Pretrained Anime StyleGAN2 — convert to pytorch and editing images by encoder
Allen NgFollow
Jan 31, 2020 · 4 min read
Using a pretrained anime stylegan2, convert it pytorch, tagging the generated images and using encoder to modify generated images.
Recently Gwern released a pretrained stylegan2 model to generating anime portraits. The result looks quite good, let’s try it out.
Convert to pytorch
Since the official implementation of stylegan2 is highly depends on GPUs machine, it maybe very painful to make it able to run on CPU and requires a lot of code modification.
I found a very good repository that able to convert the pretrained stylegan2 weights from tensorflow to pytorch. Able to produce the same result using the official FFHD dataset on pytorch.
You can start from playing with the official FFHD model first, but here we will directly start with the anime model.
After cloning the repository and downloading the model from here, we can simply run
python run_convert_from_tf.py --input=2020-01-11-skylion-stylegan2-animeportraits-networksnapshot-024664.pkl --output checkpoint
Converted model should store inside checkpoint folder
Let’s try to generate some images
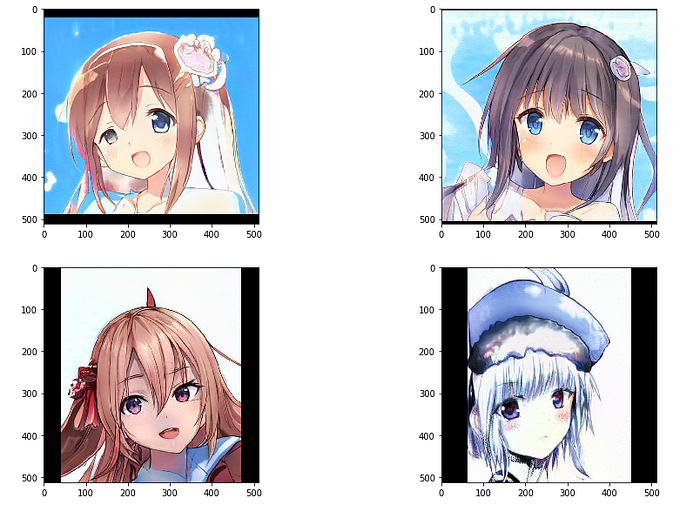
python run_generator.py generate_images --network=checkpoint/Gs.pth --seeds=66,230,389,1518 --truncation_psi=1.0
You should able to see these 4 images generated under result

Tagging generated images
The idea also came from Gwern’s website, We can use KichangKim’s DeepDanbooru to tag the generated images.
I am using the v2 model in this time, after downloading the model we can see it’s a cntk model, which is not so friendly to mac user like me (They still don’t have official wheel for mac, we can only use it inside docker).
Okay, I don’t want to spin up docker, so I will convert the cntk model to onnx and run it via onnxruntime
Convert code can be found here, good thing is both cntk and onnx are microsoft’s product, so the convert is also very easy. I am using kaggle notebook to do the convert since I don’t want to spin up the docker, so kaggle notebook is a good linux env for me to do it!
Let’s use the onnx model to tag some image!
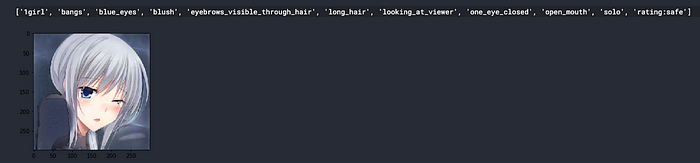
OK seems it’s working, we can now proceed to batch tagging the generated images, here we are referencing the Puzer’s stylegan-encoder, I will generate same size of samples *(n=20000). *But also from halcy’s pervious work, maybe (*n=6000*) already enough.
As stylegan2 have a similar structure as stylegan, we need to store 3 things, latent vector *z, *d-latents vector *d, *and the tag scores. The detailed code can refer to this notebook. The process can take up to 4–5 hours if u are running on a singe GPU machine. If you are running on CPU machine, can try to reduce the sample size.
Train the encoder
As Puzer’s stylegan-encoder already pointed out we can train a single tag classifier to find out which part inside the latent space is controlling what features, instead of using Logistic Regressions, let’s build a extremely simple linear model to achieve that.
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# kernel
self.main = nn.Sequential(
nn.Linear(in_features=16*512, out_features=1),
nn.LeakyReLU(0.2),
nn.Sigmoid(),
)def forward(self, x):
return self.main(x)
That’s it! we have 16 affine layers and the latent size is 512, that means the input size of Generator Synthesis is 16*512, and the out feature is 1, and then we apply sigmoid to it, which yield the 0–1 likelihood generated by the tagger.
After that the weights for first layer already representing the coefficient to the tag. We can use the weight inject to the dlatents space and control the generated image’s feature.
Editing Images
Let’s try with some popular tags first, like black hair:


Since the model is very simple, only trained with 3 epochs, the coefficient here is [-5, -1.5, 0, 1.5, 5], so it does works, but when we enlarged the coefficient we can see not only the decided direction, also other feature got changed a bit as well.
Let’s try some others, open_mouth:
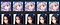

top one worked quite obviously, but interesting is the second one, it even closed her mouth compare to the beginning, looks like not every tag will work.
Character specify encoder?
If the dataset contains enough data of some specify character, will it be able to twist the generator to only generate that character instead of doing a transfer learning?
I picked one character which appears in the generated dataset kirisame_marisa(n=194)


Interesting, the encoder only picked up yellow_hair feature from Marisa. in order to make it works I guess we need a more balancer dataset, with more marisa samples together with the normal images.
Also it’s very hard to generate character that is very rare during the originally generator training, maybe for now, transfer learning is still a better way to go with character specify or some rare attributes.
The full notebook of training the encoder can be found in here.
