介绍
这篇文章包括三部分:第一部分介绍相关和因果的区别以及我们为什么需要因果关系,第二部分介绍因果关系的定义,第三部分介绍怎么从数据中判断出因果关系。
希望大家读后能对因果推断有初步的了解,在分析数据时有意识地想一下是否存在因果关系。但这次分享无法提供一个稳定得出因果关系的方法,而是提供思路和工具,帮助我们更好地处理这类问题。
Why
相关≠因果/correlation does not imply causation
人均巧克力消费量与诺贝尔奖比例:

参考网站:http://www.tylervigen.com/spurious-correlations


xkcd
因果关系有什么用?
基于相关可做出准确度很高的预测,但不能直接指导决策,因果关系则可以指导我们做决定。
例子:假设我们有酒店价格和入住率的历史数据,且酒店价格由基于入住率的算法自动实现,入住率高就提价。那么,机器学习算法能够识别出价格和入住率的正相关,即已知价格时,可以准确地预测入住率。但如果我们想知道提价对入住率的影响,用这套算法却会得出“提价能多卖出更多房间”的结论,这好像违背了经济学常识。此时,我们就需要用另一种方法来解答这个问题。
同样的数据可以对应多种不同的数据生成过程,从数据本身无法判断真正的数据生成过程,但可以用作预测。
我们可以回忆一下历史上用来预测天体轨迹的日心说和地心说模型。托勒密的地心说模型的预测精度非常高,却是完全错误的。
更贴近业务来看下预测模型用于决策会有什么问题,比如流失率预测的例子:在很多公司经常需要对可能流失的用户做干预,从而减少流失率。因为资源有限,所以一般做法是用过去的流失客户做样本训练一个识别客户流失概率的模型,然后针对最容易流失的客户做干预,但这么做并不一定是高效的。原因很简单,虽然我们可以很好地预测客户的流失概率,但是预测并不是我们的目的。我们的目的是为了通过干预减少流失率,所以要找的是干预带来留存提升最大的客户群体,而这部分客户未必是最容易流失的客户。因此,要想真正实现有效的干预,就不能靠准确预测流失率的算法,而要想办法找到干预后最有效果的客户,但后者靠通常的预测算法不一定能得到。
另一个例子是搜索广告有效性的评估。eBay曾经不区分相关与因果,建了一个用点击来预测成交的简单模型,发现搜索广告的回报率高达1400%;然而用实验方法来衡量真实的回报率时,发现只有-63%。之所以差别这么大,是因为那些会点广告的人即使没有广告也会去eBay买东西。所以,衡量广告的真实回报要看广告对效果的提升,而不是看广告行为后续的效果本身。
小结
上面几个例子都是在说明我们面临的很多决策问题不能通过预测模型来回答。实际工作中,数据分析师的很多工作都是辅助决策,其实不止数据分析师,只要是需要从数据中得到结论的场景,经常就需要超越简单的相关关系,去努力搞清楚事物之间的因果联系,这样才能做出高质量的决策。

What
什么是因果关系?
前面虽然没有明确定义因果关系,但我们对什么是因果关系其实有很好的直觉。
因果关系试图回答的是what-if的问题:其他不变,如果改变A后,Y的取值改变,则AY有因果关系,A 导致了Y。
其他不变这个前提要求我们想象一个反事实的场景,在常用的因果模型里叫做潜在结果(Potential Outcome)。我们用手术来举例,假如A - 是否手术,Y - 1年后能否存活,那每个个体都有两个潜在结果,一个是接受手术后的结果,一个是不接受手术后的结果。这两种结果之间的差别就是手术和存活的因果关系。
但现实中我们只能观察到个体的某一个潜在结果,所以个体粒度的因果关系是很难确定的。这个难题被称作因果推断的根本难题,本质上是一个缺失数据(missing data)的问题,但缺失的这部分数据是不可能搜集到的。
假设我们全知全能,看到了平行宇宙中的选择,知道每个个体在不同处理方式下的结果,那么就不受这个问题困扰。
全知全能的情况:

全知全能的情况
但实际上:
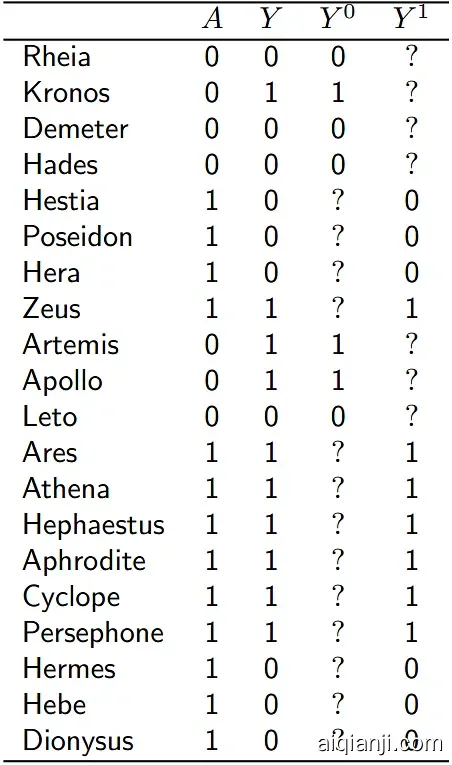
实际情况
我们只能观察到同一个个体在一种操作下的结果,我们观察不到what if。
小结:相关和因果的区别
了解因果关系的定义后,可以用一张图解释因果关系和相关关系的区别:

How
A/B实验: gold standard of causal inference
如果我们不关注个体粒度的因果关系,只关注整体的平均因果效应,则随机试验可以完美解决这个问题,业务上的问题基本上都属于这类。
为什么随机可以解决:随机可以保证两组用户的潜在结果一致。随机试验的实质在于分配机制(用户分流)与潜在结果无关,现实中可能影响每个人潜在结果的因素很多,其中很多观测不到,我们不需要关心,随机分组本身就保证了它和潜在结果无关。换言之,实验组/对照组可交换,每组的潜在结果可以认为是整体的潜在因果,因此可以直接对比得出因果效应(假设样本量接近无限,忽略抽样方差)。
这就是互联网公司为什么重视A/B实验,因为它可以提供其他方法很难提供的因果效应,从而指导决策。我们常说的数据驱动,不是有数据就可以驱动,需要A/B实验这样的结果数据才能更好地驱动,不然数据驱动的决策也可能是很糟糕的决策。
如何从观察数据中推断因果关系?
随机实验虽好,但不是所有场景都可行(需要考虑成本/伦理/可行性等)。那么可以从观测数据中推断因果关系吗?从前面的例子可以知道,不能直接推断,但也有方法。
假设/业务理解的重要性:以辛普森悖论为例
因果推断的前提是比较同样或者说可比较的对象。在随机试验中,这一点是通过随机分流实现的;但在观测数据里没有随机这个过程,要用别的办法。这时最重要的是从已有的知识出发,得出可信的假设,即哪些因素会影响到我们关心的X和Y;再根据这些假设建立因果模型,以推断因果关系。比如冰淇淋销售量和游泳溺水的人数相关,如果我们确定同时影响两者的变量只有温度,那就可以比较同样温度下两者是否仍然相关,由此得出因果关系。
在实际工作中,这些假设就是我们对业务的理解,这是好的数据分析工作的前提。用xx之前说的一句话,“要用业务来解释数据,而不是用数据来解释数据”。
为什么只从数据无法得出结论?
分性别看数据:应该吃药。这时要看分性别数据,而不是汇总数据。

分性别看数据
分血压看数据:不应该吃药。这时要看汇总数据,而不是分血压的数据。

分血压看数据
同样的数据,结论为何不同?什么时候要看总体,什么时候又要分维度看数据?
因果关系的识别(Identification)与估计(Estimation)
识别:根据假设和观测数据判断是否可以从中估计出因果关系,这个过程是判断一个因果效应能否用观测数据表示出来;
估计:在因果关系可识别的前提下,从观测数据中计算出因果效应大小的方法。
下面讲的DAG特别适合用来识别。估计效应大小经常要用传统的统计学方法或机器学习方法;但同样是多元回归,预测数据或估计因果时选择变量的逻辑不一样,预测只需要选提高预测准确度的变量,估计因果要根据预设的因果方向来确定。
DAG:把假设可视化呈现
DAG简介
Directed Acyclic Graph (有向无环图)是把假设可视化呈现的一种工具,用来判断在什么情况下可以识别因果关系,以及如何识别因果关系。

以分析机票价格和售出率的关系为例:(左上的a图)设Y是价格,Z是售出率,X是影响需求的其他变量(比如是否假日)。简单起见,我们认为除了X没有其他变量同时影响Y和Z,这种情况下要计算AY/Z之间的因果关系,就需要控制X,即在X固定的情况下看Y/Z之间的相关性。
在这种简单场景下,看图就可以知道应该控制哪些变量。在更复杂的情况下,DAG有一套规则来确定应该控制哪些变量。
DAG是假设的可视化,它使得假设更清晰,推理过程更明确。如果没有假设,我们无法直接从数据得出应该控制哪些变量。产出同一份数据的可能过程是很多的,不同的数据生成过程要求控制不同的变量来得到因果关系。因此如果只从数据出发,我们不可能知道哪一种做法是对的。
需要注意的是在画DAG时,每一条线都是一个因果称述,缺失的线同样重要,同样是因果判断。
后门法则
这是在图里确定控制哪些变量的一个法则,控制这些变量就可以得出因果效应(前提是图本身是对的)。步骤是列出所有变量间的路径,确认哪些是后门路径,然后看需要控制哪些变量能关闭这些路径,在图比较复杂的情况下更有用。
用DAG看辛普森悖论
性别是混杂变量,所以要分性别看数据:
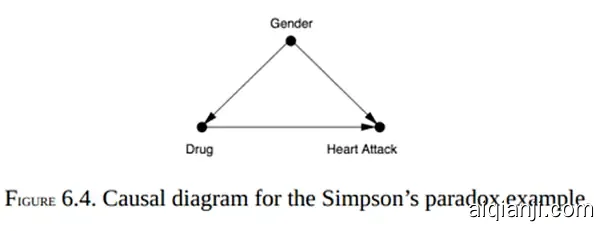
血压是药物发生作用的中介变量,所以不应该分血压看数据:

在实际问题上,因果关系可能没有这么明显。比如Google做的关于性别薪酬不平等的一项研究,结论是在同样的职位上,女性的薪酬更高一些。这样的结论合理吗?如果我们认为性别会影响获得管理职位的可能性,那比较同样职位的做法就是不准确的。

两种Bias
混杂偏差(confounding bias):Common causes

混杂偏差很常见,也比较容易被发现,这种偏差主要出现在有些变量不容易或不能被观察到的场景中。比如我们分析发现游戏转化人群中,近期有过多次转化的用户在单个游戏中的留存低于只转化一次的人群,那是否意味着我们加上转化保护后留存情况会提升?有可能但不一定,因为有过多次转化的用户和只有一次转化的用户在用户特征上不一样,而这会影响留存,只看观测数据我们无法判断转化保护的效果,因为不能直接找出可比较的用户,但我们还有随机实验,类似的还有dislike用户活跃或留存更高,有过转化行为的用户的留存/活跃更高。
选择偏差(selection bias):Conditioning on common effects

幸存者偏差即是选择偏差的一种。
招聘的案例:假设是否通过面试取决于两点:简历和能力,两者都不行的话会被刷掉,两者都很好的可能付不起工资,这样的话通过面试的人就是所有人群中的一小部分,这部分人里简历和能力的负相关就是选择偏差导致的,不足以指导决策。
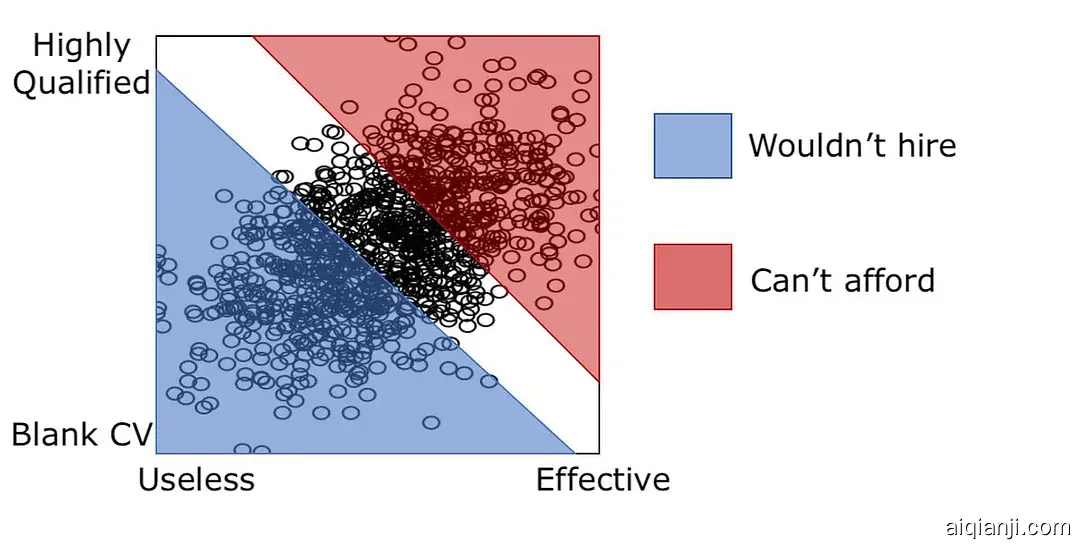
比如X-颜值Y-智商,Z-是否结婚:

这种场景很常见,比如新奇的科学发现大概率不能被重复,比如演技与颜值的相关。在广告系统里,我们看到的后验数据会受到各种因素的影响,因此选择偏差非常常见。比如计划出价和CVR的关系,在看到的数据里可能是负相关的,但这不是因为出价和CVR之间有因果关系,而是能跑出来的计划要么是出价够高要么CVR够高,只有这样预估ecpm才可能胜出。我们常说后验数据有偏,也是在说投放出来的数据不是全部数据,这对数据分析是很大的挑战,因为我们无法知道没投出来的广告的后验数据。
小结
这部分介绍了获取因果关系的常用方法和常见偏差,除了随机实验外,利用DAG可以从观测数据推断因果关系,除了DAG这种因果图的方法之外,统计学和计量经济学还发展出了断点回归/双重差分/工具变量/倾向值匹配等工具。
从观测数据推断因果关系的可靠性依赖于假设的合理性,在实际使用中推断出的因果效应可能存在较大偏差,比如FB一个衡量广告有效性的研究表明,从观测数据推断的因果效应和随机试验的结果存在较大diff,如下图:

https://www.facebook.com/business/news/insights/demystifying-measurement-why-methodology-matters
总结
- 相关关系适合预测,不适合指导决策;
- 因果关系依赖what if;
- 随机实验是因果推断的黄金准则;
- 从观测数据推断因果关系依赖假设/业务理解;
- DAG是一种可视化呈现假设的方法,且有一套规则来估计因果效应;
- 混杂偏差和选择偏差是最常见的两种偏差;
“More has been learned about causal inference in the last few decades than the sum total of everything that had been learned about it in all prior recorded history."
A “causal revolution” is upon us.
参考资料
- Causal inference in economics and marketing
- 辛普森悖论:如何用同一数据证明相反的论点
- Want to make good business decisions? Learn causality
- The Book of Why中文版
- Causal Inference in Statistics - A Primer
- Common Structures of Bias
- An Introduction to Directed Acyclic Graphs
- A Crash Course in Good and Bad Control
- Causation and Correlation
- Causal Diagrams: Draw Your Assumptions Before Your Conclusions
- Causal Inference: What If
- Tutorial on Causal Inference and Counterfactual Reasoning
- Don’t Put Too Much Meaning Into Control Variables
- Causal Data Science
- Beyond prediction: Using big data for policy problems
- Causal Reasoning: Fundamentals and Machine Learning Applications
- Using Causal Inference to Improve the Uber User Experience
- A Comparison of Approaches to Advertising Measurement
- An introduction to Causal inference
- A Revolution in Measuring Ad Effectiveness: Knowing Who Would Have Been Exposed
[深度]A/B 测试中的因果推断——潜在结果模型
对 A/B测试有了解的读者都知道,A/B测试通过用户分组进行在线试验,可以对比产品两个版本的方案找出哪一个更好。但是很多人可能会问:我为什么一定要用 A/B Testing?Google Analytics 这么强大,我的产品的用户访问一目了然,通过数据分析不难找到问题所在,A/B测试还有必要吗?

这篇文章里,作者将从因果关系方面仔细分析为什么在关键的产品决策时,您需要 A/B Testing,而不仅仅是 GA。
AB测试有两个隐含的前提:“稳定性假设”和“分配机制随机”,虽然线上互联网产品基本都满足这些设定,但是并不意味着AB测试能无往不利。在大量的场景下,稳定性假设和分配机制随机并不成立。
稳定性假设
稳定性假设通俗讲,就是测试环境和全量环境下,非实验条件是不变的。
常见的线上产品是用户自己使用,比如你刷抖音和别人刷抖音其实是互不干扰的,抖音修改了算法在20%用户下算法效果提升,在100%的用户下算法效果应该也是提升的。
但很多情况下用户之间是有关联的,比如滴滴的分单算法做了调整,一半的司机使用新算法,一半的司机使用旧算法,新算法的司机如果拿了更多的订单,就会影响剩余司机的绩效。不能把两类司机的绩效差值认为是新算法的效果。更有甚者,如果新算法的特点就是更容易抢老算法的订单,那么可能全量之后新算法效果不变或者下降。
总而言之,如果你通过所谓的随机分组之后,并不能保证稳定性假设成立,那么AB测试就会失效。
分配机制随机
分配机制随机意味着可以将用户分成随机组,保证其他因素的影响相同。问题是,能做实验的产品迭代其实是有限的。
类似按钮的样式、图片的样式、信息的排布格式这些可以AB测试,包括排序策略、召回策略、广告展示策略这些策略类也可以做AB测试。
然而这些调整简而言之就是规模比较小,对用户体验影响也并不重大。大部分重大的迭代,反而无法做测试。
比如会员权益,只能同时发布,否则一半用户没有会员权益会引起投诉。比如一系列的市场代言活动,无法进行分组测试,甚至用户无法追踪。比如商品定价策略,更不可能去做AB测试,否则一篇大数据杀熟的公众号能要了你的命。
解决方案
从数据中挖掘因果效应是近些年来计量经济学的重要方向,之前的学术研究聚焦在假设检验中,但是时代变了。在互联网时代,也许数据量不能支持所有的问题都机器学习一波流,但是达到均值差异置信是没问题的。在现在的情况下,因果关系的确认变得更加重要。在计量经济学中,有一个概念叫做潜在结果。如果一个用户被干预,会表现出行为A,不干预的潜在结果就是行为B,那么A-B的效益差就是干预变量带来的因果效应。
概念很简单,解决方案也很简单,就是找到潜在结果的估算方法。
AB测试的本质是拿对照组作为潜在结果。时间段前后分析是假设功能发布前后的其他因素稳定;时间片轮转测试,每隔1个小时用不同的策略,消除时间上的差异。这些是非AB测试之外的方法。另外回归算法也是一个好方法,可以通过回归确认某些因素对指标的影响。
相关性与因果关系
前面问题的回答从统计学上看很简单,GA 这种观察性的数据分析工具主要用于探索性的研究,它长于发现问题,而不是解决问题;它可以用来发现事物之间的相关性,但是很难用来确认因果关系。
在概率论和统计学中,相关(Correlation,或称相关系数),显示两个随机变量之间线性关系的强度和方向。
——维基百科
相关性在探索性的研究中是很有用的,它可以在实践中预示某种关系,指明进一步研究的方向。相关性的典型例子是产品的需求和价格的关系,空气质量和汽车数量的关系。这两个相关性的例子都暗示了更进一步的因果关系,因为从经济学上看价格下降会提升需求,汽车数量增加使得尾气排放量增加而导致空气质量变差。但是,不是所有的相关性都有因果关系,相关并不意味着因果。
15 Insane Things That Correlate With Each Other 这个网站收集了很多看起来很荒谬的相关性例子。
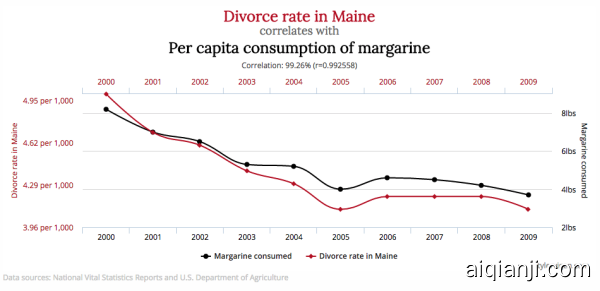
上面的例子中,美国缅因州的离婚率和人均黄油消耗量在 2000 年至 2009 年间达到了极强的相关性(相关系数 0.9926)。吃黄油和离婚明显是没有因果关系的两件事,因为根据我们的常识,吃多点黄油不至于让人性情大变而导致离婚,离婚之后也不太可能因为心情沮丧而多吃黄油。
如果我们的研究目的是找出缅因州离婚率下降的主因,人均黄油消耗量和离婚率之间的相关性有用吗?显然这个相关性的作用是很有限的,你不能据此得出结论:少吃黄油有助于婚姻和谐。我们希望得到的是和离婚率之间的因果关系,这就需要针对性的调查或试验。吃黄油和离婚两者表面上的相关性顶多起到提示性的作用(假如有的话),例如,研究人员可能会想到,是否有一个第三因素,导致了缅因州离婚率和黄油消耗量的共同下降,如经济形势?
因果关系在很多应用场合是我们的核心关注点,例如产品的优化方案。更醒目的 Call to Action 按钮是否会促进着陆页的转化?什么样的表单用户更愿意去完成?这些问题的背后都是一些 PM 需要去确证的因果关系,正是 A/B 测试可以大展身手的地方。
A/B 测试也称为在线对照试验 (Online Controlled Experiments) ,是一种科学地进行统计因果推断的研究方法,它和其他统计研究方法(如观察性研究)的主要区别在于它可以通过针对性的试验简单高效地对所考察的因素和变量间的因果关系进行科学地推断。
那到底什么是因果关系呢?
因果关系是一个事件(即“因”)和第二个事件(即“果”)之间的关系,其中后一事件被认为是前一事件的结果。一般来说,因果还可以指一系列因素(因)和一个现象(果)之间的关系。对某个结果产生影响的任何事件都是该结果的一个因素。
——维基百科
A/B 测试要研究的就是这种简单逻辑上的因果关系,而不是先有鸡还是先有蛋这种近乎哲学上的因果。确切地说,我们通过试验要证明的是:某个因素/处理是否会对某个现象/结果产生作用。

下面我们将根据统计学上的潜在结果模型,仔细分析因果关系的定义和推断过程。
潜在结果
首先明确一下统计学上因果关系的定义。在试验的上下文中,我们讨论的因果关系是和某个处理 (treatment) 关联在一起的,作用的目标主体是参加试验的个体。
一个或多个处理作用在个体上产生的预期效果我们称之为潜在结果 (Potential outcome)。之所以称为潜在结果是因为在一个个体上最终只有一个结果会出现并被观察到,也就是和个体所接受的处理相对应的那个结果。另外的潜在结果是观察不到的,因为它们所对应的处理并没有实际作用在该个体上。
举个例子,今天北京是重度雾霾天(很正常),你出门可能戴口罩了,也可能没戴口罩(忘了,很不幸!)。这个小试验的个体就是你,戴口罩和不戴口罩就是两个不同的处理。戴或者不戴,当然只能选一个,结果也只能观察到一个。如果你没有戴口罩,今天痛苦地咳嗽了 100 分钟(会不会挂掉?),你会很后悔地想:要是我今天记得戴口罩,那么我可能只会咳嗽 10 分钟。戴口罩的话你会咳嗽 10 分钟,不戴口罩的话你会咳嗽 100 分钟,咳嗽 10 分钟和 100 分钟分别就是这两个处理所对应的潜在结果。因为你实际上没戴口罩而咳嗽了 100 分钟,所以,这戴口罩只咳嗽 10 分钟的潜在结果只是你想象的结果,不是实际发生和观察到的。
听起来是不是有点反事实 (Counterfactual) 推断的味道?是的,潜在结果就是这种想象中的:假如我这几年买的是美股,而不是 A 股,那结果就是赚 100 万,而不是赔 100 万了(捶胸顿足)。
因果效果
在定义了潜在结果之后,不同的处理产生的因果效果 (Causal effect)就很清楚了,它就是不同潜在结果的比较。

在上面的例子中,作用在个体“你”上的因果效果就是戴口罩咳嗽 10 分钟 – 不戴口罩咳嗽 100 分钟 = 少咳嗽 90 分钟。我们用符号 Y 来表示潜在结果,Y(不戴口罩) 和 Y(戴口罩) 分别表示两个不同处理(戴 or 不戴口罩)情况下的潜在结果。
我们可以看出,因果效果的定义依赖于潜在结果,但是它并不依赖于哪一个潜在结果实际发生。无论你今天戴了口罩(观测到咳嗽 10 分钟)还是没戴口罩(观测到咳嗽 100 分钟),个体的因果效果都是不变的(戴口罩少咳嗽 90 分钟)。
可能你会问了:事实上我今天没戴口罩,我知道我咳嗽了 100 分钟,但是我怎么知道如果我戴了口罩,只会咳嗽 10 分钟呢?这确实是个问题,戴或者不戴口罩,你只能选择一个,观测到一个结果。聪明的读者可能会想到一个解决办法:你可以今天不戴口罩,明天戴口罩,对比一下,不就知道了吗?这个办法在逻辑和推断上不是那么严谨的,因为今天和明天,尽管只隔了一天,但是很多情况会发生变化,导致今天戴口罩和明天戴口罩观察到的咳嗽时间是不一样的。例如,虽然北京的雾霾每天都很醇,但是今天和明天还是有差别的,可能今天和燕京啤酒一样醇,明天和茅台一样醇,那么你今天戴口罩会咳嗽10次,明天戴还是要咳嗽 100 次。很明显,有雾霾时段这个另外的因素影响的话,我们就不知道戴口罩的效果是多少了,因为第二天的醇如茅台的雾霾完全抵消了你戴口罩的效果,让你误以为戴口罩没有用。

我们都知道 A/B 测试是隔绝了其他影响因素条件下对某个因素的效果进行比较,而把今天的结果和明天的结果进行直接比较的做法已经不是严谨的对照试验了。从潜在结果模型的观点来看,今天的“你”和明天的“你”已经不是同一个统计个体了 (⊙o⊙)(虽然从物理上看,明天的你还是原来的你),而个体级别的因果效果是对同一个统计个体而言的。因此,对比个体在不同时段得到的潜在结果不再能够反映个体的因果效果,据此决策将导致逻辑上错误的结论。
难道就没有办法了吗?是的,时光不能倒流,你不可能在不戴口罩观测一次之后再回退然后戴口罩重来一次。对于作用在个体上的因果效果而言,我们确实没有太好的办法。从因果效果的定义上来看,因为两个潜在结果你注定只能观测到其中一个,所以你不能只靠一个实际观测结果就知道比较的效果,这是统计因果推断要解决的一个基本问题。
不过好消息是在 A/B 测试中我们关心的是如何“估计”总体中所有个体上的平均因果效果,没必要准确知道每一个个体的因果效果。因此,和上面类似的办法在恰当的统计模型下也是可行的。
这里我们要注意到因果效果的“定义”和“估计”的区别。大家都知道统计是一门以概率为基础的科学,统计推断得到的结论不是绝对正确的唯一结果,而是有一定概率分布的多种可能结果。我们进行因果推断的主要任务是要得到有一定概率保证的“估计”,而不是绝对符合“定义”的正确结果。
因果效果的“估计”和“定义”相比所要进行的潜在结果的比较是不同的。因果效果的定义不要求多个个体,而对于估计和推断,我们需要比较实际观测到的潜在结果,我们不得不考虑多个个体的情况。因为单个个体我们只能观测到一个潜在结果,我们必须观测多个个体,其中一部分和另外一部分分别接受不同的处理,观测到不同的潜在结果。我们前面说的同一个人在不同时段的比较,以及不同人在同一时段的比较,都属于多个个体的情况。这样的比较尽管不严格符合因果效果的定义,却是估计因果效果的关键方法。
SUTVA 假定
有了多个个体进行观测就万事大吉了吗?统计学家常用的一招还没使出来呢,那就是把复杂的现实世界简化为理想数学模型的强力手段——假定 (Assumption)。
在因果推断的潜在结果模型中,我们需要一个非常重要的 SUTVA (stable unit treatment value assumption) 假定,它包括两个部分:
任何个体的潜在结果不受其他个体所接受处理的影响;
每一个个体所接受的处理水平是唯一的,所导致的潜在结果也是唯一的。
我们先看看 SUTVA 假定的第一部分,无干扰原则:某个体所接受的处理不会影响到其他个体的潜在结果。以上面的例子来说,就是假定你戴口罩与否不会影响你的朋友小强和小明的咳嗽时间。在我们的雾霾小试验中,这显然是一个很合理的假定。因为个人的力量是有限的,即便你不戴口罩大力呼吸,为北京的空气净化作出了很大个人牺牲,这点微薄贡献和整个北京的雾霾相比是微不足道的,小强和小明吸入的雾霾不会因此变少,当然咳嗽时间也不会有变化。(不过,如果咳嗽能够传染,而你和小明在一起的话,这种情况下无干扰原则可能就不能成立了:你不戴口罩使劲咳嗽传染了带口罩的小明,小明的咳嗽时间也增加了。)
无干扰原则是很重要的,如果个体之间互相干扰,干扰的效果难以确定,那么潜在效果的比较就不准确,不同处理造成的因果效果就很难确定了。在实际应用中,我们通常根据试验的内容及相关的知识来判断这个原则是否成立。在大多数情况下,这个原则是成立或者说近似成立的。但是在某些特殊试验情况下,这个原则是否成立就要慎重考虑了。
例如,在社交类产品如微信的 A/B 测试中,假如产品经理要测试新版的红包设计是否会促使用户发送更多的红包,无干扰原则很可能就不成立了。因为即使看到新版红包的用户很喜欢这个设计从而发送了更多的红包,但是没看到新版红包的用户可能因为收到朋友更多的红包,出于回赠心理也发送了更多的红包,这样新版的用户和老版的用户之间的效果就难以比较了。
SUTVA 假定的第二部分是指所有处理水平都是已知和明确定义的,没有隐藏的不同之处。以我们的雾霾小试验为例,处理水平只有两个:戴口罩和不戴口罩。这里我们认为,戴口罩的作用对个人是相同的,没有不同牌子的口罩带来过滤效果不同诸如此类的影响。如果你戴的口罩是 3M 牌子,他戴的口罩是 9M 牌子,是 3M 牌子效果的 3 倍,SUTVA 假定的第二部分就不成立了。
我们必须注意到,SUTVA 假定的第二部分并没有要求每个个体所受处理的潜在结果是相同的,它只要求指定个体及处理水平的潜在结果是明确不变的。
SUTVA 假定是使用潜在结果模型进行因果推断的前提,因此,我们在进行试验前,必须认真考虑试验的情况,检查该假定是否成立。如果假定不成立,据此进行推断很难得到可信的结果。
此文中我们介绍了用于A/B测试因果推断的潜在结果模型,包括潜在结果的定义,因果效果和 SUTVA 假定等重要的概念,下一篇文章中我们将从统计学上看看这个模型是怎么应用的。
一、分流机制
前面我们说过,对于因果效果的估计,我们需要比较多个个体的实际观测到的潜在结果,其中一部分个体和另外一部分分别接受不同的处理,观测到不同的潜在结果。
假如我们有两个用户参与这个雾霾小试验:小强和小明,观测到如下的结果。
表面上来看,小强不戴口罩咳嗽 100 分钟,小明戴口罩也是咳嗽 100 分钟,我们也许就简单地得出一个结论:雾霾时戴口罩没有用,咳嗽不会少。
但是真实情况可能是:小强对雾霾的抵抗力比小明好很多,所以他不戴口罩咳嗽 100 分钟,戴口罩只咳嗽 10 分钟;而身体较弱的小明不戴口罩会咳嗽 200 分钟,戴口罩咳嗽 100 分钟。
那么真实的因果效果应该是戴口罩少咳嗽 100 分钟左右,我们从数据表面得出的戴口罩无用的结论是错误的。
上面给出的是一个只有两个个体的简单例子,如果参与试验的个体很多,同样可能出现这样的状况。
- 问题出在哪里?
显然,个体之间是存在差异的,如果我们把抵抗力强的分派在一组,把抵抗力差的分派到另外一组,然后进行对比,结果就会和真实情况偏差很大,从而得出错误的结论。
问题的关键在于参与试验的用户进行分组的方法,也就是哪些用户观测到戴口罩的潜在结果,哪些用户观测到不戴口罩的潜在结果,这是对试验比较的结果影响很大的重要因素。
我们把这个分组的过程称为用户分流/分派机制 (assignment mechanism)。
也就是说,多个个体参与试验并不足以保证我们进行有效的因果推断,我们必须掌握个体的分流机制这个关键信息或者对其进行有计划的控制。
分流机制和因果效果的定义没有关系,但是它是潜在结果模型应用过程中的关键一步,是决定效果估计准确性的重要因素。
我们通常需要在试验设计中选择一个好的分流方案,以使得因果效果的估计接近于它的定义,并且尽可能提升试验的统计功效。
因果效果是通过潜在结果(只能观测到其中一个)的比较来定义的,和实际接受到的处理无关。
但是,因为我们只能观测到一半的潜在结果,无法得知个体的因果效果,在评估因果效果时就存在一个因果推断的困难:数据缺失问题,个体没有接受到的处理所对应的潜在结果的数据是缺失的。
因此,解决问题的关键就是缺失数据的处理机制,在因果推断中就是分流机制。
哪些个体应该接受哪些处理,或者说哪些潜在结果应该被观测到?分流机制的这些分派决定是非常关键的。
我们再看看有 4 个用户参与雾霾小试验的例子,这次试验增加了用户小芳和小刚,小芳和小强在一组,不戴口罩;小刚和小明在一组,戴口罩。
观测到数据如下:

这次从数据上看:不戴口罩咳嗽 150 分钟(平均)、戴口罩咳嗽 55 分钟(平均)、结论是戴口罩可以减少咳嗽时间 95 分钟(平均)。
和真实的个体因果效果对比我们可以看出,这个估计结果是很准确的。
这次试验为什么可以推断出正确的结论呢?
因为我们增加了试验用户小芳和小刚,而小芳的雾霾抵抗力和小明接近(相同),小刚的抵抗力和小强接近(相同);
从而解决了数据缺失的问题:你可以把小芳的结果看作是小明没有观测到的不戴口罩情况下的潜在结果,把小刚的结果看作是小强没有观测到的戴口罩情况下的潜在结果。
这里分流的关键在于把用户属性(抵抗力)差不多的小强 vs 小刚,以及小明 vs 小芳,分派到两个不同的组,接受不同的处理。
如果反过来,把属性差不多的用户都放在同一个组,那么数据缺失问题还是没有得到解决,试验结论和上面两个用户情况下的试验一样依然是错的。
从这两个例子我们可以看出:我们不能脱离个体的分流机制而仅仅由个体观测到的潜在结果来进行因果推断。
有效的推断要求我们必须考虑这个问题:为什么这些用户接受这个处理,另外的用户接受另一个处理?
二、随机化试验
采用随机化分流方式的试验设计就是随机化试验 (Randomized Experiments),它是我们在 A/B 测试中进行统计推断的基础。传统的随机化试验主要有三种类型:
伯努利(Bernoulli)随机化试验完全随机化试验(Completely Randomized Experiments)分层随机化试验(Stratified Randomized Experiments)最简单的 Bernoulli 试验以类似于抛硬币的方式来决定每一个个体的分派;
完全随机化试验中每个 treatment 分派到的个体数量是固定的,但个体的分派是随机的;分层随机化则是在完全随机化的基础上,先通过协变量对总体进行分层,然后在层内随机化分派。
不同的随机化试验类型(随机化分流方式)导致不同的分派概率分布。
以完全随机化试验为例,其个体概率如下:
根据这个概率分布,我们就可以对总体的平均因果效果进行统计推断和估计了。
平均因果效果的估计
让我们先从数学上正式地定义平均因果效果(Average Causal Effect),它是我们试验和分析的最终目标。
首先把总体中所有的个体编号为 i = 1, …, N,N 是总体的容量。
每个个体可接受一组处理中的一个,我们用 Ti 来表示个体 i 可接受的处理的集合。
大多数情况下,这个集合对所有个体都是相同的。
在我们的小试验中,Ti 包括两个处理水平:0 表示不戴口罩(control 组),1 表示戴口罩(treatment 组)。
每个个体可接受的处理水平都有一个对应的潜在效果,Yi(0)和 Yi(1)、Yi(1)和 Yi(0) 的比较(通常是差值),就是个体 i 的因果效果了。
个体的因果效果我们是无法直接得知的,也不是我们的关注重点。
我们通常关心的是总体中所有个体的因果效果的平均值,即平均因果效果。
其中
分别是所有个体不戴口罩(0)的平均潜在结果,和所有个体戴口罩(1)的平均潜在结果。
ACE 就是我们试验分析的目标,它等于“戴口罩(1)的平均潜在结果 ——不戴口罩(0)的平均潜在结果”。
我们前面已经说过,每个个体的两个潜在结果只能观测到其中一个,另外一个是不知道的,所以Yi(0)和Yi(1) 里面有一半是没有观测值的,我们不能由 ACE 的定义公式直接计算出它的值。
对 ACE 的一个很自然的估计量就是“treatment 组观测到的平均潜在结果—control 组观测到的平均潜在结果”
假设参与试验的 N 个用户中有 Nt 个分派到 treatment 组,Nc 个在 control 组,那么 treatment 组和 control 组的平均潜在结果分别是
我们需要评估一下这个估计量的准确性,最基本的衡量标准就是它是否 ACE 的无偏估计,即该估计量的期望是否等于 ACE。
令指示变量 Wi 表示个体 i 被分派的处理(取值 0 或 1),估计量可改写为:
其期望值:
如果分派机制 W 是完全随机化分派,那么随机变量 Wi 的期望:
因此可得:
可知,在完全随机化试验中,我们根据直观得到的简单估计量是 ACE 的无偏估计,是基本可用的。
从上面的推断过程可以看出,个体的完全随机化分派机制在其中扮演了非常重要的角色,正是由于随机变量 Wi 的概率分布的特点,使得 ACE 的这个简单估计量是无偏估计。
现在我们来看看这个 ACE 估计量的精确性,也就是其抽样方差。
根据随机变量 Wi 的概率分布的特点,通过类似的方法,可得到 ACE 估计量的方差为:
其中
分别是潜在结果 Yi(0)和 Yi(1)的样本方差,而
则是个体因果效果 Yi(1) – Yi(0) 的样本方差。
如果总体中的个体因果效果为常量(例如,戴口罩的效果对所有人都是少咳嗽 100 分钟),那么该项为 0,我们得到:
以观测到的组内样本方差近似代替总体的样本方差可得到一个方差估计量:
结合平均因果效果的估计量和抽样方差估计量可得到假设检验统计量为:
是不是看起来很眼熟?嗯,其实就是我们常用的独立双样本情况下的 z 检验量的计算公式:
本文作者:吆喝科技大数据产品经理钟书毅
- 因果推断方法可以被分为两大类:贝叶斯网络结构学习算法和基于加噪声模型的因果推断算法。具有完整数据的因果推断方法可以被分为两大类: 基于估计马尔可夫等价类的贝叶斯网络结构学习算法和基于加性噪声模型的因果推断算法。
- 贝叶斯网络结构学习算法主要有两种方法.第一种是基于打分-搜索的贝叶斯网络结构学习方法,第二种是基于依赖分析的学习算法.缺点:,这两种方法都无法识别 一个因果网络中存在的马尔可夫等价类,特别是这类方法无法 区分 X→Y 和 Y→X 两种情况。
- 在基于加噪声模型的算法方面
线性:
Shohei等人提出了一种基于线性ANM的算法,可以从数据集中构建出具体的因果网络图,利用 ANM 在缺失数据因果推断中数据填补上将变得更加简易和准确。缺点:只适用于线性加噪声模型,无法解决非线性问题.
非线性:
Hoyer等人提出了一种在基于非线性加噪声模型的适用于连续数据的算法(ANM), Peters 等人对 ANM 算法进行了深一步的推广,使之适用于离散型数据。缺点:非线性加噪声模型算法都只适用很低维的数据集,一旦数据集的维度较大(n>8),准确度就会降到很低;
JonasPeters等人提出了一种基于非线性ANM的算法去解决离散数据的问题,缺点:非线性加噪声模型算法都只适用很低维的数据集,一旦数据集的维度较大(n>8),准确度就会降到很低;
JanzingD等人提出了一种基于信息熵的因果推断算法IGCI,这种算法可以适用于有无噪声的情况,相对于ANM 算法,IGCI 算法能很好地控制判断率,并且在判断率高的时候其对无向图边的方向识别准确率要高于其余的因果推断算法缺点:IGCI也无法处理高维数据,只要维数超过2,方法就失效.
缺失数据:
基于 EM 算法的评分—搜索方法和王双成等人提出的基于依赖分析的 BN-GS 算法。缺点:不能识别到一个准确的因果图,缺点原因:算法都是倾向于拟合数据的( 条件) 概率分布或提高预测的准确性而不太关注局部的因果机制,换句话说,对局部边的方向依然没有准确的判断。
- 因果网络是表示变量间概率依赖关系的有向无环图(DAG),它可表示为一个三元组G=(N,E,P).其中,N={x1,x2,...,xn}表示DAG中的所有节点的集合,每个节点代表一个变量(属性).E={e(xi,xj)|xi,xj∈N}表示DAG中每两个节点间的有向边的集合.其中,e(xi,xj)表示xi,xj间存在依赖关系xi→xj.P={P(xi|xj)|xi,xj∈N}是一组条件概率的集合,其中P(xi|xj)表示xi的父节点集xj对xi的影响.
- d-分离准则:设X、Y、Z是因果无向图G中任意3个互不相交的节点的集合,称Z在图G中d-分离节点集X和Y,记为X⊥Y|Z,如果对任意的从X的节点到Y的一个节点的路P均被Z阻断,也就是路径P上存在一个结点w满足下列其中一个条件:(1)w在P上有—个碰撞箭头,即→w←(此时称w为碰撞点),且w及其后代结点都不在Z中.(2)w在P上无碰撞箭头,即→w→或←w←或←w→,且w∈Z。
- 条件独立性测试:设X、Y、Z是因果无向图G中任意3个互不相交的节点的集合,如果Zd-分离节点集X和Y,那么在给定Z的情况下,X和Y统计独立.
- 互信息:描述了某个变量取值对另外一个变量的取值能力.两个变量间的互信息越大,表明它们之间的关系紧密,反则越小.当且仅当X和Y互相独立的时候,它们之间的互信息I(X;Y)=0.
- ANM定义:若X,Y∈Z,存在噪声变量N∈Z和映射函数F(Z→Z)满足以下条件,则称X到Y能符合ANM;否则,X到Y不能符合ANM。Y=F(X)+N,N⊥X(1)其中:N⊥X表示N与X统计独立。文献[5,6,14]基于ANM利用如下因果推断准则判断变量间的因果方向:若X到Y符合一个ANM,而Y到X不能符合一个ANM,则称X是Y的原因,Y是X的结果,即X、Y方向判定成X→Y(Y→X同理判定);若X到Y和Y到X都符合ANM,那么X、Y之间的方向是可逆的(即XY);若X到Y和Y到X不能符合ANM,那么X、Y之间的方向无法确定,需要其他方法判断。
[ 5] Shimizu S,Hoyer P O,Hyvarinen A,et al. A linear non-Gaussian acyclic model for causal discovery[J] . The Journal of Machine Learning Research, 2006, 7( 4) :2003-2030.
[ 6] Hoyer P O,Janzing D,Moolj J M,et al. Nonlinear causal discovery with additive noise models[C]/ /Advances in Neural Information Processing Systems.[S. l. ]: MIT Press, 2009:689-696.
[ 14]Zhang Kun,Hyvrinen A. Causality discovery with additive disturbances: an informationtheoretical perspective[C]/ /Proc of Joint European Conference on Machine Learning and Knowledge Discovery in Databases. Berlin: Springer, 2009:570-585.
- 贝叶斯网络结构学习以变量(节点)的条件概率(后验概率)作为学习参数的缺点:条件概率只是在联合概率分布下刻画变量间的联系,没有真实反映变量之间的因果信息。
- 最大似然估计的优点:最大似然估计是统计意义上最优的参数估计方法,它比其他可选择的参数估计方法更加简单有效,特别在样本增加时,其收敛性质会更好。