通过 git submodule 将前端代码链接到 frontend 目录。因此,在 git clone 命令中需要添加 --recursive 标志。
# 克隆仓库 / 下载最新的 Github 版本
git clone https://github.com/icodebase-cn/vtuber_client --recursive
# 进入项目目录
cd 千集助理
对于桌面宠物模式或桌面客户端,访问 vtuber_client 版本 并下载 vtuber-client-electron 文件 - Windows 用户下载 exe 文件,而 macOS 用户下载 dmg 文件。此桌面客户端可以在您配置后端并成功启动后端服务器后启动宠物模式。
2. 安装项目依赖
⚠️ 如果您不位于中国大陆,请不要使用镜像源。
中国大陆用户可以为 Python 和 pip 配置镜像以提高下载速度。这里,我们将设置阿里巴巴镜像。
Details
请将以下内容添加到项目目录中的 pyproject.toml 文件底部。
[[tool.uv.index]]
url = "https://mirrors.aliyun.com/pypi/simple"
default = true
其他一些镜像源(修改上面的 url 部分):
- 腾讯镜像:https://mirrors.cloud.tencent.com/pypi/simple/
- 中科大镜像:https://pypi.mirrors.ustc.edu.cn/simple
- 清华镜像(似乎对我们的项目有一些问题):https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
- 华为镜像:https://repo.huaweicloud.com/repository/pypi/simple
- 百度镜像:https://mirror.baidu.com/pypi/simple
有些镜像可能有时不稳定。如果遇到问题,请尝试切换到不同的镜像。 使用镜像源时不要启用代理。
验证 uv 是否正确安装:
uv --version
创建环境并安装依赖:
# 确保您在项目根目录中运行此命令
uv sync
# 此命令将创建 `.venv` 虚拟环境
对于在此步骤遇到问题的中国大陆用户,请启用您的代理并重试。
接下来,让我们运行主程序来生成配置文件。
uv run run_server.py
然后按 Ctrl + C 退出程序。
从 v1.1.0 版本开始,conf.yaml 文件可能不会自动出现在项目目录中。请运行主程序 uv run run_server.py 一次来生成配置文件。
3. 配置 LLM
我们将以 Ollama 为例进行配置。有关其他选项,请参阅 LLM 配置指南。
如果您不想使用 Ollama / 遇到 Ollama 配置困难,本项目还支持:
- OpenAI Compatible API
- OpenAI 官方 API
- Claude
- Gemini
- Mistral
- 智谱
- DeepSeek
- LM Studio(类似于 Ollama,更易于使用)
- vLLM�(性能更好,配置更复杂)
- llama.cpp(直接运行 .gguf 格式模型)
- 更多(大多数 LLM 推理后端和 API 支持 OpenAI 格式,可以直接集成到本项目)
有关 LLM 配置的更多信息,请参阅相关配置指南。
安装 Ollama
- 从 Ollama 官方网站 下载并安装
- 验证安装:
ollama --version
- 下载并运行模型(以
qwen2.5:latest为例):
ollama run qwen2.5:latest
# 成功执行后,您可以直接与 qwen2.5:latest 聊天
# 您可以退出聊天界面(Ctrl/Command + D),但不要关闭命令行
- 查看已安装的模型:
ollama list
# NAME ID SIZE MODIFIED
# qwen2.5:latest 845dbda0ea48 4.7 GB 2 分钟前
查找模型名称时,使用 ollama list 命令检查 ollama 中下载的模型,并直接复制并粘贴模型名称到 model 选项中,以避免模型名称错误、全角冒号或空格等问题。
选择模型时,请考虑您的 GPU 内存容量和计算能力。如果模型文件大小超过 GPU 内存容量,模型将被强制使用 CPU 计算,这非常慢。此外,较小的模型参数数量较低,会降低对话延迟。如果您想减少对话延迟,请选择参数数量较少的模型。
修改配置文件
如果您的项目目录中没有 conf.yaml 文件,请运行主程序 uv run run_server.py 一次来生成配置文件,然后退出。
编辑 conf.yaml:
- 在
basic_memory_agent下将llm_provider设置为ollama_llm - 在
llm_configs部分调整ollama_llm下的设置:base_url可以保持默认值进行本地操作,无需修改。- 将
model设置为您正在使用的模型,如本指南中使用的qwen2.5:latest。
ollama_llm:
base_url: http://localhost:11434 # 保持默认值进行本地操作
model: qwen2.5:latest # 从 ollama list 获取的模型名称
temperature: 0.7 # 控制响应随机性,值越高越随机(0~1)
有关配置文件的详细说明,请参阅项目中的配置说明。
4. 配置其他模块
本项目 conf.yaml 中的默认配置使用 sherpa-onnx-asr (SenseVoiceSmall) 和 edgeTTS,默认禁用翻译,因此您无需修改。
或者,您可以参阅相关配置指南进行 ASR、TTS 和翻译器的设置。
5. 启动项目
运行后端服务:
uv run run_server.py
# 首次运行可能需要更长时间,因为需要下载一些模型。
成功执行后,访问 http://localhost:12393 打开 web 界面。
如果您更喜欢 Electron 应用程序(窗口模式 + 桌面模式),您可以从 vtuber_client 版本 下载对应平台的 Electron �客户端,可以在后端服务运行时直接使用。您可能会遇到安全警告,因为缺少代码签名 - 请查看模式介绍了解详情和解决方案。 ::
有关前端的更多信息,请参阅前端指南。
延伸阅读
桌面宠物模式、桌面模式和网页模式
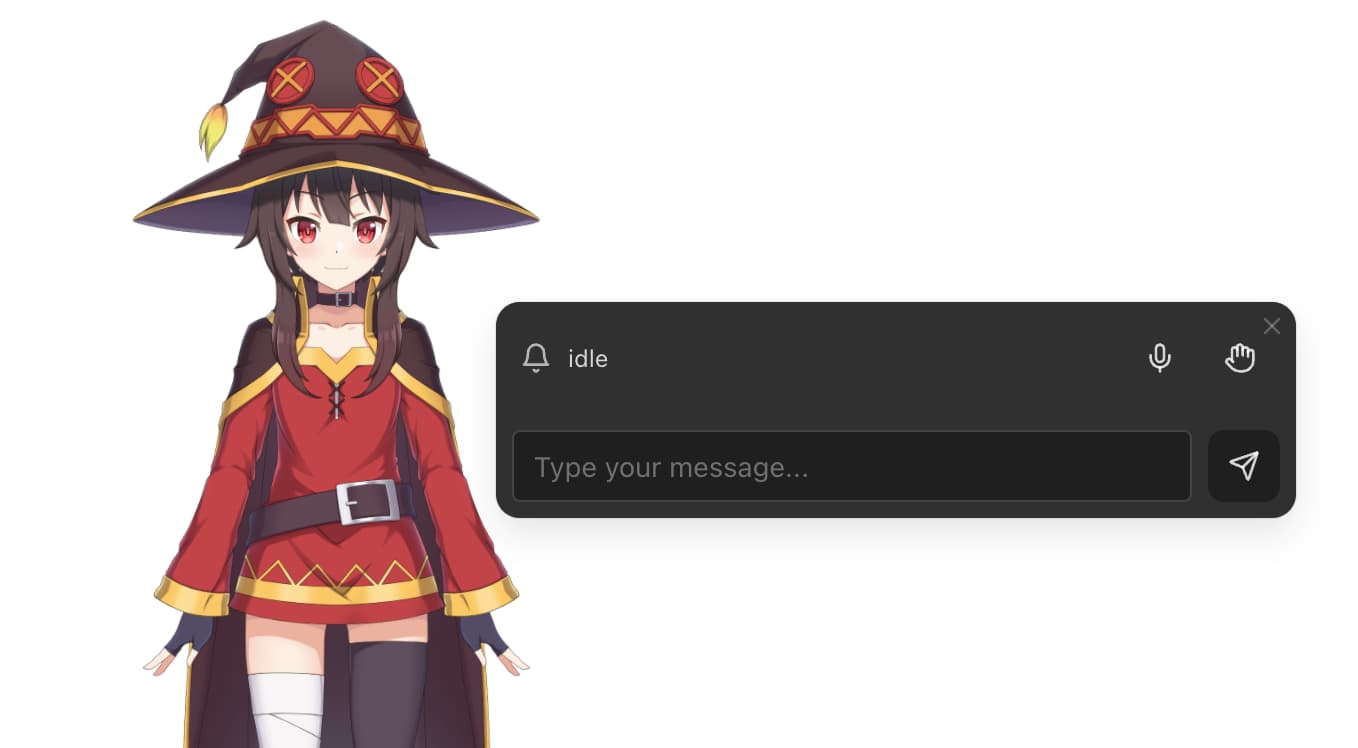
有关桌面宠物模式的介绍和使用指南,请参阅前端模式介绍
修改 Live2D 模型
请参阅 Live2D 相关指南
社区、讨论和交流
请参阅社区参与指南
常见问题故障排除与常见问题
请参阅常见问题指南
如果您的项目目录中没有 conf.yaml 文件
从 v1.1.0 版本开始,conf.yaml 文件可能不会自动出现在您的项目目录中。请运行主程序 uv run run_server.py 一次来生成配置文件。
如果您遇到 Error calling chat endpoint... 错误,请检查:
-
http://localhost:11434/ 是否可访问。如果不可以,可能是因为
ollama run没有成功运行,或者在成功执行后关闭了命令行。 -
如果错误消息表明
Model not found, try pulling it...,使用ollama list检查已安装的模型名称,并确保配置文件中的模型名称与列表完全匹配。 -
如果您的代理软件没有绕过本地地址,Ollama 将无法连接。尝试暂时禁用代理或参考前面的部分设置本地地址的代理绕过。