一个项目越复杂,架构的作用就越显得重要。这就跟收拾家里面的东西一样,如果我们只有为数不多的几件物品,即便我们随意摆放,也不会妨碍我们找到想要的东西。但是随着购置的物品越来越多,如果不设置一套摆放规则,那么想找到东西就可能会花费大量的时间,效率低下。在我看来,架构就像这样一套摆放东西的规则。规则设置得好,屋子里面的东西将摆放得井井有条,我们的生活不仅将更高效也将更舒适顺心。
在最近的一个项目上,我们和客户一起建设了一个机器学习平台。对于某一个机器学习项目,最重要的四个部分是特征处理,模型探索,模型训练与模型推理。构建一个平台的目的是将这四个部分中通用的能力沉淀下来。一个成功的平台可以为新的机器学习项目提供基础设施,让项目快速起步,还可以使得项目组更专注在模型优化上而提升模型迭代效率。
在机器学习平台演进了将近一年之后,系统已经变得非常复杂。我们不仅需要支持大量通用的特征处理过程,还需要支持大量的通用机器学习算法及其指标。此外,对于超大数据集的支持也是系统中非常重要的一环,这就要求系统对于分布式计算有良好的支持。在这个平台中,分布式的特征处理过程和机器学习任务将需要被调度到yarn或者kubernetes上面执行。
对于这样一个复杂的系统,需要设计一个怎样的架构才能有效支撑系统的快速演进呢?本系列文章将从不同的方向切入,总结几个在我看来非常有效的架构设计决策,有了它们,系统更容易理解了,添加新功能更容易了,潜在的bug也更少了。这里的架构不仅不错的适应了当前规划的需求,而且具备足够的扩展性,能不错的支撑将来潜在的需求。
我将分为三个部分来进行分享,分别是:
- 微服务实践
- 配置管理实践
- 面向对象设计实践
本文将分享我们在微服务方面的实践。
整体架构
先来看一下系统的整体架构,简单来说,系统可以分为以下几个部分:

面向用户的接口包括一个基于Angular的web应用,还包括一个命令行工具。后端Rest API基于数据库实现,为面向用户的接口提供支持。调度器负责将任务调度到分布式计算平台上面执行,并负责任务状态的管理。整个系统的底层有一套大数据集群作支持,为系统提供数据存储和计算。
微服务实践
认识微服务拆分带来的问题
从上面的整体架构图中可以看出,后端Rest API部分集中了大量的业务逻辑。按照我们一般系统建设的思路,那就是考虑进行微服务拆分,将复杂度分散到多个服务中去。微服务拆分的一般思路是按照业务领域进行拆分,比如在我们的系统中,多数人会考虑拆分为数据集服务、Pipeline服务(特征处理)、模型服务等。
但是微服务拆分带来的弊端其实也是显而易见的,通常比较突出的有:
- 一个
API的实现逻辑被分配到好几个服务中去,一旦遇到问题,我们不得不跨多个服务去分析代码,联合调试 - 微服务拆分之后,各种维护工具(如
pipeline、编译脚本等)、依赖组件(如数据库)都可能会存在多个,这不仅给系统运维带来了负担,还给问题诊断带来了成倍的工作量 - 本地集成测试将变得更慢。为了在本地运行起来整个系统,常常需要启动多个
web服务,这带来了额外的启动时间,同时受制于开发机本身的配置,开发体验也将更差 - 可能带来潜在的难以解决的分布式一致性问题
可能有人会说微服务发展这么长时间了,上面的问题其实都已经有很好的应对方案了。比如spring cloud给我们提供了中心化的配置解决方案,提供了断路器,日志追踪支持等等。Istio的边车方案,还将这些复杂性抽象到一个无侵入的伴生进程中。这些无疑有效的缓解了上面的问题,但是每个团队要自己维护这些额外的组件也并不是一件容易的事情。在系统尚未产生可见的大的价值之前,在我看来,进行过细的业务上的微服务拆分实际上可能会浪费费大量的宝贵时间,而产生的价值却不明显。
我们是怎么做的呢?有以下几点设计决策在我看来对我们帮助很大。
设计上支持服务拆分,但推迟执行
我们在业务领域维度只进行逻辑上的微服务拆分,而不进行物理上的微服务拆分。
在源代码管理上,对应到微服务设计,我们会相应进行模块划分。模块划分时按照隔离程度从低到高可以有:1. java包模块隔离;2. maven module模块隔离;3. 代码仓库模块隔离。单从隔离程度上看,我们期望越高越好,这样模块间的耦合程度就会越低。但隔离程度越高,相应的管理维护成本就会越高,因为在实际操作中我们会把模块配置进行不同程度的复制,而由复制带来的同步更新成本、依赖兼容性维护成本就会显现出来。在实际情况下,我们一般会根据具体情况,将这些模块划分方式结合起来使用。
具体而言,我们只使用了一个API模块来支持所有的业务Rest API,业务逻辑代码放在同一个maven模块内部(Rest API服务基于Spring Boot框架)。但是在模块内部,我们用java的包管理机制将不同的领域代码分配到不同的包中去。比如用于特征处理的pipeline模块代码会单独存放在一个java包中,用于实验管理的experiment模块代码存在于另一个java包中,等等。
由于不同业务领域的代码放在了同一个maven模块中,在演进过程中我们会难以避免的在不同模块间产生依赖,甚至会导致模块间循环依赖,这也是java包的隔离程度低带来的问题。但是这种做法的好处是,在允许一定程度的耦合下,我们可以更容易为程序添加功能。比如某一个API的实现可能会操作多个领域实体,这个时候只需要用一个@Transactional标记就可以完成事务控制。为避免模块间耦合过重,使用archunit(一个支持自动化架构测试的工具),我们添加了模块间依赖测试。如果不可避免的要引入不寻常的模块间依赖,我们需要显示的在测试中申明,并需要在code review时向大家解释这样做的合理性。
用这样的方式,我们避免了过早的进行业务级别的微服务拆分,保证了添加新功能的效率。但同时,我们在设计上为后续系统演进时可能要进行的微服务拆分留下空间,到时候拆分时也会相对容易。
同时我们还进行了分层设计,将系统拆分出了核心领域层(如common模块,主要是领域实体及领域逻辑)和通用层(如connector模块,用于连接各个外部系统,如hive hbase等)。分层模块间,采用隔离程度更高的maven module实现。同时在分层模块内部同样采用java包加archunit测试的方式来降低内部模块间的耦合。
将来,如果我们要进行业务级别的微服务拆分,我们主要需要完成三个部分改造:1. 建立同样的模块结构,将代码分出去;2. 用服务间rpc调用的方式处理耦合;3. 处理分布式情况下的数据一致性。
除了Rest API模块,应用层还有一个重要的ml模块,这个模块内部主要实现了运行于大数据集群之上的分布式应用。这些应用基于Spark分布式计算引擎实现,内部由于需要使用到一些领域对象,并需要连接hbase等外部组件,所以ml模块依赖了common和connector模块。
进行了上面的分析之后,我们可以得到下面这样的模块划分图:
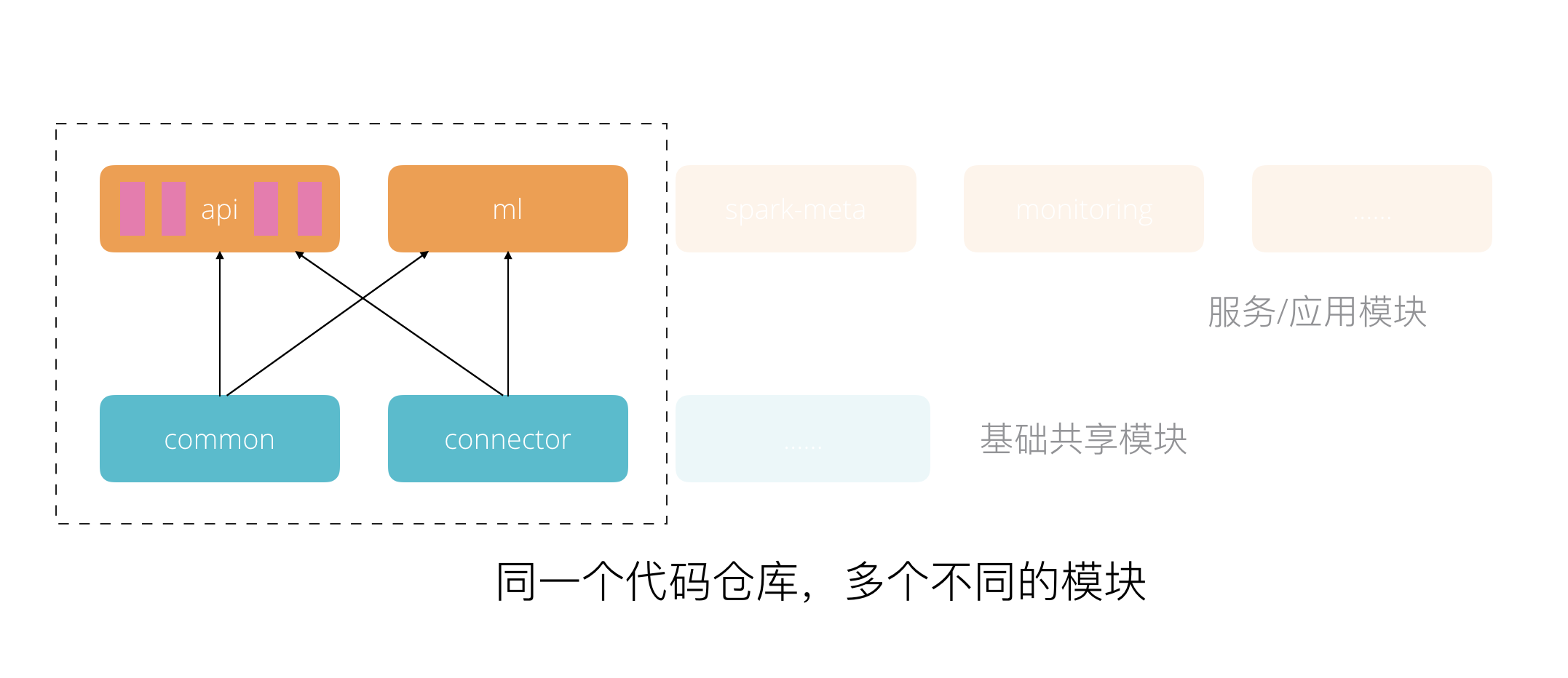
拆分稳定且独立的模块
除了Rest API和ml模块,对于相对稳定且功能较独立的通用领域服务,我们将它们拆分为独立的微服务,独立部署。
对于特征处理模块而言,其真实的运行环境是yarn集群,但是集群环境非常复杂,需要进行大规模的资源调度,其速度是很慢的。这个模块的另一个特点是配置特别多,比如某一个特征处理算子(可以理解为一个Spark MLLib的Transformer或者Estimator),为了支持其实现功能,可能会配置输入特征、输出特征、异常处理方式、外部资源信息等。配置一旦复杂,就比较容易引入配置错误,进而带来运行时错误,比如某一个不支持字符串类型的算子如果配置了字符串类型的输入特征,就会在运行时报错。
为了改进用户配置特征处理Pipeline的体验,我们希望实现Pipeline的调试功能。这个功能的目的是快速给用户提供反馈,其运行环境是一个本地的Spark Session。
另外,对于某些特征处理的算子,还存在schema计算无法通过简单配置来实现的问题,比如SQL Transformer算子,这个算子中,用户可以配置任意合法的sql,可以在sql中包含复杂的计算与函数调用,这就导致schema的计算也需要依赖一个Spark运行时环境。
经过对业务需求的理解和分析,我们发现可能需要抽象一个独立模块来快速的提供Spark运行时元信息支持,这个模块我们将其命名为SparkMeta。其功能相对独立和通用,可以在将来用于支持更多的Spark元信息服务。并且,在当前看来,由于我们特征处理模块强依赖Spark来实现功能,将来潜在的元信息相关需求还会比较多。这样的通用领域的抽象应该是合适的。
于是我们拆分了一个独立的SparkMeta模块,将其放置于同一个代码仓库里面,使用maven module进行隔离管理。
这一设计带来了很多好处:
- 无需在
Rest API的web服务中引入Spark相关的依赖。这些依赖特别多,一旦引入将导致最后的程序包体积变得很大,非常不利于运维和快速的持续集成部署 SparkMeta模块的功能相对独立而稳定,我们无需频繁的进行部署,实际上在整个系统演进过程中,我们也只是进行过两到三次部署而已- 对于测试环境,
SparkMeta模块可以只部署一套环境,无需跟着Rest API模块一样去配置过多的环境(比如,我们一般会设置用于开发的dev环境,用于QA集成测试的sys环境,用于验收测试的uat环境),这进一步简化了整个系统的部署。
与此类似,我们还设计了一个专用于监控告警的模块,同样使用maven module进行隔离,并独立部署为一个web服务。这个模块依赖于一个第三方的监控告警服务,需要进行特殊的配置(在虚拟机上面安装一个搜集数据的agent,对于容器化并不友好)。通过这样的独立微服务拆分,我们可以为其他系统模块提供一套更友好的Restful的API,使得其他模块更容易的集成监控告警服务。同时,如果某一天我们希望更换第三方监控告警服务,我们只需要修改这个模块即可,这带来了很大的灵活性。
通过这样的微服务拆分设计,我们可以得到下面这样的模块划分图:

拆分具有架构不确定性的模块
随着系统的演进,我们发现推理服务模块(未在整体架构中画出,其功能是将特征处理过程或机器学习模型发布为可供外部调用的服务)具有非常大的不确定性。这些不确定性主要体现在技术选型上。由于推理服务需要为线上业务提供支持,所以不管是在调用延迟还是在TPS指标上面要求都非常严格。我们先后尝试了多种技术方案,比如用mleap来支持特征处理的线上服务,用angel serving来支持angel模型的线上服务,采用高度优化的算法自实现线上服务,使用rust语言重写整个线上服务模块等。
对于不确定性如此高的一个模块,如果我们将其与Rest API置于同一个代码仓库,将带来非常大的不便。不仅要在同一个代码仓库支持多种编译工具,还需要共同遵守某些的(有时并不合理)规范。比如我们的Rest API采用Merge Request的机制进行代码合并,这种方式对于快速集成有一定的副作用,对于一个需要快速演进的服务并不适合。还比如持续集成和持续部署的pipeline,由于技术方案上需要快速变化,我们也在一定程度上进行了弱化。
为了这个线上服务模块可以快速演进,我们将其分离出来置于一个独立的代码仓库进行维护。这一决策对于我们去快速实验一些新的特性提供了很好的支持,使得我们的精力始终集中在最有价值的事情上。
总结
总结起来,对于一个实用的系统架构设计,有以下对于我们而言十分受用的几点经验:
- 一个实用的微服务拆分方式并不是一开始就进行业务级别的微服务拆分,而是在设计上支持,但推迟执行
- 抽象更通用且更稳定更独立的支撑性领域服务,进行独立部署,可选的进行代码仓库拆分
- 拆分具有架构不确定性的模块,采用代码仓库级别的拆分,并设置不同程度的代码质量要求
架构设计的主要目的是将繁杂的东西整齐有序的管理起来,降低系统的复杂度,快速的支撑业务。要做到这一点,从实现思路上讲,我们要有效的进行模块拆分,合理的运用各种技术手段。当模块间的耦合度有效降低且模块内的内聚性有效增强的时候,就证明我们的架构是合适的架构了。上面三点经验正是应用了这些思路,结合系统本身的业务需求一步步演进而来的。系统架构并不是一蹴而就,这要求我们在开发过程中时刻关注架构,一旦识别出不合理的地方,及时进行调整。