大家晚上好!我是来自爱奇艺的算法工程师蒋紫东,很荣幸能参加今天这次活动,也欢迎大家参加这次关于ZoomAI视频增强技术的分享,这个也是我在爱奇艺的主要工作之一。
本次分享大概会有这四个方面:
第一、这个技术提出的背景暨我们为什么需要视频增强?
第二、我们对视频或者图像中各种增强技术的原理介绍,包括学术界的最新论文的介绍,以及我们自己的一些思考和尝试。
第三、介绍爱奇艺ZoomAI技术的框架,以及在各条业务线的应用情况。
第四、分享总结以及一些参考资料的陈述。
01
视频/图像增强技术的重要性及现状

现在我们先看我们为什么要视频增强。去年开始大家有一个共识,视频行业已经进入到叫“超高清时代”,去年央视也开播了4K超高新的电视频道,我们会发现市面上的硬件产品基本上超高清或者4K就是标配,不管是电视屏幕、机顶盒、VR设备等等。实际上,我们虽然有这么多的高清的硬件设备,但是其实我们并没有那么多的超高清的视频资源,甚至可以说很多视频资源的质量是非常低的。为什么会这样?我们总结了以下几个原因:
第一点原因,用户的行为不可控。大家都知道最近的UGC类的视频应用或者图片应用是非常火爆的,也就是用户可以自己拍摄、制作和上传很多的短视频和图片。比如说像微博、抖音、朋友圈等等,爱奇艺也有好多视频、姜饼、泡泡这样各类的应用,可是用户的行为不可控,用户缺少专业的拍摄器材和拍摄的技能。比如在暗光拍摄导致背景有很多噪点且画面过暗,比如图片在转播中经过多次压缩,导致有很大的压缩噪声。
第二点原因,本身的片源是非常老旧的。比如说下面的两个例子,左边的《渴望》是90年的,右边的《护士日记》是1957年的黑白电影。

因为以前的介质像VCD、DVD它们的分辨率都是在720P以下的。我们可以简单来看一下,比如这是《渴望》的效果,人物脸上很多噪点,背景也有很多划痕。可以看到脸上有很多的噪点,然后片子中也会有一些划痕,就是一条条的横线,而且看到细节也比较模糊,然后像这里的《护士日记》就可以看到明显的有很多的划痕白点。我们可以看到旁边的桌子上面一闪一闪的,有很多白的或者黑的,各种各样的划痕。这个原因就是因为可能是胶片本身的损伤,也有可能是在胶片转数字化的过程中引入了损伤,这样就会造成会出现右边的这些问题,比如说有划痕、有噪声、画面会抖动。
最后一点,用户主动选择低码流。一个客观存在的问题,就是哪怕这个质量再好,我也要看低画质,为什么?因为比如说可能到月底了,或者是我所在的我所在的地方网络信号不好,我不得不选择低码流的模式。既然选择了低码流,服务器就会尽可能的把分辨率给下降,也会加入更多的压缩,就会有产生很多的压缩噪声。
由此可见,产生低质量视频的原因是各种各样的。随着大家的追求越来越高,提高视频或者图片质量的需求也变得越来越迫切。我们可以看一下历年来的关于图像和视频增强的相关文献,可以看到它是逐步提高这么一个趋势。
02
视频/图像增强技术原理及面临的挑战

因为前面我们说到造成图片或者视频质量低下的原因是多维度的,其实针对于每一个维度都是学术界和业界研究的课题,我们今天会从这五个方面来讲:
超分辨率这个是解决分辨率低的问题;去噪锐化是解决有背景噪声或者压缩噪声的问题;色彩增强是解决色彩灰暗这样问题;插帧就是帧率低;去划痕就是由于胶片的损伤导致的视频上有很多的划痕,或者是白点,或者白块,或者水渍等这样的问题。

我们首先来看超分辨率的问题,这个问题的描述,我相信来听这个课的朋友们应该有所了解,就是一张低分辨率的图,过一个模块以后就变成一张高分辨率图。如果说我们用现在比较流行的深度学习的模型来完成这项,它一般来说是一个CNN的模型,得到一张高分辩率图,然后我们有一张真实的高分辨率图,两者之间取一个loss,把这个loss降到最小,来通过反向传递来优化CNN里面的系数。

主要面临两个问题:第一个就是CNN的结构设计,如何设计这个模型结构,使得可以有效的恢复或者创造出更多的像素。其实这里就是创造出像素,因为原来的像素点少,变成高分辨以后像素点多。
第二点就是loos函数如何选择可以使得图像的细节或者是边缘更加的清晰。
我们来看一下主流的几种做法:
第一大类,就是单帧超分。

输入是一张图片,输出是这张输入图片的高分辨率图片。这张图是来自于右下角DBPN的这篇文章的一个总结,我把它拿过来了。首先,左上角就是最原始的DNN的方法,就是一张小图,首先经过一种传统的插值处理放大,比如说双线性插值这种方法放大,放大以后再经过一个全卷积网络。这里最经典的就是SRCNN,是用深度学习来进行超分的开山之作,后面有它的进化型VDSR,VDSR主要的区别就是它最后训练的是两者的差,而不是直接生成张真实的图。这种全局残差后面也会用到,实测效不错。
左下角就是先经过全卷积,最后再经过一个上采样的过程上,这个上采样可以用反卷积,也可以用次像素,代表的就是FSRCNN和EDSR。它有一个好处,就是它做这个全卷积时输入图片尺寸是比较小的,所以首先第一个好处就是它的速度快。然后也给了放大这件事情一个训练的机会,就是我的放大并不是直接放大,它可以有训练系数。
右边这两个虽然是新的方法,但是其实它们是适合于放大两倍或两倍以上的,像上面像这个Lap这种放大,一听名字就知道说是先把图像进行金字塔分解,然后逐级放大,比如说你要放大八倍,那你就先放大两倍,再放大两倍,再放大两倍,而不是一次性放八倍。
右下角DBPN就是一张图先放大再缩小,再放大再缩小,然后中间的每一个模块之间都是利用类DenseNet这样的方法进行全部相连的,最后融合以后得到一个结果。DBPN自己文章中也有数据比较,它的性能在放大两倍的情况下,是不如EDSR的,只有在高倍数超分的时候才能在这种结构中体现出优势。代价就是它的运算的复杂度和消耗的时间以及对于内存显存的消耗都会增加。
第二类,根据多帧图像进行超分辨率。
因为很多情况下我们处理的视频,其实是可以利用视频的前后帧的关系,因为前后帧有更多的细节,我们就可以呈现出更多的细节。如何来融合前后帧的关系?一个方法就是把时间作为通道数。正常情况下我们一张图片有三个通道,如果有三张图片,其实就是九个通道,那么就把它当成是一个九个通道的东西,然后直接通过2D卷积来进行后续的处理,也可以将时间作为另一个维度,用3D卷积来处理。

第二种融合前后帧的方法就是利用光流,光流也是最近非常火,在视频的很多领域中都会用到的。凡是考虑前后帧关系的算法,有一大类就是利用光流的方法。我们先简单看看什么是光流,看一下左边的有这个人,他从背上拿出一把箭的时候,他的手肘不就是从这个位置变到了这个位置,其实这里的每一个像素点的运动就是光流。如果粗糙的理解就可以认为是一种运动估计。
因为有各种各样的网络可以学会光流,假设我们的光流已经学会了以后,我们怎么样来融合?就是TOFlow这篇文章提到,如果我们有这帧和它的前一帧和后一帧,我们可以根据两帧之间的光流来估计,根据上一针来估算出当前帧,也可以根据下一帧来估算出当前帧,这样我们就三个当前帧,就是真实的当前帧和两个估算出来当前帧,我们把这三帧合在一起,经过一个2D和3D卷积的处理,就能拿到最后的生成出来的超分辨率图。

我们现阶段的模型设计的结构是这样的,首先我们采用的是单帧处理,然后单次上采样,再全局残差。
因为我们也其实也比较了单帧和多帧的区别,发现其实从肉眼上来看,单帧的效果和多帧的已经非常接近,在这种情况下多帧的消耗会多很多,而且会有一些其他的影响,所以我们选择了单帧的处理方法。为什么只采用单次上采样?在我们的业务场景中,图片基本上就会放大两倍,不太可能会放大四倍,所以直接采用单次的就是最合算。用DenseNet的结构就是借鉴了DBPN的思想,引入更多的低层的特征。然后全局残差,因为在VDRI以后基本上大多数超分都会采用全局残差的形式。因为可以想象低分辨率图和高分辨率在低频的情况下基本上都是一致的,唯一有差别的就是那些细节的部分,这个加法就说明右边的这一图就是低频的成份,整个网络只要学习那些高频的细节就可以了。
关于loss函数的选择,一般情况下最常见的就是这种L1或者L2的loss,也就是mse或者mae,很多paper也讨论过了,像mse的loss会天生导致图像产生模糊,现在有一大类叫做GAN的loss,它是根据图像的分布来生成像素。GAN的loss在很多demo中可以说是非常的惊艳,但我们自己在使用过程中发现有两大问题,我们对于自动化的流程来说可能不是很合适:
第一个可能会导致语义不符的问题,我们可以看一下框里,就左边这个是没有加GAN的,右边这个是加GAN的,可以看到右边的这张图的确比左边清晰很多的。

但问题就在于“太清晰”了。最右边这张原图中真正的头饰其实是一个太阳,但经过GAN放大的图虽然很清晰,但是看不出太阳的样子。所以它改变了图的语义。而左边这张虽然它模糊,但是它只是看不清,但是没有改变语义。如果我们是针对UGC图片用户上传的图片,我们不能擅自更改用户的本意,在语义准确和画面模糊之间做个权衡,我们觉得语义准确更重要。
GAN的第二个问题会放大噪声。往往低分辨率图伴随着噪声,这些噪声可能会被GAN当成一个具体的东西被具象化。

我们最后的选择是mse加上一个梯度的loss。梯度的loss其实是动作预测网络中一个常见的loss,就是要求生成图和真实图的梯度要一致。因为梯度就是边缘。我们的超分很多情况下是想让边缘变得锐利,加入梯度的loss以后会使得整个网络的边缘倾向锐利。我们可以看一下下面这个例子,左边这个就是最普通的,然后这里就是不加梯度的los了,这边就加了梯度的loss,就是看到头发的就是边缘会更加的锐利一些。
下面我们可以看一个超分在视频中的例子,这个例子在去年爱奇艺世界大会上展示过,可以看到左边整体比较模糊,右边会清晰一些,就是从540P到1080P的一个视频。

之前介绍的是一个云端的算法,其实对于移动端来说采用深度学习的方法就不合适,虽然现在有tflite,ncnn这样的移动端深度学习框架,但是毕竟还没有跟机器是配得非常好,很多中低端的手机其实跑不动这种生成模型的。我们在移动端主要是考虑效率,那么我们就采用单层滤波器的方式来实现,进行训练和优化。

说完了超分以后我们再来说去噪的问题,图像中的噪声主要是背景噪声和压缩噪声,其实去噪和超分的网络结构是可以非常类似的,因为都是一个“图到图”的生成网络,所以前面讲过的东西基本上都可以相互借鉴。比如说右边也去引导全局残差这些东西。


其实对于去噪来说主要的问题有两个:
一个是去噪本身是一个低通滤波器,就是基本上可以近似为一个低通滤波器,如何在去燥的时候尽可能的保留住边缘和细节?
第二就是如何的模拟真实噪声,因为很多paper其实讲过,很多去噪的方法在人工合成噪声的测试集上非常优秀,因为他们训练的时候也是用人工合成造成的方法来训练的,比如说加一个高斯噪声,但是这个时候在真实的图片上可能就不行了,那么我们如何更好的模拟真实造成也是一大问题。

我们可以看一看两个去噪的经典网络,第一个是DNCNN,它就是一个全卷积的模型,就输入一张噪声图,经过多层卷积以后,最后出来一个全局的残差。它在训练的时候,训练集里面加入各种层次的高斯去噪,来模拟那种多造成混合的数据集。第二个是CBDNet,这是2019年的CVPR。它的网络分成两个部分,首先就来一张图以后先要估算一下,噪声是什么水平的,然后再把估算出来的噪声水平输入到第二个网络中,再加上原图,再来算出一个最终的生成图。它中间还引入一个不对称的loss,就是根据实验发现前面的噪声估计,如果同样是估不准,往小的估和往大了估相比,还是往大了估更好一点。不对称loss,就是两边的惩罚是不一致。

我们这边做的时候就是采取了一个端到端的网络同时完成去噪和锐化。噪声主要主要是背景噪声和压缩噪声。同时完成去噪和锐化就是为了弥补由于去造成的边缘模糊,网络结构和之前的超分是很类似的。
如何同时完成去造和锐化?其实大致的思想就是在训练集的时候加入一定比例的噪声和模糊,然后不断的去贴近真实的情况,然后不断的调整,然后来拿到一个比较好的效果。

可以看到一些真实图片的例子,绿色的手上周围的噪点没有了。然后右边《渴望》的图里比如说文字高亮,衣服的格子纹理会更加的清晰一些。

接下来我们来看下一个问题,就是色彩增强的问题,它主要是解决图片或者视频亮度不行,过亮、过曝或者色彩暗淡的问题,主流有两种方式,第一个是黑盒模式,这是一个端到端的生成模型,就是拿一张不好的图,经过这个网络以后,或者全卷积,或者unet,然后生成一张好的图,代表的比如DPE是18年的CVPR。前面这个网络是一个unet结构,输出一张图以后,然后如果我们有成对的数据科,就是有一张不好的图和对应的经过人工PS以后的好图,那么我们就可以用mse的loss+GAN的loss来做,如果我们没有成对的数据,就用cycleGAN的这种方法来做。为什么说它是黑盒模式?因为我们最终拿到的是一张增强图,我们也不知道它是怎么把一张坏图变成一张好图的。
第二类是白盒模式,它这个网络不是一个生成网络,而是一个回归模型。输入原图,输出各种色彩相关的参数,接下来就是只要用正常的图像处理的方法来对原图进行处理就可以了。我们可以参见微软提出的这个exposure的方法,它里面融合了强化学习和GAN,一步步的把一张坏图变成一张好图,为什么强化学习?这跟下棋一样,比如有12个棋子,每个分别到底应该先做哪一步、后做哪一步,每一步采用的量是多少,都可以调整。

我们可以来总结一下这两个方法,首先,黑盒模型它是比较容易训练的,因为它就是生成模型,之前用的生成模型都可以训练。但是它的问题是色块中有可能出现异常值可能导致语义不符的问题。毕竟卷积的原理导致了,输出的像素值除了和原像素值相关,还和感受野中其他像素值相关。第二个问题是如果这个原图非常大的话,这个时间会非常慢。
白盒模型其实更符合人类PS的习惯,拿到一张图之后只需要知道调节哪些参数来改变就可以了。而且更适合处理视频的情况。但是它的问题是训练很难收敛,而且效果上那些最好的例子中可能还不如黑盒的好。

为了线上模型的求稳,我们自行设计了一个和exposure相比简化了很多的白盒版本。首先,我们不再引入强化学习了,我们只处理这三个量:曝光度,饱和度和白平衡。因为经过我们大量的实验发现,这三个值对于调节图片的色彩最重要。然后我们固定它的顺序。最后我们在求loss的时候有两个loss,第一个loss是增强图与真实好图的mse,因为我们有一些成对的数据集,比如Adobe的FiveK。第二个loss是色彩调整参数的mse,这个真值是如何得到的呢?我们也可以做一些自建的数据集,就是我们拿到一张好图以后,刻意把它的曝光调低、饱和调低,这时其实我们知道应该加多少的曝光和饱和能把它补回来。所以我们还可以把这两个loss给融合,一方面来拿到这个mse的loss,另外一方面让这些回归的loss也要小,这样可以使得整个模型比较稳定。同时,它的计算量很小,一张大图缩小到64×64来处理就可以了。

来看最后处理的效果,第一列和第三列是原图,右边两列是增强过的图。我们对于亮度、饱和度、白平衡的调整以后,可以看到效果还是可以的。

接下来的问题是如何在视频处理中保持帧间的一致。我们的视频很多情况下都是逐帧做的,怎么保证这帧比如变的这个红色是正红色,下一帧变的也应该是正红色,如果一会儿变得比较深,一会儿比较暗的话,就会发现色彩在抖。怎么解决这个问题?公开论文上讨论这个问题的很少,我们则设计了一个解决方案:先过场景切分,再进行白盒模型。就是一个视频帧经过场景切分以后,我们可以分为不同的场景,这个场景切分的依据就是发现画面色彩色彩的突变点,然后我们在每一个场景中选取一帧来进行白盒模型得到参数,这个场景中所有的帧都用同样的参数来进行色彩增强就行了。

我们可以看个简单的视频例子,对《渴望》做的色彩增强,比如树叶会更加绿。
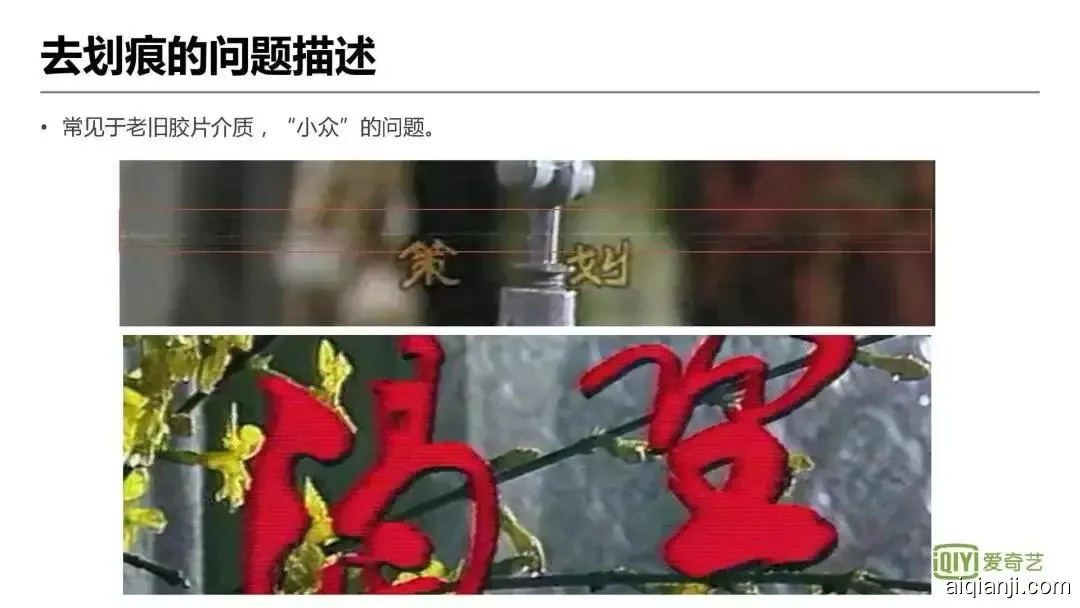
说完了色彩增强,下面看去划痕。去划痕其实是一个比较小众的问题,相关的论文比较少,它主要是因为胶片本身介质受到了损伤。像这里可能有人在胶片上划了一下,最后播出来时就会有一道划痕,或者在读取时受到磁头的干扰或者什么,出现了这种上下波纹会动的情况。

此类问题的解决方法,经典的方法是两步走的,首先是划痕的检测,然后将划痕去除,划痕的检测大多数情况采用直线检测的方式,直线检测就是通过找到空间中的竖线、横线、直线,然后再利用空间插值或者时间的插值,把这个线用别的像素给补上去。它的缺点比较明显,第一,如果这个划痕不是直线,它是个水渍,它是个白点,它是个弯弯曲曲的,可能效果就不行了。第二,画面本身可能是有水平线或者竖直线的,比如电线杆或者桌子上的纹理,那么就会误识别的把它去掉。

那么怎么处理这个方法呢?我们可以借鉴之前超分中讲到的光流法来设计,但是这里有一个前提,就是划痕只可能在这个帧的这个位置出现,在前后帧的同一个位置是不会出现的。这是划痕产生的原理决定的,因为不可能两个胶片真的这么凑巧的在同一个位置产生一模一样的划痕。我们有了这样的前提以后就可以设计上述的模型,利用光流来估算某一帧,然后进行融合。
但是这有一个问题,就是我们怎么保证这前后2k帧是在同一个场景的?因为正常视频中有剪辑的,会出现场景切换,这时我们刚才讲到的场景算法又可以来用一下。我们可以看看最后的效果。


最后一个问题讲的是插帧,插帧的技术其实也是非常好理解的,就是原来的视频帧率比较低,我们如何提高视频的帧率,使得观影体验更加流畅,比如在体育直播,或者动画片,或者打斗的动作片、武打片里可能用得比较多一些。主流的方法基本都是这样的,通过光流估计出,然后经过warp、经过融合,和之前去划痕的结构非常像。

比如CVPR18年的这篇,可以看到它这边是光流,右边是融合,它的创新点在哪里?就是加入了一些边缘提取,做了一些边缘特征,要保证最后合成出来的、插出来的那帧也有比较好的边缘。这篇现在还没有开源实现的,我们在这个模型的基础上做了一些裁减,因为右边这个实在是太庞大了。我们简单看看效果左边的这个原视频,汽车滑过去看到一卡、一卡、一卡,右边的就会比较流畅。

03
介绍ZoomAI技术实现和应用
第三部分是ZoomAI的框架和应用的介绍。
ZoomAI图片解决方案。针对于图片的,它在工具包里有三个——超分辨率、去噪锐化、色彩增强。因为它们都是对单张图片来做的,输入一个图片以后,这三个接口可以做得都一样,这样各条业务线就可以自由的配置,到底要用什么工具以及它们的顺序是怎样的,或者各自的参数是怎样的,可以做到灵活配置,这是1.0方案。

在2.0中我们加入了内容的理解,大家想想现在很多图片,比如拍人像模式时背景是虚化的,这时背景就不应该进行锐化操作,如果这张图片中是有文字的,文字区域的锐化又可以做得特别大胆。所以在2.0中我们先经过文字检测,检测出文字区域,也通过一个前景提取网络来检测出这张图片的前景区域和背景区域,然后每一个区域的这个模块都是之前1.0那个模块,最终得到一个结果。
我们看看示意图,比如这张图里谢娜本身是前景区域,文字的部分就是文字区域,后面其他的就是背景区,这样来进行融合。

ZoomAI视频解决方案。这个视频方案有多个工具,首先是两个预处理的工具——场景切分和重复帧的去除,然后是帧间的一些算法——去划痕和插帧,然后是单帧的算法——对于单张图片进行处理的超分、去噪锐化、色彩增强等。每个视频解压成图片,然后去除掉重复帧,然后经过场景切分,每一个场景分别做帧间的算法和单帧的算法,最后和原来的音频一起合成,变成最终的视频。中间这个部分是根据业务线的逻辑可以随时调整。

各项业务与使用场景。可以看到ZoomAI已经包含了多个算法模块,应用在了爱奇艺的多条产品线中、多个应用场景中。

下面介绍一些已经有的应用场景。首先,是这个国剧修复的项目,主要用到去噪锐化和去划痕这两个模块,经过我们处理后人脸显得更光滑,背景没有噪声,文字上不会有抖动,文字也更加的突显。
这里AI处理相对于人工处理最大的优势就是效率提高、成本降低,提高效率500倍。第一期的国剧修复成果已经在春节期间上线了。现在正准备在暑期上线包括四大名著在内的第二批经典电视剧。

这是老旧综艺视频的处理,评书《乱世枭雄》全集刚在爱奇艺上线,它原来的分辨率很低,只有240P,而且有很多锯齿,经过修复以后清晰度提高不少,使它达到了上线的标准。我们可以看一下例子,桌子这里的纹理更加的清晰,左边的原图就会比较模糊。
下面有一个动画片的增强,我们用到了超分的模块和色彩增强,右边的红色就会更加的红。我们看一下视频的效果,右边的草地会更加的绿一些,整体的色彩更加的鲜艳。这里的红色,包括之后会出现的黄色,整体会更加鲜艳。而且采用了场景切分以后,色彩不会抖动,很平稳。

这是对3D动漫《四海鲸骑》的插帧效果展示。左边这个是原始的,可以看到这个船在转弯时一卡一卡的,右边的明显比较流畅,特别是镜头拉远时,左边有很强的卡顿感,右边就会很流畅。

下面是对各个频道封面图增强的效果,现在大家打开爱奇艺看到的封面图基本都是经过ZoomAI增强的,用到的模块是去噪锐化和色彩增强。
04
进阶资源推荐及经验分享

这里重点讲一下关于工程思维的问题。学术圈与工程应用这两个群体的重点不同,前者主要精力花在模型设计和创新上,而工程应用最多的时间花在了数据与训练上。
我们在业务中最重要的一点就是数据,与kaggle竞赛不同,我们都没有现成的数据集,需要凭借各种工程技术去收集反应实际应用场景的数据。数据的好坏极大的影响了最终模型的效果。然后对于模型的结果,PSNR等指标可以作为参考,但是最终还是看主观感受。我们在超分和插帧的训练中,遇到很多A比B指标好,但是主观感受B比A好的情况。毕竟最后呈现给用户的就是主观感受。这也是现在的评价指标的偏差,GAN相关论文已经阐述了很多,我们也在研究这个问题。
对于模型的选择,我们更看重模型的稳定性和泛化能力。毕竟是一个上线运行的服务,而不是为了一个惊艳的demo效果。当然在选择和设计模型时,也需要考虑更重约束,比如模型大小本身的约束、执行速度的约束、用什么框架来支持等等。最终在效果和效率之间找到一个平衡点。
最后是我之前提到那些算法的论文出处,有兴趣的朋友可以进一步看一看,这个就是今天大致的分享内容了。
Q
&
A
以下是蒋紫东老师对于用户问题的回答。
问:超分辨率用传统的方法进行图片细节的增强,有哪些客观指标可以评价不同增强方法的效果,还是只能主观评价?
答:客观指标可以看一些趋势,做一些快速的判断。但是最后确定效果,还是应该引入主观评价。爱奇艺就是有完整的质检团队来做介质质量的判断。除非你是打比赛,如果你是打比赛的话,它用什么客观指标,你就用什么客观指标。但如果是真实应用的话,主观的评价更重要。
问:去划痕的流程里有一个融合CNN,这个CNN是用什么数据集训练的?
答:去划痕的数据是我们自己生成的数据,就是我们可以拿到很多视频帧的片段,然后我们自己把划痕加进去,划痕就是不同形状的、不同颜色的块或者线。还有一个方法,大家可以试一试,现在很多编辑软件可以加入老电影效果,也可以用这个方法把划痕加进去。
问:去噪的训练数据是如何构造的?怎么模拟真实噪声?模型是实时处理吗?
答:现在的去噪模型不是实时的,但可以实时,实时的话就需要把网络做得更简化。怎么模拟真实噪声?真实噪声是这样的,其实可以看一个香港理工大学的PolyU数据集,这是一个真实噪声的数据集,它是通过一个固定的照相机对一个场景多次狂拍,狂拍了以后每一帧都有噪声,然后再取个平均以后就觉得那是真实图片,我们的数据集一方面是用了这个,另外一方面是自己加入了不同的高斯噪声和压缩噪声尝试。
问:去噪的时候如何同时训练去噪和锐化?
答:在数据集上设计加入不同比例的噪声和高斯模糊。
问:对于无参考指标的视频,怎么判断当前视频的质量好坏?是否进行增强、去噪和锐化?
答:这就是我们正在做的视频质量评价的东西,可以判断视频的噪声等级,模糊等级,用来指导后面的增强。现在线上的短视频增强中就已经加入这么一个模块,只会对于评价不那么好的视频进行增强处理。
问:ZoomAI是爱奇艺开发的一个框架吗?
答:ZoomAI应该是爱奇艺开发的一个介质增强解决方案,是对视频或者图片进行增强的,它本身由多个算法模块组成。
问:超分的梯度loss是如何选取的?
答:梯度loss就是指,生成图和真实图的“梯度”的mse一致。因为梯度就是边缘,说明除了让它平缓的地方接近以外,更要强调它梯度的部分接近。这时有两个loss,两个loss融合起来肯定有一个权重的参数,来调节权重的参数,使得在最好的场景下效果最好就行。
问:手机终端的超分功耗怎么解决?
答:手机终端相当于我们没有用一个深度学习的框架,我们用的是自己在GPU上自己写的SDK,所以它的功耗可以自己控制。如果用深度学习的话,可能这个功耗就有点问题。
问:明明移动端AI模型那么多,为什么超分不能用深度学习?
答:这是生成模型和回归或者分类模型的区别,生成模型的复杂度和要生成的图片面积呈正比。,而做图像增强,图片的目标分辨率肯定不会太小,所以模型就简单不了、运算量小不下去。而如果你指分类的问题或者简单的回归问题,可以把原始的图片缩到很小,这时你的运算量就没有那么大。就好像我们色彩的白盒处理那样。
问:去噪是一个模型吗?还是不同的噪声有不同的模型?
答:这里我们现在做的是有多个模型的,其实前置会有一个判断,会根据噪声的判断来决定采用不同配比的模型。
问:视频打分数据集是什么?
答:数据集是我们爱奇艺内部的,通过我们的质检团队会有很多这样的数据。
问:对于NIMA这种图片评价算法怎么看?
答:觉得有参考价值,但是不能作为硬指标判断。因为它是第一篇用CNN来做质量评价的,而且效果上也还可以。如果对于同一张图片不同处理的时候这个评价还具有参考价值,但是如果对于多种图片,因为图片有可能是风景,有可能是人物,有可能是一个杯子,这时因为数据集的局限性,可能这个分数就没有那么可信了。
问:色彩增强会进行场景分类吗?
答:其实是会有的,分成了5类,人物,风景,美食,卡通,其他。
问:关于ZoomAI可以实时处理实时显示吗?
答:,如果是一个纯实时的视频流的话,那么就是手机端那个,是实时显示的。其它的没有必要,如果我们只在服务器端做的话没有必要做到实时,只需要把视频上传,最后生成一个好的视频就可以了。
问:锐化和降噪处理的顺序?
答:因为它们是一起处理的,没有顺序区别,是一个模型直接出来结果的。
问:场景风格有用深度学习的吗?
答:这个方面没有特别的去研究,觉得可能是可以用的,但是对于我们的业务来说,不需要这么复杂。比如对色彩增强来说,我们就想分割出色彩的强烈变化,哪怕这个场景没有变化,突然开灯那一下,还是客厅的场景,但是色彩发生突变,这时我们也希望它判断出来场景发生变化,所以我们用色彩这个维度来做相似度判断,效果是不错的。
问:如何缩小模型放进移动端?
答:这个其实是一个很大的问题,其实有很多论文都在讲这个问题。首先就是如果去分类或者什么的话,就先选择那种天生就是为移动端设计的,像MobileNet等等这样的结构,会好放进去很多。如果对于生成模型的话,确实只有大刀阔斧的裁剪了,把它的中间特征的层数给减小和通道数减小。
问:我们现在的ZoomAI有应用在不同地方吗?
答:有应用在移动端实时跑的,像之前说的手机端和爱奇艺播放器的PC端。以及之还有一部分是在后端进行介质增强的,用来代替人工修复或者人工增强。
问:训练样本一般需要多少?
答:这个是根据任务以及能拿到多少,有一些就比较容易,像去噪,我记得是200万的图片,有一些数据不那么容易拿到的就会少一些。
问:视频插帧以后,25变到50fps,视频增长了1倍,对应的音频也要插值吗?
答:音频不用插值,因为音频的采用率没有变,还是按原来那样。插帧了以后时长是不变的,插帧了以后还是1小时,音频也是1小时,你只要把这两个合起来就可以了。
谢谢大家!