The AI Behind LinkedIn Recruiter search and recommendation systems
author
Guo qin
April 22, 2019
Co-authors: Qi Guo, Sahin Cem Geyik, Cagri Ozcaglar, Ketan Thakkar, Nadeem Anjum, and Krishnaram Kenthapadi
LinkedIn Talent Solutions serves as a marketplace for employers to reach out to potential candidates and for job seekers to find career opportunities. A key mechanism to help achieve these goals is the LinkedIn Recruiter product, which helps recruiters and hiring managers source suitable talent and enables them to identify “talent pools” that are optimized for the likelihood of making a successful hire. In this blog post, we will first highlight a few unique information retrieval, system, and modeling challenges associated with talent search and recommendation systems. We will then describe how we formulated and addressed these challenges, the overall system design and architecture, the issues encountered in practice, and the lessons learned from the production deployment of these systems at LinkedIn.
LinkedIn Talent Solutions为雇主提供了一个与潜在应聘者接触并为求职者寻找职业机会的市场。LinkedIn Recruiter产品是帮助实现这些目标的关键机制,该产品可帮助招聘人员和招聘经理寻找合适的人才,并使他们能够确定“人才库”。”进行优化,以实现成功录用的可能性。在此博客文章中,我们将首先重点介绍与人才搜寻和推荐系统相关的一些独特的信息检索,系统和建模挑战。然后,我们将描述我们如何制定和解决这些挑战,总体系统设计和体系结构,实践中遇到的问题,以及从LinkedIn上这些系统的生产部署中汲取的经验教训。
Introduction 介绍
The LinkedIn Recruiter product provides a ranked list of candidates corresponding to a search request in the form of a query, a job posting, or a recommended candidate. Given a search request, candidates that match the request are selected and then ranked based on a variety of factors (such as the similarity of their work experience/skills with the search criteria, job posting location, and the likelihood of a response from an interested candidate) using machine-learned models in multiple passes. A screenshot from the application is presented in Figure 1.
LinkedIn Recruiter产品以查询,职位发布或推荐候选人的形式提供与搜索请求相对应的候选人排名。给定搜索请求后,将根据各种因素(例如,他们的工作经验/技能与搜索条件的相似性,职位发布地点以及有兴趣者做出回应的可能性)来选择符合该请求的候选人,然后对其进行排名候选人)多次使用机器学习的模型。该应用程序的屏幕截图如图1所示。

*Figure 1: A (mocked) screenshot from the LinkedIn Recruiter product
*
对于每个推荐的候选人,招聘人员可以执行以下操作:
- 查看候选人的个人资料,
- 将个人资料保存到招聘项目中(可能的话),
- 发送一封InMail给候选人。
For each recommended candidate, the recruiter can perform the following actions:
- View the candidate’s profile,
- Save the profile to a hiring project (as a potential fit), and,
- Send an InMail to the candidate.
In this blog post, we discuss multiple methodologies we utilize in the talent search systems at LinkedIn. These methods aim to address a set of unique information retrieval challenges associated with talent search and recommendation systems, which can be listed as the following:
- Unlike traditional search and recommendation systems, which solely focus on estimating how relevant an item is for a given query, the talent search domain requires mutual interest between the recruiter and the candidate in the context of the job opportunity. In other words, we require not just that a candidate shown must be relevant to the recruiter’s query, but also that the candidate contacted by the recruiter must show interest in the job opportunity. Hence, it is crucial to use appropriate metrics for model optimization, as well as for online A/B testing. We define a new objective, InMail Accept, which occurs when a candidate received an InMail from a recruiter and replies with a positive response. We take the InMail accept as an indication of two-way interest, which may lead to the candidate receiving a job offer and accepting it. We use the fraction of the top k ranked candidates that received and accepted an InMail (viewed as precision@k) as the main evaluation measure when we experiment with new models for the Recruiter product (please see our BigData’15, CIKM’18, and SIGIR’18 papers for details).
与传统的搜索和推荐系统不同,传统的搜索和推荐系统仅专注于估计项目与给定查询的相关性,而人才搜索领域则需要招聘人员和候选人之间就工作机会达成共同利益。换句话说,我们不仅要求所显示的候选人必须与招聘者的查询相关,而且还要求招聘者联系的候选人必须对工作机会表现出兴趣。因此,对于模型优化以及在线A / B测试使用适当的度量至关重要。我们定义了一个新的目标,即InMail接受,这是当候选人从招聘人员处收到InMail并做出积极回应时发生的。我们将InMail接受视为双向兴趣的指示,这可能会导致应聘者接受并接受工作邀请。有关详细信息,请参见BigData'15,CIKM'18和SIGIR'18论文)。 - Additionally, the underlying query to the talent search system could be quite complex, combining several structured fields, such as canonical title(s), canonical skill(s), and company name, along with unstructured fields, such as free-text keywords. Depending on the application, the query could either consist of an explicitly entered query text and selected facets (Recruiter Search or “Talent Search” in the research literature), or be implicit in the form of a job opening or ideal candidate(s) for a job (Recommended Matches). In Recruiter Search, to assist our users with query formulation, we also suggest related entities that the user might be interested in, e.g., recommending titles like “Data Scientist” and skills like “Data Mining” to recruiters searching for title “Machine Learning Engineer.” With a given query, our goal is to determine a ranked list of the most relevant candidates in real time among hundreds of millions of semi-structured candidate profiles. Consequently, robust standardization, intelligent query understanding and query suggestion, scalable indexing, high-recall candidate selection, effective ranking algorithms, and efficient multi-pass scoring/ranking systems are essential (please see our SIGIR’16 and WWW’16 papers for details)
此外,人才搜索系统的基础查询可能非常复杂,将几个结构化字段(例如规范标题,规范技能和公司名称)与非结构化字段(例如自由文本关键字)结合在一起。根据应用的不同,查询可以由明确输入的查询文本和选定的方面(研究文献中的“招聘者搜索”或“人才搜索”)组成,也可以以职位空缺或理想人选的形式隐含工作(推荐搭配)。在“招聘人员搜索”中,为了帮助我们的用户制定查询,我们还建议用户可能感兴趣的相关实体,例如,向搜索“机器学习工程师”职位的招聘人员推荐“数据科学家”之类的标题和“数据挖掘”之类的技能。 。” 对于给定的查询,我们的目标是实时确定亿万个半结构化候选档案中最相关的候选者的排名列表。因此,强大的标准化,智能的查询理解和查询建议,可伸缩的索引,高召回率的候选人选择,有效的排名算法以及有效的多遍评分/排名系统至关重要(请参阅我们的SIGIR'16和WWW'16论文以了解详细信息) - Finally, personalization is of the essence to a talent search system where we need to model the intents and preferences of recruiters concerning the type of candidates they are looking for. This could either be achieved through offline learning of personalized models through stored recruiter usage data, or via understanding the preferences of the recruiter during online use. On occasion, the recruiter may not even be sure about, say, the set of skills to search for, and this has to be learned through a set of candidate recommendation and evaluation stages (please see our CIKM’18 and WWW’19 papers for more details on how we apply personalization for talent search at LinkedIn).
最后,个性化对于人才搜寻系统至关重要,在该系统中,我们需要对招聘人员针对他们所寻找的候选人类型的意图和偏好进行建模。这可以通过存储的招聘人员使用数据的离线学习个性化模型来实现,也可以通过了解在线使用过程中招聘人员的偏好来实现。有时候,招聘人员甚至可能不确定要寻找的技能集,这必须通过一组候选人推荐和评估阶段来学习(请参阅我们的CIKM'18和WWW'19论文以获取相关信息)。有关我们如何在LinkedIn上将个性化应用于人才搜索的更多详细信息)。
With the help of the modeling approaches described in this blog post, we have been able to steadily increase our key business metrics. For example, in a two-year period we were able to double the number of InMails accepted by job candidates. All these efforts also contribute to our vision of creating economic opportunity for every member of the global workforce.
借助本博客文章中描述的建模方法,我们能够稳定地增加我们的关键业务指标。例如,在两年的时间内,我们能够使求职者接受的InMail数量增加一倍。所有这些努力也有助于我们为全球劳动力的每个成员创造经济机会的愿景。
Methodologies 方法
**深度学习和表示学习的努力
**如上所述,为LinkedIn Recruiter产品提供支持的现有排名系统由于具有优于线性模型的优势,因此利用了梯度提升决策树(GBDT)模型。尽管GBDT提供了相当不错的性能,但它带来了以下挑战:
- Non-linear modeling with Gradient Boosted Decision Trees
Our earliest machine learning model for LinkedIn Recruiter search ranking was a linear model. Linear models are the easiest to debug, interpret, and deploy, and thus a good choice in the beginning. But linear models cannot capture non-linear feature interactions well. We now use Gradient Boosted Decision Trees (GBDT) to unleash the power of our data. GBDT models feature interaction explicitly through a tree structure. Aside from a larger hypothesis space, GBDT has a few other advantages, like working well with feature collinearity, handling features with different ranges and missing feature values, etc. Our online experiments with GBDTs for Recruiter Search ranking were able to achieve statistically significant high single-digit percentage improvement over engagement (between the recruiter and the candidate) metrics.
使用梯度提升决策树的非线性建模
我们用于LinkedIn Recruiter搜索排名的最早的机器学习模型是线性模型。线性模型最容易调试,解释和部署,因此一开始就是一个不错的选择。但是线性模型不能很好地捕捉非线性特征相互作用。现在,我们使用梯度增强决策树(GBDT)释放我们数据的力量。GBDT模型通过树结构显式地具有交互功能。除了更大的假设空间外,GBDT还具有其他一些优势,例如与特征共线性良好地处理,处理具有不同范围的特征以及缺失的特征值等。我们使用GBDT进行的Recruiter Search排名在线实验能够获得具有统计意义的高单(招聘人员和候选人之间)参与度指标的百分比提高。
2.Context-aware ranking with pairwise learning-to-rank
To add awareness of the search context to our GBDT models, we worked on the following improvements. For searcher context, we added some personalization features. For query context, we added more query-candidate matching features, some directly leveraged from LinkedIn’s flagship search product. And very importantly, we used GBDT models with a pairwise ranking objective, to compare candidates within the same context, i.e., the same search request. Pairwise optimization compares pairs of impressions within the same search query. Pointwise optimization assumes all the impressions are independent, no matter if they are in the same search query or not. For this reason, pairwise ranking is more aware of the context. Application of contextual features and pairwise GBDT models helped us achieve a low two-digit (in the tens) percentage improvement in the recruiter-candidate engagement metrics.
上下文感知排名和成对学习排名
为了使我们的GBDT模型更加了解搜索上下文,我们进行了以下改进。对于搜索者而言,我们添加了一些个性化功能。对于查询上下文,我们添加了更多查询候选匹配功能,其中一些功能直接从LinkedIn的旗舰搜索产品中获得利用。非常重要的是,我们使用具有成对排名目标的GBDT模型来比较相同上下文(即相同搜索请求)中的候选者。逐对优化比较同一搜索查询中的展示对。按点优化假定所有印象都是独立的,无论它们是否在同一搜索查询中。因此,成对排名更了解上下文。
3.Deep and representation learning efforts
As discussed above, the existing ranking system powering the LinkedIn Recruiter product utilizes a Gradient Boosted Decision Tree (GBDT) model due to its advantages over linear models. While GBDT provides quite a strong performance, it poses the following challenges:
深度学习和表示学习的作用
如上所述,为LinkedIn Recruiter产品提供支持的现有排名系统由于具有优于线性模型的优势,因此利用了梯度提升决策树(GBDT)模型。尽管GBDT提供了相当不错的性能,但它带来了以下挑战:
- It is quite non-trivial to augment a tree ensemble model with other trainable components, such as embeddings for discrete features. Such practices typically require joint training of the model with the component/feature, while the tree ensemble model assumes that the features themselves need not be trained.
用其他可训练的组件(例如,用于离散特征的嵌入)来增强树集成模型是非常重要的。此类实践通常需要对具有组件/特征的模型进行联合训练,而树状集成模型假定不需要对特征本身进行训练。 - Tree models do not work well with sparse id features such as skill ids, company ids, and member ids that we may want to utilize for talent search ranking. Since a sparse feature is non-zero for a relatively small number of examples, it has a small likelihood of being chosen by the tree generation at each boosting step, especially since the learned trees are shallow in general.
树模型无法与稀疏ID功能配合使用,例如技能ID,公司ID和会员ID,我们可能希望将这些ID用于人才搜索排名。由于稀疏特征在相对较少的示例中为非零,因此在每个提升步骤中被树生成选择的可能性很小,特别是因为学习的树通常很浅。 - Tree models lack flexibility in model engineering. It might be desirable to use novel loss functions, or augment the current objective function with other terms. Such modifications are not easily achievable with GBDT models, but are relatively straightforward for deep learning models based on differentiable programming. A neural network model with a final (generalized) linear layer also makes it easier to adopt approaches such as transfer learning and online learning. 树模型在模型工程中缺乏灵活性。可能需要使用新颖的损失函数,或使用其他术语来增加当前的目标函数。使用GBDT模型不容易实现这种修改,但是对于基于可区分编程的深度学习模型而言,这样的修改相对简单。具有最终(广义)线性层的神经网络模型还使采用转移学习和在线学习等方法变得更加容易。
In order to overcome these challenges, we also explored the usage of neural network based models, which provide sufficient flexibility in the design and model specification. Our offline experiments with pairwise deep-models of up to three layers have shown promise against our baseline GBDT model, where we have observed low single-digit improvements over baseline engagement metrics.
为了克服这些挑战,我们还探索了基于神经网络的模型的使用,这些模型在设计和模型规范中提供了足够的灵活性。我们对多达三层的成对深度模型进行的离线实验表明,相对于我们的基准GBDT模型而言,该方法有希望。在该模型中,我们发现基准参与度指标的单位位数改进较低。
We're currently exploring utilizing LinkedIn's recent model serving infrastructure improvements to deploy neural network models.
为了克服这些挑战,我们还探索了基于神经网络的模型的使用,这些模型在设计和模型规范中提供了足够的灵活性。我们对多达三层的成对深度模型进行的离线实验表明,相对于我们的基准GBDT模型而言,该方法有希望。在该模型中,我们发现基准参与度指标的单位位数改进较低。
Another significant challenge for Talent Search modeling pertains to the sheer number of available entities that a recruiter can include as part of their search, and how to utilize them for candidate selection as well as ranking. For example, the recruiter can choose from tens of thousands of LinkedIn’s standardized skills. Since different entities could be related to each other (to a varying degree), using syntactic features (e.g., fraction of query skills possessed by a candidate) has its limitations. Instead, it is more desirable to utilize semantic representations of entities—for example, in the form of low dimensional embeddings. Such representations allow for numerous sparse entities to be better incorporated as part of a machine learning model. Within Recruiter, we utilize unsupervised network embeddings trained via the Large-Scale Information Network Embeddings (LINE) approach. LINE can optimize for first-order proximity and second-order proximity, is applicable to both directed and undirected graphs, and can scale well. The network embeddings are trained with a modified version of the LinkedIn Economic Graph, where we generate edge weights between entities according to the number of LinkedIn members that have the two entities listed together in their profile (e.g., they have both of the skills or worked at both companies on two ends of the edges, etc.). An illustration for the graph in terms of company entities is given below:
人才搜索建模的另一个重大挑战涉及招聘人员可以在搜索中包括的大量可用实体,以及如何利用它们进行候选人选择和排名。例如,招聘人员可以从成千上万的LinkedIn标准化技能中进行选择。由于不同的实体可能彼此关联(程度不同),因此使用语法功能(例如,候选人所拥有的查询技能的比例)有其局限性。相反,更希望利用实体的语义表示,例如以低维嵌入的形式。这样的表示允许将许多稀疏实体更好地合并为机器学习模型的一部分。在Recruiter中,我们利用通过大规模信息网络嵌入(LINE)方法。LINE可以针对一阶接近度和二阶接近度进行优化,适用于有向图和无向图,并且可以很好地缩放。网络嵌入是使用LinkedIn经济图的修改版进行训练的,其中我们根据在个人资料中同时列出两个实体的LinkedIn成员的数量,来生成实体之间的边权重(例如,他们既具有技能又具有工作能力)在两家公司的边缘的两端等)。以下是有关公司实体的图表说明:
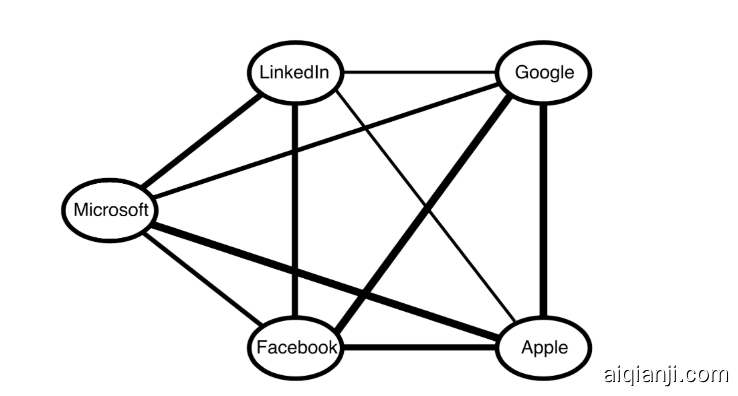
*Figure 2: An illustration of the company entity graph
*
We have utilized the generated embeddings as part of the features on which we train GBDT models. Our online experiments of a GBDT model with network embedding semantic similarity features have shown low single-digit improvements over engagement metrics. The ranking lift, however, was not statistically significant. The hypothesis is that, because the retrieval process is doing exact match based on title ids, the embedding-based similarity won’t differentiate the retrieved results by much. This motivated us to apply this to the retrieval stage. We implemented a query expansion strategy that adds results with semantically similar titles, like “Software Developer” for “Software Engineer,” when the number of returned results from the original query is too small.
我们已将生成的嵌入用作训练GBDT模型的功能的一部分。我们对具有网络嵌入语义相似性功能的GBDT模型进行的在线实验表明,与参与度指标相比,单位数的改进较低。但是,排名提升幅度在统计上并不显着。假设是,由于检索过程是基于标题ID进行精确匹配,因此基于嵌入的相似性不会使检索结果相差太多。这促使我们将其应用于检索阶段。我们实施了一种查询扩展策略,当原始查询返回的结果数量太少时,会添加具有语义相似标题的结果,例如“ Software Developer”(软件工程师)的“ Software Developer”(软件开发人员)。
Entity-level personalization with GLMix 使用GLMix进行实体级别的个性化
In the Recruiter Search domain, multiple entities, such as recruiters, contracts, companies, and candidates, play a role. In order to incorporate entity-level preferences into nonlinear models, we combined best of both worlds in a hybrid model. For entity-level personalization, we used Generalized Linear Mixed (GLMix) models, and experimented with personalization for multiple entities in the Recruiter Search domain. In order allow nonlinear feature interactions, we used a GBDT model in production as a feature transformer, which generates tree interaction features and a GBDT model score. Based on our offline experiments, we used recruiter-level and contract-level personalization in the final GLMix model. Figure 3 shows the pipeline for building GLMix models using learning-to-rank features, tree interaction features, and GBDT model scores. Learning-to-rank features are used as input to a pre-trained GBDT model, which generates tree ensembles that are encoded into tree interaction features and a GBDT model score for each data point. Then, using the original learning-to-rank features and their nonlinear transformations in the form of tree interaction features and GBDT model scores, we build a GLMix model with recruiter-level and contract-level personalization.
在Recruiter Search域中,多个实体(例如,招聘人员,合同,公司和候选人)起着作用。为了将实体级别的偏好合并到非线性模型中,我们在混合模型中结合了两个方面的优势。对于实体级别的个性化设置,我们使用了广义线性混合(GLMix)模型,并针对Recruiter搜索域中的多个实体进行了个性化测试。为了允许非线性特征交互,我们在生产中使用了GBDT模型作为特征转换器,它生成树交互特征和GBDT模型得分。根据我们的离线实验,我们在最终的GLMix模型中使用了招聘人员级别和合同级别的个性化设置。图3显示了使用等级学习功能,树交互功能和GBDT模型得分构建GLMix模型的管道。等级学习功能用作预先训练的GBDT模型的输入,该模型会生成树集成体,这些树集成体被编码为树交互功能和每个数据点的GBDT模型得分。然后,

*Figure 3: Pipeline for GLMix models with tree interaction features
*
In online experiments, we benchmarked the best GLMix model variant, GLMix global + per-contract + per-recruiter model, with the production model at the time, which was a pairwise GBDT model. Online experiment results utilizing the GLMix model with tree interaction features resulted in low single-digit statistically significant improvements of engagement metrics, compared to the baseline pairwise GBDT model.
在在线实验中,我们对最佳的GLMix模型变体进行了基准测试,即GLMix全局+每个合同+每个招聘者模型,以及当时的生产模型,该模型是成对的GBDT模型。与基线成对GBDT模型相比,利用具有树交互功能的GLMix模型进行在线实验的结果导致参与度指标的统计学上显着的低单位数改进。
In-session online personalization 在线个性化会话
A shortcoming of utilizing offline-learned models is the fact that, as the recruiter examines the recommended candidates and provides feedback, that feedback is not taken into account during the current search session. Within the Recruiter team, we have therefore worked on systems that adapt to the user’s feedback and, after some steps (i.e., immediate feedback given to candidates that are presented one at a time), recommend the best candidates for the job.
使用离线学习的模型的缺点是,当招聘人员检查推荐的候选人并提供反馈时,在当前搜索会话中不会考虑反馈。因此,在Recruiter团队内部,我们致力于开发适合用户反馈的系统,并在某些步骤(即,一次向一次提出的候选人提供即时反馈)之后,推荐适合该职位的最佳候选人。
Below is the architecture we utilize for such a system, which first separates the potential candidate space for the job into skill groups. Then, a multi-armed bandit model is utilized to understand which group is more desirable based on the recruiter’s current intent, and the ranking of candidates within each skill group is updated based on the feedback.
下面是我们用于这种系统的体系结构,该体系结构首先将潜在的职位候选空间划分为技能组。然后,基于招募人员的当前意图,利用多武装匪徒模型来了解哪个组更可取,并且根据反馈来更新每个技能组中候选人的排名。

*Figure 4: The architecture of the multi-armed bandit online personalization system
*
Below are some results from our initial experimentation with such a recommendation algorithm. We present the precision (in terms are whether candidates are positively rated by the user) of the recommendations as more candidates are presented to the user. The graph shows that the quality of the recommended candidates improve (we get more and more positive feedback), as more feedback is incorporated to the recommendation model. The exact percentage of candidates that were marked as a good match was modified for company policy.
以下是我们使用这种推荐算法进行的初步实验得出的一些结果。随着更多的候选者呈现给用户,我们提出了推荐的精度(就候选者是否被用户正面评价)。该图显示,随着更多的反馈被合并到推荐模型中,推荐候选人的质量得到了改善(我们获得了越来越多的积极反馈)。标记为良好匹配的候选人的确切百分比已根据公司政策进行了修改。

Figure 5: Percentage of good-match candidates at each index
Another recent effort in the online learning direction within our team has been toward learning a variety of profile attributes (e.g., skill, title, industry, and seniority) that might be most relevant to the recruiter based on the feedback for each candidate with those attributes. If a recruiter is consistently interested in candidates who are, say, accountants with leadership skills, or project managers who are adept at social media, we aim to recommend more of such candidates, implicitly learning a search query for the current intent of the recruiter. This all happens online in real time so that the feedback is taken instantly into account. For more details on this methodology, we invite the interested readers to check out another recent LinkedIn Engineering blog post.
我们团队内部在线学习方向的另一项最新努力是根据具有这些属性的每个候选人的反馈,学习与招聘者最相关的各种个人资料属性(例如技能,头衔,行业和资历) 。如果招聘人员始终对具有领导技能的会计师或精通社交媒体的项目经理等候选人感兴趣,那么我们的目标是推荐更多此类候选人,隐式地学习针对招聘者当前意图的搜索查询。所有这些都是实时在线发生的,因此反馈会被立即考虑在内。有关此方法的更多详细信息,我们邀请感兴趣的读者阅读另一篇最近的LinkedIn Engineering博客文章。
System Design and Architecture ## 系统设计与架构
LinkedIn has built a search stack on top of Lucene called Galene, and contributed to various plug-ins, including capability to live-update search index. The search index consists of two types of fields:
- The inverted field: a mapping from search terms to the list of entities (members) that contain them.
- The forward field: a mapping from entities (members) to metadata about them.
These search index fields contribute to the evaluation of machine learning feature values in search ranking. The freshness of data in the search index fields is also of high importance for machine learning features.
LinkedIn已在Lucene之上建立了一个名为Galene的搜索堆栈,并为各种插件做出了贡献,包括实时更新搜索索引的功能。搜索索引包含两种类型的字段:
- 反向字段从搜索词到包含它们的实体(成员)列表的映射。
- 前向字段从实体(成员)到有关它们的元数据的映射。
这些搜索索引字段有助于对搜索排名中的机器学习特征值进行评估。搜索索引字段中数据的新鲜度对于机器学习功能也非常重要。

*Figure 6: Talent Search architecture and flow
*
Recruiter Search has a layered ranking architecture:
- L1: Scoops into the talent pool and scores/ranks candidates. In this layer, candidate retrieval and ranking are done in a distributed fashion.
- L2: Refines the short-listed talent to apply more dynamic features using external caches.
招聘者搜索具有分层的排名架构:
- L1 Sc入人才库并为候选人评分/排名。在这一层中,候选者的检索和排名以分布式方式完成。
- L2筛选入围人才以使用外部缓存应用更多动态功能。
![talent-ai-application-8]()

Figure 7: Detailed search retrieval and ranking architecture
The Galene broker system fans out the search query request to multiple search index partitions. Each partition retrieves the matched documents and applies the machine learning model to retrieved candidates. Each partition ranks a subset of candidates, then the broker gathers the ranked candidates and returns them to the federator. The federator further ranks the retrieved candidates using additional ranking features that are dynamic or referred to from the cache—this is the L2 ranking layer. For more details about our federated search architecture, please see the prior LinkedIn Engineering blog post related to the topic.
Galene经纪人系统将搜索查询请求散发到多个搜索索引分区。每个分区都检索匹配的文档,并将机器学习模型应用于检索的候选对象。每个分区对候选者的子集进行排名,然后代理收集排名的候选者并将其返回给联合者。联合者还使用动态的或从缓存引用的其他排名特征(这是L2排名层)进一步对检索到的候选者进行排名。有关我们的联合搜索体系结构的更多详细信息,请参阅先前与该主题相关的LinkedIn Engineering博客文章。
Conclusion 结论
In this blog post, we have given a brief overview of the journey of our model explorations and the architecture utilized for Talent Search systems at LinkedIn. As shown, these models have had an impact on our key business metrics. More importantly, however, is the improvement in outcomes for our members and customers. Recently, motivated by LinkedIn’s goal of creating economic opportunity for every member of the global workforce and by a keen interest from our customers in making sure that they are able to source diverse talent, we have also deployed gender representative ranking as part of our Talent Search systems to all users of the LinkedIn Recruiter product worldwide. We look forward to sharing additional insights into the evolution of AI for recruiting at LinkedIn.
在此博客文章中,我们简要介绍了模型探索的历程以及LinkedIn上Talent Search系统所使用的体系结构。如图所示,这些模型对我们的关键业务指标产生了影响。但是,更重要的是,我们的会员和客户的成果得到了改善。最近,出于LinkedIn为全球劳动力的每个成员创造经济机会的目标以及客户对确保他们能够招聘多样化人才的强烈兴趣,我们还将性别代表排名作为我们人才搜寻的一部分面向全球LinkedIn招聘产品的所有用户的系统。我们期待与他人分享有关AI演变的更多见解,以便在LinkedIn进行招聘。
Acknowledgments
This blog post is based on the ACM SIGIR 2018 paper (slides) on talent search and recommendation systems at LinkedIn, an ACM CIKM 2018 paper on in-session personalization for talent search, an ACM CIKM 2018 paper on deep and representation learning for talent search, and a WWW 2019 paper on entity-personalized talent search models with tree interaction features. We would like to thank all members of the LinkedIn Talent Solutions team for their collaboration in deploying our work as part of the launched products, and the following people for insightful feedback and discussions (alphabetically ordered): Abhishek Gupta, Ajit Singh, Alex Shelkovnykov, Alexandre Patry, Alice Wu, Anish Nair, Anthony Hsu, Aparna Krishnan, Arashpreet Singh Mor, Ashish Gupta, Badrul Sarwar, Baolei Li, Bo Hu, Brian Schmitz, Busheng Wu, Chang-Ming Tsai, Dan Liu, Daniel Hewlett, David DiCato, Divyakumar Menghani, Erik Buchanan, Fan Yang, Fei Chen, Florian Raudies, Gil Cottle, Gio Borje, Gungor Polatkan, Gurwinder Gulati, Haitong Tian, Hakan Inan, Hong Li, Huiji Gao, Janardhanan Vembunarayanan, Jared Goralnick, Jieqing Dai, Joel Young, Jonathan Pohl, Joshua Hartman, Jun Xie, Keqiu Hu, Kexin Fei, Lei Ni, Lin Yang, Luthfur Chowdhury, Luxin Kang, Mathuri Vasudev, Matthew Deng, Meng Meng, Michael Chernyak, Mingzhou Zhou, Patrick Cheung, Prakhar Sharma, Qinxia Wang, Rakesh Malladi, Ram Swaminathan, Rohan Ramanath, Runfang Zhou, Ryan Smith, Sai Krishna Bollam, Sara Smoot, Scott Banachowski, Sen Zhou, Shan Zhou, Shipeng Yu, Siyao Sun, Skylar Payne, Sriram Vasudevan, Tanvi Motwani, Tian Lan, Viet Ha-Thuc, Vijay Dialani, Wei Lu, Wen Pu, Wensheng Sun, Wenxiang Chen, Xianren Wu, Xiaoyi Zhang, Xuebin Yan, Xuhong Zhang, Yan Yan, Yen-Jung Chang, Yi Guo, Yiming Ma, Yu Gong, and Zian Yu.