导读:
短视频已经成为信息流行业的风口,成为拉动规模增长的主要驱动力。短视频天然具有信息能量高、用户粘性大、内容丰富等优点,也有视频帧内容难以分析提取、结构化的缺点。如何提高短视频的分发效率和推荐精准度,做到千人千面的个性化推荐,是一个推荐系统的核心能力。基于深度学习的推荐模型,是业界前沿的研究课题;在短视频推荐的业务中,如何利用深度学习算法有效的提升消费点击和消费时长,是推荐模型的核心命题。此次演讲主要讲解视频推荐模型在多目标和模型优化方面的进展。包括以下几个模块:
- 业务和系统
- 基于 Graph Embedding 的多目标
- 基于 WnD 的 Boosting 算法
- 未来规划
▌业务和系统
1. 短视频业务背景、系统结构

我们的业务主要是做视频推荐,嵌入到 UC 浏览器中做国内信息流:
- UC 从工具型产品转型至内容分发平台,信息流业务成为 UC 的第二大引擎;
- 短视频已经成为信息流行业的风口,成为拉动规模增长的主要驱动力;
- 短视频播放时长已经超过图文,极大的增强了信息流的用户粘性;
- 算法的持续优化与迭代提高了短视频流量分发的效率和准确度。
右图是视频推荐的界面,其背后的视频推荐系统分为三个结构,第一个是召回模块,第二个是粗排的模型,第三个是精排的模型。从召回 -> 粗排 -> 精排,Item 的数目从多到少,推荐的准确性从低到高。
2. 技术演进史

我们在视频推荐上,尝试过多个推荐方案:
- 最早用的是 LR ( 如图,左下角 ),LR 的缺点主要是在特征工程上会耗费很大的人力;
- 后来我们又尝试了 GBDT 和 FM ( 如图,中间部分 ),但是这些模型在泛化性上相对较弱;
- 最后我们采用了 Wide & Deep model ( 如图,右下角 )。
这里主要介绍的工作是:从多目标的角度优化 Loss Function。与粗排和精排使用的 WnD 对比,线上收益增幅相当,增量超过。
3. 多目标在视频推荐模型中的应用
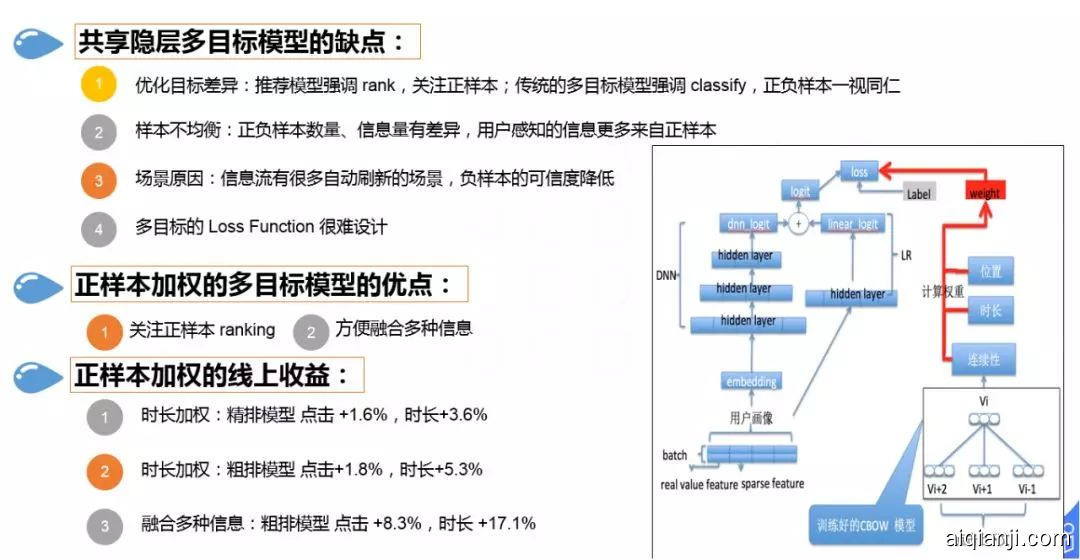
常规的多目标是共享隐层的 soft 多目标模型,我们使用的是基于正样本加权的模型。
共享隐层多目标模型的缺点:
① 优化目标差异:推荐模型强调 rank,关注正样本排序;传统的多目标模型强调 classify 分类,正负样本一视同仁;
② 样本不均衡:在信息流中正负样本数量、信息量存在差异,用户感知的信息更多来自正样本;
③ 场景原因:信息流有很多自动刷新的场景,负样本的可信度降低
④ 多目标的 Loss Function 很难设计,市面上的多目标方案大多是一个主目标和一个辅助的目标
我们使用的正样本加权的多目标模型的优点:
① 关注正样本 ranking
② 方便融合多种信息
我们的方案最终在线上取得了不错的效果。
▌基于 Graph Embedding 多目标融合的 WnD 模型优化
1. 优化 WnD 模型 logit 配比
- 信号正向传播

首先是 WnD 模型的一个小的优化,我们知道 WnD 分为 LR 侧和 DNN 侧,LR 侧使用的优化器是 FTRL,它的优化速度非常快,在数千万 DAU 的场景下,只需采用一次流式训练,在这样的场景下 DNN 对样本的训练很难迭代多次,这时 WnD 模型更倾向于使用 LR 侧的 logit。基于这样的原因,我们想能不能增加 DNN 侧的 logit,提高系统的准确度,大体就是这样的 motivation。
具体实施的时候,见图中红框部分,d 指 DNN,w 指 LR,zdL 指 DNN 最后一个隐层的输入,zw 指 LR 最后一个隐层的输入,我们在 DNN 侧乘以了一个系数 m,这就是大体的一个优化方向:
① 对于已经能很好识别的样本:概率增幅不明显(如右图最上部分的箭头,已经进入饱和区,所以增加不明显)
② 对于可以识别,但可信度低的样本:概率增幅明显(如右图中间部分的箭头)
③ 识别错误:错误概率变化幅度明显(如右图最下部分的箭头)
④ 对于 ③,概率增加,可以增加 Loss,从上述3点,可以对错误样本有针对性的训练
- 梯度反向传播、Adagrad 优化器

这是一个反向传播公式的推导,上面讲过增加 DNN 侧的 logit 会增加 Loss,图中标红的表示 Loss 会增大,同时,m 可以提出来作用到 Adagrad 优化器时:

也是相应增加的。
2. 基于时长加权的多目标融合的 WnD 模型优化
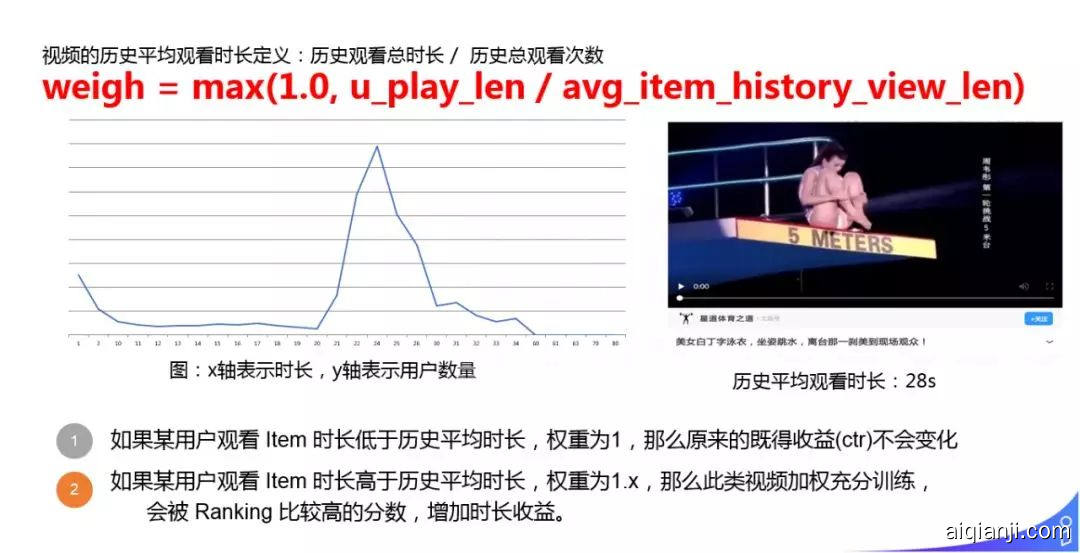
这部分的 motivation 是我们在做模型训练时,做的还是二分类的一个分类模型,这时点击观看的时长没有用到。因此,我们利用用户观看时长,来提升推荐效果。
这里设计了一个 weigh 计算方式:对于某个视频用 u_play_len 这个视频的历史观看总时长 / avg_item_history_view_len 这个视频历史的平均观看时长,用 max 做了一个规范化,求得 weigh,且 weigh>1。图中统计了右边视频随着时长增加,用户观看数量的一个变化情况。有了 weigh 我们可以对 WnD loss function reweight:
① 如果某用户观看 Item 时长低于历史平均时长,权重为1,那么原来的既得收益 ( ctr ) 不会变化。
② 如果某用户观看 Item 时长高于历史平均时长,权重为 1.x,那么此类视频加权充分训练,会被 Ranking 比较高的分数,增加时长收益。
3. 基于 Graph Embedding 多目标融合的 WnD 模型优化
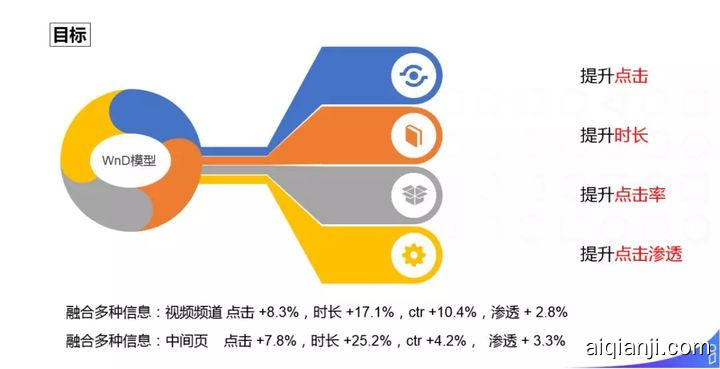
基于 Graph Embedding 多目标融合的方案中,多目标包括:提升点击、提升时长、提升点击率、提升点击渗透。
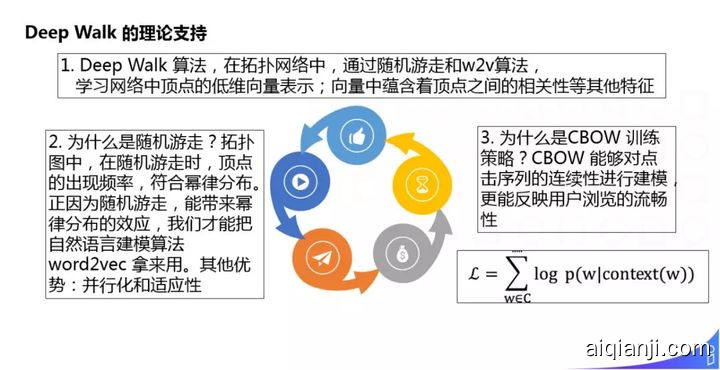
首先如何取到一个 Item Embedding?我们采用的是 Deep Walk 算法,在拓扑网络中,通过随机游走和 w2v 算法,学习网络中顶点的低维向量表示,向量中蕴含着顶点之间的相关性等其他特征。真正训练的时候采用的是 CBOW 训练策略,其 Loss Function 如下:
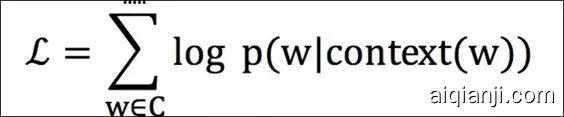
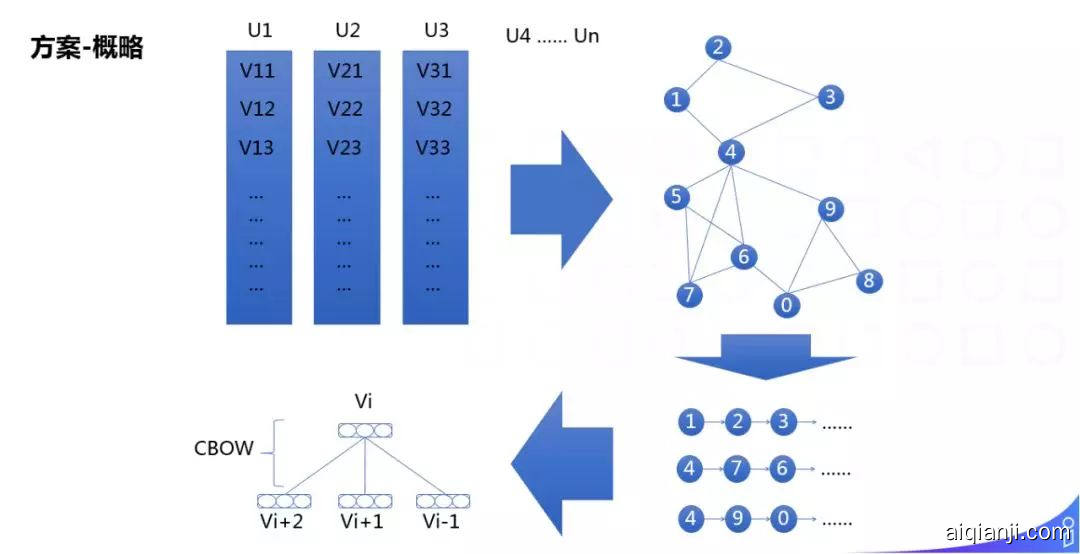
我们的方案是,从用户日志中挖掘出每个 User 的点击序列,根据点击序列建立无向图,然后在每个节点随机游走形成句子,最后经过 w2v 的训练策略,得到每个 Item 的 Embedding 表示。
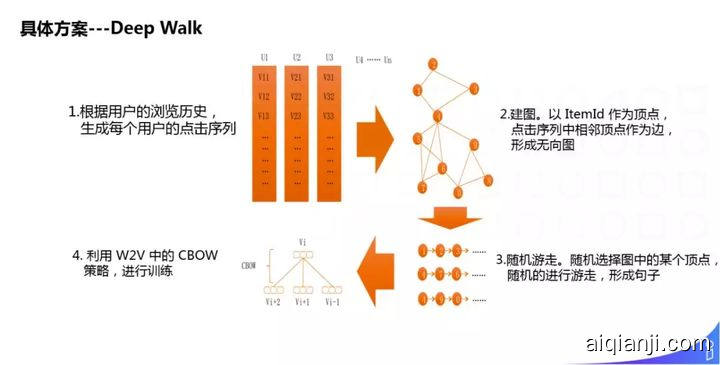
具体方案:
① 根据用户浏览历史,生成每个用户的点击序列;
② 建图,以 ItemId 作为顶点,点击序列中相邻顶点作为边,形成无向图;
③ 随机游走,随机选择图中的某个顶点,随机的进行游走,形成句子;
④ 利用 w2v 中的 CBOW 策略,进行训练。
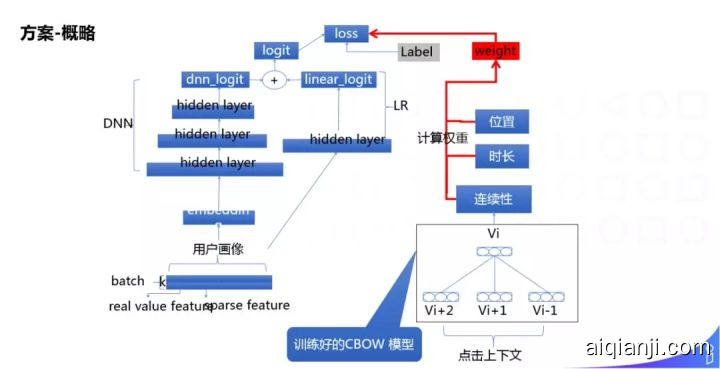
有了 Item Embedding 之后,做 Loss Function 的 reweight,reweight 时加入了位置、时长、连续性 ( 通过 Graph Embedding 计算得出 ) 等信息。

Loss Function reweight 方式是在正样本前面乘一个系数 di,j,然后负样本保持不变,如果拿掉系数,是一个标准的交叉熵公式,di,j 考虑了观看时长、观看连续性、Item 的位置等综合信息来得到的,它们之间用的是 α、β、γ 线性加权得到的:
f(play_len)是关于时长的函数,由播放时长的分布估计得出:

左下角为用户播放数的累加,它的上面是观看到某一时长 n 的用户播放数的累加,右边侧延续了时长加权公式的模板。
4. 连续性

接下来讲一个连续性的实际案例:
①②③④⑤⑥⑦⑧这是用户的点击顺序,对应的分数是基于连续性 w2v 算法计算出来的分数,我们认为分数较高的视频很容易带领用户继续看下去,把它称作一个连续性的信息,我们对此类信息进行加权,希望能够带动用户整体的消费。
▌基于 WnD 的 Boosting 算法
1. 模型

由于 Wide&Deep 建模方案是一个二分类,理论上只有一个分类超平面,很容造成样本错分。我们理想的方案是,虽然是二分类,但是我们可以有多个决策超平面,所以我们用了 Boosting 算法,综合5个 Wide&Deep,进行二分类。其应用场景是训练的实时流,每次训练都是一个 Batch ( 相当于在线训练 ),中间融合了5个 Wide&Deep 模型 ( 5个模型的特征是不变的,共享 Embedding 隐层,采用的是并行计算 ),最终生成一个强分类器。
Adaboost:

这是 Adaboost 算法的标准模式:
① 初始化训练数据的权值分布
② 使用权值分布 Dm 的训练数据集学习,得到子分类器 Gm(x)
③ 计算 Gm(x) 在训练数据集上的分类误差率
④ 利用分类误差率计算基本分类器在最终分类器中所占的权重
⑤ 更新每个样本的权重,继续训练下一个模型,如果有5个子模型就训练5个子模型
⑥ 最终综合每个子模型的权重和预测值,得到一个强分类器
2. 算法

具体的算法有几个不同点:
第一个是误差项的计算方式,原先标准 Adaboost 算法误差项计算用的是加权指标函数:

我们的方案采用的是 AUC 加权的误差项:
每个子模型的权重,由于是在线训练,所以采用的是迭代的方式:

每次用上一个 Batch 1/2 权重加上此次误差项的计算。

第二个是样本权重的更新,样本权重更新时只对正样本进行更新,而标准的 Adaboost 是对正负样本都进行更新的:

di,j+ 指的是这个样本上一个子模型的权重,εi 是误差项。

这是样本的更新方式。
最终强分类器的预测和 Adaboost 标准模型差不多:

也是线性加权然后除以总的权重。
实际应用中 Adaboost.Rank 的 WnD 子模型有5个,每个 WnD 都有相同的网络结构且它们共享 Embedding 层,Adaboost.Rec 模型的磁盘大小只比单个 WnD 模型增加了6%。
3. 在短视频推荐中的应用

方案的实验效果和 WnD 模型对比如上,提升了模型推荐的精准性。
▌未来规划

未来的规划:
- 现在的推荐都是基于 point wise 的推荐模型,每次都是预测单个 Item 的分数,未来希望可以一次给用户推荐一刷的结果。
- 因为每天都有新用户进来,所以我们希望建立一个留存新用户模型,来留住新用户。
- UC 信息流目前的主要消费群体为男性用户,在推荐的偏好上模型和策略都偏向男性用户,我们希望可以留住更多的女性用户。
这就是未来的一个方向,谢谢大家。
分享嘉宾:语露 阿里 高级算法工程师
阿里大文娱于2016年10月31日正式筹建。其前身为阿里巴巴集团于2016年6月15日宣布成立的阿里巴巴集团大文化娱乐板块。
作为阿里巴巴集团“快乐+健康”战略中“快乐”产业的载体之一,阿里大文娱承担着阿里巴巴集团在未来十年乃至更久时间内的重要战略落地的使命,亦是阿里巴巴集团继电子商务、金融、智能物流和云计算业务之后的最新产业布局。
站在文娱产业角度,阿里大文娱的使命是赋能于外,利用互联网技术的不断迭代创新,推动人们释放想象力、解放生产力,同时让文娱产业的从业者获得应有的回报和尊严,打造文娱产业的持续竞争力。
阿里大文娱打造文娱产业新基础设施,将从4个层面——用户触达新基础设施、技术新基础设施、商业新基础设施以及人才成长新基础设施,赋能文娱产业链上下游各环节,推动文娱产业向数字化、网络化、智能化发展升级。
用户触达新基础设施:让更多人享受更多快乐
阿里大文娱整合多样化、优质的互联网平台,帮助文娱产业的从业者更好理解消费者,建立内容与消费者的有效连接,从而使内容更贴近市场、精准触达目标受众,让广大消费者享受个性化的优质内容和服务,获得更多快乐。
技术新基础设施:让快乐创造和体验更简单高效
阿里大文娱提供以云计算、大数据、人工智能等前沿新技术为核心的互联网基础服务,赋能文娱产业上下游的从业者,从而更好地激发产业创新,提高效率,降低成本,改善用户体验,让用户更便捷舒适地享受快乐。
商业新基础设施:让快乐创造更多经济价值
阿里大文娱将文娱生态融入阿里电商、金融生态,促进文娱产业商业模式的创新,使文娱产品的货币化方式极大丰富,从而提升文娱产品的商业价值,为产业从业者带来更多增量收入,创造更多经济价值。
人才成长新基础设施:让更多创造快乐者梦想成真
阿里大文娱依托多元化的互联网平台,提供个人展示能力的机会,打破身份界限,同时构建合理的成长机制,保证上升通道的通畅性,让更多文娱人才梦想成真,为行业发掘、扶持更多更优质的文娱人才。
阿里大文娱依托优酷、UC两大用户平台引擎,以及阿里影业、阿里音乐、阿里文学、阿里互娱、大麦网等多个垂直业务纵队,形成大文娱生态体系内的一张矩阵联动网络,为行业创造更多价值,为用户提供更好体验。
具体业务介绍
优酷
中国领先的数字娱乐内容平台,覆盖5.8亿多屏终端、日播放量11.8亿。优酷现支持PC、电视、移动三大终端,兼具版权、合制、自制、自频道、直播等多种内容形态。业务覆盖会员、游戏、支付、智能硬件和艺人经纪,从内容生产、宣发、营销、衍生商业到粉丝经济,贯通文化娱乐全产业链。
优酷奉行布局类型化、内容品牌化、排播自主化的策略,有影响力的内容是优酷引领文化娱乐产业的核心能力。
2017年,优酷超级剧集战略成效显著,先后推出《大军师司马懿之军师联盟》、《春风十里不如你》、《白夜追凶》等口碑和播放量双丰收的剧集,以全年539.2亿的播放量位居行业第一。其中,《白夜追凶》海外发行权被Netflix买下,成为首部通过正规渠道在海外大范围落地的国产网络剧集。2018年,优酷综艺以网综大片作为战略方向,推出“这就是”系列超级网综,豆瓣评分均分超过8.0,成为行业内首个获市场认可的综艺厂牌。其中,《这就是街舞》海外播放权被江广盈科买下;《这就是灌篮》模式版权被福克斯传媒集团买下,开创国产原创综艺模式版权出海先河。
阿里家庭娱乐是聚焦于大屏终端和客厅场景的业务平台,旗下终端和CIBN酷喵影视App累计激活过亿。为更好的服务中国家庭用户,阿里巴巴相继战略投资海尔、海信和康佳,为传统电视产业赋能,并推出自有硬件产品天猫魔盒、智能微型投影仪天猫魔屏和手机投屏器天猫魔投。旗下CIBN酷喵影视是优酷和国广东方网络(北京)有限公司联合开发的互联网电视应用,千人千面的个性化内容推荐等创新功能让大屏追剧更酷。
UC
专注移动互联网业务创新,致力于打造简单、可信赖的移动互联网信息服务平台。以UC为核心,涵盖其生态体内相关业务线,包括神马搜索、阿里应用分发等。
作为阿里大文娱的核心旗舰产品之一,定位于“大数据新型媒体平台”的UC目前每月活跃用户数达4.3亿,旨在根据移动场景和浏览习惯,并应用阿里系大数据资产和技术,将信息和服务以更好的方式和体验传递给用户,实现“千人千面”;神马搜索则是阿里巴巴旗下移动搜索品牌,致力于为用户创造方便、快捷、开放的移动搜索新体验,目前在国内移动搜索市场中稳居第二;阿里应用分发整合了豌豆荚、PP助手、UC应用商店、神马搜索,并联合YunOS应用商店等应用分发平台,实现全流量矩阵布局。
同时,UC海外业务布局已初具规模,UC浏览器在印度、印尼等多个新兴国家的市场占有率名列第一。UC还在利用其在海外的先发优势快速布局浏览器以外的创新产品,比如其信息流产品UC News自2016年中在印度、印尼发布,快速成为当地成长最快的新闻应用,目前在双印已有超1亿月活用户,在印度构建的内容生态目前拥有6.5万创作者。第三方安卓应用商店9Apps则拥有全球超过2.5亿月活用户。
阿里影业
以互联网为核心驱动的影视实业公司,拥有内容生产制作、互联网宣传发行、IP授权及综合运营、院线票务管理及数据服务的全产业链娱乐平台。阿里影业专注于挖掘互联网与传统影视行业整合及创新应用的全部业务潜能,核心业务涵盖三大版块:互联网与传统线下发行相结合的互联网宣发业务;包含国际和国内两大范畴的内容制作业务;依托阿里巴巴集团生态体系所延伸出的综合开发业务。
互联网宣发方面,阿里影业旗下淘票票是目前中国领先的用户观影决策平台,2014年底上线至今,覆盖中国影院超过9000家,合作影片数量突破500部。2018年4月,阿里影业旗下一站式宣发平台灯塔上线,针对行业痛点,基于大数据和多平台资源的联动,整合域内外流量推广渠道,从而为片方实现宣发效果的最大化。上线以来,灯塔服务的影片超过30部,这些电影累计实现票房超百亿元。
在内容领域,阿里影业秉持“有影响力、正能量”的理念,坚持与多家国内外优秀的制片公司、工作室建立战略合作关系,新增优秀影视立项项目,打造专业制作团队,为电影市场持续输出优质的内容作品。迄今为止,中国电影史上总票房前四名的《战狼2》、《红海行动》、《唐人街探案2》和《我不是药神》,都有阿里影业的深度参与。国际化方面,阿里影业和派拉蒙、Amblin Partners、eOne、索尼影业等国际知名影视公司展开合作,联合推出了多部优质作品。
综合开发方面,阿里影业在《碟中谍5:神秘国度》、《星际迷航3:超越星辰》等电影的衍生品开发方面获得成功,2017年,《三生三世十里桃花》衍生商品累计销售额超过3亿元。阿里影业旗下的衍生品授权与开发平台阿里鱼,为IP版权方和阿里生态体系的品牌商家提供全链路服务,打造面向全球授权产业链的新基础设施,加快推动内容商业化进程。
阿里音乐
作为阿里巴巴文化娱乐集团中的重要组成部分之一,阿里音乐联动阿里巴巴全平台资源,在专业内容生态搭建、音乐版权和曲库运营、独立原创音乐人扶持和发掘、新技术赋能音乐产业、娱乐数据跨界营销等多方向持续发力,打造新数字娱乐行业生态环境。
旗下虾米音乐成立于2008年,早期是中国最具专业调性的音乐平台。2013年正式融入阿里巴巴集团,2017年平台的用户活跃率、人均播放时长居行业第一,体现了超强的用户粘度。秉承对待音乐一贯的专业调性与严谨态度,虾米音乐至今吸引了70万+音乐人入驻,拥有1000+曲风流派。依托超过2000万海量曲库的优质音乐资源,以及科技感十足的AI智能音乐推荐,被广大乐迷们誉为“音乐图书馆”。
通过链接“青年文化”、“寻光音乐人”等方式,阿里音乐依托阿里集团庞大的生态链,用音乐娱乐资源反哺淘宝、天猫、支付宝、优酷等业务,助力天猫双11狂欢夜,打造云栖虾米音乐节、阿里音乐专场论坛等活动,为用户带来更优质、更专业的音乐体验。同时,虾米音乐探乐实验室、听见不同、AI作曲等一系列黑科技的引入,赋予了音乐更多的科技感和想象空间。
阿里文学
致力让阅读更简单、高效、快乐。定位于以阅读平台和IP联动平台为基础的综合型基础设施体系,通过建设文学领域的新基础设施助力产业升级。业务涵盖,数字阅读(通俗文学及严肃文学)、原创内容培育及IP衍生等三大领域。
在数字阅读领域,阿里文学先后推出书旗小说、天猫读书、妙读等数字阅读产品,并拥有UC小说、优酷书城、PP书城等渠道入口,根据《2018上半年度中国移动阅读市场研究报告》显示,书旗小说在用户满意度和使用时长上均处在行业第一。在IP衍生层面,由阿里文学原创的100余部作品已经完成衍生或正在改编中,涵盖漫画、网络电影、剧集、院线电影、游戏及相关衍生商品。与此同时,阿里文学已经与超百家合作伙伴达成深度合作,建立了与文学产业链相关的多元化开放生态。
阿里互娱
阿里巴巴大文娱事业群互动娱乐事业部,以数字互动娱乐内容的创作、分发为核心,深度洞察年轻用户的娱乐需求,通过互动虚拟世界的构建与创作,以及更便捷、更优质的互动娱乐内容分发和服务,最终实现“让年轻人的快乐更阳光”。
大麦网
大麦网,成立于2004年,是中国领先的现场娱乐全产业综合服务提供商,业务覆盖演唱会、话剧、音乐剧、体育赛事、曲苑杂坛、亲子、展览休闲等多个领域。2017年3月,大麦网成为阿里巴巴全资子公司,融入阿里大文娱业务布局。作为阿里体系内连接文娱产业线上和线下的关键链条,大麦网在巩固自身在票务领域原有优势的基础上,持续发力产业上下游,致力于通过对内容、场馆、票务三大现场娱乐领域的全链路布局,全方位服务消费者,推动现场娱乐产业的业态升级。