Machine Learning for Recommender systems — Part 1 (algorithms, evaluation and cold start)
Recommender systems are one of the most successful and widespread application of machine learning technologies in business. There were many people on waiting list that could not attend our MLMU talk so I am sharing slides and comments here.
引言

You can apply recommender systems in scenarios where many users interact with many items.
你可以在许多用户与项目交互的场景中应用推荐系统。
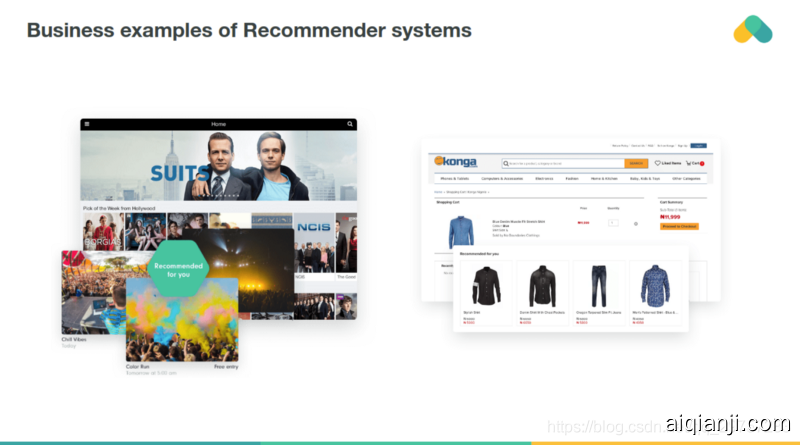
You can find large scale recommender systems in retail, video on demand, ormusic streaming. In order to develop and maintain such systems, a company typically needs a group of expensive data scientist and engineers. That is why even large corporates such as BBC decided to outsource its recommendation services.
你可以在零售、视频点播或音乐流中找到大型推荐系统。为了开发和维护这样的系统,公司通常需要一群昂贵的数据科学家和工程师。这就是为什么即使是像BBC这样的大公司也决定外包其推荐服务的原因。

Our company Recombee is based in Prague and develops an universal automated recommendation engine capable of adapting to business needs in multiple domains. Our engine is used by hundreds of businesses all over the world.

Surprisingly, recommendation of news or videos for media, product recommendation or personalization in travel and retail can be handled by similar machine learning algorithms. Furthermore, these algorithms can be adjusted by using our special query language in each recommendation request.
Algorithms 算法

Machine learning algorithms in recommender systems are typically classified into two categories — content based and collaborative filtering methods although modern recommenders combine both approaches. Content based methods are based on similarity of item attributes and collaborative methods calculate similarity from interactions. Below we discuss mostly collaborative methods enabling users to discover new content dissimilar to items viewed in the past.
推荐系统中的机器学习算法通常分为两类:基于内容的推荐方法和协同过滤方法,尽管现代推荐者将这两种方法结合在一起。基于内容的方法是基于项目属性的相似性和协作方法,从交互中计算相似度。下面我们主要讨论协同过滤方法,使用户能够发现与过去查看过的项目不同的新内容。

Collaborative methods work with the interaction matrix that can also be called rating matrix in the rare case when users provide explicit rating of items. The task of machine learning is to learn a function that predicts utility of items to each user. Matrix is typically huge, very sparse and most of values are missing.
协同过滤方法与交互矩阵一起工作,当用户提供项目的显式评分时,这种交互矩阵也可以称为评分矩阵。机器学习的任务是学习一个函数,它可以预测项目对每个用户的效果。矩阵通常很大,非常稀疏,而且大多数值都丢失了。

The simplest algorithm computes cosine or correlation similarity of rows (users) or columns (items) and recommends items that k — nearest neighbors enjoyed.
最简单的算法是计算行(用户)或列(项)的余弦或其他相关相似性,并推荐k个最近邻居喜欢的项。

Matrix factorization based methods attempt to reduce dimensionality of the interaction matrix and approximate it by two or more small matrices with k latent components.
基于矩阵因式分解的方法试图降低相互作用矩阵的维数,并将其近似为两个或多个具有k个潜在分量的小矩阵。

By multiplying corresponding row and column you predict rating of item by user. Training error can be obtained by comparing non empty ratings to predicted ratings. One can also regularize training loss by adding a penalty term keeping values of latent vectors low.
通过将相应的行和列相乘,你可以根据用户预测项目的评分。训练误差可以通过比较非空评分和预测评分来获得。还可以通过增加惩罚项,保持潜在向量的低值来调整训练损失。

Most popular training algorithm is a stochastic gradient descent minimizing loss by gradient updates of both columns and rows of p a q matrices.
最流行的训练算法是随机梯度下降算法,通过对p q矩阵的列和行进行梯度更新,使下降损失最小化。

Alternatively, one can use Alternating Least Squares method that iteratively optimizes matrix p and matrix q by general least squares step.
或者,可以使用交替最小二乘法,通过一般最小二乘步骤迭代优化矩阵p和矩阵q。

Association rules can also be used for recommendation. Items that are frequently consumed together are connected with an edge in the graph. You can see clusters of best sellers (densely connected items that almost everybody interacted with) and small separated clusters of niche content.
关联规则也可用于推荐。经常在一起消费的项目与图形中的边缘相关联。你可以看到一组畅销书(几乎每个人都与之交互的紧密连接的项目)和小的、分离的内容集群。

Rules mined from the interaction matrix should have at least some minimal support and confidence. Support is related to frequency of occurrence — implications of bestsellers have high support. High confidence means that rules are not often violated.
从交互矩阵中挖掘出的规则至少应该有一些最小的支持度(support)和置信度(confidence)。支持度与发生频率有关,比如畅销书有很高的支持度。高置信度意味着规则不会经常被违反。
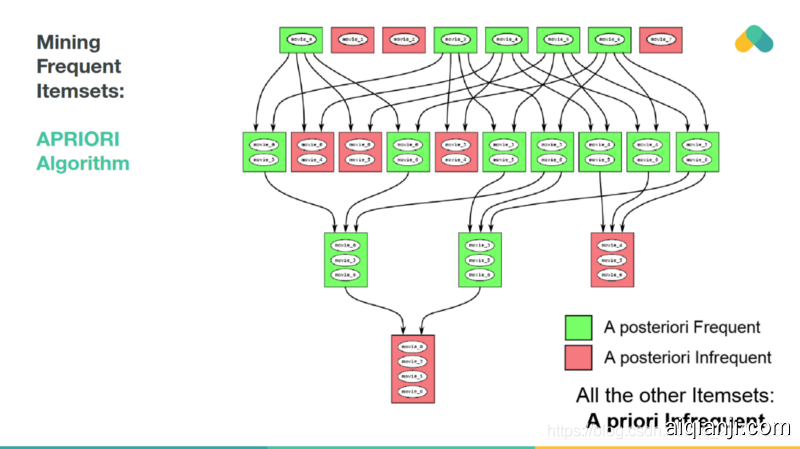
Mining rules is not very scalable. The APRIORI algorithm explores the state space of possible frequent itemsets and eliminates branches of the search space, that are not frequent.
挖掘规则的规模不大,先验算法探索了可能的频繁项集的状态空间,消除了搜索空间中不频繁的分支。
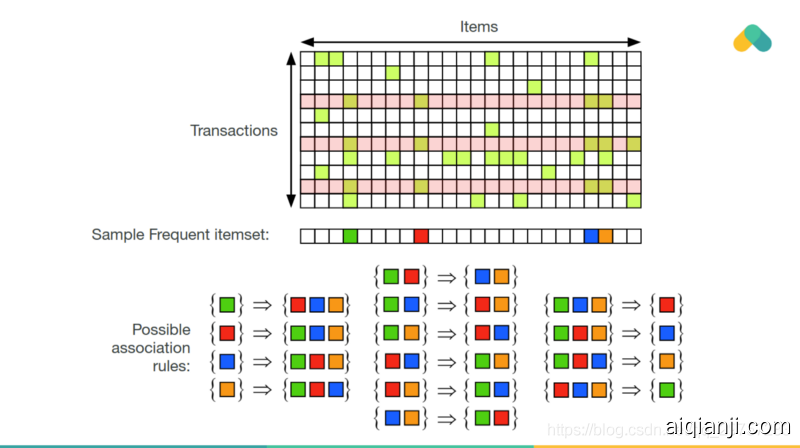
Frequent itemsets are used to generate rules and these rules generate recommendations.
频繁项集用于生成规则,这些规则产生推荐。

As an example we show rules extracted from bank transactions in the Czech Republic. Nodes (interactions) are terminals and edges are frequent transactions. You can recommend bank terminals that are relevant based on past withdrawals / payments.
例如,我们展示了从捷克共和国的银行交易中提取的规则。节点(交互)是终端,边缘是频繁的交易。你可以根据过去的取款/付款推荐相关的银行终端。
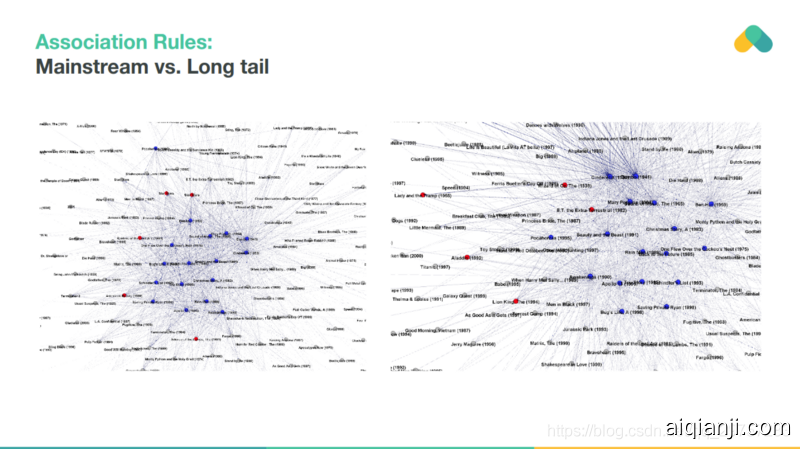
Penalizing popular items and extracting long tail rules with lower support leads to interesting rules that diversify recommendations and help to discover new content.
惩罚受欢迎的项目和提取支持度较低的长尾规则会产生有趣的规则,使推荐多样化并有助于发现新的内容。
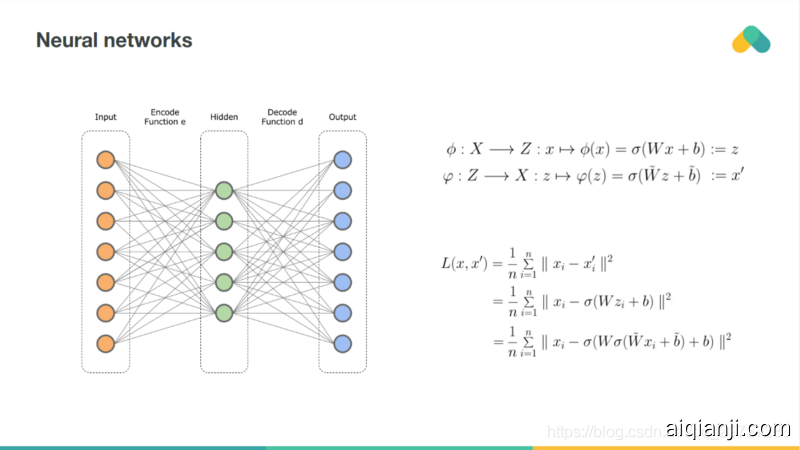
Rating matrix can be also compressed by a neural network. So called autoencoder is very similar to the matrix factorization. Deep autoencoders, with multiple hidden layers and nonlinearities are more powerful but harder to train. Neural net can be also used to preprocess item attributes so we can combine content based and collaborative approaches.
评分矩阵也可以用神经网络进行压缩,所谓的自编码器与矩阵分解非常相似,具有多个隐藏层和非线性的深层自编码器更强大,但更难训练。神经网络也可以用来预处理项属性,这样就可以将基于内容的方法和协同过滤方法结合起来。

User-KNN top N recommendation pseudocode is given above.
上面给出了user-KNN Top-N推荐伪代码。

Associations rules can be mined by multiple different algorithms. Here we show the Best-Rule recommendations pseudocode.
关联规则可以通过多种不同的算法来挖掘。这里我们给出了最佳规则推荐(Best-Rule recommendations)的伪代码。

The pseudocode of matrix factorization is given above.
上面给出了矩阵因式分解的伪代码。

In collaborative deep learning, you train matrix factorization simultaneously with autoencoder incorporating item attributes. There are of course many more algorithms you can use for recommendation and the next part of the presentation introduces some methods based on deep and reinforcement learning.
在协同深度学习中,结合项目属性与自编码器同时训练矩阵因式分解,当然还有更多的算法可用于推荐,本文的下一部分介绍了一些基于深度学习和强化学习的方法。
Evaluation of recommenders 推荐系统的评估

Recommenders can be evaluated similarly as classical machine learning models on historical data (offline evaluation).
推荐者可以与历史数据上的经典机器学习模型(离线评估)进行类似的评估。

Interactions of randomly selected testing users are cross validated to estimate the performance of recommender on unseen ratings.
随机选择的测试用户之间的交互作用被交叉验证,以估计推荐者在未见的评级上的性能。

Root mean squared error (RMSE) is still widely used despite many studies showed that RMSE is poor estimator of online performance.
尽管许多研究表明,均方误差(RMES)对在线性能的估计能力较差,但它仍得到了广泛的应用。

More practical offline evaluation measure is recall or precision evaluating percentage of correctly recommended items (out of recommended or relevant items). DCG takes also the position into consideration assuming that relevance of items logarithmically decreases.
更实用的离线评估措施是召回率(Recall)或准确率(Precision)评估正确推荐项目的百分比(不包括推荐项目或相关项目)。DCG还考虑到了假设项目的相关性对数下降时的位置。

One can use additional measure that is not so sensitive to bias in offline data. Catalog coverage together with recall or precision can be used for multiobjective optimization. We have introduced regularization parameters to all algorithms allowing to manipulate their plasticity and penalize recommendation of popular items.
我们可以使用对离线数据偏差不太敏感的附加度量。Catalog coverage以及Recall或Precision可以用于多目标优化。我们在所有算法中引入正则化参数,允许对它们的可塑性进行操作,并惩罚对流行项的推荐。

Both recall and coverage should be maximized so we drive recommender towards accurate and diverse recommendations enabling users to explore new content.
Recall和coverage都应该最大化,因此推动推荐系统向准确和多样化发展,使用户能够探索新的内容。
Cold start and content based recommendation 冷启动和基于内容的推荐

Sometimes interactions are missing. Cold start products or cold start users do not have enough interactions for reliable measurement of their interaction similarity so collaborative filtering methods fail to generate recommendations.
交互有时会丢失。冷启动产品或冷启动用户没有足够的交互来可靠地度量其交互相似性,因此协同过滤方法无法产生推荐。

Cold start problem can be reduced when attribute similarity is taken into account. You can encode attributes into binary vector and feed it to recommender.
当考虑到属性相似性时,冷启动问题可以减少。你可以将属性编码成二进制向量,并提供系统进行推荐。

Items clustered based on their interaction similarity and attribute similarity are often aligned.
基于交互相似性和属性相似性的项目聚类往往是对齐的。

You can use neural network to predict interaction similarity from attributes similarity and vice versa.
你可以使用神经网络从属性相似性预测交互相似性,反之亦然。

There are many more approaches enabling us to reduce the cold start problem and improve the quality of recommendation. In the second part of our talk we discussed session based recommendation techniques, deep recommendation, ensembling algorithms and AutoML that enables us to run and optimize thousands of different recommendation algorithms in production.
Continue to the second part of the presentation discussing Deep Recommendation, Sequence Prediction, AutoML and Reinforcement Learning in Recommendation.
有很多其他方法使我们能够减少冷启动问题,提高推荐质量。在第二部分中,我们将会讨论基于会话(session based)的推荐技术、深度推荐、集成算法和自动化,使我们能够在生产中运行和优化数千种不同的推荐算法。