系统架构
Netflix在2013年公布了自己推荐系统的架构,本文主要总结和翻译自System Architectures for Personalization and Recommendation,但这并不是一篇完整的翻译文章。
Overview
首先,我们在下图中提供推荐系统的整体系统图。 该体系结构的主要组件包含一个或多个机器学习算法。

计算可以被online,nearline或者offline完成。
online计算可以更好地响应最近的事件和用户交互,但必须实时响应请求。这会限制所采用的算法的计算复杂性以及可以处理的数据量。offline计算对数据量和算法的计算复杂性的限制较少,因为它以批量方式运行且具有宽松的时序要求。个性化架构中的关键问题之一是如何以无缝方式组合和管理在线和离线计算。近线计算是这两种模式之间的中间折衷,我们可以在其中执行类似在线的计算,但不要求它们实时提供。模型训练是另一种计算形式,它使用现有数据生成模型,该模型稍后将在实际计算结果期间使用。该体系结构的另一部分描述了事件和数据分发系统如何处理不同类型的事件和数据。相关问题是如何组合离线,近线和在线制度所需的不同信号和模型。最后,我们还需要弄清楚如何以对用户有意义的方式组合中间推荐结果。本文的其余部分将详细介绍此体系结构的这些组件及其交互。Netflix的整个基础架构都在Amazon Web Services云上运行。
Computation
Online计算可以快速响应事件并使用最新数据。 一个示例是使用当前context为action movie gallery排序。 联机组件受可用性和响应时间服务级别协议(SLA)的约束,该协议指定响应来自客户端应用程序的请求的进程的最大延迟。 这使得在复杂且计算成本高的算法难以在online service中使用。 此外,纯粹的在线计算在某些情况下可能无法满足其SLA,因此考虑快速回退机制(例如恢复到预先计算的结果)很重要。 online计算还意味着所涉及的各种数据源也需要在线提供,这可能需要额外的基础设施。
Offline计算允许使用更复杂的算法和更多的数据一个简单的例子可能是定期汇总数百万电影播放事件的统计数据,以计算baseline的流行度指标。离线系统也有更简单的工程要求。例如,可以轻松满足客户施加的宽松响应时间SLA。可以在生产中部署新算法,而无需在性能调优上投入太多精力。这种灵活性支持敏捷创新。Netflix利用这一点来支持快速实验:如果新的实验算法执行速度较慢,我们可以选择简单地部署更多Amazon EC2实例来实现运行实验所需的吞吐量,而不是花费宝贵的工程时间来优化性能对于可能被证明具有很小商业价值的算法。但是,由于脱机处理没有强大的延迟要求,因此它不会对上下文或新数据的更改做出快速反应。这可能会降低用户体验。离线计算还需要具有用于存储,计算和访问大量预先计算结果的基础结构。
Nearline计算可以看作是前两种模式之间的折衷。Nearline计算是响应于用户事件而完成的。
在任何情况下,online/nearline/offline都可以而且应该结合起来。有很多方法可以将它们组合在一起。我们已经提到了使用离线计算作为后备的想法。另一种选择是使用离线过程预先计算部分结果,并留下算法中成本较低的部分或者上下文敏感的部分用于online计算。
甚至建模部分也可以以混合离线/在线方式完成。传统的监督分类应用必须从标记数据批量训练分类器,并且在线进行预测。但是,矩阵分解等方法更适合混合在线/离线建模:某些因素可以离线预先计算,而其他因素可以实时更新以创建更新鲜的结果。其他无监督方法(例如cluster)还允许cluster center的离线计算和cluster的在线分配。
Offline Jobs
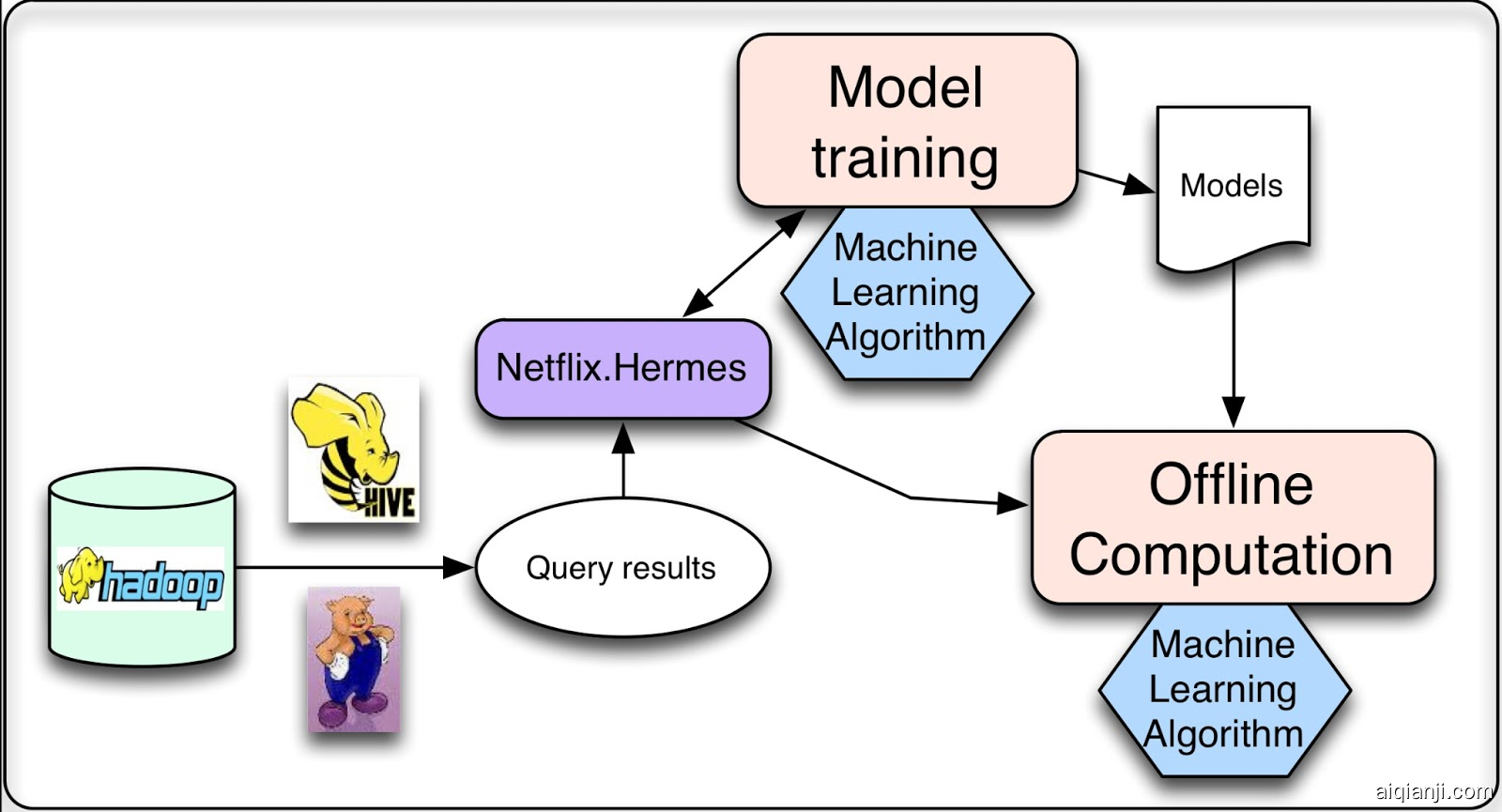
offline jobs的主要内容是数据统计和模型的离线训练,这些内容通常以batch为单位完成。
这两个任务都需要处理数据,这通常是通过运行数据库查询生成的。由于这些查询会运行大量数据,它们适合以分布式方式通过Hive或Pig作业在Hadoop上运行。查询完成后,我们需要一种机制来发布结果数据。我们对该机制有几个要求:首先,它应该在查询结果准备好时通知订阅者。其次,它应该支持不同的存储库(不仅是HDFS,还有S3或Cassandra)。最后,它应该透明地处理错误,允许监视和警报。Netflix使用一个名为Hermes的内部工具,从某种意义上说,它涵盖了与Apache Kafka相同的一些用例,但它不是消息/事件队列系统。
Signals & Models & Event & Data
无论我们是在进行在线还是离线计算,我们都需要考虑算法如何处理三种输入:model,data和signal。 Model通常是先前已离线培训的参数的小文件。 Data是先前处理的信息,已存储在某种数据库中,例如电影元数据或流行度。 我们使用术语“signal”来指代我们输入算法的新信息。 该数据从实时服务获得,并且可以由用户相关信息(例如,成员最近观看的内容)或诸如会话,设备,日期或时间的上下文数据构成。
Netflix尝试区别event和data。他们将事件视为时间敏感信息的小单位,需要以尽可能少的延迟进行处理,以触发后续操作或过程,例如更新nearline结果集。另一方面,他们将数据视为可能需要处理和存储以供以后使用的更密集的信息单元。这里的延迟并不像信息质量和数量那么重要。当然,有些用户事件可以被视为事件和数据,因此被发送到两个流。
Recommendation Results
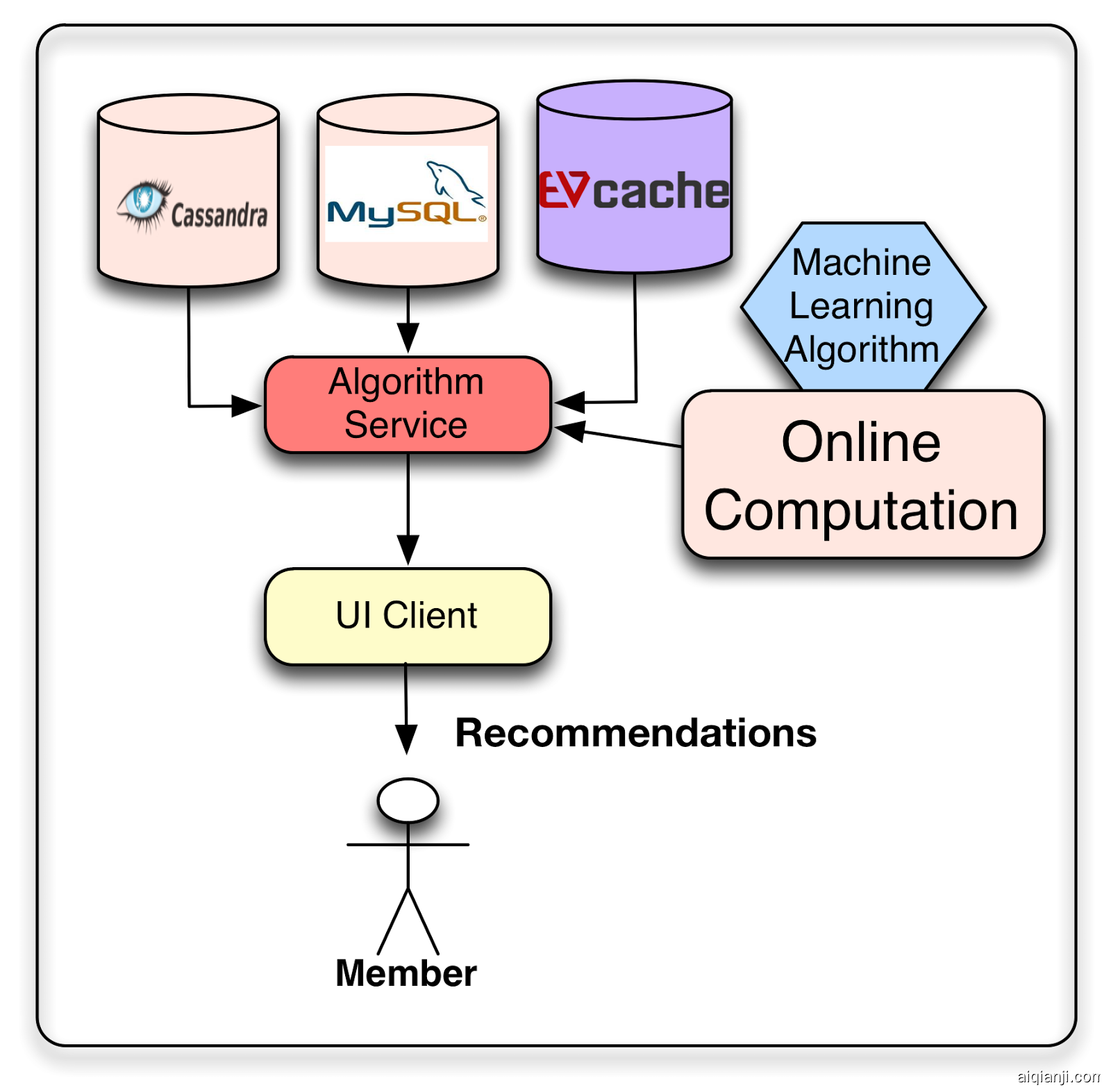
Netflix将offline和intermediate结果存储在各种存储库中,以便稍后在请求时使用:他们使用的主要数据存储是Cassandra,EVCache和MySQL。每种解决方案都有其优点和缺点。
MySQL允许存储结构化关系数据,这些数据可能是通过通用查询进行的某些未来过程所必需的。但是,这种通用性是以牺牲分布式环境中的scalability为代价的。 Cassandra和EVCache都提供了键值存储的优势。当需要分布式和可扩展的无SQL存储时,Cassandra是一个众所周知的标准解决方案。 Cassandra在某些情况下运行良好,但EVCache更适合密集和持续的写操作。
排序算法
内容来自netflix-techblog:recommendations
按照时间顺序,最早的关于推荐系统的文章发表于2012年.
Netflix Recommendations: Beyond the 5 stars (Part 1)
Netflix Recommendations: Beyond the 5 stars (Part 1)
最早在2006年,Netflix举办了一个名叫Netflix Prize的比赛,用来征集movie rating prediction算法。最终, Matrix Factorization和Restricted Boltzmann Machines (RBM)算法在比赛中取得了最好的结果。Netflix把这两个算法用到了自己的产品中。
Netflix在这篇blog中阐述了推荐算法的重要性以及他们为什么要使用推荐算法,但我们忽略这一部分,只阐述技术相关的问题。
从用户进入首页开始,Netflix就开始在各种地方使用推荐系统,以使用户尽可能获得个性化的体验。Netflix的推荐系统有这些目标:
- Accuracy:这是一般推荐系统都有的预测准确度的目标
- Diversity:在家庭使用的场景,多样性尤为重要
- Awareness:Netflix希望用户知道个性化内容是怎样生成的,其中最典型的一个做法是explainable recommendation reason
在推荐理由的可视化上,Netflix充分利用了与Facebook的连接,这样他们就可以使用好友的兴趣爱好来进行reco以及reco reason的解析。
一些最有识别度的collection被称为genre,这相当于一些cluster,根据这些cluster推荐能更好地保证diversity。内容之间的similarity也是考虑的重点,实际上,大部分推荐系统都是以此为根基的。
Netflix的推荐系统从结构上就是经典的普通推荐系统,主要由retriver和ranker组成,而上述的算法主要是用在ranking阶段的。
Netflix Recommendations: Beyond the 5 stars (Part 2)
Netflix Recommendations: Beyond the 5 stars (Part 2)
Ranking是推荐系统最重要的组成部分之一。推荐系统的目标主要是提供一些有吸引力的物品供人选择。 这通常通过选择一些项目并按某个指标的顺序对其进行排序来完成。 最常见的呈现推荐项目的方式是某种形式的列表,推荐系统需要一个适当的排名模型,可以使用各种各样的信息来为每个项目提供最佳的项目排名。 Netflix选择的排序目标是"受欢迎程度"和"预期用户评分",这是很容易理解的,当然在实际情况的不同场景中,还会有很多其它的附属指标。
许多监督学习方法可用于排名。 典型的选择包括Logistic回归,支持向量机,神经网络或基于决策树的方法,如梯度提升决策树(GBDT)。 另一方面,近年来出现了大量专门用于学习排名的算法,例如RankSVM或RankBoost。 没有简单的办法去确定哪种模型在给定的排名问题中表现最佳。您的特征空间越简单,您的模型就越简单。 只有和特征空间和实际情况匹配的算法,才是好算法。
Data and Models
Netflix的数据源包括:
- 来自用户的数十亿item rating。每天收到数百万的new ratings。
- 使用item popularity作为基线。有很多方法可以计算受欢迎程度,可以在不同的时间范围内计算它,例如每小时,每天或每周。或者按地区或其他相似性指标对成员进行分组,并计算该组内的受欢迎程度.
- 每天收到数百万个流播放事件,其中包括持续时间,时间和设备类型等上下文。
- 用户每天都会在他们的队列中添加数百万个项目。
- 每个item都有丰富的元数据:演员,导演,流派,家长评级和评论。
- 知道Netflix推荐的项目以及向用户展示的内容,并了解这些如何影响用户的行动。还可以观察用户的interaction:滚动,鼠标悬停,点击或在给定页面上花费的时间。
- 社交数据:可以处理相关朋友观看或评分的内容。
- 用户每天直接在Netflix服务中输入数百万个搜索字词。
- 上面提到的所有数据都来自内部资源。还可以利用外部数据来改进的功能。例如,可以添加外部项目数据功能,如票房表现或评论。
- 当然,这还不是全部:还有许多其他功能,例如可以在预测模型中使用的人口统计,位置,语言或时间数据。
以下model是Netflix曾经考虑或者尝试过的,但这并不是全部:
- Linear regression
- Logistic regression
- Elastic nets
- Singular Value Decomposition
- Restricted Boltzmann Machines
- Markov Chains
- Latent Dirichlet Allocation
- Association Rules
- Gradient Boosted Decision Trees
- Random Forests
- Clustering techniques from the simple k-means to novel graphical approaches such as Affinity Propagation
- Matrix factorization
数据驱动是我们研究推荐系统时一般会采用的方法,Netflix也不例外。具体表现就是,每个上线的算法都要经过AB test。它的AB Test的流程和大部分公司都没什么区别。
