Netflix Recommendations: Beyond the 5 stars (Part 1)

Netflix Technology BlogFollow
Apr 6, 2012 · 9 min read
by Xavier Amatriain and Justin Basilico (Personalization Science and Engineering)
In this two-part blog post, we will open the doors of one of the most valued Netflix assets: our recommendation system. In Part 1, we will relate the Netflix Prize to the broader recommendation challenge, outline the external components of our personalized service, and highlight how our task has evolved with the business. In Part 2, we will describe some of the data and models that we use and discuss our approach to algorithmic innovation that combines offline machine learning experimentation with online AB testing. Enjoy… and remember that we are always looking for more star talent to add to our great team, so please take a look at our jobs page.
在这个由两部分组成的博客文章中,我们将打开Netflix最有价值的资产之一:推荐系统。
在第1部分中,我们将讨论 推荐比赛Netflix Prize 和相关的获胜算法,概述我们个性化服务的外部组件,并强调我们的任务是如何随着业务发展而变化的。
在第2部分中,我们将描述一些我们使用的数据和模型,并讨论将离线机器学习实验与在线AB测试相结合的算法创新方法。并请记住,我们一直在寻找更多的明星人才来加入我们的优秀团队,所以请查看我们的工作页面。
The Netflix Prize and the Recommendation Problem Netflix Prize和推荐问题
In 2006 we announced the Netflix Prize, a machine learning and data mining competition for movie rating prediction. We offered $1 million to whoever improved the accuracy of our existing system called Cinematch by 10%. We conducted this competition to find new ways to improve the recommendations we provide to our members, which is a key part of our business. However, we had to come up with a proxy question that was easier to evaluate and quantify: the root mean squared error (RMSE) of the predicted rating. The race was on to beat our RMSE of 0.9525 with the finish line of reducing it to 0.8572 or less.
最早在2006年,Netflix举办了一个名叫Netflix Prize的比赛,用机器学习和数据挖掘来做电影评分预测的竞赛。我们提供了100万美元来作为奖金,如果有人可以把现在我们的系统Cinematch 的准确率提高10%。我们的目标是寻找新的方法来改进向会员提供的建议,这是我们业务的关键部分。我们提出一个指标来进行评估和量化:对预测的评分计算均方根误差(RMSE)。最优算法最终打破了我们的的记录,将0.9525的RMSE,降低到0.8572或更小
A year into the competition, the Korbell team won the first Progress Prize with an 8.43% improvement. They reported more than 2000 hours of work in order to come up with the final combination of 107 algorithms that gave them this prize. And, they gave us the source code. We looked at the two underlying algorithms with the best performance in the ensemble: Matrix Factorization (which the community generally called SVD, Singular Value Decomposition) and Restricted Boltzmann Machines (RBM). SVD by itself provided a 0.8914 RMSE, while RBM alone provided a competitive but slightly worse 0.8990 RMSE. A linear blend of these two reduced the error to 0.88. To put these algorithms to use, we had to work to overcome some limitations, for instance that they were built to handle 100 million ratings, instead of the more than 5 billion that we have, and that they were not built to adapt as members added more ratings. But once we overcame those challenges, we put the two algorithms into production, where they are still used as part of our recommendation engine.
参加比赛的第一年,Korbell团队以8.43%的提升赢得了第一名的进步奖。他们报告了2000多个小时的工作,以便最终得出107个算法的组合,从而获得了该奖项。并且,他们给了我们源代码。我们研究了整体中性能最佳的两种基础算法:Matrix Factorization矩阵分解(社区通常将其称为SVD,奇异值分解)和受限玻尔兹曼机(RBM)。SVD本身提供了0.8914 RMSE,而RBM本身提供了竞争性但略差的0.8990 RMSE。这两者的线性混合将误差降低至0.88。为了使用这些算法,我们必须努力克服一些局限性,例如,它们被构建为可处理1亿个评级,而不是我们拥有的50亿以上,并且其构建不适应成员的添加更多评分。但是,一旦克服了这些挑战,便可以将这两种算法投入生产,它们被用作推荐引擎的一部分。
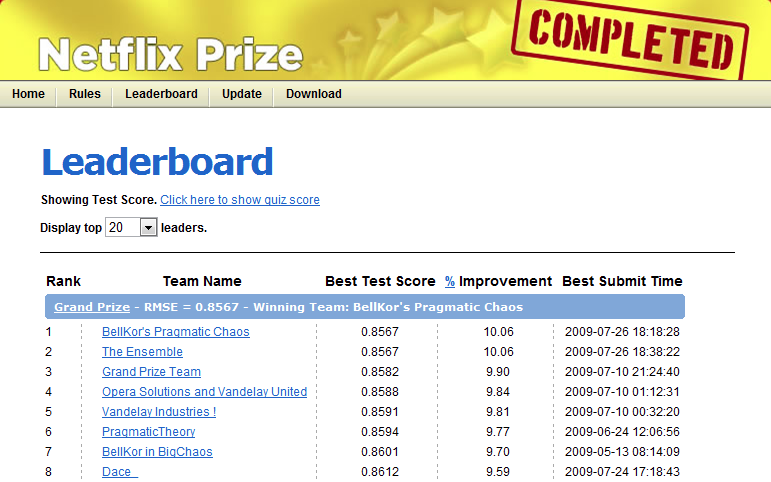
If you followed the Prize competition, you might be wondering what happened with the final Grand Prize ensemble that won the $1M two years later. This is a truly impressive compilation and culmination of years of work, blending hundreds of predictive models to finally cross the finish line. We evaluated some of the new methods offline but the additional accuracy gains that we measured did not seem to justify the engineering effort needed to bring them into a production environment. Also, our focus on improving Netflix personalization had shifted to the next level by then. In the remainder of this post we will explain how and why it has shifted.
如果继续跟踪竞赛发展,您可能会想知道两年后赢得100万美元奖金的最终大奖是什么算法。这是非常令人印象深刻的工作,它融合了数百种预测模型,最终跨越了终点线。我们离线评估了一些新方法,但是我们测得的额外的准确性提高似乎不足以证明将应该将它们引入生产环境。此外,到那时,我们对改善Netflix个性化的关注已转移到一个新的水平。在本文的其余部分中,我们将说明其变化方式和原因。
From US DVDs to Global Streaming 从美国DVD到全球流媒体
One of the reasons our focus in the recommendation algorithms has changed is because Netflix as a whole has changed dramatically in the last few years. Netflix launched an instant streaming service in 2007, one year after the Netflix Prize began. Streaming has not only changed the way our members interact with the service, but also the type of data available to use in our algorithms. For DVDs our goal is to help people fill their queue with titles to receive in the mail over the coming days and weeks; selection is distant in time from viewing, people select carefully because exchanging a DVD for another takes more than a day, and we get no feedback during viewing. For streaming members are looking for something great to watch right now; they can sample a few videos before settling on one, they can consume several in one session, and we can observe viewing statistics such as whether a video was watched fully or only partially.
我们对推荐算法的关注发生了变化的原因之一是因为Netflix在过去几年中整体发生了巨大变化。Netflix奖开始一年后的2007年,Netflix推出了即时流媒体服务。流不仅改变了我们的成员与服务交互的方式,而且改变了可用于我们的算法的数据类型。对于DVD,我们的目标是帮助人们在接下来的几天和几周内将标题接收到他们的队列中;选择的时间与观看时间相距遥远,人们进行了仔细的选择,因为将DVD换成另一盘需要一天以上的时间,并且在观看过程中我们没有任何反馈。对于流媒体会员来说,他们正在寻找一些值得关注的东西。他们可以先预览一些视频,然后再选择一个,在一个会话中会看好几个视频。
Another big change was the move from a single website into hundreds of devices. The integration with the Roku player and the Xbox were announced in 2008, two years into the Netflix competition. Just a year later, Netflix streaming made it into the iPhone. Now it is available on a multitude of devices that go from a myriad of Android devices to the latest AppleTV.
另一个重大变化是从单个网站迁移到数百个设备。与Roku播放器和Xbox的集成于2008年宣布,距Netflix竞赛已经两年了。仅仅一年之后,Netflix的流媒体就将其应用到了iPhone中。现在,它可以在从无数的Android设备到最新的AppleTV的众多设备上使用。
Two years ago, we went international with the launch in Canada. In 2011, we added 43 Latin-American countries and territories to the list. And just recently, we launched in UK and Ireland. Today, Netflix has more than 23 million subscribers in 47 countries. Those subscribers streamed 2 billion hours from hundreds of different devices in the last quarter of 2011. Every day they add 2 million movies and TV shows to the queue and generate 4 million ratings.
两年前,我们通过在加拿大的发布而走向国际。2011年,我们将43个拉丁美洲国家和地区添加到了列表中。就在最近,我们在英国和爱尔兰推出了产品。如今,Netflix在47个国家/地区拥有2300万订户。这些订户在2011年最后一个季度从数百种不同的设备中流式传输了20亿小时的节目。每天,他们将200万部电影和电视节目添加到队列中,并产生400万个收视率。
We have adapted our personalization algorithms to this new scenario in such a way that now 75% of what people watch is from some sort of recommendation. We reached this point by continuously optimizing the member experience and have measured significant gains in member satisfaction whenever we improved the personalization for our members. Let us now walk you through some of the techniques and approaches that we use to produce these recommendations.
我们已经针对这种新情况调整了个性化算法,以使现在人们观看的内容中有75%来自某种推荐。我们通过不断优化会员体验达到了这一点,并在改善会员的个性化水平时测得会员满意度的显着提高。现在让我们为您介绍一些用于产生这些建议的技术和方法。
Everything is a Recommendation 万事皆推荐
We have discovered through the years that there is tremendous value to our subscribers in incorporating recommendations to personalize as much of Netflix as possible. Personalization starts on our homepage, which consists of groups of videos arranged in horizontal rows. Each row has a title that conveys the intended meaningful connection between the videos in that group. Most of our personalization is based on the way we select rows, how we determine what items to include in them, and in what order to place those items.
我们发现我们记录了用户这些年的订阅,可以使Netflix个性化推荐具有巨大价值。个性化从我们的首页开始,该首页由水平排列的视频组组成。每行都有一个标题,传达了该组视频之间预期的有意义的联系。我们的大多数个性化设置基于我们选择行的方式,我们如何确定要包括在其中的项目以及以什么顺序放置这些项目。
Take as a first example the Top 10 row: this is our best guess at the ten titles you are most likely to enjoy. Of course, when we say “you”, we really mean everyone in your household. It is important to keep in mind that Netflix’ personalization is intended to handle a household that is likely to have different people with different tastes. That is why when you see your Top10, you are likely to discover items for dad, mom, the kids, or the whole family. Even for a single person household we want to appeal to your range of interests and moods. To achieve this, in many parts of our system we are not only optimizing for accuracy, but also for diversity.
首先举一个排在前10名的书:这是我们对您最可能喜欢的十个书名的最佳猜测。当然,当我们说“您”时,我们实际上是指您家中的每个人。重要的是要记住,Netflix的个性化旨在处理可能有不同口味的不同人的家庭。这就是为什么当您看到Top10时,您可能会发现爸爸,妈妈,孩子或整个家庭的物品的原因。即使对于单身家庭,我们也希望吸引您的兴趣爱好和心情。为了实现这一点,在我们系统的许多部分中,我们不仅针对准确性进行了优化,而且还针对多样性进行了优化。

=Another important element in Netflix’ personalization is ==awareness==. We want members to be aware of how we are adapting to their tastes. This not only promotes trust in the system, but encourages members to give feedback that will result in better recommendations.= A different way of promoting trust with the personalization component is to provide **explanations** as to why we decide to recommend a given movie or show. We are not recommending it because it suits our business needs, but because it matches the information we have from you: your explicit taste preferences and ratings, your viewing history, or even your friends’ recommendations.
=Netflix个性化的另一个重要元素是 ==意识==。我们希望成员意识到我们如何适应他们的口味。这不仅可以增强对系统的信任,还可以鼓励成员提供反馈,从而产生更好的建议。=通过个性化组件提高信任度的另一种方法是提供**有关**为什么我们决定推荐给定电影或节目的解释。我们不建议您使用它,因为它适合我们的业务需求,但是因为它与我们从您那里获得的信息相匹配:您明确的口味偏好和评分,您的观看记录,甚至是您朋友的推荐。
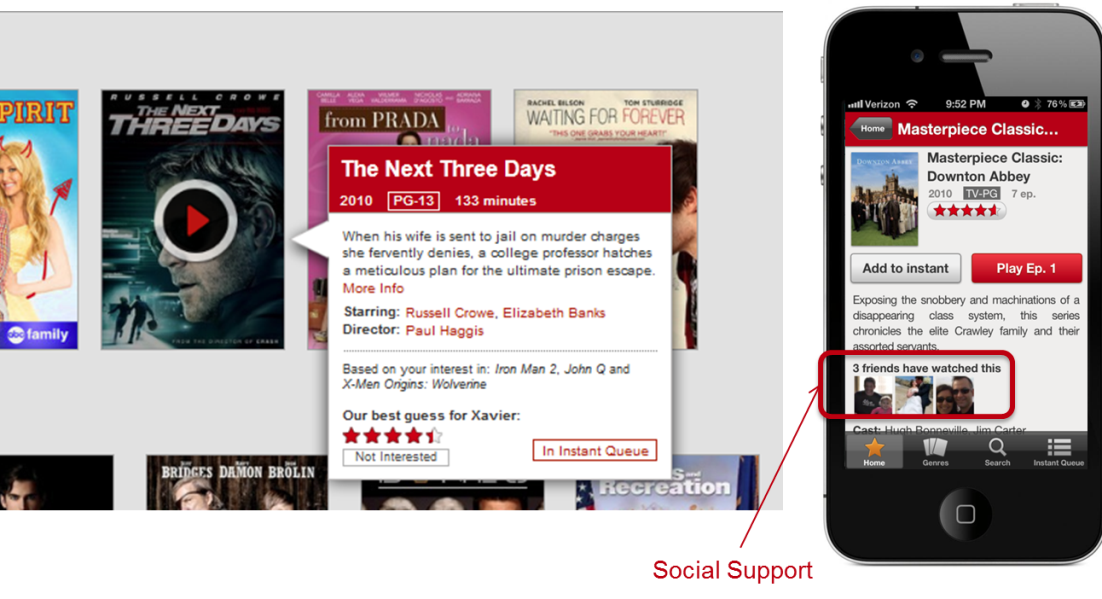
On the topic of friends, we recently released our Facebook connect feature in 46 out of the 47 countries we operate — all but the US because of concerns with the VPPA law. Knowing about your friends not only gives us another signal to use in our personalization algorithms, but it also allows for different rows that rely mostly on your social circle to generate recommendations.
关于朋友的话题,我们最近在我们运营的47个国家中的46个国家/地区中的46个国家/地区发布了Facebook连接功能-由于对VPPA法的担忧,除美国以外的所有国家/地区。了解您的朋友不仅为我们提供了在我们的个性化算法中使用的另一种信号,而且还允许主要依靠您的社交圈的不同行生成推荐。

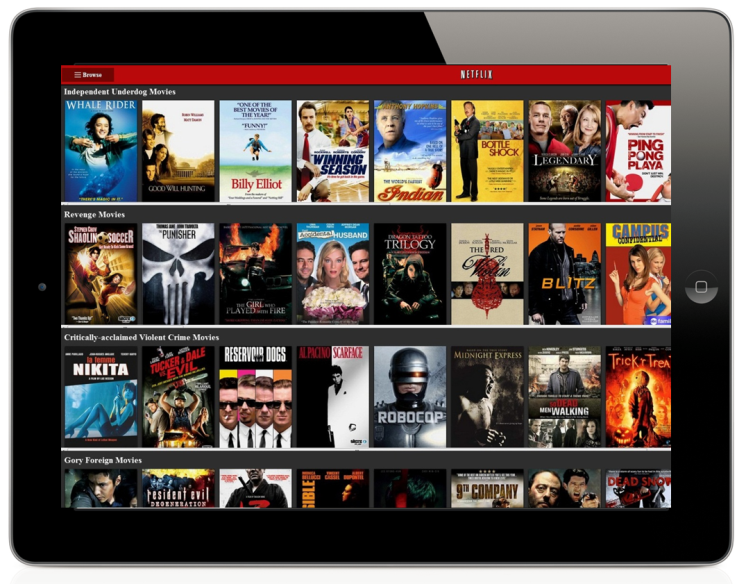
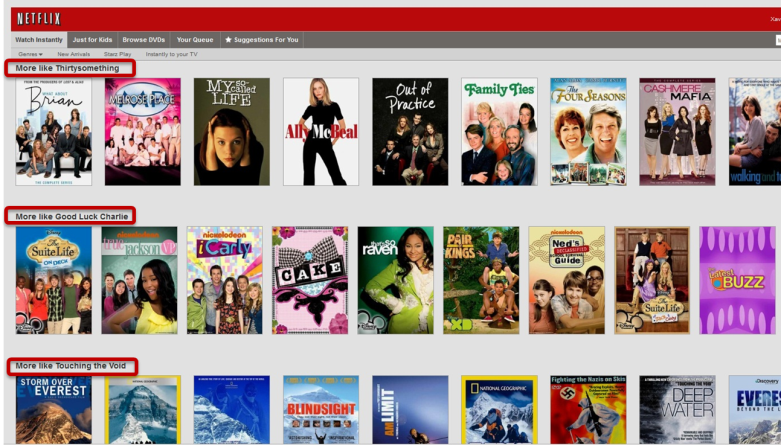
Some of the most recognizable personalization in our service is the collection of “genre” rows. These range from familiar high-level categories like “Comedies” and “Dramas” to highly tailored slices such as “Imaginative Time Travel Movies from the 1980s”. Each row represents 3 layers of personalization: the choice of genre itself, the subset of titles selected within that genre, and the ranking of those titles. Members connect with these rows so well that we measure an increase in member retention by placing the most tailored rows higher on the page instead of lower. As with other personalization elements, freshness and diversity is taken into account when deciding what genres to show from the thousands possible.
在我们的服务中,一些最知名的个性化设置是“genre”行的集合。这些范围从熟悉的高级类别(如“喜剧”和“戏剧”)到高度定制的片段,如“ 1980年代的富有想象力的时空旅行电影”。每行代表3层个性化:类型本身的选择,在该类型中选择的标题子集以及这些标题的排名。成员与这些行的连接非常好,以至于我们通过将最适合的行放在页面的上方而不是较低的位置来衡量成员保留的增加。与其他个性化元素一样,在决定从数千种可能显示的类型中选择时要考虑新鲜度和多样性。
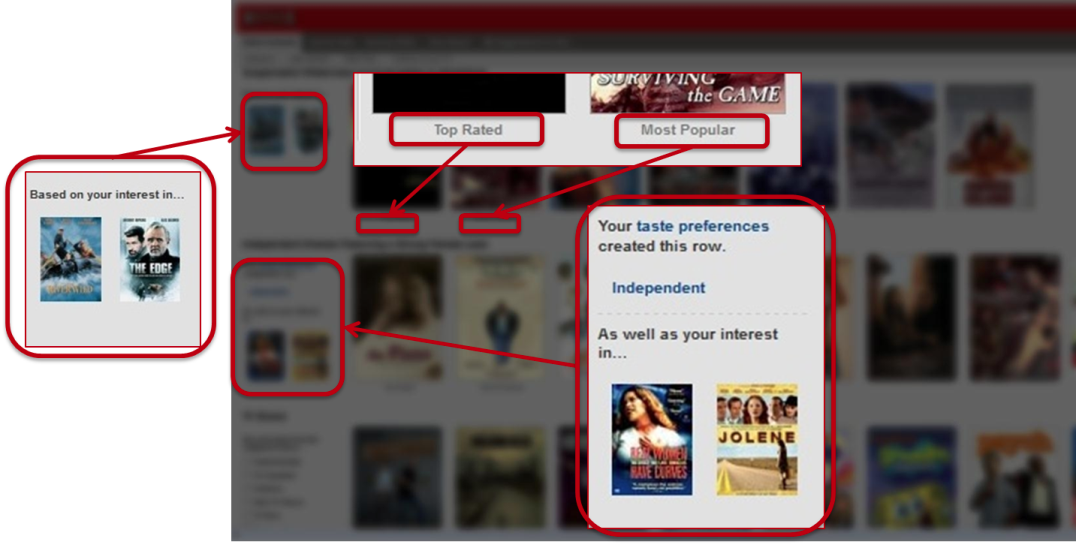
We present an explanation for the choice of rows using a member’s implicit genre preferences — recent plays, ratings, and other interactions — , or explicit feedback provided through our taste preferences survey. We will also invite members to focus a row with additional explicit preference feedback when this is lacking.
我们使用会员的隐式流派偏好(最近的演出,评分和其他互动)或通过我们的喜好偏好调查提供的显式反馈,为行的选择提供了解释。如果缺少,我们还将邀请成员将重点放在一行上,并提供其他明确的偏好反馈。
Similarity is also an important source of personalization in our service. We think of similarity in a very broad sense; it can be between movies or between members, and can be in multiple dimensions such as metadata, ratings, or viewing data. Furthermore, these similarities can be blended and used as features in other models. Similarity is used in multiple contexts, for example in response to a member’s action such as searching or adding a title to the queue. It is also used to generate rows of “adhoc genres” based on similarity to titles that a member has interacted with recently. If you are interested in a more in-depth description of the architecture of the similarity system, you can read about it in this past post on the blog.
相似性也是我们服务中个性化的重要来源。我们从广泛的意义上考虑相似性。它可以在电影之间或在成员之间,并且可以在多个维度上使用,例如元数据,评分或观看数据。此外,可以将这些相似性融合在一起并用作其他模型中的特征。在多个上下文中使用相似性,例如,响应于成员的动作(例如,搜索队列或向队列添加标题)。它也用于基于与成员最近与之交互的标题的相似性来生成“特殊类型”的行。如果您对相似性系统的体系结构有更深入的描述感兴趣,可以在博客的上一篇文章中阅读。
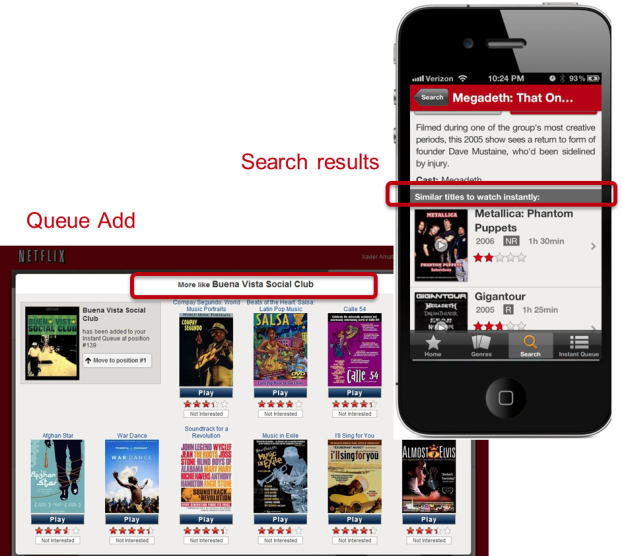
In most of the previous contexts — be it in the Top10 row, the genres, or the similars — ranking, the choice of what order to place the items in a row, is critical in providing an effective personalized experience. The goal of our ranking system is to find the best possible ordering of a set of items for a member, within a specific context, in real-time. We decompose ranking into scoring, sorting, and filtering sets of movies for presentation to a member. Our business objective is to maximize member satisfaction and month-to-month subscription retention, which correlates well with maximizing consumption of video content. We therefore optimize our algorithms to give the highest scores to titles that a member is most likely to play and enjoy.
在以前的大多数情况下(无论是在Top10行中,在流派中还是在类似情况中),对于提供有效的个性化体验而言,排名(选择将项连续放置的顺序)都是至关重要的。我们的排名系统的目标是在特定的上下文中实时找到成员的一组商品的最佳排序。我们将排名分解为对电影集进行评分,排序和过滤,以呈现给成员。我们的业务目标是最大程度地提高会员满意度和按月订阅保留率,这与最大限度地提高视频内容的消费量密切相关。因此,我们优化了算法,为会员最有可能玩和喜欢的游戏打出最高分。
Now it is clear that the Netflix Prize objective, accurate prediction of a movie’s rating, is just one of the many components of an effective recommendation system that optimizes our members enjoyment. We also need to take into account factors such as context, title popularity, interest, evidence, novelty, diversity, and freshness. Supporting all the different contexts in which we want to make recommendations requires a range of algorithms that are tuned to the needs of those contexts. In the next part of this post, we will talk in more detail about the ranking problem. We will also dive into the data and models that make all the above possible and discuss our approach to innovating in this space.
现在很明显,Netflix奖的目标,即准确预测电影的收视率,只是有效推荐系统中众多组件的其中之一,它可以优化会员的娱乐体验。我们还需要考虑诸如背景,标题受欢迎程度,兴趣,证据,新颖性,多样性和新鲜度等因素。要支持我们要提出建议的所有不同上下文,需要一系列适合这些上下文需求的算法。在本文的下一部分,我们将更详细地讨论排名问题。我们还将深入研究使上述所有可能性变为可能的数据和模型,并讨论我们在该领域进行创新的方法。
Netflix Recommendations: Beyond the 5 stars (Part 2)
Netflix Technology BlogFollow
Jun 20, 2012 · 10 min read
by Xavier Amatriain and Justin Basilico (Personalization Science and Engineering)
In part one of this blog post, we detailed the different components of Netflix personalization. We also explained how Netflix personalization, and the service as a whole, have changed from the time we announced the Netflix Prize.
[## Netflix Recommendations: Beyond the 5 stars (Part 1)
One of the most valued Netflix assets is our recommendation system
medium.com
](https://medium.com/@Netflix_Techblog/netflix-recommendations-beyond-the-5-stars-part-1-55838468f429)
The $1M Prize delivered a great return on investment for us, not only in algorithmic innovation, but also in brand awareness and attracting stars (no pun intended) to join our team. Predicting movie ratings accurately is just one aspect of our world-class recommender system. In this second part of the blog post, we will give more insight into our broader personalization technology. We will discuss some of our current models, data, and the approaches we follow to lead innovation and research in this space.
在第一部分这篇博客中,我们详细Netflix的个性化的不同组件。我们还解释了自宣布Netflix Price之日起,Netflix的个性化以及整个服务的变化。
Ranking
The goal of recommender systems is to present a number of attractive items for a person to choose from. This is usually accomplished by selecting some items and sorting them in the order of expected enjoyment (or utility). Since the most common way of presenting recommended items is in some form of list, such as the various rows on Netflix, we need an appropriate ranking model that can use a wide variety of information to come up with an optimal ranking of the items for each of our members.
推荐系统的目标是呈现许多吸引人的项目供个人选择。这通常是通过选择一些项目并按预期享受(或效用)的顺序对它们进行排序来完成的。由于推荐项目的最常见呈现方式是某种形式的列表,例如Netflix上的各个行,因此我们需要一个合适的排名模型,该模型可以使用各种信息来为每个项目提供最佳的排名我们的成员。
=If you are looking for a ranking function that optimizes consumption, an obvious baseline is item popularity. The reason is clear: on average, a member is most likely to watch what most others are watching. However, popularity is the opposite of personalization: it will produce the same ordering of items for every member. Thus, the goal becomes to find a personalized ranking function that is better than item popularity, so we can better satisfy members with varying tastes.=
=如果您正在寻找优化消费的排名功能,则显而易见的基线是商品受欢迎程度。原因很明确:平均而言,成员最有可能观看大多数其他成员正在观看的内容。但是,受欢迎程度与个性化相反:它将为每个成员产生相同的项目排序。因此,目标是找到一种比商品受欢迎程度更好的个性化排名功能,以便我们更好地满足口味不同的会员的需求。=
Recall that our goal is to recommend the titles that each member is most likely to play and enjoy. One obvious way to approach this is to use the member’s predicted rating of each item as an adjunct to item popularity. Using predicted ratings on their own as a ranking function can lead to items that are too niche or unfamiliar being recommended, and can exclude items that the member would want to watch even though they may not rate them highly. To compensate for this, rather than using either popularity or predicted rating on their own, we would like to produce rankings that balance both of these aspects. At this point, we are ready to build a ranking prediction model using these two features.
回想一下,我们的目标是推荐每个成员最有可能玩和喜欢的游戏。解决此问题的一种显而易见的方法是使用会员对每个商品的预测评分作为商品受欢迎程度的辅助手段。单独使用预测的收视率作为排名功能可能会导致推荐的商品过于小众或不熟悉,并且会排除会员想要观看的商品,即使它们可能未对它们进行高评价。为了弥补这一点,我们不希望自己单独使用流行度或预测评分,而是希望在两者之间取得平衡。至此,我们准备使用这两个功能构建排名预测模型。
There are many ways one could construct a ranking function ranging from simple scoring methods, to pairwise preferences, to optimization over the entire ranking. For the purposes of illustration, let us start with a very simple scoring approach by choosing our ranking function to be a linear combination of popularity and predicted rating. This gives an equation of the form frank(u,v) = w1 p(v) + w2 r(u,v) + b, where u=user, v=video item, p=popularity and r=predicted rating. This equation defines a two-dimensional space like the one depicted below.
构造排名函数的方法有很多种,从简单的评分方法到成对的偏好,再到整个排名的优化。为了说明的目的,让我们从一个非常简单的评分方法开始,将我们的排名函数选择为受欢迎程度和预测评分的线性组合。这给出了形式为frank(u,v)= w1 p(v)+ w2 r(u,v)+ b的方程式,其中u =用户,v =视频项,p =人气,r =预测的收视率。此方程式定义了一个二维空间,如下图所示。
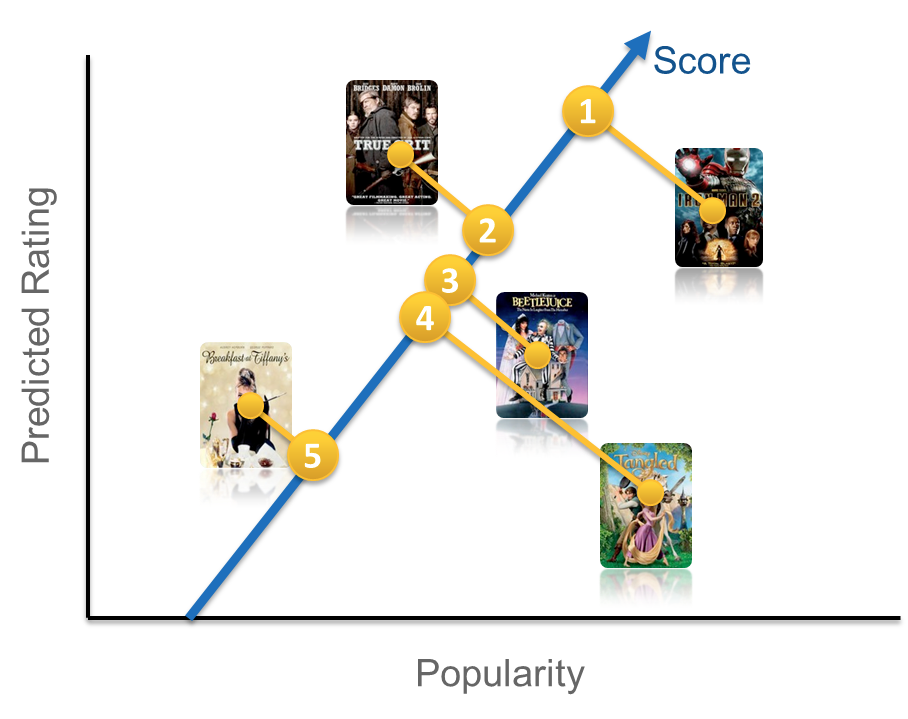
Once we have such a function, we can pass a set of videos through our function and sort them in descending order according to the score. You might be wondering how we can set the weights w1 and w2 in our model (the bias b is constant and thus ends up not affecting the final ordering). In other words, in our simple two-dimensional model, how do we determine whether popularity is more or less important than predicted rating? There are at least two possible approaches to this. You could sample the space of possible weights and let the members decide what makes sense after many A/B tests. This procedure might be time consuming and not very cost effective. Another possible answer involves formulating this as a machine learning problem: select positive and negative examples from your historical data and let a machine learning algorithm learn the weights that optimize your goal. This family of machine learning problems is known as “Learning to rank” and is central to application scenarios such as search engines or ad targeting. Note though that a crucial difference in the case of ranked recommendations is the importance of personalization: we do not expect a global notion of relevance, but rather look for ways of optimizing a personalized model.
一旦有了这样的功能,我们就可以通过我们的功能传递一组视频,并根据得分以降序对它们进行排序。您可能想知道我们如何在模型中设置权重w1和w2(偏差b是常数,因此最终不影响最终排序)。换句话说,在我们简单的二维模型中,我们如何确定受欢迎程度是否比预测收视率重要?至少有两种可能的方法。您可以在可能的权重空间中进行抽样,并让成员在进行多次A / B测试后决定什么才有意义。此过程可能很耗时,并且成本效益不高。另一个可能的答案涉及将其表述为机器学习问题:从历史数据中选择正面和负面的例子,然后让机器学习算法学习可以优化目标的权重。这一系列的机器学习问题被称为““学习排名”是应用场景(例如搜索引擎或广告定位)的核心。请注意,尽管排名建议之间的关键区别在于个性化的重要性:我们不期望全局相关性,而是寻找优化个性化模型的方法。
As you might guess, apart from popularity and rating prediction, we have tried many other features at Netflix. Some have shown no positive effect while others have improved our ranking accuracy tremendously. The graph below shows the ranking improvement we have obtained by adding different features and optimizing the machine learning algorithm.
您可能会猜到,除了受欢迎程度和收视率预测之外,我们还尝试了Netflix的许多其他功能。一些没有显示出积极的影响,而另一些则极大地提高了我们的排名准确性。下图显示了我们通过添加不同的功能并优化了机器学习算法而获得的排名改进。
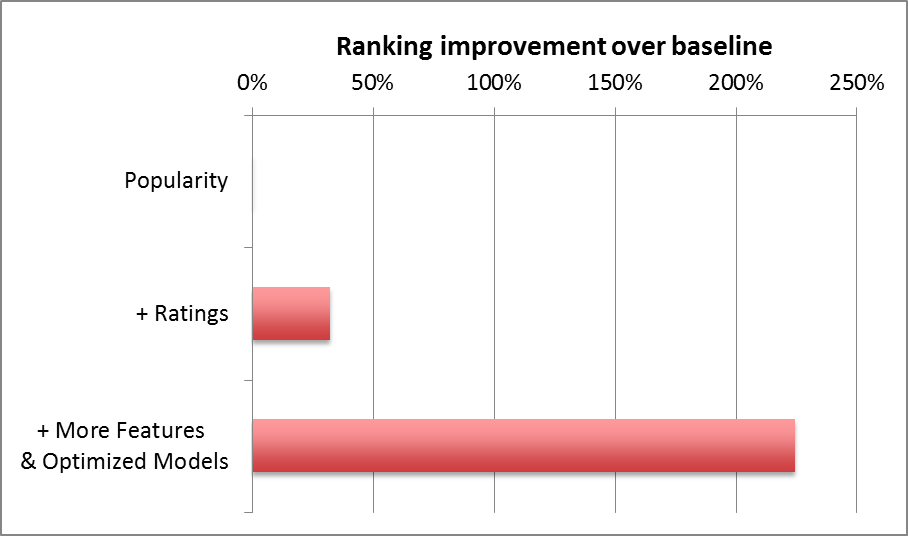
Many supervised classification methods can be used for ranking. Typical choices include Logistic Regression, Support Vector Machines, Neural Networks, or Decision Tree-based methods such as Gradient Boosted Decision Trees (GBDT). On the other hand, a great number of algorithms specifically designed for learning to rank have appeared in recent years such as RankSVM or RankBoost. There is no easy answer to choose which model will perform best in a given ranking problem. The simpler your feature space is, the simpler your model can be. But it is easy to get trapped in a situation where a new feature does not show value because the model cannot learn it. Or, the other way around, to conclude that a more powerful model is not useful simply because you don’t have the feature space that exploits its benefits.
可以使用许多监督分类方法进行排名。典型的选择包括Logistic回归,支持向量机,神经网络或基于决策树的方法,例如梯度增强决策树(GBDT)。另一方面,近年来出现了许多专门为学习排名而设计的算法,例如RankSVM或RankBoost。没有简单的答案来选择哪种模型在给定的排名问题中表现最佳。特征空间越简单,模型就越简单。但是很容易陷入因模型无法学习而无法显示新功能价值的情况。或者,反过来,得出结论,认为功能更强大的模型没有用,仅仅是因为您没有利用其优势的特征空间而得出的结论。

Data and Models 数据与模型
The previous discussion on the ranking algorithms highlights the importance of both data and models in creating an optimal personalized experience for our members. At Netflix, we are fortunate to have many relevant data sources and smart people who can select optimal algorithms to turn data into product features. Here are some of the data sources we can use to optimize our recommendations:
先前有关排名算法的讨论强调了数据和模型对于为我们的会员创建最佳个性化体验的重要性。在Netflix,我们很幸运有许多相关的数据源和聪明的人,他们可以选择最佳算法将数据转换为产品功能。以下是一些我们可以用来优化建议的数据源:
- We have several billion item ratings from members. And we receive millions of new ratings a day.
- We already mentioned item popularity as a baseline. But, there are many ways to compute popularity. We can compute it over various time ranges, for instance hourly, daily, or weekly. Or, we can group members by region or other similarity metrics and compute popularity within that group.
- We receive several million stream plays each day, which include context such as duration, time of day and device type.
- Our members add millions of items to their queues each day.
- Each item in our catalog has rich metadata: actors, director, genre, parental rating, and reviews.
- Presentations: We know what items we have recommended and where we have shown them, and can look at how that decision has affected the member’s actions. We can also observe the member’s interactions with the recommendations: scrolls, mouse-overs, clicks, or the time spent on a given page.
- Social data has become our latest source of personalization features; we can process what connected friends have watched or rated.
- Our members directly enter millions of search terms in the Netflix service each day.
- All the data we have mentioned above comes from internal sources. We can also tap into external data to improve our features. For example, we can add external item data features such as box office performance or critic reviews.
- Of course, that is not all: there are many other features such as demographics, location, language, or temporal data that can be used in our predictive models.
- 我们有来自会员的数十亿个项目评分。我们每天都会收到数百万个新的评分。
- 我们已经提到了商品受欢迎程度作为基准。但是,有许多方法可以计算受欢迎程度。我们可以在不同的时间范围内进行计算,例如每小时,每天或每周。或者,我们可以按地区或其他相似性指标对成员进行分组,然后计算该组中的受欢迎程度。
- 我们每天收到数百万个流播放,其中包括持续时间,一天中的时间和设备类型等上下文。
- 我们的成员每天将数百万个商品添加到他们的队列中。
- 目录中的每个项目都有丰富的元数据:演员,导演,体裁,父母评分和评论。
- 演示文稿:我们知道我们推荐了哪些项目以及在哪里显示了它们,并且可以查看该决定如何影响成员的行为。我们还可以观察成员与以下建议的互动:滚动,鼠标悬停,点击或在给定页面上花费的时间。
- 社交数据已成为我们最新的个性化功能来源;我们可以处理连接的朋友观看或评价的内容。
- 我们的成员每天都在Netflix服务中直接输入数百万个搜索词。
- 我们上面提到的所有数据均来自内部来源。我们还可以利用外部数据来改善我们的功能。例如,我们可以添加外部项目数据功能,例如票房表现或评论家评论。
- 当然,还不止这些:我们的预测模型还可以使用许多其他功能,例如人口统计,位置,语言或时间数据。
So, what about the models? One thing we have found at Netflix is that with the great availability of data, both in quantity and types, a thoughtful approach is required to model selection, training, and testing. We use all sorts of machine learning approaches: From unsupervised methods such as clustering algorithms to a number of supervised classifiers that have shown optimal results in various contexts. This is an incomplete list of methods you should probably know about if you are working in machine learning for personalization:
那么,模型呢?我们在Netflix上发现的一件事是,由于数量和类型的数据都非常丰富,因此需要一种周到的方法来进行模型选择,培训和测试。我们使用各种机器学习方法:从诸如聚类算法之类的无监督方法,到在各种情况下均显示最佳结果的许多有监督分类器。如果您正在为个性化而在机器学习中工作,这可能是您应该知道的方法的不完整列表:
- Linear regression
- Logistic regression
- Elastic nets
- Singular Value Decomposition
- Restricted Boltzmann Machines
- Markov Chains
- Latent Dirichlet Allocation
- Association Rules
- Gradient Boosted Decision Trees
- Random Forests
- Clustering techniques from the simple k-means to novel graphical approaches such as Affinity Propagation
- Matrix factorization
- 线性回归
- 逻辑回归
- 弹力网
- 奇异值分解
- 受限玻尔兹曼机
- 马尔可夫链
- 潜在狄利克雷分配
- 关联规则
- 梯度提升决策树
- 随机森林
- 从简单的k均值到新颖的图形方法(如亲和力传播)的聚类技术
- 矩阵分解
Consumer Data Science 消费者数据科学
The abundance of source data, measurements and associated experiments allow us to operate a data-driven organization. Netflix has embedded this approach into its culture since the company was founded, and we have come to call it Consumer (Data) Science. Broadly speaking, the main goal of our Consumer Science approach is to innovate for members effectively. The only real failure is the failure to innovate; or as Thomas Watson Sr, founder of IBM, put it: “If you want to increase your success rate, double your failure rate.” We strive for an innovation culture that allows us to evaluate ideas rapidly, inexpensively, and objectively. And, once we test something we want to understand why it failed or succeeded. This lets us focus on the central goal of improving our service for our members.
大量的源数据,测量结果和相关实验使我们能够运营数据驱动的组织。自公司成立以来,Netflix就将这种方法嵌入其文化中,我们将其称为“消费者(数据)科学”。从广义上讲,我们的消费者科学方法的主要目标是有效地为会员进行创新。唯一真正的失败是创新的失败。或就像IBM创始人Thomas Watson Sr所说的那样:“如果要提高成功率,则将失败率提高一倍。”我们努力营造一种创新文化,使我们能够快速,廉价且客观地评估想法。而且,一旦我们测试了某些东西,我们就想了解它失败或成功的原因。这使我们能够专注于改善为会员提供服务的中心目标。
So, how does this work in practice? It is a slight variation over the traditional scientific process called A/B testing (or bucket testing):
那么,这在实践中如何运作?它与称为A / B测试(或存储桶测试)的传统科学过程略有不同:
1. Start with a hypothesis 从一个假设开始
- Algorithm/feature/design X will increase member engagement with our service and ultimately member retention
算法/功能/设计X将增加会员对我们服务的参与度,并最终增加会员保留率
2. Design a test ## 设计测试
- Develop a solution or prototype. Ideal execution can be 2X as effective as a prototype, but not 10X. 开发解决方案或原型。理想的执行效率可以是原型的2倍,但不能达到10倍。
- Think about dependent & independent variables, control, significance… 虑因变量和自变量,控制权,重要性...
3. Execute the test ## 执行测试
4. Let data speak for itself
When we execute A/B tests, we track many different metrics. But we ultimately trust member engagement (e.g. hours of play) and retention. Tests usually have thousands of members and anywhere from 2 to 20 cells exploring variations of a base idea. We typically have scores of A/B tests running in parallel. A/B tests let us try radical ideas or test many approaches at the same time, but the key advantage is that they allow our decisions to be data-driven. You can read more about our approach to A/B Testing in this previous tech blog post or in some of the Quora answers by our Chief Product Officer Neil Hunt.
## How We Determine Product Success
在执行A / B测试时,我们会跟踪许多不同的指标。但是我们最终相信成员的参与度(例如游戏时间)和保留率。测试通常有成千上万的成员,从2到20个单元中的任何位置,探索基本概念的变化。通常,我们有数十个并行运行的A / B测试。A / B测试让我们可以尝试激进的想法或同时测试许多方法,但主要优点是它们使我们的决策可以由数据驱动。您可以在此以前的技术博客文章中或在我们的首席产品官Neil Hunt的一些Quora回答中了解有关我们A / B测试方法的更多信息。
An interesting follow-up question that we have faced is how to integrate our machine learning approaches into this data-driven A/B test culture at Netflix. We have done this with an offline-online testing process that tries to combine the best of both worlds. The offline testing cycle is a step where we test and optimize our algorithms prior to performing online A/B testing. To measure model performance offline we track multiple metrics used in the machine learning community: from ranking measures such as normalized discounted cumulative gain, mean reciprocal rank, or fraction of concordant pairs, to classification metrics such as accuracy, precision, recall, or F-score. We also use the famous RMSE from the Netflix Prize or other more exotic metrics to track different aspects like diversity. We keep track of how well those metrics correlate to measurable online gains in our A/B tests. However, since the mapping is not perfect, offline performance is used only as an indication to make informed decisions on follow up tests.
我们面临的一个有趣的后续问题是如何将我们的机器学习方法整合到Netflix的这种数据驱动的A / B测试文化中。我们通过脱机在线测试过程来做到这一点,该过程试图结合两个方面的优势。离线测试周期是我们在执行在线A / B测试之前测试和优化算法的步骤。为了离线测量模型性能,我们跟踪了机器学习社区中使用的多个指标:从排名指标(例如归一化折现累积收益,平均倒数排名或一致对的分数)到分类指标(例如准确性,精度,召回率或F分数。我们还使用Netflix奖中著名的RMSE或其他更奇特的方法跟踪诸如多样性等不同方面的指标。我们会在A / B测试中跟踪这些指标与可衡量的在线收益的相关程度。但是,由于映射不是完美的,因此脱机性能仅用作对后续测试做出明智决策的指示。

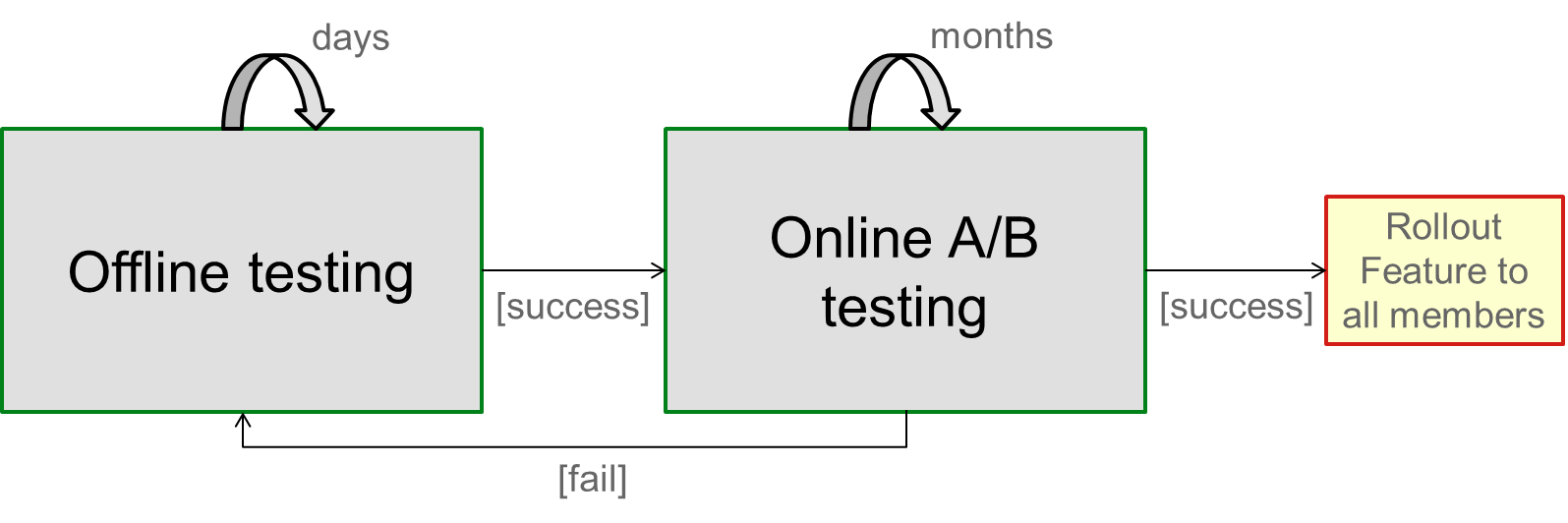
Once offline testing has validated a hypothesis, we are ready to design and launch the A/B test that will prove the new feature valid from a member perspective. If it does, we will be ready to roll out in our continuous pursuit of the better product for our members. The diagram below illustrates the details of this process.
一旦离线测试验证了假设,我们就可以设计并启动A / B测试,该测试将从成员角度证明新功能有效。如果是这样,我们将准备继续为我们的会员不断追求更好的产品。下图说明了此过程的详细信息。

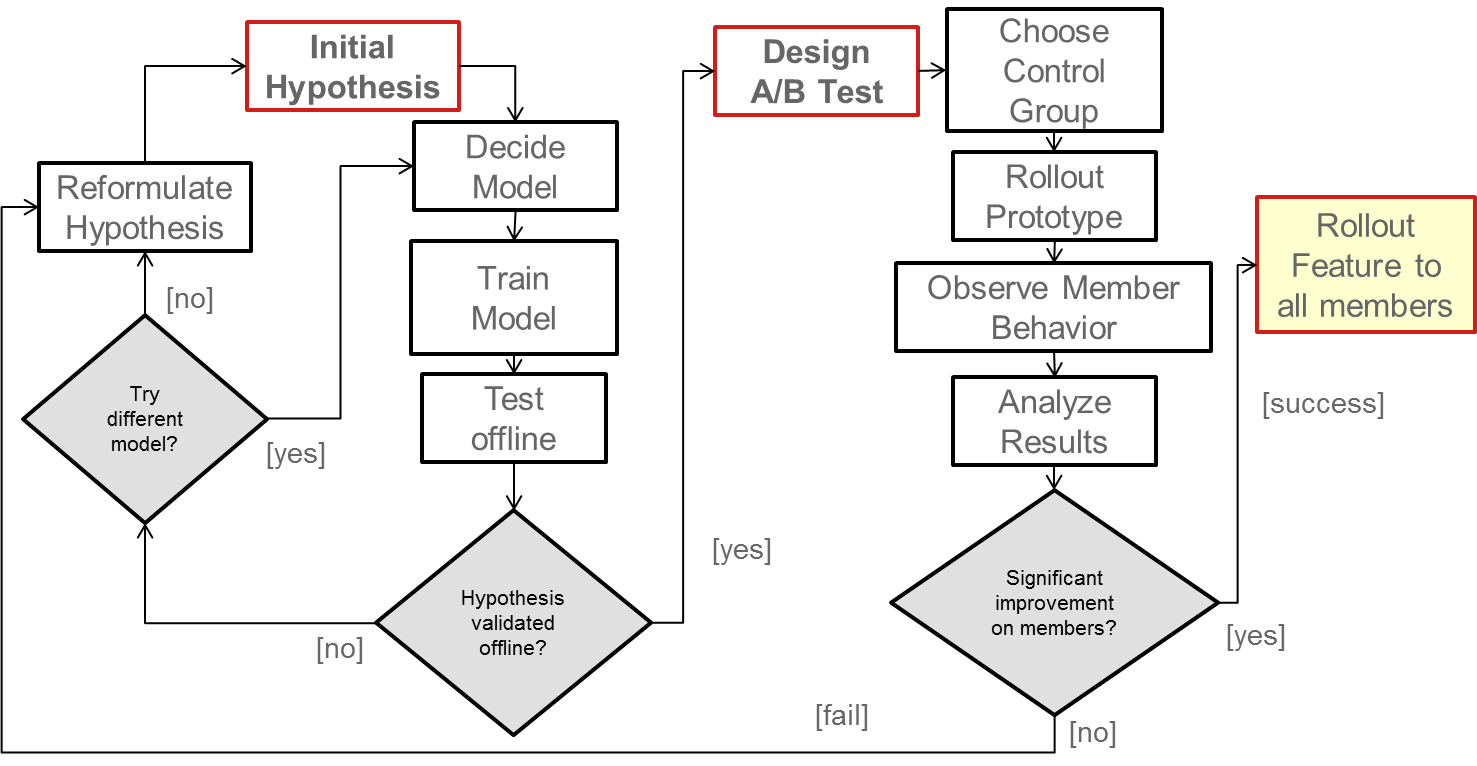
An extreme example of this innovation cycle is what we called the Top10 Marathon. This was a focused, 10-week effort to quickly test dozens of algorithmic ideas related to improving our Top10 row. Think of it as a 2-month hackathon with metrics. Different teams and individuals were invited to contribute ideas and code in this effort. We rolled out 6 different ideas as A/B tests each week and kept track of the offline and online metrics. The winning results are already part of our production system.
这种创新周期的一个极端例子就是我们所说的Top10马拉松。这是一项耗时10周的重点工作,旨在快速测试与改善我们的Top10行有关的数十种算法思想。可以将其视为具有指标的为期2个月的黑客马拉松。邀请了不同的团队和个人为这项工作贡献思想和代码。每周我们都会在A / B测试中推出6种不同的想法,并跟踪离线和在线指标。获奖结果已经成为我们生产系统的一部分。


Conclusion 结论
The Netflix Prize abstracted the recommendation problem to a proxy question of predicting ratings. But member ratings are only one of the many data sources we have and rating predictions are only part of our solution. Over time we have reformulated the recommendation problem to the question of optimizing the probability a member chooses to watch a title and enjoys it enough to come back to the service. More data availability enables better results. But in order to get those results, we need to have optimized approaches, appropriate metrics and rapid experimentation.
Netflix奖将推荐问题抽象为预测收视率的代理问题。但是会员评分只是我们拥有的众多数据来源之一,评分预测只是我们解决方案的一部分。随着时间的流逝,我们将推荐问题重新分配为优化成员选择观看标题并享受到足以返回服务的可能性的问题。更高的数据可用性可带来更好的结果。但是为了获得这些结果,我们需要有优化的方法,适当的指标和快速的实验。
To excel at innovating personalization, it is insufficient to be methodical in our research; the space to explore is virtually infinite. At Netflix, we love choosing and watching movies and TV shows. We focus our research by translating this passion into strong intuitions about fruitful directions to pursue; under-utilized data sources, better feature representations, more appropriate models and metrics, and missed opportunities to personalize. We use data mining and other experimental approaches to incrementally inform our intuition, and so prioritize investment of effort. As with any scientific pursuit, there’s always a contribution from Lady Luck, but as the adage goes, luck favors the prepared mind. Finally, above all, we look to our members as the final judges of the quality of our recommendation approach, because this is all ultimately about increasing our members’ enjoyment in their own Netflix experience. We are always looking for more people to join our team of “prepared minds”. Make sure you take a look at our jobs page.
要在创新个性化方面表现出色,这在我们的研究中是不够有条理的;探索的空间实际上是无限的。在Netflix,我们喜欢选择和观看电影和电视节目。我们将研究的热情转化为对追求成功方向的强烈直觉,从而专注于研究。未充分利用的数据源,更好的功能表示,更合适的模型和指标以及错过的个性化机会。我们使用数据挖掘和其他实验方法来逐步告知我们的直觉,因此优先考虑投入的精力。就像任何科学追求一样,幸运女神总是有贡献的,但是随着谚语的发展,幸运会偏向有准备的人。最后,最重要的是,我们希望我们的成员成为我们推荐方法质量的最终裁判,因为这最终都是要增加我们成员在自己的Netflix体验中的享受。我们一直在寻找更多的人加入我们的“有准备的头脑”团队。确保您看看我们的作业页。
Originally published at techblog.netflix.com on June 20, 2012.