
作者 gingo
二月底的时候,收到智东西邀请,给大家讲了一堂关于GAN的公开课,主要说的就是GAN的发展,以及在动漫领域的一些相关应用和进展。主要也就是帮助大家对现在的很多工作有一个大致的了解,起个抛砖引玉的作用吧。
周末大概整理了一下公开课里面关于动漫的部分内容,分享出来,希望对大家有帮助。
首先,大家聊算法在各个领域的应用之前,先要知道这些算法可以做什么方面的应用,才能理解这些应用和自己的领域合不合适,契合度有多高。能不能用这些算法来解决。
同样的,我们考虑GAN在动漫领域的应用的时候,首先要考虑,GAN在图像领域是怎样应用的。
在图像应用领域主要有如下几个部分:图像生成,图像翻译,超分辨率,图像补全,和交互式图像生成等几个方面了。图像生成,前面在介绍GAN的发展历史的时候,已经看到了这几年的生成发展历程


这几个方面中,最关键的,就是图像翻译了。很多方向都是从图像翻译拓展而来。因此在这里主要介绍图像翻译。

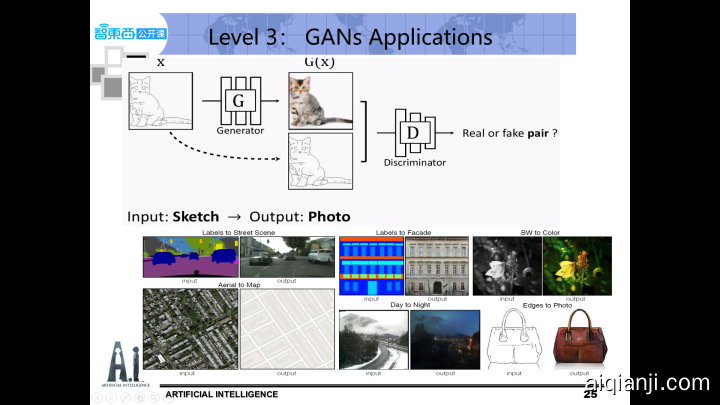
什么是图像翻译。我们刚刚说了,是从一副(源域)输入的图像到另一副(目标域)对应的输出图像的转换。它分为两种,一种是输入和输出的图像需要一一对应的,叫Paired Image-to-Image Translation 另一种是不用一一对应的,Unpaired Image-to-Image Translation。

有成对训练数据的图像翻译问题,一个典型的例子是pix2pix,传统的GAN输入一个随机噪声,就会输出一幅随机图像。但我们说过那样随机的图像用处不大,但如果我们有一个帮手,输入给它一张图像,它可以完成一定的功能,最终输出一张对应的图像,用处就很大了。比如输入一只猫的草图,输出同一形态的猫的真实图片。于是它对传统的cGAN做了个小改动,它不再输入随机噪声,而是输入一张的图片。然后把输入的图像作为一个condition,和生成图一起给到判别网络,则生成的虚假图片就一定和这个输入的图片相关联,这样的结构可以学到x到y之间的一一映射。
它代表了图像处理的很多问题,比如图像上色,简图到实际图之间的转换等。
无成对训练数据的图像翻译问题,一个典型的例子是 CycleGAN。我们有了GAN可以将一张图片转成另外一张图片。很自然而然的,大家就想到,我能不能将图片从A转到B,然后再转回来呢?理念就是,如果从A生成的B是对的,那么从B再生成A也应该是对的。
CycleGAN 就是基于这种想法,它使用了两对 GAN,让两个域的图片互相转化一个斑马到马的A→B单向GAN加上一个马到斑马的B→A单向GAN,形成个环形,所以命名为Cycle。
CycleGAN不要求训练的A和B数据集中的图像一一对应,也就是unpaired。

除了大家感兴趣的苹果变橘子,橘子变苹果的效果,还有更加实用的有趣的效果,譬如将用《堡垒之夜》卡通风格的游戏 通过cyclegan转成《绝地求生》写实风的游戏。 长视频效果链接 https://v.qq.com/x/page/s0833gs6yfd.html
而unpaired image to image translation 除了在两个领域可以转换,还可以多个领域转换。譬如2019年 FUNIt 用少量数据,完成多领域的图像转换,左上角是输入图像,同时可以转换成猫咪 金钱豹 狗等多种动物。

其他三个方向 这次不展开细说,基本原理和思想很多时候是源于图像翻译 这两个是英伟达 图像修复 和 交互式图像生成的工作展示。智东西这次英伟达专场刘老师有对论文的详细解读。英伟达官网上也有ai-playground试玩,大家可以去体验一下。https://www.nvidia.com/en-us/research/ai-playground/

接来下 我们聊聊动漫领域,动漫我们都很熟悉,它本身包含动画与漫画两个部分。除了大家熟知的日本动漫,这几年无论是国产动画,还是国产漫画,都有了蓬勃的发展,常常听到大家惊呼,国漫崛起了。左边这些最近的国产动画,比如哪咤,白蛇缘起,罗小黑战记,右边是一些知名度比较高的的国产漫画,一人之下,镖人,长歌行,非人哉,斗破苍穹,我想不少人都能在里面找到自己熟悉的那一部。

中国的文娱产业,主要有几个部分,影视,小说,动漫,游戏,往往鼎力相助构成完整的产业链。影视受众较广,表达能力真实,细节丰富,而动漫可以增加更佳夸张的手法,在各种充满想象力的背景环境下来进行故事表达,小说,尤其是网络文学,妥妥的是现在的领头军,据统计,到现在网文作品累计达到近3000万部,网文用户占网民一半以上。也正是因为有大量的作品,才能大浪淘沙,精品倍出。这几年,我们都能感受到很多精品小说不断向影视,动漫,游戏输出,给大家带来不一样的优质体验。网文改编的年末大剧《庆余年》相信大家现在依然还回味无穷。
虽然现在动漫领域不断有好的作品出现,可是数量还有点少。追其缘由,还是生产力跟不上的问题。过去日本漫画发展的年代,由于是出杂志,因此漫画是月更的,后来改成了周更,而且是黑白漫画。画师有足够的时间来产出,没有网络文化的冲击,用户也很有耐心。而现在时代不一样,要求也不一样了。而中国漫画这几年在网文日更的带动下,很多工作室选择了一周两更到三更,而且是彩漫。平台和用户都对漫画作者提出了更高的要求。
所以 漫画作者自己也发出了呐喊:故事好,画面好,就要等,故事好,更新快,画面就会崩,画面好,更新快,故事就不好看,而三者全占的漫画 根本不存在嘛。

要想解决生产力的问题,我们先看看国内画师画一幅漫画,需要哪些步骤吧。
拿到剧本后,首先要进行动漫形象设计,人总是故事中最重要的环节。画师时间不够的话,很多群演,其他人物,都成了简笔画。同样的问题也出现在一些avg游戏里,有的配角,往往连个立绘都没有,只给一个名字。这样的问题使得一些有着宏大设定,复杂剧情的故事,如果完全精美绘制,则制作成本较高,只绘制主要故事情节人物,则降低了故事和人物发丰满度,也降低读者的体验。
第二个是分镜草稿,这个是画师创造力和水平的体现。
第三个是对草稿勾线,完成线稿。
第四个是线稿上色,黑白线稿成为彩色漫画。
第五个漫画的场景也是很重要的一个环节。丰富细致的背景图,往往加分不少。
第六个是后期特效,特效有很多,核心的一个是给漫画加上不同的光线效果,达到更加逼真的程度

提升生产力的关键,是改进生产工具,我们看看在动漫方向AI算法可以做什么。
以往,想要绘制一个动漫形象总是要画师来动手,当GAN可以开始生成人脸的时候,大家也想到,是不是也可以生成动漫人脸呢。
当然可以,如果有同学在听一些老师讲GAN的课,往往会留个作业让大家试着用DCGAN来尝试进行动漫人脸生成。不过可能大家生成的效果都不太好,第一个原因,当然是数据集的原因。这个在后面会跟大家说一下类似这种数据集如何清洗。第二个原因,就是算法的原因。我们来看看其他人的生成效果吧。

这张图来自于makegirlsmoe,是复旦大学的Yanghua Jin,2017年在日本P站实习的时候做的工作。他的训练框架来自于DCGAN的改进版DRAGAN,可以定制不同的发色,发型(长发还是短发),眼睛的颜色等多种特征来生成256*256尺寸的动漫人脸。后来他更新算法后,他还做成了一个区块链游戏crypko,和我开始展示的真人特征合成相似,用两张动漫小姐姐的特征合成新的小姐姐。不过需要翻墙
到2018年Stylegan出来之后,合成效果又大幅度的提升,大神Gwern Branwen 用stylegan合成了更高质量的动漫人脸,而且还可以针对某个特定人生成,所谓的生成一百个明日香 就是他的作品。最大动漫数据库开源,他是这个行业的领头人,推动着相关发展。
国内飒漫画ios版本也上线了类似的工作,可以获取不同的书灵动漫角色,然后通过合成或者定制得到动漫形象,整体生成质量比较高,比较少出现奇怪的人脸。相比较其他的产品,体验起来速度快。

2019年底,出了stylegan2,上面这张图是Gwern用新的模型和语义生成gpt-2生成的小姐姐故事。 右下角是waifulabs出品的小姐姐。他们对数据清洗和优化,合成范围更大,能够合成上半身效果,不过服装部分出bug的几率还是比较大。
还记得之前提到stylegan的latent space特征分离效果极佳,因此,动漫头像的可适配调整的语义特征,从开始的十几个特征变成了几十个特征,这还是因为人类的理解力有限,否则定个几百个特征,也是不在话下的。

大家肯定在想,动漫头像可以自动生成了,那全身立绘还有多远?
还真是不远了,日本的几位学者,结合pose信息,在Progan的基础上,创作了PSGAN。可以实现卡通小人的服装,动作等变换,这是512512的一个效果,最新的效果他们已经做到了10241024的分辨率。

上传视频封面
好的标题可以获得更多的推荐及关注者
由于pose结合图像生成,可以进行服装的变换,所以这个解决方案在修改数据集后,可以直接做换衣生成。

而使用stylegan进行换衣生成的效果最优效果为Gokhan Yildirim ICCV2019文章中的效果,因此只要有充足的数据支持,动漫立绘自动生成指日可待。

除去图像生成,图像翻译的应用里,动漫上色算一个很重要的部分。
一个好的算法能够大量减少画师的工作。
现在公开给大家体验的算法主要有日本P站的“Paints Chainer”。它主要给大家提供了自动上色功能的体验,包含三种不同的风格, 这些就是自动上色的效果。
另一个就是国内苏州大学的zhang lvming 江湖人称 一喵,开发了style2paints,是目前上色效果最好的开源论文。最新情况是提供v4.5 版本下载。V4的效果是加入了光渲染模式,你们看这张图就是加入了光渲染模式的效果。

线稿上色,分为自动上色和基于用户的提示点上色两种。虽然自动上色看上去简单快捷,但是毕竟很多时候 ,算法上色并不会和你想要的完全一样,而让用户给出他想上色的提示颜色,并根据需求上色的提示点上色,是更加实用有效的做法。
早期上色最早使用的方法都是unet,对,就是那个适合做分割的网络,在医学领域应用特别多。 后来style2paints v3版本开始将上色分解为两个步骤,分别由两个GAN来完成,第一个步骤称为“草图阶段”(Drafting Stage),该阶段的上色不完全遵照线稿的分界线,是以相对随性的方式将色彩泼洒到画布上。该阶段的目的在于增加配色的丰富性。生成的草图可能包含较多的上色错误和模糊的纹理,但充满了丰富、鲜艳的配色。第二个阶段称为“精修阶段”(Refinement Stage),该阶段专注于修正细节问题,并将模糊的纹理清晰化,以得到最终的画作。而且作者表示“精修阶段”不仅可以修正自己算法生成的草图,还可用于修正其他深度上色网络(如:PaintsChainer)生成画作中的上色缺陷。通用性强。
V3界面如图 所示。首先,用户在线稿上添加少量“粗略颜色提示点”(draft hints,即图 7-A中的方块),以生成初始的草图;同时,软件会输出经过修正后的最终画作(图 7-C)。若用户对最终画作的一些上色细节不够满意,可在草图中逐步地添加“精确颜色提示点”(accurate hints,即图 7-B中的圆点),并实时预览最终画作的效果,直到获得满意的上色效果为止。
就像很多检测算法一样,将复杂的问题分解为更简单的子问题,能够提出更好的解决方案。
自动上色和提示点上色各有所长,style2paints v4 v4.5版本 提供了大量的自动配色方案,并辅助以提示点修改,并同时产生加入光线后期渲染的效果。完成一张画作上色的效率大大提高。

除了动漫上色,图像翻译领域研究的另外一个重点就是动漫背景图生成了。
自从风格转换算法出现之后,大家发现,原来不同风格的图像是可以相互转换的,出现了大量的研究。动漫风格作为大家喜爱的一种,研究者众多。效果的话,大家应该都被之前时光相册的新海诚风格刷过屏。
但是风格转换出来的图像可用于娱乐,却不一定适合生产。究其原因,漫画风是对现实的一种抽象,而不是添加纹理和边界线,需要从现实世界图像的复杂构造中高度简化
清华大学针对这个问题提出cartoon gan,他针对 新海诚 宫崎骏 等多种风格图像进行GAN学习,为了优化效果,他们在loss上特别加强了对边缘信息的考虑,保证清晰的边缘

虽然目前看到的效果,都不足以推动行业的变革,不过很多人还在这个方向继续研究,期待今年或者明年 能看到更好的图像转换效果。
图像翻译第三个好玩的方面是卡通人脸转换,人们总是对定制化充满了兴趣。能不能用人脸,生成最适合的漫画形象,一直也是大家想要探索的方面。
这种不成对图像训练,要从cyclegan 看起。 这是google的李嘉铭用cyclegan跑出来的效果。如果直接cyclegan生成人脸,很容易五官什么的有点不大对劲。或者和原图相似度并没那么高。如果用普通人脸,大家做的时候,往往有一个步骤,我开始去做stylegan人脸转换的实验中也使用了,有没有想起来,就是alignment,人脸校正,这样生成是不会有问题的。 那动漫人脸和普通人脸的一个区别就是,动漫人脸因为数据的原因很难进行alignment。于是将普通人脸的生成改成动漫的人脸的生成,可以在loss中考虑人脸特征点的关系,就能出比较好的效果,右上是贾佳亚老师和腾讯优图做的,右下是我之前尝试算法出一个结果,
2019,出了一个算法叫u-get-it加入了注意力机制,也达到了比较好的转换效果。

而超分辨率 其实动漫领域没啥好说的,因为有个算法waifu2x已经非常厉害了。

图像补全,则有算法DeepCreamy,使用的也是英伟达之前inpaint的算法。

应用方面除了GAN,其他也有一些好玩的方向
左上这是漫画图像内容分析,由于数据库里有大量标签,于是我们可以对图像进行内容分析,给定一张图像,有90%的几率是,女孩,一个人,穿着日式传统服饰,有80%的几率是有花,长头发,蓝眼睛等等
右上这张图是动漫人物识别,是爱奇艺做的,
这是线稿提取,P站做的,这是3D渲染2D技术,通过3D建模,然后渲染成2D效果,可以提高效率,让一些无比艰难的手绘2D可以快速成型

这个是一张图生成虚拟主播, 输出一张正面动漫人脸图像,就可以生成虚拟主播,这个成果极具期待性。

上传视频封面
好的标题可以获得更多的推荐及关注者
用AI助力动漫行业,改进生产工具,是一件非常有意义的事情。凡事技术先行,希望技术和产业能够更快结合,提高生产力。让大家都能看到更多更好精美的作品。
相关代码 网址 可以在 开源项目AlphaTree GAN的 动漫部分找到。
https://github.com/weslynn/AlphaTree-graphic-deep-neural-networkgithub.com
ppt 后续会提供下载地址。