Search Federation Architecture at LinkedIn
March 14, 2018
author
Co-authors: Yi Shen, Claire Liu, and Ali Mohamed
Introduction: A brief history of Search Federation at LinkedIn 简史
Almost every part of LinkedIn contains data that needs to be discoverable by our members or customers. Use cases range from a member looking up a news article posted by someone in their network to a recruiter looking for candidates on the platform. One of the primary mechanisms for discovering this content is search.
Accordingly, at LinkedIn, we have many different search engines for a variety of use cases, such as People Search (members) and Job Search (posted job opportunities). The Search Federation team’s mission is to help our members and customers find resources by searching across these engines. We call these use case-focused engines “search backends.”
We also provide a family of mid-tier services designed to answer search and search typeahead queries. These services typically follow the federation pattern, where the user’s query is first expanded through query understanding, spell checking, and other techniques. This expansion is used to write queries specific for each search backend. The documents returned from the backends are then combined to be most useful to the user through a process called “blending.”
Collectively, this process makes up Search Federation at LinkedIn. Search Federation provides us with a way to personalize ambiguous queries. For instance, when a user searches for "machine learning" on LinkedIn, they could mean to search for people with machine learning skills, jobs requiring machine learning skills, or content about the topic.
LinkedIn的几乎每个部分都包含需要我们的会员或客户发现的数据。从用户查找其社交网络中某人发布的新闻文章 到 招聘人员在平台上寻找候选人。搜索是发现此内容的主要机制之一。
因此,在LinkedIn上,我们针对各种用例提供了许多不同的搜索引擎,例如“人物搜索”(成员)和“职位搜索”(发布的工作机会)。Search Federation团队的任务是通过搜索这些引擎来帮助我们的会员和客户找到资源。我们称这些针对用例的引擎为“搜索后端”。
我们还提供一系列中间层服务,旨在回答搜索和搜索提前查询。这些服务通常遵循联合身份验证模式,在该模式中,首先通过查询理解,拼写检查和其他技术来扩展用户的查询。此扩展用于编写特定于每个搜索后端的查询。然后,将从后端返回的文档进行合并,以通过称为“混合”的过程对用户最有用。
总的来说,此过程构成了LinkedIn上的Search Federation。Search Federation为我们提供了一种个性化歧义查询的方法。例如,当用户在LinkedIn上搜索“机器学习”时,他们可能意味着搜索具有机器学习技能的人,需要机器学习技能的工作或有关主题的内容。
Search Federation mid-tier building blocks Search Federation中层构建块
Historically, our Search Federation architecture has consisted of three mid-tier services.
从历史上看,我们的Search Federation体系结构由三个中层服务组成。
The federated-search-rest service was created in 2012 to provide a Rest.li API for the Search endpoint and served as a Search Federation mid-tier for the blended search experience. Additionally, federated-search-rest calls the search-decoration service to decorate the result with unindexed information.
federated-search-rest服务创建于2012年,旨在为Search端点提供Rest.li API,并充当Search Federation中间层的混合搜索体验。此外,联合搜索休息会调用搜索装饰服务,以使用未编制索引的信息来修饰结果。
The typeahead-rest service was created in Q1 2014 to provide a Rest.li API for the typeahead endpoint and to serve as a typeahead federation mid-tier for the blended typeahead experience.
typeahead-rest服务创建于2014年第一季度,以提供用于typeahead终结点的Rest.li API,并用作混合aatypehead体验的aatypeahead联合中间层。
The seas-federated-search service was created in Q2 2014 to be the new federator used by all external services to access search. During the Galene migrations, all calls from federated-search-rest to the legacy backends were moved over to seas-federated-search. In this blog post, we use "new federation mid-tier" to refer to seas-federated-search service.
seas-federated-search服务于2014年第二季度创建,是所有外部服务用来访问搜索的新联合身份验证程序。在Galene迁移期间,所有从联合搜索站点到传统后端的呼叫都移到了海联合搜索上。在此博客文章中,我们使用“新的联合中间层”来指代seas-federated-search服务。
Like with any service, over the years product requirements have changed, the number of callers has grown, and an increase in use cases has resulted in a good amount of legacy code. At the same time, there has been a tremendous increase in demand for ease-of-use and rapid iteration from developers modifying Search Federation architecture (110+ code contributors and 800+ commits, for instance, in 2017) for different verticals.
In early 2015, the team identified three main challenges in our legacy federation architecture that were impeding our ability to iterate quickly and threatened search stability as our scale increased:
与其他服务一样,多年来,产品要求已发生变化,调用方的数量有所增加,用例的增加导致大量的旧代码。同时,针对不同行业的开发人员修改Search Federation体系结构(例如,在2017年,提供了110多个代码贡献者和800多个提交),对易用性和快速迭代的需求已大大增加。
在2015年初,该团队发现了我们的旧联盟架构中的三个主要挑战,这些挑战阻碍了我们快速迭代的能力,并随着规模的扩大而威胁到搜索稳定性:
- Leverage between search and typeahead - Similar federation logic in these closely-related mid-tiers was written with different design patterns. This meant adding a new feature would always involve changing in stacks of multiple services and making separate deployments.
- Code isolation - The legacy design was based on inheritance so that verticals serving different use cases were inevitably coupled. On top of that, it wasn’t easy to extend for new vertical use cases in a clean way, and complicated if-else clauses were added in many shared components.
- Test and deployment - Low test coverage in 2015 and no Search Federation services supporting daily deployment made it difficult to reliably deploy changes without regressions.
- 在搜索和提前输入之间发挥杠杆作用-在这些密切相关的中间层中,类似的联合逻辑使用不同的设计模式编写。这意味着添加新功能将始终涉及更改多个服务的堆栈并进行单独的部署。
- 代码隔离-传统设计基于继承,因此服务于不同用例的垂直行业不可避免地会耦合在一起。最重要的是,要以干净的方式扩展新的垂直用例并不容易,并且在许多共享组件中添加了复杂的if-else子句。
- 测试和部署-2015年的测试覆盖率较低,并且没有支持每日部署的Search Federation服务使得难以可靠地部署更改而不进行回归。
Roadmap: Building a bridge to the future 路线图:搭建通往未来的桥梁
To address the above problems, the Search Federation team began implementing a redesign of the federation service with the following strategies: services consolidation, code isolation, and improving our overall test coverage.
为了解决上述问题,Search Federation团队开始采用以下策略对联合身份验证服务进行重新设计:服务合并,代码隔离和提高总体测试覆盖率。
Services consolidation:
- We merged the legacy search federation mid-tier and legacy typeahead federation mid-tier into a new federation mid-tier to ease leveraging between search and typeahead.
- Access to all backends now goes through this new federation mid-tier, the same place where query understanding, spell checking, and data fetching are happening.
服务整合:
- 我们将旧版搜索联合中间层和旧式提前键入联合中间层合并为新的联合中间层,以简化在搜索和预输入之间的平衡。
- 现在,对所有后端的访问都经过这个新的联合中间层,即查询理解,拼写检查和数据获取发生的同一位置。
Code isolation:
- We used a workflow framework to compose a use case specific workflow, which provides code isolation among verticals. No if-else clauses are needed, and new use cases can be onboarded easily by reusing common workflows.
- Modularize code per vertical use case.
代码隔离: - 我们使用了工作流框架来组成特定于用例的工作流,该工作流提供了垂直行业之间的代码隔离。不需要if-else子句,并且可以通过重用常见的工作流轻松地引入新的用例。
- 每个垂直用例模块化代码。
Overall test coverage improvement:
-
Add more unit tests to increase code coverage.
-
Add more integration tests to enhance PCx test.
-
Add dark canary hosts.
总体测试覆盖率的提高:
-
添加更多的单元测试以增加代码覆盖率。
-
添加更多的集成测试以增强PCx测试。
-
添加dark canary hosts。
Additionally, this had to be accomplished while accommodating the search needs of a rapidly-growing global membership, which was dramatically increasing the overall amount and number of types of content that needed to be searchable on LinkedIn. These issues needed to be addressed without disrupting the ~700 million searches that LinkedIn handles every single day.
此外,必须在满足快速增长的全球会员的搜索需求的同时实现这一点,这极大地增加了需要在LinkedIn上搜索的内容的总数和类型。必须解决这些问题,同时又不影响LinkedIn每天处理的约7亿次搜索。
Progress so far 到目前为止的进展
The Search Federation team kicked off the Search Federation Re-architecture Project by building the SeaS workflow framework, then we rolled-out the migration in stages: individual workflow migration, typeahead federation consolidation, and Search Federation consolidation.
Search Federation团队通过构建SeaS工作流框架启动了Search Federation重新架构项目,然后我们分阶段进行了迁移:单个工作流迁移,预输入联合合并和Search Federation合并。
Workflow migration (2016)
Starting in Q4 2015 and working through Q2 2016, we successfully migrated all query processing to new federation mid-tier and all 40+ search use cases to SeaS workflow. Access to all Galene backends was routed through this new federation mid-tier.
工作流程迁移(2016)
从2015年第四季度开始一直到2016年第二季度,我们成功地将所有查询处理迁移到了新的联合中间层,并将所有40多个搜索用例迁移到了SeaS工作流。对所有Galene后端的访问均通过此新的联合中间层进行。

Search Federation architecture at the end of 2016
Typeahead federation consolidation
Through the remainder of 2016, we made a lot of progress for typeahead consolidation, where we extracted typeahead-federator (core typeahead fanout and blending logic) out of the legacy typeahead federation mid-tier and integrated it into the new federation mid-tier. After that, typeahead-rest served solely as a proxy/adapter for API calls. Following ramping for federated and blended typeahead requests to 100% was done in Q1 2017 without any impact of relevance and operational metrics.
Typeahead联合合并
在2016年剩余时间里,我们在typeahead合并方面取得了很多进展,我们从传统的typeahead联合中间层提取了typeahead-federator(核心typeahead扇出和混合逻辑)并将其集成到新的联邦中间层。之后,typeahead-rest仅充当API调用的代理/适配器。在2017年第一季度,将联邦和混合预先输入的请求增加到100%之后,没有任何相关性和运营指标的影响。
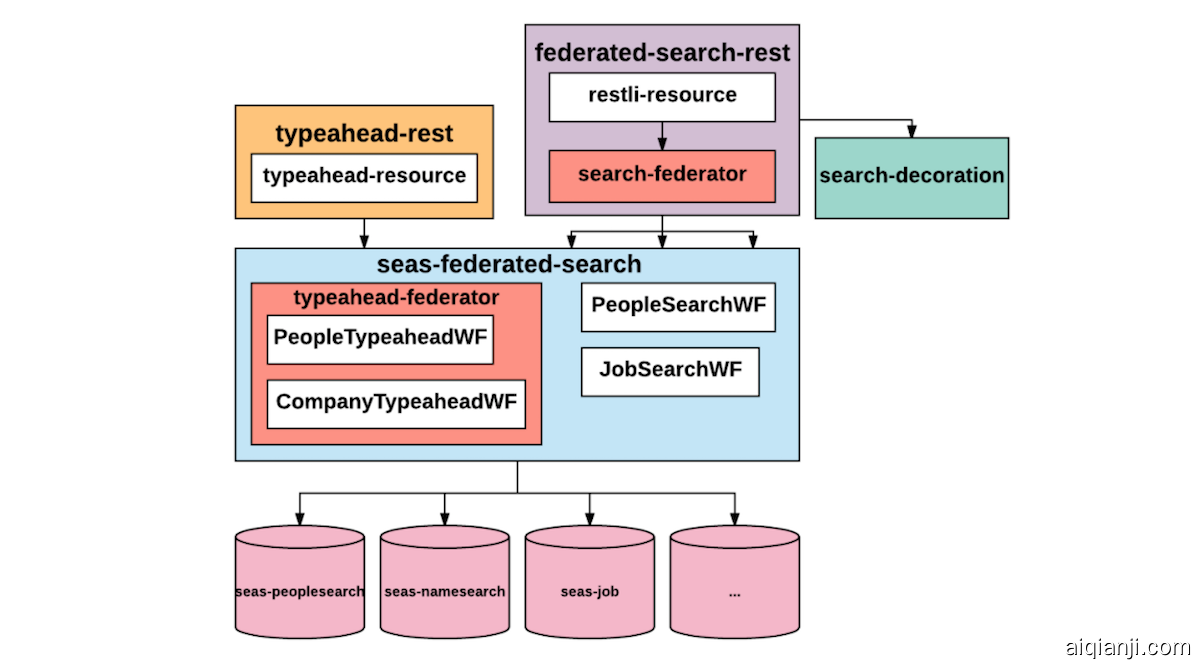
Search Federation architecture at Q1/2017
The typeahead consolidation helped reduce the QPS of the new federation mid-tier by half, from 16K to 8K. There were 0 GCNs caused by this migration, and no noticeable latency change.
预先进行的合并有助于将新联盟中层的QPS降低一半,从16K降至8K。此迁移导致了0个GCN,并且没有明显的延迟变化。
**Search Federation consolidation
**Besides typeahead federation consolidation, another big missing piece of the re-architecture was to move search-federator (search fanout and blending logic) from the legacy search federation mid-tier to the new search federation mid-tier. There were a few challenges for this move, such as:
- A large number of deprecated Federated Search Rest.li API parameters and half-ramped features owned by different verticals. To clean them up, collaboration and coordination across multiple teams was critical.
- A good amount of legacy undocumented code was present in search-federator, which also added difficulties to the migration. For example, to determine query intent and select search verticals to fanout, the legacy search federation has a built-in intent prediction system, Dreamweaver (created in 2013). Dreamweaver also depends on an older version of Lucene, which we were in the process of deprecating.
- Partner teams could be aggressively onboarding and testing new features during the migration, which in the meantime also needed to be synced in the new federation mid-tier.
搜索联盟合并
除了预先进行的联盟合并之外,重新架构的另一个重要缺失是将搜索联合者(搜索扇出和混合逻辑)从传统搜索联合中间层迁移到新的搜索联合中间层。此举面临一些挑战,例如:
- 大量不赞成使用的联合搜索Rest.li API参数和不同行业拥有的半斜坡特征。为了清理它们,多个团队之间的协作与协调至关重要。
- 搜索联合器中存在大量的遗留未记录代码,这也给迁移增加了难度。例如,要确定查询意图并选择搜索垂直方式进行扇出,旧版搜索联盟具有内置的意图预测系统Dreamweaver(于2013年创建)。Dreamweaver还依赖于我们正在弃用的旧版Lucene。
- 合作伙伴团队可能会在迁移过程中积极加入并测试新功能,与此同时,还需要在新的联合中间层中同步这些功能。
Based on the understanding of the challenges and the experience gained from typeahead federation consolidation, the team allocated a third of its resources over the past three quarters to complete this significant re-architecture. Here are some highlights from this consolidation:
基于对挑战的理解以及从预先联合的合并中获得的经验,该团队在过去的四个季度中分配了三分之一的资源来完成这一重要的重新架构。以下是此合并的一些要点:
- Documentation: We chalked out a migration plan and documented it in an internal design document that was shared with the rest of the engineering and product teams.
- Lining-up with the ReMix roadmap: ReMix is the next-gen, developer-friendly workflow framework that supports asynchronous and synchronous task execution. Operator is the minimum logical unit in ReMix, which composes workflows, and gets executed by the ReMix engine during runtime. In order for ReMix to easily integrate with the current architecture seamlessly and have enough performance and correctness proof for baseline, the Search Federation migration was implemented in both SeaS and ReMix versions, and both workflows were sharing the same set of ReMix operators which fulfill the core functionality.
- Leverage parity check framework: Correctness of migration results is always a pain point for any migration. A parity check library was initiated by the Federation Infra team and Relevance Infra Tools Engineering team. The migration has embedded this framework to compare results from legacy and migrated flow, before we started the A/B testing. It provides early detection of obvious issues before exposing the system to end users.
- 文档: 我们制定了一个迁移计划,并将其记录在内部设计文档中,该文档与其他工程和产品团队共享。
- ReMix路线图的补充: ReMix是下一代,对开发人员友好的工作流程框架,支持异步和同步任务执行。运算符是ReMix中最小的逻辑单元,它构成工作流,并在运行时由ReMix引擎执行。为了使ReMix轻松无缝地与当前体系结构无缝集成并为基线提供足够的性能和正确性证明,在SeaS和ReMix版本中都实施了Search Federation迁移,并且两个工作流共享同一组ReMix运算符,这些运算符可以满足核心要求功能。
- 利用奇偶校验框架: 迁移结果的正确性始终是任何迁移的痛点。联邦基础设施团队和相关基础设施工具工程团队启动了一个奇偶校验库。在开始A / B测试之前,迁移已嵌入了此框架,以比较旧数据流和迁移后的数据流的结果。在将系统暴露给最终用户之前,它可以提早发现明显的问题。

Search Federation architecture at Q4/2017
As we write this update in the middle of Q4 2017, we’ve made the following progress on consolidating our Search Federation architecture:
- Completed all the code change for the new architecture, which is ramped to 5% of members.
- Passed correctness/parity test: 95% of the primary results are identical, and the other 5% difference is due to query tagging and spell-check platform upgrades.
- No impacts on system stability: no GCNs occurred during the entire consolidation process.
- No negative impacts on relevance or operational metrics were reported during this time.
- Consolidating these systems alone lead to a performance improvement of 3% up for P90 latency.
在2017年第四季度中期撰写此更新时,我们在整合Search Federation体系结构方面取得了以下进展: - 完成了新架构的所有代码更改,该更改增加到5%的成员。
- 通过正确性/奇偶性测试:95%的主要结果相同,其他5%的差异是由于查询标记和拼写检查平台升级所致。
- 对系统稳定性没有影响:在整个合并过程中都没有发生GCN。
- 在此期间,未报告对相关性或运营指标产生负面影响。
- 单独整合这些系统可将P90延迟性能提高3%。
Future Work 未来的工作
Search Federation consolidation will continue ramping until Q1/2018 when it is completed. Then, collapsing the Typeahead Rest.li endpoint and Search Rest.li endpoint into the new search federation mid-tier will bring us to below state.
Search Federation合并将继续进行,直到完成2018年第1季度。然后,将Typeahead Rest.li端点和Search Rest.li端点折叠到新的搜索联盟中间层中,将使我们进入以下状态。

Future Search Federation architecture
Besides, there is more to be done in the future to support the demand from verticals for more agility:
此外,未来还有更多工作要做,以支持垂直行业对更大敏捷性的需求:
- ReMix workflow migration: All SeaS workflows will be replaced by ReMix workflow, which makes it easier for Search Federation developers to develop, iterate, debug, test, maintain, and operate federation use cases.
- Better vertical isolation: As a monolithic service, seas-federated-search hosts many vertical use cases, in which any misbehaving vertical change may block the production release for all others or increase the latency for other verticals or even clog the whole search service. The Search Federation team is working on finding a better way to isolate the vertical use case to ease the problem.
- ReMix工作流程迁移: 所有SeaS工作流程都将被ReMix工作流程取代,这使Search Federation开发人员可以更轻松地开发,迭代,调试,测试,维护和操作联盟用例。
- 更好的垂直隔离: 作为一项整体服务,seasfedered-search托管了许多垂直用例,其中任何不当的垂直变更都可能阻止其他所有产品的生产发布,或者增加其他垂直行业的延迟,甚至阻塞整个搜索服务。Search Federation团队正在努力寻找一种更好的方法来隔离垂直用例,以缓解问题。
Takeaways
The work we’ve done over the last two years to re-architecture our Search Federation infrastructure has provided the following advantages for LinkedIn:
在过去两年中,我们为重新构造Search Federation基础架构所做的工作为LinkedIn带来了以下优势:
- **Common logic centralization and reusability: ** Both search and typeahead federation logic are gathered into the new federation mid-tier, which means some sharable federation components (e.g., data fetchers, query understanding, spell check, etc.) can be reused easily, increasing leverage and future scale.
- Ease of use: This simplified architecture lowers the learning cost for customers who are looking to take advantage of our search federation stack. Additionally, they no longer need to modify/deploy multiple services in order to onboard a new feature.
- Code isolation: Using the workflow composition mechanism in the new federation mid-tier improves the extensibility of customized workflows per vertical use case.
- Rapid iteration: We have increased the test coverage to 87%, and most Search Federation services now support daily deployment. This allows for faster iteration and improves the overall long-term stability of the system.
- 通用逻辑的集中化和可重用性: 搜索和预先输入的联合逻辑都被收集到新的联合中间层中,这意味着可以轻松地重用某些可共享的联合组件(例如数据获取程序,查询理解,拼写检查等),从而提高了利用率和未来的规模。
- 易于使用: 这种简化的体系结构为希望利用我们的搜索联盟堆栈的客户降低了学习成本。此外,他们不再需要为了启用新功能而修改/部署多种服务。
- 代码隔离: 在新的联合中间层中使用工作流程组合机制,可以提高每个垂直用例的自定义工作流程的可扩展性。
- 快速迭代: 我们将测试覆盖率提高到87%,并且大多数Search Federation服务现在都支持每日部署。这样可以加快迭代速度,并改善系统的整体长期稳定性。
Acknowledgements 致谢
非常感谢参与迁移的团队和个人的不断帮助。我们想召集以下团队:联合基础架构,旗舰搜索,相关基础设施工具工程,搜索相关性和基础,人员搜索相关性,职位搜索,职位搜索相关性,内容搜索相关性和搜索SRE。
Many thanks to the teams and individuals involved in migration for their constant help. We’d like to call out the following teams: Federation Infrastructure, Flagship Search, Relevance Infra Tools Engineering, Search Relevance and Foundation, People Search Relevance, Job Search, Job Search Relevance, Content Search Relevance, and Search SRE.