
简介
GoogLeNet,采用InceptionModule和全局平均池化层,构建了一个22层的深度网络,使得很好地控制计算量和参数量的同时( AlexNet 参数量的1/12),获得了非常好的分类性能. 它获得2014年ILSVRC挑战赛冠军,将Top5 的错误率降低到6.67%.
GoogLeNet这个名字也是挺有意思的,将L大写,为了向开山鼻祖的LeNet网络致敬
基本信息
论文 Going deeper with convolutions.
作者 Szegedy, Christian, et al
发表于 2015年 CVPR(Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition)
翻译 http://www.aiqianji.com/blog/article/25
创新点
GoogLeNet的网络结构设计很大程度上借鉴了2014年 ICLR 的paper:Network In Network。
它打破了常规的卷积层串联的模式,精心设计了InceptionModule,提高了参数的利用效率,完成了22层的模型。
此外,它最后的全连接层也是用全局平均池化层来取代。
Inception 这一名字来自于科幻电影《盗梦空间》。
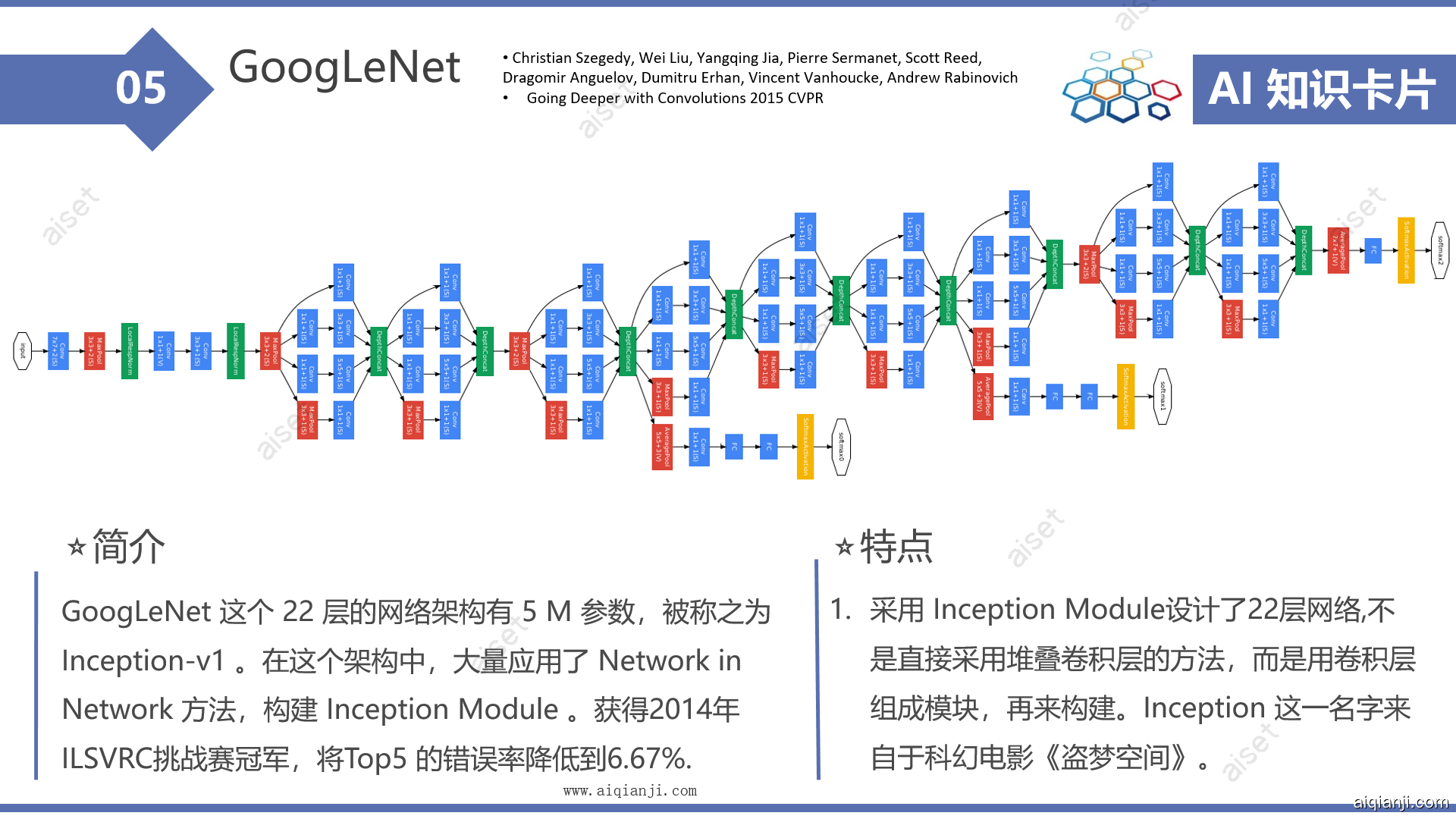
网络结构
GoogLeNet 原始结构如图:


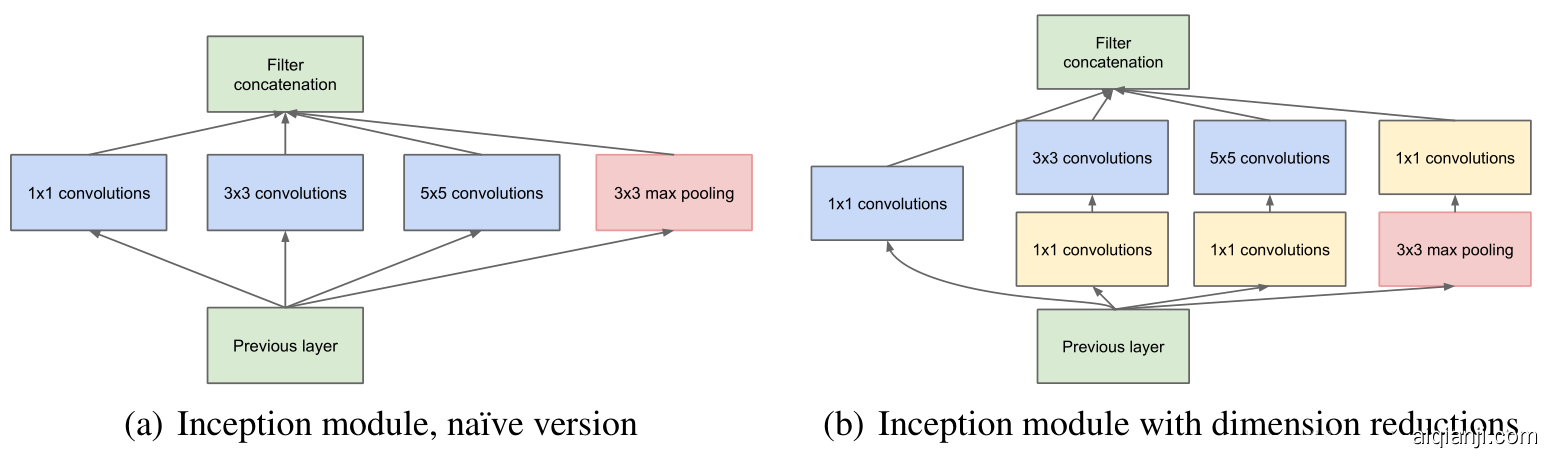
将InceptionModule 提取出来之后,可以将模型抽象如图

每个InceptionModule 是两层结构:
源码
tensorflow 源码 https://github.com/tensorflow/models/tree/master/research/slim/nets/inception_v1.py
caffe https://github.com/BVLC/caffe/blob/master/models/bvlc_googlenet/train_val.prototxt
pytorch :https://github.com/pytorch/vision/blob/master/torchvision/models/googlenet.py
练习:在32*32 的 cifar10 上进行十分类,用pytorch构建网络结构
手写示例:
class Inception(nn.Module):
def __init__(self, in_planes, kernel_1_x, kernel_3_in, kernel_3_x, kernel_5_in, kernel_5_x, pool_planes):
super(Inception, self).__init__()
# 1x1 conv branch
self.b1 = nn.Sequential(
nn.Conv2d(in_planes, kernel_1_x, kernel_size=1),
nn.BatchNorm2d(kernel_1_x),
nn.ReLU(True),
)
# 1x1 conv -> 3x3 conv branch
self.b2 = nn.Sequential(
nn.Conv2d(in_planes, kernel_3_in, kernel_size=1),
nn.BatchNorm2d(kernel_3_in),
nn.ReLU(True),
nn.Conv2d(kernel_3_in, kernel_3_x, kernel_size=3, padding=1),
nn.BatchNorm2d(kernel_3_x),
nn.ReLU(True),
)
# 1x1 conv -> 5x5 conv branch
self.b3 = nn.Sequential(
nn.Conv2d(in_planes, kernel_5_in, kernel_size=1),
nn.BatchNorm2d(kernel_5_in),
nn.ReLU(True),
nn.Conv2d(kernel_5_in, kernel_5_x, kernel_size=3, padding=1),
nn.BatchNorm2d(kernel_5_x),
nn.ReLU(True),
nn.Conv2d(kernel_5_x, kernel_5_x, kernel_size=3, padding=1),
nn.BatchNorm2d(kernel_5_x),
nn.ReLU(True),
)
# 3x3 pool -> 1x1 conv branch
self.b4 = nn.Sequential(
nn.MaxPool2d(3, stride=1, padding=1),
nn.Conv2d(in_planes, pool_planes, kernel_size=1),
nn.BatchNorm2d(pool_planes),
nn.ReLU(True),
)
def forward(self, x):
y1 = self.b1(x)
y2 = self.b2(x)
y3 = self.b3(x)
y4 = self.b4(x)
return torch.cat([y1,y2,y3,y4], 1)
结果:
GoogLeNet : BEST ACC. PERFORMANCE: 92.860%