简介
- 2022年11月,OpenAI推出了一款AI聊天机器人程序,其强大的问答能力瞬间引爆全网关注度。
- 组成部分:GPT3.5 + 大型语言模型(LLM) + 强化学习微调训练
- 实现方法:目前没有开源,也没有对应论文,仅在试运行推广收集数据。看实现方式可参考其前身 InstructGPT(GPT+RLHF:模型参数量1.3B远小于GPT-3的 175B),ChatGPT在其基础上可以减少有害和误导性的回答。
- 优势:相比较其他聊天机器人,ChatGPT可以记住之前和用户对话的内容,且输入内容由审核API过滤避免有冒犯性的言论(如种族注意或性别歧视)
- 局限:Reward围绕人类监督而设计,可能导致过度优化,从而影响性能(古德哈特定律)。比如训练中审核者都偏向于更长的答案。
可参考的官方链接
-
官网(可试用,需国外手机注册):https://openai.com/blog/chatgpt/
-
OpenAI的RLHF博客:https://huggingface.co/blog/rlhf
-
由于ChatGPT没有开源,我们只能通过InstructGPT来近似了解ChatGPT的实现
(1)InstructGPT blog:https://openai.com/blog/instruction-following/
(2)InstructGPT paper:https://arxiv.org/abs/2203.02155
(3)InstructGPT code:https://github.com/openai/following-instructions-human-feedback
-
大型语言模型Large Language Model(LLM)一般使用仓库:https://huggingface.co/
使用的数据集
- 开源数据集 TruthfulQA 和 RealToxicity
什么是GPT
-
Generative Pre-trained Transformer (GPT) 是一个深度学习模型,用互联网语料数据训练,可以用于问答、文本摘要生成、机器翻译、分类、代码生成和对话 AI。
-
历史
(1)2018 年6月,GPT-1 诞生(参数量117M,约1.1亿),这一年也是 NLP(自然语言处理)的预训练模型元年。性能方面,GPT-1 有着一定的泛化能力,能够用于和监督任务无关的 NLP 任务中。其常用任务包括:推理(判断两个句子是包含、矛盾、中立关系)、问答(输入文章和几个答案,选择一个答案)、语义相似度识别(两个句子语义是否相关)、分类。GPT-1在未经调试的新任务上具有一些效果,但泛化能力远远低于微调过的,所以只能算个工具不能算对话式AI
(2)2019年2月GPT-2如期而至,没有对网络做结构创新,仅仅是加大网络参数(参数量1.5B,15亿),大力出奇迹,除了阅读理解之外,在摘要、聊天、续写、编故事、假新闻等都非常强。
(3)2020年5月,GPT-3出现了,作为一个无监督模型(现在经常被称为自监督),几乎可以完成NLP绝大部分任务,比如面向问题搜索、阅读理解、语义推断、机器翻译、文章生成、自动问答,尤其在翻译上能达到无法辨认机翻的程度。让人看到了AGI的希望
(4)据说,GPT-4 会在明年发布,它能够通过图灵测试,并且能够先进到和人类没有区别,除此之外,企业引进 GPT-4 的成本也将大规模下降。
![1.png]()

什么是ChatGPT
-
本质是一个对话模型,它可以回答日常问题、进行多轮闲聊,也可以承认错误回复、挑战不正确的问题,甚至会拒绝不适当的请求。在上周公布博文和试用接口后,ChatGPT很快以令人惊叹的对话能力“引爆”网络。
-
主要特点:
(1)有强大的语言理解和生成系统
(2)降低人类学习成本和时间成本,可以帮助人类快速改写查错,生成小说摘要,定位代码bug
(3)具有安全机制和去除偏见的能力:对于偷东西的行为表示责怪,对于模糊的提问圆滑的回答,对于未知的问题拒绝回答
-
主要缺点
(1)仍存在一些简单的逻辑错误,比如把numbers这个字母数量算成8个。但比GPT3好很多,多轮对话下来还是能修正。
(2)有时候会给出看似合理,但是并不正确甚至荒谬的答案,如果用户本身对答案未知,容易被误导
(3)抵抗不安全prompt的能力比较差,还存在过分猜测用户意图的问题,而不是进一步的提问
(4)容易回答废话较多,固定句式,主要是因为构造训练数据时候,用户倾向于选择更长的回复。
-
和InstructGPT的区别:InstructGPT整体流程和ChatGPT流程基本相同,但是在数据收集、基座模型(GPT3 vs GPT 3.5)以及第三步初始化PPO模型时略有不同。
-
ChatGPT是站在InstructGPT以及以上理论的肩膀上完成的一项出色的工作,它们将LLM(large language model)/PTM(pretrain language model)与RL(reinforcement learning)出色结合证明这条方向可行。当然,这也是未来还将持续发展的NLP甚至通用智能体的方向。
-
ChatGPT应用:
(1)ChatGPT对于文字模态的AIGC应用具有重要意义:包括但不限于内容创作、客服机器人、虚拟人、机器翻译、游戏、社交、教育、家庭陪护等领域。比如机器翻译以助手问答的形式出现,甚至只是翻译个大概
(2)ChatGPT作为文字形态的基础模型,自然可以与其他多模态结合:比如Stable Diffusion模型,利用ChatGPT生成较佳的Prompt,对于AIGC内容和日趋火热的艺术创作。
(3)ChatGPT可以作为搜索引擎的有效补充,从效果上来说为时尚早。有答案的query对结果排序就好,没有答案的query也没人能保证ChatGPT是不是对的。
(4)ChatGPT本身的升级:与WebGPT的结合对信息进行实时更新,并且对于事实真假进行判断。现在的ChatGPT没有实时更新和事实判断能力,而这如果结合WebGPT的自动搜索能力,让ChatGPT学会自己去海量知识库中探索和学习,预测可能会是GPT-4的一项能力。
-
ChatGPT思考:
(1)基于LLM和RLHF,是非常有趣的方向,RL大概率在即将发布分GPT-4中扮演关键角色
(2)目前没有任何信息能确定ChatGPT的规模大小,最早的GPT-3代号Davinci大小175B,InstructGPT的模型代号是Davinci-text-002/003属于GPT3.5,GhatGPT可能是其中一个模型微调得到的,因此猜测应该也是千亿模型。
(3)ChatGPT不算突破式的创新,是近两年业界发展的成果汇总,同一时期的工作还有Deepmind的Sparrow和Google的LaMDA,效果与ChatGPT应该不相上下。
(4)每次聊天过程需要几美分的成本(GPT3.5(Davinci)的成本推测:1k tokens≈700 words为0.02美元)
ChatGPT历史
- 2017年6月的OpenAI Deep Reinforcement Learning from Human Preferences工作就提出了RLHF(reinforcement learning from human feedback )的思想,核心思想是利用人类的反馈判断最接近视频行为目标的片段;通过训练来找到最能解释人类判断的奖励函数,然后使用RL来学习如何实现这个目标。

- 2019年GPT2问世后,OpenAI 就尝试了GPT2+PPO:
(1)NeurIPS 2020的 Learning to Summarize with Human Feedback
(2)三步走的核心思想:收集反馈数据 -> 训练奖励模型 -> PPO强化学习。
(3)RLHF第一阶段是针对多个候选摘要人工排序(这里就体现出OpenAI的钞能力,按标注时间计费,标注过快的会被开除);第二阶段是训练排序模型(依旧使用GPT模型);第三阶段是利用PPO算法学习Policy(在摘要任务上微调过的GPT)。
(4)文中模型可以产生比10倍更大模型容量更好的摘要效果。但文中也同样指出,模型的成功部分归功于增大了奖励模型的规模。但这需要很大量级的计算资源——训练6.7B的强化学习模型需要320 GPU-days的成本。

- 2020年初的OpenAI的Fine-Tuning GPT-2 from Human Preferences可看出,它同样首先利用预训练模型来训练reward模型,进而使用PPO策略进行强化学习。整体步骤初见ChatGPT的雏形!

- 2021年底OpenAI的提出 WebGPT,核心思想是使用GPT3模型强大的生成能力,学习人类使用搜索引擎的一系列行为,通过训练奖励模型来预测人类的偏好,使WebGPT可以自己搜索网页来回答开放域的问题,而产生的答案尽可能满足人类的喜好。
什么是RLHF
-
Reinforcement Learning from Human Feedback
-
RLHF是Hugging Face这家美国公司(最著名的是构建了Transformer库)在一篇发布的博客中提出的概念,旨在于讲述ChatGPT背后的技术原理。
-
过去几年里,基于prompt范式的AI生成模型取得了巨大成功,以语言模型LM为例,大多采用『自回归生成』方式,通过循环解码的方式基于上下文信息预测下一个词,用交叉熵来计算每个词的loss,但token-level的loss不能很好的刻画整体输出质量,人们往往用BLEU或者ROUGH等评价指标来刻画模型输出和人类偏好的相近程度。所以如果能直接用这些指标作为reward,引入RL训练去微调LM,理论上比交叉熵的监督学习训练方式更好。
-
RLHF训练过程分为3个核心步骤:
(1)预训练语言模型(LM):这些语言模型往往见过大量的 [Prompt,Text] 对,输入一个prompt(提示),模型往往能输出还不错的一段文本。可以在人工精心撰写的语料上进行微调,但不是必要的,因为成本非常贵
(2)收集数据并训练奖励模型:一个奖励模型(RM)的目标是刻画模型的输出是否在人类看来表现不错。即,输入 [提示(prompt),模型生成的文本] ,输出一个刻画文本质量的标量数字。OpenAI的Prompt数据主要来自那些调用GPT API的用户。奖励模型可以基于预训练语言模型热启,在 [x=[prompt,模型回答], y=人类满意度] 构成的标注语料上去微调,也可以直接随机初始化在语料上训。标注人员的任务则是对初始语言模型生成的文本进行排序『pair-wise』,而不是直接打分,因为不同标注人员评价标准不一。有趣的是,奖励模型的大小最好是跟生成模型的大小相近,这样效果会比较好。
(3)通过强化学习微调 LM:策略就是基于该语言模型,接收prompt作为输入,然后输出一系列文本(或文本的概率分布);而动作空间就是词表所有token在所有输出位置的排列组合(单个位置通常有50k左右的token候选);观察空间则是可能的输入token序列(即prompt),显然也相当大,为词表所有token在所有输入位置的排列组合;**奖励函数(reward)**基于RM模型,再叠加一个约束项。约束项基于前面提到的预先富集的数据,从里面采样prompt输入,同时丢给初始的语言模型和我们当前训练中的语言模型(policy),得到俩模型的输出文本y1,y2。然后用奖励模型RM对y1、y2打分,判断谁更优秀。显然,打分的差值便可以作为训练策略模型参数的信号,这个约束项信号一般通过KL散度来计算“奖励/惩罚”的大小,loss=r(θ) - λ·r(KL),目的是为了不要让模型通过『取巧』的方式小修小改骗RM的高额RL奖励。
-
OpenAI的第一个RLHF模型是InstructGPT,用小规模参数版本的GPT3
-
DeepMind的第一个RLHF模型则使用了2800亿个参数的Gopher模型
-
RLHF的局限性:仍然可能输出有害或者事实上不准确的文本。人类标注成本非常高昂,RLHF最多达到标注人员的知识水平。PPO算法已经比较老了,但目前没有其他更好RL算法来优化RLHF了。
RLHF整体框架(参考InstructGPT)
根据OpenAI的思路,RLHF里分3步:
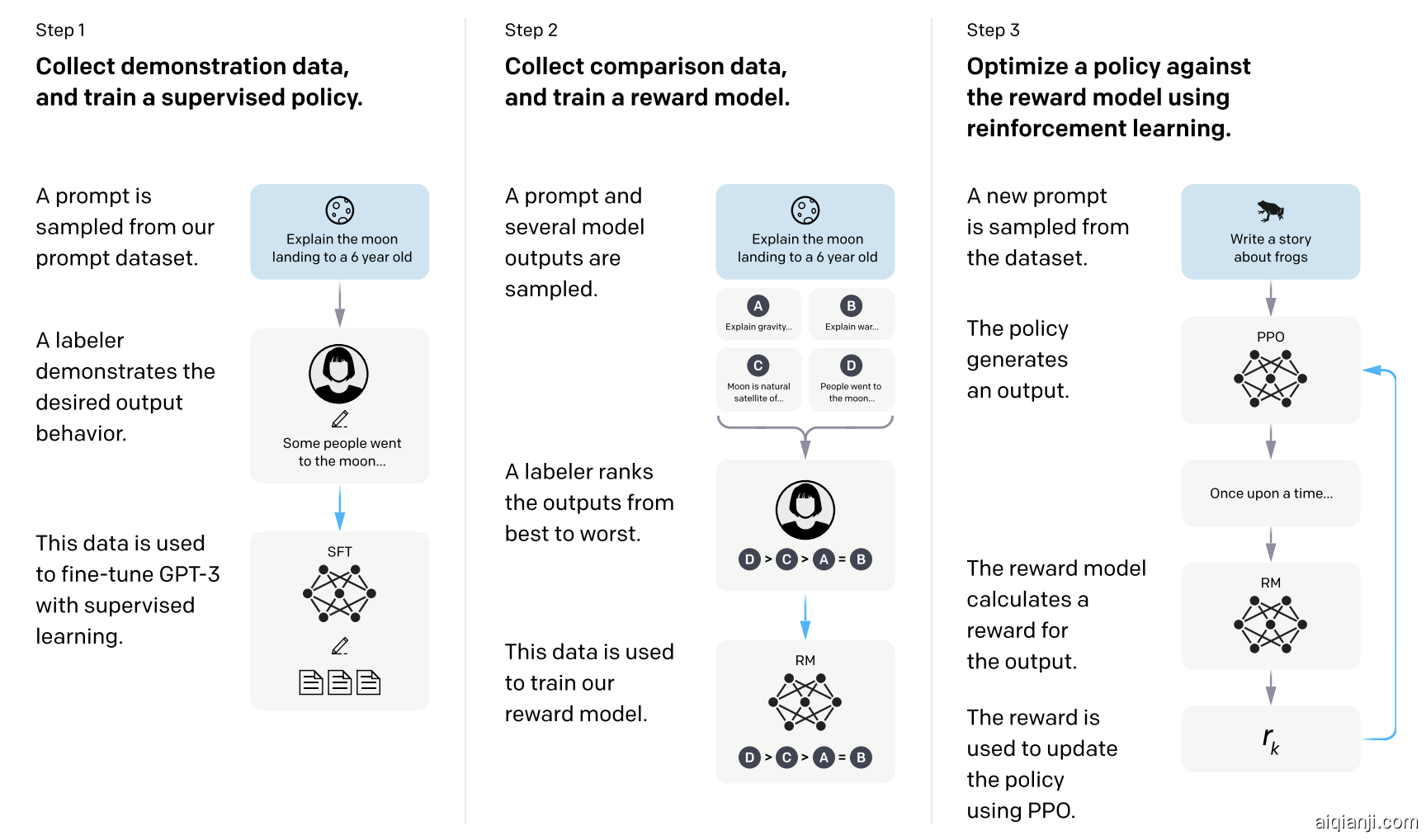
InstructGPT
- 1、花钱招人给问题(prompt)写回答(demonstration),然后finetune一个GPT3。这一步大家都懂,就不用说了。这一步可以多训几个版本,第二步会用到。

- 2、用多个模型(可以是初始模型、finetune模型和人工等等)给出问题的多个回答,然后人工给这些问答对按一些标准(可读性、无害、正确性blabla)进行排序,训练一个奖励模型/偏好模型来打分(reward model)

(1)不直接打分是因为主观需要归一化,从排序变成奖励分数用到了Elo排名系统打分
(2)RM模型一般直接用LM+回归,可以从零训练也可以用老LM做finetune,RM模型和LM模型需要大小差不多,因为它俩的输入都是所有文本,需要差不多的理解能力
(3)除了用Elo打分,也可以对偏序样本直接用pairwise Learning to Rank来打分。
- 3、用强化学习训练上面那个finetune后的GPT3模型。用强化学习做LM训练的一种思路是用Policy Gradient做,这一块OpenAI用的是他们在17年提出的PPO算法,即Proximal Policy Optimization。

(1)policy是给GPT输入文本后输出结果的过程;
(2)action space是全词表(~50k);
(3)observation space是输入文本序列的空间(全词表大小 x 序列长度);
(4)reward function则是一个基于RM输出的一个函数。具体而言,把问题分别输入第一步finetune的模型和正在训练的模型得到输出





- GPT3只是个语言模型,它被用来预测下一个单词,丝毫没有考虑用户想要的答案;当使用代表用户喜好的三类人工标注为微调数据后,1.3B参数的InstructGPT在多场景下的效果超越175B的GPT3:

- InstuctGPT的工作也很有开创性:它在“解锁”(unlock)和挖掘GPT3学到的海量数据中的知识和能力,但这些仅通过快速的In-context的方式较难获得。InstuctGPT找到了一种面向主观任务来挖掘GPT3强大语言能力的方式。
- OpenAI博文中有这样一段原话:当我们要解决的安全和对齐问题是复杂和主观,它的好坏无法完全被自动指标衡量的时候,此时需要用人类的偏好来作为奖励信号来微调我们的模型。
什么是 PPO
PPO(Proximal Policy Optimization) 一种新型的Policy Gradient算法(Policy Gradient是一种强化学习算法,通过优化智能体的行为策略来解决在环境中实现目标的问题)。我们只需了解普通的Policy Gradient算法对步长十分敏感,但是又难以选择合适的步长。在训练过程中新旧策略的的变化差异如果过大则不利于学习。
而PPO提出了新的目标函数可以在多个训练步骤实现小批量的更新,解决了Policy Gradient算法中步长难以确定的问题。由于其实现简单、性能稳定、能同时处理离散/连续动作空间问题、利于大规模训练等优势,近年来受到广泛关注,成为OpenAI默认强化学习算法。
几个做RLHF的项目
- (1)https://github.com/openai/lm-human-preferences
- (2)https://github.com/lucidrains/PaLM-rlhf-pytorch 在机器之心宣传
- (3)https://github.com/allenai/RL4LMs
- (4)https://github.com/CarperAI/trlx
- (5)https://github.com/lvwerra/trl
几篇RLHF最热门的必读论文
- (0)迭代式的更新奖励模型(RM)和策略模型(policy),让奖励模型对模型输出质量的刻画愈加精确,策略模型的输出则愈能与初始模型拉开差距,使得输出文本变得越来越符合人的认知。Anthropic就曾经在论文里讨论了这种做法,并命名为 "Iterated Online RLHF (2022.04.12)"
- (1)Deep Reinforcement Learning from Human Preferences (Christiano et al. NeurIPS 2017) :RLHF用于Atari,使用一些规则标注的不同轨迹之间的pair-wise方式来微调策略。
- (2)Fine-Tuning Language Models from Human Preferences(Zieglar et al. arXiv 2019) (配一篇OpenAI Blog):一篇早期的文章,研究reward Learning在4个具体任务(continuing text with positive sentiment or physically descriptive language, and summarization tasks on the TL;DR and CNN/Daily Mail datasets.)上的影响,通过5,000 次人类的比较评估就取得了非常好的reasonable ROUGE scores
- (3)Learning to summarize with human feedback (Stiennon et al., NeurIPS 2020) RLHF方法应用于 summarize 任务,用ROUGE指标来微调策略提升summarize质量,使用的是GPT-2和PPO。另外一篇文章Recursively Summarizing Books with Human Feedback(OpenAI Alignment Team, arXiv preprint 2021) 做了这篇文章的后续工作,在GPT3上微调,生成章节摘要再生成整本书摘要,研究表明人类只需要标注5%的摘要数据,就可以在 NarrativeQA 基准上取得先进性效果。
- (4)WebGPT: Browser-assisted question-answering with human feedback (OpenAI, arXiv 2021) 允许GPT3模型根据搜索引擎实时拿到的结果来预测,并在ELI5(Reddit 用户提出的问题的数据集)上训练,根据人类标注偏好的数据,用behavior cloning的方式微调模型,结果65%的情况下都取得很好的效果。
- (5)InstructGPT: Training language models to follow instructions with human feedback (OpenAI Alignment Team 2022) 讲述RLHF应用在通用语言生成模型上。1.3B 参数 InstructGPT 模型的输出优于 175B GPT-3 的输出,因为通过了人类反馈标记数据,用RL来微调GPT,虽然仍然会犯一些低级错误,但是不真实性和有毒性都明显降低了很多。OpenAI的博客Aligning Language Models to Follow Instructions 2022.07.27
- (6)GopherCite: Teaching language models to support answers with verified quotes (Menick et al. 2022(配一篇Google的技术博客 ):把RLHF应用于训练“开卷式”QA 模型, 2800 亿参数模型 GopherCite 能够生成具有高质量支持证据的答案,并在不确定时放弃回答。对 NaturalQuestions 和 ELI5 数据集的一个子集中的问题答案进行人工评估来衡量 GopherCite 的性能,对抗性 TruthfulQA 数据集的分析安全和可信度
- (7)Sparrow: Improving alignment of dialogue agents via targeted human judgements (Glaese et al. arXiv 2022) 用RLHF微调对话Agent,an information-seeking dialogue agent。从 70B 语言模型 Dialogue Prompted Chinchilla (DPC) 开始,再训练两个同样大小的RM模型来近似人类判断:偏好奖励模型 (Preference RM)预测分数 和 规则违反奖励模型 (Rule RM) 预估违反规则的概率,用A2C训练。
- (8)ChatGPT: Optimizing Language Models for Dialogue (OpenAI 2022) 使用RLHF来训练一个LM(language Model)并合理的应用于所有的对话场景
- (9)Scaling Laws for Reward Model Overoptimization (Gao et al. arXiv 2022) 研究了缩放奖励偏好在RLHF中的影响,避免古德哈特定律(Goodhart's law)的影响
- (10)Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback (Anthropic, 2022) 一个详细的文档研究了如何用RLHF训练LM,偏好模型RM和RL一周训练一次,并确定了 RL 奖励与策略及其初始化之间 KL 散度的平方根之间的大致线性关系
- (11)Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned (Ganguli et al. 2022) :详细的研究了如何在训练LM中『发现、测量、减少有害行为』,论文研究了3 种模型大小(2.7B、13B 和 52B 参数)和 4 种模型类型:普通语言模型(LM);LM 提示乐于助人、诚实且无害;具有拒绝抽样的 LM;以及使用人类反馈强化学习 (RLHF) 训练有帮助和无害的模型。
- (12)Dynamic Planning in Open-Ended Dialogue using Reinforcement Learning (Cohen at al. 2022) 使用RL去提升一个实时开放式的对话系统的对话技能。
- (13)RL4LM的论文:Is Reinforcement Learning (Not) for Natural Language Processing?: Benchmarks, Baselines, and Building Blocks for Natural Language Policy Optimization (Ramamurthy and Ammanabrolu et al. 2022) 讨论RLHF开源工具的设计空间,提出一个新的算法NLPO来代替PPO
参考
抱抱脸:ChatGPT背后的算法——RLHF | 附12篇RLHF必刷论文 https://zhuanlan.zhihu.com/p/592671478
从零实现ChatGPT——RLHF技术笔记 https://zhuanlan.zhihu.com/p/591474085
算法工程师深度解构ChatGPT技术 https://juejin.cn/post/7176077467092779068
作者:臻甄
链接:http://events.jianshu.io/p/8ae1f2d40abb
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。