1. 简介
人类思维具有将原因与特定事件联系起来的能力,我们不断地联系导致特定效果的事件链。神经心理学将这种认知能力称为因果推理。计算机科学和经济学研究一种特定形式的因果推理,称为因果推理,侧重于探索两个观察到的变量之间的关系。多年来,机器学习产生了许多因果推理的方法,但是在没有A / B测试的情况下这些基于模式识别和相关分析的传统机器学习方法不足以进行因果推理,这导致它们仍然难以在主流应用中使用。
因果科学的工作大致可以分为基础因果假设及框架(fundamental causal assumption and framework)、因果学习(causal learning)、因果推断(causal reasoning/inference)和应用系统
其中因果学习又可以分为因果结构学习(causal discovery/causal structure learning)和因果表示学习(causal representation learning)。
为什么需要因果推断?
与监督学习不同,因果推断取决于对未观察量的估计。预测模型揭示了连接观察数据中输入和结果的模式。但是,为了进行干预,我们需要估计从当前值更改输入值的各种效果,因为没有数据存在。这些涉及估计反事实的问题在决策方案中很常见。
它会起有效吗?对系统的拟议更改是否会改善人们的结果?它为什么有效?是什么导致了系统结果的变化?我们应该做什么?系统的哪些变化可能会改善人们的成果?总体效果如何?系统如何与人类行为相互作用?系统建议对人们活动的影响是什么?回答这些问题需要因果推理。虽然存在许多用于因果推理的方法,但很难比较它们的假设和结果的稳健性。
2. 概率编程框架
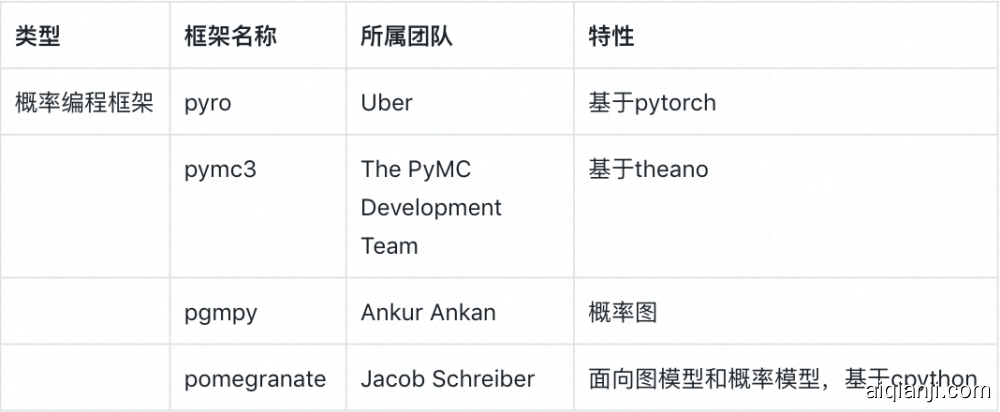
相关链接:
pyro:
pymc3:
pgmpy:
https://github.com/pgmpy/pgmpy
pomegranate:
https://github.com/jmschrei/pomegranate
3. 工具包


相关链接:
TETRAD:
https://github.com/cmu-phil/tetrad
CausalDiscoveryToolbox:
https://github.com/FenTechSolutions/CausalDiscoveryToolbox
gCastle:
https://github.com/huawei-noah/trustworthyAI/tree/master/gcastle
tigramite:
https://github.com/jakobrunge/tigramite
Ananke:
https://ananke.readthedocs.io/en/latest/
EconML:
https://github.com/microsoft/EconML
dowhy:
https://github.com/microsoft/dowhy
微软研究院:DoWhy,一个基于Python的专注因果思考和分析的框架。DoWhy为因果推理方法提供了统一的界面,并自动测试了许多假设,从而使非专家可以进行推理。它试图简化机器学习应用中因果推理的采用。受到Judea Pearl的因果推理的微积分的启发,DoWhy在一个简单的编程模型下结合了几种因果推理方法,消除了传统方法的许多复杂性。
DoWhy的设计还是为了显示常被忽略的因果分析假设。所以,DoWhy的特点之一就是会让潜在的假设更容易理解。另外,DoWhy可以进行敏感度分析和其他鲁棒性检查。我们的目的是让人们关注他们在对因果推断做假设时的思考而不是其中的细节。
总结一下,DoWhy为因果推理模型的实施做出了三项重要贡献。
提供将给定问题建模为因果图的原则方法,以便明确所有假设。为许多流行的因果推理方法提供统一的界面,结合图形模型的两个主要框架和潜在的结果。如果可能,自动测试假设的有效性,并评估估计对违规的稳健性。从概念上讲,DoWhy是根据两个指导原则创建的:明确要求因果假设,并测试对违反这些假设的估计的稳健性。换句话说,DoWhy将因果效应的识别与其相关性的估计分开,这使得能够推断出非常复杂的因果关系。
为了实现其目标,DoWhy通过四个基本步骤对工作流中的任何因果推断问题进行建模:模型,识别,估计和反驳。

模型: DoWhy使用因果关系图来模拟每个问题。当前版本的DoWhy支持两种图形输入格式:gml(首选)和点。该图可能包括变量中因果关系的先验知识,但DoWhy没有做出任何直接的假设。
识别:使用输入图,DoWhy根据图形模型找到识别所需因果效果的所有可能方法。它使用基于图形的标准和do-calculus来找到可以找到可以识别因果效应的表达式的潜在方法
估计: DoWhy使用统计方法(如匹配或工具变量)估算因果效应。当前版本的DoWhy支持基于倾向的分层或倾向得分匹配的估计方法,这些方法侧重于估计治疗分配以及侧重于估计响应面的回归技术。
验证:最后,DoWhy使用不同的稳健性方法来验证因果效应的有效性。
causalml:
https://github.com/uber/causalml
WhyNot:
https://whynot.readthedocs.io/en/latest/
CausalImpact:
https://github.com/google/CausalImpact
Causal-Curve:
https://github.com/ronikobrosly/causal-curve
grf:
https://github.com/grf-labs/grf
dosearch:
https://cran.r-project.org/web/packages/dosearch/index.html
causalnex:
https://github.com/quantumblacklabs/causalnex
4. 数据集或基准
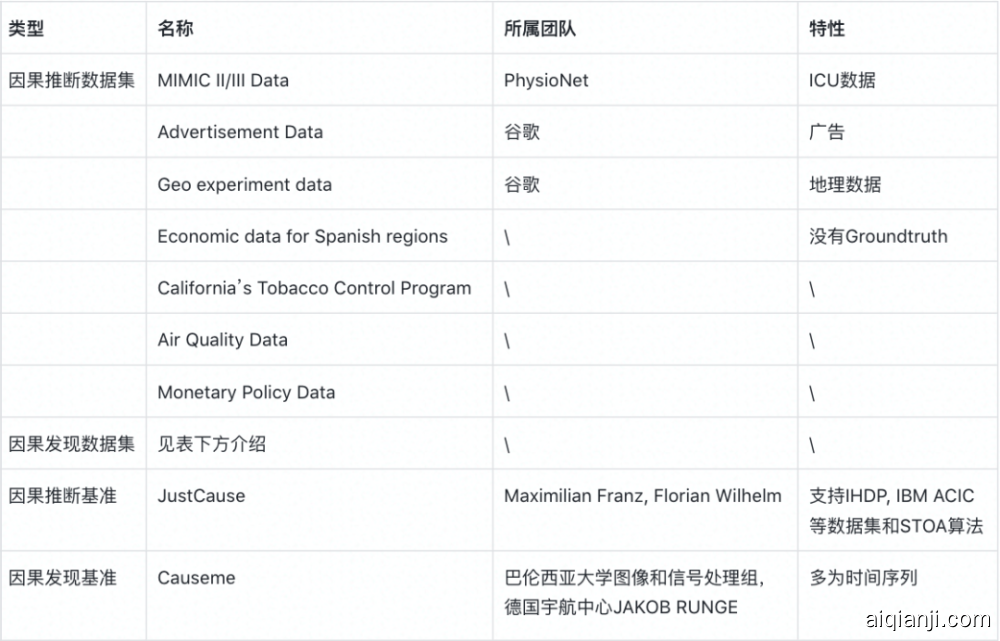
。
- 因果推断是什么?
1.1 因果性与相关性
事件/变量之间的关系,最主要的有相关性和因果性。
相关性是指在观测到的数据分布中,X与Y相关,如果我们观测到X的分布,就可以推断出Y的分布
因果性是指在操作/改变X后,Y随着这种操作/改变也变化,则说明X是Y的因cause
在常用的机器学习算法中,关注的是特征之间的相关性,而无法去识别特征之间的因果性,而很多时候在做决策与判断的时候,我们需要的是因果性。
举个例子,我们会发现在学校中,近视的同学成绩更好。近视和成绩好之间有强相关性,但显然近视不是成绩好的原因。而我们想要提升学生成绩,自然需要找到因,否则就会通过给学生戴眼镜的方式来提高成绩。
上面的例子是很明显地可以区分出相关与因果的,但是也有很多难以区分的,如经常喝葡萄酒的人寿命更长,是因为葡萄酒确实能延长寿命,还是因为能经常喝的人通常更富有,享有更好的医疗条件。
1.2 识别因果的必要性
很多时候,我们通过统计学方法或者机器学习算法得到的特征之间的相关性,就足以为我们的验证、决策提供指导,比如,我们通过数据发现,用户曝光的图片越多,留存越高,我们不需要知道这之间是否有复杂的因果关系,只需要通过简单的ABtest来检验更多的曝光是否有效果即可。
是否还有必要去识别因果性呢?答案是有的。
很多时候,我们需要确切地知道因果性,且无法通过ABtest简单地判断,比如:
药物是否有效、政策是否有效,这种问题无法做ABtest
新的推荐算法是否有效,ABtest成本高(不好的用户体验等)
……
因此,面对这种特殊的问题,我们需要从已有的数据中推断出变量间的因果性。
1.3 本质是对因果效应的估计
前面说了因果性和相关性的区别、以及识别因果性的必要性,那么因果推断究竟是什么?
因果推断的核心思想在于反事实推理counterfactual reasoning,即在我们观测到X和Y的情况下,推理如果当时没有做X,Y'是什么。
因果推断的目的是要判断因果性,即计算因果效应(有无X的情况下Y值的变化量)。在进行反事实推理后,可得出因果效应e = |Y - Y'|,进而判断因果性。
实际上,对于一个对象,我们永远只能观察到Y和Y'的其中一个,因果推断所做的就是从已有数据中估计因果效应,所以我认为因果推断的本质是,对因果效应的估计。
- 一些因果推断的方法
上一部分对因果推断做了简单的介绍,本部分主要介绍一些因果推断的方法,如下图所示——
2.1 随机实验Randomization
2.1.1 A/B Test
以推荐算法为例,判断推荐算法是否有效,ABTest通过将用户随机分为两组,分别应用不同的算法,通过判断两组用户点击率的差异来估计因果效应。通过随机分组,排除了混淆变量的影响。
A/B Test实际上是判断因果性的很有效的方法,但有时候成本过高无法采用,如这里的推荐算法——
可能新的推荐算法太差导致用户流失
如果有很多新的算法要测试,A/B Test效率较低
2.2.1 多臂老虎机 Multi-armed bandits
针对上述问题,另一种随机实验方法是强化学习中的多臂老虎机,实际上是对explore和exploit的平衡。
explore,随机选择一个动作,在上面的问题中是随机选择一个算法
exploit,选择收益最高的动作,在上面的问题中是选择当前效果最好的算法
通过某种规则(e-greedy等)重复上述过程,优点是可以同时测试多种算法,并且每个用户都能使用到最好的算法,减少流失可能性。缺点是效果难以评估,也很难让用户按照我们的想法行动。
2.2 自然实验Natural Experiments
理想的实验需要:随机分配(分组)、人为干预(施加不同的treatment)、结果比较,
自然实验实际上是一种观察性研究,满足上述三个条件中的两个,是指不加干预地、实验对象**“自然”**地分为若干组,对实验对象的结果进行观察比较。
显然自然实验法的关键在于,实验对象是否能“自然”/随机地分组。比如,将是否民主将国家分为两组,探究制度与国家对外战争的关系。但是在这里,是否民主不是随机的分给各个国家,所以无法满足自然实验所需的随机分配原则。
2.2.1 断点回归Regression discontinuity
断点回归是自然实验中的一种观察方法,简单理解就是在回归过程中,观察在临界点处是否出现断层/断点。
举一个简单的例子,假设现在有一个产品,收集500个金币后就可以得到一个勋章,现在要判断有无勋章对用户在线时长的影响。
断点回归法观察金币在500附近的用户,如497到502,观察【接近500但小于500(无勋章)】与【接近500但大于500(有勋章)】的用户在线时长是否有显著区别,若有,说明有勋章很可能会增加用户的在线时长。
2.2.2 工具变量Instrumental Variables
对于要判断因果关系的两个变量间,如果存在其他混淆变量,在计量经济学中采用工具变量的方法解决。
以下述关系为例,要判断对APP1的访问,是否会导致对APP2的点击。实际上由于APP1和APP2之间的需求关系,误差项与解释变量相关,即计量经济学中的内生性。
引入工具变量的目的是为了让误差项与解释变量不相关。具体地,通过找到一个变量,满足与解释变量相关且与误差项无关,那在引入这一变量之后,解释变量变化的部分就与误差项无关。
同样是上面的例子,假设某一天有个活动,下载APP1的人有奖励,这个活动与解释变量相关,但不会影响到APP2的需求,那根据多出来的APP1访问量与多出来的APP2点击率就不再受到需求关系的影响,就可以判断对APP1的访问,是否会导致对APP2的点击。
2.3 Conditioning
2.3.1 分层Stratification
分层的核心思想是控制条件变量,一般步骤如下:
尽可能完整的绘制出变量之间的因果图
选择影响要判断因果性的变量的条件变量
对用户进行分层/分组,满足组内的用户条件变量取值一致(上层的变量将全部不需要再考虑,类似贝叶斯网络中的d分隔)
比较两组用户的输出,计算因果效应
这种方式有点类似要找到相似的用户,当条件变量很多的时候,这种方法很难实现,很难找到很多条件变量都相同的用户,即使找到也会使得分组偏小。
2.3.2 倾向得分匹配Propensity score matching
当条件变量很多的时候,可以考虑使用倾向得分匹配。
以推荐算法为例,当条件变量很多的时候,通过逻辑回归等方法对这些变量进行训练,并计算出一个倾向得分,在这里是用户被施加新算法的概率。因此倾向得分匹配的一般步骤如下:
尽可能完整的绘制出变量之间的因果图
选择影响要判断因果性的变量的条件变量
对用户进行分层/分组,满足组内的用户计算得出的倾向得分接近(上层的变量将全部不需要再考虑,类似贝叶斯网络中的d分隔)
比较两组用户的输出,计算因果效应
3. 小结
关于因果推断,上面介绍了三类方法——
如果可以的话,尽可能使用随机实验(ABtest……)
如果无法进行随机实验,则探索自然实验(断点回归……)
如果自然实验也无法找到,考虑使用基于条件的方法(倾向得分匹配……)
原文链接:https://blog.csdn.net/qq_36153312/article/details/102781633
作者:会飞的鲲
链接:https://www.zhihu.com/question/410413388/answer/1940097224
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
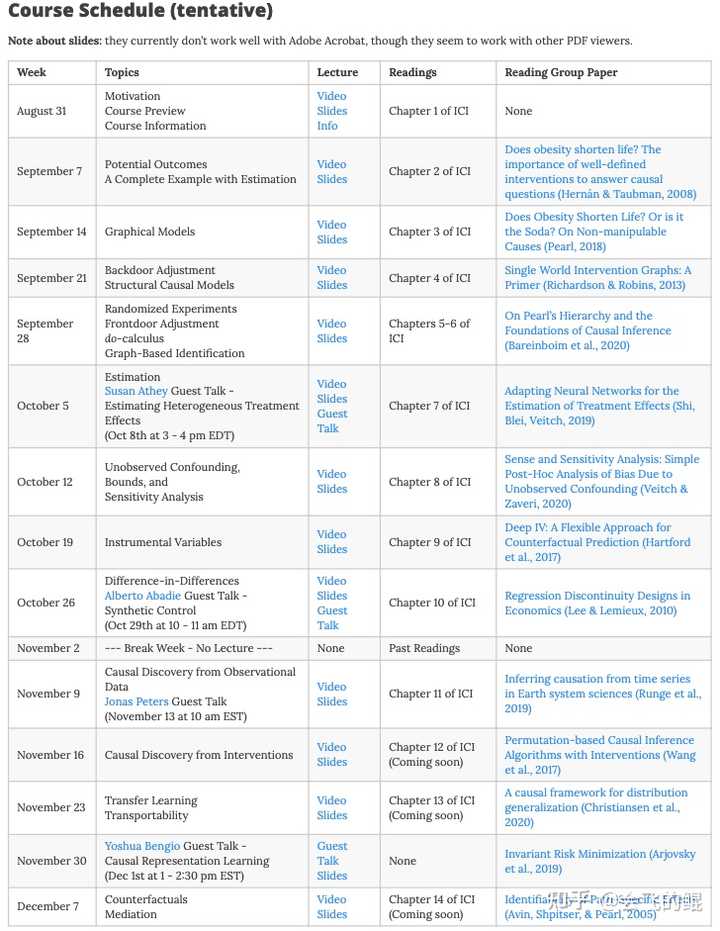
 Yoshua Bengio的高徒Brady Neal在网上开放了个公开课Introduction to Causal Inference,所有的资源都是开放的,以及小哥自己准备的资料。本课程难度不大,只要有概率论的相关基础都是可以的。
Yoshua Bengio的高徒Brady Neal在网上开放了个公开课Introduction to Causal Inference,所有的资源都是开放的,以及小哥自己准备的资料。本课程难度不大,只要有概率论的相关基础都是可以的。
课程的教材是作者自己写的,主要是从机器学习学习的角度来看待因果推理:Introduction to Causal Inference:from a Machine Learning Perspective,下载链接。
文章内容涉及到:概率图模型,后门调整,因果结构模型(Structural Causal Models),do算子(do-calculus)等等。
- 课程主页:Introduction to Causal Inference
- B站视频:B站链接

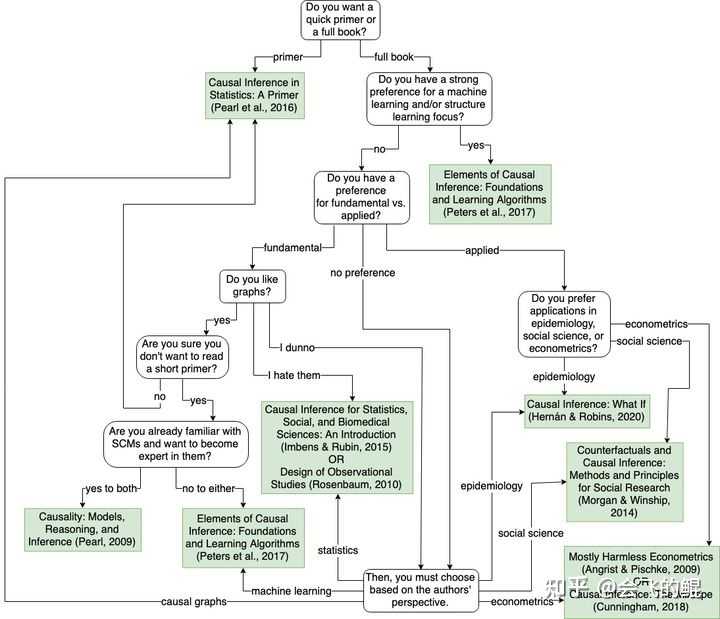
本课程的作者还写过一篇关于因果推理入门书籍的阅读介绍,我做了一个中文的翻译,感觉讲的很不错,对于入门因果推理很有帮助。
会飞的鲲:因果推断书籍which causal inference book you should read53 赞同 · 1 评论文章
 其他参考资料:
其他参考资料: