KDnuggets Exclusive: Interview with Yann LeCun, Deep Learning Expert, Director of Facebook AI Lab
Tags: Andrew Ng, Deep Learning, Facebook, Interview, NYU, Support Vector Machines, Vladimir Vapnik, Yann LeCun
We discuss what enabled Deep Learning to achieve remarkable successes recently, his argument with Vapnik about (deep) neural nets vs kernel (support vector) machines, and what kind of AI can we expect from Facebook.
本文主要讨论是什么给深度学习带来了今日如此令世人瞩目的成绩,Yann Lecun和Vapnik关于神经网络和核函数(支持向量机)的争论,以及Facebook理想中的AI是什么样子的。
By Gregory Piatetsky, KDnuggets.
Gregory Piatetsky,KDD会议创始人,是1989,1991和1993年KDD的主席,SIGKDD第一个服务奖章获得者,KDnuggets网站和周刊的维护者。
Prof. Yann LeCun](http://yann.lecun.com/) has been much in the news lately, as one of the leading experts in Deep Learning - a breakthrough advance in machine learning which has been achieving amazing successes, as a founding Director of NYU Center for Data Science, and as the newly appointed Director of the AI Research Lab at Facebook. See his bio at the end of this post and you can learn more about his work at yann.lecun.com/.
[
He is extremely busy, combining his new job at Facebook and his old job at NYU, so I am very pleased that he agreed to answer a few questions for KDnuggets readers.
Gregory Piatetsky: 1. Artificial Neural networks have been studied for 50 years, but only recently they have achieved remarkable successes, in such difficult tasks as speech and image recognition, with Deep Learning Networks. What factors enabled this success - big data, algorithms, hardware?
问:人工神经网络的研究已经有五十多年了,但是最近才有非常令人瞩目的结果,在诸如语音和图像识别这些比较难的问题上,是什么因素让深度学习网络胜出了呢?数据?算法?硬件?
Yann LeCun: Despite a commonly-held belief, there have been numerous successful applications of neural nets since the late 80's.
Deep learning has come to designate any learning method that can train a system with more than 2 or 3 non-linear hidden layers.
Around 2003, Geoff Hinton, Yoshua Bengio and myself initiated a kind of "conspiracy" to revive the interest of the machine learning community in the problem of learning representations (as opposed to just learning simple classifiers). It took until 2006-2007 to get some traction, primarily through new results on unsupervised training (or unsupervised pre-training, followed by supervised fine-tuning), with work by Geoff Hinton, Yoshua Bengio, Andrew Ng and myself.
But much of the recent practical applications of deep learning use purely supervised learning based on back-propagation, altogether not very different from the neural nets of the late 80's and early 90's.
答:虽然大部分人的感觉是人工神经网络最近几年才迅速崛起,但实际上上个世纪八十年代以后,就有很多成功的应用了。深度学习指的是,任何可以训练 多于两到三个非线性隐含层模型的学习算法。大概是2003年,Geoff Hinton,Yoshua Bengio和我策划并鼓动机器学习社区将兴趣放在表征学习这个问题上(和简单的分类器学习不同)。直到2006-2007年左右才有了点味道,主要是通 过无监督学习的结果(或者说是无监督预训练,伴随监督算法的微调),这部分工作是Geoff Hinton,Yoshua Bengio,Andrew Ng和我共同进行的。
但是大多数最近那些有效果的深度学习,用得还是纯监督学习加上后向传播算法,跟上个世纪八十年代末九十年代初的神经网络没太大区别。
What's different is that we can run very large and very deep networks on fast GPUs (sometimes with billions of connections, and 12 layers) and train them on large datasets with millions of examples. We also have a few more tricks than in the past, such as a regularization method called "drop out", rectifying non-linearity for the units, different types of spatial pooling, etc.
Many successful applications, particularly for image recognition use the convolutional network architecture (ConvNet), a concept I developed at Bell Labs in the late 80s and early 90s. At Bell Labs in the mid 1990s we commercially deployed a number of ConvNet-based systems for reading the amount on bank check automatically (printed or handwritten).
At some point in the late 1990s, one of these systems was reading 10 to 20% of all the checks in the US. Interest in ConvNet was rekindled in the last 5 years or so, with nice work from my group, from Geoff Hinton, Andrew Ng, and Yoshua Bengio, as from Jurgen Schmidhuber's group at IDSIA in Switzerland, and from NEC Labs in California. ConvNets are now widely used by Facebook, Google, Microsoft, IBM, Baidu, NEC and others for image and speech recognition. [GP: A student of Yann Lecun recently won Dogs vs Cats competition on Kaggle using a version of ConvNet, achieving 98.9% accuracy.]
区别在于,我们现在可以在速度很快的GPU上跑非常大非常深层的网络(比如有时候有十亿连接,12层),而且还可以用大规模数据集里面的上百万的样本来训练。过去我们还有一些训练技巧,比如有个正则化的方法叫做 dropout ,还有克服神经元的非线性问题,以及不同类型的空间池化(spatial pooling)等等。
很多成功的应用,尤其是在图像识别上,都采用的是卷积神经网络( ConvNet ),是我上个世纪八九十年代在贝尔实验室开发出来的。后来九十年代中期,贝尔实验室商业化了一批基于卷积神经网络的系统,用于识别银行支票(印刷版和手写版均可识别)。
经过了一段时间,其中一个系统识别了全美大概10%到20%的支票。最近五年,对于卷积神经网络的兴趣又卷土重来了,很多漂亮的工作,我的研究小组有参 与,以及Geoff Hinton,Andrew Ng和Yoshua Bengio,还有瑞士IDSI的AJargen Schmidhuber,以及加州的NEC。卷积神经网络现在被Google,Facebook,IBM,百度,NEC以及其他互联网公司广泛使用,来进 行图像和语音识别。
GP: 2. Deep learning is not an easy to use method. What tools, tutorials would you recommend to data scientists, who want to learn more and use it on their data? Your opinion of Pylearn2, Theano?
问:深度学习可不是一个容易用的方法,你能给大家推荐一些工具和教程么?大家都挺想从在自己的数据上跑跑深度学习。
Yann LeCun: There are two main packages:* Torch7, and
They have slightly different philosophies and relative advantages and disadvantages. Torch7 is an extension of the LuaJIT language that adds multi-dimensional arrays and numerical library. It also includes an object-oriented package for deep learning, computer vision, and such. The main advantage of Torch7 is that LuaJIT is extremely fast, in addition to being very flexible (it's a compiled version of the popular Lua language).
Theano+Pylearn2 has the advantage of using Python (it's widely used, and has lots of libraries for many things), and the disadvantage of using Python (it's slow).
答:基本上工具有两个推荐:
- Torch7
- Theano + Pylearn2
他们的设计哲学不尽相同,各有千秋。Torch7是LuaJIT语言的一个扩展,提供了多维数组和数值计算库。它还包括一个面向对象的深度学习开 发包,可用于计算机视觉等研究。Torch7的主要优点在于LuaJIT非常快,使用起来也非常灵活(它是流行脚本语言Lua的编译版本)。
Theano加上Pylearn先天就有Python语言带来的优势(Python是广泛应用的脚本语言,很多领域都有对应的开发库),劣势也是应为用Python,速度慢。
GP: 3. You and I have met a while ago at a scientific advisory meeting of KXEN, where Vapnik's Statistical Learning Theory and SVM were a major topic. What is the relationship between Deep Learning and Support Vector Machines / Statistical Learning Theory?
问:咱俩很久以前在KXEN的科学咨询会议上见过,当时Vapnik的概率学习理论和支持向量机(SVM)是比较主流的。深度学习和支持向量机/概率学习理论有什么关联?
Yann LeCun: Vapnik and I were in nearby office at Bell Labs in the early 1990s, in Larry Jackel's Adaptive Systems Research Department. Convolutional nets, Support Vector Machines, Tangent Distance, and several other influential methods were invented within a few meters of each other, and within a few years of each other. When AT&T spun off Lucent In 1995, I became the head of that department which became the Image Processing Research Department at AT&T Labs - Research. Machine Learning members included Yoshua Bengio, Leon Bottou, and Patrick Haffner, and Vladimir Vapnik. Visitors and interns included Bernhard Scholkopf, Jason Weston, Olivier Chapelle, and others.
答:1990年前后,我和Vapnik在贝尔实验室共事,归属于Larry Jackel的自适应系统研究部,我俩办公室离得很近。卷积神经网络,支持向量机,正切距离以及其他后来有影响的方法都是在这发明出来的,问世时间也相差 无几。1995年AT&T拆分朗讯以后,我成了这个部门的领导,部门后来改成了AT&T实验室的图像处理研究部。部门当时的机器学习专家 有Yoshua Bengio, Leon Bottou,Patrick Haffner以及Vladimir Vapnik,还有几个访问学者以及实习生。
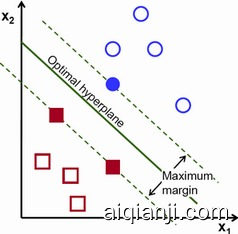 Vapnik and I often had lively discussions about the relative merits of (deep) neural nets and kernel machines. Basically, I have always been interested in solving the problem of learning features or learning representations. I had only a moderate interest in kernel methods because they did nothing to address this problem. Naturally, SVMs are wonderful as a generic classification method with beautiful math behind them. But in the end, they are nothing more than simple two-layer systems. The first layer can be seen as a set of units (one per support vector) that measure a kind of similarity between the input vector and each support vector using the kernel function. The second layer linearly combines these similarities.
Vapnik and I often had lively discussions about the relative merits of (deep) neural nets and kernel machines. Basically, I have always been interested in solving the problem of learning features or learning representations. I had only a moderate interest in kernel methods because they did nothing to address this problem. Naturally, SVMs are wonderful as a generic classification method with beautiful math behind them. But in the end, they are nothing more than simple two-layer systems. The first layer can be seen as a set of units (one per support vector) that measure a kind of similarity between the input vector and each support vector using the kernel function. The second layer linearly combines these similarities.
我和Vapnik经常讨论深度网络和核函数的相对优缺点。基本来讲,我一直对于解决特征学习和表征学习感兴趣。我对核方法兴趣一般,因为它们不能 解决我的问题。老实说,支持向量机作为通用分类方法来讲,是非常不错的。但是话说回来,它们也只不过是简单的两层模型,第一层是用核函数来计算输入数据和 支持向量之间相似度的单元集合。第二层则是线性组合了这些相似度。
It's a two-layer system in which the first layer is trained with the simplest of all unsupervised learning method: simply store the training samples as prototypes in the units. Basically, varying the smoothness of the kernel function allows us to interpolate between two simple methods: linear classification, and template matching. I got in trouble about 10 years ago by saying that kernel methods were a form of glorified template matching. Vapnik, on the other hand, argued that SVMs had a very clear way of doing capacity control. An SVM with a "narrow" kernel function can always learn the training set perfectly, but its generalization error is controlled by the width of the kernel and the sparsity of the dual coefficients. Vapnik really believes in his bounds. He worried that neural nets didn't have similarly good ways to do capacity control (although neural nets do have generalization bounds, since they have finite VC dimension).
第一层就是用最简单的无监督模型训练的,即将训练数据作为原型单元存储起来。基本上来说,调节核函数的平滑性,产生了两种简单的分类方法:线性分 类和模板匹配。大概十年前,由于评价核方法是一种包装美化过的模板匹配,我惹上了麻烦。Vapnik,站在我对立面,他描述支持向量机有非常清晰的扩展控 制能力。“窄”核函数所产生的支持向量机,通常在训练数据上表现非常好,但是其普适性则由核函数的宽度以及对偶系数决定。Vapnik对自己得出的结果非 常自信。他担心神经网络没有类似这样简单的方式来进行扩展控制(虽然神经网络根本没有普适性的限制,因为它们都是无限的VC维)。
My counter argument was that the ability to do capacity control was somewhat secondary to the ability to compute highly complex function with a limited amount of computation. Performing image recognition with invariance to shifts, scale, rotation, lighting conditions, and background clutter was impossible (or extremely inefficient) for a kernel machine operating at the pixel level. But it was quite easy for deep architectures such as convolutional nets.
我反驳了他,相比用有限计算能力来计算高复杂度函数这种能力,扩展控制只能排第二。图像识别的时候,移位、缩放、旋转、光线条件以及背景噪声等等问题,会导致以像素做特征的核函数非常低效。但是对于深度架构比如卷积网络来说却是小菜一碟。
GP: 4. Congratulations on your recent appointment as the head of Facebook new AI Lab. What can you tell us about AI and Machine Learning advances we can expect from Facebook in the next couple of years?
问:祝贺你成为Facebook人工智能实验室的主任。你能给讲讲未来几年Facebook在人工智能和机器学习上能有什么产出么?

Yann LeCun: Thank you! it's a very exciting opportunity. Basically, Facebook's main objective is to enable communication between people. But people today are bombarded with information from friends, news organizations, websites, etc. Facebook helps people sift through this mass of information. But that requires to know what people are interested in, what motivates them, what entertains them, what makes them learn new things. This requires an understanding of people that only AI can provide. Progress in AI will allow us to understand content, such as text, images, video, speech, audio, music, among other things.
答:非常谢谢你,这个职位是个非常难得的机会。基本上来讲,Facebook的主要目标是让人与人更好的沟通。但是 当今的人们被来自朋友、新闻、网站等等信息来源狂哄乱炸。 Facebook 帮助人们来在信息洪流中找到正确的方向。这就需要Facebook 能知道人们对什么感兴趣,什么是吸引人的,什么让人快乐,什么让人们学到新东西。 这些知识,只有人工智能可以提供。人工智能的进展,将让我们理解各种内容,比如文字,图片,视频,语音,声音,音乐等等。
Gregory Piatetsky: 5. Looking longer term, how far will AI go? Will we reach Singularity as described by Ray Kurzweil?
问:长期来看,你觉得人工智能会变成什么样?我们会不会达到Ray Kurzweil所谓的奇点?
Yann LeCun: We will have intelligent machines. It's clearly a matter of time. We will have machines that, without being very smart, will do useful things, like drive our cars autonomously.
答:我们肯定会拥有智能机器。这只是时间问题。我们肯定会有那种虽然不是非常聪明,但是可以做有用事情的机器,比如无人驾驶车。
How long will it take? AI researchers have a long history of under-estimated the difficulties of building intelligent machines. I'll use an analogy: making progress in research is like driving a car to a destination. When we find a new paradigm or a new set of techniques, it feels like we are driving a car on a highway and nothing can stop us until we reach the destination.

至于这需要多长时间?人工智能研究者之前很长的一段时间都低估了制造智能机器的难度。我可以打个比方:研究进展就好像开车去目的地。当我们在研究上发现了新的技术,就类似在高速路上开车一样,无人可挡,直达目的地。
But the reality is that we are really driving in a thick fog and we don't realize that our highway is really a parking lot with a brick wall at the far end. Many smart people have made that mistake, and every new wave in AI was followed by a period of unbounded optimism, irrational hype, and a backlash. It happened with "perceptrons", "rule-based systems", "neural nets", "graphical models", "SVM", and may happen with "deep learning", until we find something else. But these paradigms were never complete failures. They all left new tools, new concepts, and new algorithms.
但是现实情况是,我们是在一片浓雾里开车,我们没有意识到,研究发现的所谓的高速公路,其实只是一个停车场,前方的尽头有一个砖墙。很多聪明人都 犯了这个错误,人工智能的每一个新浪潮,都会带来这么一段从盲目乐观到不理智最后到沮丧的阶段。感知机技术、基于规则的专家系统、神经网络、图模型、支持 向量机甚至是深度学习,无一例外,直到我们找到新的技术。当然这些技术,从来就不是完全失败的,它们为我们带来了新的工具、概念和算法。
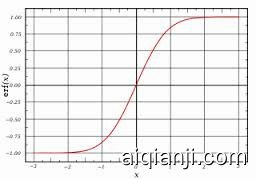
Although I do believe we will eventually build machines that will rival humans in intelligence, I don't really believe in the singularity. We feel like we are on an exponentially growing curve of progress. But we could just as well be on a sigmoid curve. Sigmoids very much feel like exponentials at first. Also, the singularity assumes more than an exponential, it assumes an asymptote. The difference between dynamic evolutions that follow linear, quadratic, exponential, asymptotic, or sigmoidal shapes are damping or friction factors. Futurists seem to assume that there will be no such damping or friction terms. Futurists have an incentive to make bold predictions, particularly when they really want them to be true, perhaps in the hope that they will be self-fulfilling.
虽然我相信我们最终一定会制造出超越人类智能的机器,但是我并不相信所谓的奇点理论。大部分人觉得技术的进展是个指数曲线,其实它是个S型曲线。 S型曲线刚开始的时候跟指数曲线很像。而且奇点理论比指数曲线还夸张,它假设的是渐进曲线。线性、多项式、指数和渐进以及S曲线的动态演变,都跟阻尼和摩 擦因子有关系。而未来学家却假设这些因子是不存在的。未来学家生来就愿意做出盲目的预测,尤其是他们特别渴望这个预测成真的时候,可能是为了实现个人抱 负。
GP: 6. You were ( are ?) also a Director for the NYU Center for Data Science. How will you combine your work at Facebook and at NYU?
问:你还在NYU数据科学中心当兼职主任,你怎么权衡或者结合在Facebook的工作?
Yann LeCun: I have stepped down as (founding) director of the  NYU Center for Data Science.
NYU Center for Data Science.
The interim director is S. R. Srinivasa "Raghu" Varadhan, possibly the most famous probability theorist in the world. NYU has initiated a search for a new permanent director. I have invested a huge amount of energy into the creation of CDS. We now have an MS program in Data Science, and will soon have a PhD program. We have 9 open faculty positions for the center, we have won a very large, five-year grant from the Moore and Sloan foundations in collaboration with Berkeley and University of Washington, we have a partnership with Facebook and other companies, we will soon have a new building. The next director is going to have all the fun!
答:我在NYU数据科学中心已经不再担任实际职务了,而是名誉主任。在新的主任选举出来以前,代理主任是 S.R. Srinivasa “Raghu” Varadha ,世界上最有名的统计学家。NYU已经展开了新主任的遴选工作。在数据科学中心的建立过程中,我花费了相当大的精力。我们现在数据科学方面有硕士生项目, 未来会有博士生项目。现在中心有9个工作空缺,和Berkeley和华盛顿大学合作,我们从Moore和Sloan基金会拿到了非常大的一个五年基金支 持,中心现在和Facebook等各大公司都有合作伙伴关系,我们马上要盖新大楼。下一任中心主任将会非常热爱自己的工作!
GP: 7. The term "Data Science" has emerged recently and has been described as an intersection of Statistics, Hacking, and Domain/Business Knowledge. How is Data Science different from previous terms like "Data Mining" and "Predictive Analytics" ? If it is a new science, what are its key equations / principles ?
问:“数据科学”这个词,近来经常出现,被认为是统计学、商业智能等学科的交叉。这个数据科学和之前的“数据挖掘”或者“预测分析”有什么不同?它是一个新学科?它的公理和原则有哪些?
Yann LeCun: Data Science pertains to the automatic or semi-automatic extraction of knowledge from data. This concept permeates many disciplines, each of which has a different name for it, including statistical estimation, data mining, predictive analytics, system identification, machine learning, AI, etc.
答:数据科学指的是自动或半自动地从数据中抽取知识。这个过程涉及很多的学科,每个学科对它都有自己的名字,包括概率估计,数据挖掘,预测分析,系统辨识,机器学习,人工智能等等。
On the methods side, statistics, machine learning, and certain branches of applied mathematics could all claim to "own" the field of data science. But in reality, Data Science is to Statistics, Machine Learning, and Applied Math as Computer Science was to Electrical Engineering, Physics, and Mathematics in the 1960s. The same way computer science became a full-fledged disciplined, rather than a sub-field of mathematics or engineering is its importance to society.
从各个学科的角度,统计学、机器学习以及某些应用数学,都可以声称是数据科学的起源。但是实际上,数据科学之于统计学、机器学习以及应用数学,正 如上个世纪六十年代的计算机科学之于电子电气、物理和数学。后来计算机科学变成了一个完全成熟的独立学科,而不是数学或者工程的子学科,完全是因为它对社 会非常重要。
With the exponential growth of data generated by our digital world, the problem of automatically extracting knowledge from data is growing rapidly. This is causing the emergence of Data Science as a discipline. It is causing a redrawing of the boundaries between Statistics, Machine Learning, and Applied Mathematics. It is also creating a need for tight interactions between "methods" people and "domain" people in science, business, medicine, and government.
当今的数字时代,数据指数级别的疯涨,从数据中自动抽取知识这个问题,已经逐渐成为了人们的焦点。这正促进数据科学成为一个真正独立的学科。也促 进着统计学、机器学习和数学重新划定自己的学科界限。数据科学还创造了“方法学科”的科学家和“领域学科”如自然科学、商科、药学和政府的工作人员紧密交 流的机会。
My prediction is that 10 year from now, many top universities will have Data Science departments.
我预测,未来十年,很多顶尖大学都会设立数据科学系。
GP: 8. What is your opinion on "Big Data" as a trend and as a buzzword? How much is hype and how much is real?
问:您对于“大数据”这个词怎么看?作为一种趋势或者一个时髦词,它有多少成分是夸大,多少是真实的?
Yann LeCun: I like the joke circulated around social networks that compared big data to teenage sex: everyone talks about it, nobody really knows how to do it, everyone thinks everyone else is doing it, so everyone claims they are doing it. [GP: this joke came from Dan Ariely Facebook post]
答:对于这个词,我觉得最近社交网络上比较流行的那个笑话非常贴切,把大数据比作青少年性行为:每个人都在谈论它,没人知道到底怎么做,每个人都以为其他人知道怎么做,所以每个人都声称自己也在做,这个笑话我是从Dan Ariely的 Facebook 上看到的。
I have seen people insisting on using Hadoop for datasets that could easily fit on a flash drive and could easily be processed on a laptop.
There is hype, to be sure. But the problem of how to collect, store and analyze massive amounts of data is very real. I'm always suspicious of names like "big data", because today's "big data" is tomorrow's "little data". Also, there are many important problem that arise because of too little data. It is the often the case for genomics and medical data. There is never enough data.
我碰到过一些人,哪怕是闪盘可以存下,笔记本可以处理的数据,都坚持使用hadoop来处理。
这个词确实被夸大了。但是如何收集、存储和分析海量数据这个问题是实际存在的。我经常怀疑的是诸如“大数据”这样的名字而已,因为今日的大数据,将成为明日的小数据。还有,很多问题都是因为数据量不足而产生的,比如基因和医疗数据,数据永远都不会够用。
GP: 9. Data Scientist has been called "the sexiest profession of the 21st century". What advice would you give to people who want to enter the field?
问:数据科学家被称为“二十一世纪最性感的职业”。你给想要进入这个领域的人们提一点建议?
Yann LeCun: If you are an undergrad, take as many math, stats, and physics courses as you can, and learn to program (take 3 or 4 CS courses).
If you have an undergraduate degree, apply to NYU Master of Science in Data Science .
答:如果你是个本科生,多学数学、统计学还有物理学,更重要的是你要学着写代码(学三到四门计算机课程)。如果你有本科学位,那么你可以申请NYU数据科学中心的 硕士项目 。
GP: 10. What is a recent book you read and liked? What do you like to do when away from a computer /smartphone?
问:你最近对哪本书比较感兴趣?不接触计算机和手机的时候你都在干些什么?
I design and build miniature flying contraptions, I tinker with 3D printers, I hack microcontroller-based widgets, and I hope to get better at making music (I seem to collect electronic wind controllers). I read mostly non-fiction, and I listen to a lot of jazz (and to many other types of music).
答:在我空闲的时候,我会造一些微型飞行器,我非常喜欢3D打印,我还经常研究带微控制器的电路板,我还希望能更好的制造音乐(我收集电子风门控制器)。大多数非小说的作品我都看,还听可多的爵士乐(或者类似的音乐)。
**Bio: **Yann LeCun is Director of AI Research at Facebook, and the founding director of the Center for Data Science at New York University. He is Silver Professor of Computer Science, Neural Science, and Electrical Engineering and NYU, affiliated with the Courant Institute of Mathematical Science, the Center for Neural Science, and the ECE Department.
He received the Electrical Engineer Diploma from Ecole Supérieure d'Ingénieurs en Electrotechnique et Electronique (ESIEE), Paris in 1983, and a PhD in Computer Science from Université Pierre et Marie Curie (Paris) in 1987. After a postdoc at the University of Toronto, he joined AT&T Bell Laboratories in Holmdel, NJ in 1988. He became head of the Image Processing Research Department at AT&T Labs-Research in 1996, and joined NYU as a professor in 2003, after a brief period as a Fellow of the NEC Research Institute in Princeton. He was named Director of AI Research at Facebook in late 2013 and retains a part-time position on the NYU faculty.
His current interests include machine learning, computer perception, mobile robotics, and computational neuroscience. He has published over 180 technical papers and book chapters on these topics as well as on neural networks, handwriting recognition, image processing and compression, and on dedicated circuits and architectures for computer perception. The character recognition technology he developed at Bell Labs is used by several banks around the world to read checks and was reading between 10 and 20% of all the checks in the US in the early 2000s. His image compression technology, called DjVu, is used by hundreds of web sites and publishers and millions of users to access scanned documents on the Web. A pattern recognition method he developed, called convolutional network, is the basis of products and services deployed by companies such as AT&T, Google, Microsoft, NEC, IBM, Baidu, and Facebook for document recognition, human-computer interaction, image tagging, speech recognition, and video analytics.
LeCun has been on the editorial board of IJCV, IEEE PAMI, and IEEE Trans. Neural Networks, was program chair of CVPR'06, and is chair of ICLR 2013 and 2014. He is on the science advisory board of Institute for Pure and Applied Mathematics, and has advised many large and small companies about machine learning technology, including several startups he co-founded. He is the recipient of the 2014 IEEE Neural Network Pioneer Award.
LeCun简介
Yann LeCun (杨立昆),Facebook人工智能实验室主任,NYU数据科学中心创始人,计算机科学、神经科学、电子电气科学教授。他1983年在ESIEE获得电 气工程学位,1987年在UPMC获得计算机博士学位。在多伦多大学做了一段时间博士后,于1988年加入位于新泽西州的AT&T贝尔实验室。 1996年他成为图像处理研究部的主任,2003年,在普林斯顿NEC研究院经历短暂的Fellow生活以后,加入NYU。2013年,他被 Facebook聘请为人工智能实验室主任,同时仍在NYU兼职。
他目前的研究兴趣在于:机器学习,计算机认知,移动机器人以及计算神经学。在这些领域他发表了180余篇论文和图书,涉及主题有神经网络、手写体 识别、图像处理和压缩以及计算机认知的专用电路和架构。他在贝尔实验室研发的字符识别技术,被全世界多家银行用于识别支票,早在2000年左右,该程序识 别了全美10%-20%的支票。他发明的图片压缩技术DjVu,被数百家网站和出版商采纳,拥有上百万用户。他研发的一个识别方法,卷积网络,是 AT&T、Google、微软、NEC、IBM、百度以及Facebook等公司在文档识别,人机交互,图片标注、语音识别和视频分析等等技术的 奠基石。
LeCun教授是IJCV、PAMI和IEEE Trans的审稿人。CVPR06的程序主席、ICLR2013和2014的主席。他是IPAM(Institute for Pure and Applied Mathematics)的顾问。他是2014年IEEE神经网络领军人物奖获得者。
https://www.kdnuggets.com/2014/02/exclusive-yann-lecun-deep-learning-facebook-ai-lab.html